一種輕量級的處理器核性能分析框架*
2021-03-01 03:33:34雷國慶馬馳遠王永文
計算機工程與科學 2021年2期
雷國慶,馬馳遠,王永文,鄭 重
(國防科技大學計算機學院,湖南 長沙 410073)
1 引言
通用微處理器作為信息系統的基石,其重要性不言而喻。近二十年來,國家大力支持國產中央處理器CPU(Central Processing Unit)研發,打造出了以飛騰、龍芯和申威等為代表的國產 CPU 品牌,開發了涵蓋高性能計算、服務器、桌面終端和嵌入式等各個領域的 CPU 產品,并且在黨政軍地多個國產安全替代項目中批量應用,增強了國產化替代的信心。然而,現有的國產通用微處理器 CPU 也存在明顯的不足,技術指標與國際先進水平差距仍然較大。以體現了 CPU 核心性能的 SPEC2006 基準測試為例,當前 Intel 主流CPU 的 SPEC2006 得分超過40分[1],而國產CPU的SPEC2006得分只有 15~20 分,這說明國產CPU的核心性能與 Intel 主流水平相比還有 3~5 倍的差距。為了提升國產CPU 的可用性,必須進一步提升 CPU 性能,縮短與國際主流 CPU 的差距。
為了提升處理器特別是處理器核的性能,需要從架構設計、性能建模、邏輯實現和性能分析等多個方面進行大量的工作。隨著摩爾定律和 Dennard 縮放定律逐漸失效,單純依靠先進工藝帶來的性能提升越來越有限,架構設計在處理器中的作用越來越重要[2]。處理器架構特別是處理器微架構一般包含各種關鍵設計參數,如取指寬度、譯碼寬度、分派寬度、緩存大小(包括一級緩存、二級緩存、三級緩存等)、發射隊列端口數、發射隊列項數,執行部件數目和執行部件延遲等。為了獲得優化的設計參數,工業界和學術界都十分重視使用模擬器來進行處理器性能建模和微架構設計空間探索[3]。然而,性能失準是模擬器建模存在的問題,為了更好地發揮模擬器的作用,需要在處理器的開發過程中不斷地對模擬器進行性能校準和性能驗證[4]。
模擬器主要用于架構探索和處理器的 RTL 設計完成之前的性能分析和軟件開發。與模擬器相比,處理器的RTL模型準確度高,直接決定了最終芯片的實際性能,因此基于RTL模型進行性能分析是實際處理器設計中性能分析的重點。從處理器設計和實現的流程來看,處理器的設計和實現一般包括概要設計、詳細設計、前端RTL 設計編碼、功能驗證、性能測試、RTL signoff、物理設計、流片、硅前和硅后測試等過程。在實際流程中,處理器的RTL性能驗證在上述開發流程中處于中后期,并且在實際中一般以系統級的性能驗證為主。如果在系統級驗證中發現影響比較大的性能缺陷,則需要返回到前端修改RTL設計,設計修改較大時可能會導致重啟所有的功能驗證和性能驗證流程,使得研制進度嚴重滯后。因此,在系統級性能驗證之前,如何提前發現和快速定位 RTL 設計中引入的性能缺陷就顯得十分重要。
為了及時發現RTL設計中引入的和預期不符的性能缺陷,本文提出了一種輕量級的基于RTL 仿真的處理器核性能分析框架,在處理器核的RTL 代碼基本功能穩定以后,通過輸入輕量級的裸機測試激勵,即可基于該框架對新一代處理器核(New Core)的RTL設計實現的性能預期進行驗證,從而在核級驗證的早期及時發現性能設計缺陷。
2 相關工作
由于處理器的研制周期長,在處理器實際芯片生產完成之前,采用性能建模是處理器性能分析的一種重要方式。文獻[5]針對超標量微處理器的結構特點,提出了適用于大數據集基準程序的性能分析模型 MAMO(Mircroprocessor Analytical MOdel),采用指令窗口模型、功能部件受限模型、分支誤預測事件模型、指令和數據 Cache 失效模型等計算微處理器各個部件對程序CPI(Clock cycles Per Instruction,執行一條指令所需的平均時鐘周期數)的貢獻,從而估算處理器的實際性能。文獻[6]提出了一種使用高級語言對硬件建模的方法,并進一步建立了一種更高層的性能模型 Sim-godson。除了建立了高級語言性能模型,還建立了相關的性能分析環境,包括 RTL 和 FPGA 仿真環境以及一些輔助的軟件工具,主要用來驗證高級語言模型。性能建模存在的問題是模型準確度和實際測試之間存在偏差。文獻[5]對MAMO 模型和基準模擬器進行了對比校驗,指出對于 SPEC CPU2000 定點程序使用該模型進行 CPI 估算的平均誤差約為 8.53%。文獻[3]對體系結構模擬器在處理器設計中的重要作用進行了論述,并且對性能模擬器的校準方法進行了總結。
文獻[4]提出了一種單元級、核級和系統級整合的層次化的性能驗證方法學,從多種層次識別和解決性能缺陷。在單元級建立了參數敏感的性能模型和覆蓋率驅動的激勵,在核級給出了面向實現的性能校準和基于 RTL 模擬的基準測試,系統級則建立了原型和基于計數器的性能分析。文獻[7]給出了一種工具來對 Intel x86 指令的延遲、吞吐率和端口使用進行可信建模,從而為預測、解釋和優化軟件的性能提供依據。
性能測試和分析離不開測試程序,典型的來自真實應用的綜合性能的基準測試程序包括 SPEC CPU2006、SPEC CPU2017和PARSEC等[8]。這些測試程序通常規模較大,運行時間較長,但是使用廣泛。還有基于常用程序統計分析而設計的合成測試程序,如測試整數性能的 Dhrystone和CoreMark,測試浮點計算能力的 Whetstone 等。有的測試程序則是從科學計算中提取的核心循環代碼,如用于測試矩陣操作的Linpack、測試浮點運算能力的 Livermoore 等[9]。除了基準測試程序以外,研究人員也會針對自己的需求開發特定的性能測試程序。比如 IBM 公司面向 PowerPC 處理器開發了 alpha、beta和gamma 等一系列測試程序,龍芯團隊針對龍芯處理器性能分析開發了 Godson-Microbench 測試集,支持分支預測、部件資源利用率和計算延遲等分析[5]。
處理器性能建模需要從多種實現層次中對性能建模進行性能校準與分析,提升性能模型精度,從而為設計更高性能的處理器提供指導。與采用模擬建模并進行性能校準的方法不同,本文對處理器核性能提升研制中的基準處理器核(Base Core)和新一代處理器核2種處理器核 RTL 模型的性能進行對比分析,從而發現 New Core RTL設計實現中引入的性能缺陷。
3 性能分析總體框架
圖 1 給出了基于 RTL 仿真的輕量級性能分析框架,該框架主要包括激勵生成環境、模擬仿真環境和性能分析環境3個部分。其中激勵生成環境負責生成用于性能測試分析的測試激勵,包括生成測試程序源碼和編譯生成可執行二進制程序;模擬仿真環境用于對2種不同的處理器核執行模擬仿真,性能分析環境用于對仿真結果進行對比分析。
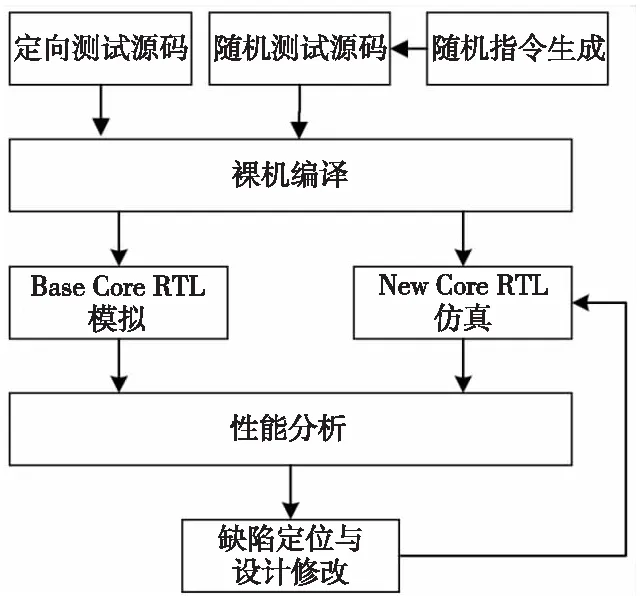
Figure 1 Overview of performance analysis framework
3.1 激勵生成環境
測試激勵類型包括定向測試激勵和隨機測試激勵2種類型。定向測試激勵是指針對特定的微架構性能敏感參數編寫的特定測試程序。定向測試程序的標準以針對性能參數敏感為有效,具體可以采用手工編寫匯編程序或者高級語言程序如C程序,也可以參考來自標準基準測試程序或者一些微基準測試程序來進行編制。隨機測試激勵主要是指根據指令模板采用隨機數生成的方式對指令模板進行實例化,從而生成一系列隨機匯編指令流。為了加速模擬速度,使用裸機編譯環境對測試激勵程序進行編譯和鏈接,并生成可執行二進制文件。相比依賴于操作系統環境生成的可執行文件,裸機測試激勵具有小巧、輕量的特點。裸機編譯環境包括交叉編譯環境、裸機環境下需要的基本函數庫等。
圖2給出了一種典型的測試激勵程序框架,圖2a中給出了該框架程序入口Main函數,Main函數首先對測試激勵需要的地址和數據空間進行初始化;然后調用Test_kernel函數實現測試。圖2b給出了Test_kernel函數的2種實現方式:一種是采用手工編寫匯編代碼的方式實現定向測試;另一種則為隨機生成的匯編指令流。通過使用計時器Timer,實現對Test_kernel的執行時鐘周期或者執行時間進行統計,用于對測試性能進行比較和分析。

Figure 2 Programming framework of test stimulus
3.2 模擬仿真環境
模擬仿真環境包括 RTL 仿真軟件、Base Core 和 New Core 的 RTL 設計源代碼、協同模擬驗證環境、若干編譯和運行腳本等。模擬仿真環境的輸入是源代碼文件和測試激勵二進制文件,輸出包括仿真波形文件、運行過程中產生的蹤跡文件等。波形文件的作用是發現功能和性能缺陷時方便設計師進行調試和分析。蹤跡文件則記錄了處理器核執行的所有指令流信息。對于每條指令,蹤跡文件需要記錄該指令的 PC 地址、指令編碼和匯編形式、指令分派和提交的時刻,以及指令讀寫寄存器操作數的結果。為了支持蹤跡信息的打印,模擬仿真環境需要支持對處理器核關鍵模塊信息的抓取。為了實時對計算結果進行驗證,模擬仿真環境需要支持協同功能驗證,能夠將每條指令的計算結果和參考模型計算結果進行比較,如果結果計算錯誤,則退出仿真,打印相關錯誤信息,以便設計師調試和分析。
圖3給出了處理器核仿真框架,該框架的頂層Testbench由Core和Memory實例化、設計協同仿真(Cosim env)、蹤跡打印(Trace print env)和波形dump等幾個模塊構成,仿真環境還依賴于仿真工具(Simulation tools)和協同仿真庫(Cosim lib)等。當仿真正常結束或者發現指令錯誤異常終止,設計協同仿真環境都會輸出一個驗證結果。為了加速仿真速度,實際過程中可以關閉協同仿真驗證環境和采用并行仿真加速。如果開啟了蹤跡打印或者波形輸出選項,仿真框架會生成模擬的蹤跡文件或者波形文件,以供分析和調試。
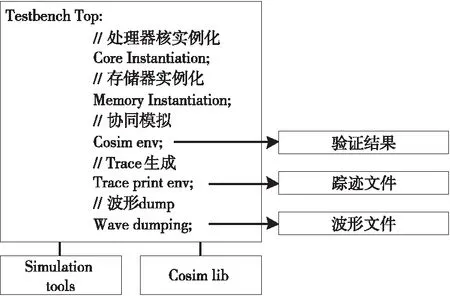
Figure 3 Simulation framework of processor core
3.3 性能分析環境
性能分析環境主要用于對Base Core 和 New Core 運行相同測試激勵生成的蹤跡文件進行信息提取和分析。對關注的指令執行時間區間進行分析,可以獲得關注指令區間所有指令執行的總的時鐘周期數,根據指令的條數,可以獲得相關指令的延遲、指令的吞吐率和CPI 信息等指標。除了蹤跡分析以外,性能分析環境還包括性能分析模塊,用于設置性能事件并對性能進行輔助分析。根據 New Core 和Base Core 的一些指令延遲、吞吐率等對比數據,如果發現與性能預期不符的情況,則需要進行性能調試和缺陷定位,必要時要對RTL設計進行修改。基于本性能分析框架,從修改RTL設計完成到編譯、運行、完成模擬仿真并獲得分析結果的時間一般在 15 min以內,輕量級的性能分析框架使得進行快速的性能分析和設計迭代成為可能。
圖4給出了指令吞吐率的計算方法,首先根據關注的時鐘周期區間計算得到區間內時鐘周期數,然后統計該區間內指令的條數,最后將指令條數除以時鐘周期數可以近似得到該時鐘周期區間內該指令的吞吐率。為了提升測試的準確度,關注的時鐘周期內應盡量執行多條同類型的指令,并減少其它類型指令的執行。

Figure 4 Computing method of instruction throughput
4 典型性能分析應用場景
基于表 1 給出的Base Core 和 New Core 的主要體系結構參數對比,結合本文所提出的性能分析框架,從Cache容量、指令延遲和吞吐率等方面對處理器核的性能進行分析。

Table 1 Comparison of architecture parameters for Base Core and New Core
4.1 Cache容量擴展性能測試
根據表 1 給出的參數,和Base Core相比,New Core在L1指令Cache和數據Cache 容量方面均是Base Core的2倍。一般地,大容量的L1 Cache 在Cache 失效率方面將比小容量 Cache 要低,因此可以預期具有大容量 Cache 的New Core 在執行相同程序時的執行時間將比Base Core 要短。為此,本文提出了基于順序指令執行和連續數據讀取的測試方法來分別對 L1 指令Cache和數據 Cache 進行性能測試,測試方法分別如圖 5a和圖5b所示。當指令 Cache 和數據Cache 載入容量超過 32 KB 時,Base Core 將會出現Cache 失效,導致性能下降,New Core 的性能應高于 Base Core的。如果實際過程中發現,相比 Base Core 性能,New Core 性能相當或者下降,那么就有可能存在與 L1 Cache 相關的性能缺陷。
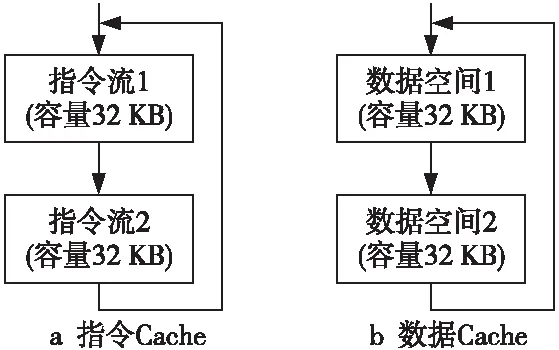
Figure 5 Performance test of L1 Cache volume extension
對于 L1 指令 Cache 和數據 Cache 容量測試,Base Core 和 New Core 分別同時循環多次執行 64 KB 容量大小的指令(每條指令大小為 4 B)和執行 64 KB 容量大小的數據載入操作,統計每次循環的執行周期數,并取平均進行比較。如圖6所示為L1 Cache擴容性能測試加速比。當 L1 指令 Cache 容量從 32 KB 擴展到64 KB 時,執行圖5a所示的指令測試流,New Core 的性能提升可以達到 7% 左右;而數據 Cache 容量從 32 KB 增加到64 KB時,執行圖5b所示的數據load操作,New Core 的性能提升可達 50%左右(New Core有2條load流水線)。由此可見L1 Cache容量擴展帶來的性能提升與預期總體上相符。
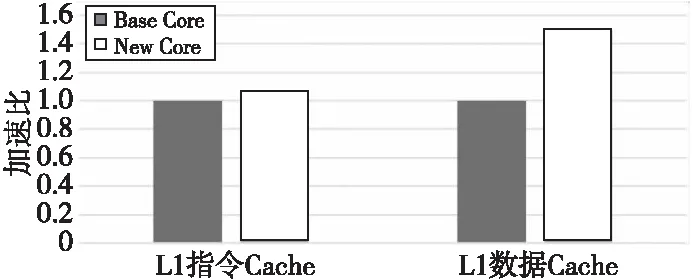
Figure 6 Performance test result of L1 Cache volume extension
4.2 指令延遲和吞吐率測試
指令延遲和吞吐率是處理器核性能的2種直觀性能指標。通過減少執行部件的執行延遲和增加計算部件數量能夠顯著優化指令延遲和提升吞吐率。例如,為了提升整數指令的吞吐率,現代微處理器普遍采用添加 ALU 數量的方式來增強整數計算能力。對于不同指令的延遲和吞吐率的測試,可以編寫定向或者通過隨機指令生成的方式產生相關指令的測試激勵,通過模擬結果分析得到蹤跡中指令執行區間的時鐘周期數和指令條數,進而計算得到指令的平均執行延遲和吞吐率等相關信息,從而對性能預期進行驗證。
在表1中,相比Base Core,New Core增強了ALU和load部件的數目,ALU部件的個數從2個變為3個,load部件從1個變為2個。由此可知,ALU或者load相關指令理論上的最大吞吐率將為3或者2。基于這個基本的性能預期,利用本文提出的性能分析框架就可以對相關指令的吞吐率進行測試。特別地,雙精度浮點乘加指令的吞吐率體現了單個處理器核的峰值浮點計算性能,為了測試峰值計算性能的可達性,可以構造全部由雙精度浮點乘加指令構成的定向或者隨機測試激勵,統計從第1條乘加指令到最后1條指令完成的時鐘周期數和乘加指令條數,從而可計算出乘加指令的實際吞吐率,通過對實際吞吐率進行測試就可以對浮點計算的峰值性能可達性進行測試。
實際測試中本文選取雙精度乘加指令 FMLA 進行測試,測試結果如圖7所示。隨著 FMLA 指令執行條數的增加,FMLA 的吞吐率也隨之增大,最終趨近于最大吞吐率 2。由此可知,通過測試FMLA的吞吐率,驗證了浮點計算峰值性能的可達性。
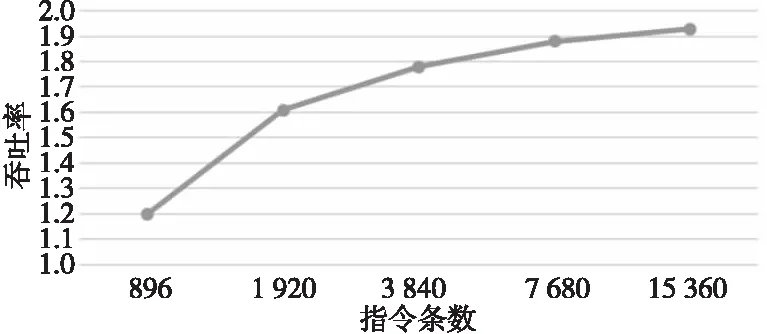
Figure 7 Throughput test result of FMLA instruction
5 結束語
本文針對處理器核性能提升研制過程中新一代處理器核RTL設計可能出現的性能缺陷,提出了一種基于RTL仿真的輕量級性能分析框架,并基于該框架給出了典型應用場景下的性能分析測試方法,從而在核級功能驗證的初期快速發現RTL設計中可能引入的與預期不符的性能缺陷,有效加速了新一代高性能處理器核的研制進程。未來我們將繼續對該框架進行完善,包括設計用于支持更多類型架構參數測試的測試激勵,對性能預期進行量化,并設計支持多種類型的性能分析和結果展示等。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
