基于空洞-稠密網絡的交通擁堵預測模型
2021-03-02 10:17:34蔡少委易清明
上海交通大學學報 2021年2期
石 敏, 蔡少委, 易清明
(暨南大學 信息科學技術學院, 廣州 510632)
在具有不確定性、非線性或時變性的數據中,提取數據的時空特征是獲取數據信息的一種重要方式,研究數據的時空特征信息提取方法對于提升模型的預測能力具有重要意義[1-4].在一些復雜的預測場景如在短時交通擁堵預測中,由于車輛速度容易受到包括鄰近道路交通擁堵情況、節假日等干擾因素的影響,使得車速數據波動較大且異常值較多.而常態和異常時的數據特征同樣重要,因此需要有效的方法來提取這些數據的時空特征信息.隨著近年來深度學習模型的廣泛應用,越來越多的深度學習預測模型通過不同的改進方式來獲取并利用數據的時空特征.羅文慧等[5]利用卷積神經網絡(CNN)能夠提取數據時空特征的特點,將CNN和SVR(Su-pport Vactor Regression)相結合應用于短時交通流預測.Deng等[6]提出基于CNN 的隨機子空間學習方法,將數據轉換成圖像的形式并進行時空特征信息的提取,從而提高了模型的預測能力.Lin等[7]利用稀疏自動編碼器提取數據的時空特征信息并作為LSTM(Long Short-Term Memory)的輸入,通過實際交通數據驗證了模型的有效性.Kang等[8]將車流量、車輛速度和檢測器占有率等數據同時作為LSTM的輸入方式,提高了輸入數據特征的多樣性,并達到不同數據特征共同影響預測結果的目的.An等[9]通過利用殘差網絡來增加卷積的層數并聯合不同時間間隔輸入建立起一個模糊卷積神經網絡深度模型,使得數據在時間上的特征信息能被充分利用.上述研究主要采用了LSTM和CNN兩種模型, LSTM更適合時間序列等具有波動性較小、異常值較少、變化規律較明顯的場景預測,在復雜的預測場景中,其對時空特征信息的提取不夠充分.而CNN模型由于感受野的變化能夠提取出不相鄰數據之間的結構信息,可以通過這個特點來獲取數據的時空特征信息,用于數據波動性較大、異常值較多的預測場景中[10-12].
考慮CNN提取數據時空特征信息的方法還存在一定存在缺陷,即模型在完成卷積過程后,需要通過池化過程來對特征進行壓縮,并對二維數據進行填充,該過程會使圖像特征的空間信息出現丟失.針對此問題,本文提出了空洞-稠密網絡結構模型.該結構利用空洞卷積能靈活控制卷積采樣間隔的特點[13],在降低模型復雜度的同時可以減小池化層的作用.此外,本文開辟了第2條下采樣通道,用于提取數據的顯著特征,然后將空洞卷積通道與下采樣通道在輸出部分進行稠密連接[14-16],使得更多的時空特征信息被傳遞,從而保證了模型結構的深度和預測精度,在道路擁堵預測等方面取得較好的預測效果.
1 空洞-稠密網絡結構構造
1.1 模型網絡結構
本文延用CNN的特征提取和分類器的方式,將輸入通過1層卷積后傳遞到以多個稠密塊為核心的稠密層中充分提取特征,稠密塊之間以卷積核大小為1×1的卷積層進行連接,最后通過兩層全連接層進行輸出,算法結構流程如圖1所示.其中稠密塊的數量取決于輸入矩陣的大小,全連接層為普通的前饋網絡,激活函數為Sigmoid.
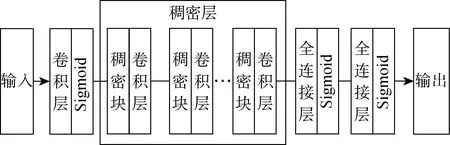
圖1 算法結構流程圖Fig.1 Flowchart of algorithm structure
1.2 輸入矩陣構造
考慮到同一類型的數據在相鄰的時間間隔上具有一定的延續性且不同采集數據區域具有關聯性的特點,本文將i個測量周期內j個不同區域采集數據以二維矩陣I的形式進行輸入:
(1)
式中:xi,j表示第i區域在j時刻的采集數據,i≥1,j≥0.每1行元素表示1個采集點從采集時間0到采集時間j的j個測量數據,每1列元素表示同一時刻不同采集點的i個測量數據,從而構成基于時空特征的輸入矩陣,并作為卷積層的輸入.
1.3 稠密塊構造
稠密塊主要由兩條通道構成,第1條空洞卷積通道由3個卷積塊組成,其中每個卷積塊由1層空洞卷積層、批量歸一化層和Sigmoid激活函數層構成,卷積塊的輸入為X,輸出為Y,通過改變空洞卷積的k值可以改變卷積核大小,并通過采用間隔r設置卷積核空洞的大小.第2條下采樣通道由兩層最大值池化層和1層1×1的卷積層組成.稠密塊的輸入為I′,空洞卷積通道和下采樣通道在通道輸出部分進行稠密連接,并輸出O,稠密塊的結構如圖2所示.
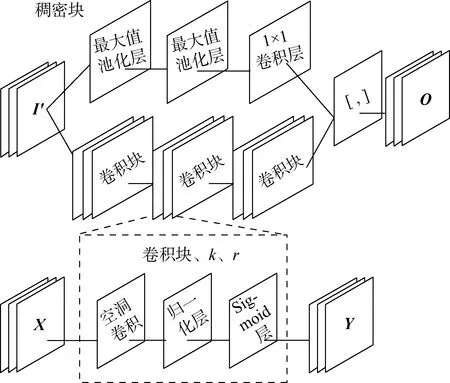
圖2 稠密塊結構圖Fig.2 Structure diagram of dense block
1.4 空洞卷積和下采用通道構造
空洞卷積是在普通的卷積核內部加入空洞,主要是通過控制r的大小來實現,如圖3所示.假設r為1、2和3時,3×3大小的卷積核下的感受野隨r的增大而增大.此外,隨著r的增大,空洞卷積的卷積核參數量與傳統卷積核的參數數量相同,而卷積過程的輸出能夠包含數據更大范圍內的特征信息.
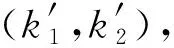
(2)
(3)
卷積核提取的特征大小滿足:
n1=[n+2p-k-r(k-1)]/(s+1)
(4)
m1=[m+2p-k-r(k-1)]/(s+1)
(5)
式中:p為卷積核移動的步長;s為特征圖填充的像素數.假設空洞卷積輸入X′的大小為M×N,卷積核權重W的大小為m×n,并且M≥m,N≥n,則卷積操作為
(6)
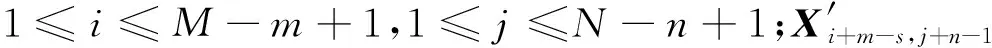
為了避免空洞卷積塊中的參數更新導致空洞卷積層的輸出發生劇烈變化,本文在空洞卷積層后增加1層批量歸一化層.通過引入小批量數據的均值和標準差來調整輸出,從而使整體模型輸出更加穩定.用f1(x)表示空洞卷積層的輸出,f2(x)表示批量歸一化過程的輸出,f3(x)表示批量歸一化層輸出,則數據歸一化過程為
(7)
f3(x)=γf2(x)+β
(8)
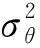
Y=Sigmoid(f3(x))
(9)
由于最大值池化層具有保留數據的顯著特征且能夠進行尺度放縮的特點[2],本文選擇最大值池化層對輸入稠密塊的數據進行下采樣,并將下采樣得到的特征通過卷積核大小為1×1的卷積層后作為該通道的輸出,使得顯著的特征能夠傳遞到輸出部分,并且特征塊能夠與空洞卷積層輸出特征塊大小相適應.
考慮目前特征塊連接的方式主要包括殘差和稠密連接兩種方式,相對于殘差網絡,稠密連接結合了殘差連接能夠使網絡更好地收斂的優點,同時僅需更少的參數數量,能夠降低模型整體參數數量.因此本文的稠密塊中兩條通道在輸出部分采用稠密進行連接,稠密連接為
O=[fy]
(10)
式中:O為輸出,將空洞卷積通道的輸出f和下采樣通道的輸出y進行稠密連接.
1.5 網絡訓練
空洞-稠密網絡結構訓練的過程由兩部分構成,輸入矩陣經過網絡模型進行正向傳播得到下一檢測周期的預測數據.對這些預測數據進行均方差分析,損失函數為
(11)
式中:N為輸入樣本的批量;Hi為空洞-稠密網絡模型的輸出值;Zi為數據的真實值.考慮本文選取的實測數據具有復雜多變且存在噪聲的特點,因此本文選擇Adam(Adaptive Moment Estimation)[17]梯度下降算法來更新模型參數,假設a時刻,損失函數L對于參數的一階導數為ga,則梯度的一階矩估計和二階矩估計式為
ma=β1ma-1+(1+β1)ga
(12)
(13)
(14)
(15)
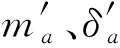
(16)
式中:η為學習率;ε為維持數值穩定性的常熟,設為10-8.Adam算法能夠通過梯度的一階矩估計和二階矩估計對不同模型參數自適應不同學習率,使得模型參數變化比較平穩有利于數據特征的提取.
2 實驗及分析
2.1 數據預處理
為了驗證空洞-稠密網絡結構的有效性,本文選擇對城市交通擁堵情況進行預測.本文數據來源于OpenITS聯盟提供的2016年8月1日至2016年9月30日的廣州214條匿名路段,主要是主干路和快速路的實測車速數據,數據監測周期為10 min.選取00∶00~24∶00時間段的車速數據進行訓練和預測,以數據的前55 d共 221 760 個數據作為訓練數據,后6 d共 24 192 個數據作為預測數據.由于車輛在發生擁堵時數據的波動較大,模型會出現受局部數據影響較大的情況,導致預測結果與真實數據擬合程度較差,預測精度較低.所以本文通過 Z-score 標準化方法對輸入數據進行預處理,預處理后數據符合標準的正態分布,減小了數值差異的影響,預處理公式為
μ′=(x-μ)/σ
(17)
式中:x為輸入矩陣I中的數據;μ為輸入矩陣樣本的均值;σ為輸入矩陣樣本的標準差.通過標準化后使得輸出數據μ′值在[0,1]之間.
2.2 網絡結構參數
考慮輸入矩陣大小和空洞卷積的采樣間隔對模型預測精度的影響,本文將模型的卷積核的統一設置為3×3大小,模型的學習率為0.01,批量大小為32,稠密塊個數為3,在Python的IDE PyCharm中進行實驗.通過對3種不同采樣間隔條件下輸入不同的道路數進行測試,道路數量每次增加4條,模型的訓練迭代次數為 8 000,得到損失函數值,如表1所示,其中Loss為損失函數值.
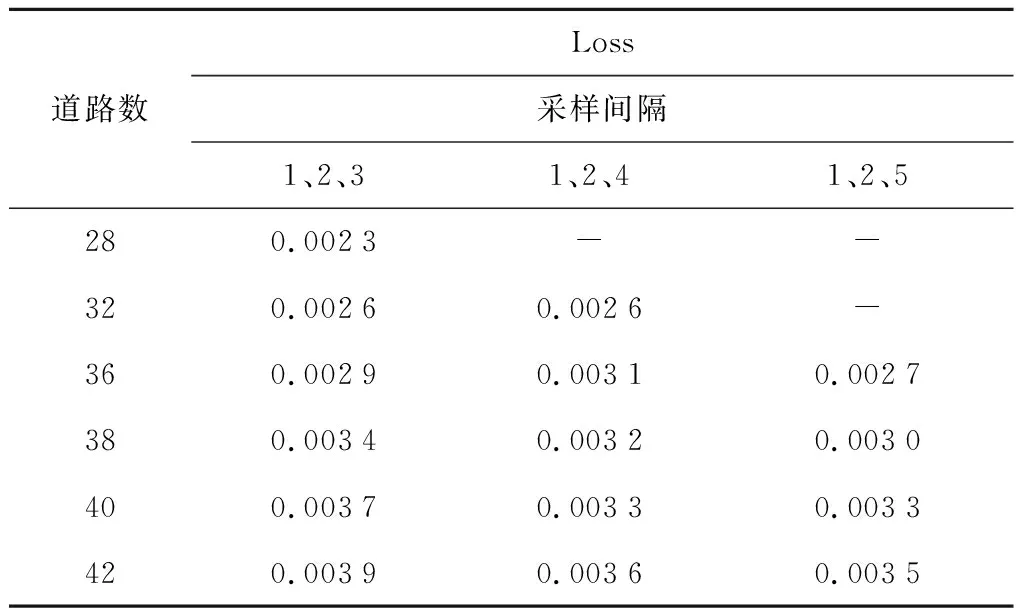
表1 道路數和采樣間隔配置表Tab.1 Road number and sampling interval configuration
可以看出,Loss越小,真實值與預測值的誤差越小.由于輸入矩陣中道路數決定輸入矩陣的行數,因此當道路數為28,采樣間隔為1、2、4 或1、2、5時不能滿足本文結構的要求,因此損Loss為空,適合采樣間隔為1、2、3,其他情況同理.此外,輸入矩陣增大,需要增大采樣間隔來減少對預測精度的影響.
2.3 直觀效果對比分析
選擇9月26日和9月27日相鄰兩天的數據作為假日和正常日的測試數據集并在同一框圖中進行表示.根據表1 的數據選取道路數為28,采樣間隔分別為1、2、3進行觀察,結果如圖4所示.圖中:t為時間,v為車速.t=0~24 h所對應數值為9月26日監測周期內所對應的車輛速度變化情況,t=24~48 h所對應的數值為9月27日監測周期內所對應的車輛速度變化情況.本文隨機列舉其中4條道路實際速度測量值和預測值,如圖5所示, 4個曲線圖分別為4條道路的車輛速度真實值與預測值變化情況.可以看出,真實值與預測值有相似的變化趨勢,擬合程度較高,在第1天8 h和第2天12 h左右道路發生擁堵時,車速預測值與真實值之間的誤差較小,在其他擁堵情況較平緩的時間段,預測值曲線與真實值的重合度較高.
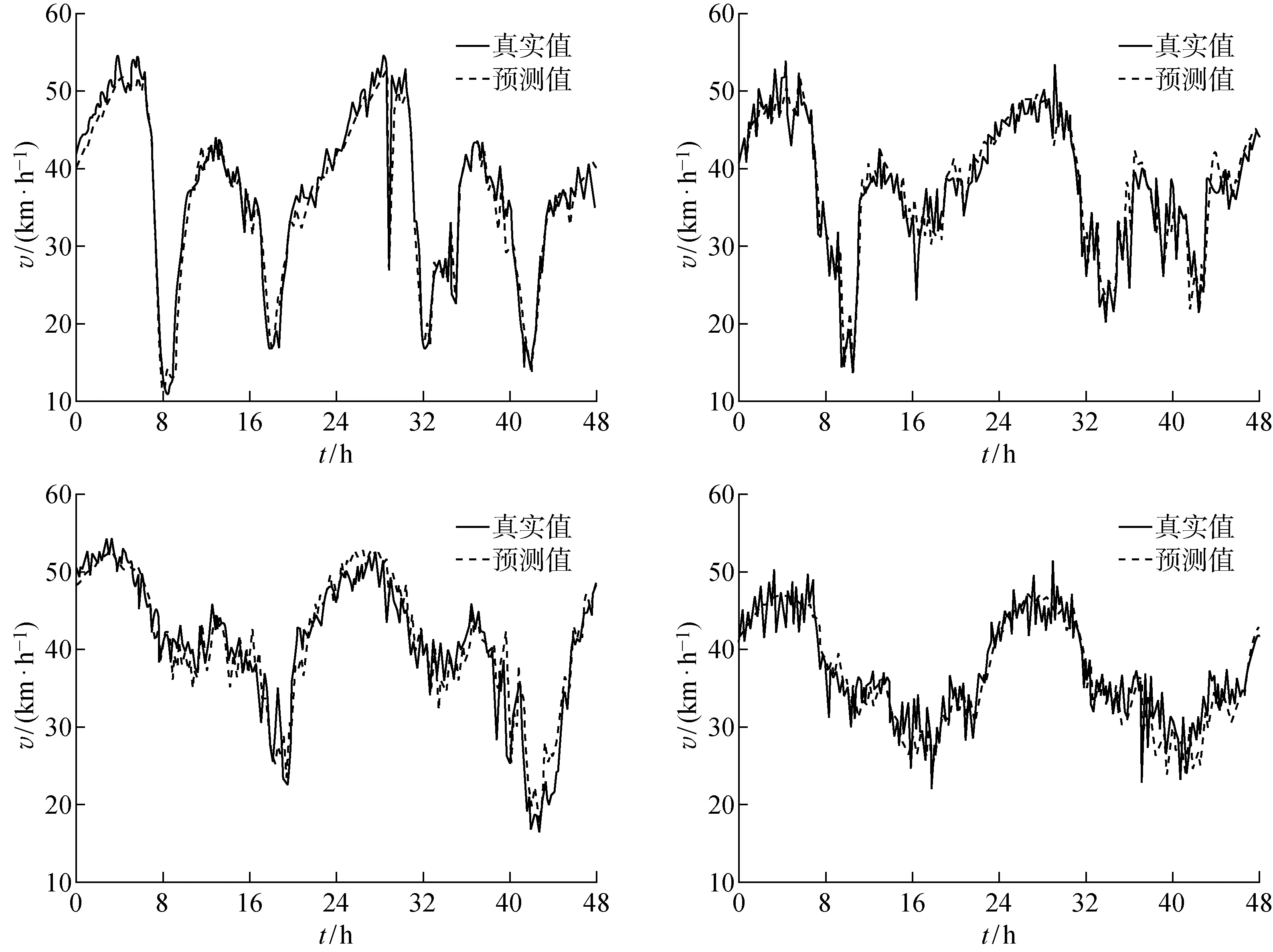
圖4 多條道路真實值與預測值對比Fig.4 Comparison of true and predicted values of multiple roads

圖5 4種模型在正常工作日和假日的殘差對比Fig.5 Comparison of residuals between four models on normal working days and holiday
空洞-稠密結構的預測曲線能夠較貼切地反映正常工作日及假日的真實車流量的變化情況,說明該結構能夠有效提取出輸入矩陣中波動較大點或異常值的特征,且能夠正確預測正常值部分的變化情況.此外模型的預測數據的是由28條道路的預測數據構成,因此本文模型可以在不增加計算量的同時對28道路進行預測,大大降低整體車輛擁堵預測系統的復雜度.
2.4 模型殘差對比分析
為了驗證模型的魯棒性,本文引入LeNet模型[11]、空洞卷積模型[13]、空洞-殘差結構模型及空洞-稠密結構模型,并對這些模型在正常工作日和假日兩天的真實值與預測值之間的殘差值進行分析.根據表1數據選取道路數為28,采樣間隔分別為1、2、3進行分析,結果如圖5所示.可以看出,LeNet模型在不同時刻的殘差值相對其他采用空洞卷積的模型的殘差值較大,而在速度變化較明顯的時間段4種模型的殘差值變化都較明顯.空洞-殘差結構模型和空洞-稠密結構模型相對空洞卷積模型的殘差值更小,在整體上空洞-稠密卷積結構模型比空洞-殘差模型的殘差值分布在更小的區域.從測試結果來看,空洞-稠密結構模型的殘差值相比較其他3種模型在車速正常狀態和異常狀態的情況下能保持較小值.
2.5 客觀參數對比分析
分析LeNet模型、空洞卷積模型及空洞-殘差結構模型的平均絕對誤差(MAE) 和均方根誤差(RMSE)來驗證模型結構的有效性,并且保證網絡模型參數的一致性.MAE 反映了預測值誤差的實際情況,而RMSE反映了預測的誤差分布情況,MAE和RMSE 值越小,預測模型擬合程度更好,預測精度更高,其表達式分別為
(18)
(19)
式中:Fi為預測值;Zi為實際測量值;M為測量值的數量.
4種模型通過訓練集進行訓練后,分別對9 月26 日和9 月27 日兩天車輛速度進行預測.選擇圖4中第1條道路數據,分析其MAE和 RMSE.
4種模型的MAE和RMSE如表2所示,相比LeNet模型和空洞卷積模型,空洞-殘差網絡結構模型和空洞-稠密結構模型的MAE和RMSE都有一定的降低,并且空洞-稠密結構相對空洞殘差結構模型MAE和RMSE更小.在測試集中,相比其他3種模型,空洞-稠密模型的MAE降低了約3%至23%,而RMSE降低了2%至26%.
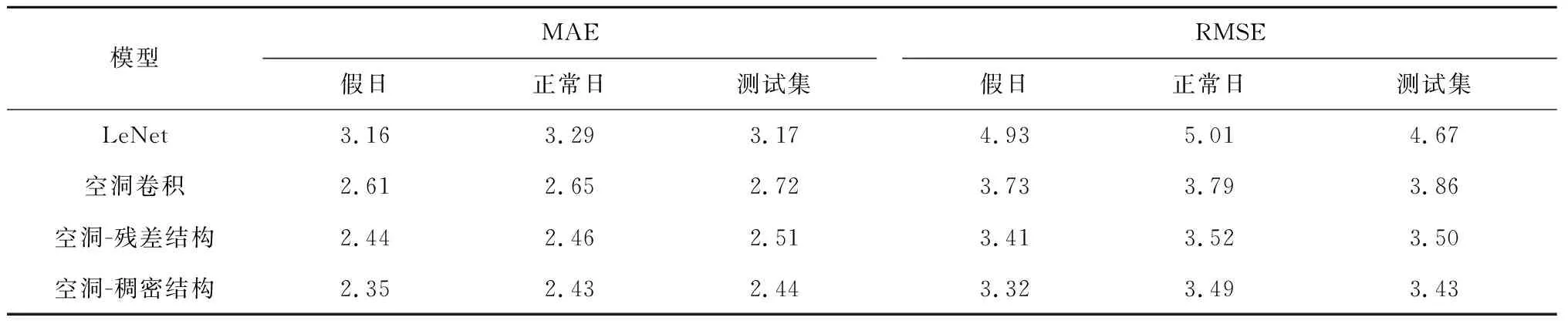
表2 空洞-稠密結構和其他3種模型的MAE及RMSE比較Tab.2 Comparison of MAE and RMSE between dilated convolution-dense network and the other three models
3 結語
設計了用于車輛擁堵預測的空洞-稠密神經網絡模型.該模型能更好地提取復雜數據的時空特征以及不同道路之間的關聯性信息,為預測過程提供更多的判斷依據,從而提高了車輛擁堵的預測性能.應用模型對廣州市的道路擁堵情況進行預測,并與其他模型進行了比較.結果表明空洞-稠密網絡結構的預測值與真實值的誤差相對較小,能夠較好地預測車輛速度.而且模型能夠實現同時對多條道路進行預測,在錯綜復雜、數量龐大的城市道路的擁堵預測中可以作為一種有效的方法.由于城市路段與高速路段受干擾因素的不同,表現出對模型結構要求的差異性.因此結合高速路段的相關因素,提高模型的泛化能力并研究模型在其他預測場景中的適用性是未來研究的重要內容.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
