融入BERT的企業年報命名實體識別方法
2021-03-02 13:30:18張靖宜賀光輝劉亞東
上海交通大學學報 2021年2期
張靖宜, 賀光輝, 代 洲, 劉亞東
(1. 上海交通大學 電子信息與電氣工程學院, 上海 200240; 2. 南方電網物資有限公司, 廣州 510641)
命名實體識別作為自然語言處理領域中的一項重要技術,與關系抽取[1]、事件抽取[2]、問答系統等其他自然語言處理任務的基礎相關.其主要負責準確、自動識別指定語料中實體(專有名詞或有價值的短語)的邊界并劃分實體類別.對企業年報進行命名實體識別可獲得企業的基本信息和財務數據,為企業評價系統提供數據支撐,有助于企業掌握行業發展現狀和趨勢、規劃發展方向、評估合作伙伴等.因此,準確識別企業年報中的命名實體是建立企業評價系統的重要途徑.
目前,命名實體識別方法包括:基于規則和字典、統計機器學習和深度學習.其中,基于規則和字典的方法需要手動建立知識庫和字典,耗時長且移植性差.基于統計機器學習的方法應用較廣泛,如隱馬爾科夫模型(HMM)、條件隨機場(CRF)、最大熵模型(ME)等,但以上方法需要人工設定特征模板,對語料庫的依賴性較大且對特征選取要求較高.與基于統計機器學習的方法相比,基于深度學習的方法能自動獲取語料特征,命名實體識別的性能更好.由于命名實體的標簽之間的依賴關系較強,所以Huang等[3]將雙向長短時記憶網絡(BiLSTM)和CRF結合,所得模型能夠利用過去和將來的信息更好地挖掘上下文關系.Chiu等[4-5]將BiLSTM和卷積神經網絡(CNN)結合,所得模型能夠更好地利用前、后綴的字符級特征,減少人工構造特征.Cho等[6]提出了門控循環單元(GRU),其比長短時記憶網絡(LSTM)少一個門,結構更簡單,訓練速度更快.王潔等[7]將字向量作為輸入,利用BiGRU-CRF模型提取會議名稱的語料特征,發現與LSTM相比,GRU的訓練時間減少了15%.Bharadwaj等[8]在BiLSTM-CRF模型的基礎上融入注意力機制,使模型更關注于對當前輸出貢獻大的字符.Cao等[9]提出利用對抗遷移學習框架進行命名實體識別,通過提取不同任務中的共享詞邊界信息并利用自注意力機制,學習句子中任意2個字符之間的依賴關系.Vaswani等[10]提出了利用自注意力機制快速并行的一種包含編碼器和解碼器的轉換器(Transformer)模型.Devlin等[11]提出了能夠更好獲取字符、詞語和句子級別關系特征的基于轉換器的雙向編碼器表示(BERT)預訓練語言模型.
對企業年報進行識別的難點主要如下:① 專業財務術語、企業名稱實體繁多.其中,如凈利潤、營業收入等財務術語的專業性較強;企業名稱包括以“有限公司”“集團”等為尾的全稱和僅包含企業名稱關鍵信息的簡稱;② 數值信息多且數字實體的識別難度大,如“公司2011年末總資產和歸屬于上市公司股東的所有者權益分別為 170 704.67 萬元和 156 542.08 萬元”,需要正確識別出財務術語對應的數值信息及其單位;③ 財務數值相對于上年變化趨勢的描述方式多變,如下降10%、同上年持平等;④ 企業年報語料庫規模較小,僅為1998年人民日報語料庫的19.28%.
針對以上問題,提出BERT-BiGRU-Attention-CRF融合模型.在基礎模型BiGRU-CRF上引入BERT預訓練語言模型,并在大型語料庫上進行預訓練學習語義特征,補足企業年報語料庫的特征,克服語料庫規模小的問題.同時,BERT利用Transformer模型提升自身模型的抽取能力,能夠更好地明確實體邊界.此外,在BiGRU-CRF模型中引入注意力機制,便于理解句子結構,從而充分挖掘上下文的語義信息,進一步提升實體的識別性能.
1 企業年報數據集的構建
目前,關于企業年報的命名實體識別方法的研究較少,且缺乏實驗測試所需的典型數據集,因此本文利用網絡爬蟲技術抓取企業官方年報,自行構建和標注該領域的數據集.具體構建步驟如下:
(1) 數據預處理.利用正則表達式從每份年報中自動提取出“企業經營概況”標題下的語段.
(2) 實體類別確立.構建企業評價系統需要從企業年報中獲取企業的基本信息和經營狀況.其中,基本信息包括年份和企業名稱共兩類實體;通過閱讀企業年報和利用詞頻-逆文檔頻次(TF-IDF)算法[12]提取關鍵詞的方式,選取與“利潤”和“收入”相關的財務指標概括企業的經營狀況.自行標注的實體共7大類,如表1所示.
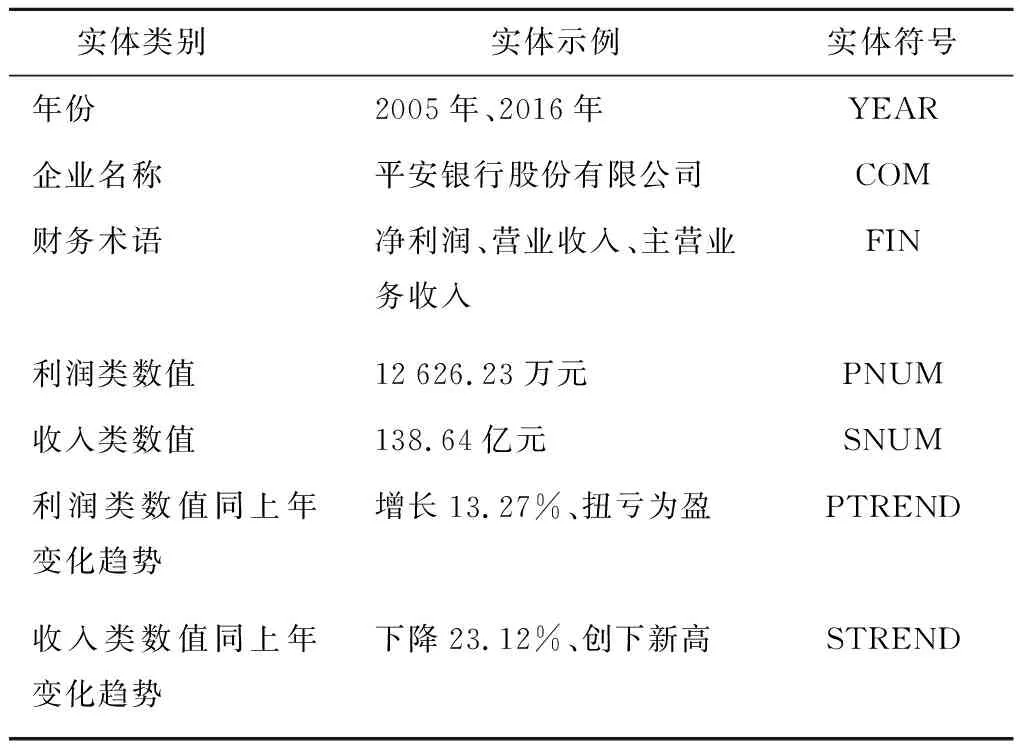
表1 企業年報實體Tab.1 Entities of enterprise annual report
(3) 標注體系.實驗采用的標注體系為BIO.其中,B代表實體的起始位置,I代表實體中除起始位置的其他部分,O代表非實體部分.需要預測的實體共15小類,標注示例如表2所示.

表2 標注示例Tab.2 A example of labeling
2 BERT-BiGRU-Attention-CRF模型
本模型由BERT預訓練語言模型、BiGRU網絡、注意力機制和CRF層構成.首先,把輸入字符的字向量、文本向量和位置向量之和作為BERT的輸入.利用BERT獲取上下文語義信息,把融合語義后的輸出向量輸入到BiGRU網絡進行編碼,前向GRU網絡學習未來特征,反向GRU網絡學習歷史特征.然后,將挖掘得到的全局特征,即t時刻的隱藏狀態(ht)作為輸出,并利用注意力機制補足局部特征,預測出輸入文本序列與標簽之間的關系.最后,利用CRF進行解碼預測標簽之間的合理性關系,輸出最佳標簽序列,模型結構如圖1所示.
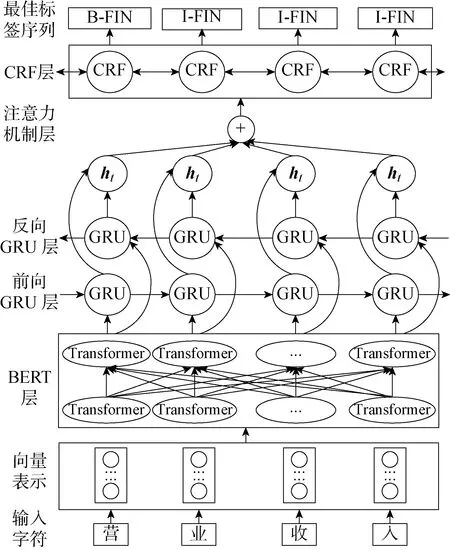
圖1 BERT-BiGRU-Attention-CRF模型結構Fig.1 Structure of BERT-BiGRU-Attention-CRF model
2.1 BERT預訓練語言模型
BERT預訓練語言模型將深度學習的思想融入語言模型中,可將詞表征為向量形式, 從而獲取詞語之間的相似度[13].在雙向Transformer編碼器(見圖2)的基礎上,該模型提出了“掩碼(Masked)語言模型”和“下一句預測模型”.Masked語言模型通過對語料中15%的信息進行遮蓋,最大程度地使模型在每1個詞上都能夠學習到全局語境下的表征,從而令BERT獲得的相關詞向量更貼合語境.具體遮蓋方法為80%的遮蓋信息替換為[MASK];10%的遮蓋信息替換為任意詞;剩余10%的遮蓋信息保持不變.同時,BERT也借鑒了Skip-thoughts中的句子預測方法[14],可以學習句子級別的語義關系:為每個預測樣例選擇1個句子對A和B,讓模型預測A和B是否先后近鄰,從而將“下一句預測”問題轉化為二分類問題.其中,50%的B為A的下一個句子,標記為“IsNext”;剩余50% 的B為語料庫中的1個隨機句子,標記為“NotNext”.具體編碼過程如下所示.
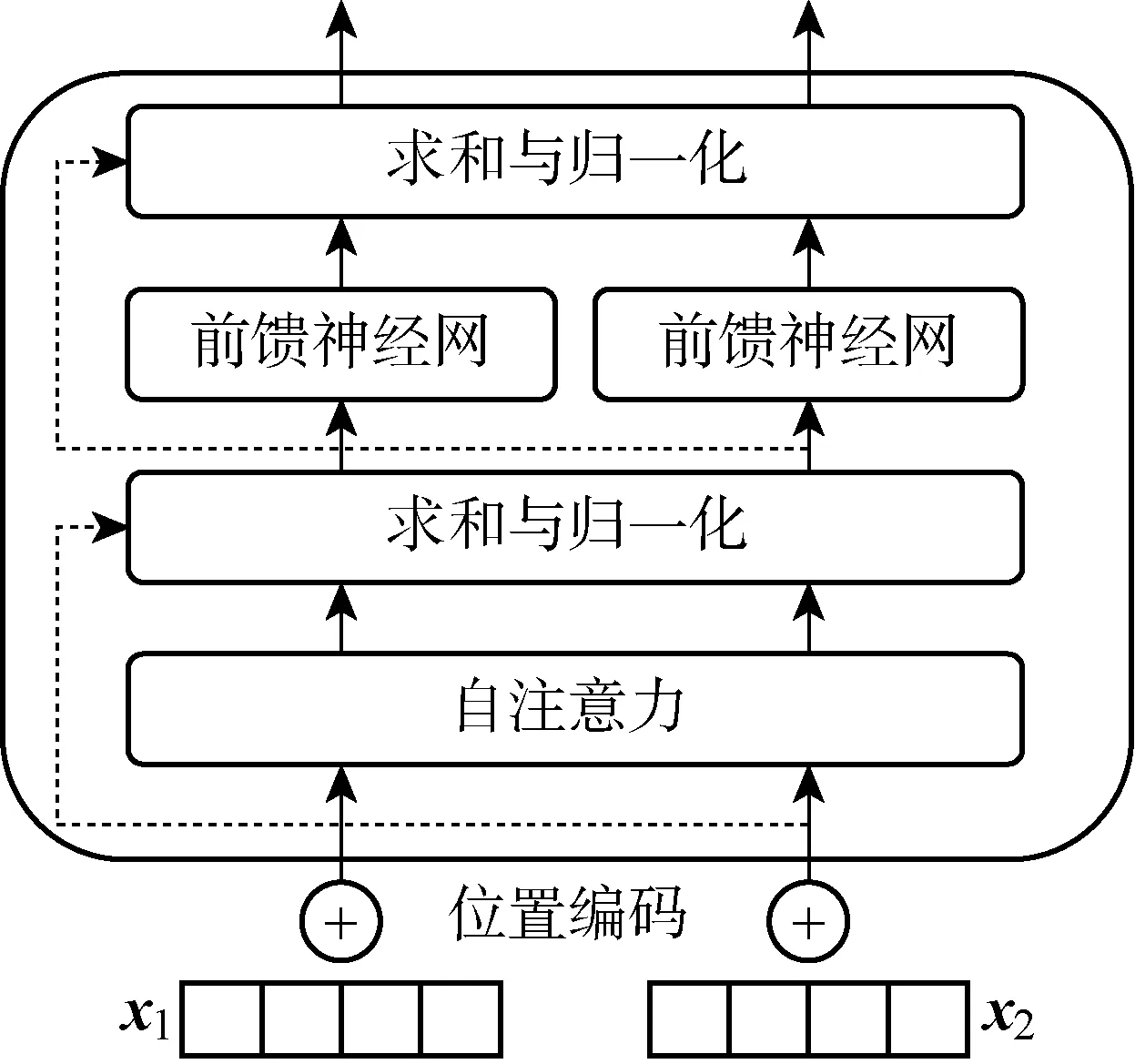
圖2 Transformer編碼器結構Fig.2 Structure of Transformer encoder
首先,將輸入序列X=(x1,x2, …,xT) 經過詞嵌入(EL)和位置編碼(PE)加和后作為Transformer編碼器的輸入:
Xe=EL(X)+PE(X)
(1)
式中:Xe為經過詞嵌入和位置編碼后的輸入序列.位置編碼提供每個字符的位置信息, 以便Transformer理解句中字詞的順序關系.詞語在句子中的位置不同可能導致語義不同,因此需要對序列中詞語的位置進行編碼:
(2)
(3)
式中: pos為詞語在句子中的位置;dmodel為PE的維度.
為了提取多重語意含義,輸入向量需要經過1個多頭自注意力機制層:
(4)
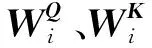
(5)
式中:dk為輸入向量的維度.利用注意力權重對字向量進行加權線性組合,使每個字向量都含有當前句子內所有字向量的信息.
然后,對上一步的輸出做一次殘差連接(X1)和層歸一化:
X1=Xe+Attention(Q,K,V)
(6)
(7)
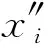
最后,將經過殘差連接和層歸一化處理后的信息輸入到前饋神經網絡中,重復進行一次殘差連接和層歸一化后輸出.
2.2 BiGRU神經網絡
GRU是LSTM的變體.相比于由3個門函數(輸入門、遺忘門和輸出門)構成的LSTM,GRU僅由2個門函數構成,即更新門(輸入門和遺忘門的結合體,決定過去傳遞到未來的信息量)和重置門(決定過去信息的被遺忘量).2個門控機制能夠保存長期序列中的信息,決定哪些信息能夠作為門控循環單元的輸出.此外,GRU具有模型精簡、計算速度快、參數少等優勢,在小樣本數據集上的泛化效果更好.GRU的具體結構如圖3所示,表達如下:
(8)
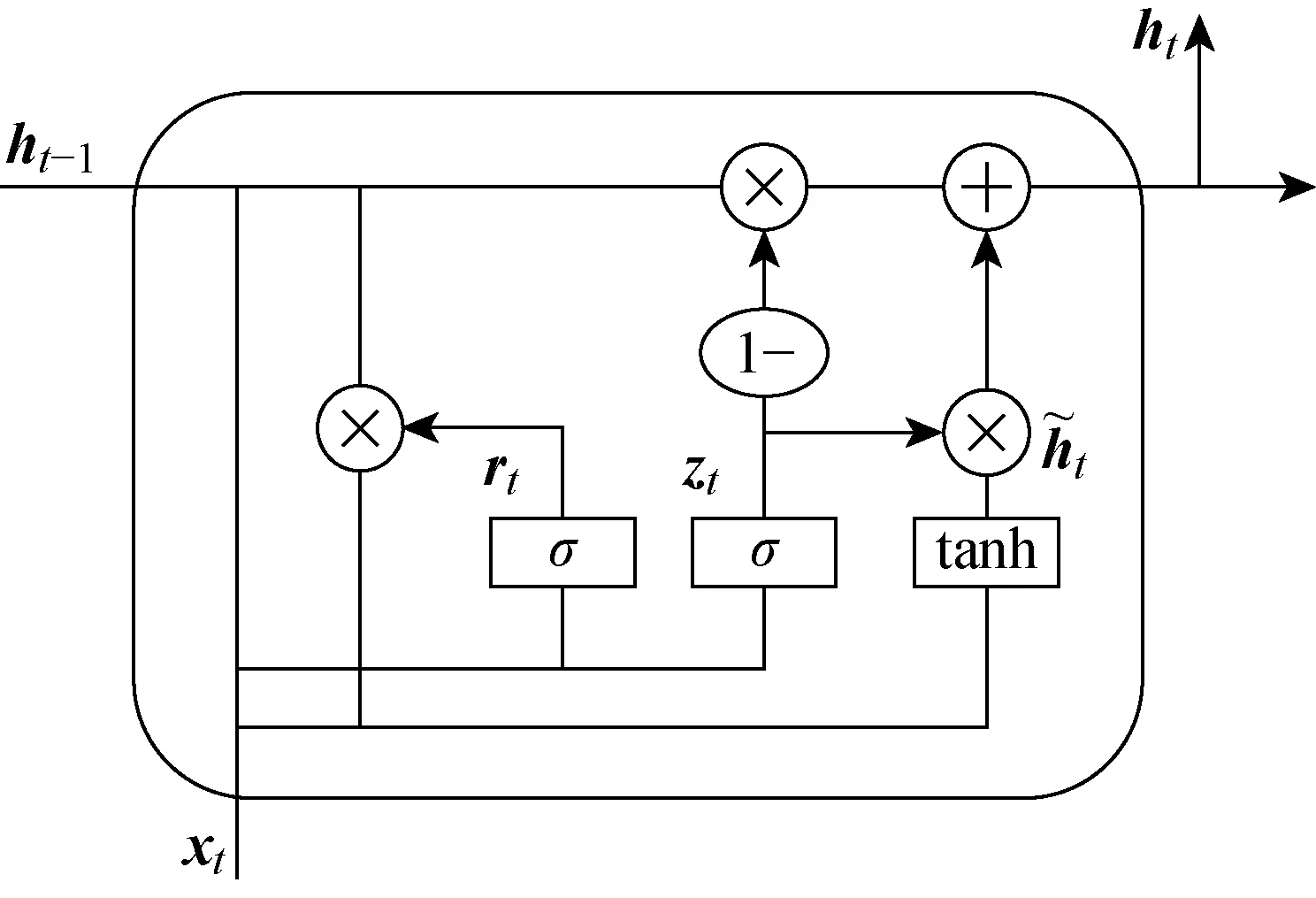
圖3 GRU結構Fig.3 Structure of GRU
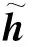
2.3 注意力機制層
BiGRU網絡在獲取語料局部特征上存在不足.因此,本文利用注意力機制學習句子中任意2個字符之間的依賴關系,獲取句子的內部結構信息.注意力機制使命名實體識別模型更專注于挖掘與當前時刻輸出相關的輸入信息和局部信息.利用注意力機制對BiGRU層輸出的特征向量(hj)進行權重(atj)分配,計算得到t時刻BiGRU和注意力機制層共同輸出的特征向量(ct),并作為最后的輸出:
(9)
式中:etj為對齊模型;v、w和m為權重向量.
2.4 CRF層
BiGRU層雖然可以學習上下文之間的特征信息,選出最大概率值的標簽作為輸出,但是不能獲取輸出標簽之間的依賴關系,可能導致2個相同標簽相互接連.而CRF具有轉移特征,能夠考慮輸出標簽之間的順序性.因此,選擇CRF作為BiGRU和注意力機制的輸出層.
(10)
式中:pi,yi為第i個位置標簽輸出為yi的概率;Ayi,yi+1為從標簽yi轉移到yi+1的轉移概率.對于每一個X′,得到所有可能的標簽序列的分數,則歸一化結果和損失函數分別為
(11)
ln(p(y|x′))=s(X′,y)-
(12)
最后,利用維特比(Viterbi)算法[15]得到最佳預測標簽序列:
y*=argmax(s(X,y))
(13)
Viterbi算法利用動態規劃算法解決CRF的預測問題,可以尋找概率最大狀態路徑.
3 實驗與分析
3.1 數據集及標注體系
實驗搜集了近5年的企業年報,涵蓋 2 927 家公司,共 13 129 份.經過數據清洗和預處理后,按照6∶2∶2的比例將其劃分為訓練集、測試集和開發集.表3為企業年報數據集的詳細結構,表4為數據集中實體類別個數分布.
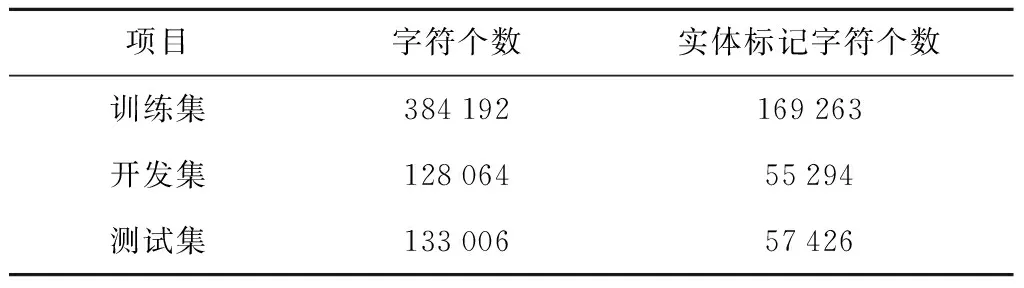
表3 企業年報數據集結構Tab.3 Dataset structure of enterprise annual report

表4 實體類別個數分布Tab.4 Number distribution of entity categories
3.2 實驗環境和參數設置
在Python 3.7.3和Tensorflow 1.13.1框架下進行模型的訓練和測試.實驗利用BERT-Base模型,其含有12個Transformer層,768維隱層和12頭多頭注意力機制.GRU網絡的隱層設為128維.注意力機制層設置為50維,最大序列長度設置為256.優化函數采用Adam,學習率設置為5×10-5,dropout層設置為0.5.
3.3 評估標準
實驗利用精確率(P)、召回率(R)和F1值共3個指標評價7大類實體的命名實體識別效果,3個評價指標的計算方法如下:
P=a/b
(14)
R=a/c
(15)
F1=2PR/(P+R)
(16)
式中:a為正確識別實體數;b為識別實體總數;c為所有實體總數.
4 實驗結果與分析
BERT-BiGRU-Attention-CRF模型對不同實體的識別效果如表5所示.其中 “年份”“企業名稱”“財務術語”“利潤類/收入類數值”實體有較高的P、R和F1值.模型對“利潤類/收入類數值同上年變化趨勢”實體的識別性能相對較差,主要是由于該類實體表達形式較復雜,包括純文字表達、文字和數字組合表達等,且描述變化趨勢的文字表達形式多樣.對此,可以通過深入的劃分實體、融合詞典特征和改進模型等方式,令實體學習更多語義特征.
為了驗證BERT-BiGRU-Attention-CRF模型在企業年報命名實體識別中的優異性,在同一數據集上,分別對CRF、 BiGRU-CRF、BiGRU-Attention-CRF和BERT-BiGRU-CRF模型進行實驗,對比結果如表6所示.此外,利用雷達圖顯示不同實體在不同模型上的F1值,如圖4所示.由圖4可知,BERT-BiGRU-Attention-CRF模型在7大類實體上的F1值都處于較高水平,說明該模型在企業年報領域的識別性能高于其他模型.
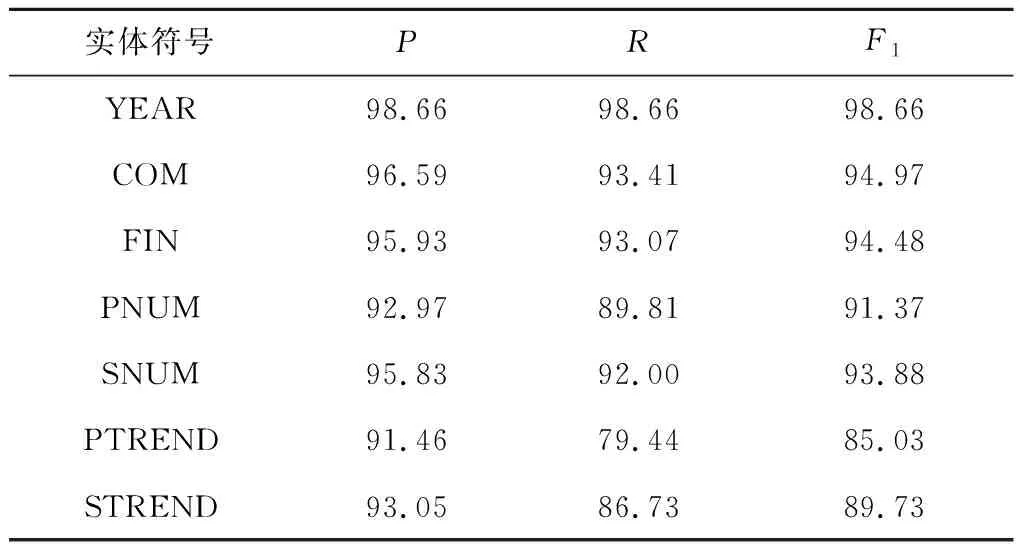
表5 不同實體識別效果Tab.5 Recognition effect of different entities %
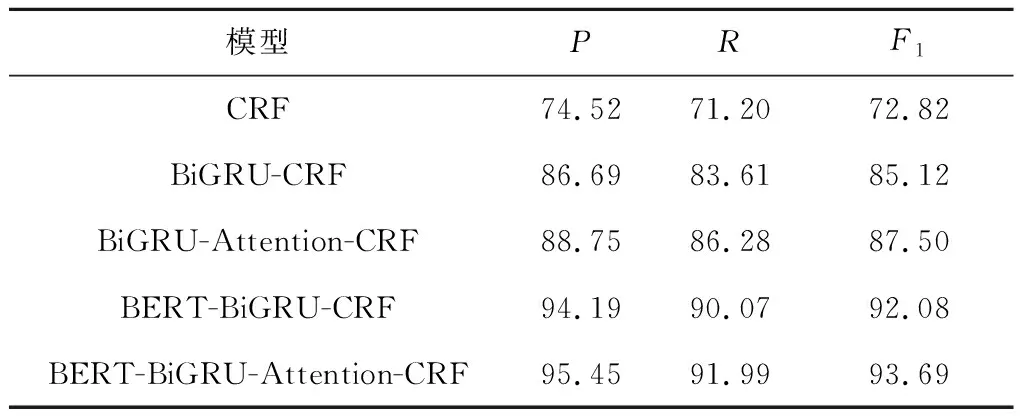
表6 不同模型實驗結果Tab.6 Experimental result of different models %
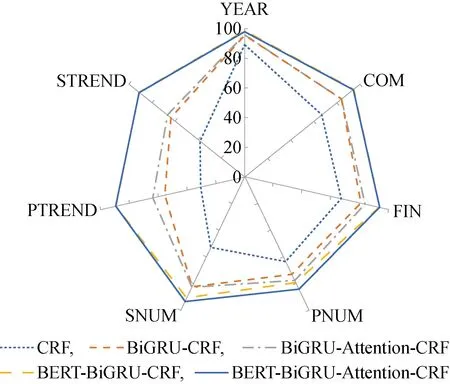
圖4 不同實體在不同模型上的F1值(%)Fig.4 F1 values of different entities in different models (%)
不同模型結合不同實體的具體分析如下:
(1) CRF模型是基于統計的命名實體識別方法,由于CRF是在分詞的基礎上通過設置特征模板獲取語料的特征,所以對“企業名稱”“財務術語”“利潤類/收入類數值”和“利潤類/收入類數值同上年變化趨勢”這4類屬于未登錄詞的實體識別效果較差,其F1值均在68%以下.
(2) 相比于CRF模型,BiGRU-CRF模型整體的F1值提高了12.3%,且對未登錄詞實體的邊界劃分更準確.這是因為未登錄詞實體的構成較復雜、詞長較長,CRF特征模板只能在有限的窗口范圍內進行提取,而BiGRU網絡可以更好地利用上下文的語義特征,如更善于區分 “凈利潤”和“歸屬于母公司的凈利潤”這類易混淆詞語、識別出更多完整的企業名稱和簡稱.
(3) 相比于BiGRU-CRF模型,BiGRU-Attention-CRF模型的F1值提高了2.38%.句子中不同的字詞和上下文的關聯程度不同,而注意力機制可以關注更多的局部特征,特別是和當前輸出有關聯的信息,如識別句“實現凈利潤13億元”中的“利潤類數值”實體,詞語“凈利潤”與實體的關聯程度大于詞語“實現”,則注意力機制會更關注 “凈利潤”和實體之間的關系.
(4) 相比于BiGRU-CRF模型,BERT-BiGRU-CRF模型的F1值提高了6.96%;相比于BiGRU-Attention-CRF模型,BERT-BiGRU-Attention-CRF模型的F1值提高了6.18%,具體反映為“收入類數值”和“利潤類數值同上年變化趨勢”2類實體的F1值分別提高10.38%和25.31%.這2類實體和上下文之間的關聯較強,且表達方式較靈活,如在字詞級別方面,“數值”實體中單位的表示方式有元、萬元、億元等;在句子級別方面,“數值同上年變化趨勢”實體有文字-數字結合(漲幅/增長/下降+百分比)和純文字描述(創下新高、扭虧為盈)共2種表達方式.此外,融入BERT模型的企業年報命名識別方法更能夠結合語義找到數值和財務術語的映射關系,尤其適用于同時包含2個數值的句字,如“營業收入和主營業務收入分別為13萬元和10萬元”.綜上可知,BERT通過在大型語料庫上學習獲得更多語義特征,可以對企業年報這一小規模語料庫進行特征補足;其利用雙向Transformer結構進行基于上下文語境的深度雙向語義理解,提高特征抽取的能力和邊界不明顯且表述靈活實體的識別效果.此外,BERT能夠學習字符級、詞級和句子級關系特征,可以更全面地理解句子語義.
5 結語
企業年報命名實體識別為企業評價系統的建設提供了基本企業信息和經營情況的數據支撐.本文提出了BERT-BiGRU-Attention-CRF模型.在基礎模型BiGRU-CRF上引入BERT預訓練語言模型,以獲得與上下文有關聯的雙向特征表示,更加深刻地理解語義,克服了企業年報語料庫規模小、實體專業性和映射關系強的問題.然后,采用注意力機制改進BiGRU-CRF模型,使模型可以選擇性地關注重要信息,提高信息的有效關注率.自建企業年報語料庫的識別結果表明:BERT-BiGRU-Attention-CRF模型能夠較好地識別企業年報中的實體,可以達到95.45%的精確率和91.99%的召回率以及93.68%的F1值,能夠滿足應用需求.在后續研究中,將擴大語料庫規模,進一步完善并規范企業年報的實體標注,提取更多有價值的實體,并在保證性能的基礎上,對模型結構進行簡化.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語學刊(2011年1期)2011-01-22 03:38:33
