GAN網絡混合編碼的行人再識別
2021-03-02 13:38:58張玉霞
液晶與顯示 2021年2期
楊 琦, 車 進*, 張 良, 張玉霞
(1. 寧夏大學 物理與電子電氣工程學院,寧夏 銀川 750021; 2. 寧夏沙漠信息智能感知重點實驗室,寧夏 銀川 750021)
1 引 言
行人再識別[1](Person ReID)可以看作是一個跨攝像機視角的人物檢索問題,旨在建立多個攝像機圖像之間的身份對應關系。由于拍攝角度、光照、姿勢、視角、圖像分辨率、相機設置、遮擋和背景雜波的影響,會導致同一行人的不同圖像可能會有顯著不同,造成較大的類內差異,這使得行人再識別仍然是一項充滿挑戰性的任務。
隨著深度學習在行人再識別任務中的廣泛應用,卷積神經網絡由于其強大的特征表達能力以及學習不變的特征嵌入,近年來涌現出各種各樣的深度學習算法,尤其在GAN網絡方面取得不錯的進展。生成對抗網絡最初是由Goodfellow等人[2]提出,被描述為一個通過對抗訓練生成模型的過程。GAN由生成圖像的生成器(G)和鑒別器(D)組成,這兩個組件在極小極大值之間進行博弈。文獻[3]提出將GAN擴展到CNN領域,使得利用GAN獲取的訓練樣本更加可控,進一步說明了GAN網絡在計算機視覺任務中的可行性。
眾所周知,深度學習的發展得益于大數據的發展,而在如今行人再識別課題中,面臨著數據不足與類內差異明顯等問題。作為GAN網絡的先行者,文獻[4]提出一種標簽平滑的方法,利用生成的數據擴充原始數據集,一定程度上提高了行人再識別的精度。不同于文獻[4]采用標簽平滑對生成圖像的標簽采用平均的策略,文獻[5]采用偽標簽的策略,對生成圖像采用最大概率預測為其分配身份,作為具備真實標簽的數據使用。文獻[6]提出一種識別模型與GAN中的判別器共享權重進行聯合優化。文獻[7]基于不同攝像機類內差異,生成不同相機風格的行人圖像。此外,最近的一些研究學者開始將姿態估計應用到GAN網絡中。文獻[8]為減小姿態不同對行人外表的影響,使用PN-GAN將數據中的所有行人歸一化到8個姿態中,將真實數據中提取到的行人特征和生成數據中提取到的行人特征融合之后做ReID匹配。文獻[9]提出一種基于姿態遷移的 ReID 框架,通過引入姿態樣本庫,進而生成多姿態標簽樣本。文獻[10]利用姿態引導的 GAN 網絡,學習與身份相關且與姿態無關的特征,使得生成的行人圖像與姿態特征無關。不同于上述算法,也有學者將不同特征進行融合得到新的特征表示。文獻[11]提出一種多尺度殘差網絡模型,融合不同的特征得到最終的特征表示。文獻[12]提出一種融合了全局特征、局部特征以及人體結構特征的行人再識別算法,該算法無需引入任何人體框架先驗知識,并采用多級監督機制優化網絡。文獻[13]提出一種利用姿態遷移來生成行人圖片,并利用兩種不同的獨立卷積神經網絡提取圖像特征,融合兩種特征得到最后的特征表示。
不同于上述GAN 網絡,本文提出一種基于外觀特征和姿態特征混合編碼的行人再識別網絡,生成模型通過切換外觀特征以及姿態特征,結合兩幅圖像中的特征混合編碼生成高質量圖像,進一步降低了類內差異造成的影響。網絡采用外觀損失、姿態損失、對比損失、判別損失等多損失函數對生成的圖像進行監督,進一步提高生成圖像的質量。利用擴充數據集對網絡進行訓練,使得網絡模型更加健壯。
2 網絡架構
網絡架構如圖1所示。將原數據集中的人物圖像輸入到生成對抗網絡,利用輸入圖像的姿態特征以及外觀特征進行自圖像以及互圖像生成,將生成的人物圖像結合原數據集中的人物圖像共同輸入到卷積神經網絡,對網絡進行訓練,一方面擴充了原數據集中圖像不足的問題,另一方面利用這種自圖像與互圖像生成模式進一步挖掘了圖像的細粒度特征,使得訓練的模型更加魯棒。
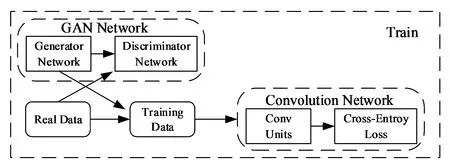
圖1 網絡架構
2.1 生成網絡
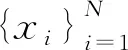
2.1.1 自生成網絡
.
(1)
考慮到yi=yj,即為同一行人的不同圖像, 行人圖像的外觀特征是相近的,因此提出一種利用同一行人的不同圖像來生成圖像的方法。即采用圖像xi的姿態特征,僅采用圖像xj的外觀特征。由于外觀特征是相似的,所以基于同一行人的圖像生成應該無限接近于原輸入圖像xi,因此仍然采用像素級的L1損失對其進行訓練,損失函數為:
(2)
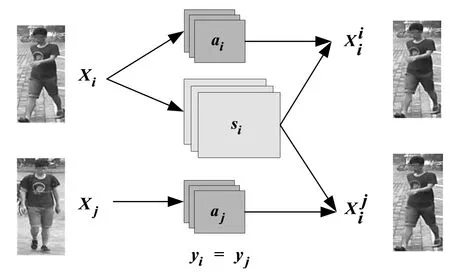
圖2 自生成網絡
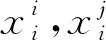
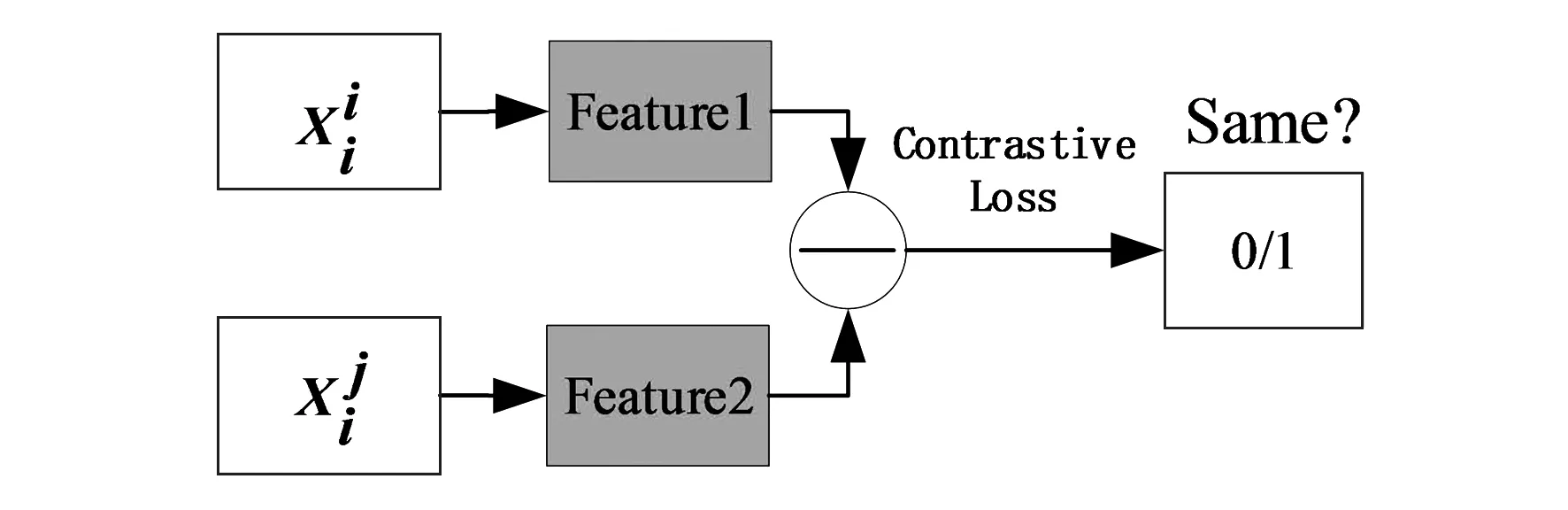
圖3 驗證網絡
d=‖f1-f2‖2
.
(3)
采用對比損失[15]優化網絡具體公式如下:
(4)
式中,d表示兩個樣本特征的二范數,y為兩個樣本是否匹配的標簽,y=1表示匹配,m為設定的閾值,N為樣本的個數。
2.1.2 互生成網絡
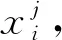
(5)
.
(6)
利用混合編碼對原始數據進行圖像生成,使得生成的圖像更加逼真,一方面,有效擴充了數據集。另一方面,有效減緩了類內差異的影響。采用多損失優化網絡進一步提高了圖像的真實性,有效解決了行人不夠真實、圖像模糊、背景不真實等問題。
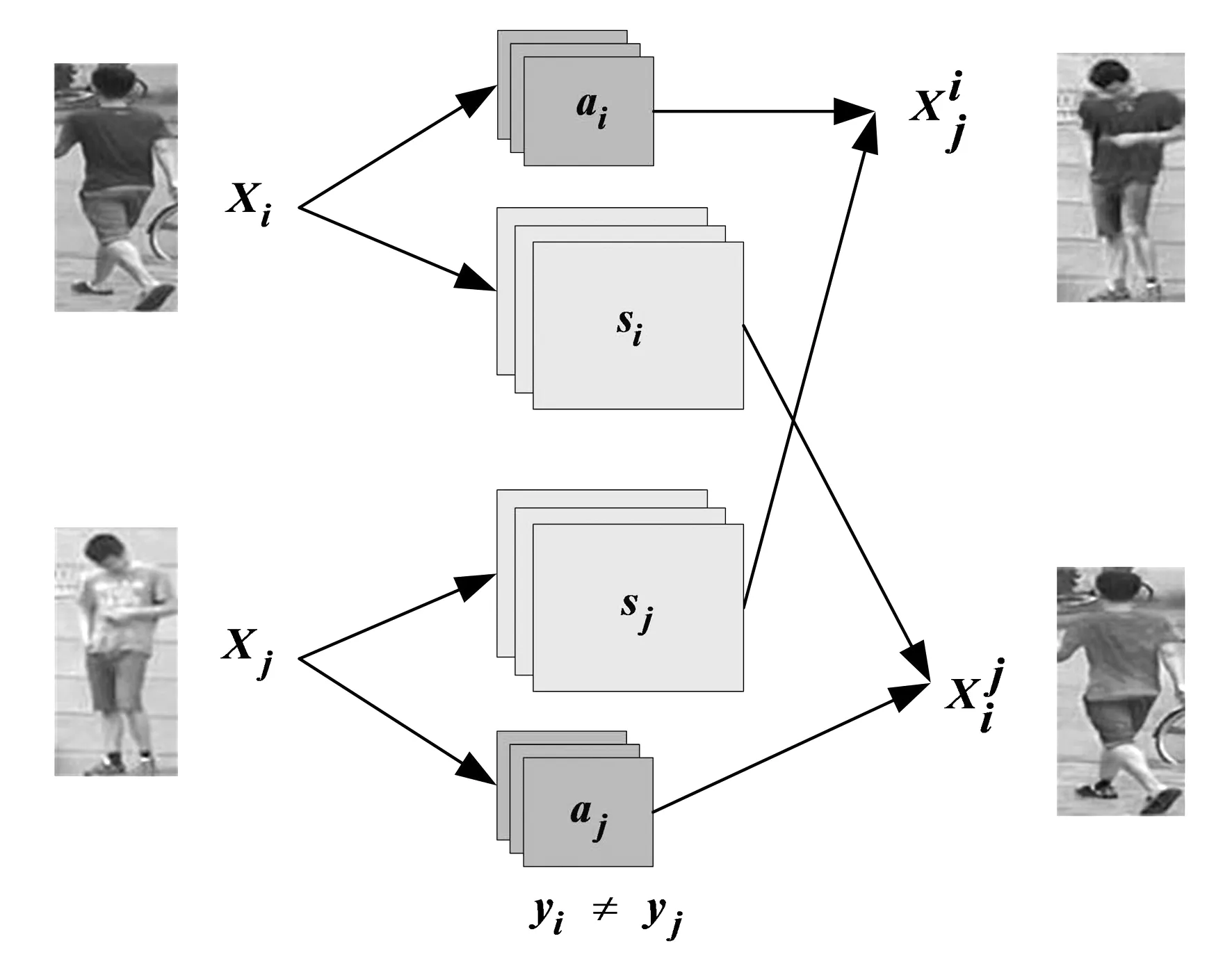
圖4 互生成網絡框架
2.1.3 基于外觀特征的ID分配
網絡提取了人物圖像的姿態特征以及外觀特征,由于行人圖像在不同攝像機的視角下姿態是各異的,所以姿態特征并不具備區分不同行人的特性。在跨攝像機視角中,外觀特征的不變性可以作為區分不同屬性的行人。考慮到這個問題,首先訓練一個基于外觀特征對行人圖像進行身份鑒別的網絡模型,提取原始數據集中所有圖像的外觀特征,保留其標簽屬性,采用交叉熵損失對網絡進行訓練,損失函數如下:
(7)
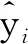
式(7)為單個樣本的損失,總樣本的損失可以表示為:
(8)
(9)
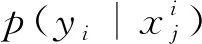
2.2 判別網絡
生成器G和判別器D在極小極大博弈中扮演了兩個競爭對手的角色,D作為一個判別網絡(如圖5所示)將原數據集圖像與生成圖像共同輸入到判別網絡,提取特征利用交叉熵損失優化判別網絡。
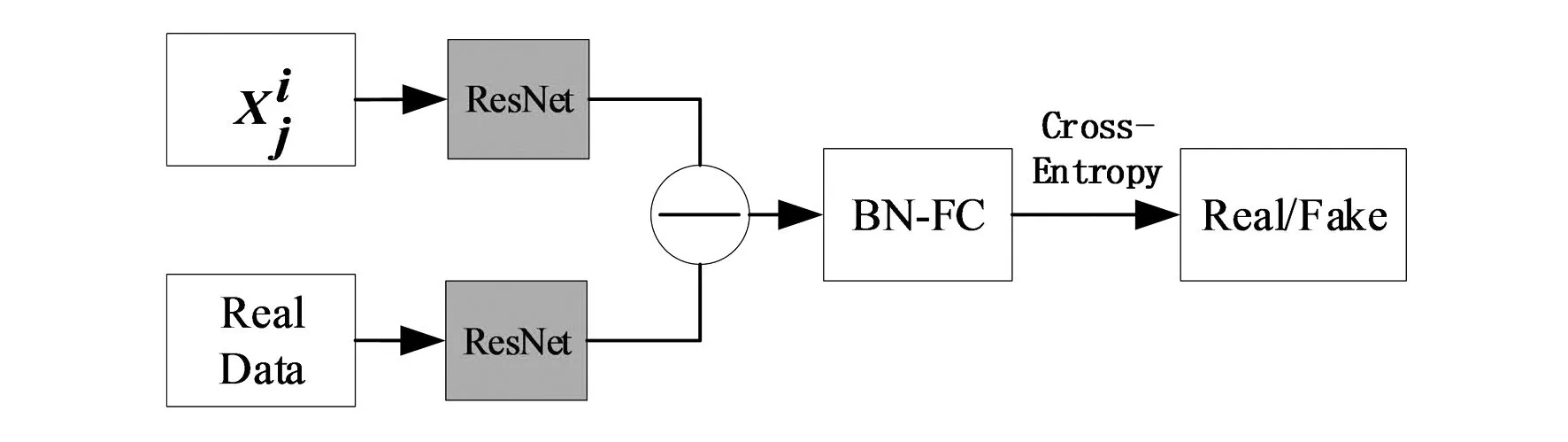
圖5 判別網絡模型
網絡優化的目的是讓D(xi)無限接近于1,D(O(ai,sj))盡可能大,使用對抗性損失[16]來匹配生成圖像的分布與真實數據的分布如下:
L3=E[logD(xi)+log(1-D(O(ai,sj)))],
(10)
式中,D(xi)表示判斷真實圖片是否真實的概率。
對于相同的框架特征,將使用不同的外觀特征進行圖像合成的圖像屬性視為與提供框架特征的行人具有相同的身份屬性。也就是說,可以看到同一位行人穿著不同的衣服,這迫使網絡模型學習與衣服等特征無關的特征表示,從而迫使網絡模型挖掘出更多的判別特征(圖,背包等),進一步挖掘圖像中的細粒度信息,并增強網絡模型的魯棒性。損失函數可表示為:
(11)
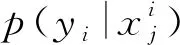
2.3 目標函數
在訓練階段,網絡優化了外觀損失姿態損失、驗證損失、以及判別損失作為優化的總目標,如式(12):
(12)
2.4 網絡設置
基于PyTorch深度框架搭建網絡模型,在訓練階段,采用ResNet50作為基準網絡提取外貌特征,訓練的基線網絡僅僅依據外貌特征對圖像進行分類。采用殘差塊與卷積層組合的輕量級網絡[17]提取姿態特征。驗證網絡采用了DenseNet121[18]提取生成圖像的外貌特征。生成網絡[19]是由殘差塊經過下采樣輸入到卷積單元組成的,判別網絡[20]是由6個卷積層和一個殘差塊組成。所有圖像的寬高比為128×384,參數m設置為1,并且通過SGD方法優化和迭代網絡。初始學習率設置為0.001。
3 實驗數據庫
3.1 數據集
本文提出的行人再識別算法在公開的數據集Market1501[21]、DukeMTMC-reID[22]上進行實驗并取得不錯的效果。本文使用累積匹配特征曲線(CMC)和平均精度均值(mAP)兩個指標來衡量模型的性能。表1列出了數據集的詳細信息。
Market1501是一個大型的行人數據集,采集了6個攝像機的數據,包含751個行人的12 936張訓練圖像, 750個行人的19 732張測試圖像,邊界框直接由可變形零件模型(DPM)[23]檢測,這更接近于真實的場景,采用訓練集中的12 936張圖像訓練網絡,在single-shot模式下進行。
DukeMTMC-reID是由8個攝像機采集的1 812個行人圖像,在數據集中有1 404個行人出現在兩個攝像機以上的視角中,隨機選擇702個行人的圖像作為訓練集,剩余702個行人圖像作為測試集。

表1 數據集詳細信息
3.2 生成圖像示例

圖6 生成圖像示例
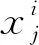
3.3 實驗結果
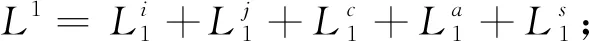
本文對提出的利用姿態特征以及外貌特征混合編碼的行人再識別算法與現有的行人再識別算法進行了比較,如表3所示。表3中分割線以上為未采用生成圖像擴充數據的算法,分割線以下為采用生成圖像輔助訓練的算法。由表中的實驗數據可以看出,采用姿態特征和外貌特征混合編碼的行人再識別算法后,在Market1501數據集上的表現效果較好,Rank-1僅比PCB算法稍低0.4%,但mAP的性能卻高于PCB算法0.6%;在DukeMTMC-ReID數據集上的Rank-1僅僅低于Part-aligned、Mancs算法不到一個百分點,而mAP的性能僅低于Mancs算法。綜上所述,本文提出的算法在兩大公開的數據集上表現效果較好,Rank-1、mAP評估指標能優于現有的大部分主流算法,可以看出所提算法的優越性。
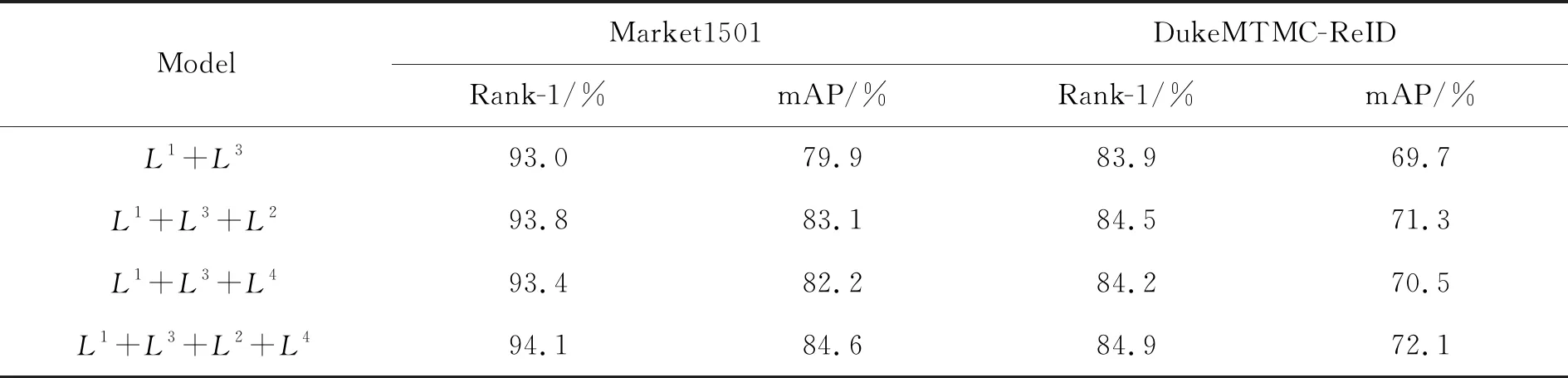
表2 不同損失函數對模型的影響
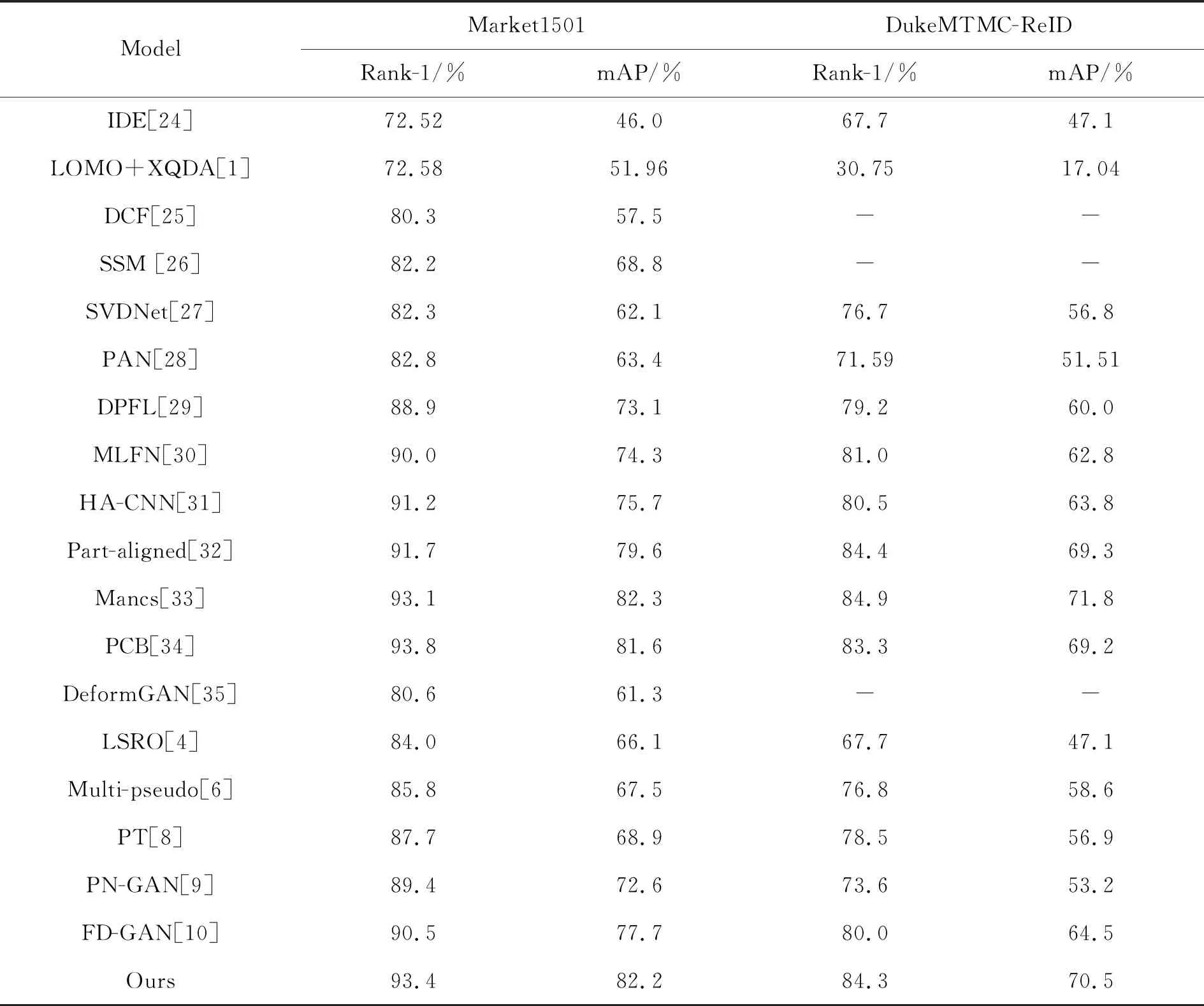
表3 本文算法與現有算法進行比較
4 結 論
本文提出一種利用姿態以及外觀特征混合編碼生成圖像的行人再識別算法。采用多損失監督的方式修正生成圖像,使得生成模塊與判別模塊是一個在線的交互循環,使得兩者相互受益。生成模型通過切換外觀特征以及結構特征,結合兩幅圖像中的特征混合編碼生成高質量圖像,判別模型將生成圖像的外觀特征反饋給生成模型的外觀編碼器,通過聯合優化,進一步提高生成圖片的質量。一方面,解決了數據集不足的問題,另一方面,進一步解決了行人圖像不真實、模糊、背景不真實等問題。這種利用擴充數據集訓練網絡的方式,使得網絡模型更加魯棒。兩個數據集的實驗結果顯示,算法的Rank-1指標相比于FD-GAN方法提升了2.9%、4.3%,相比于mAP提升了4.5%、6%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
