小樣本學習研究綜述*
2021-03-06 09:28:50趙凱琳靳小龍王元卓
軟件學報 2021年2期
趙凱琳 ,靳小龍 ,王元卓
1(中國科學院 計算技術研究所 網絡數據科學與技術重點實驗室,北京 100190)
2(中國科學院大學 計算機與控制學院,北京 100049)
隨著大數據時代的到來,深度學習模型已經在圖像分類、文本分類等任務中取得了先進成果.但深度學習模型的成功,很大程度上依賴于大量訓練數據.而在現實世界的真實場景中,某些類別只有少量數據或少量標注數據,而對無標簽數據進行標注將會消耗大量的時間和人力.與此相反,人類只需要通過少量數據就能做到快速學習.例如,一個五六歲的小孩子從未見過企鵝,但如果給他看過一張企鵝的圖像,當他進入動物園看到真正的企鵝時,就會馬上認出這是自己曾經在圖像上見過的“企鵝”,這就是機器學習和人類學習之間存在的差距.受到人類學習觀點的啟發[1],小樣本學習(few-shot learning)[2,3]的概念被提出,使得機器學習更加靠近人類思維.
早在20 世紀八九十年代,就有一些研究人員注意到了單樣本學習(one-shot learning)的問題.直到2003 年,Li等人[4]才正式提出了單樣本學習的概念.他們認為:當新的類別只有一個或幾個帶標簽的樣本時,已經學習到的舊類別可以幫助預測新類別[5].小樣本學習也叫做少樣本學習(low-shot learning)[6],其目標是從少量樣本中學習到解決問題的方法.與小樣本學習相關的概念還有零樣本學習(zero-shot learning)[7]等.零樣本學習是指在沒有訓練數據的情況下,利用類別的屬性等信息訓練模型,從而識別新類別.
小樣本學習的概念最早從計算機視覺(computer vision)[8]領域興起,近幾年受到廣泛關注,在圖像分類任務中已有很多性能優異的算法模型[9-11].但是在自然語言處理領域(natural language processing)[12]的發展較為緩慢,原因在于圖像和語言特性不同.圖像相比文本更為客觀,所以當樣本數量較少時,圖像的特征提取比文本更加容易[13].不過近年來,小樣本學習在自然語言處理領域也有了一些研究和發展[14-16].根據所采用方法的不同,本文將小樣本學習分為基于模型微調、基于數據增強和基于遷移學習這3 種.基于模型微調的方法首先在含有大量數據的源數據集上訓練一個分類模型,然后在含有少量數據的目標數據集上對模型進行微調.但這種做法可能導致模型過擬合,因為少量數據并不能很好地反映大量數據的真實分布情況.為解決上述過擬合的問題,基于數據增強和基于遷移學習的小樣本學習方法被提出.基于數據增強的方法是利用輔助數據集或者輔助信息增強目標數據集中樣本的特征或擴充對目標數據集,使模型能更好地提取特征.本文根據學習方法的不同,將基于數據增強的小樣本學習方法進一步細分為基于無標簽數據、基于數據合成和基于特征增強這3 類方法.基于遷移學習的方法是目前比較前沿的方法,是指將已經學會的知識遷移到一個新的領域中.本文根據學習框架,將基于遷移學習的方法細分為基于度量學習、基于元學習和基于圖神經網絡(graph neural network)的方法.在度量學習的框架下,目前已有許多性能較好的小樣本學習模型,例如比較著名的原型網絡(prototypical network)[9]和匹配網絡(matching network)[17]等.基于元學習的方法不僅在目標任務上訓練模型,并且從許多不同的任務中學習元知識,當一個新的任務到來時,利用元知識調整模型參數,使模型能夠快速收斂.近年來,隨著圖神經網絡的興起,研究者將圖神經網絡也應用到小樣本學習中,取得了先進的結果.
除了圖像分類和文本分類這兩個主要任務,許多其他任務也面臨著小樣本問題.在計算機視覺應用中,利用小樣本學習進行人臉識別[8,18,19]、食品識別[20]、表情識別[21]、手寫字體識別[22,23]以及其他的圖像識別[24].在自然語言處理應用中,使用小樣本方法實現對話系統[25]、口語理解[26],或者完成NLP 的基本任務,例如word embedding[27].在多媒體領域應用中,可以使用小樣本方法實現影像提取[28]和聲紋識別[29]等.在生物與醫學領域,可以應用于疾病診斷[30,31]、臨床實驗[32,33]、護士能力評價[34]、農作物病害識別[35,36]、水量分析[37]等.在經濟領域,可應用于產品銷量預測[38]等.在工業與軍事領域,可應用于齒輪泵壽命預測[39]、軍事目標識別[40]和目標威脅評估[41]等.
本文首先從基于模型微調、基于數據增強和基于遷移學習這3 種方法介紹小樣本學習的研究進展,總結小樣本學習的幾個著名數據集以及已有模型在這些數據集上的實驗結果;接下來,本文對小樣本學習的研究現狀和主要挑戰進行總結;最后展望了未來的發展趨勢.
1 基于模型微調的小樣本學習
基于模型微調的方法是小樣本學習較為傳統的方法,該方法通常在大規模數據上預訓練模型,在目標小樣本數據集上對神經網絡模型的全連接層或者頂端幾層進行參數微調,得到微調后的模型.若目標數據集和源數據集分布較類似,可采用模型微調的方法.
為了使微調后的小樣本分類模型取得較好的效果,使用何種微調方法需要被考慮.Howard 等人[14]在2018年提出了一個通用微調語言模型(universal language model fine-tuning,簡稱ULMFit).與其他模型不同的是,此方法使用了語言模型而非深度神經網絡.該模型分為3 個階段:(1) 語言模型預訓練;(2) 語言模型微調;(3) 分類器微調.該模型的創新點在于改變學習速率來微調語言模型,主要體現在兩個方面.
1)傳統方法認為,模型每一層學習速率相同;而ULMFit 中,語言模型的每一層學習速率均不相同.模型底層表示普遍特征,這些特征不需要很大調整,所以學習速率較慢;而高層特征更具有獨特性,更能體現出任務和數據的獨有特征,于是高層特征需要用更大的學習速率學習.總體看來,模型底層到最高層學習速率不斷加快.
2)對于模型中的同一層,當迭代次數變化時,自身學習率也會相應地產生變化.作者提出了斜三角學習率的概念,當迭代次數從0 開始增加時,學習速率逐漸變大;當迭代次數增長到某個固定值時,此時已經學習到了足夠知識,固定值之后的學習率又開始逐步下降.
論文從縱向和橫向兩個維度學習速率的變化對語言模型進行微調,讓模型更快地在小樣本數據集上收斂;同時,讓模型學習到的知識更符合目標任務.另外,Nakamura 等人[42]提出了一種微調方法,主要包含以下幾個機制:(1) 在小樣本類別上再訓練的過程使用更低的學習率;(2) 在微調階段使用自適應的梯度優化器;3) 當源數據集和目標數據集之間存在較大差異性時,可以通過調整整個網絡來實現.
基于模型微調的方法較簡單,但是在真實場景中,目標數據集和源數據集往往并不類似,采用模型微調的方法會導致模型在目標數據集上過擬合.為解決模型在目標數據集上過擬合的問題,兩種解決思路被提出:基于數據增強和基于遷移學習的方法.這兩種方法將在接下來的兩個章節中依次介紹.
2 基于數據增強的小樣本學習
小樣本學習的根本問題在于樣本量過少,從而導致樣本多樣性變低.在數據量有限的情況下,可以通過數據增強(data augmentation)[43]來提高樣本多樣性.數據增強指借助輔助數據或輔助信息,對原有的小樣本數據集進行數據擴充或特征增強.數據擴充是向原有數據集添加新的數據,可以是無標簽數據或者合成的帶標簽數據;特征增強是在原樣本的特征空間中添加便于分類的特征,增加特征多樣性.基于上述概念,本文將基于數據增強的方法分為基于無標簽數據、基于數據合成和基于特征增強的方法三種.接下來,就這3 種方法分別介紹小樣本學習的進展.
2.1 基于無標簽數據的方法
基于無標簽數據的方法是指利用無標簽數據對小樣本數據集進行擴充,常見的方法有半監督學習[44,45]和直推式學習[46]等.半監督學習是機器學習領域研究的重點問題[47],將半監督方法應用到小樣本學習現在已經有了許多嘗試.2016 年,Wang 等人[48]在半監督學習的思想下,同時受到CNN 可遷移性的啟發,提出利用一個附加的無監督元訓練階段,讓多個頂層單元接觸真實世界中大量的無標注數據.通過鼓勵這些單元學習無標注數據中低密度分離器的diverse sets,捕獲一個更通用的、更豐富的對視覺世界的描述,將這些單元從與特定的類別集的聯系中解耦出來(也就是不僅僅能表示特定的數據集).作者提出了一個無監督的margin最大化函數來聯合估計高密度區域的影響并推測低密度分離器.低密度分離器(LDS)模塊可以插入任何標準的CNN 架構的頂層.除此之外,Boney 等人[49]在2018 年提出使用MAML[11]模型來進行半監督學習,利用無標簽數據調整嵌入函數的參數,用帶標簽數據調整分類器的參數.MAML 算法本文將在第3.2 節詳細介紹.2018 年,Ren 等人[50]在原型網絡[9]的基礎上進行改進,加入了無標注數據,取得了更高的準確率.此模型本文將在第3.1 節進行詳細介紹.
直推式學習可看作半監督學習的子問題.直推式學習假設未標注數據是測試數據,目的是在這些未標記數據上取得最佳泛化能力.Liu 等人[51]使用了直推式學習的方法,在2019 年提出了轉導傳播網絡(transductive propagation network)來解決小樣本問題.轉導傳播網絡分為4 個階段:特征嵌入、圖構建、標簽傳播和損失計算.該模型在特征嵌入階段,將所有的標注數據和無標注數據通過嵌入函數f映射到向量空間中;在圖構建階段,使用構建函數g將嵌入向量構建為無向圖中的節點,連邊權重由兩個節點計算高斯相似度得到;隨后,根據公式F*=(I-αS)(-1)Y來進行標簽傳播(其中,F*是標簽預測結果,S是歸一化之后的連邊權重,Y是初始標簽的矩陣),讓標簽從標注數據傳播到無標注數據;最后,通過交叉熵函數計算損失,用反向傳播更新嵌入函數和構建函數的參數.另外,Hou 等人[52]也提出了一個交叉注意力網絡(cross attention network),基于直推式學習的思想,利用注意力機制為每對類特征和查詢生成交叉注意映射對特征進行采樣,突出目標對象區域,使提取的特征更具鑒別性.其次,提出了一種轉換推理算法,為了緩解數據量過少的問題,迭代地利用未標記的查詢集以增加支持集,從而使類別特性更具代表性.
2.2 基于數據合成的方法
基于數據合成的方法是指為小樣本類別合成新的帶標簽數據來擴充訓練數據,常用的算法有生成對抗網絡(generative adversarial net)[53]等.Mehrotra 等人[54]將GAN 應用到小樣本學習中,提出了生成對抗殘差成對網絡(generative adversarial residual pairwise network)來解決單樣本學習問題.算法使用基于GAN 的生成器網絡對不可見的數據分布提供有效的正則表示,用殘差成對網絡作為判別器來度量成對樣本的相似性,如圖1 的流程圖所示.
· 輸入樣本為xt,為了防止生成器簡單復制原樣本,首先對xt進行破壞得到損壞樣本tx~,將x~t輸入到生成器G中得到生成樣本x,x的另一個來源是真實的數據集.
· 其次,xt空間變換后輸入到判別器D中,同時輸入的還有樣本x.
· 隨后,判別器會給出3 種判別結果:(1)x是真實樣本,并且x與xt不同;(2)x是真實樣本,并且x與xt相似;(3)x是假樣本.
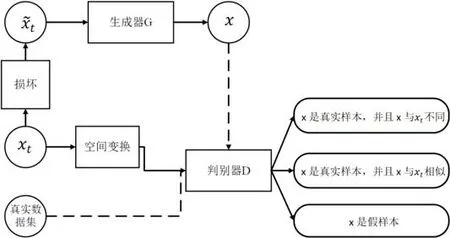
Fig.1 An indicative figure of generative adversarial residual pairwise network[54]圖1 生成對抗殘差成對網絡示意圖[54]
除了基于GAN 的數據合成方法,Hariharan 等人[55]提出了一種新的方法,該方法分為兩個階段:表示學習階段和小樣本學習階段.
· 表示學習階段是指在含有大量數據的源數據集上學習一個通用的表示模型,在此階段中,作者提出一個新的損失函數——平方梯度量級損失來提升表示學習的效果.
· 小樣本學習階段是指在少量數據的新類別中微調模型,在此階段中,本文提出了生成新數據的方法來為小樣本類別進行數據增強.
作者認為,屬于同一類別的兩個樣本之間存在著一個轉換.那么給定新類別的一個樣本x,通過這個轉換,生成器G可以生成屬于該類別的新樣本.
Wang 等人[56]將元學習與數據生成相結合,提出了通過數據生成模型生成虛擬數據來擴充樣本的多樣性,并結合當前比較先進的元學習方法,通過端到端方法共同訓練生成模型和分類算法.通過讓現有圖像的一些屬性和特征發生變化,如拍照姿態改變、光照改變、位置遷移等,遷移到新的樣本上,從而生成具有不同變化的新樣本圖像,實現數據的擴充.此外,本模型可以套用任何元學習模型,具有靈活性.
但是現有的數據生成方法具有以下缺點:(1) 沒有捕捉到復雜的數據分布;(2) 不能泛化到小樣本的類別;(3) 生成的特征不具有可解釋性.Xian 等人[57]為解決上述問題,將變分編碼器(VAE)和GAN 進行結合,充分利用了兩者的優勢集成了一個新的網絡f-VAEGAN-D2.這個網絡再完成小樣本學習圖像分類的同時,能夠將生成樣本的特征空間通過自然語言的形式表現出來,具有可解釋性.Chen 等人[58]對此繼續研究,提出可以利用元學習對訓練集的圖像對支持集進行插值,形成擴充的支持集集合:首先,從元訓練集的集合中每一類隨機選擇幾個樣本,形成集合G;其次,針對某個任務提取支持集的特征,形成最近鄰分類器,對集合G中的所有圖像分類,找到概率最高的N個圖像;將對應的圖像加權得到擴充的圖像,圖像標簽與原圖像保持一致;最后,用擴充的支持集與查詢樣本計算分類損失,用來優化權重生成子網絡.
2.3 基于特征增強的方法
以上兩種方法都是利用輔助數據來增強樣本空間,除此之外,還可通過增強樣本特征空間來提高樣本的多樣性,因為小樣本學習的一個關鍵是如何得到一個泛化性好的特征提取器.Dixit 等人[59]提出了AGA(attributedguided augmentation)模型學習合成數據的映射,使樣本的屬性處于期望的值或強度.然而,將基于合成數據的網絡應用到真實圖像中具有遷移學習的問題,但之前的方法都不適用于具有姿態物體的遷移,AGA 是一個解決方法,但是它的軌跡是離散的,不能連續.所以基于此,Liu 等人[60]提出了特征遷移網絡(FATTEN),用于描述物體姿態變化引起的運動軌跡變化.與其他特征提取不同的是,該方法對物品的外觀和姿態分別有一個預測器.網絡包括一個編碼器和一個解碼器,編碼器將CNN 對目標圖像的特征x映射為一對外觀A(x)和姿態P(x)參數,然后,解碼器需要這些參數產生相應的特征向量x.
此外,Schwartz 等人[61]提出了Delta 編碼器,通過看到少量樣本來為不可見的類別合成新樣本,將合成樣本用于訓練分類器.該模型既能提取同類訓練樣本之間可轉移的類內變形,也能將這些增量應用到新類別的小樣本中,以便有效地合成新類樣本.但此方法的特征增強過于簡單,無法顯著改善分類邊界[1].為解決這個問題,Chen 等人[62]提出了一個雙向網絡TriNet,他們認為,圖像的每個類別在語義空間中具有更豐富的特征,所以通過標簽語義空間和圖像特征空間的相互映射,可以對圖像的特征進行增強.該模型用一個4 層卷積神經網絡ResNet-18 提取圖像的視覺特征,再通過TriNet 的編碼器將視覺特征映射到語義空間,在語義空間中進行數據增強;之后,通過TriNet 的解碼器將增強后的語義特征映射回圖像的特征空間.例如,shark 這個類別在語義空間中與已知的一些類別fish,whale_shark 和halobios 距離較近,即代表它們的語義相似,TriNet 可借用這些鄰近類別的特征來調整網絡中用于特征提取的參數,幫助模型更好地提取圖像特征.
但是在上面的方法中,分類網絡通常提取的特征只關注最具有判別性的區域,而忽略了其他判別性較弱的區域,不利于網絡的泛化.為了解決這個問題,Shen 等人[63]提出可以把固定的注意力機制換成不確定的注意力機制M.輸入的圖像經提取特征后進行平均池化,分類得到交叉熵損失l.用l對M求梯度,得到使l最大的更新方向從而更新M.其次,將提取的特征與更新后的M相乘,得到對抗特征,得到分類損失l1;將初始特征再經過多個卷積,得到一維特征對其分類,得到分類損失l2.這兩個分類器共享參數,從而使得高層特征對底層特征具有一定的指導作用,從而優化網絡.
通過梳理基于數據增強的小樣本學習模型的研究進展,可以思考未來的兩個改進方向.
1)更好地利用無標注數據.由于真實世界中存在著大量的無標注數據,不利用這些數據會損失很多信息,更好、更合理地使用無標注數據,是一個非常重要的改進方向.
2)更好地利用輔助特征.小樣本學習中,由于樣本量過少導致特征多樣性降低.為提高特征多樣性,可利用輔助數據集或者輔助屬性進行特征增強,從而幫助模型更好地提取特征來提升分類的準確率.
3 基于遷移學習的小樣本學習
遷移學習是指利用舊知識來學習新知識,主要目標是將已經學會的知識很快地遷移到一個新的領域中[64].舉例說明:一個程序員在掌握了C 語言的前提下,能夠更快地理解和學習Python 語言.遷移學習主要解決的一個問題是小樣本問題.基于模型微調的方法在源數據集和目標數據集分布大致相同時有效,分布不相似時會導致過擬合問題.遷移學習則解決了這個問題.遷移學習只需要源領域和目標領域存在一定關聯,使得在源領域和數據中學習到的知識和特征能夠幫助在目標領域訓練分類模型,從而實現知識在不同領域之間的遷移.一般來說,源領域和目標領域之間的關聯性越強,那么遷移學習的效果就會越好[65].近年來,遷移學習這個新興的學習框架受到了越來越多研究人員的關注,很多性能優異的小樣本算法模型被提出.在遷移學習中,數據集被劃分為3 部分:訓練集(training set)、支持集(support set)和查詢集(query set).其中,訓練集是指源數據集,一般包含大量的標注數據;支持集是指目標領域中的訓練樣本,包含少量標注數據;查詢集是目標領域中的測試樣本.
隨著深度學習的發展,深度神經網絡常被用來學習樣本的嵌入函數,如卷積神經網絡(convolutional neural network)[66]、循環神經網絡(recurrent neural network)[67]和長短期記憶網絡(long short-term memory)等.在圖像分類任務中,常使用卷積神經網絡作為嵌入網絡,比較常用的變型包括VGG,Inception,Resnet 等.Wang 等人[68]基于遷移學習的思想,在2016 年提出了回歸網絡(regression network)來解決小樣本問題.他們認為:一個由少量樣本訓練的模型和一個由大量樣本訓練的模型之間存在一個通用的忽略類別的轉換T,這個轉換T由回歸網絡學習得到.通過T的轉換,可以把由小樣本訓練得到的效果不佳的模型,映射為由大量樣本訓練得到的效果較好的模型.兩個模型的轉換實質上是模型參數的映射,即,將一個模型的權重映射到另一個模型.
近年來,隨著遷移學習的興起,與之相關的模型也不斷涌現.但是在以前的遷移學習算法中,源網絡中的某一層遷移到目標網絡中的某一層是人工給定的,并且是將所有的特征映射都遷移,沒有考慮遷移到哪里和遷移多少的問題.Jang 等人[69]專注于遷移學習中遷移什么(what)和遷移到哪里(where)的問題,提出利用元學習來學習遷移特征映射的權重和遷移層的權重來解決這個問題,同時提出了一步學習的策略,只用一步來適應目標數據集.該方法同時在小樣本數據集上進行了實驗,但是效果提升沒有大規模數據集多.根據遷移學習的方法不同,本文將其分為基于度量學習、基于元學習和基于圖神經網絡的方法這3 類.接下來就這3 類方法中典型的算法模型及研究進展進行介紹.
3.1 基于度量學習的方法
在數學概念中,度量指衡量兩個元素之間距離的函數,也叫做距離函數[70].度量學習也稱為相似度學習,是指通過給定的距離函數計算兩個樣本之間的距離,從而度量它們的相似度[71].在深度學習中,我們通常采用歐氏距離、馬氏距離和余弦相似度等[72,73]作為距離函數.將度量學習的框架應用到小樣本學習上,顧名思義,就是通過計算待分類樣本和已知分類樣本之間的距離,找到鄰近類別來確定待分類樣本的分類結果.基于度量學習方法的通用流程如圖2 所示,該框架具有兩個模塊:嵌入模塊和度量模塊,將樣本通過嵌入模塊嵌入向量空間,再根據度量模塊給出相似度得分.基于度量學習的方法通常采用episodic training,是指將數據集分為多個任務進行訓練,每個任務從訓練集中隨機采樣C-wayK-shot 的樣本,即選出C個類別,每個類別含有K個樣本,通過多次采樣構建多個任務.當進行訓練時,將多個任務依次輸入到模型中,這就是episodic training.在測試時,一般從剩余的樣本中選取一個batch 來進行測試.
Koch 等人[74]在2015 年最先提出使用孿生神經網絡(siamese neural network)進行單樣本圖像識別.孿生神經網絡是一種相似性度量模型,當類別數多但每個類別的樣本數量少的情況下,可用于類別的識別.孿生神經網絡從數據中學習度量,進而利用學習到的度量比較和匹配未知類別的樣本,兩個孿生神經網絡共享一套參數和權重.其主要思想是:通過嵌入函數將輸入映射到目標空間,使用簡單的距離函數進行相似度計算.孿生神經網絡在訓練階段最小化一對相同類別樣本的損失,最大化一對不同類別樣本的損失.該模型使用兩個CNN 提取輸入圖像的特征,將圖像映射成向量.輸入是一對樣本而不是單個樣本,同一類樣本標簽為1,不同類為0;然后,通過交叉熵函數計算損失.對于單樣本學習,訓練集中每個類別只有一個樣本,所以測試集中的每張圖像和訓練集中的每個樣本都組成一個樣本對,依次輸入到孿生神經網絡中,得到每對樣本的距離.選取距離最小的訓練樣本的標簽作為測試樣本的類別,從而完成分類.
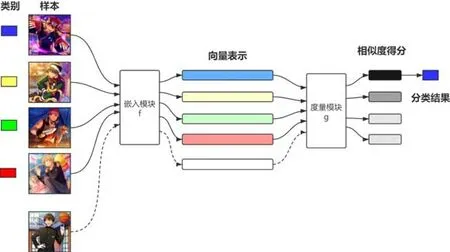
Fig.2 Generalized flow chart of the metric learning based models[17]圖2 基于度量學習的模型通用流程圖[17]
Vinyals 等人[17]繼續就單樣本學習問題進行深入探討,在2016 年提出了匹配網絡(matching network),該網絡可將帶標簽的小樣本數據和不帶標簽的樣本映射到對應的標簽上.針對單樣本學習問題,該模型使用LSTM將樣本映射到低維向量空間中,新樣本與每個帶標簽樣本計算相似度,使用核密度估計函數(kernel density estimation)輸出預測標簽.核密度估計函數專注于從數據樣本本身出發來研究數據的分布特征,是在概率論中用來估計未知的密度函數,屬于非參數檢驗方法.該模型在兩個方面進行了創新.
· 一是在模型層面提出了匹配網絡的概念.匹配網絡使用公式計算目標樣本與已知標簽樣本之間的相似度,其中,支持集是待分類樣本,y? 是待分類樣本的預測標簽.在此公式中,a可以看作注意力機制,yi看作約束于xi的記憶單元,即匹配網絡在計算中引入了外部記憶和注意力機制.
· 二是訓練過程中保持訓練集和測試集的匹配.這與機器學習中獨立同分布的概念相似,在保證訓練集和測試集獨立同分布的條件下,訓練模型在測試集上也能取得較好的效果.
Jiang 等人[75]基于匹配網絡的思想,將嵌入函數改進為4 層的卷積神經網絡,分別采用雙向LSTM 和基于注意力機制的LSTM 算法深入提取訓練樣本和測試樣本中更加關鍵和有用的特征并進行編碼;最后,在平方歐氏距離上利用softmax非線性分類器對測試樣本分類.實驗結果表明,改進的匹配網絡在類別數更多而樣本數較少的復雜場景下具有更好的分類效果.
在基于度量學習的單樣本圖像分類方面,上述方法都是從圖像本身特征出發,沒有考慮到分類標簽這一信息.Wang 等人[76]認為需要將圖像的分類標簽納入考慮,并提出了多注意力網絡模型(multi-attention network).該模型使用GloVe Embedding 將圖像的標簽嵌入到向量空間,通過構建標簽語義特征和圖像特征之間的注意力機制,得到一張圖像屬于該標簽的特征主要集中于哪一個部分(單注意力)或哪幾個部分(多注意力),利用注意力機制更新該圖像的向量,最后通過距離函數計算相似度得到分類結果.
盡管上述模型已經取得了較好的成果,但它們針對的都是單樣本學習問題.為了進一步深入解決小樣本問題,Snell 等人[9]在2017 年提出了原型網絡(prototypical network).作者認為,每個類別在向量空間中都存在一個原型(prototype),也稱作類別中心點.原型網絡使用深度神經網絡將圖像映射成向量,對于同屬一個類別的樣本,求得這一類樣本向量的平均值作為該類別的原型.通過不斷訓練模型和最小化損失函數,使得同一類別內的樣本距離更為靠近,不同類別的樣本更為遠離,從而更新嵌入函數的參數.原型網絡的思路如圖3 所示,輸入樣本x,比較x的向量和每個類別原型的歐式距離.根據計算發現,x與原型2 的距離更近,也就代表x與原型2 所代表的類別更為相似,于是將x分到類別2.
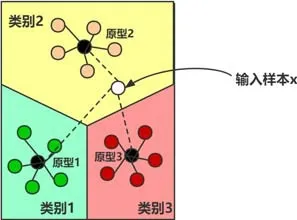
Fig.3 A case study of prototypical networks[9]圖3 原型網絡樣例[9]
原型網絡的思想和實現方法都十分簡單明晰,但效果與之前的工作相比得到了一定的提升.但是僅僅使用標注數據得到的結果不一定是準確的,因為樣本量太少會導致分類邊界偏差.針對這個不足之處,Ren 等人[50]于2018 年在原型網絡的基礎上進行擴展,使用了半監督學習的思想,在訓練集中加入了不帶標簽的數據來改善分類邊界.實驗證明:無標簽數據的加入,提高了分類效果.原因在于:原型網絡只使用帶標簽數據進行原型的計算,但是帶標簽數據數量較少導致了類別中心的計算不準確;而改進的網絡加入了無標簽數據之后,對類別的原型進行了修正,使得待分類樣本能夠得到正確的分類.論文中對這種使用半監督方法的原型網絡提出了3 種變型.
· 第1 種,所有的無標簽數據都屬于帶標簽的數據所屬的類別.在這種假設下,將無標簽數據和帶標簽數據一起計算新的原型.
· 第2 種,無標簽數據要么屬于帶標簽數據所屬的類別,要么屬于一個另外的類——干擾類(distractor class).干擾類開始以原點(0,0)作為原型,模型學習的是干擾類的半徑.
· 第3 種,無標簽數據要么屬于已知的類別,要么被掩蓋(masked).這種變型的提出,是因為第2 種假設的不合理性.第2 種假設下,把所有沒有標簽的數據分到同一個類顯然是不符合實際場景的,所以作者又提出了一種新的算法:maskedK-means 算法.在這種假設下,論文用一個多層感知機(multi-layer perception,簡稱MLP)來學習每個類的半徑和斜率,用這兩個參數和距離得到一個沒有標簽的數據屬于每個類別的概率.
作者認為:一個樣本離原型越遠,它就越容易被掩蓋.但是上面的網絡在計算時均沒有考慮樣本的權重,只是做了一個簡單的平均數計算.在很多情況下,用來計算原型的樣本的重要程度是不同的,尤其當樣本是噪聲數據的時候,體現的更為明顯.受到這個問題的驅動,Gao 等人[77]提出了基于人工注意力的原型網絡.相比于傳統的原型網絡,該模型多了兩個部件:樣本級別的注意力機制和特征級別的注意力機制,來分別捕捉對分類更重要的樣本和特征.作者分別用含有0%,10%,30%和50%的噪聲數據集進行了效果評測,均比baseline 取得了更好的效果;并且噪聲越多,提升效果越好.說明該模型具有很好的魯棒性.Sun 等人[78]也為解決這個問題提出了層次注意力原型網絡(HAPN),比起傳統的原型網絡添加了特征級別、詞語級別和樣本級別的3 種注意力機制.詞語級別的注意力機制是文本分類中常用的方法,在這里不再贅述.基于人工注意力的原型網絡和層次注意力原型網絡均添加了樣本級別和特征級別的注意力機制,表明不同的樣本和特征對于分類任務的重要性確實不同,只做簡單的平均計算是遠遠不夠的,需要對樣本的特征進行加權處理.
上述模型都是基于距離函數來計算相似度,這樣雖然簡單易操作,但有時候距離函數卻并不適用于一些特定的任務.針對這個問題,一些研究人員提出可以使用深度神經網絡來進行度量[1].Sung 等人[79]在2018 年提出了一個新的模型——關系網絡(relation network,簡稱RN),該模型分為兩個模塊:嵌入模塊和關系模塊.其中,嵌入模塊f是一個4 層的卷積神經網絡,用來學習樣本到低維向量空間的嵌入;關系模塊g是一個相似度比較模塊,使用ReLU 來進行相似度計算,用來輸出兩個樣本的相似度得分.關系網絡在3 種問題上作了討論.
1)單樣本學習.每種類別有一個支持樣本x,嵌入向量為f(x),針對查詢樣本y獲得嵌入向量f(y),C(f(x),f(y))表示兩個向量的連接,將這個連接后的向量放到關系模塊g中,得到相似度打分,完成分類.
2)小樣本學習.對于每一類的支持樣本,將它們的嵌入向量相加作為整個類別的特征映射.剩下的過程和單樣本學習相同.
3)零樣本學習.對于沒有標注樣本的問題,利用每個類別的語義特征嵌入向量v,使用新的嵌入函數f2,得到這個類別的特征映射f2(v),剩下過程與上面相同.
在關系網絡的基礎上,Zhang 等人[10]提出了深度比較網絡(deep comparison network,簡稱DCN),將嵌入學習分解為一系列模塊,并將每個模塊與一個關系模塊配對.關系模塊利用相應嵌入模塊的表示計算一個非線性度量對匹配進行打分.為了保證所有嵌入模塊的特征都被使用,關系模塊被深度監控.最后,通過學習噪聲調節器進一步提高泛化性.Hilliard 等人[80]也使用了一種新的體系結構,拋棄了傳統的度量學習方法,通過訓練一個網絡來執行類別之間的比較,而不是依賴于靜態度量比較.該網絡可以決定一個類的哪些方面對于分類比較重要,從而更好地區分類別邊界.
之前的方法注意力集中在一階統計量的概念表示上,Li 等人[81]提出了一個協方差度量網絡(CovaMNet),在基于小樣本分類任務的分布一致性上,利用了協方差表示和協方差矩陣,其中,協方差表示用來捕獲二階統計信息,協方差矩陣用來衡量query 樣本與新類別之間的分布一致性.但由于現有的方法忽略了局部特征的信息,為了捕捉局部特征,Li 等人[82]又提出了深度最近鄰神經網絡(DN4).與其他方法的最大不同是:在最后一層用圖像到類別的局部描述符來代替圖像級別的特征測量,查詢樣本在進行特征映射時,為每個空間特征計算一個相似性.針對一個查詢樣本特征映射的每個空間特征,找到支持特征映射中最相近的K個特征來計算相似性,最后將所有位置相似性加和,得到此查詢樣本的相似性.
但是上面的方法是針對每個任務提取不同的特征,仍舊忽略了支持集中所有圖像之間的語義關系.受到這個想法的驅動,Li 等人[83]提出可以利用模型整合支持集中所有圖像的信息,從而找到最具有判別性的特征.
· 首先,根據支持集得到一個channel attention;隨后,對所有的圖像應用channel attention,對于支持集中的圖像提取特征,經過一個卷積層求得原型;將所有類連接,得到一個特征;再經過卷積,得到一個channel attention.
· 其次,將支持集特征和查詢樣本特征經過一個卷積層,與上述得到的attention 相乘,得到更具有判別性的特征.
· 最后,對于更新后的特征做度量學習.
由上面的模型可以看出:基于度量學習的方法經歷了從解決單樣本問題到解決小樣本問題再到同時解決小樣本問題和零樣本問題的變革,模型逐漸趨近于成熟;同時,也經歷了從基于傳統距離函數的方法到基于深度網絡的方法的改進.繼續采用基于傳統距離函數的方法很難在小樣本分類準確率方面得到較大的提升,所以加強對基于神經網絡進行度量方法的研究,將是今后重點關注的方向.
3.2 基于元學習的方法
元學習(meta-learning)也叫做學會學習(learning to learn)[84],是機器學習領域一個前沿的研究框架,針對于解決模型如何學習的問題.元學習的目的是讓模型獲得一種學習能力,這種學習能力可以讓模型自動學習到一些元知識.元知識指在模型訓練過程之外可以學習到的知識,比如模型的超參數、神經網絡的初始參數、神經網絡的結構和優化器等[85].在小樣本學習中,元學習具體指從大量的先驗任務中學習到元知識,利用以往的先驗知識來指導模型在新任務(即小樣本任務)中更快地學習.元學習中的數據集通常分為元訓練集和元測試集,二者均包含了原始模型所需要的訓練集和測試集.如圖4 所示,分類模型的數據集包括訓練集和測試集;元學習模型的數據集包括元訓練集和元測試集,其中,元訓練集和元測試集均包含訓練集和測試集.
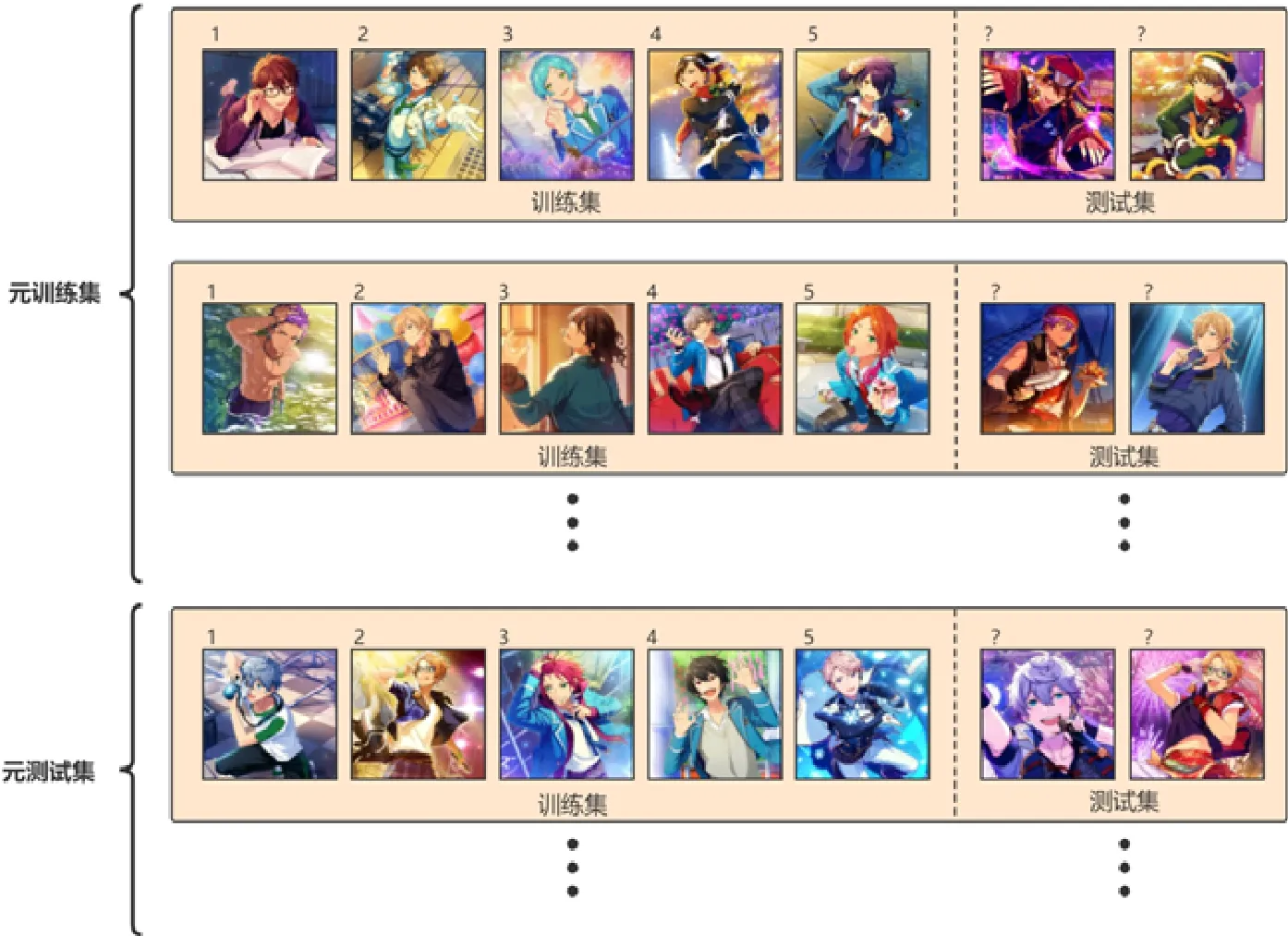
Fig.4 Example of meta-learning dataset[86]圖4 元學習數據集實例[86]
早在2001 年,Hochreiter 等人[87]就證明了記憶神經網絡可適用于元學習.在此工作的基礎上,Santoro 等人[88]在2016 年提出了基于記憶增強的神經網絡(memory-augmented neural networks,簡稱MANN)來解決單樣本學習問題.作者使用了神經圖靈機(neural Turing machine,簡稱NTM)[89]作為MANN 的基本模型,因為NTM 作為一種可微的MANN,可以直接通過梯度下降進行訓練.神經圖靈機既可以通過緩慢權重更新來實現長期存儲,又能夠通過記憶庫實現短期存儲,這與元學習的思想完全一致.作者致力于讓神經圖靈機學習到一種策略,這個策略可以指導NTM 將樣本類型放入到記憶庫中,同時指導它今后如何通過這些類型進行預測或者分類.
MANN 是元學習方法在單樣本學習問題上較早且較成功的一次嘗試,此后,應用元學習框架解決小樣本問題逐漸進入人們的視野.在2017 年,Munkhdalai 等人[90]繼續采用元學習的框架來解決單樣本分類的問題,并提出了一個新的模型——元網絡(meta network).元網絡主要分為兩個部分:base-learner 和meta-learner,還有一個額外的記憶塊,這個記憶塊可以幫助模型快速學習.
Base-learner 在任務空間中學習,meta-learner 在抽象的元空間中持續學習并且從不同的任務中獲取元知識.當新任務到來時,base-learner 對當前任務進行分析,并將元信息反饋給meta-learner;Meta-learner 收到元信息之后,根據元信息對自身和base-learner 快速參數化.具體來說,元網絡分為一個緩慢權重化的過程和一個快速權重化的過程,在學習不同任務之間的泛化信息時權重更新緩慢,而當對一個新任務快速適應時,則需要快速權重化.
雖然上面兩個工作已經將元學習的框架帶進了小樣本學習中,但是它們解決的都是單樣本問題.為了使模型更加適用到小樣本分類問題上,Finn 等人[11]在2017 年提出了未知模型的元學習方法(model-agnostic metalearning,簡稱MAML).使用這個模型,從很少的數據中進行少步數的訓練,就可以得到較好的分類效果.MAML首先使用RNN 從所有任務的分布中來學習知識,而不是僅僅學習單一任務.MAML 致力于找到神經網絡中對每個任務較為敏感的參數,通過微調這些參數,讓模型的損失函數快速收斂.模型的初始參數為θ,針對不同的任務分別計算損失,根據每個任務的損失更新對應的模型參數.MAML 的目標是求得初始化參數θ,使得模型在面對新任務時,能夠使用梯度下降的方法在很少的步數內得到收斂.為了避免元學習器的偏移,并且提高元學習器的泛化性,Jamal 等人[91]提出了算法未知任務元學習法(task-agnostic meta-learning,簡稱TAML).在這項工作中,為了避免元學習模型對訓練任務過擬合,作者在輸出預測時加入了一個正則化項.正則化要么會使預測具有更高的熵(即預測的概率不會看起來像一個獨熱矢量),要么使模型在不同任務之間的差異更小(即,在不同任務上表現相同).顯然,對于小樣本學習來說,有一個強大的正則化機制是十分重要的.本文作者在MAML 的基礎上測試了該方法,得到了更優的性能.
MAML 在小樣本圖像分類任務中已經得到了廣泛使用,但是在自然語言處理領域,小樣本學習的問題還亟待解決.相比圖像分類的任務,文本分類的任務更具有挑戰性,這和文本本身的性質有關.例如,使用微博評論做情感分析任務,將會面臨拼寫錯誤、縮略詞等難題;而針對一張圖像,模型只需要提取它的圖像特征即可,因為圖像是一個客觀的實體.由于上述原因,文本分類比圖像分類更具有挑戰性[13].不過,近幾年文本方面的小樣本學習仍取得了一些突破性進展[14-16].Xiang 等人[15]在2018 年將MAML 遷移到了文本領域,并且在方法中加入了注意力機制,提出了基于注意力機制的未知任務元學習法(attentive task-agnostic meta-learner,簡稱ATAML).在文本分類中,不同的詞對于分類的重要程度不同.例如,對書的評論進行情感分析的任務中,“我覺得這本書十分有趣”中的“有趣”,對于將這條評論判定為正面情感起著更重要的作用.注意力機制可以將文本中的詞語賦予不同的權重,使得對分類起著更重要作用的詞語能夠有更高的影響力.ATAML 主要分為兩個部分:一是忽略任務的表示學習,二是面向任務的注意力學習.第1 部分是在許多任務中學習一個通用的嵌入模型,將一段文本中的每個詞都表示為向量,模型參數為θE;第2 部分是針對特定的任務學習特定的參數θT,θT={θW,θATT},其中,θATT為注意力機制參數,θW為分類器參數.
但是MAML 存在著一些缺點:一是訓練時需要數量足夠多的任務才可以收斂;二是這種方法一般只適用于淺層網絡,在深層網絡中泛化性較差,容易過擬合.Sun 等人[92]提出:可以讓MAML 只學習最后一層作為分類器,用所有訓練數據預訓練一個特征提取器,固定特征提取器.該算法利用了MAML 的思想,隨機初始化分類器W的參數;然后針對每個任務,利用支持集來優化W,得到更新后的W;計算查詢集的損失,梯度更新W,以得到新的W.Liu 等人[93]也在MAML 上做了一些改進,他們認為:對于一個元學習的任務,超參數的設置是十分重要的.可以利用元學習對網絡中每一層學習一個超參數,并且在通常情況下,一個分類器具有不穩定性,可以在MAML的機制上學習如何融合多個分類器:首先,MAML 內循壞更新初始參數多次,得到多個分類器;其次,在MAML 外循環優化分類器的初始參數、超參數和多個分類器融合系數.其中,測試集上的預測類別為多個分類器預測值加權求和,利用測試集的損失函數更新上述參數.
為了更好地融入語義信息,Wang 等人[94]提出了任務感知特征嵌入網絡(TAFE-Net).在這項工作中,標簽嵌入被用來預測數據特征提取模型的權重.該方法通過權重分解,做到只需要預測一個較低維的權重向量,使得權重預測更加簡便.此外,該方法還通過嵌入損失使得語義嵌入和圖像嵌入對齊.除此之外,還有很多元學習的方法.例如,Ravi 等人[86]在2017 年提出了利用優化器的元學習模型進行小樣本圖像分類,該模型使用基于LSTM的元學習器學習優化算法,用優化算法的參數更新規則更新分類器的網絡參數,使得分類器在小樣本數據上能取得較好的分類效果.同樣地,使用上述方法也可以幫助分類器學習到一個較好的初始化參數,使得模型能夠在新的小樣本數據集上快速收斂.模型的具體流程如下:首先,元學習器給分類器一個初始化參數θ,將第1 個batch的數據輸入分類器進行訓練,得到當前的損失和斜率,并將其反饋給元學習器;元學習器根據損失更新模型參數,將更新后的參數傳給分類器.按照這個步驟循環迭代.因為元學習器參數更新和LSTM 細胞狀態更新的過程十分相似,所以在此方法中,可以把LSTM 細胞單元更新的計算方法應用到元學習器的參數更新中.Gidaris 等人[95]提出了一種方法,該方法包含一個基于注意力機制的權重生成器,同時,在特征表示和類別權重向量之間重新設計一個CNN 作為余弦相似度函數.先使用訓練集訓練得到特征提取器;然后對于新的小樣本數據,通過一個元學習器來生成對應的參數權重.在含有多個樣本時,使用了注意力機制來選擇對應的初始權重,而不是做一個簡單的平均.
在上述基于元學習的方法中,元學習器從多個任務中學習知識,但是對于不同的任務學習到的模型初始參數是相同的,忽略了不同任務之間的差異性.而在現實世界中,不同任務之間千差萬別,基于這個前提,Yu 等人[16]在2018 年提出了多任務聚類的元學習法.該模型對所有任務進行聚類,將不同的任務分成不同的簇,同一簇中的任務較為相似,它們共享一套分類器參數.當新任務到來時,計算每個簇的分類器在當前小樣本數據上的適應效果,該適應效果由適應參數α表示;隨后,當前分類任務的模型參數由所有簇的參數與α線性組合得到;最后輸出分類結果.
通過梳理近年來基于元學習的小樣本學習模型,不難看出:隨著元學習的興起,各種元學習方法層出不窮.元學習方法經歷了從單樣本學習到小樣本學習的轉變,同時也從圖像領域遷移到了文本領域.元學習方法為小樣本學習帶來了很大突破,到今后很長一段時間都將是小樣本學習的主流方法.研究人員可以設計新的元學習器,讓分類器在少量樣本上學得更快更好.
3.3 基于圖神經網絡的方法
在計算機科學中,圖作為一種數據結構,由點和邊構成.圖這種數據結構,具有表現力強和展示直觀的優點.隨著近年來機器學習的興起,機器學習逐漸被應用到圖的分析上.圖神經網絡是一種基于深度學習的處理圖領域信息的模型,由于其較好的性能和可解釋性,它最近已成為一種廣泛應用的圖分析方法[96].圖神經網絡有很多種變體,比較常用的有圖卷積神經網絡(graph convolutional network)、門控圖神經網絡(gated graph neural network)和圖注意力網絡(graph attention network)等.
Garcia 等人[97]在2018 年使用圖卷積神經網絡實現小樣本圖像分類.在圖神經網絡里,每一個樣本被看作圖中的一個節點,該模型不僅學習每個節點的嵌入向量,還學習每條邊的嵌入向量.卷積神經網絡將所有樣本嵌入到向量空間中,將樣本向量與標簽向量連接后輸入圖神經網絡,構建每個節點之間的連邊;然后通過圖卷積更新節點向量,再通過節點向量不斷更新邊的向量,這就構成了一個深度的圖神經網絡.如圖5 所示,5 個不同的節點輸入到GNN 中,根據公式A 構建邊,然后通過圖卷積更新節點向量,再根據A 更新邊,再通過一層圖卷積得到最后的點向量,最后計算概率.利用公式
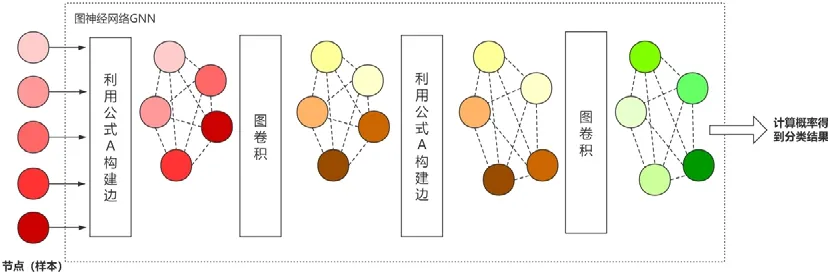
Fig.5 Model process of GNN[97]圖5 GNN 模型流程圖[97]
上面的方法是對圖中的節點進行分類,Kim 等人[98]從另一個方面進行考慮,對圖中的邊進行分類.首先,對圖中的邊特征向量進行初始化,邊的特征向量有兩維:第1 維表示相連的兩個節點屬于同一類的概率,第2 維表示它們不屬于同一類的概率.隨后,用邊的特征向量更新節點向量,邊的兩維特征分別對應節點的類內特征和類間特征.經過多次更新后,對邊進行二分類,得到兩個節點是否屬于同一類.為了對傳統的GNN 進行改進,Gidaris等人[99]在GNN 中加入了降噪自編碼器(DAE),以修正小樣本類別的權重.DAE 理論指出:對于被高斯噪聲干擾的輸入,DAE 能夠估算其輸入w的密度的能量函數p(w)的梯度.首先,在進行訓練時加入部分的高斯噪聲數據來防止過擬合,樣本經過嵌入網絡之后,輸入到圖神經網絡中作為節點.根據未加入高斯噪聲的各類初始權值向量的余弦相似性,將最近的類連接起來,而圖的兩個節點之間的邊的邊緣強度(邊的權值)就是兩個節點的余弦相似性的softmax 函數值,根據softmax 函數輸出結果.基于圖神經網絡的方法相比基于度量學習和基于元學習的方法較少,但圖神經網絡可解釋性強并且性能較好,可以思考如何對其進行改進,從而提高分類準確率.
4 數據集與實驗
在小樣本圖像分類任務中,一些標準數據集被廣泛使用.單樣本學習最常用的是Omniglot 數據集[100],小樣本學習最常用的數據集是miniImageNet[101].除此之外,常用數據集還有CUB[102]、tieredImageNet[50]等,同時,CIFAR-100、Stanford Dogs 和Stanford Cars 常用作細粒度小樣本圖像分類.接下來對每個數據集進行簡單介紹.
(1) Omniglot 包含50 個字母的1 623 個手寫字符,每一個字符都是由20 個不同的人通過亞馬遜的Mechanical Turk[103]在線繪制的.
(2) miniImageNet 是從ImageNet[104]分割得到的,是ImageNet 的一個精縮版本,包含ImageNet 的100 個類別,每個類別含有600 個圖像.一般64 類用于訓練,16 類用于驗證,20 類用于測試.
(3) tieredImageNet 是Mengye 等人[50]在2018 年提出的新數據集,也是ImageNet 的子集.與miniImageNet不同的是,tieredImageNet 中類別更多,有608 種.
(4) CUB(caltech-UCSD birds)是一個鳥類圖像數據集,包含200 種鳥類,共計11 788 張圖像.一般130 類用于訓練,20 類用于驗證,50 類用于測試.
(5) CIFAR-100 數據集:共100 個類,每個類包含600 個圖像,分別包括500 個訓練圖像和100 個測試圖像.CIFAR-100 中的100 個子類所屬于20 個父類,每個圖像都帶有一個子類標簽和一個父類標簽.
(6) Stanford Dogs:一般用于細粒度圖像分類任務.包括120 類狗的樣本共計20 580 個圖像,一般70 類用于訓練,20 類用于驗證,30 類用于測試.
(7) Stanford Cars:一般用于細粒度圖像分類任務.包括196 類車的樣本共計16 185 個圖像,一般130 類用于訓練,17 類用于驗證,49 類用于測試.
本文選取一些著名模型在上述數據集上的實驗結果進行總結,所有方法都選取了5-way 1-shot(即5 個類別,每個類別具有1 個樣本)和5-way 5-shot(即5 個類別,每個類別具有5 個樣本)的結果進行對比.圖像分類的任務一般使用CNN 作為嵌入網絡,常用的有VGG,Inception 和Resnet 等.具體見表1.
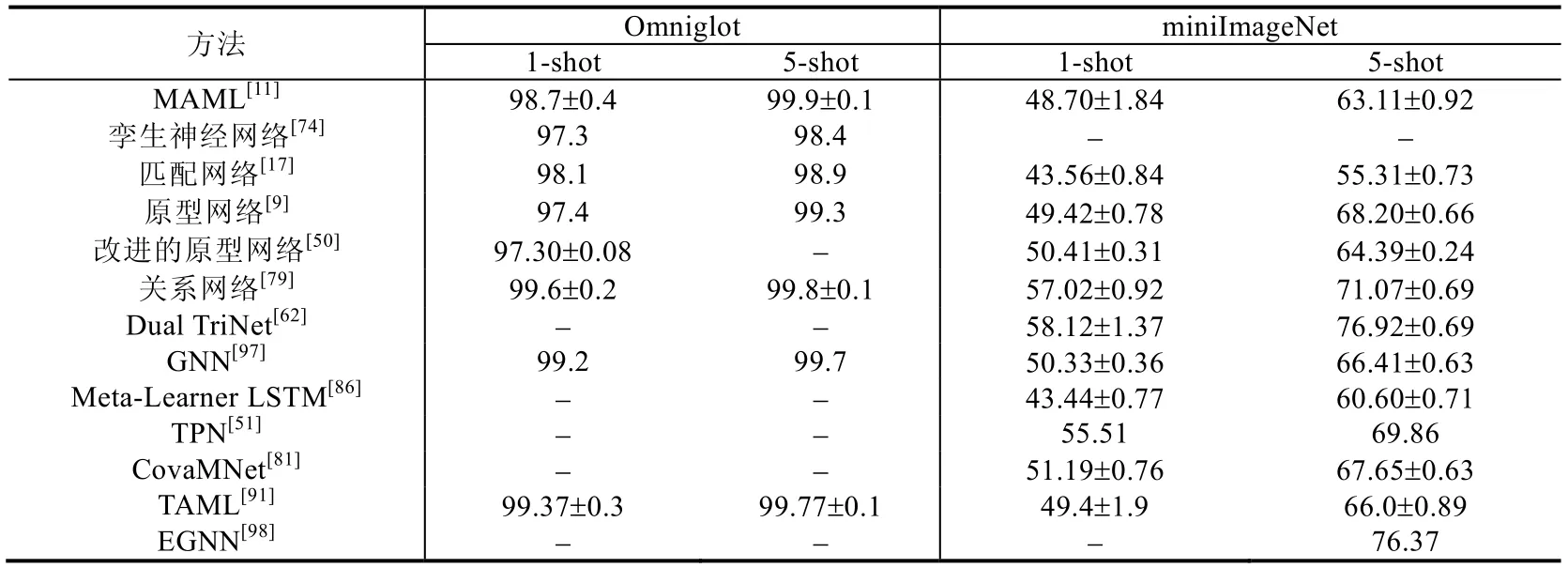
Table 1 Comparison of precision in few-shot learning methods表1 小樣本學習方法準確率對比
表1 選取了Omniglot 和miniImageNet 數據集的實驗結果作為對比參考,因為其他的數據集使用次數較少,所以在此不多加討論.由表1 可看出,每個數據集中5-shot 的準確率均比1-shot 的高.表明訓練數據越多,學到的特征也越多,分類效果越好.在Omniglot 數據集上,所有模型在1-shot 場景下的準確率都達到了97%,在5-shot任務下的準確率均達到了98%,可提升空間較少;在miniImageNet 數據集上,不同模型之間的提升較大,在1-shot任務下效果最好的模型比效果最差的準確率提升了15%左右,在5-shot 任務下準確率提升了高達21%,表明在此數據集上還有較大的提升空間.
5 小樣本學習總結與展望
5.1 小樣本學習總結
由于真實世界的某些領域中樣本量很少或標注樣本很少,而樣本標注工作會耗費大量時間和人力,近年來,小樣本學習逐漸成為人們重點關注的問題.本文介紹了圖像分類和文本分類兩個任務中小樣本學習的研究進展,總體上看,小樣本圖像分類已有了許多性能優異的算法模型,但小樣本文本分類仍是個亟待解決的問題.根據小樣本學習方法的不同,本文將其分為基于模型微調、基于數據增強和基于遷移學習的方法這3 類,其中,基于數據增強的方法可以細分為基于無標簽數據、基于數據合成和基于特征增強的方法這3 種,基于遷移學習的方法可以細分為基于度量學習、基于元學習和基于圖神經網絡的方法這3 種.本文對以上幾種方法做了總結,并且比較了它們的優點和缺點,具體見表2.
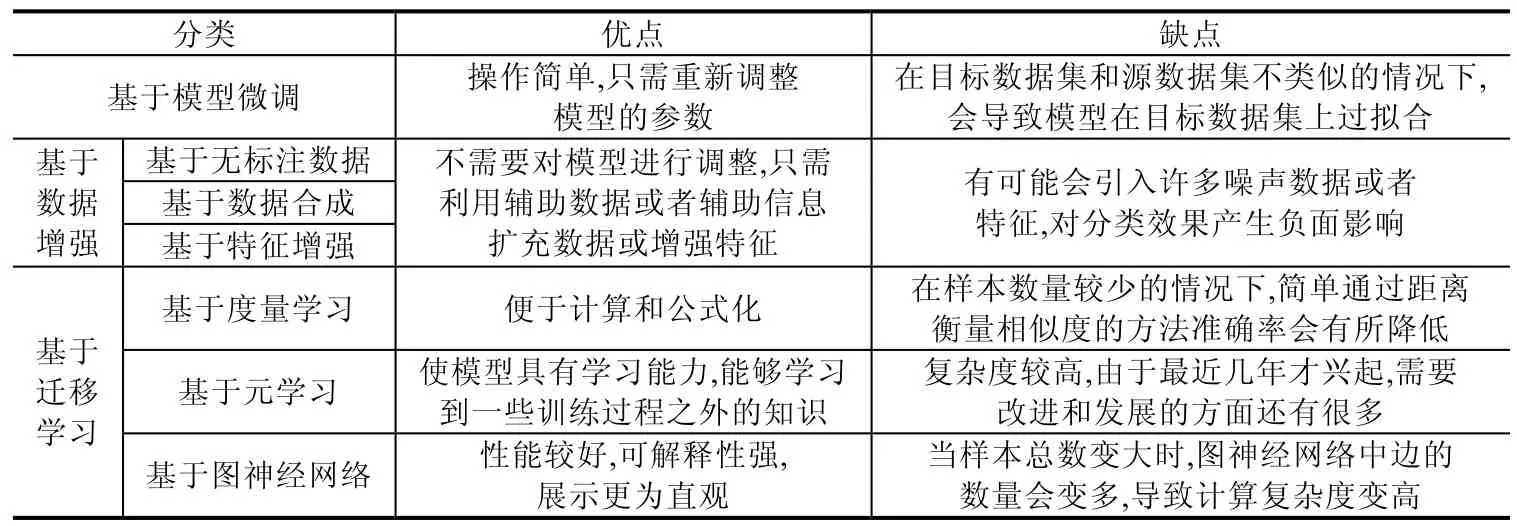
Table 2 Comparison of advantages and disadvantages in different few-learning methods表2 小樣本學習方法優缺點對比
總體來說,小樣本學習研究已有很大進展,但和人類分類準確率相比還有很大差距.為了解決基于模型微調方法帶來的過擬合問題,基于數據增強和基于遷移學習的方法被提出.基于數據增強的方法是對小樣本數據集進行數據擴充或特征增強,這種方法可以不對模型進行參數調整,但是容易引入噪聲數據.基于遷移學習的方法是將舊領域學到的知識遷移到新領域,并且不需要兩者之間有很強的關聯性,但關聯性越強,遷移效果越好.在基于遷移學習的方法中,基于度量學習的方法最簡單、容易操作,只需要通過距離來衡量樣本之間的相似度,但是學習到的知識太少.基于元學習比基于度量學習的方法學習能力更強,可以學習到更多知識.基于圖神經網絡的方法在3 種方法中展示最為直觀、可解釋性較強,但樣本總數變大時,會導致計算復雜度增高.
5.2 小樣本學習挑戰
盡管近年來小樣本學習已經得到深入研究,并且取得了一定進展,但仍面臨著一些挑戰.
(1) 強制的預訓練模型[4]
在已有的小樣本學習方法中,不管是基于模型微調的方法還是基于遷移學習的方法,都需要在大量的非目標數據集上對模型進行預訓練,致使“小樣本學習”一定程度上變成個偽命題.因為模型的預訓練依舊需要大量標注數據,從本質上來看,與小樣本學習的定義背道而馳.從根本上解決小樣本問題,就要做到不依賴預訓練模型,可以研究利用其他先驗知識而非模型預訓練的方法.
(2) 深度學習的可解釋性
由于深度學習模型本身是一個黑盒模型,在基于遷移學習的小樣本深度學習模型中,人們很難了解到特征遷移和參數遷移時保留了哪些特征,使得調整參數更加困難[105].提高深度學習的可解釋性,能幫助理解特征遷移,在源領域和目標領域之間發現合適的遷移特征[106].在此方面已有了一些工作[107].
(3) 數據集挑戰
現有的小樣本學習模型都需要在大規模數據上預訓練,圖像分類任務中已經有了ImageNet 作為預訓練數據集,而文本分類中,缺少類似的預訓練數據集,所以需要構建一個被各種任務廣泛使用的小樣本文本分類預訓練數據集.同時,在小樣本圖像分類任務中,miniImageNet 和omniglot 是兩個被廣泛使用的標準數據集.但在小樣本文本分類任務中,不同工作所采用的目標數據集千差萬別,有很多都是網上爬取的數據集.所以,構建一個適用于文本分類任務的小樣本目標數據集是需要考慮的問題.為解決這個問題,Han 等人[108]在2018 年提出了一個小樣本關系抽取數據集FewRel,其中包含100 種分類,共70 000 個實例,規模和miniImageNet 相當.
(4) 不同任務之間復雜的梯度遷移[90]
在基于元學習的小樣本學習方法中,從不同任務中學習元知識的過程梯度下降較慢.將模型遷移到新任務中時,由于樣本數量較少,所以期望模型能在目標數據集上快速收斂,在此過程中,梯度下降較快.針對基于元學習的方法設計合理的梯度遷移算法,也是目前需要研究并亟待解決的問題.
(5) 其他挑戰
在小樣本文本分類中,不同語言的分類難度不同.英文的文本分類比較成熟,但是中文分類由于分詞等問題,目前還不是很成熟.另外,跨語種或者多語種的文本分類是一個難題,由于源語言與目標語言的特征空間相差甚大,同時,各國的語言、文字又包含了不同的語言學特征,這無疑加大了跨語言文本分類的難度[105].
5.3 小樣本學習展望
通過對當前小樣本學習研究進展的梳理,可以展望未來小樣本學習的發展方向.
1)在數據層面,嘗試利用其他先驗知識訓練模型,或者更好地利用無標注數據.為了使小樣本學習的概念更靠近真實,可以探索不依賴模型預訓練、使用先驗知識(例如知識圖譜)就能取得較好效果的方法.雖然在很多領域中標注樣本數量很少,但真實世界中存在的大量無標注數據蘊含著大量信息,利用無標注數據的信息訓練模型,這個方向也值得深入研究.
2)基于遷移學習的小樣本學習面臨著特征、參數和梯度遷移的挑戰.為更好地理解哪些特征和參數適合被遷移,需要提高深度學習的可解釋性;為使模型在新的領域新任務中快速收斂,需要設計合理的梯度遷移算法.
3)針對基于度量學習的小樣本學習,提出更有效的神經網絡度量方法.度量學習在小樣本學習中的應用已經相對成熟,但是基于距離函數的靜態度量方法改進空間較少,使用神經網絡來進行樣本相似度計算將成為以后度量方法的主流,所以需要設計性能更好的神經網絡度量算法.
4)針對基于元學習的小樣本學習,設計更好的元學習器.元學習作為小樣本學習領域剛興起的方法,目前的模型還不夠成熟.如何設計元學習器,使其學習到更多或更有效的元知識,也將是今后一個重要的研究方向.
5)針對基于圖神經網絡的小樣本學習,探索更有效的應用方法.圖神經網絡作為這幾年比較火熱的方法,已經覆蓋到很多領域,并且可解釋性強、性能好,但是在小樣本學習中應用的模型較少.如何設計圖網絡結構、節點更新函數和邊更新函數等方面,值得進一步探究.
6)嘗試不同小樣本學習方法的融合.現有小樣本學習模型都是單一使用數據增強或遷移學習的方法,今后可以嘗試將二者進行結合,從數據和模型兩個層面同時進行改進,以達到更好的效果.同時,近年來,隨著主動學習(active learning)[109]和強化學習(reinforcement learning)[110]框架的興起,可以考慮將這些先進框架應用到小樣本學習上.
6 結束語
由于真實世界中樣本稀缺的問題,小樣本學習越來越受到人們的重視.隨著機器學習和深度學習的不斷發展,基于小樣本學習的分類問題已經在計算機視覺和自然語言處理領域有了深入的研究,并將在醫療領域(如疾病診斷)、金融領域(如資金異常)等不同領域展現出良好的應用前景.本文對目前小樣本學習的研究進展進行了詳細闡述,同時分析了目前小樣本學習面臨的挑戰,最后對其進行了前景展望.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
