基于Scrapy技術的高校計算機類課程網絡視頻庫建設的研究
2021-03-07 12:36:37張笑青蔣慧
電腦知識與技術 2021年36期
張笑青 蔣慧







摘要:該文基于Scrapy爬蟲技術采集慕課網站(大型開放式網絡課程)的視頻資源,并使用協同推薦算法對采集的信息進行推薦和展示。主要內容包括對大學開放課程平臺進行視頻爬蟲、數據解析、數據存儲;將數據爬取的結果與Recommend算法相結合實現課程信息推薦功能;通過使用Flask框架對采集和推薦的結果進行展示,并實現視頻分類與模糊查詢等功能。該視頻庫系統可以給教師與學生提供更豐富便捷的教學資源平臺。
關鍵詞:Python爬蟲;Scrapy框架;視頻庫;高校計算機課程
中圖分類號:TP393? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)36-0037-03
開放科學(資源服務)標識碼(OSID):
1 背景
基于慕課平臺的高校計算機類課程網絡教學是推動高校計算機類課程教育改革、促進高校計算機課程教育網絡化、科學化的有效途徑。視頻課程突破了傳統教學活動的時間和空間限制,使課堂上枯燥的教學內容變得更加生動,同時實現了教學雙方的全面交流與互動。隨著慕課模式在高等教育中的普及,視頻課程庫的開發逐漸成為高等教育領域的重要課題之一。為了確保高校教育的質量和效果,本文對高校慕課平臺下計算機類視頻課程庫建設過程中的相關問題進行了研究,討論了構建視頻課程庫系統的方法,有助于確定與設計有效且穩健的視頻課程模型相關的問題,期望能為高校計算機類視頻課程的科學建設提供一些參考。
本文的各部分組織如下:首先,介紹網絡爬蟲Scrapy框架,它包含了Scrapy引擎(核心)、Downloader Middlewares下載器、Schedular調制器、管道Spiders解析器,并介紹其相關功能。其次,介紹視頻信息的采集和存儲,根據慕課平臺的內容和它的網頁源代碼分析其頁面結構,從而實現網頁數據的采集;同時,采用協同過濾算法(Recommend)得出權重矩陣并返回數據庫進行永久保存。最后,介紹對采集的視頻信息數據進行描述性的界面展示,并對采集的數據進行二次開發,使用Flask技術實現視頻數據的分類和模糊搜索。
2 網絡爬蟲
網絡爬蟲可以根據既定的算法和邏輯自動采集所需要的頁面資源數據,并能更新網頁數據[1]。通常網絡爬蟲可以分為數據爬取、數據預處理、數據存儲幾部分操作。其中,聚焦爬蟲能根據既定的定量爬取策略,通過網頁分析算法,過濾有效的URL及其與主題相關的鏈接,在特定的搜索框架下,從所需要的隊列中選取下一個數據想要爬取的網頁,并進行反復爬取,直到得到滿足數據匹配的URL網頁時停止。根據爬取策略所爬取的網頁數據,將會被后臺處理,包括分析過濾、創建索引以便下一步可以進行查詢和檢索操作。
2.1 視頻信息采集爬蟲的分析與設計
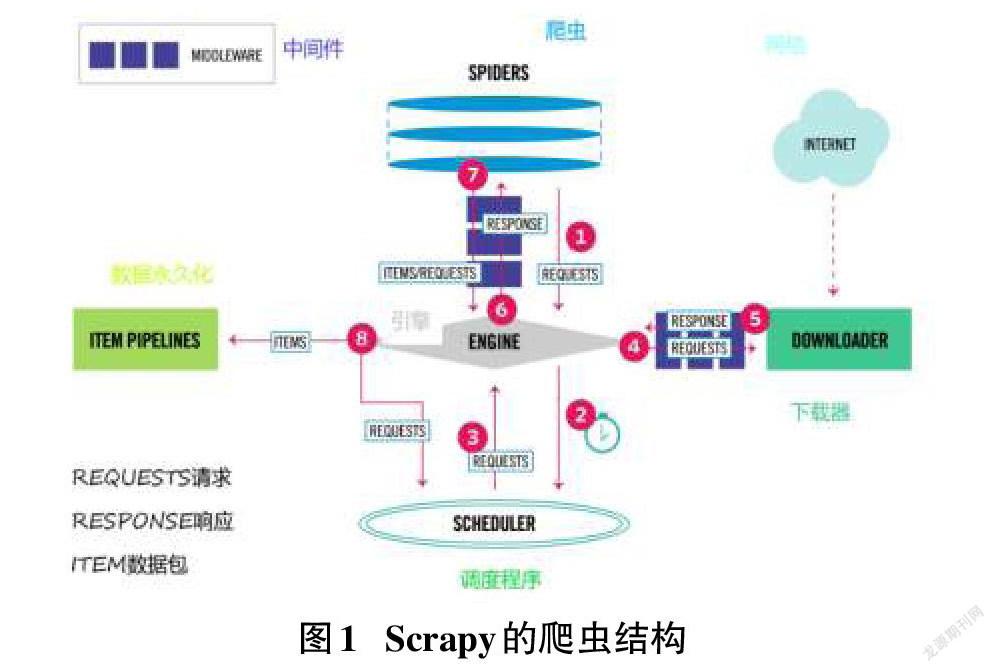
Scrapy引擎是Scrapy的核心,它可以將前端收到的請求發送給爬蟲,然后Spiders發送給核心對Scheduler請求,再被引擎提交到下載器處理,下載器處理完成后會發送Responses給引擎,引擎將其發送至Spiders進行處理[2]。Scrapy的爬蟲結構如圖1所示。
3 視頻信息采集的實現
本文的網絡視頻數據爬蟲的整體框架大致如圖2所示。
3.1 數據源與網頁分析
本文先對慕課網站的爬取進行研究,由于網課為在線播放的模式,普通爬蟲較難下載視頻,所以本次抓取的慕課網的視頻基本信息包括課程名稱、圖片的地址、課程圖片內容、課程人數、課程簡介、課程的評分、課程難度指數以及課程的時長等,示例頁面如圖3所示。
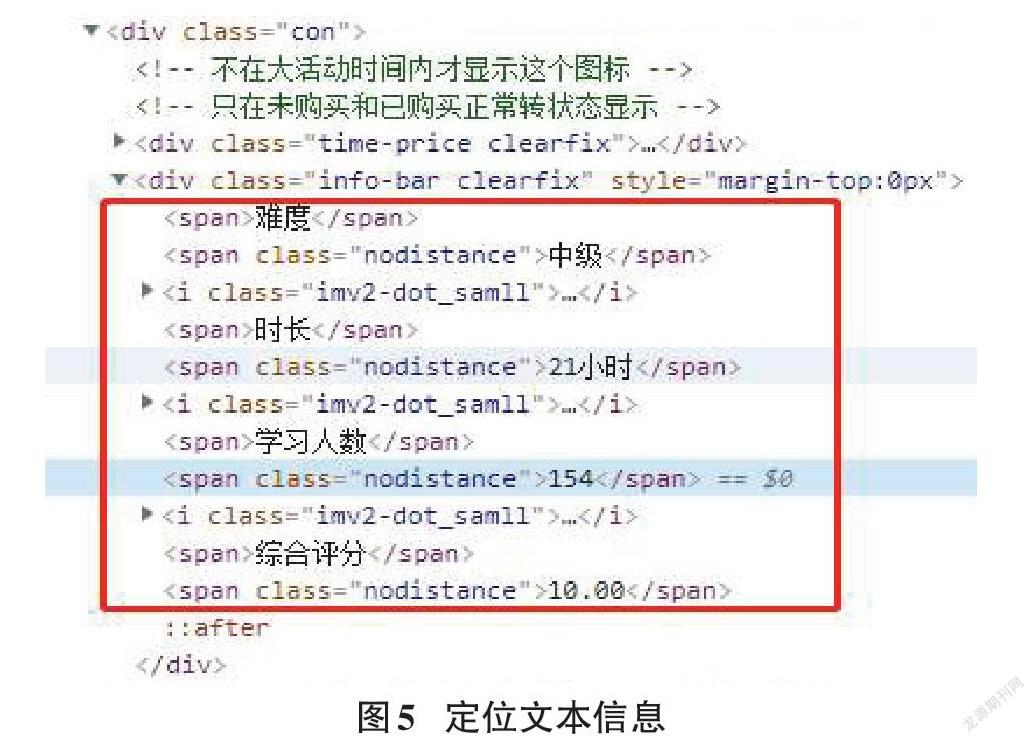
使用Response爬蟲請求獲取網頁資源,可以抓取慕課網站中每個課程的Div,這里Scrapy支持使用Xpath定位器定位想要爬取網頁資源的具體位置,可以使用Xpath表達式獲取所有h3標簽里的文本內容,從而獲取頁面中課程的標題[3-4]。如圖4代碼可以定位課程名稱:
3.2 MongoDB數據庫與數據存儲
本文采集的數據是慕課網的視頻信息,對于視頻信息的存儲,這里選擇使用非關系型的文檔數據庫MongoDB來進行存儲。
MongoDB數據庫是基于文檔的非關系型數據庫,因此MongoDB并沒有固定的結構,在建立文檔型的范例時,即便沒有該數據庫的布局信息,仍能存到MongoDB數據庫中[5]。根據慕課網提供的字段信息,設計了如下集合:cursesinfo用于存儲采集的視頻信息數據,history用于存儲點擊的歷史數據,hotcourse是根據前面的演算和總結計算出8大熱門課程。其中curseinfo集合存儲的信息對應慕課網爬取的各個字段如圖7所示。
數據存儲使用代碼實現,即先將爬蟲爬取的網頁元素內容解析,并創建一個dict對象,將爬取的數據逐一對應填充到dict內,再通過PyMongo的collection方法將dict中的數據存儲到MongoDB中即可。
3.3 數據預處理
數據預處理主要是去除臟數據,這里主要從數據缺失值檢測、數據去重、噪聲數據處理、數據集成這四個方面對數據進行清洗。通常在數據采集和傳輸等情況下會導致數據缺失,對于缺失值處理方法通常有兩種方法:第一種方法是直接刪除不完整的數據,該方法適用于缺失值的樣本占整個數據集樣本的比例較低的情況,但是這樣可能會丟失大量隱藏在這些刪除數據中的信息或者造成資源浪費;第二種方法是通過插入數據將數據填充完整,通常是將平均數據插入來補充完整,即是取數據中的平均數代替數據中所缺少的值,或者在數據中隨機地挑選個別數據進行插入。本文中使用的是第一種方法,Python中的isnull為是否需要進行插入填補。
3.4 基于物品的協同過濾算法的實現
基于物品的協同算法步驟:1)計算物品之間的相似度;2)根據物品的相似度和用戶的歷史行為記錄給用戶生成推薦列表。該算法的核心是:從物品角度找到相似度高的商品進行推薦。算法思想為:根據用戶對物品的喜歡程度找到相似的物品,再根據用戶曾經喜歡的物品推薦相類似的物品。從計算層面看,衡量物品的好壞就是根據用戶對這個物品的喜歡程度,根據用戶的曾經喜歡程度和現在喜歡程度得到一個物品推薦的排序列表。
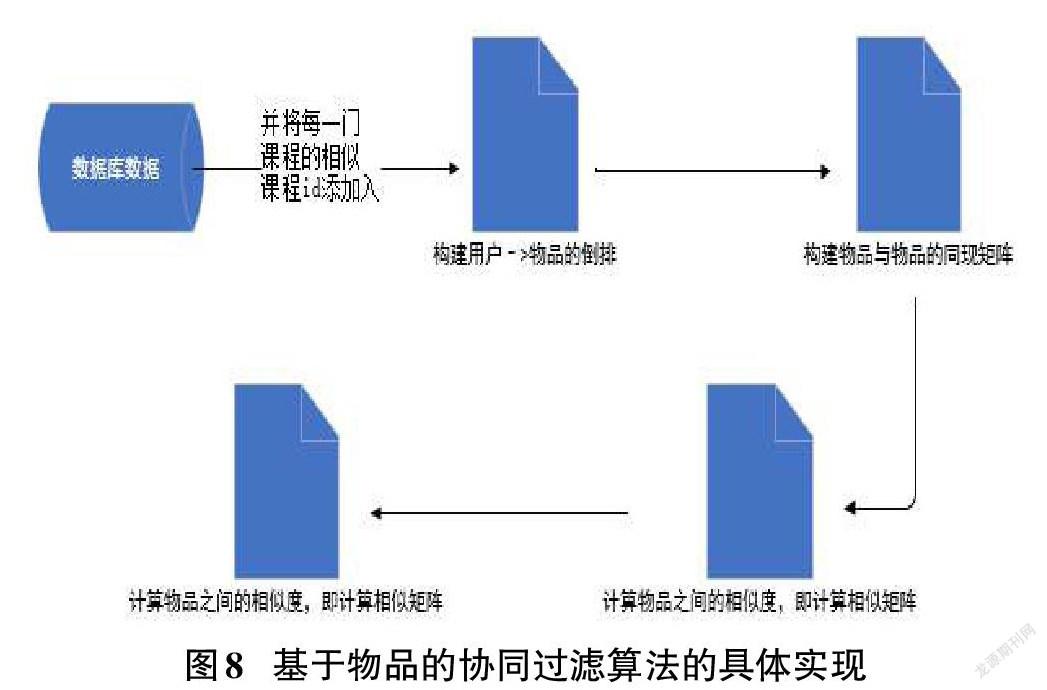
基于Python語言和物品的協同過濾推薦算法,對數據庫中的課程相關數據進行功能的實現,具體實現過程如圖8所示。
圖8的第一步是搭建用戶和物品的直接關系,接著得到用戶和物品之間的權重矩陣,計算他們之間的相似度,然后根據用戶的瀏覽記錄,給用戶推薦系統認為用戶需要的物品,因此最終推薦的物品根據用戶自己的喜好決定。
4 視頻數據采集展示的實現
本文中推薦課程系統的設計采用Flask框架,其功能主要為視頻課程的推薦、搜索、分類。Flask是如今流行的Web框架,它使用Python實現功能,由于Flask不會將其全部的Web框架放在Python里面,而是將代碼簡單化,因此它又被稱為“微框架”。通常情況下Flask自己不會主動提供系統所需要的功能,在項目結構的運行狀態下它們可以自由進行配置。Flask主要包含兩個核心:Werkzeug和Jinja2,這兩個核心有著不一樣的功能。而就是由于Flask這兩個核心功能讓Web前端展示更為簡便明了。
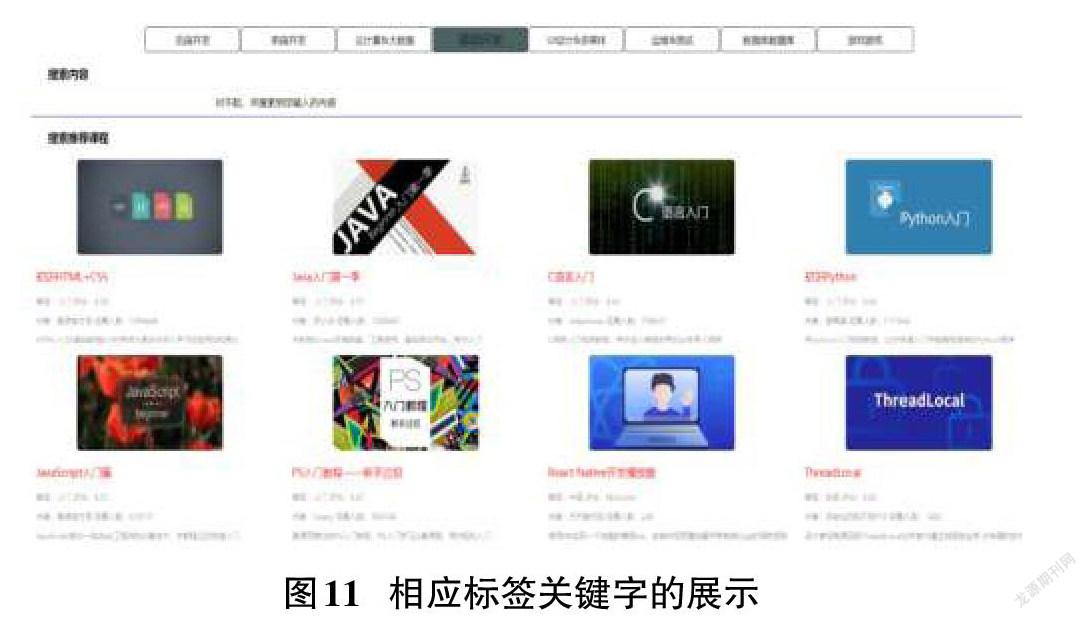
分類展示:選擇搜索框下的技術標簽,對于慕課網的對應分類視頻信息書籍進行展示,如圖11展示結果為前端技術教學相關內容。
推薦課程展示:在系統的推薦下,Recommend算法根據用戶瀏覽的課程進行推薦,實現推薦與關鍵字相關的課程信息。
相關課程關鍵字搜索:系統根據輸入的關鍵字進行模糊查詢,并實時進行數據采集,將采集后的內容呈現在頁面上,以展示相關的課程搜索結果及相關推薦課程展示。
5 結束語
本文主要使用Scrapy爬蟲技術爬取慕課網站的視頻資源,并使用協同推薦算法對采集的信息進行推薦和展示。該視頻資源系統可以給教師與學生提供更豐富便捷的教學資源平臺,對今后的計算機課程在線教與學具有創新價值和意義。
參考文獻:
[1] 劉雯.主流開源爬蟲框架比較與分析[J].電子世界,2018(6):65-67.
[2] 施金龍.基于PythonScrapy技術的新聞線索匯聚實現[J].電子技術與軟件工程,2020(13):180-181.
[3] 張捷,郝建維,李歡歡.基于Scrapy的分布式網頁及文件爬蟲應用的研究[J].科技創新導報,2020,17(21):149-153.
[4] 唐琳,董依萌,何天宇.基于Python的網絡爬蟲技術的關鍵性問題探索[J].電子世界,2018(14):32-33.
[5] 李興武.大數據下MongoDB數據庫數據文檔存儲去重研究[J].數字技術與應用,2017(9):99-101.
【通聯編輯:謝媛媛】
