文本情緒分析中詞嵌入模型對比研究
2021-03-07 12:36:37胡瓊李奇王樹軍
電腦知識與技術 2021年36期
胡瓊 李奇 王樹軍

摘要:在利用神經網絡進行文本情緒分析時,不同的詞嵌入會得到不同的判斷結果。該文對比了由文本自身建立的基線模型和預訓練詞嵌入模型GloVe以及FastText的識別效果,通過實驗得出了在不同情況下兩種類型的識別優劣性。此外,針對兩種預訓練詞嵌入,得出高頻詞匯的缺失對總體結果無重要影響的結論。
關鍵詞:情緒分析;預訓練詞嵌入
中圖分類號:TP311? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)36-0109-03
開放科學(資源服務)標識碼(OSID):
文本情緒分析是在神經網絡,尤其是以RNN(Recurrent Neural Network)為方向的深度學習方法上所重點研究的對象之一。簡單的文本情緒分類有正、負情感評價之分,稍微復雜一點的增加了中性評價,再為復雜的分類則是以1~5或1~10類似的多級評分表示,如對網店商品的打分,對酒店、旅游景點的評價等。研究文本情緒分析可在一定程度上協助被評價方更改產品體驗,改進廣告投放策略等。例如KFC決定用在社交媒體上獲取的“流行文化元素”作為某一季的產品主題,Apple公司以市場調研和競爭對手產品分析獲取的情感評價作為新產品的研發關鍵詞等[1]。
在以文本為分析對象的神經網絡結構中,文本信息通常是以詞元(token)的形式進行計算,即將單個字符(charlevel)或單詞(wordlevel)的數據轉換為數字,再將數字轉換為固定大小的向量。向量可以由文本自身決定,也可由外部預訓練詞向量導入。這一將獨立的文本信息映射為向量或矩陣的形式稱為詞嵌入。詞嵌入將作為深度模型中嵌入層的輸入進行下一步的運算。選擇合適的詞嵌入能更好地建立權重參數,不僅降低計算維度,且能更為準確地描述各個向量之間的關系[2]。為對下文中名詞概念加以解釋說明,本文以文本自身建立詞向量作為嵌入層輸入的算法模型稱為基線模型,以預訓練詞向量輸入嵌入層所建立的模型稱為預訓練嵌入層模型。
目前針對英文詞嵌入的研究主要包含有Word2Vec、GloVe和FastText三個方向等,根據語料庫差異,又可分為谷歌新聞熱詞模型、維基百科詞匯模型、網絡爬蟲(CommonCrawl)詞匯模型等。使用預訓練詞嵌入的目的一般是為了節約訓練時間,減少損失,同時獲得更為準確的預測性。目前,已有不少論文論證了預訓練嵌入層模型的有效性[3],也有部分論文表明相對基線模型,使用預訓練嵌入層模型并無優勢[4]。其中大部分論文都是以文本分類(如判斷文本內容是否包含非法信息等)作為研究方向,針對文本情緒分析的詞嵌入研究還不太多。
本文選取了金融類數據集[5],該數據集包含散戶投資者對美國財經新聞標題的4837條看法,每條看法有其對應的情緒標簽,為正、負、中三種評價之一。通過實驗,可針對該數據集建立一個較為準確的神經網絡預測模型。因研究對象為含有較長信息的文本變量,實驗選用了RNN算法,基于Tensorflow的Keras[6]建立了神經網絡模型,包括有嵌入層、含有256個神經元的GRU層、最大池化層以及全連接層,激活函數為softmax。在詞嵌入方面,為研究基線模型及預訓練嵌入層模型的區別和利弊,本文使用了FastText[7]以及GloVe[8]預訓練詞向量,通過調整參數,對比發現和使用文本自身詞嵌入時對識別結果造成的不同影響。
1 預訓練嵌入層和基線模型
在Keras中,定義一個嵌入層需要有詞匯表大小,輸出詞向量維度,初始化權重等。在以文本自身為語料庫的詞向量建立中,可設嵌入層初始化權重值為高斯隨機數,設定該權重值可隨著迭代次數學習更新;而在使用預訓練詞向量時,需首先導入詞向量,初始化權重值為向量值并禁止其迭代更新。在使用GloVe詞向量時,本文采用了其基于維基百科訓練的300維詞向量模型,FastText詞匯表同樣如此,同時為了更好地保持在實驗中各嵌入層一致性,實驗設定基線模型的輸出詞向量也是300維。
比較兩種預訓練詞嵌入,GloVe以單詞作為訓練中的最小單位,通過構建各單詞在指定語料庫中所對應的共現矩陣進行訓練,共現矩陣表示了每個單詞在上下文中出現的頻率。為了提高效率,需要分解共現矩陣以實現降維計算,例如在本文中所用GloVe向量為300維,GloVe同時也提供了100維、50維等向量模型。GloVe的優勢是在詞向量空間中能夠更好地描述詞與詞之間的關系。
FastText使用n-gram字符作為最小單位。例如,詞向量“apple”可以分解為單獨的詞向量單元,如“ap”“app”“ple”等,取決于n的大小。使用FastText的最大好處是它可以為稀有詞甚至是訓練期間未見過的詞生成更好的詞嵌入,因為經過n-gram分解后的字符向量與其他詞所分解的字符向量部分重復。這是以單詞為基本學習單位的GloVe或Word2vec詞嵌入所無法實現的。
2 簡單預處理
在訓練之前通常會對數據作預處理,在本文中,僅對數據作了簡單的清理,刪除了非英語字符、數字、各種標點符號,以及將所有單詞一律改成小寫。盡管在GloVe模型中保留了數字及部分特殊符號,為和FastText作對比,文本中統一不予考慮。事實上,如“經濟增長10%”這一句中,“經濟增長”作為關鍵,數字10或者符號%的省去并不會造成理解上的誤差。
在預處理后,實驗將預訓練詞向量與文本中所有詞匯量作對比,取交集作為詞嵌入。對于文本中出現,預訓練詞向量中未出現單詞統一設零,對于預訓練詞向量中包含,文本中未包含單詞統一舍去。對比而言,在基線模型中,預處理后文本中所有單詞參與訓練,沒有置零或舍去的操作。
3 實驗
3.1 分批次訓練
以前文所述RNN模型進行實驗,機器運行環境為Linux系統,Anaconda版本4.10.1,Tensorflow-2.4.1,Python-3.8.1。通過調整訓練集大小和批次大小進行分步實驗,設測試集大小分別占總數據集的0.2、0.5和0.8。同時設時期(epoch)為50,提前停止(EarlyStopping)節點設定為損失函數停止下降3次。驗證集大小設為0.2。將訓練好的模型用于測試集,以批次大小為32、128和512分三次進行實驗。結果如圖1所示。
從圖中可以看到,測試集正確判斷文本情緒的比例總體隨著訓練集的增加而上升。當訓練集數量占比0.2時,三種詞嵌入形式預測正確率都在70%以下,使用預訓練詞嵌入的效果比自嵌入更好,當訓練集數量增加時,三種詞嵌入形式預測正確率超越70%,使用基線模型的結果和預訓練詞嵌入的結果逐漸持平,在訓練集占比0.8時,三種詞嵌入形式預測正確率在74%上下,基線模型的準確度和GloVe詞嵌入近似,高于FastText模型。對比兩種詞嵌入,GloVe的識別率相對FastText略高。因設定訓練集每次打亂數據進行學習,Keras在同一參數下運行結果可能產生3%的波動,根據上圖并不能取得更詳細的結論,同時經作者多次驗證,圖1只是所有可能性的一種,實驗結果證明GloVe并不一定比FastText識別結果要好。
3.2 同一批次下損失函數分析
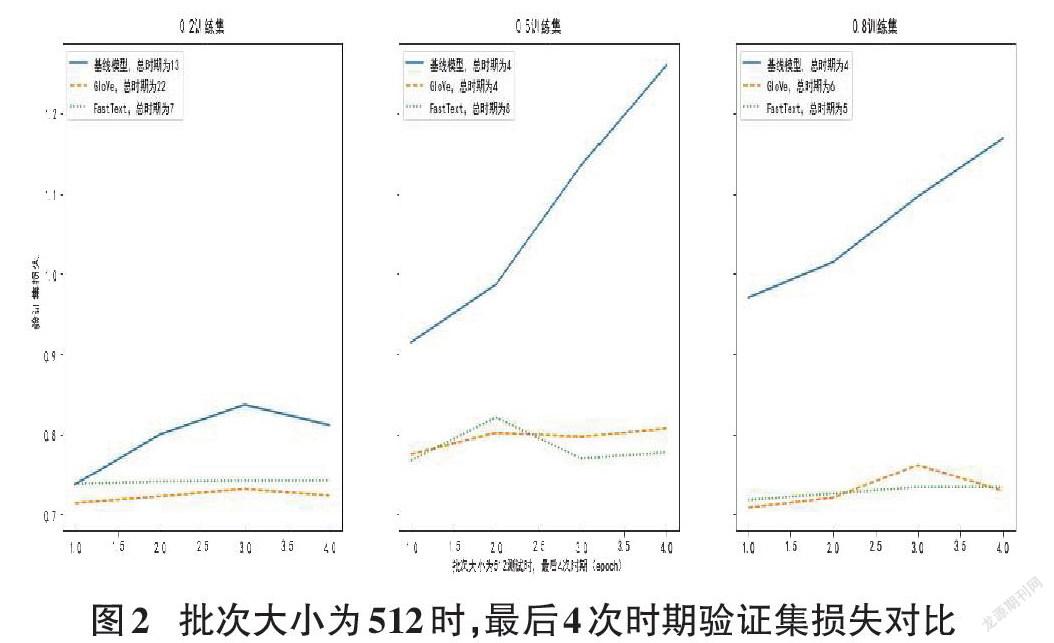
從圖1中三種批次大小設定來看,32~512的改變并沒有對測試集的識別率產生重要影響,本例中批次大小改變更多的是影響運算效率而非結果準確性。圖2展示了以512為批次大小運算情況下,不同詞嵌入方式的驗證集損失。因設定了提前停止為3,故選取最后4次時期運算結果作圖。
從圖中可以看到基線模型損失基本全部高于預訓練詞嵌入模型且呈上升趨勢,兩種詞嵌入模型之間的區別并不大。說明預訓練詞嵌入在取得較小的損失函數上具有更大的優勢。以本例來看,基線模型的損失更大,更容易產生過擬合。另一點需加以說明的是在實驗中發現總體上使用基線模型需要的時期小于預訓練詞嵌入,也就是在相同參數的設定下,基線模型的運算速度大于預訓練嵌入層模型。
3.3 GloVe與FastText對比
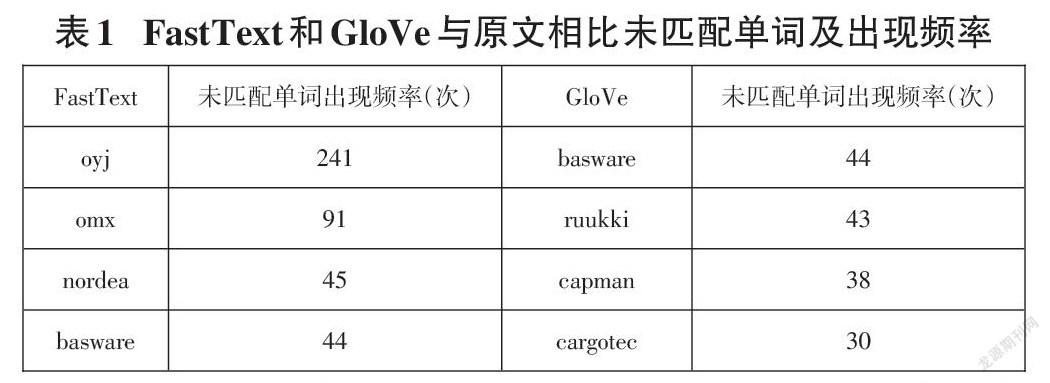
為進一步找出兩種不同預訓練詞嵌入的區別,實驗分別對比了GloVe和FastText詞向量與原文的匹配度,結果為FastText的詞匯匹配度是80.62%,即4846個總詞匯量中有3906個單詞存在于預訓練詞匯庫中,總文本詞嵌入為94.91%,未匹配單詞為“oyj”等專有名詞。對比而言,GloVe的單詞匹配度有88.46%,總文本詞嵌入達到了97.45%,未匹配單詞為“basware”等專有名詞,且出現頻率不高。GloVe的預訓練單詞總量為40萬,FastText為100萬,前者是基于2014年的維基百科和英語字典(English Gigaword Fifth Edition), 后者是基于2017年的維基百科、UMBC語料庫和統計機器翻譯(SMT)中新聞數據集。表1列出了兩種詞嵌入中前4種高頻未匹配單詞。
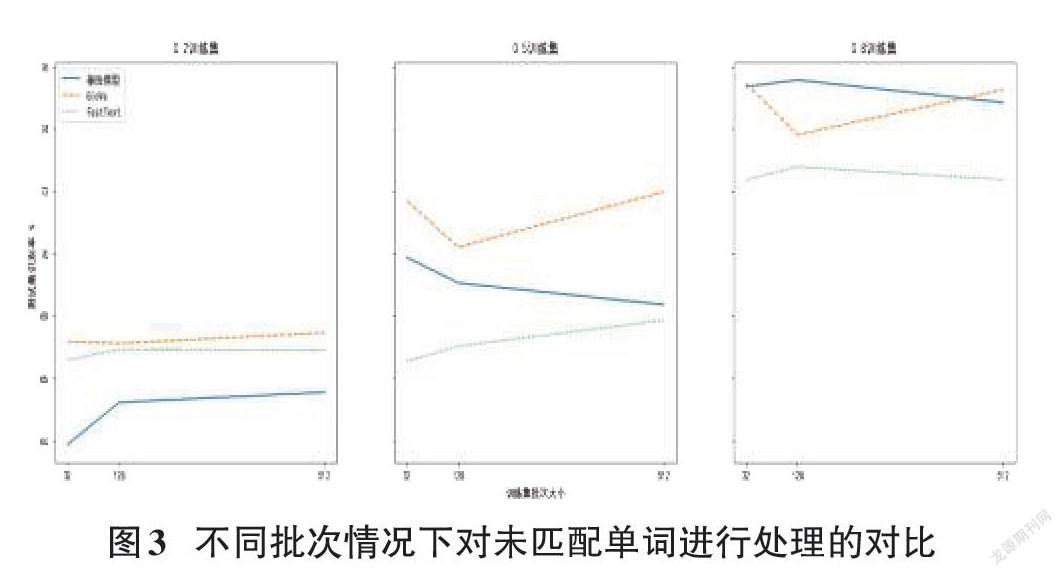
以“basware”為界,“oyj”“omx”“nordea”這三個單詞在GloVe中全部匹配而在FastText中全部未匹配。因無法獲得真實的fasttext中三個單詞所對應的詞向量,實驗將GloVe中這三個單詞所對應的詞向量值全部置零,重復前文實驗,如測試集結果下降則能說明更精確的單詞匹配度能獲得更好的識別效果。為了證明高頻單詞對全文識別的影響,實驗同樣考慮將基線模型中這三個單詞的詞向量置零。
結果證明在去掉三個單詞后,文本情緒判斷的準確率幾乎不受影響,圖3是對原實驗多次重復后的一種情況。盡管圖中數據間有較大空隙,以Keras計算波動來看可以說幾乎沒有差別。可見本例中高頻未匹配單詞并不是影響兩種預訓練嵌入層模型測試結果之差的主要原因。
4 結語
本例中,不管是基線模型還是預訓練嵌入層模型都表現出了較好的識別率,總體損失上后者相比前者更為穩健,同時使用預訓練詞向量可以更好地解決過擬合的問題,如訓練集數量較少,預訓練詞嵌入應是一種更為推薦的嵌入層方法。在比較GloVe和FastText兩種預訓練詞嵌入時,前者的單詞匹配度大于后者,測試集識別率兩者相近,意味著更高的單詞匹配度不一定帶來更好的識別結果。此外,本文選用金融新聞類數據集,FastText中本身包含有新聞類語料庫但其真實匹配度反而不如GloVe,說明在選擇預訓練詞嵌入時不一定要尋找與文本相應的類別,100萬的總詞匯量不一定比40萬的詞匯量更貼合文本數據。從另一角度來看,FastText在單詞匹配度較低的情況下可以獲得和GloVe基本一致的識別率,說明n-gram算法確實對陌生單詞有更好的識別率,如文本內容較為生僻,FastText詞嵌入或可取得更為優異的分析結果。
參考文獻:
[1] Régens. How companies can leverage sentiment analysis to improve operations and maximize their workflows[EB/OL].[2021-04-10].https://www.regens.com/en/-/how-companies-can-leverage-sentiment-analysis-to-improve-operations-and-maximize-their-workflows,2021-3-16.
[2] Levy O, Goldberg Y. Neural word embedding as implicit matrix factorization[J].Advances in neural information processing systems,2014,27:2177-2185.
[3] Kumar P S, Yadav R B, Dhavale S V. A comparison of pre-trained word embeddings for sentiment analysis using Deep Learning[C]//International Conference on Innovative Computing and Communications. Springer, Singapore, 2021: 525-537.
[4] Rezaeinia S M,Rahmani R,Ghodsi A,et al.Sentiment analysis based on improved pre-trained word embeddings[J].Expert Systems With Applications,2019,117:139-147.
[5] Malo P,Sinha A,Korhonen P,et al.Good debt or bad debt:Detecting semantic orientations in economic texts[J].Journal of the Association for Information Science and Technology,2014,65(4):782-796.
[6] Géron A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems[M]. Cambridge:O'Reilly Media,2019.
[7] Bojanowski P,Grave E,Joulin A,et al.Enriching word vectors with subword information[J].Transactions of the Association for Computational Linguistics,2017,5:135-146.
[8] Pennington J,Socher R,Manning C.Glove:global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha,Qatar.Stroudsburg,PA,USA:Association for Computational Linguistics,2014:1532-1543.
【通聯編輯:朱寶貴】
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
