基于深度學習的自然場景多方向文本檢測與識別
2021-03-07 07:57:40王明宇
電子技術與軟件工程 2021年24期
王明宇
(格拉斯哥大學 英國蘇格蘭格拉斯哥 G128QQ)
1 背景介紹
自然場景圖像的文本檢測與識別技術有助于獲取、分析和理解場景內容信息,對提高圖像檢索能力、工業自動化水平和場景理解能力具有重要意義。它可以應用于自動駕駛、車牌識別和智能機器人等場景,具有很大的實用價值和廣闊的研究前景。
與以往用于印刷文本的OCR 技術不同,自然場景中的文本檢測和識別任務更加困難。復雜的背景使得許多文本很難從背景物體中區分出來。目前的研究通常將自然場景中的文本識別分為兩個步驟:文本檢測和文本識別。即用視覺處理技術提取中文文本,用自然語言處理技術獲取文本內容。這兩個步驟密切相關,文本檢測結果的準確性直接影響到最終的文本識別結果。因此,本文開發了一個將檢測和識別這兩個步驟整合在一起的應用,以提高識別的效率。
本文的研究內容主要包括以下三個方面。
(1)結合目標檢測的知識,對SegLink 模型進行了分析和改進。利用連接組件的CNN 網絡對檢測結果進行過濾,提高檢測結果的準確性。
(2)針對自然場景文本識別的不足,設計了結合二維CTC 和注意力機制的適應性強的文本識別模型。本文詳細介紹了二維CTC的原理以及連接二維CTC 和注意力機制模型的文字識別全過程,并介紹了Encoder-Decoder 模型的詳細改進和操作,進一步提高對不規則和傾斜文本序列的識別精度。
(3)通過整合檢測和識別框架,設計并實現了一個端到端的自然場景文本檢測和識別系統,并對識別效果進行了驗證。結果表明,所提出的模型取得了良好的效果。
2 基于SegLink的文本檢測
SegLink 是一個深度神經網絡文本檢測模型,它將一個文本行視為多個文本片段的集合,這些片段可以是一個字符或文本行的任何部分。這些文本片段被連接在一起,形成一個文本行。在SegLink 的基礎上,本文提出通過使用CNN 網絡對連接部件進行進一步過濾,以提高檢測結果的準確性。如圖1所示。
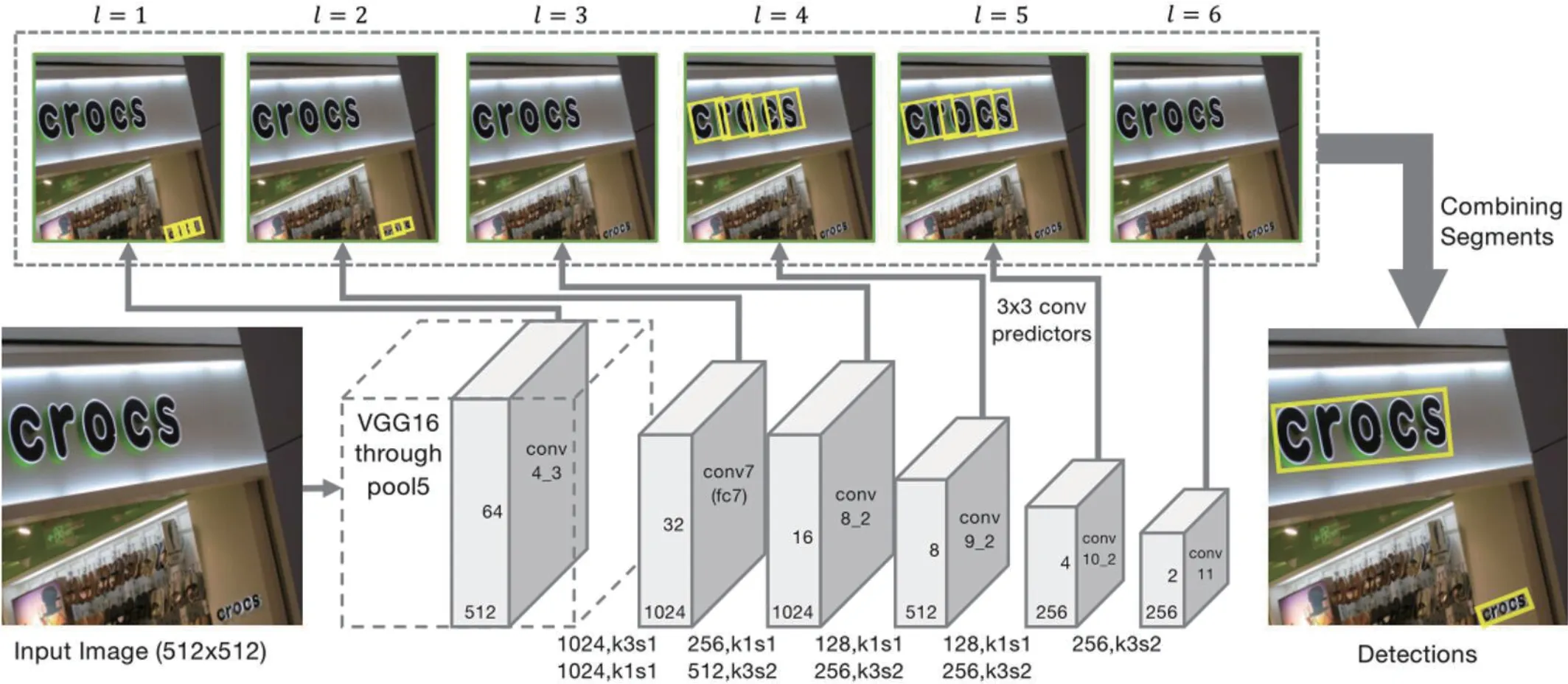
圖1:SegLink 的網絡結構
SegLink 文本檢測網絡使用一個前饋CNN 來檢測文本。給定尺寸為W1×H1 的圖像I,該模型輸出固定數量的文本片段和連接,根據置信度對其進行過濾,把過濾后的連接作為邊,構造為單詞邊界框。
該網絡使用vGG16 作為特征提取網絡,從圖像中提取特征,其中vGG16 中的全連接層(FC6,FC7)被卷積層(conv6,conv7)取代。受SSD 網絡的啟發,SegLink 使用3*3 的卷積層為每層的特征圖生成預測內容,圍繞方框的文本片段為傾斜方框,用S=(xs,ys,ws,hs,θs)表示。每層卷積預測器產生7 個通道的預測內容,其中兩個通道分別代表默認方框為文字/大寫的概率,并進行softw=Max 歸一化,得到文字置信度。剩下的5 個通道代表默認框的幾何偏移內容。特征圖中某一位置的坐標為(x,y),預測內容中的五個通道的內容(ΔxS,Δys,ΔwS,Δhs,Δθs)用來表示該位置的文本片段。文本片段幾何信息的位置是用以下公式確定的。


常數al控制輸出文本片段的大小,它根據第L 層接受域的大小決定。
2.1 層內鏈路
將一對相鄰的文本片段連接起來,表示它們屬于同一個詞,如圖2所示。文本片段之間的連接也是由卷積預測器預測的。每個鏈接有兩個分數,一個是正分數,另一個是負分數。正分用來表示這兩個片段是否屬于同一個詞,應該被連接起來;負分表示它們是否是獨立的詞,應該被斷開。每個片段的鏈接是一個8×2=16 維的向量。這兩個通道的值將進一步被softmax 規范化,以獲得連接的置信度。
如圖2 部所示,黃色方框的鄰居是兩個藍色方框,它們之間有一條連接線(綠線),表明它們屬于同一個詞。

圖2:層內鏈路和跨層鏈路
鄰居的歸一化定義為公式(6)。

2.2 跨層鏈路
在這個網絡中,同一個詞可能在不同的層被檢測到,每個卷積層在一定的尺度范圍內智能處理詞。為了解決重復檢測的冗余問題,引入跨層連接。跨層連接可以將在兩個特征層檢測到的具有關聯性的文本片段連接起來。該公式定義如下。

每個文本片段都有4 個跨層連接,這是由兩層特征圖像之間的長度、寬度和倍數關系保證的。同樣,跨層連接也是由卷積預測器預測的,它輸出8 個通道的值,用于預測當前文本片段和4 個跨層連接段之間的連接關系。對每2 個通道進行Softmax 歸一化,以產生置信度分數。
跨層連接允許連接并合并不同大小的文本片段。與傳統的非最大抑制算法相比,跨層連接提供了一種可訓練的冗余連接方式。
圖3 展示了卷積預測器的輸出通道,它由一個卷積層和一個Softmax 層實現。

圖3:卷積預測器的輸出通道
2.3 結合Segments和Links
如圖4所示,測試網絡最終會產生一系列的文本片段和鏈接,按照置信度進行排序和過濾,α 和β 分別代表片段和鏈接的閾值(通過網格搜索發現這兩個值是最優的)。將每個片段視為節點,鏈接視為邊,建立圖模型,然后用DFS(深度優先搜索)來尋找連接成分,每個連接成分就是一個詞。然后再把輸出的詞一起融合在box 中。

圖4
算法1 實際上是一個平均化的過程。首先,計算出所有片段的平均θ,作為詞的θ。然后,以得到的θ 為給定條件,找到最有可能通過每段的線(線段)。以線段的中點作為Word 的中心點(x,y)。用所有線段的平均高度作為字的高度。
2.4 Char-CNN
SegLink 在窗口層面對圖像進行操作,但是在文本鏈接組件層面沒有特征約束。因此提取的候選文本對象不一定完全是文本,有時可能是一些具有類似整體文本特征的非文本區域。在此基礎上,我們通過對提取的文本候選區域使用基于CNN 的字符級過濾算法來改進SegLink 網絡,進一步排除非文本候選區域,從而提高圖像中文本檢測的準確性。
具體來說,首先對SegLink 提取的字級文本進行MSER 區域檢測,并將檢測到的MSER 區域的最大邊界框作為字符的邊界框,從而將字分割為字符級的候選文本。然后,將分割好的候選字統一調整大小,作為CNN 分類器的輸入,并進行評分,得到每個候選字的字符文本置信度。在此之后,對同一單詞分割得到的所有候選字符使用非最大抑制算法,得到一個單詞中所有字符的平均得分,作為該單詞的文本置信度,并將置信度低于一個閾值的詞過濾掉。如圖5所示。

圖5:Char-CNN 結構
3 基于連接二維CTC和注意力機制的文本識別
與A4 紙上的印刷文字不同,自然場景中的文字多為空間排列不規則、噪聲較大的文字。雖然CRNN+CTC 的收斂速度較快,但CRNN 存在解碼信息缺失的問題,并且CTC 模型要求的特征序列高度為限制了識別能力。基于Attention 機制的sequence to sequence模型收斂速度慢,但準確率比CRNN+CTC 模型高,但它也有缺陷。基于注意力機制的序列到序列模型在一定程度上對自然場景中的英語有較高的識別率。但對自然場景中的中文的識別效果并不理想。為了解決上述問題,本文提出了一種基于連接二維CTC 的序列和注意力機制的文字識別模型。
3.1 2D CTC
二維CTC 消除了背景噪音的影響,可以自適應地關注空間信息。它還可以處理各種形式的文本實例(水平、定向和彎曲),同時給出更多的中間預測。對于二維CTC,在路徑搜索中增加了一個額外的維度:除了時間步長(預測長度)之外,還保留了高概率分布。它確保所有可能的高路徑都得到考慮,不同的路徑選擇仍可能導致相同的目標順序。
二維CTC 也需要在高度維度上進行歸一化。一個單獨的SoftMax 層產生了一個額外的形狀為H×W 的預測路徑轉換圖。概率分布和路徑轉換被用于損失計算和序列解碼。二維CTC 繼承了CTC 的對齊概念。與一維CTC 相比,二維CTC 實質上是將高度轉化為大小,從而緩解了信息丟失或連接的問題,為CTC 解碼提供了更多的路徑。
3.2 連接二維CTC和注意力序列機制的模型
基于二維CTC和注意力機制的文本序列識別框架分為兩部分。編碼部分由一個卷積神經網絡和一個多層雙向LSTM 組成,負責將圖像轉換為特征序列。解碼部分由一個結合了二維CTC 和注意力機制的序列-順序模型組成。在基于注意力機制的序列-順序解碼中,所有的特征都以語義C 為中心,并為每個特征計算出注意力權重。解碼過程的計算方法如下。

其中h I 和j 代表第i 個關系中JTH h 的編碼特征向量,代表由平滑歸一化函數處理的權重參數,e代表注意力的權重,g代表h I,j和的線性變換。最后,生成下一個狀態s 和下一個標簽y。

在這一點上,注意力損失函數的計算公式為:
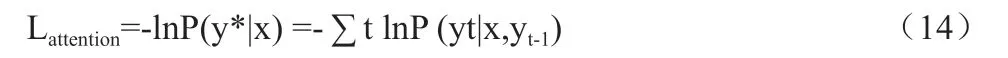
其中y*t-1 是第一個t-1 標簽序列。
該模型的思路是在多任務學習框架下,用二維CTC 目標函數作為輔助任務來訓練注意力模型編碼器。與注意力模型不同的是,CTC 的前向-后向算法可以實現語音和標簽序列的單調對齊,而且CTC 要求的特征序列高度為1,不能考慮空間信息,而二維CTC可以考慮文本的空間信息。模型的損失函數的計算方法是:
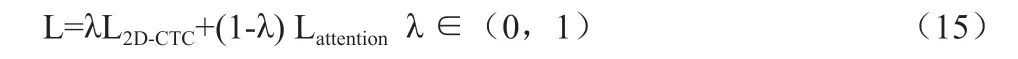
4 自然場景文本檢測與識別系統
該系統使用Python 語言開發,實現了基于SegLink 改進和二維CTC 連接關注機制的端到端文本檢測和識別。
自然場景圖像文本識別模型的處理流程包括文本檢測、文本處理和文本識別。系統檢測到圖像輸入后,首先檢測文字區域并畫出文字框,然后切出文字區域進行水平統一處理,并將其轉換成灰度圖像。然后,將校正后的文本圖像輸入到文本識別網絡模型中進行識別,最后輸出識別結果。
該系統的主界面如圖6所示。系統的各個功能模塊都可以在主頁上直觀地找到。通過網絡交互,系統簡單明了。通過系統的界面,直接選擇要上傳的圖片。系統的文字識別功能模塊如圖7所示,對文字區域進行檢測和識別,并在右側輸出結果。圖6 是沒有上傳圖像時的系統主界面。圖7 展示了識別結果的例子。
圖6:系統主界面
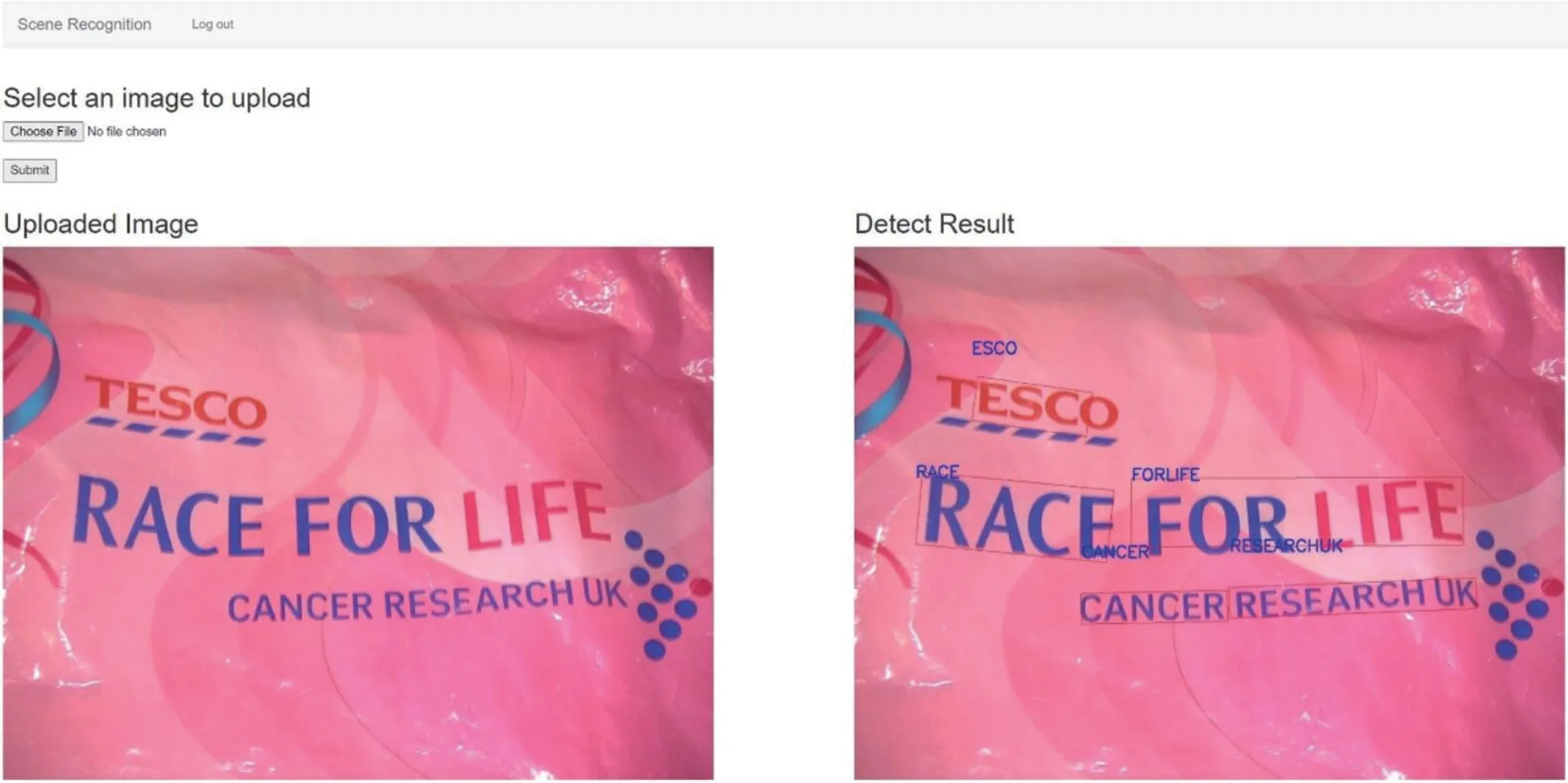
圖7:識別結果界面
5 結論
在文字檢測方面,通過增加CNN 網絡的連接部件的濾波器,改進了SegLink 模型,提高了檢測結果的準確性。在文字識別方面,針對自然場景文字識別的不足,設計了一個結合二維注意力機制和CTC 的文字識別模型,具有較強的適應性,進一步提高了不規則和傾斜文字的識別精度。結合上述兩項相關工作,將該框架整合并擴展為一個端到端的識別系統。該系統的實現簡單高效,在水平和多方向的文本數據集上有很好的表現。目前的文本檢測和識別只能達到識別和感知。對于場景文本識別,基于深度學習的文本檢測和識別的最終目標是排版、存儲和分析圖像文本內容。由于本人在自然場景文本檢測和識別的技術領域的研究和學習還不夠深入,有很多需要改進的地方,因此提出了兩點建議供大家進一步參考。
(1)本文提出了一個統一的檢測和識別系統,對傾斜和彎曲的文本取得了良好的效果。但是,自然場景中仍然存在較大的噪聲和相對變形的形狀。今后將對文字彎曲變形的檢測進行改進。
(2)雖然本文提出的端到端識別模型具有良好的效果,但由于計算機配置有限,識別時間較長,今后將進一步開展工作,縮短檢測和識別時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
