基于改進目標檢測算法的吸煙行為檢測
2021-03-07 07:57:46趙冬
電子技術與軟件工程 2021年24期
趙冬
(國華投資有限公司河北分公司 河北省張家口市 075000)
1 引言
吸煙嚴重危害著全世界人民的生命財產安全,吸煙引發的火災和癌癥不計其數[1]。近年來,人工智能和深度學習發展迅速。計算機視覺也已應用于交通安全、危險物品檢測和公共環境安全領域[2]。傳統的煙霧報警、人工巡檢等吸煙行為檢測方式,不僅耗費人力財力,而且效果不佳。本文提出了一種基于YOLOv5s 算法的檢測方法,以實現對吸煙行為更好的實時檢測。由于YOLOv5s 算法對小目標檢測并不友好,所以本文提出一種改進的YOLOv5s 算法,通過K-means算法和增加檢測層的方法進行吸煙行為檢測。
本文組織結構如下:第二節詳細描述了YOLOv5s 目標檢測原理;第三節介紹了改進的YOLOv5s+檢測方法;第四節給出了本文試驗結果分析;第五部分對全文進行總結。
2 YOLOV5S目標檢測原理
YOLOv5s 是YOLOv5 系列中最小的網絡。如圖1所示,YOLOv5s 由四部分組成:輸入部分、骨干部分、頭部部分和檢測部分。
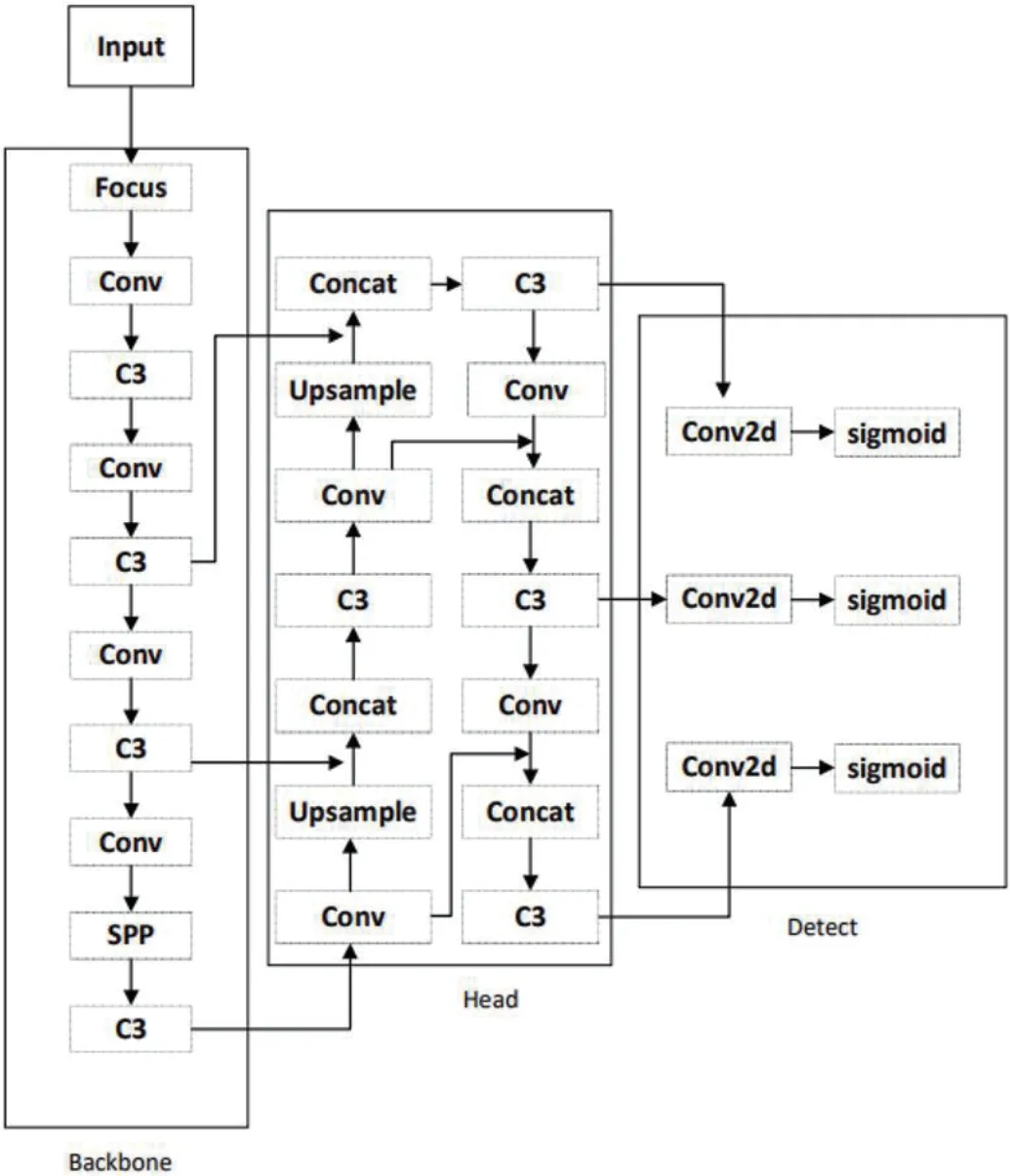
圖1:YOLOv5s 網絡結構
2.1 輸入部分
Input 部分主要包括數據增強、自適應錨框計算、自適應圖像縮放。初始錨點是先驗學習的基礎,針對數據集它們是[10,13,16,30, 33,23][30,61, 62,45, 59,119][116,90, 156,198, 373,326]。設置合適的錨點會得到更高的IOU(Intersection over Union,是一種測量在特定數據集中檢測相應物體準確度的一個標準),有助于提高模型的準確率。在訓練過程中,先驗學習模塊可以更好地學習適應不同待測物體的形狀信息。
2.2 骨干部分
在骨干部分,YOLOv5s 使用了CSPNet(Cross Stage Partial Networks),主要用于解決較大卷積層中梯度重復的問題。基于Densnet 的思想,包括Partial Dense Block 和Partial Transition Block。Partial Dense Block 主要用于添加梯度路徑,平衡每一層的計算,減少內存消耗。Partial Transition Block 主要用于增加不同梯度層的區分度。此外,YOLOv5 系列還加入了其他YOLO 版本所沒有的Focus 結構[3-5]。
2.3 頭部部分
頭部部分位于主干部分和檢測部分之間,用于提取融合特征。如圖2所示,頭部使用特征金字塔網絡(FPN)和感知對抗網絡(PAN)結構來實現上采樣和下采樣過程。FPN 是自頂向下的,它使用上采樣的方法來傳遞和融合信息,得到預測的特征圖。PAN 使用自上而下的特征金字塔。FPN 主要用于自頂向下的特征卷積,使用插值在較高的特征層上進行2 次從19*19 到38*38 的上采樣,同時特征通過1x1 卷積進行水平連接,并改變底層通道數在較低的要素圖層上。與原始圖像金字塔相比,特征金字塔可以減少推理時間,減少內存占用,并且不需要處理不同分辨率的圖像。
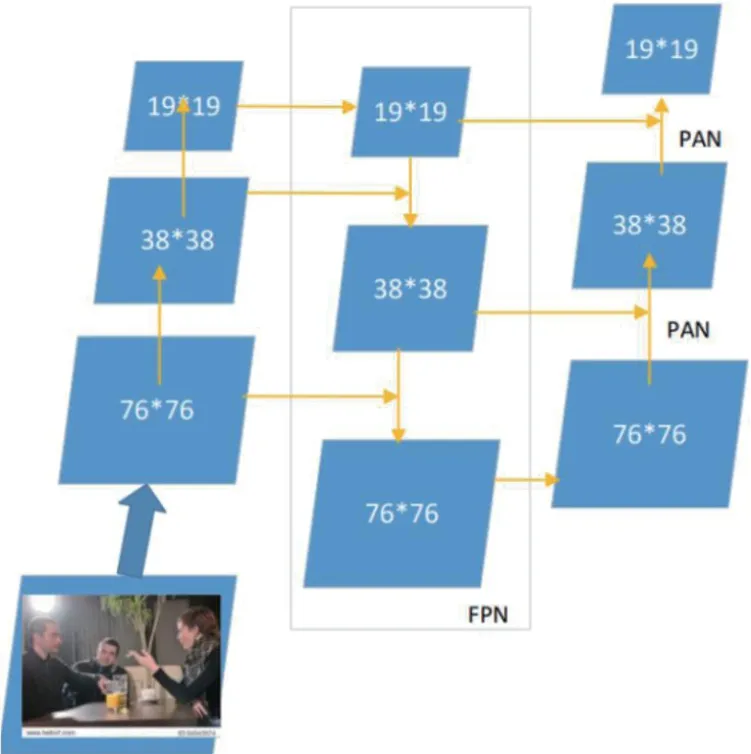
圖2:頭部部分
2.4 檢測部分
檢測部分主要包括Bounding box 的損失函數和非極大值抑制(NMS)。損失函數為 GIOU_Loss[6]。GIOU_Loss 的公式是(1)。GIOU_Loss 有效解決了預測幀與真實幀不相交時,預測幀與真實幀的距離信息丟失,IOU 為零的問題。
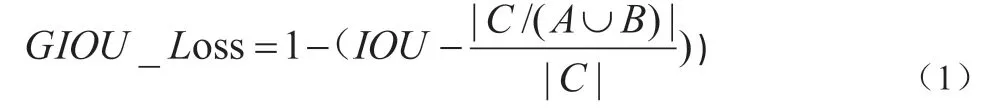
3 改進的YOLOV5S+檢測模型
針對YOLOv5s 網絡模型,增加了一個基于YOLOv5s 算法的小目標檢測層。針對香煙的小目標,首先基于K-means算法得到合適的anchors。K-means算法的輸入為x 個樣本的數據樣本集。樣本集中的每個樣本都是平面上的一個點,相似特征的樣本被算法聚類為一個類別。該算法首先隨機選擇k 個中心點,計算該點與每個點最接近所有中心點的中心點的距離,將該點歸類為該中心點所代表的簇Ci。經過一次迭代,得到簇類。對于每個聚類,然后重新計算每個點的中心點的距離,并重新找到離自己最近的中心點,直到前兩次迭代中沒有聚類變化,然后將樣本分配到相同的中心歸為一類。最后得到k 類。使用這種方法,本文可以將6565 個樣本聚類為12個類,并將這12 個類作為YOLOv5s 的初始錨點值。
4 試驗結果分析
實驗環境使用Ubuntu16.04 操作系統,選擇Pytorch 架構,使用GeForce GTX 2080Ti 顯卡進行計算。具體實驗配置見表1。

表1:實驗環境配置
本文通過網絡爬蟲、視頻截圖等方式獲取了6565 張圖片,如表2所示,訓練集5664 張,驗證集701 張,測試集200 張。

表2:實驗數據集
在網絡模型訓練期間,epochs 為 300,batch-size 為32,初始學習率(Ir0)為0.01。True Positives(TP)、False Positives(FP)、False Negatives(FN)、True Negatives(TN),判斷訓練結果的參數指標是Accurancy、Precision、Recall、F1 score、AP。F1 分數定義為準確率和召回率的調和平均值。F1 是算術平均值除以幾何平均值。F1的公式為(2)。

精度是所有TP、TN、FP 和FN 的TP 和TN 比例。Accuracy的公式為(3)。

Precision 是所有TP 和FP 的TP 比例。Precision 的公式為(4)。

Recall 是所有TP 和FN 的TP 比例。Recall 的公式是(5)。

AP 衡量每個類別中訓練模型的質量。計算方法是準確度之和除以負數。AP 的公式為(6)。

實驗結果Precision 的值為0.88,Recall 的值為0.87。改進后的算法AP 提高了6.7%。 改進后的YOLOv5s+算法性能更好,可以在200 個測試集中正確識別目標。
如圖3所示,YOLOv5s+算法訓練完成后,得到一個權重模型,可以處理視頻或圖片,可以實時標記香煙目標。

圖3:YOLOv5s+測試結果
5 結論
在本文中,為了更好地檢測公共場所的吸煙行為,提出了基于K-means算法和小目標檢查層的YOLOv5s+算法。在這個YOLOv5s+算法中,制作了數據集。Detect部分增加了小目標檢測層,訓練后的模型對香煙小目標的識別準確率高達92.3%。該算法可以實時處理攝像頭反饋的數據,并將處理結果輸出給監管者。所以主管可以更好地進行人力洗牌,大大節省人力資源。改進后的算法具有很好的應用前景,針對其他的識別場景也同樣適用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
