基于大數據的零售戶價值挖掘實證分析
2021-03-07 03:12:58侯毓
經營者 2021年23期
侯毓
(湖北中煙工業有限責任公司信息中心,湖北 武漢 430040)
一、引言
2020年4月9日,中共中央、國務院發布《關于構建更加完善的要素市場化配置體制機制的意見》,正式將數據納入生產要素范圍,數據資源的重要性已不言而喻。對于煙草行業而言,目前中國煙民大概3.5億人,全國注冊零售戶1 286萬戶。2019年,全年行業訂單2.28億份,交易明細記錄73.59億條。煙草行業有如此大體量數據,應積極探索識別不同零售戶的潛在價值以實現卷煙資源的合理配置以及營銷物資的合理投放。
1956年,Wendell R. Smith提 出 市 場 細 分理論,針對不同客戶群體實行差異化營銷[1]。通過對4 998戶柳州市轄區持證卷煙零售戶開展滿意度調查,梁娟等研究發現零售戶對客戶服務和市場管理的滿意度較高,但對盈利情況、貨源供應政策、月度商定總量、卷煙品質的豐富性、零售戶分檔公平性等的滿意度較低[2]。煙草公司現行的營銷策略是根據“購進數量”“購進金額”“購進品規數”三個維度,通過權重附分值的方法進行月度滾動式分檔管理。由于貨源投放依賴分檔結果,缺乏靈活性,面對市場環境的變化難以快速調整投放策略,貨源投放不精準。面對卷煙消費的升級不能及時響應,導致零售戶所處檔位與其實際銷售能力不匹配,許多零售戶對現有的檔位劃分結果不滿意[3]。
各學者試圖利用數據挖掘技術尋找更為科學的方法,如姚龍飛基于RFM模型構建用戶畫像標簽,通過云模型聚類算法將湖南省某地市零售戶劃分為重要保留客戶、重要發展客戶、重要挽留客戶、低價值客戶四大類[4];周旭以“客戶為中心”,基于Hadoop大數據平臺,利用FCM模糊聚類算法構建客戶價值模型,將全國零售戶劃分為五大類[5];鄧基剛等基于K-means聚類將12 357個客戶劃分為VIP客戶、重要客戶、普通客戶、小客戶四大類[6]。
文章以RFM模型和K-means算法為理論基礎,從實際業務出發,將方法論與業務實踐深度融合,以融合后的實際結果為依據劃分零售戶類別,并進行相應的價值挖掘,相比傳統的理論導向更有實踐意義。
二、相關模型
(一)RFM模型
RFM模型由美國數據庫營銷研究所Arthur Hughes提出,是一種被廣泛應用的經典的精細化運營方法,是衡量客戶當前價值和潛在價值的重要工具和手段。該模型由觀察期內客戶最近一次消費時間到當前時間的間隔R(Recency)、消費頻次F(Frequency)、消費總金額M(Monetary)三項指標構成。
(二)K-means聚類
聚類分析是數據挖掘中研究分類問題的一種重要的統計分析方法,屬于機器學習中的無監督學習。K-means聚類是聚類算法中的一種常用算法,也是數據挖掘中的十大經典算法之一,其核心思想是通過計算樣本點至類中心的距離劃分k個類別,找出使組內距離平方和總和D最小的類別進行劃分,即求解最優化問題[7]。
三、數據收集與處理
(一)數據收集
就煙草行業某省級工業公司而言,對于行業零售戶訂單數據,傳統數據庫存儲數據量5~6T,日均處理數據量5億~6億條,處理時間少則1小時、多則8小時,甚至出現崩潰狀態。利用內存計算、高效索引、執行優化和高度容錯的大數據技術,可以滿足海量訂單數據對數據庫存儲和處理的需求,處理時間僅需要10分鐘。將數據庫中的訂單主表與零售戶維度表進行左連接,抽取湖北省某地市全年零售戶所有卷煙的訂單數據,共計零售戶38 567戶、訂單162.99萬份,涉及的字段如表1所示。

表1 零售戶相關分析字段
數據收集完成后,需要進行數據質量檢查。研究范圍內的數據未出現數據缺失、格式不統一、數據不規范、重復記錄等問題,原因在于行業訂單下行數據進入大數據平臺時,平臺會開展相關數據清洗工作,清洗后的數據質量相對較高。
(二)數據處理
1.構建RFM指標
R:先找出某年1月1日至12月31日,各零售戶的最近一次訂購日期,然后以年度商業公司準予的最后一次訂購日期12月31日為基準,計算各零售戶最近一次訂購日期到12月31日的間隔天數,即各零售戶的R值,單位:天。
F:一次訂單僅對應一個編號,故訂單編號唯一。計算1月1日至12月31日,各零售戶不同訂單編號總數,即各零售戶的F值,單位:次。
M:1月1日至12月31日,各零售戶訂購金額總和,即各零售戶的M值,單位:元。
利用R語言構建RFM模型,樣本量共計38 567個。
2.剔除異常值
根據卷煙管控的特殊性質,最近一次訂購間隔和年度訂購次數一般不會出現極端情況,而訂購總金額可能會因為不同零售戶的不同經營狀況出現極端差異,須對M值進行異常值檢查。通過R語言繪制的箱形圖,一個樣本M值存在異常。經查實,該零售戶是一家大型便利店,推測該零售戶可能是特殊客戶,故研究不將該零售戶納入樣本范圍,剔除后樣本量為35 863個。
3.數據標準化
為消除不同量綱對后續聚類分析產生的影響,需要對R、F、M進行標準化。文章采用Z-Score方法進行數據標準化,具體換算過程:
利用R語言中的scale函數實現Z-Score標準化。
四、基于K-means的聚類建模
(一)類別k的選擇
K-means算法需要事先確定k值,利用R語言繪制組內距離平方和隨k值變化的折線圖,可以看到k的最優值為5,也就是說整個樣本分為5類是最合適的。
(二)聚類建模
利用R語言進行K-means聚類建模,得到不同角度的三維聚類效果如表2所示。可以看到,整體劃分結果較為理想。
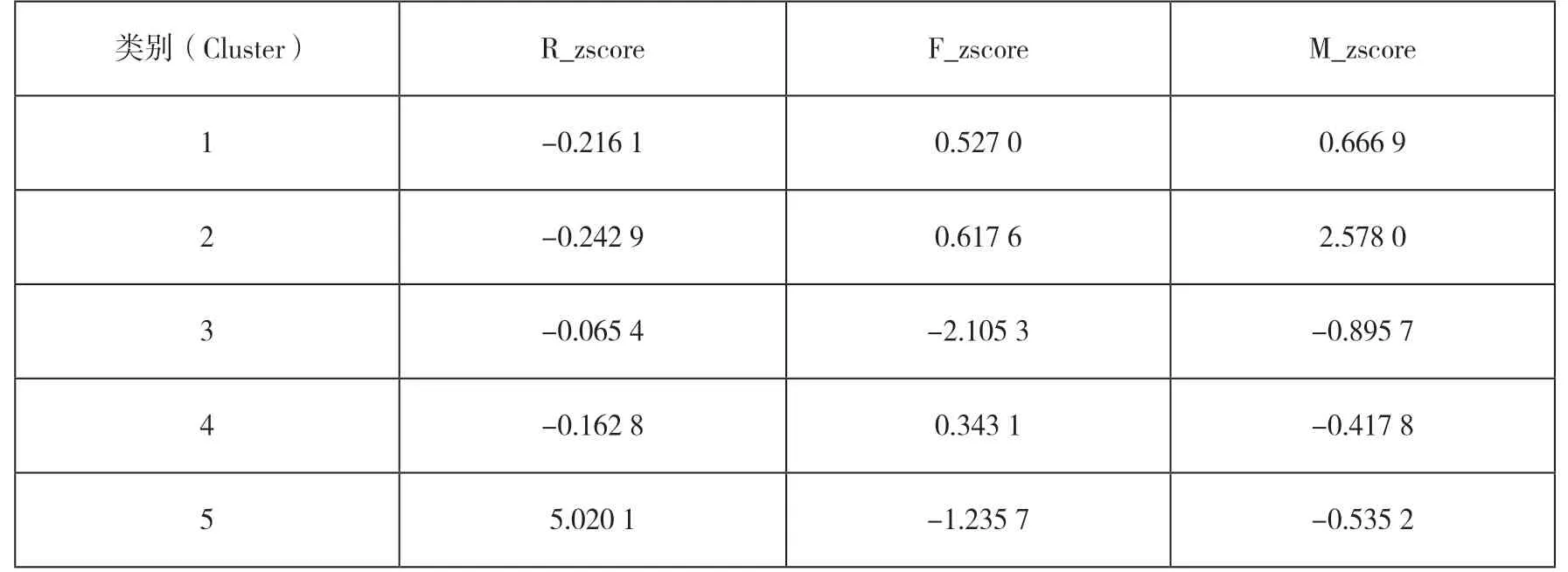
表2 聚類模型的各類中心值
五、應用分析
(一)類別定位
映射到原數據的各類中心值如表3所示,結合實際業務對5類零售戶進行精準定位。根據某年該地市實際訂煙情況看,全年訂購周期共計53期,下面針對表3進行定位分析。
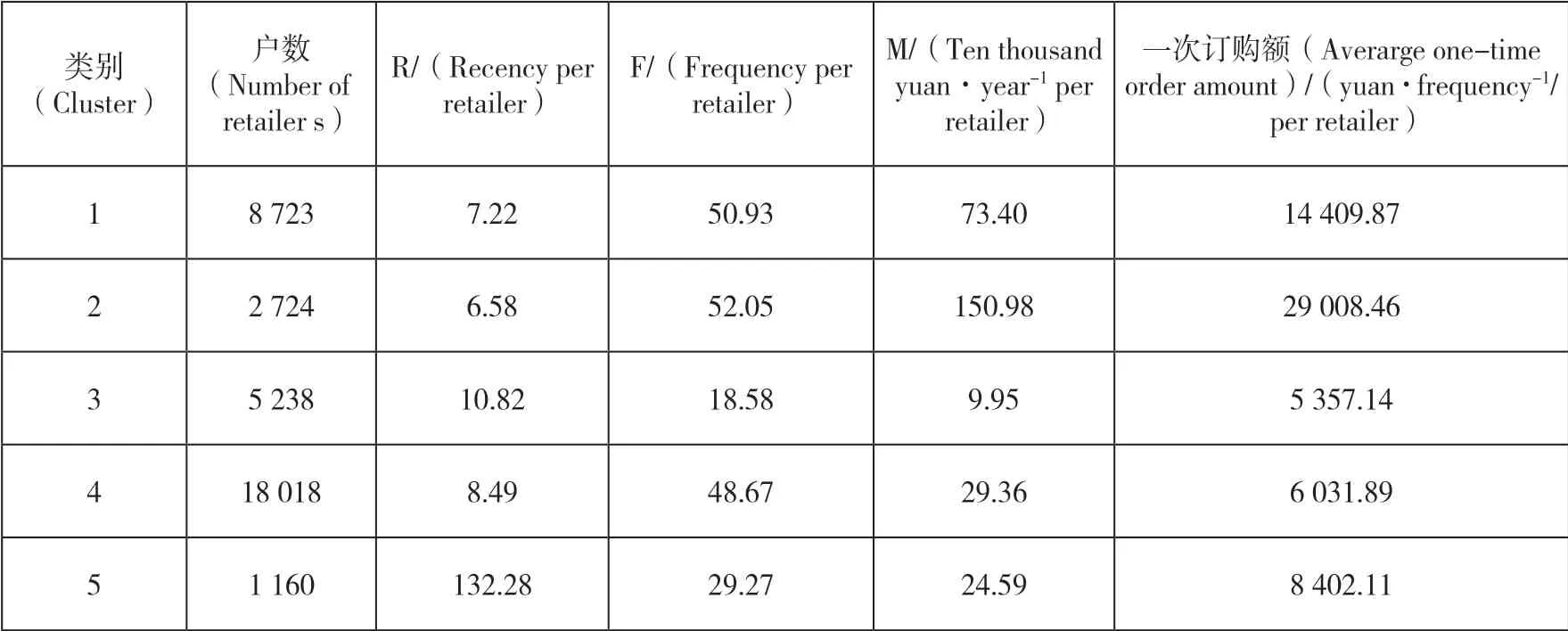
表3 映射到原數據的各類中心信息表
第1類:最近一次訂購時間平均間隔為7.22天,平均每戶訂購50.93次,屬于高頻戶;平均每戶年訂購金額次于第3類,優于其他類。該類零售戶經營狀況不錯,通過一定的營銷手段或激勵措施,有望進一步增強銷售能力,故文章將該類定位為潛力客戶。
第2類:最近一次訂購時間平均間隔為6.58天,說明最近一次訂購周期內該類零售戶正常訂煙;平均每戶訂購52.05次,說明該類零售戶在整年每個訂煙周期內均未缺席;平均每戶年訂購金額達到百萬以上,是所有類別中訂購金額最高的一類。該類零售戶經營狀況最好,銷售能力最強,故文章將該類定位為優質客戶。
第4類:最近一次訂購時間平均間隔為8.49天,與其他4類相比,屬于中等水平,故文章將該類定位為一般客戶。
第5類:最近一次訂購時間平均間隔達到132.28天,說明該類零售戶有4個多月沒有訂購行為,相對應的平均每戶訂購次數較少。該類零售戶可能對卷煙市場經營形勢不看好,處于流失狀態,故文章將該類定位為流失客戶。
(二)供需情況
商業公司對每一規格投放的數量有嚴格限制。零售戶根據需求下單時,實際能夠訂購的數量最多只能與商業公司提供的上限一致,不一定能滿足需求,用需求滿足率=訂購量/需求量來衡量供需情況。各類客戶需求滿足情況如表4所示,從中可以看出,整體需求滿足率在60%上下,供遠小于求,市場供需不平衡較為明顯,但從“吸煙有害健康”的角度來說,供給側嚴格控量符合國家行業稍緊平衡和垂直管控政策。
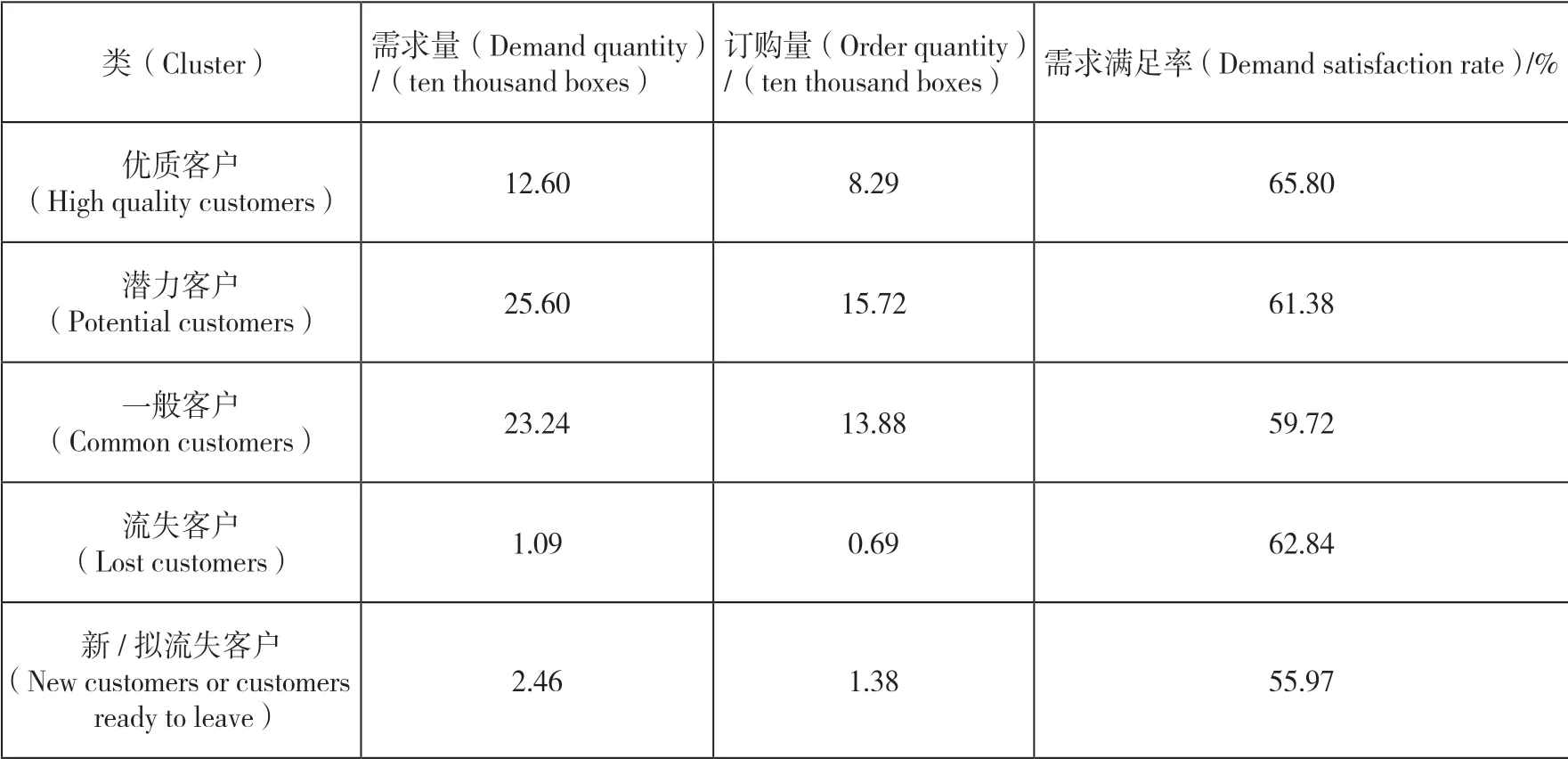
表4 各類客戶需求滿足情況
(三)分布差異
1.不同業態下的分布差異
不同業態類型下的客戶分布存在差異,如表5所示。

表5 不同業態類型下的客戶分布情況
根據零售戶店鋪的經營范圍,業態類型分為食雜店、便利店、煙酒店、商場、娛樂服務及其他6種。縱向看,食雜店在所有業態類型中占到了3/4以上,說明該地市卷煙銷售大部分集中在食雜店,這是符合實際情況的,食雜店俗稱“小賣部”,隨處可見。從百分比角度看,便利店、食雜店中的各類客戶占比情況一致——一般客戶>潛力客戶>新/擬流失客戶>優質客戶>流失客戶;商場的一般客戶、潛力客戶居多,優質客戶尚可;娛樂服務店中一般客戶、新/擬流失客戶比重較高,流失客戶在所有業態類型中比率最高,說明娛樂服務店的客戶在所有業態中最易流失;其他業態中一般客戶居多,也是6大業態類型里一般客戶比重最大的一類。
2.不同規模下的客戶分布
不同規模,客戶分布也不同,如表6所示。
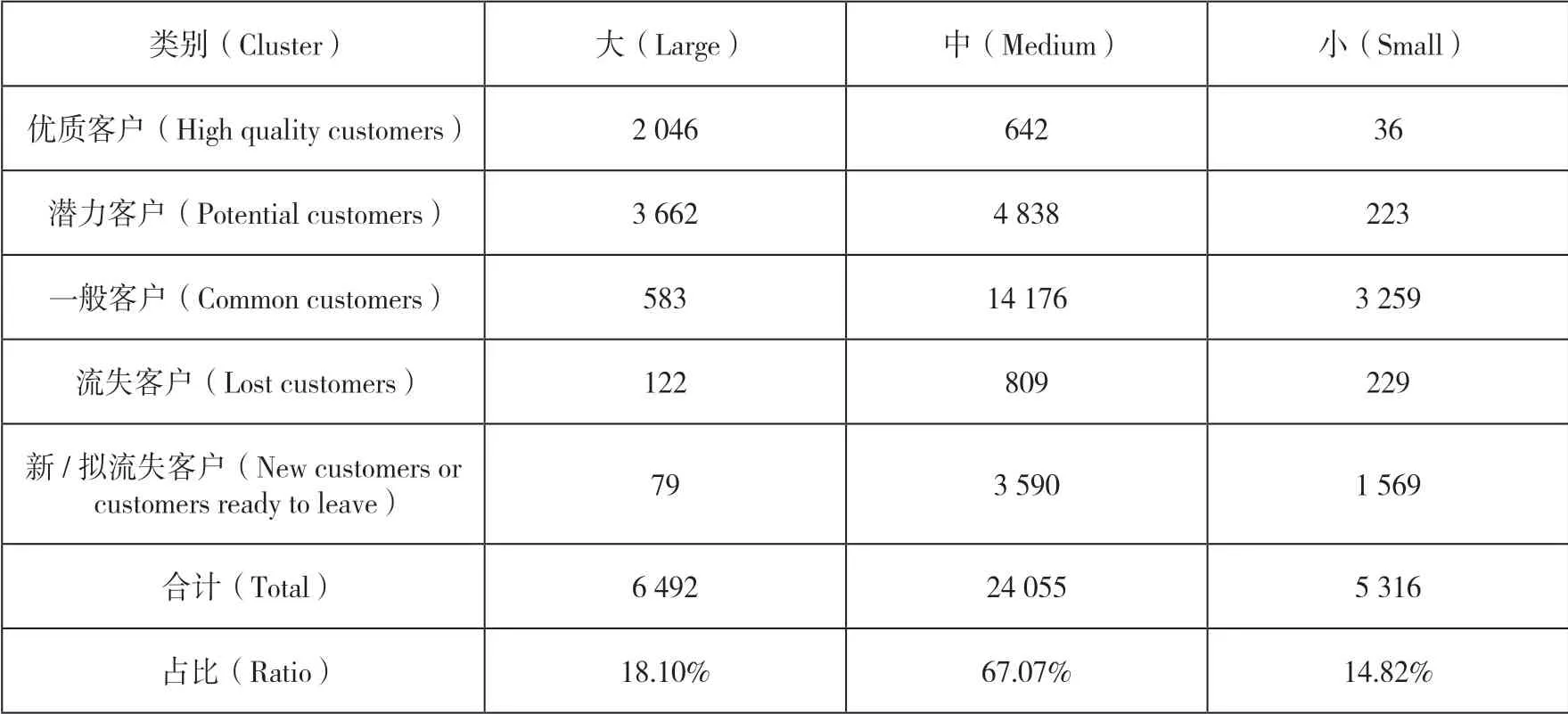
表6 不同規模的客戶分布情況
零售戶經營規模分大、中、小3種類型。縱向看,該地市零售戶67%以上都是中型,大型和小型各占一角。橫向看,優質客戶集中于大型,中型稍多,可謂是小型零售戶里的鳳毛麟角;潛力客戶大多存在于大、中型,中型比大型多;一般客戶、流失客戶、新/擬流失客戶均以中型居多,小型其次,大型最少。大型規模的潛力客戶最多,占一半以上,優質客戶排名第二,新/擬流失客戶、流失客戶相較中、小型零售戶最少;中型規模的客戶排名是一般客戶第一、潛力客戶第二、新/擬流失客戶第三、流失客戶第四、優質客戶第五;小型規模的零售戶也以一般客戶居多,因投資成本低,新/擬流失客戶及流失客戶比重都比大、中型高,優質客戶和潛力客戶自然就極少。
六、結語
文章依托大數據平臺,收集了湖北省某地市的零售戶38 567戶、訂單162.99萬份。經過構造RFM指標、剔除無效零售戶、剔除異常值等數據處理后,得到樣本35 863個。通過R語言實現的K-means聚類建模,將分析樣本劃分為較為理想的5大類,并結合年度該地市的實際訂煙情況,實現了5大類的精準定位,分別是優質客戶、潛力客戶、一般客戶、流失客戶、新/擬流失客戶,繼而比較貼合實際地分析了不同客戶群體的經濟價值、供需情況、分布差異(包括業態差異、規模差異),為卷煙資源的合理配置以及營銷物資的合理投放提供了一定的參考,也為后續更細粒度地數據挖掘,比如零售戶對卷煙規格的偏好分析等,奠定了良好基礎。
