物聯網數據收集中無人機路徑智能規劃
2021-03-09 08:55:22付澍楊祥月張海君陳晨喻鵬簡鑫劉敏
通信學報 2021年2期
付澍,楊祥月,張海君,陳晨,喻鵬,簡鑫,劉敏
(1.重慶大學微電子與通信工程學院,重慶 400030;2.重慶大學信息物理社會可信服務計算教育部重點實驗室,重慶 400030;3.北京科技大學計算機與通信工程學院,北京 100083;4.北京郵電大學網絡與交換技術國家重點實驗室,北京 100876)
1 引言
近年來,物聯網產業的飛速發展,極大地推動了無線傳感器網絡(WSN,wireless sensor network)技術的應用,其承載的業務數據量呈幾何式增長。WSN 中存在大量的數據需要被收集,根據收集方式的不同,可將其分為2 種類型,靜態數據收集和移動數據收集。靜態數據收集是指傳感器網絡中的節點通過自組網,將自身采集的傳感器數據經過多跳上傳到數據中心[1];移動數據收集是指在被監測環境中設置一個可移動的數據收集器進行數據收集。針對部署在地表交通困難的大規模無線傳感器網絡,無人機提供了一種有效的方式來對傳感器設備移動式地進行數據輔助收集[2]。
無人機是我國人工智能產業體系的重點培育產品。與靜態數據收集方法相比,基于無人機的移動數據收集可以顯著降低數據傳輸的能耗,減少多跳間數據路由中存在的隱藏終端及其發送沖突問題帶來的射頻干擾,并有效延長網絡的使用壽命。
無人機數據收集克服了地面數據采集的局限性,但仍然有一些關鍵的問題需要解決。具體而言,無人機數據收集包括網絡節點部署、節點定位、錨點搜索、無人機路徑規劃、網絡數據采集5 個部分[3]。無人機最致命的缺點是續航時間短[4-6],因此其能耗問題是系統穩定性的關鍵。近幾年,關于無人機在數據收集的能耗研究中,無人機路徑規劃是一個開放性的研究課題,引起學術界的廣泛關注。無人機路徑規劃是一個復雜的網絡優化問題[7],一般可分為全局路徑規劃和局部路徑規劃。
一般而言,無人機將在可用能量限制下,根據任務環境信息事先規劃一條全局最優或次優路徑,得到訪問節點的訪問順序,再通過局部路徑規劃進行實時單個節點的搜索與逼近。近年來,無人機路徑規劃已經得到了廣泛的研究。文獻[3]把無人機路徑規劃問題建模成經典的旅行商問題,并執行快速路徑規劃(FPPWR,fast path planning with rule)。文獻[8]利用馬爾可夫鏈對單個無人機從遠處傳感器收集數據的移動過程進行建模,并模擬無人機運行過程中的不規則運動。文獻[9]利用部分可觀察的馬爾可夫決策過程(POMDP,partially observable Markov decision process)對無人機路徑進行規劃。文獻[10]基于Q 學習算法對無人機的路徑和避障等問題進行學習,并采用自適應隨機探測的方法實現無人機的導航和避障。文獻[11-14]基于深度強化學習(DRL,deep reinforcement learning)實現無模型的無人機路徑規劃。除了利用機器學習方法外,研究者還提出了很多啟發式算法[15-17]來解決無人機路徑規劃問題。
定向問題[18]為節點選擇和確定所選節點之間最短哈密頓路徑的組合,可以看作背包問題和旅行商問題2 種經典問題的組合。本文將無人機數據收集過程的全局路徑規劃問題建模為定向問題。本文考慮的全局路徑規劃是指綜合考慮無人機自身的能量約束、節點收益等,在指針網絡深度學習架構下進行的路徑規劃。其中,背包問題的目標是在可用資源限制下,選擇一部分節點并使之獲得的收益最大化;旅行商問題的目標是試圖使無人機服務所選節點的旅行時間或距離最小化。
文獻[19]對定向問題最近的變化、解決方案及應用等進行了綜述。近幾年,關于求解定向問題的啟發式方法很多,例如遺傳算法[20]、動態規劃法[21]、迭代局部搜索法[22]等。
2015 年,Vinyals 等[23]在人工智能頂級會議NIPS 上提出了一個用于解決變長序列到序列的神經網絡模型——指針網絡,還驗證了該模型可以單獨使用訓練示例來學習3 個幾何問題的近似解,即尋找平面散點集的凸包、Delaunay 三角剖分算法和平面旅行商問題。指針網絡深度學習被提出后,近幾年被研究者多次引用,文獻[24]將指針網絡深度學習結合強化學習解決旅行商問題,并提出該模型也可用于解決背包問題。文獻[25]使用指針網絡模型結合強化學習技術來優化3D 裝箱序列以最大化其收益。受這些模型的啟發,本文首先將無人機全局路徑規劃建模為定向問題,接著采用指針網絡深度學習對其進行求解。
在局部路徑規劃方面,無人機將根據節點廣播參考信號強度(RSS,received signal strength)的特征[26]對其局部路徑進行規劃。文獻[27]采用Q 學習利用無人機對非法無線電臺進行定位和尋找。然而,傳統Q 學習很難解決具有大量狀態空間的模型,這導致其很難適用于大規模節點網絡中的無人機路徑規劃。本文通過深度Q 網絡(DQN,deep-Q network)學習機制對大規模的Q 表進行模擬與近似,從而極大地降低了Q 學習的計算復雜度。
綜上,本文首先將無人機的全局路徑規劃建模為定向問題并通過指針網絡深度學習求解;然后在局部路徑規劃方面,利用DQN 使無人機逼近目標節點。仿真結果表明,在無人機能耗限制下,所提方案能極大地提升物聯網中的數據收集收益。
2 系統模型及問題建立
2.1 全局路徑規劃
本文綜合考慮無人機在數據采集過程中面臨的能量約束問題和路徑規劃問題。無人機能量消耗不僅與航行時間、航行速度有關,還與所處環境中的風速、障礙物等有關[28]。文獻[29]將無人機的路由算法分類為恒定速度無人機、自適應速度無人機、懸停最大服務時間(HMS,hover with maximum service time)等。本文采用HMS 的路由方法,即無人機懸停在相應節點上方,并以最大懸停時間tmax對用戶進行數據傳輸,且假設無人機以恒定的速度v飛行。
在圖1 所示的系統模型中,無人機的起點和終點均為無人機服務站Ddepot。Ddepot可對無人機收集到的數據進行處理,并對無人機充電,需要收集數據的傳感器節點隨機分布在地圖上,可通過聚類算法對隨機分布的傳感器節點進行分簇,并得到簇的中心坐標(圖1 中黑點)[30]。關于無人機以什么樣的順序訪問這些簇才能在有限的能量約束下取得最大收益的問題,可以被建模為一個定向問題,即選取點和確定最短路徑2 種問題的結合。由于無人機數據收集存在無人機能量限制,因此不是所有的簇都會被服務。令S∈{1,2,…,k}表示簇的集合,其中k表示簇的數目。第i個簇的獎勵值為pi,簇i到j的距離為disti,j,li,j=1表示i與j之間有路徑,那么無人機全局路徑規劃問題可以表示為
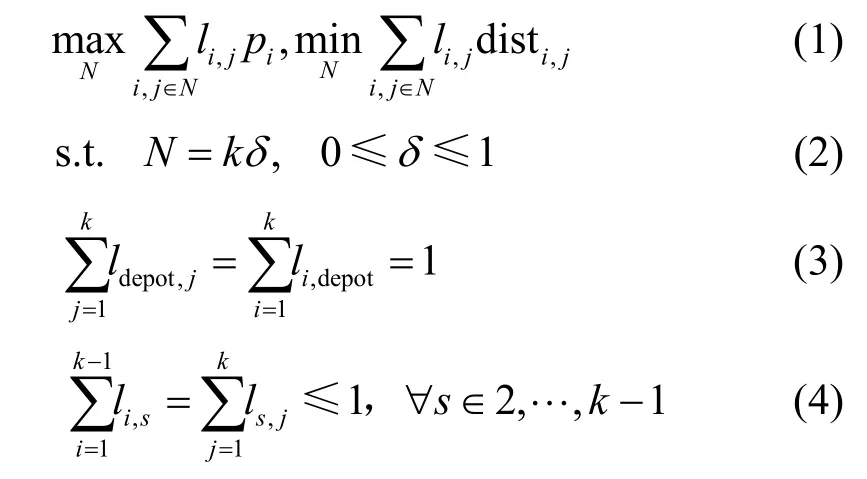
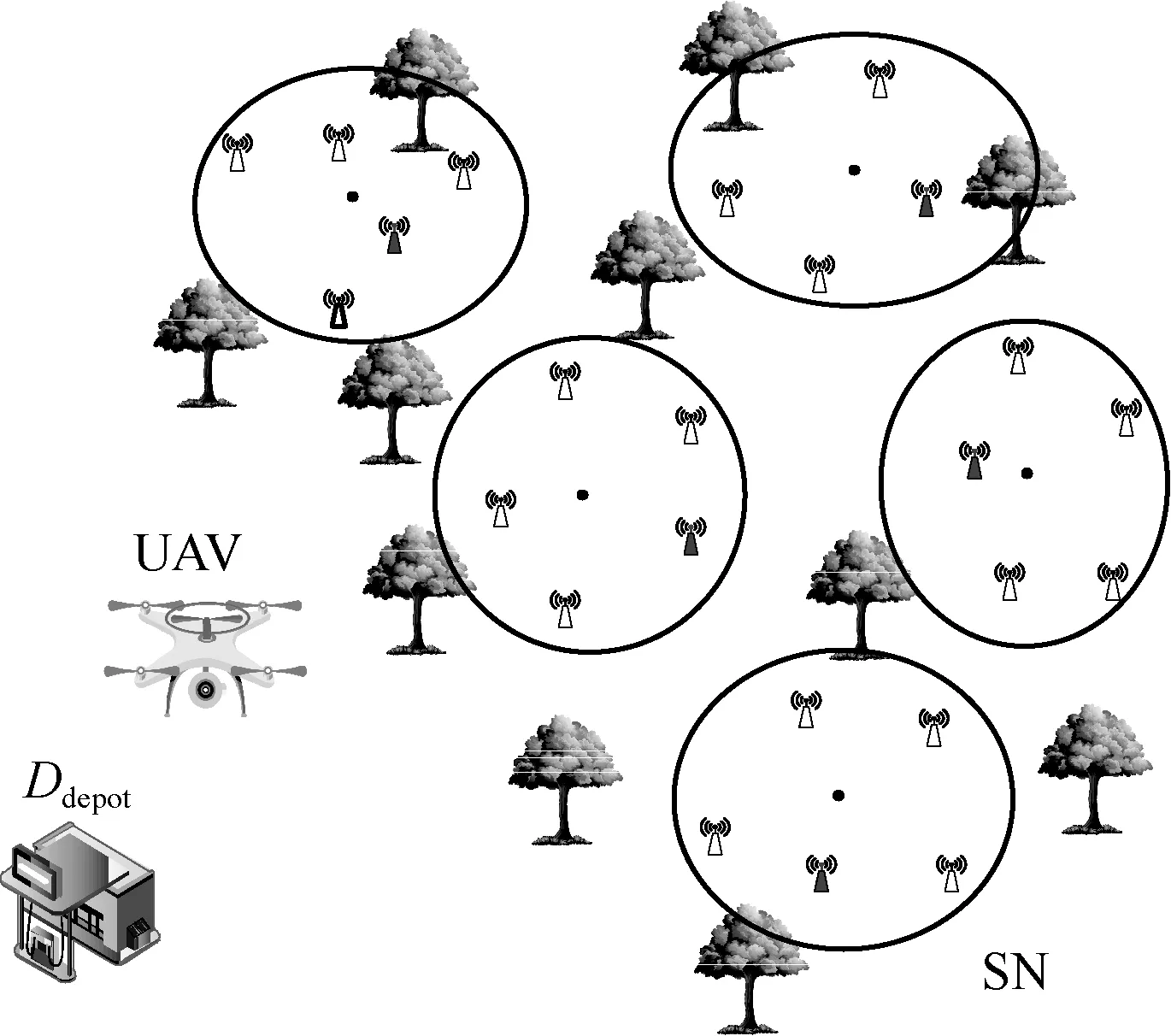
圖1 系統模型
目標方程(1)表示最大化數據收集的獎勵值,并且最小化無人機的飛行路徑;約束(2)表示無人機可服務簇的份額;約束(3)表示起點和終點均為無人機服務站Ddepot;約束(4)表示每個簇最多被服務一次。
在優化目標式(1)中,關于每個簇獎勵值的設定,如果簡單設定為簇內所有節點存儲數據的總和,則可能對稍遠的節點不公平,所以可將每個節點的獎勵值設置為
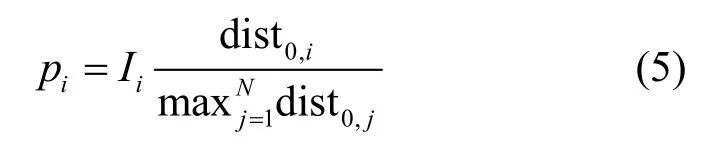
其中,Ii表示簇i內所有節點數據量總和的值(無量綱)。因此,獎勵值的設定不僅與節點到服務站的距離有關,還與數據的存儲量有關,且pi無量綱[31]。
2.2 局部路徑規劃
假設無人機對目標傳感器的位置是未知的,無人機以固定的高度飛行,只考慮二維平面的運動,目標傳感器節點的位置坐標為(x,y),無人機當前狀態的坐標為(xi,yi),無人機與目標節點之間的距離可以表示為
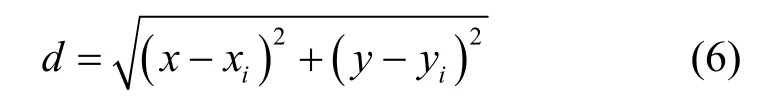
無人機通過配備天線來測量目標節點的RSS,無人機可移動方向被相等地劃分為8 個方向,具體如圖2 所示。
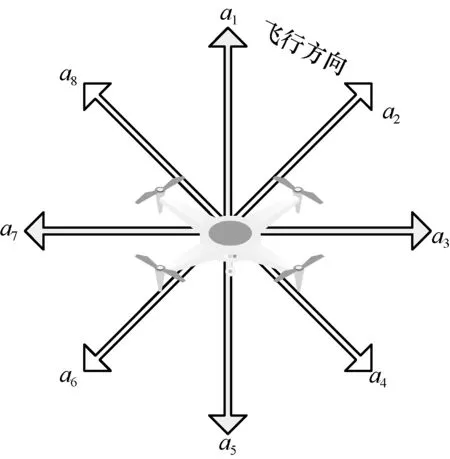
圖2 無人機移動方向
RSS 值PR可以通過以下計算式求得,它與距離d(單位為m )有關,具體為
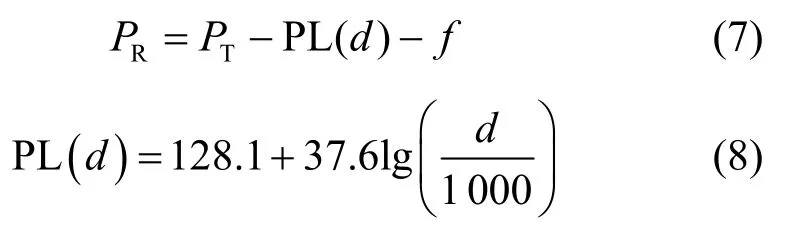
其中,PT為目標節點發射功率;PL(d)為距離d處的路徑損耗,此處的路徑損耗模型[32]采用3GPP TR 38.814,本文主要參考天線接收信號強度值,為簡化系統模型,只考慮了地對地大尺度信道衰落,后期研究無人機數據傳輸過程中將進一步同時考慮視距和非視距對傳輸性能的影響[33-35];f為捕獲信道衰落變量。
深度Q 學習[36]融合了神經網絡和Q 學習的方法,屬于強化學習的一種,當然也應該具有強化學習的基本組成部分,即智能體、環境、動作、獎勵、策略、值函數等。強化學習智能體與環境的交互過程如圖3 所示。智能體通過與環境進行交互,循環迭代產生新的狀態并結合環境給出獎勵值。
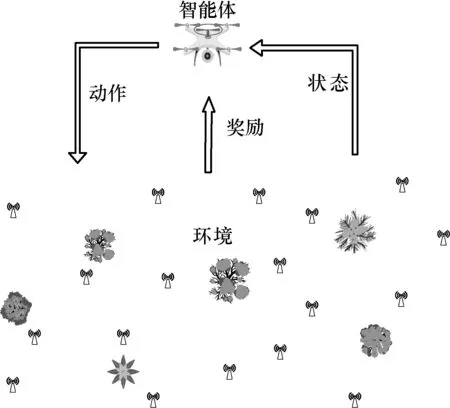
圖3 強化學習智能體與環境的交互過程
Q值函數更新式為

其中,α∈[0,1]是學習率,γ∈[0,1]是折扣因子。
無人機的狀態s取決于各個方向測量的平均RSS 值中最大的RSS 值,動作空間對應圖2 中的8個方向,即a∈{a1,a2,a3,a4,a5,a6,a7,a8}。獎勵值r(s,a)的設定為:如果當前位置各個方向測量的平均RSS 值中的最大值減去上一位置的各個方向測量的平均RSS 值中的最大值為正,則給一個正的獎勵值,該獎勵值設為固定值;如果為負,則給一個負的獎勵值。如果無人機達到終止條件,則給其較大獎勵值,本文中獎勵值設定為

無人機的終止條件為當距離d<7.0 時,目標節點定位成功。深度Q 學習的原理框架如圖4 所示。
3 算法建立
3.1 指針網絡深度學習建立
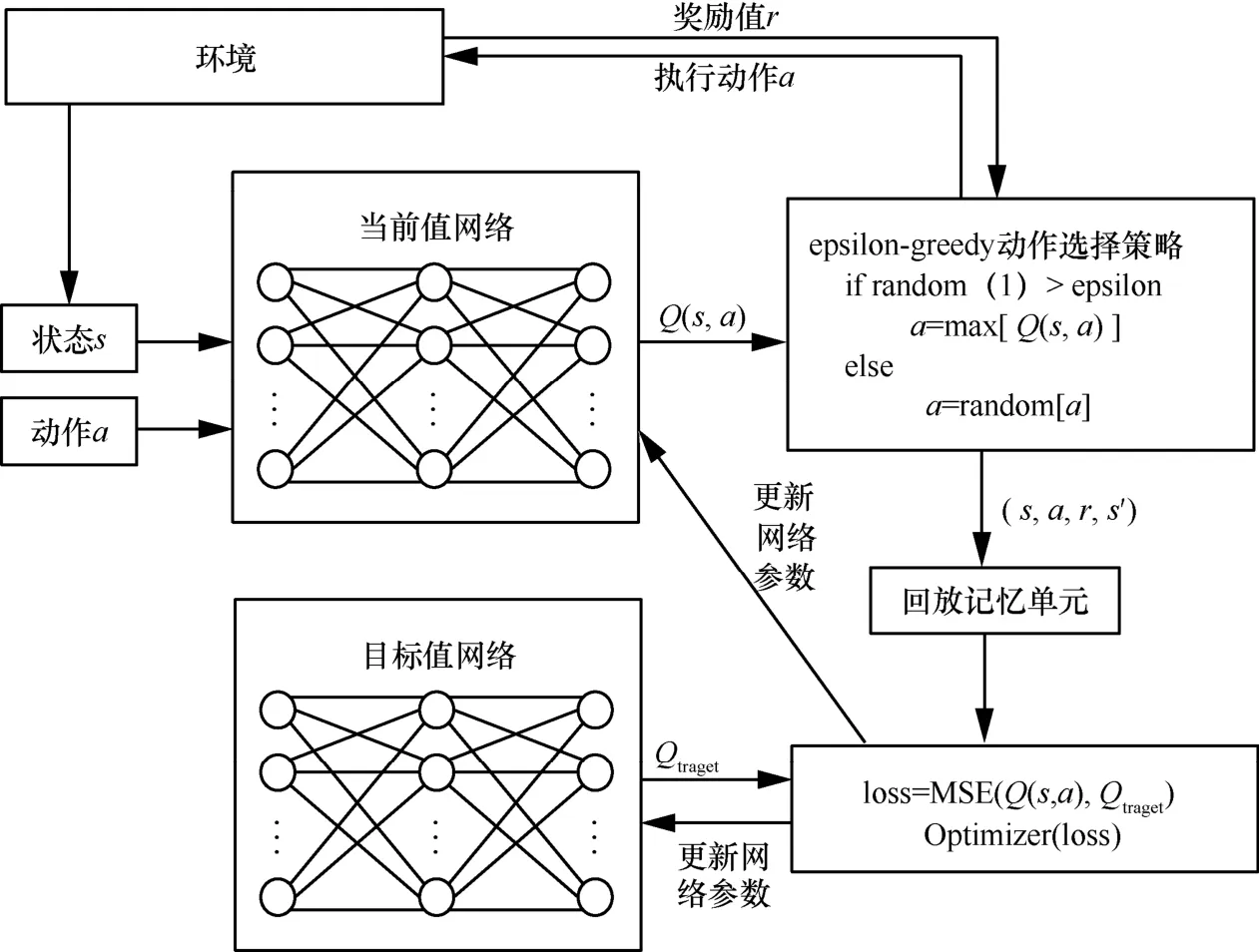
圖4 深度Q 學習的原理框架
指針網絡深度學習的結構如圖5 所示,它是由序列到序列模型[37]和注意力機制[38]結合改進得到的,由Encoder 和Decoder 這2 個階段組成。在Encoder 階段,只考慮輸入xj對輸出yi的影響;在Decoder 階段,解碼輸出注意力概率矩陣,并通過softmax 得到序列的輸出概率分布。由于長短期記憶網絡(LSTM,long short-term memory)[39]能夠成功學習具有遠距離時間依賴性數據的特征,其被用作網絡單元構建指針網絡深度學習模型。Encoder部分使用LSTM 多層神經網絡(記為LSTM-e),Decoder 部分使用LSTM 多層神經網絡(記為LSTM-d)。
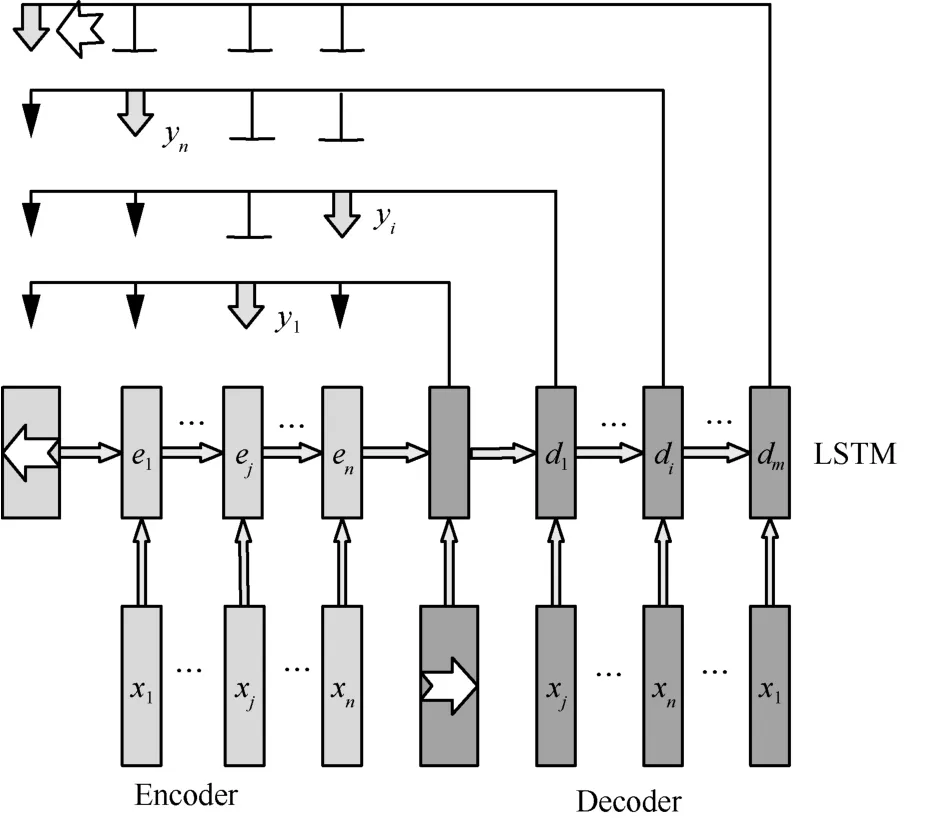
圖5 指針網絡深度學習的結構
第2 節對無人機路徑規劃問題進行了建模,分別確定指針網絡(PN,pointer network)深度學習模型的輸入輸出如下所示。
1)輸入
Dcoords={(x0,y0),(x1,y1),…,(xk,yk)}為無人機服務站Ddepot和每個簇中心坐標Dloc的并集。假設Ddepot處的獎勵值p0=0,Pprize={p0,p1,…,pk}為p0和pi的并集,Dinputs={(x0,y0,p0),(x1,y1,p1),…,(xk,yk,pk)}。
2)輸出
輸出序列Droads={P0,P1,…,Pn}表示無人機數據收集過程中簇的收集順序,Pn對應Dinputs值的索引。指針網絡深度學習的編解碼過程為:輸入序列Dinputs經過k+1 步依次輸入Encoder 模塊,然后通過Decoder 模塊依次輸出Droads中的元素。
因此指針網絡的原理可以表示如下[40]。
編碼過程。將輸入序列Dinputs經過k+1 步依次輸送給LSTM-e,得到每一步輸入所對應的LSTM-e網絡狀態ej(j=0,1,…,k),如式(11)所示。當Dinputs輸入完畢后,將得到的隱藏層狀態Enc=(e1,…,ei,…,en)進行編碼后輸入解碼模塊。
解碼過程。由式(12)計算出LSTM-d 網絡的隱藏層狀態Dec=(d1,…,di,…,dn);由LSTM-e 網絡的隱藏層狀態(e1,…,ei,…,en)和LSTM-d 網絡的隱藏層狀態Dec=(d1,…,di,…,dn)分別計算出每個輸入對當前輸出帶來的影響,如式(13)所示。將其softmax 歸一化后得到注意力矩陣ai,如式(14)~式(16)所示。然后選擇矩陣中權重占比最大的指針作為輸出,如式(17)所示。
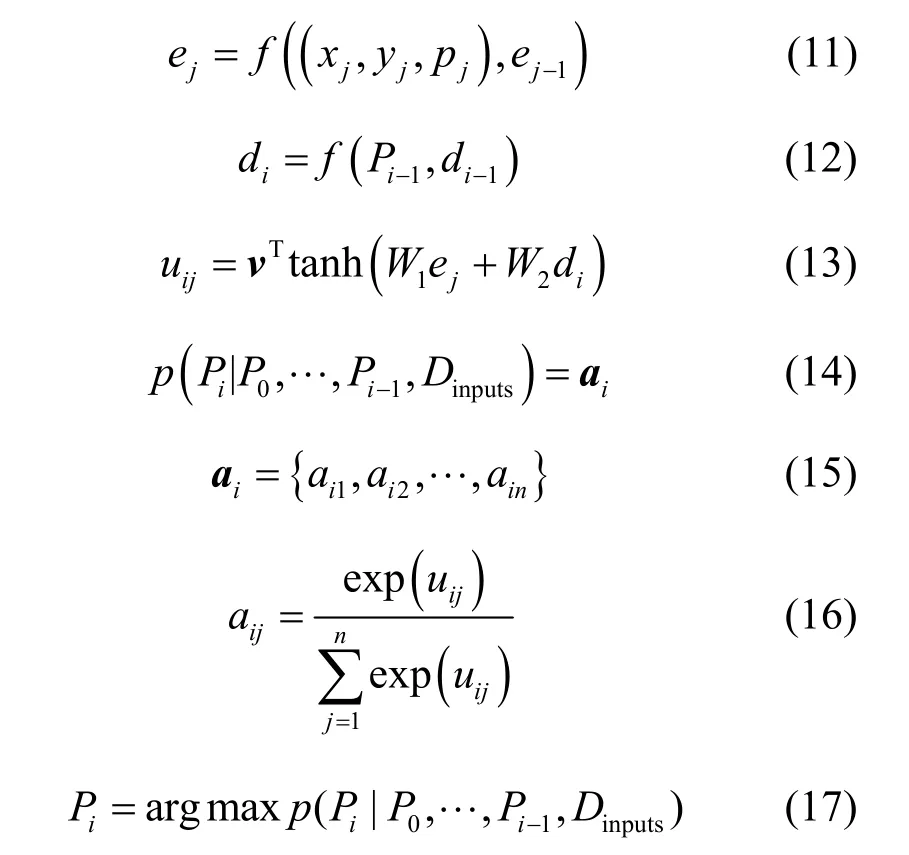
其中,f為非線性激活函數;v、W1和W2為輸出模型的可學習參數;aij由uij經過softmax 后得到,其作用是將uij標準化為輸入字典上的輸出分布[23]。
在解碼過程中,還要考慮到定向問題模型中的約束問題。首先,對于約束(2),預設一個服務份額值δ。對于約束(3),無人機的起點和終點均為無人機服務站Ddepot,因此,第一步和最后一步將P0和Pn設置為0。對于約束(4),根據禁忌搜索的思想,在每一步添加Droads元素時,將其作為禁忌元素添加到Daction表中,每一步輸出將根據Daction表,在注意力矩陣中選擇非Daction表中權值最大的作為輸出。
3.2 指針網絡+主動搜索策略
根據文獻[25]提出的主動搜索(AS,active search)策略,將Dinputs中的元素(除索引0 的位置)隨機排列組合生成B個批次的輸入序列,通過梯度下降法優化目標函數,最后輸出路徑。
通過多目標優化中的線性加權法將目標函數(1)改寫成
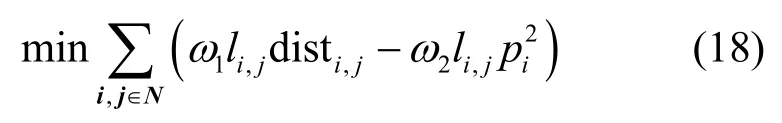
其中,ω1+ω2=1表示在減少無人機飛行距離與提升無人機服務獎勵之間的折中關系,具體可由工程經驗得到。本文設置ω1=0.9,ω2=0.1,通過梯度下降法,式(18)可以同時優化減小距離和增加獎勵值。
指針網絡+主動搜索策略的算法描述如下。
1)初始化輸入序列,將Dinputs中的元素(除索引0 的位置)隨機排列組合生成B個批次的輸入序列。
2)將序列輸入指針網絡,得到一系列結果。
3)使用梯度下降法優化目標函數(18)。
4)重復執行步驟1)~步驟3),直到達到終止條件。
5)選擇最小的目標函數值的路徑作為輸出路徑Droads。
3.3 DQN 算法建立
DQN 算法描述如下。
1)初始化經驗重放緩存區。
2)預處理環境:把狀態?動作輸入DQN,返還所有可能動作對應的Q值。
3)利用ε貪心策略選取一個動作a,以概率ε隨機選擇動作,以概率1?ε選取具有最大Q值的動作。
4)選擇動作a后,智能體在狀態s執行所選的動作,得到新的狀態s′和獎勵r。
5)把該組數據存儲到經驗重放緩沖區中,并將其記作s,a,r,s′。
6)計算目標方程(10),更新Q網絡權重。
7)重復執行步驟3)~步驟6),直到達到終止條件。
4 實驗結果與分析
4.1 參數設置
為驗證指針網絡模型對無人機全局路徑規劃的優化性能,實驗主要對比了指針網絡深度學習、基于主動搜索策略的指針網絡深度學習方法。為了對比AS 方法的效果,本文設計貪婪獎勵(GP,greed prize)方法與其進行比較。GP 方法受貪婪優化方法的影響,先貪婪地選擇獎勵值大小為前N簇的坐標,然后通過PN+AS 方法求這些簇的最短路徑。
實驗令無人機服務站Ddepot的坐標為(0,0),在[0,1]×[0,1](單位為km)的范圍內分別隨機生成50 個簇和100 個簇的中心位置坐標,分別為D50和D100。每個簇的獎勵值設定按照式(5)得到。
表1 和表2 分別給出了AS 方法和GP 方法使用的參數及其相應值。

表1 AS 方法使用的參數及其相應值

表2GP 方法使用的參數及其相應值
為驗證DQN 的性能,本文主要分析Q 學習和DQN 這2 種方法在無人機數據收集中單個節點定位的仿真效果。為模擬無人機接收信號強度值,采用網格法確定當前位置距離目標節點的距離,通過式(7)和式(8)計算接收信號強度值,實現DQN 狀態輸入。本文主要對2 種方法迭代次數內的成功率、步數及其最優路徑進行比較。2 種方法均使用ε貪心策略,在仿真中將無人機到目標節點的距離小于7 m 視為成功,為防止算法無限次迭代,將無人機步數大于200 步視為失敗。仿真結果表明,DQN 的性能優于Q 學習,能夠達到一個較高的成功率。DQN 仿真各參數的設置如表3 所示。
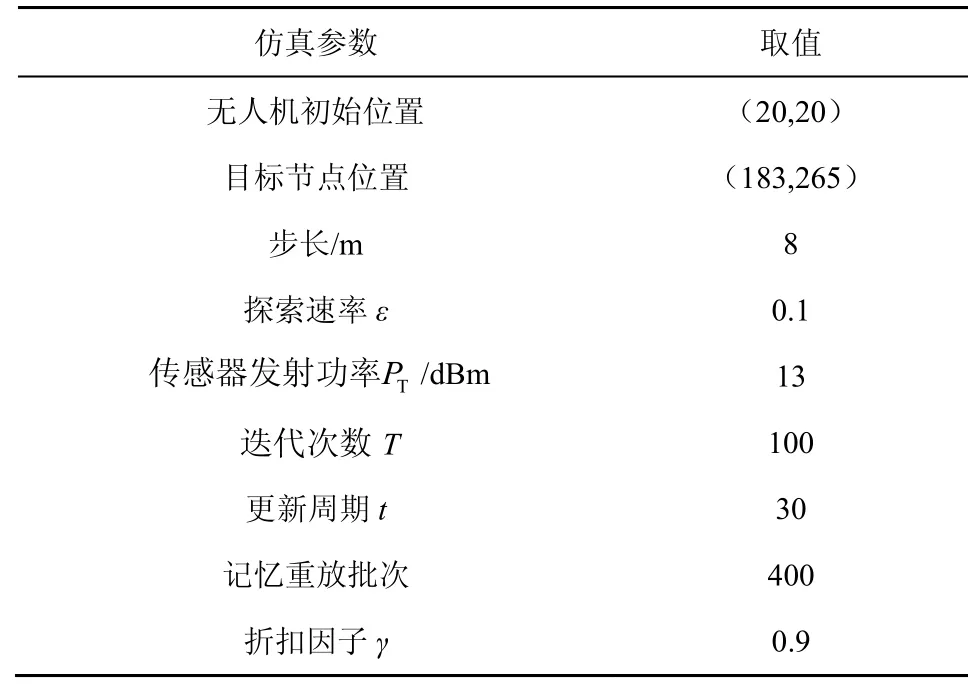
表3 DQN 仿真各參數的設置
4.2 結果分析
圖6 和圖7 分別是D50和D100下使用PN、AS和GP 的路徑規劃效果,表4 是D50和D100下使用PN、AS 和GP 的距離和獎勵值,其中,距離的單位為km。根據式(9)可知,獎勵值越大越好,距離越小越好,這樣可以使模型的收益能效更高。從圖6、圖7 和表4 中可以直觀地看出,使用PN 方法比AS 方法的路徑規劃圖交叉點多,總路徑距離大,總獎勵值小;將GP 方法與AS 方法進行比較,GP方法交叉點少,總路徑距離小,不過GP 方法存在貪婪的性質,相當于將全局路徑規劃問題變為一個簡單的旅行商問題來解決,使該算法獲得的獎勵值更好,但在某些場景下有可能導致更大的飛行距離。雖然AS 方法不能完全達到GP 方法的效果,但AS 方法的效果接近GP 方法,且AS 方法最大的特點就是同時優化距離和獎勵值,雖然獎勵值可能不如GP 方法但其距離有可能更小,且更具隨機性、更適合動態環境中的無人機路徑規劃。
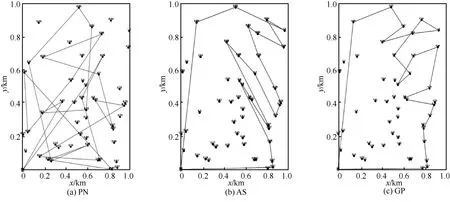
圖6 D50下使用PN、AS 和GP 的路徑規劃效果
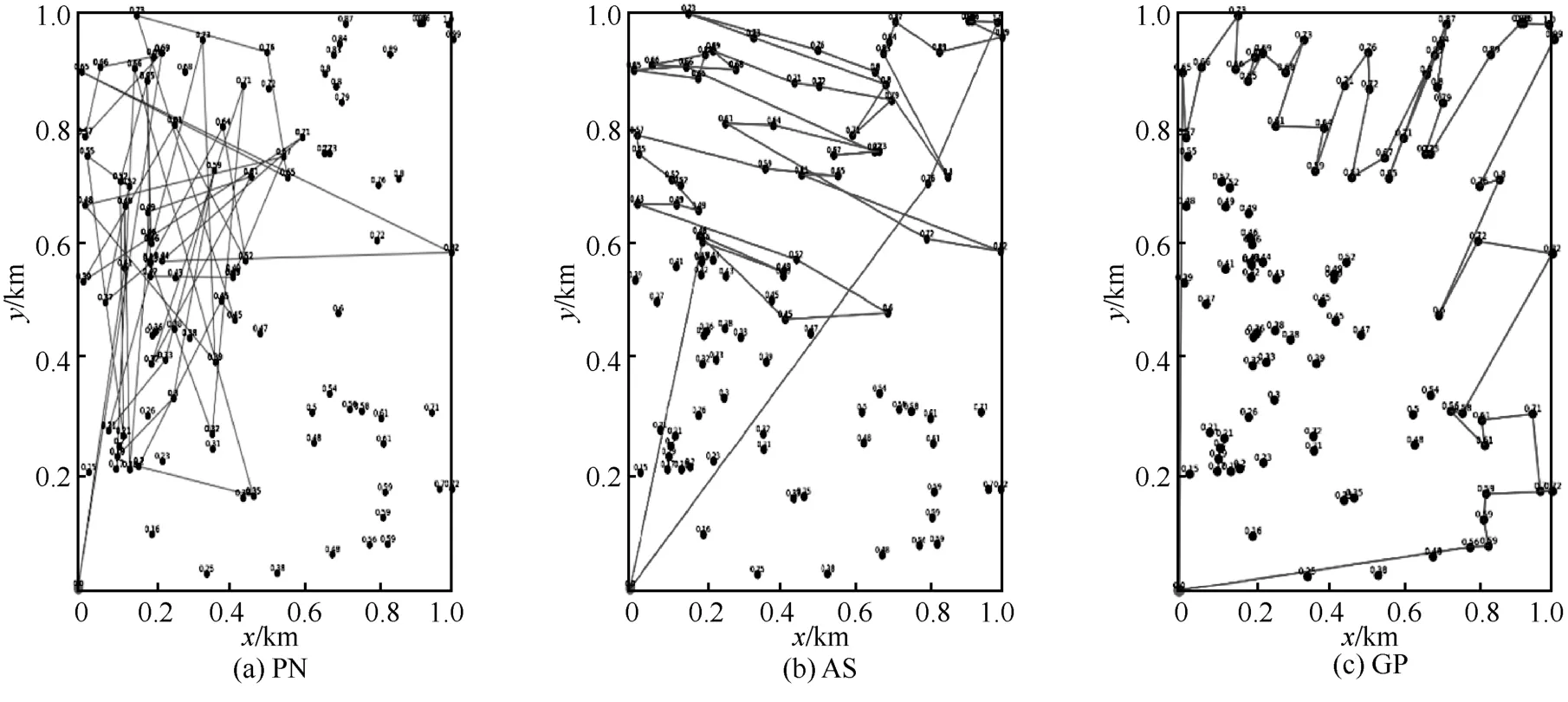
圖7 D100下使用PN、AS 和GP 的路徑規劃效果
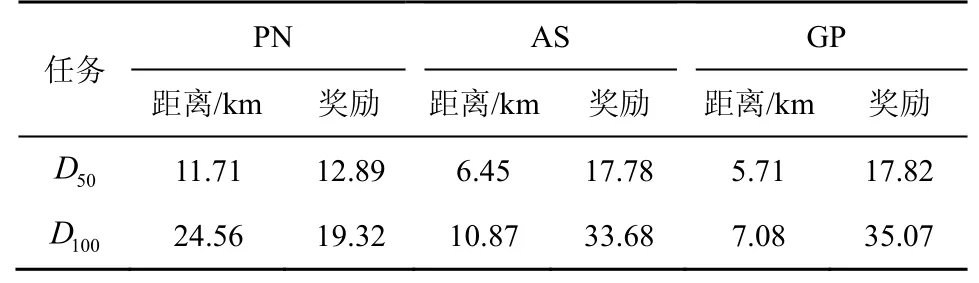
表4 D50和D100下使用PN、AS 和GP 的距離和獎勵值
圖8 是AS 方法下使用梯度下降法訓練PN 的損失值。從圖8 中可以看出,訓練PN 的損失值隨著迭代次數的增加先快速下降,而后趨于穩定,在0 值上下波動,這表明該深度模型可以在訓練后達到收斂,網絡性能可靠。
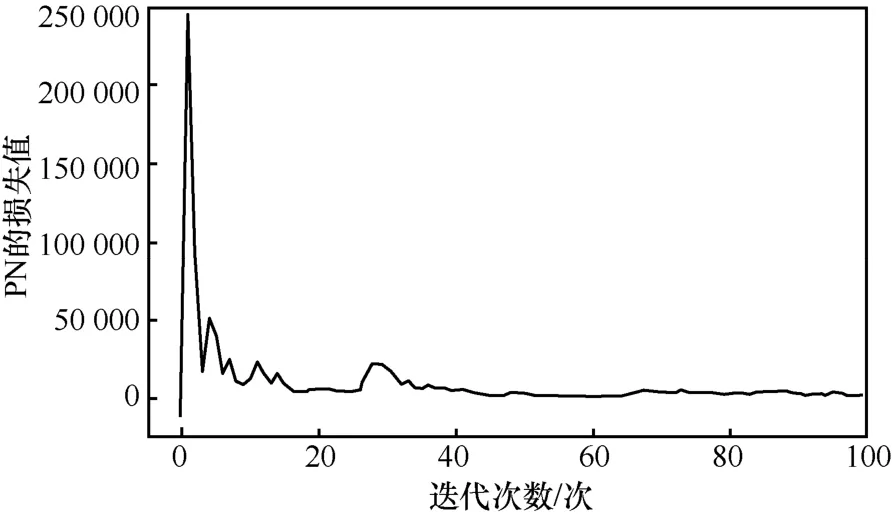
圖8 AS 方法下使用梯度下降法訓練PN 的損失值
圖9 為DQN 和Q 學習的成功次數的步數變化波動曲線。從圖9 中可以明顯看出,DQN 步數的變化只在一開始波動較大,經過一個更新周期(30 次)后波動趨于平穩,且步數較小,迭代次數為100 次,成功率接近100%;Q 學習的成功次數只有7 次,其余均大于200 步。
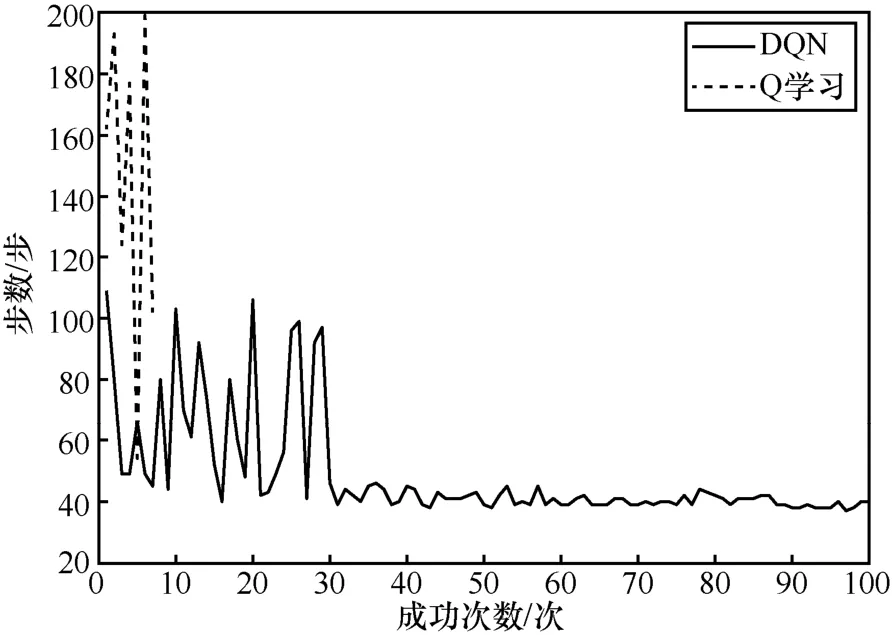
圖9 DQN 和Q 學習成功次數的步數變化波動曲線
從圖10 可以更清晰地看到,DQN 的最優路徑與Q 學習的最優路徑相比更平緩、拐點較少。表5 為不同起點和目標位置時Q 學習和DQN 的最優步長比較。從表5 可以看出,針對不同起點和目標位置,除了第三組(0,0)→(68,78)這2 種方法效果一樣外,其余場景中的DQN 都優于Q 學習,可見DQN 的泛化性能強,可以適應不同的場景。
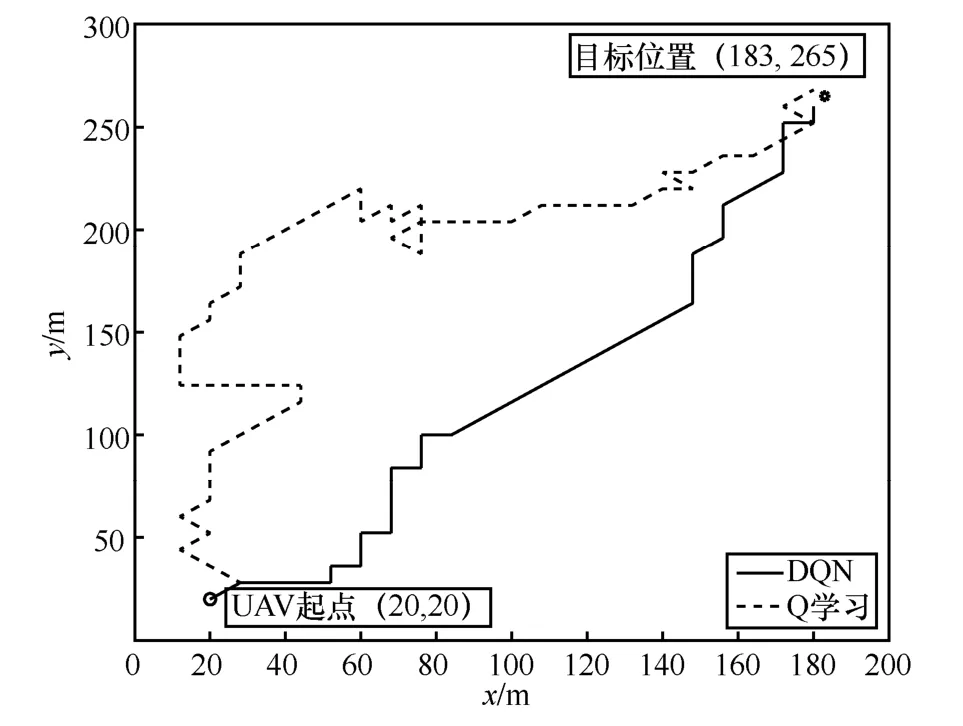
圖10 DQN 和Q 學習最優路徑對比
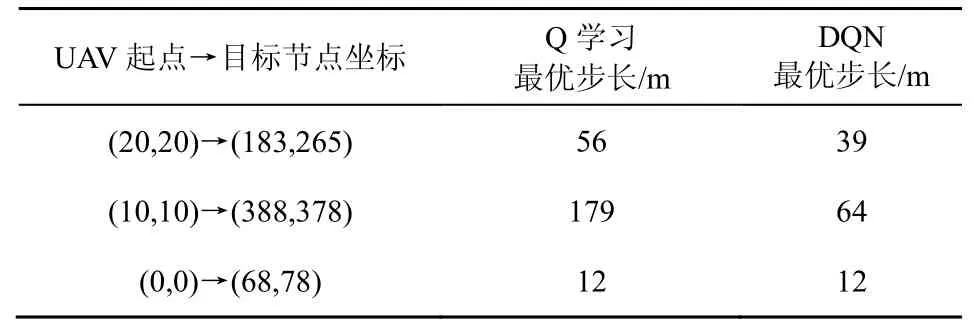
表5 不同起點和目標位置時DQN 和Q 學習的最優步長比較
5 結束語
本文首先使用指針網絡深度學習來解決無人機數據收集過程中的全局路徑規劃問題,并將該問題建模成定向問題,利用指針網絡深度學習得到無人機服務節點集合及服務順序。然后,根據無人機接收目標節點的RSS 通過DQN 來定位目標節點并接近目標節點,經仿真驗證,DQN 在時延等方面的性能優于Q 學習。最后,通過仿真驗證了所提學習機制的有效性。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
