機器學習在信道建模中的應用綜述
2021-03-09 08:55:22劉留張建華樊圓圓于力張嘉馳
通信學報 2021年2期
關鍵詞:模型
劉留,張建華,樊圓圓,于力,張嘉馳
(1.北京交通大學電子信息工程學院,北京 100044;2.北京郵電大學網絡與交換技術國家重點實驗室,北京 100876)
1 引言
信號在發射機天線發送后到達接收機天線所經歷的通道就是無線信道,無線通信正是利用電磁波信號在此通道的傳播特性進行信息交換的一種通信方式,其特性決定了無線通信系統的性能限[1]。信道建模就是在真實環境中探索和表征信道特性的過程,它可以揭示無線電磁波在不同場景中的傳播方式。借助信道模型來了解信道的傳播特性,可以為通信系統的設計和優化提供指導[2],因此,信道建模是無線通信中最重要的研究方向之一,是評估、設計和部署任何無線通信系統的前提。
從國內外研究現狀來看,面向5G 信道特性的研究主要是在某個場景或頻段下采用傳統的手段進行統計分析的,缺少自動學習規律技術的支持,難以應對海量化、時變性、特征多樣化的無線信道數據變化趨勢。因此,為了更好地了解信道的傳播特性,需要一種高效且具有自適應和自學習能力的技術[3]。機器學習(ML,machine learning)是一種可以自動地從數據中發現規律,并利用此規律對未知數據進行預測的算法,已經在學術界和工業界得到了廣泛的應用。作為人工智能的一個重要分支,機器學習具有以下幾點優勢。
1)強大的學習能力和預測能力。相關研究表明,與現有的確定性和隨機性信道建模方法相比,基于機器學習的模型在準確性、復雜性和靈活性之間具有較好的權衡。傳統的信道建模方法依賴于不同的信道配置(載波頻率、發射端/接收端位置等),比較復雜且耗時。基于機器學習的信道模型可以直接學習數據集的特征,以一種更簡單的方式直接獲得信道的統計特性,從而使結果更加準確。例如,在射線追蹤中需要構造不同的環境,在類似WINNER(wireless world initiative new radio)的模型中需要獲得不同的參數集,而基于機器學習的信道模型則從不同場景中收集數據來建立通用性更強的模型架構。
2)良好的非線性擬合及自適應能力。高速移動、大規模天線等帶來的信道在時域和空域的非平穩特性,使實際應用的無線信道都是非線性的,而機器學習恰恰在模擬非線性系統上有著良好的性能。因此,只需要利用實測數據對基于機器學習的信道模型進行足夠多的訓練,就可以用來模擬實際應用中的無線信道。此外,大規模復雜場景導致各種通信鏈路的信道條件迅速變化,此時嚴重依賴信道狀態信息(CSI,channel state information)的信道模型性能會大幅降低[4],而利用機器學習對其訓練以適應新的信道條件,可以建立泛化能力更好的信道模型。
3)擅于挖掘高維度和高冗余數據中的復雜特征,可以高效地處理海量數據。5G 應用場景中提出了增強型移動寬帶(eMBB,enhanced mobile broadband)、高可靠低時延(uRLLC,ultra reliable and low latency communication)及海量機器通信(mMTC,massive machine type communication)三大典型應用場景,為了實現這一目標,5G 系統需要成為一個范式轉變,包括帶寬很高的載波頻率、極端基站和設備密度以及前所未有的天線數量。相關的關鍵技術包括毫米波通信、大規模多輸入多輸出(massive MIMO)以及超密集組網,其中,毫米波通信利用超大帶寬提升網絡吞吐量,massive MIMO利用超高天線維度充分挖掘利用空間資源,超密集組網利用超密基站提高頻譜利用率,這使所需測量的數據量和維度迅速增加[5]。隨著數據的爆炸式增長,在獲取、存儲和處理大量數據的過程中給傳統的信道建模方法帶來了很大的挑戰,而基于機器學習的相關算法(如聚類、神經網絡、粒子群算法等)在處理大數據上卻具有得天獨厚的優勢,例如文獻[6]對179 個測量點進行測量,得到的頻域信道沖激響應(CIR,channel impulse response)的數據量為320 768×254 維矩陣。通過主成分分析(PCA,principal component analysis)進行信道建模,不僅可以將信道參數降低為6 維的主成分,而且信道容量、特征值分布等方面比TR36.873 標準更接近實際測量的結果。因此無線大數據時代給機器學習在5G 及之后的信道建模的應用研究帶來了機遇。
綜上,機器學習被認為是分析測量數據、理解傳播過程和構造模型的有力工具[7]。迄今,國內外已經對高鐵通信[8-9]、毫米波通信[10-11]、4G/5G/6G[5,12-13]、V2V 通信[14]、無人機通信[15]、massive MIMO[16]等應用場景的信道模型進行了綜述,而本文就機器學習如何與信道建模進行有機結合展開討論,主要可以分為以下三大類。
1)信道多徑分簇及參數估計。在MIMO 中出現了以簇為核心[2]的信道模型,這是因為研究簇的特性可以簡化建模過程。簇是一組具有相似的時延、角度等參數的多徑分量(MPC,multipath component),因此,為了在接收端識別出簇,需要一種與多徑傳播特性相對應的聚類算法,從而提高簇核心模型的精度。自動聚類算法(如k-power means 算法)近年來得到了廣泛應用,但仍然需要簇的數量等先驗假設信息。信道建模需要從大量實測數據中提取表征信道衰落特性的各個關鍵特征參數的隨機分布,再根據信道特征參數的隨機分布來量化各個參量,在這些參量的基礎上構建的信道模型才能真正體現和反映真實信道傳輸的特性,進而通過信道參數估計算法來提取信道特征的關鍵技術。隨著無線通信的發展,信道特征的維度由最初的時-頻二維擴展到時-頻-空三維,所需提取的參數的數據量呈現出爆炸式增長,這給傳統的信道參數估計帶來了很大挑戰。然而許多分簇算法需要在聚類之前通過高分辨率參數估計算法提取MPC,這些算法的計算復雜度普遍較高,難以在時變信道中進行實時操作。因此,基于機器學習的MPC 自動聚類算法和參數估計算法受到了廣泛的關注。
2)信道模型構造。5G 及未來通信系統將支持更大規模的天線陣列、更高的頻段、更大的帶寬及更加復雜多樣的應用場景,信道數據量也隨之激增。傳統的基于簇的統計性建模方法較難找出抽頭簇與實際散射體之間的映射關系;確定性建模方法預測準確但復雜度高,且依賴于環境信息精度。隨著人工智能的飛速發展,國內外提出了基于神經網絡(NN,neural network)[17]和基于簇核的信道建模方法[2]。前者利用神經網絡在描述數據特征和提取系統輸入與輸出之間的映射關系展現出良好的性能,可以使用實測數據集對神經網絡進行充足的訓練,從而模擬實際場景的無線信道,尋找輸入層變量和輸出層信道特征參數的相互關系。該方法利用了神經網絡自學、自適應和非線性擬合的特點,這對時變信道的建模特別重要,尤其是在分析實際信道數據時可以減少重新建模的成本。后者利用機器學習算法從海量信道數據中挖掘信道特性,找到統計性簇和確定性散射體之間的匹配映射關系,并通過有限數量有物理意義的簇核進行信道建模。該方法同時結合了統計性建模和確定性建模的優勢,既解決了確定性模型復雜度高的問題,又解決了統計性模型缺乏物理含義的問題。
3)信道狀態分類/場景識別。信道狀態分類/場景識別是信道建模和通信系統部署的重要依據,不同場景下的信道模型也不一致。另外,由于信道的復雜性,實際測量所需的時間長且難度高,那么精確的信道場景識別對系統進行分析和評估可以大大提高工作的效率。然而,在傳播環境多變的情況下,使用基于單一度量的假設檢驗對場景進行分類是不夠準確的;另一方面,一些機器學習算法對于數據的分類具有很大的優勢,比如支持向量機(SVM,support vector machine)、神經網絡、隨機森林、決策樹等。在這種情況下,學習和提取不同場景下的信道屬性差異有助于自動將測量的數據分類到不同場景中,建立相應的信道模型,并發現用于資源分配、系統優化或本地化的場景特征。
本文概述了機器學習應用于信道建模過程中的相關研究。首先,介紹了利用機器學習優化傳統的信道參數估計,總結了國內外針對分簇所采用的聚類算法,并從多個角度對不同聚類算法進行比較。其次,總結了在大尺度衰落和小尺度衰落信道下,神經網絡對不同環境、場景和頻段下的建模,歸納出可優化模型的算法和通用的模型結構,介紹了一種以簇為核心的智能化建模過程。再次,提出了無線信道場景識別的研究難點以及目前的一些研究方案。最后,對全文工作進行總結,并對未來進行展望。
2 信道多徑分簇及參數估計
對多徑分量的統計特性進行建模通常有2 類方法:非簇結構建模與簇結構建模。非簇結構建模著眼于每個多徑分量,簇結構建模則把多徑分量劃分成簇,用以研究簇內和簇間的統計特性,諸如簇數、時延擴展、角度擴展等。簇結構的使用得益于5G系統有更多的MIMO 信道數和更大的帶寬推動,并且大量測量分析顯示,多徑分量在實際環境中是以簇狀分布的[18-19]。開展對簇特性的研究,前提是從電磁波中識別出簇,也即將CIR 中的MPC 一一劃分到相應的簇中。然而,在很長一段時間內,分簇都是通過將測量的數據轉換為圖片再進行人工劃分的,這種方法沒有一個準則來衡量效果,并且無法觀測高維結果。從2006 年Czink 等[20]將機器學習算法引入信道多徑參數分析,提出自動多徑聚簇,解決了傳統人工分簇準確性低、效率低、難以應對高維大數據量參數等問題后,k-means 算法等機器學習算法就成為信道多徑分簇的主流分析方法。但是k-means 算法只基于多徑距離,并沒有考慮到信道多徑的物理傳播特性,因此,選擇一種優秀的分簇算法對基于簇的信道建模是十分關鍵的。
無線信道中MPC 特性的挖掘深度和提取精度決定了信道建模的精度和復雜度。隨著無線通信的發展,人們對無線信道特征的認知和利用也從單一的大尺度衰落層面的功率距離關系逐步發展到空-時-頻多維的小尺度衰落層面,對MPC 的描述也從幅度-時延-多普勒的三維精確到幅度-時延-水平離開角(AAOD,azimuth-angle of departure)?水平到達角(AAOA,azimuth angle of arrival)-垂直離開角(EAOD,elevation-angle of departure)?垂直到達角(EAOA,elevation-angle of arrival)-多普勒的七維特性。如果考慮極化特性,信道特征維度會再增加,而且時延域分辨率的提高(時延為1 ns 或者更低)帶來的必然結果是可分辨多徑的增多,比如對于一個采樣點所提取的MPC 可能從50 條增加到200 多條,而每條MPC 至少有7 個參數需要估計,這樣每個采樣點的信道數據要提取的信道參數則擴大到1 400 個,那么對不同位置的采樣點提取的參數總和可以擴大到以萬為單位。面對信道的大數據量,尋找高速、精確的多維無線信道特征提取算法顯得尤其迫切。
2.1 信道多徑分簇
隨著MIMO 技術的成熟,多天線技術也更加普遍地應用于通信系統的收發端,這為通信系統帶來了頻譜效率和傳輸可靠性的提高。關于MIMO 信道的建模,國內外已經取得了一些顯著的進展,出現了以簇為基本單元的模型,如歐盟信息社會技術項目組IST(Information Society Technology)提出的WINNER 模型、3GPP 開發的空間信道模型(SCM,spatial channel model)[18]。這是因為通過對簇內特征參數的研究,可以降低MIMO 信道建模的復雜度。基站(BS,base station)和移動端(MS,mobile station)之間的多徑聚類現象如圖1 所示。相同時延格里的MPC 經過同一個散射體反射、繞射、折射到達接收端,那么這些MPC 的時延、離開角和到達角就會具有相似性,本文稱之為簇。因此,簇與確定性環境中的散射體存在一種必然的聯系。
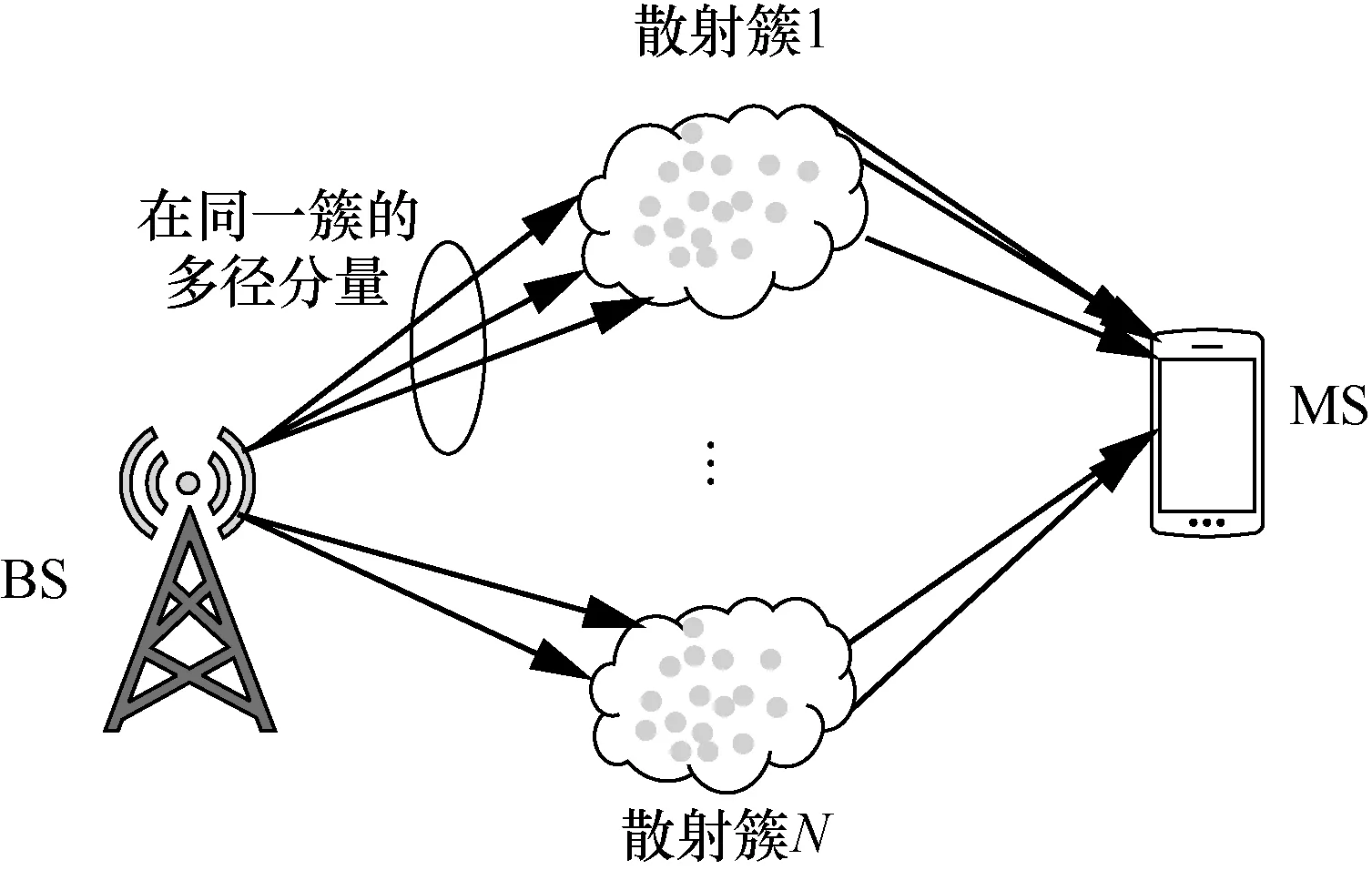
圖1 BS 和MS 之間的多徑聚類現象
在機器學習領域,分簇也稱為聚類,屬于無監督學習的一種。通過某些物理特征(如多徑分量距離、功率、時延等)將樣本劃分成多個簇,屬于同一個簇的樣本具有相似性。良好的聚類算法應具有以下特征。1)MPC 聚類算法需要少量參數且易于調整。在大多數情況下,一些算法的初始化和參數調整需要通過實驗來完成,這使實現過程變得煩瑣,不易自動挖掘信息,例如,k-power means 算法需要一個定義好的簇的數量和聚類中心的位置,并且需要仔細調整算法中時延和角度的權重因子,才能得到合理的輸出。2)選擇合適的距離度量。使用特征空間上定義的距離度量來計算兩點之間的差異,簇聚類中常用的距離度量包括歐幾里得距離、曼哈頓距離、切比雪夫距離等,不同的距離度量通常會對結果產生不同影響。3)MPC 聚類算法需要考慮其物理傳播特性。現實中由物理環境生成的MPC 具有某些固有的特性(如附加時延越大,MPC的功率越小),因此即使是視覺檢測也可以很容易地聚類MPC。然而為了更好地反映信道的傳播特性,降低模型復雜度,可以考慮信道統計特性的建模行為,例如,MPC 簇的角度分布通常建模為拉普拉斯分布,MPC 的這種預期行為可以進一步納入分簇算法來提高分簇算法的精度。
2.1.1 經典的分簇方法
基于簇的信道建模,首先要對多徑分量進行分簇,進而簇數、位置、時延擴展、角度擴展等都可以參數化,因此對于優秀的分簇算法的研究一直是一個熱門的課題。本節將主要介紹可用于分簇的三大經典聚類算法——k-means 算法/KPM(k-power means)算法、高斯混合模型(GMM,Gaussian mixture model)算法、基于密度的含噪空間聚類(DBSCAN,density-based spatial clustering of applications with noise)算法,并從信道應用的角度對這3 類聚類算法進行對比。
k-means 算法[21]基于歐氏距離對數據進行聚類識別,算法過程如圖2(a)所示。該算法首先確定簇的數目和聚類中心,再根據歐氏距離對簇進行初始聚類;然后通過迭代更新聚類中心的位置以達到收斂,得到最終的聚類中心和簇。KPM 算法[22]是一種基于k-means 算法的聚類算法,整合了功率對聚類的影響。這2 種聚類算法中簇數量的上界和下界必須是先驗的,最終簇的數量是通過使用一些有效性指標來確定的。然而KPM 算法存在參數敏感性太強、結果合理性欠佳、多徑簇數目判定方法不合理的問題。
GMM 算法是一種基于統計分布的多徑分簇算法[23],如圖2(b)所示。文獻[24]引入GMM 算法實現信道的多徑分簇,在GMM 算法中,MPC 假設由若干個高斯分布組成,其分布的概率滿足最大似然函數。為了估計GMM 算法的參數,文獻[23]首先采用期望最大化(EM,expectation maximization)算法求解GMM 算法參數的最大后驗概率估計。然后利用變分貝葉斯(VB,variational Bayesian)算法對GMM 算法優化參數求解,以增強EM 的全局搜索能力,避免局部最優和過擬合,進而在不需要交叉驗證的前提下確定了高斯分布的最優個數。最后提出了新的分簇評價指標——緊湊指數(CI,compact index),同時考慮了簇內均值和方差信息來評價分簇結果,進而發現多徑傳播特性、GMM 算法分簇機制和CI 評價指標之間的密切聯系。
DBSCAN 算法[25]考慮所有的數據點被劃分為核心點、密度可達點和離群點,其主要思想如圖2(c)所示。DBSCAN 算法可以吸收其鄰域半徑內的所有對象(即密度可達),并且鄰域需要滿足用戶指定的密度閾值(即組成一個簇所需的最小點數)。DBSCAN 算法對密度閾值很敏感,因而選擇合適的密度閾值將是一個挑戰。
k-means 算法是基于歐氏距離的,該算法容易實現、收斂快,但無法捕捉到信道多徑的傳播特性且適用于凸形簇,然而在信道建模中簇的存在形式是否為凸形尚無定論。GMM 算法是基于數據統計分布的。DBSCAN 算法是基于密度的。這些算法都考慮了MPC 的統計特性,對任意形狀的稠密數據集都可以進行聚類,但當簇分布不均勻時,DBSCAN 算法分簇效果欠佳。通過比較圖2中k-means 算法與GMM 算法的分布數據可以發現,在k-means 算法中,每一路徑分量僅屬于一個簇;在GMM 算法中,同一路徑分量可以屬于不同的簇,也即它可以同時具有不同的相似度,這使GMM 算法比k-means 算法更靈活。另外,k-means 算法和GMM 算法需要簇數量的先驗信息,如何選擇簇數量仍然是一個開放的話題,因此當前需要更好的多徑聚類算法服務于基于簇結構無線信道模型的開發。
2.1.2 改進的分簇方法
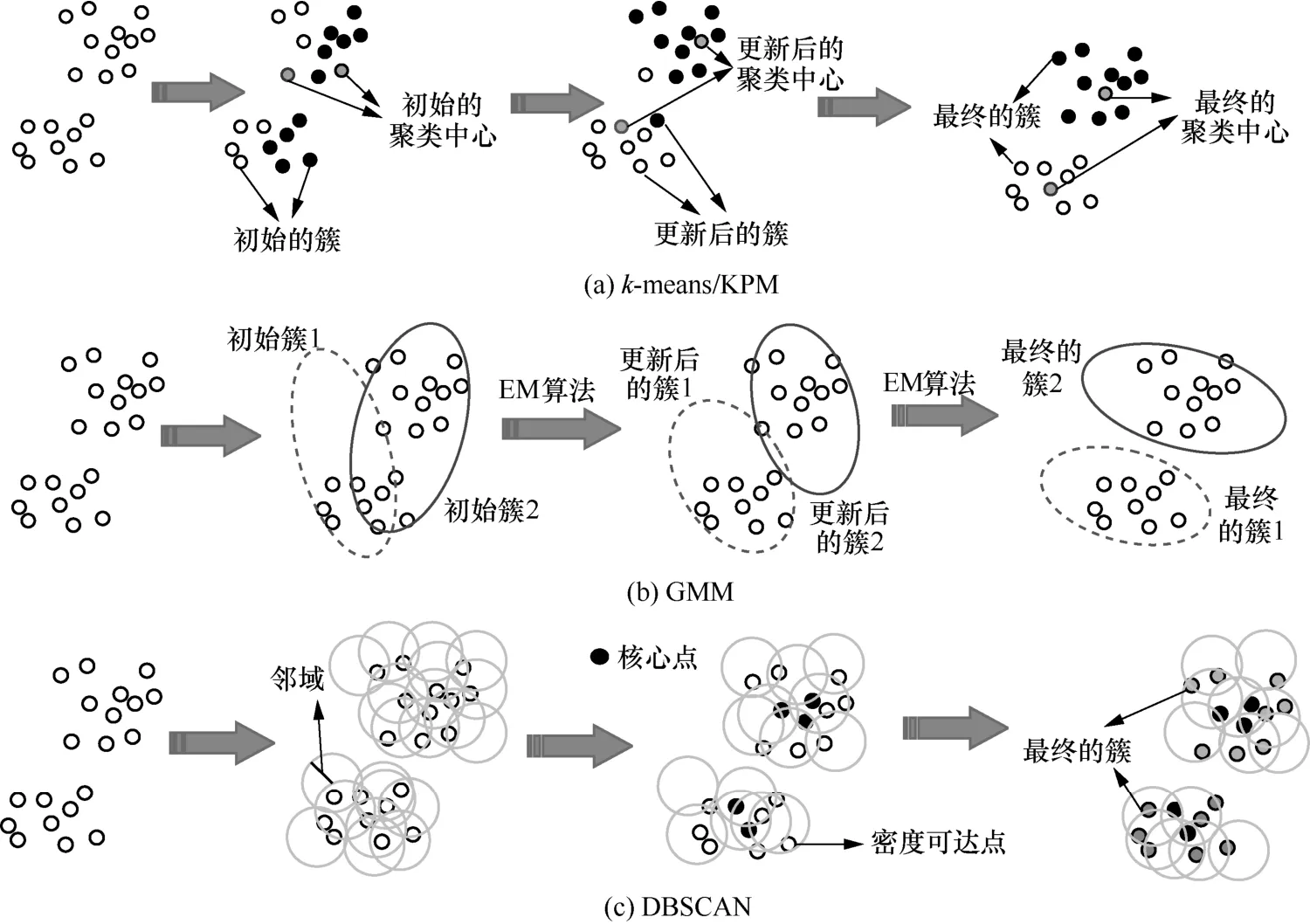
圖2 經典MPC 聚類算法的思想
文獻[26]提出了一種基于核功率密度(KPD,kernel power density)的分簇算法,該算法同時考慮了MPC 的功率和密度,這使分簇結果與多徑統計特征緊密結合,且能更好地識別MPC 的局部密度變化。另外,當大量的簇出現角度擴展的現象時,算法性能也沒有明顯的下降。文獻[27]提出了一種改進的KPD 分簇算法,不需要手動調整就可以得到各個MPC 的自適應分簇個數k,以解決KPD 中無法準確區分密度相近、多徑較小的簇的問題。文獻[28-29]提出了一種基于功率譜輪廓識別的分簇方法,該算法是適于時變信道目標識別的分簇算法,它能夠較好地識別視距環境和非視距環境下的主簇,復雜度低且不需要進行高分辨率的參數估計,便可以清晰地觀察到實時信道測量中簇的動態變化。文獻[30]提出了一種基于聯合核密度的分簇算法,該算法考慮了MPC 的統計特性,通過改進核方程并利用各參數的實際統計分布形成聯合核密度,自動得到最優分簇數的同時使聚類結果也更加準確。文獻[31]提出了一種基于稀疏度的信道沖激響應分簇算法,該算法改進了現有分簇算法中沒有充分考慮分簇形狀而使分簇性能降低的缺點,并提供了一種啟發式的方法來識別恢復CIR 中的簇,與直接識別簇算法相比,其準確性更高。文獻[32]提出了一種基于KPM-卡爾曼濾波的分簇算法,其適于大規模MIMO 的城市宏蜂窩行人移動場景,可以在測量過程中清晰地描述不同簇的軌跡,包括簇的產生、消失率和存留時長。文獻[33]提出了一種基于數據流的分簇算法,該算法考慮了多徑的時延、到達角、離開角和功率,且基于信道的時域動態特性,能夠自然地反映MPC 的動態行為,因此可以對時變信道進行分簇。文獻[34]提出了一種基于模糊C 均值的分簇,這是一種基于劃分的分簇算法,該算法建立了樣本對類別的不確定描述,實驗結果表明其性能優于KPM 算法,從而成為分簇分析方向的主流方法。文獻[35-36]提出了一種基于密度峰值的分簇算法,該算法具有自動獲取簇數和分簇中心的能力,且適用于任何分布的數據集,但只支持時延域。文獻[37]提出了一種基于最大轉移概率相似性的多徑分簇算法,建立了時變信道動態多徑的分簇關系。另外,一種由圖論演化而來的譜分簇算法[19]能夠深入挖掘信道測量數據中的特征和規律,因此效果表現良好,但仍需要預先設置簇數。上述聚類算法的特點如表1 所示。
對于SISO(single input single output)信道的聚類,僅考慮時延與功率2 個維度,因此相應的聚類算法僅需要支持時延域,并且能夠充分挖掘簇在時延維上的特點;對于MIMO 信道,由于其多徑分布于時延、空間維度,物理特征更加復雜,因此聚類時還需要考慮角度域,例如KPD、KPM 算法都可以應用于MIMO 信道。另外,在4G LTE 通信中采用了二維MIMO,聚類算法僅需要考慮水平維度的角度域,而在5G通信系統中MIMO擴展到了三維,這時MPC 的聚類就需要考慮俯仰維度的角度域[32]。此外,若聚類算法不需要預先設定簇的數目和聚類中心,則意味著該算法可以在MPC 數目較大的情況下,提高聚類的效率和準確性。
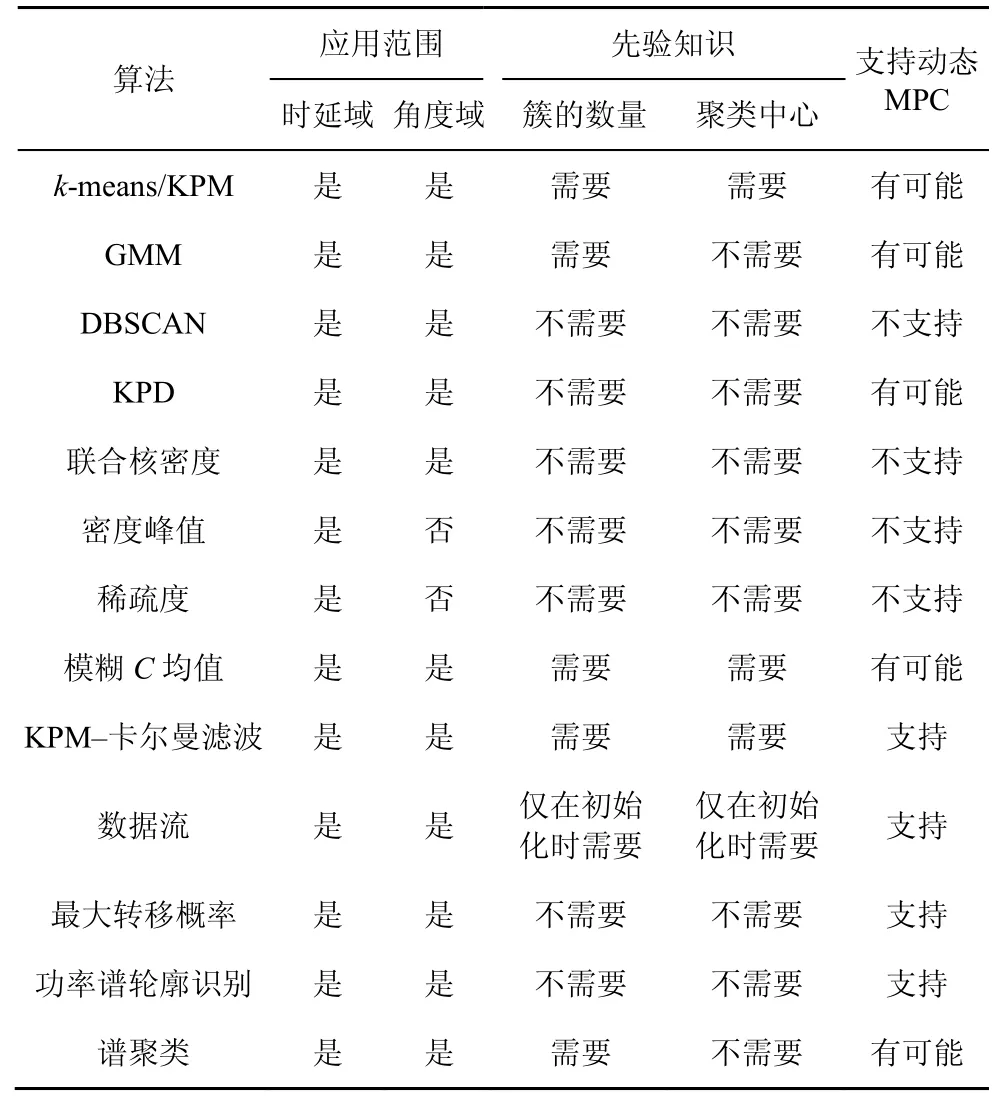
表1 MPC 聚類算法的特點
在時間或者空間上具有非平穩特性的信道,其聚類算法需要支持動態MPC。其中,時間非平穩特性稱為時變特征,指的是信號特征隨時間發生變化。適用于時變信道的聚類算法包括基于概率的、基于功率譜輪廓識別的和基于數據流的聚類算法。空間非平穩性是指描述空間關系的參數會在空間上發生變化,如大規模MIMO 信道。適用于空變信道的聚類算法包括基于KPM-卡爾曼濾波的分簇算法、一種結合KPM 和分區的算法[38]。這些適用于非平穩信道的聚類算法可以清晰并實時地觀察到信道測量中簇的動態變化,包括簇的產生、消失和存留時長等。由上述分析可知,合適的聚類算法和參數設置通常依賴于數據集,但由于MPC 數據種類繁多,尋找一種適用于多頻段或者多場景通用的聚類算法仍然是具有挑戰性的。另外,由于分簇在機器學習中屬于無監督學習的范疇,數據中沒有標簽,因此需要一些衡量指標來評判分簇效果,比如通過簇內的緊湊程度以及簇間的離散程度,但這種評價指標沒有將簇與散射體之間的關系納入評價體系中,希望在未來的研究中可以獲得可解釋的、具有物理意義的評價指標。
2.2 信道參數估計
若已知CSI,就可以采取相應的措施來抵抗信道衰落,從而在接收端降低誤碼率、提升系統性能。信道參數估計正是實現這一目標的關鍵技術。目前,應用最廣泛的信道參數估計算法是空間交替的廣義期望最大化(SAGE,space-alternating generalized expectation-maximization)算法,該算法可以實現MIMO 系統的高精度聯合估計,而且可以獲取MPC 及其多維特征。與早期的參數估計算法相比,SAGE 算法收斂速度更快,但其仍然存在著受初始精度影響大、對于低信噪比的MPC 容易出現局部收斂最優的問題,而且隨著天線數量、帶寬和應用場景的增加,算法復雜度隨之增大[39]。隨著無線信道建模的大數據化,傳統的信道參數估計算法在速度、準確度上已經很難滿足研究的預期。為了解決這一問題,科研人員對傳統算法進行了改進,為多徑分簇和建模研究打下堅實基礎。相關研究將遺傳算法[40-42]、粒子群算法[43]和稀疏貝葉斯算法[44]應用到MPC 特征的提取,實驗結果表明,這些進化計算方法可以在準確性不降低的前提下,節約特征提取的時間。
針對MIMO 信道,若要貼近實際三維MIMO信道場景,垂直維度的俯仰角參數等相關信道特征也應該納入無線信道的統計特性描述中,這就需要通過信道參數提取技術獲得多徑時延、水平維度的到達/離開方位角、垂直維度上的到達/離開俯仰角等基本信道參數。傳統參數提取方法中的信道估計算法性能較差且需要空間平滑處理技術的配合,因此只能對水平維度的參數進行特征提取,不能很好地擬合實際三維系統。文獻[45]利用神經網絡對非線性系統具有極強的自學習和自適應特性的優點,研究了反向傳播神經網絡(BPNN,back propagation neural network)在信道參數提取中的應用。該文首先利用QuaDriGa 仿真平臺生成市區場景下的信道沖激響應,并通過SAGE 算法對時延擴展、水平維度的方位角及垂直維度的俯仰角等信道參數進行提取;然后利用樣本數據訓練BPNN 對信道參數進行提取,并與SAGE 算法的效果進行比較。結果表明,BPNN 模型的預測效果與SAGE 算法的估計效果之間差異很小。因此,該模型有望克服現有統計建模方法的不足,能與實際測量環境相匹配,對5G系統和鏈路級仿真非常有用。此外,本文還對BPNN和SAGE 算法的時間復雜度進行了比較,結果表明,BPNN 的時間復雜度為O(n3),SAGE 算法的時間復雜度為O(nlogn),其中n為輸入的參數的個數。BPNN 的計算量大于SAGE 算法,但其普適性和靈活性卻優于SAGE 算法。
在動態應用場景中,對大規模MIMO 系統進行大范圍精確的信道測量是非常困難、耗時和昂貴的。另外,對龐大的測量數據進行全面分析,快速估計出一套完整的信道參數,這需要復雜的科學理論以及在電磁波領域豐富的實踐經驗。為了減少信道測量以及參數估計的工作量,文獻[46]提出了一種如圖3 所示的智能且通用的信道參數生成模型——生成式對抗網絡(GAN,generative adversarial network)模型,該模型用了2 個神經網絡:信道數據生成器和信道數據鑒別器。具體來說,GAN 模型利用測量的信道數據(或者估計的信道參數)進行訓練,達到信道數據生成器和數據鑒別器之間的最小博弈納什均衡的目的。一旦這個過程收斂,就表示信道數據生成器已經學習到了特定應用場景中原始數據的特征,那么此時信道數據生成器就是目標信道參數生成模型。

圖3 基于GAN 的信道參數生成框架
GAN 模型能夠從有限的數據中學習到其內在特征并生成逼近真實可靠的信道數據,并不需要針對某一場景進行大規模的測量或者完整的參數估計,進而簡化信道建模的過程,但仍然存在一些技術壁壘,主要體現在以下幾個方面。1)收斂困難。與傳統的機器學習問題不同,這種基于GAN 的模型是利用信道數據生成器和鑒別器相互競爭實現的,也即生成器和鑒別器需要自身的損失值減小、對方的損失值增大。另外,GAN 的訓練通常采用梯度下降算法,該算法擅長于識別損失值的最低值,而非博弈中的納什均衡,因此當訓練過程需要納什均衡時,這些算法可能會出現不收斂的情況。2)模型泛化能力有待提高。由于訓練時數據類型的不同,該模型只能學習到特定測量環境的參數特性,也即該目標信道模型不能推廣到其他具有不同信號傳播條件的通信環境中,例如,適用于具有豐富多徑的室內信道參數生成模型不適用于室外城市環境。盡管GAN 模型還有一些地方(比如合適的神經網絡的參數設置、訓練方法等)需要完善,但還是為未來多樣化且復雜化的信道參數估計提供了一種很好的思路。
3 信道模型構造
傳統的信道建模分為確定性建模、統計性建模和半確定性建模。其中,確定性建模遵從電磁場傳播理論,通過求解Maxwell 方程組來得到電磁波傳播特性,典型的方法包括射線追蹤法和時域有限差分法。這種建模方式依賴于場景信息,預測結果準確,但計算復雜度高。統計性建模建立在大量實測數據上,由統計分析歸納得到信道模型,因此在相似的傳播環境中預測值與實際值相近。這種建模方式不需要詳細的環境特征參數,但需要大量測量,既耗時又費力,并且傳統的統計方法在回歸擬合上具有一定的局限性[47]。半確定性建模兼具確定性建模和統計性建模的特點,典型模型為 GBSM(geometry based stochastic model)。這種建模方式比確定性模型復雜度低,對某一類環境具有適用性,當前一些國際標準信道模型大多使用該模型,但由于半確定性建模利用隨機分析的方法來重構CIR,故不能準確地預測某個傳播場景的無線信道[48-50]。因此,信道模型如何在準確度和復雜度之間做好權衡成為一個值得探討的課題,如圖4(a)所示。
信道建模經過長期發展已經擁有了較完備的經典設計和處理方法。大量實踐證明,這些經典方法在工程上極其有效,且易于實現。例如,文獻[51]提出了一種基于GBSM可以直接獲取CSI的信道模型的方法,該方法和機器學習類似,具有自學習的優點,且適用于時變信道,實驗結果也表明該模型的適用范圍較廣。這意味著,即使采用先進的機器學習算法,也可能無法超越這些經典算法,而且機器學習學習本身也有明顯的局限性,無論是BP 算法還是強化學習算法均存在訓練的收斂時間問題,能否滿足移動通信系統實時處理的需求,需要進行較充分的評估[52]。但是5G 系統存在大量傳統方法難以建模、求解或高效實現的問題,例如大規模多用戶的聚類、新的復雜應用場景的信道建模等,這為機器學習在5G 系統的有效應用提供了可能。同時,一些新的機器學習算法還在不斷發展,為機器學習算法在5G 系統的信道建模提供了新的機遇。因此,機器學習技術在5G 系統及6G 系統的信道建模設計與優化都具有很高的潛在價值。
3.1 基于神經網絡的信道建模
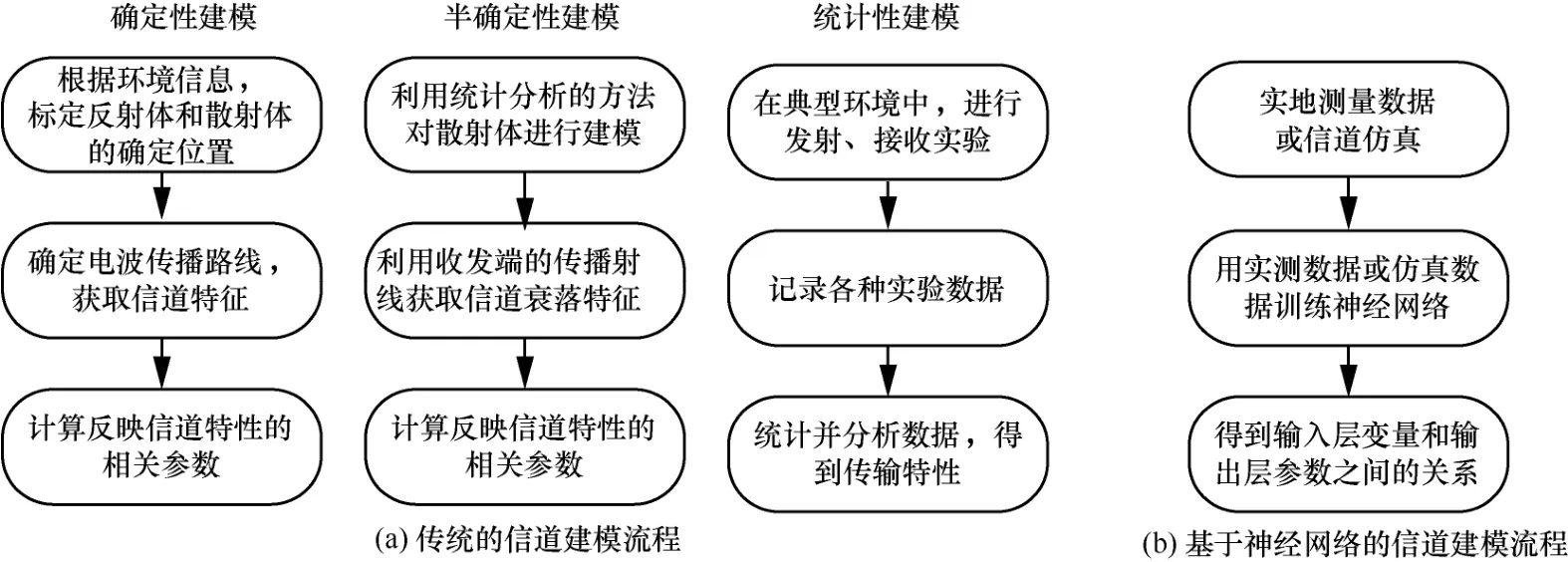
圖4 傳統的信道建模流程與基于神經網絡的信道建模流程
考慮到神經網絡優異的學習機制,前人基于實測的信道數據使用神經網絡來進行信道建模。一方面,對于已有的各種無線信道模型(它們屬于線性模型),只需要用相應模型產生的數據對神經網絡進行訓練,便可以使神經網絡在最小均方誤差的準則下逼近實際的信道模型。另一方面,當實際的無線信道都是非線性/非平穩的,而神經網絡恰恰在模擬非線性系統上有著良好的性能。使用神經網絡的方法還有一個優勢,即神經網絡的網絡結構相對固定,如果需要重新對一個無線信道進行建模,只需要用不同的數據對其訓練就可以做到,也就是說神經網絡具有自適應的特點,這個特點對信道建模特別重要。神經網絡采用普適結構,減少了重新建模的代價,尤其是在對實際信道數據的分析建模中。如圖4(b)所示,基于神經網絡的信道建模利用實測數據來訓練,不需要確定電磁波的傳播路徑,故不會受到環境的約束,更適用于各種復雜的場景。神經網絡通過不斷的訓練,建立了表征輸入層變量(訓練集)和輸出層變量(大尺度衰落參數、小尺度衰落參數)關系的模型,那么根據已知的輸入層變量,就可以精準地預測相應的信道參數。通過對比神經網絡的預測參數和實測參數,可以評估基于神經網絡建立的信道模型的性能。因此,在無線信道建模中,以神經網絡為代表的機器學習算法不僅是對模型進行適當的參數擬合的最佳方法,更是對模型進行更新以獲得更精確的無線通信系統的方式。
當今用于信道建模的神經網絡類型分別有前饋神經網絡(FNN,feed forward neural network)[53]、反向傳播神經網絡[54]、徑向基神經網絡(RBFNN,radial basis function neural network)[55-56]和卷積神經網絡(CNN,convolutional neural network)[57]。一個完整的神經網絡包括輸入層、隱含層和輸出層,基本元件為神經元。當神經網絡用于回歸擬合時,其輸入層的數據稱為訓練集,訓練集通過不斷的訓練,使輸出層得到的參數逼近于實測值。隱含層中的神經元數量和層數根據一些規則和目標進行設置[58]。
電磁波在傳輸中會經歷大尺度衰落和小尺度衰落,大尺度衰落描述了長距離內接收信號強度的緩慢變化,小尺度衰落則描述了短距離或短時間內信號強度的劇烈變化。大尺度衰落特性的研究有助于分析信道的可用性、載波頻率的選擇以及無線網絡的優化,小尺度衰落特性的研究則有利于移動通信中傳輸技術的實現及數字接收機的優化[47]。本節根據輸出層所擬合的特性參數的不同,將神經網絡在信道建模中的應用分為大尺度衰落建模和小尺度衰落建模。目前,現有的研究根據訓練集、應用環境及頻段的不同對路徑損耗進行了建模。另外,為了得到性能最佳的訓練方案,有學者針對不同訓練集及神經網絡的結構做出了測試。相應地,小尺度衰落包含信道沖激響應、時延擴展、多普勒頻偏角度擴展等參數。最后,本節歸納出了神經網絡在信道建模中的3 類模型結構。
3.1.1 大尺度衰落建模
如圖5 所示,針對大尺度衰落,可以得到路徑損耗和陰影衰落。路徑損耗決定了蜂窩網絡的覆蓋距離和受干擾的程度,其依賴于傳播環境、頻帶及天線增益。陰影衰落在對數域服從均值為0 的正態分布,其標準差σ由路徑損耗模型的預測值和實測數據的統計偏差來表示[11]。傳統大尺度衰落中對路徑損耗和陰影衰落進行建模時,都是基于統計分布、經驗值進行通用計算的,而實際中不同場景的物理傳播環境、收發天線等參數對信道模型有著重要影響,傳統經驗公式很難體現這些維度的信息。神經網絡可以對高維度數據以及非線性映射關系進行訓練和計算,解決了傳統
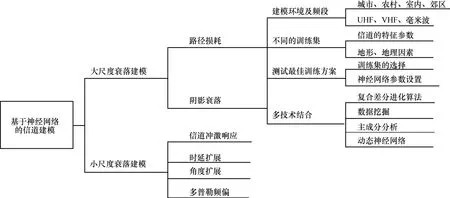
圖5 神經網絡在信道建模中的應用
、建模方法幾乎無法解決的問題[59]。研究表明,神經網絡適用于多種傳播環境下的路徑損耗建模,比如室內[60-61]、農村[62]、城市[63-66]和郊區[67-68]。如表2 所示,文獻[69-70]提出了一種用于礦井環境中超寬帶(UWB,ultra-wideband)信道路徑損耗的神經網絡模型,重點研究了路徑損耗衰減隨著時間和距離變化的情況。Ferreira 等[71]和Ayadi等[72]利用神經網絡來改善對超高頻(UHF,ultra high frequency)頻段(300~3 000 MHz)中室外信號強度的預測,測量是在城市環境中以1 140 MHz進行的,繞射損耗和信號強度被輸入神經網絡中,輸出層接收信號的強度來源于ITU-R 模型的計算結果,結果表明神經網絡可以改善UHF 頻帶中室外信號強度的預測。Faruk 等[59,73]研究了在甚高頻(VHF,very high frequency)頻段(30~300 MHz)下,路徑損耗與傳播距離之間的關系。Zhao 等[17]研究了在毫米波頻段(30~300 GHz)下路徑損耗與傳播距離之間的關系。
在信道建模中,神經網絡的訓練集通常為表征信道的特征參數,比如信號的幅值、頻率、相位等,但其并沒有綜合地理因素,而環境中的障礙物導致電磁波在傳播過程中發生了能量損耗,因此神經網絡的訓練集可以加入與地形地貌有關的變量。Lee等[74]提出了一種基于CNN 的毫米波路徑損耗的模型,該模型將三維地圖根據相應的特征(建筑物高度轉換為RGB(red,green,blue)的紅色通道值,發射機和地平面的高度轉化為RGB 的綠色通道值)轉化成二維RGB 圖,并以此作為輸入,利用三維射線追蹤算法來生成毫米波信道和相應的路徑損耗值(作為訓練輸出),測試表明,環境的變化對該模型的影響并不大,因此該模型具有較好的適應環境變化能力。文獻[75]中針對視距(LOS,line of sight)和非視距(NLOS,non-line of sight)建立了不同的城區路徑損耗預測模型。對于LOS,利用相關數據(如發射器和接收器的距離、建筑物的高度、街道的寬度、建筑物的分離度及相對于屋頂的發射天線的位置)訓練模型;對于NLOS,建立了2 個神經網絡模型,第一個模型使用LOS 中的相同參數進行訓練,第二個模型除了使用上述參數以外,還包括通過經典模型計算的繞射損耗,這種神經網絡和物理數據相結合的混合系統使結果更準確。文獻[71]則將深度神經網絡中的多層感知機(MLP,multi-layer perceptron)應用于UHF 頻段,輸入層為接發端的距離和繞射損耗,利用ITU-R 模型計算出的結果來訓練神經網絡的輸出層,神經網絡訓練后的平均偏差與ITU-R 模型相比降低了約8 dB。
對于路徑損耗模型的建立,訓練集的選擇及神經網絡參數的設置是影響性能的關鍵因素,在這種情況下,為了建立有效的模型并正確地進行路徑損耗預測,必須設計合適的訓練方案[76]。Popoola 等[77]使用實測數據訓練NN 模型,以了解輸出變量(路徑損耗)與輸入變量(訓練集)之間的非線性關系,例如傳輸頻率、建筑物高度、接收器天線高度、發射器天線高度等,從而確定實現最佳路徑損耗預測時的輸入向量和所需的神經網絡參數。結果表明,產生最佳性能的NN 模型采用4 個輸入變量(緯度、經度、海拔和距離),包含9 個隱含層,激活函數為雙曲線正切S 型。
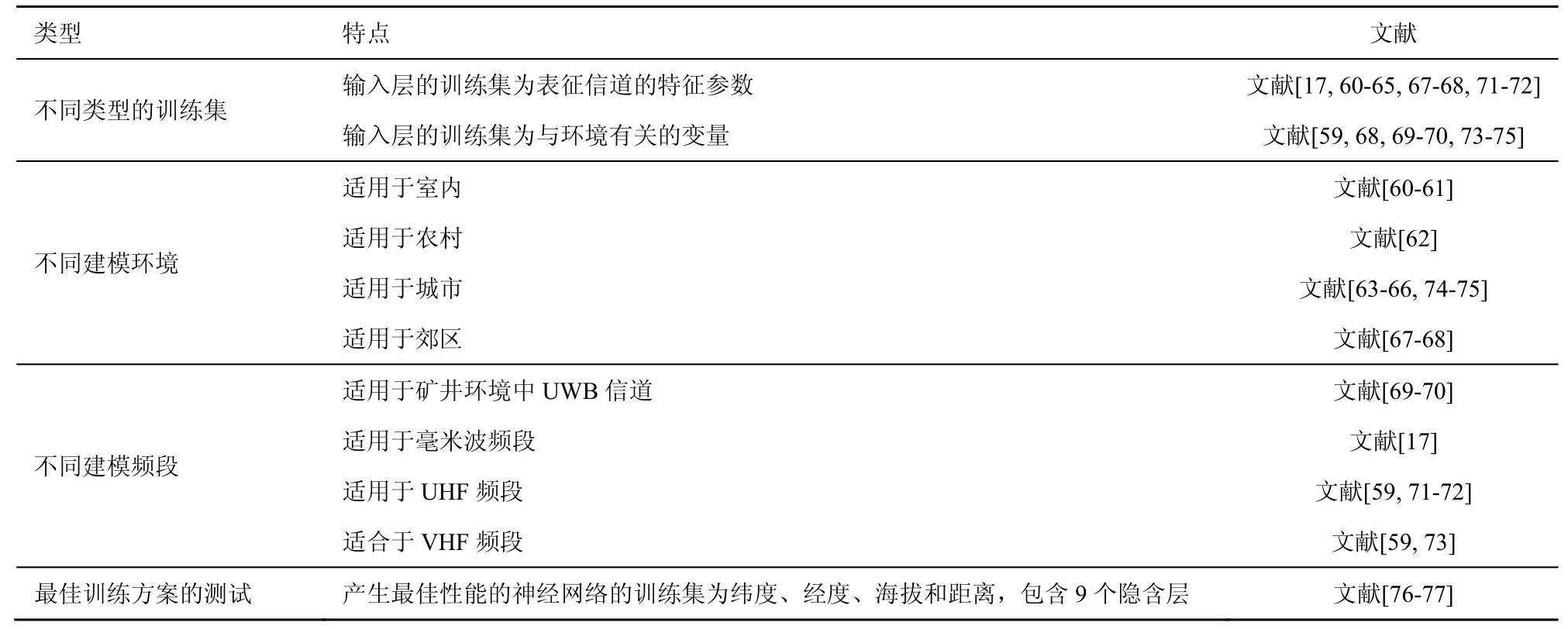
表2 基于神經網絡的大尺度衰落建模分類
此外,神經網絡還可以與一些算法或者技術相結合來優化路徑損耗模型的性能來提高模型的預測精度、效率或者擴展其適用的場景、頻段,如表3所示。Salman 等[73]評估了降維對路徑損耗預測精度的影響,通過實驗表明降維提高了機器學習模型的預測精度,且神經網絡預測路徑損耗的性能優于支持向量機。Sotiroudis 等[78]結合了復合差分進化(CDE,composite differential evolution)算法來構造模型,結果表明,CDE 算法高效、易于實現和調整,Sotiroudis 等還建議通過構建非均勻的環境數據集來提高NN 的泛化性和逼近能力。Zineb 等[79]構造了一種將神經網絡和數據挖掘技術相結合的新模型,該模型從多墻模型派生而來,適用于包括UMTS、GSM 和Wi-Fi 在內的多個頻帶,使用MLP框架以及BP 算法對測量數據(包括頻率、樓層衰減、收發器距離和頻率)進行訓練,該多頻段的多墻模型相比校正后的多墻模型表現出更好的性能和更高的精度。Bhuvaneshwari 等[80]評估了3 個動態神經網絡,即聚焦時延神經網絡(FTDNN,focusing on the time delay neural network)、分布式時延神經網絡(DTDNN,distributed delay neural network)和分層遞歸神經網絡(LRNN,layered recursive neural network)在路徑損耗預測中的應用,每個動態神經網絡都使用 LM(levenbergmarquardt)優化算法和 SCG(scaled conjugate gradient)算法進行訓練。結果表明,隨著計算時間的增加,LRNN 的性能最佳,FTDNN 的性能優于DTDNN。
3.1.2 小尺度衰落建模
目前,神經網絡在小尺度衰落建模的研究體現在對于不同場景和不同特征參數的建模,其特性參數和特點如表4 所示。Zhao 等[17]和Sun 等[81]利用RBFNN 對基于26 GHz 的5G 毫米波時變信道進行建模,并利用SAGE 算法提取出信道的多徑數和到達角來訓練RBFNN,從而實現可分辨的每一條路徑的接收功率和到達角的預測,最后將預測結果重新放到GBSM 中進行驗證。結果表明,提取的參數與實測數據吻合較好。Liu 等[54]為了得到信道傳遞函數,采用學習機和極限學習機(ELM,extreme learning machine)訓練神經網絡,結果表明ELM提供毫秒級學習的能力使它非常適于高速情況下的衰落信道建模。Bai 等[57]提出了一種針對毫米波頻段的三維MIMO 室內信道建模方法,該方法基于CNN 模型,輸入數據為發射機和接收機的坐標,輸出的特征參數包括接收功率、時延、發射方位角、發射仰角、到達方位角和到達仰角。
另外,也有文獻研究結合其他技術來優化小尺度衰落信道的建模。文獻[6,82]首先利用BPNN 去除實際測量中所帶來的噪聲,再利用PCA 提取CIR在頻域的幅值的主要特征,并根據子信道的相關性及CIR 在時域的統計特性得到其在頻域的相位,由此可以重構出時域的CIR。與GBSM 相比,該模型提升了MIMO 信道的容量。此外,還可以將神經網絡和三維射線跟蹤算法相結合[83],以計算室內無線信道的性能。該方法可以在仿真場景中使用較少的發射射線,并且利用神經網絡對射線發射中的中間點進行預測,從而降低計算復雜度,提高處理效率。

表3 模型的優化算法及特點
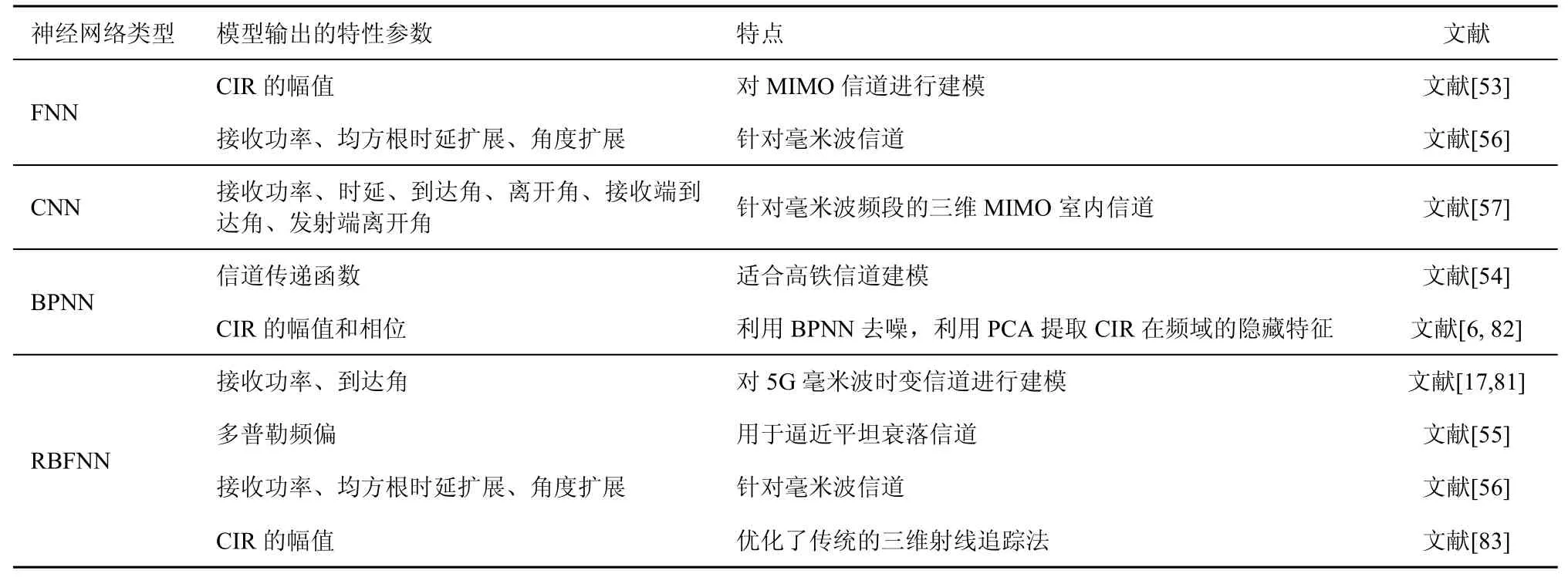
表4 基于神經網絡的小尺度衰落建模的特性參數和特點
3.1.3 通用的模型結構
由上述研究可知,在信道建模中神經網絡可用于信道特征回歸分析和參數預測,因此可以得到如圖6 所示的基于神經網絡的回歸模型,訓練該模型還用于信道估計、鏈路預算等。這種信道模型結合了神經網絡和回歸分析的優勢,可以更好地揭露復雜信道環境中變量之間的定量關系。該神經網絡輸出層的訓練參數來源于實測或者經典模型的計算值,其可以根據殘差、均方根誤差、回歸系數、標準偏差等評價指標來判斷信道性能的好壞,從而求得無線信道建模的精度。另外,還可以利用交叉驗證法來驗證模型的泛化能力[84]。
另一種信道模型結構端到端的自編碼器[4]如圖7所示。該自編碼器的發射端連接多層感知器和一個歸一化層,中間的加性白高斯噪聲信道用神經網絡的噪聲層表示,接收端則由MLP 和softmax 激活函數組成,該自編碼器基于端到端的誤比特率或誤塊率進行訓練。文獻[85]針對通信系統中數據速率受限的問題,對上述自編碼器結構進行了優化,提出了2 種新的傳輸方案。文獻[86]通過增加信道矩陣和復數乘法相關模塊,將這種自編碼器優化方法推廣到MIMO 上。
除了神經網絡以外,國內外的研究表明,SVM也可以應用在信道建模上[87],這體現在特定的場景中,比如多徑衰落信道[88]和礦井信道[89]。這是因為SVM 是建立在統計學習理論中VC 維(vapnik-chervonenkis dimension)理論和結構風險最小化原則基礎上的機器學習算法,它在解決小樣本、非線性和高緯度的問題上表現出獨特的優勢[90],并且SVM 已經成功地應用在無線通信、模式識別、生物信息等多個領域。
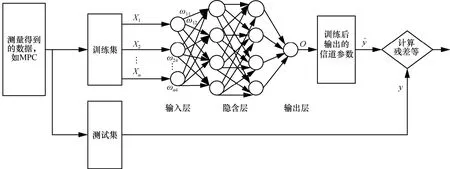
圖6 基于神經網絡的回歸預測信道參數的流程
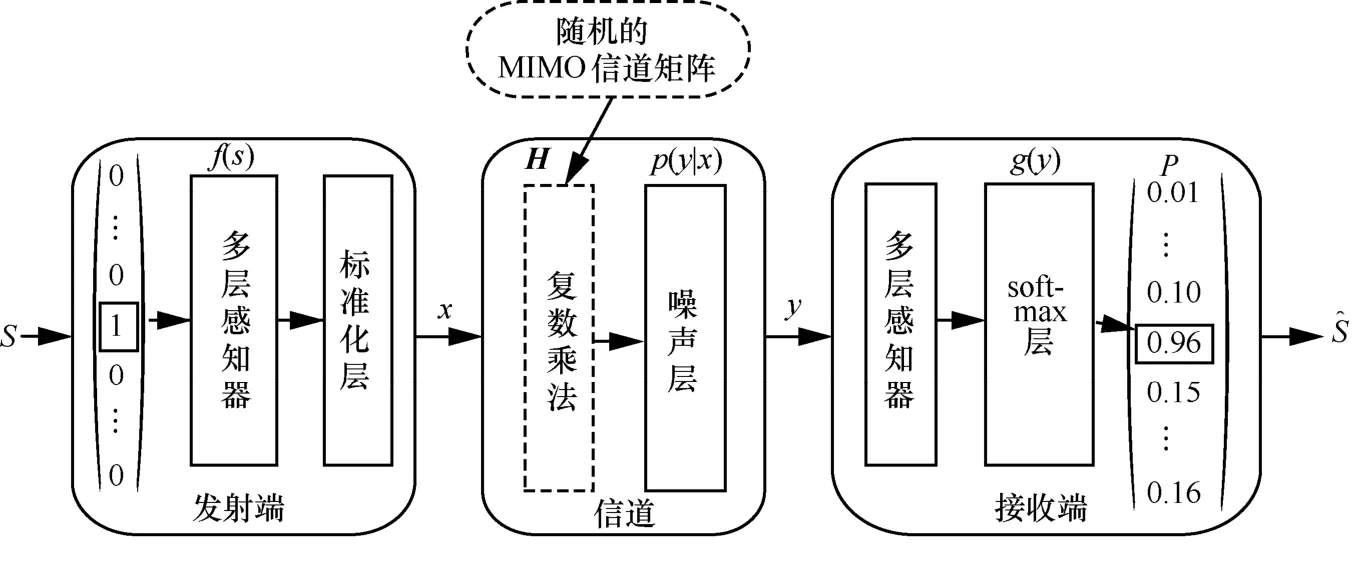
圖7 端到端的自編碼器架構
3.2 基于簇核的信道建模
與統計性建模相比,基于神經網絡的信道建模方法雖然提高了模型預測的準確度,但其復雜度和計算量通常較高。在應對未來移動通信系統需求的復雜多樣的應用場景上,其在建模高效性和模型通用性方面存在一定的局限性。而傳統基于簇的GBSM 雖然復雜度低,但難以應對大規模天線、高頻段大帶寬、應用場景多樣化等挑戰帶來的信道數據量激增,而且“簇”是從角度、時延等參數的統計定義,缺乏物理含義[2]。因此,以上2 種模型都難以同時滿足5G 系統對信道模型的高精度、低復雜、通用性的需求。
為了解決此問題,Zhang[2]提出了一種基于“簇核”的智能化信道建模新方法。簇核被定義為一種具有某種形狀,與傳播環境中散射體具有一定映射關系,且在各種場景下能夠主導CIR 生成的簇。基于此,提出了“多徑波、簇核、信道”的三層結構。由此結構出發,通過數據挖掘和機器學習,得到多樣場景、頻段、配置下簇核變化和生成信道的規律,從而預測出各種環境下的信道響應。
基于“簇核”的智能化信道建模方法的關鍵步驟是研究多徑簇與實際物理傳播環境中的散射體之間的匹配映射關系,而準確、自動地獲取傳播環境信息和散射體紋理信息是研究匹配映射關系的前提。
從電磁波傳播環境角度出發,通過機器學習算法獲取不同典型傳播環境中的物體類別標識,進而通過一定先驗知識獲得紋理標識,同時并行地對環境進行三維重構[41,91]。首先需要采用 SLAM(simultaneous localization and mapping)對場景的三維結構進行恢復[92]。然后對于每張圖片采用基于全卷積網絡的方法對環境照片進行語義分割,找到照片中每一個像素點所對應的最有可能的物體類別,再利用對物體的先驗知識對紋理材質進行標定。獲取每個像素點所代表的紋理標識之后即可將該標識與重構所得到的三維模型進行融合,得到統一表征的環境數據。所得到的傳播環境紋理可進行標識及尋找傳播環境中主要的散射體,為信道模型的學習提供環境模型。傳播環境的三維重構基本思路如圖8 所示。
圖9 為基于簇核的信道建模基本流程[2]。一方面,通過對不同場景和不同頻段進行信道測量,然后通過高精度參數估計算法,如SAGE,估計得到每條多徑的參數,并對MPC 進行分簇,類似于傳統的統計性建模過程。另一方面,利用計算機視覺和圖像處理方法識別環境中的紋理信息,并對實際傳播環境進行三維重構得到主要散射體,類似于確定性建模的過程。最關鍵的步驟是基于簇的特征和散射體的屬性,利用機器學習算法找到簇和散射體之間的匹配映射關系,建立確定性環境和統計簇之間的聯系。通過對多種場景、頻段、天線配置信道數據進行特性挖掘,可以得到相應場景的簇核,并通過有限數量的簇核得到信道CIR,實現信道建模。
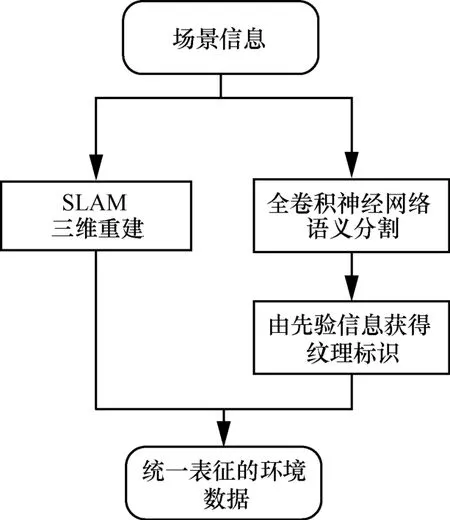
圖8 傳播環境的三維重構基本思路
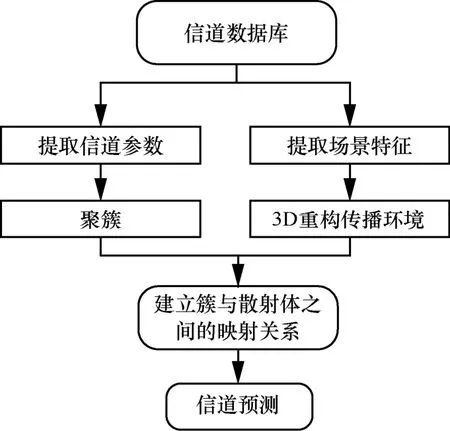
圖9 基于簇核的信道建模基本流程
由上述可知,無論是基于數據集的神經網絡建模,還是基于簇核的智能化建模,其模型能否滿足未來多樣化場景實時處理的需求,還需要進行較充分的評估。對于模型的評估,一個重要的參考項就是模型的泛化能力。盡管數據庫十分龐大,但是不能保證某一情境或者頻段下的數據一定是完整的,因此,是否可以通過改進模型的訓練方法使其能夠學習不同的數據空間,提高其泛化能力,使模型具有更好的擴展性,這對評估性能具有重要意義。另外,對于神經網絡建模來講,合適的網絡參數設置對模型的構造是十分重要的,但是目前并沒有完備的理論說明如何進行參數設置才有更好的輸出,通常都是人為調試,選擇結果較理想的一組參數用于最終模型的構造,那么對于參數的選擇還需要進行測試,這對建模來講仍然是一個較煩瑣的工作。
4 信道狀態分類/場景識別
無線信特征的差異可以用來區分不同的傳播模型,進而優化所屬的通信網絡。若能提取不同區域內無線信道的差異化特征,并根據實際情況進行必要的識別,則具有重要的科學意義與工程價值。比如列車由開闊地段進入隧道時可能會造成通信中斷,如果能識別對應的場景,進而針對不同場景進行具體分析,則對優化無線傳輸網絡的設計及模型的構造都具有重要意義。另外,對于精確的室內定位來說,視距和非視距信道產生的測量誤差相差很大[93],因此需要對信道進行識別。尤其是在5G 技術不斷發展的今天,為了能夠保證用戶在500 km/h 的速度下有更好的體驗,利用機器學習的方法迅速、準確地識別出無線信道場景,從而在不同環境下高效地完成信息傳輸任務,是非常值得研究探索的。
信道場景識別和信道狀態分類的核心思想是通過提取信道的差異化特征,并加以區分,從而判斷出目前信道所處的場景或狀態[94]。因此,該研究的難點包括以下2 個方面。1)信道特征參數的選擇及預處理。表征信道的參數有很多,比如路徑損耗、K因子、多普勒頻移等,考慮到實際測量的難度以及模型的識別效率,需要選擇具有代表性的信道參數。另外,還要根據數據的特征及選定的識別算法進行數據的預處理,比如當原數據有缺失或者異常時,可以對其進行清洗、進行插值或者異常值剔除,甚至需要對數據進行一定的變換,如傅里葉變換等。2)高效的分類算法。可用于場景識別的算法有很多,其大多來源于機器學習中的監督學習和非監督學習,比如SVM、神經網絡、GMM 算法等。因此要針對不同的應用場景,選擇合適的機器學習算法,并對其進行合理的訓練,從而構造具有高精度和高效率的無線信道場景識別模型。基于機器學習的無線信道場景識別的流程如圖10 所示。
目前,國內外針對無線信道場景識別的研究方法如表5 所示。
無線信道受到周圍環境的影響造成信道特征的差異,因此可以利用這些差異性的信道特征來區分不同的通信場景。由表5 可以發現,國內外針對無線信道場景識別的研究采用了神經網絡、決策樹、SVM、圖論等方法,基本思路可以概括為以下幾個方面。
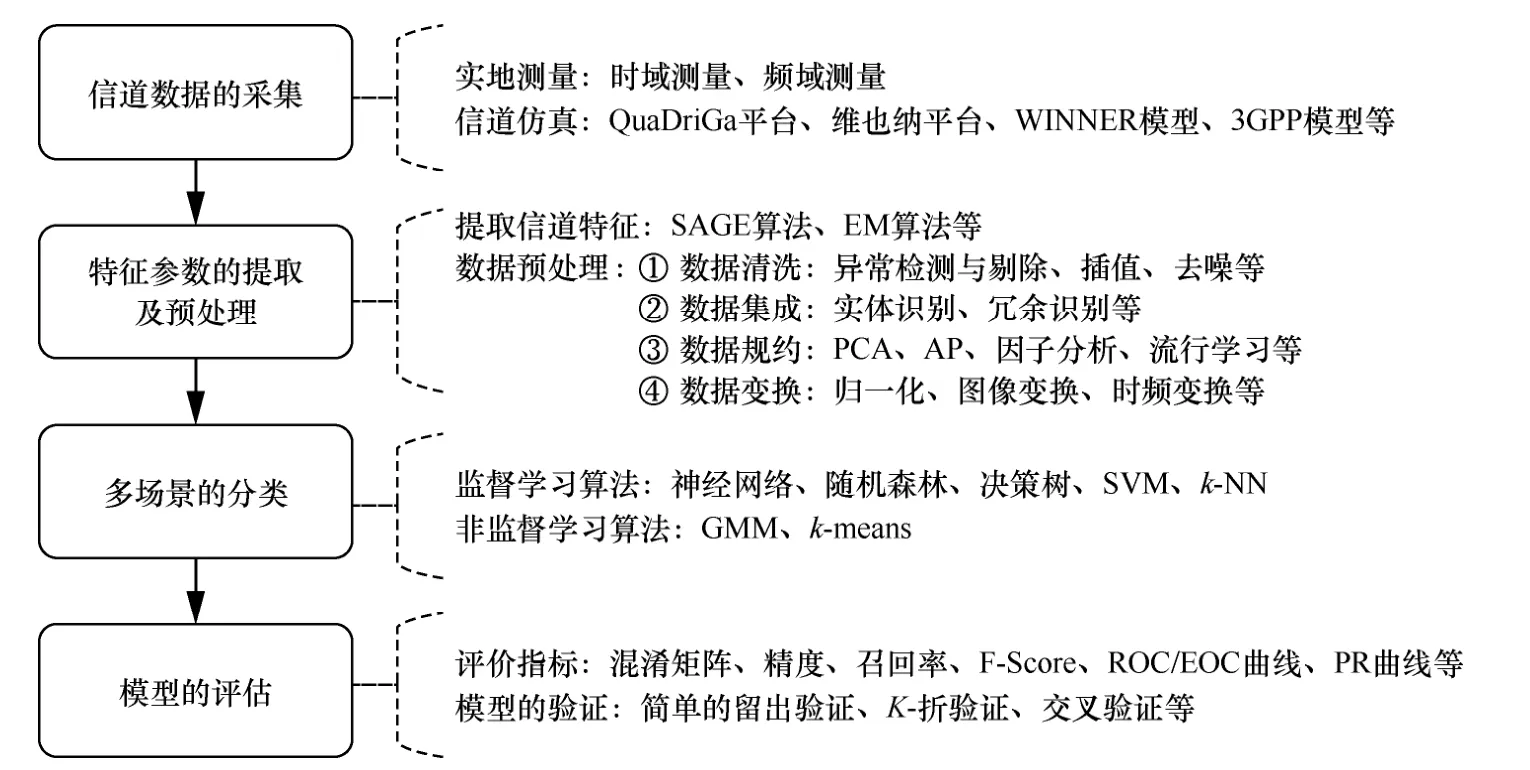
圖10 基于機器學習的無線信道場景識別的流程
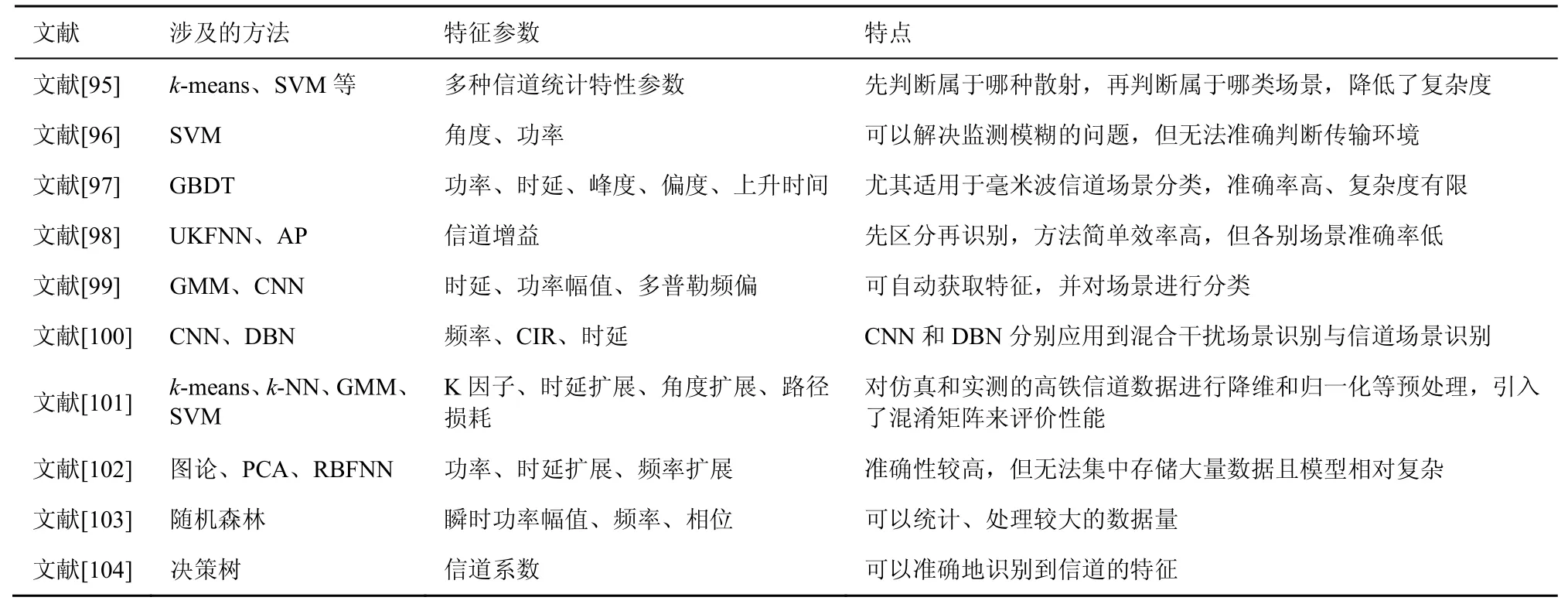
表5 國內外針對無線信道場景識別的研究方法
1)構造分類模型,即將數據分成某一大類(路段、區域等),再利用ML 細化識別為某一場景。周濤等[95]提出的高鐵信道場景下識別方案是先利用k-means 算法判斷其屬于哪類傳播場景,再利用相應的ML 算法判斷所處的原始場景。黃晨等[96]提出了一種基于SVM 的無線信道場景識別方法,該方法將采集的信道數據人為地分為LOS和NLOS兩類,再分別對兩類信道數據進行了特征提取和轉化,從而構造分類模型,最后對所構造的模型進行測試。Huang 等[97]提出了一種基于梯度提升決策樹(GBDT,gradient boosting decision tree)針對毫米波信道LOS 和NLOS 場景的分類方法。該方法首先從信道沖激響應中提取多種信道特征參數,然后分析不同特征參數相關性及對信道場景分類準確度的影響,并基于此建立了聯合多維參數的GBDT 信道場景分類方法,具有較高的識別準確率。李太福等[98]提出了一種基于無跡卡爾曼濾波神經網絡(UKFNN,unscented Kalman filtering neural network)和近鄰傳播(AP,affinity propagation)算法的識別方案,此方案根據信道狀態建立動態實時濾波效果的分段模型和分區模型,復雜度低,但個別場景下的準確率較低。
2)基于神經網絡的場景分類,先對數據進行一系列變換以滿足不同類型的神經網絡對輸入層的要求,再利用神經網絡進行分類。Li 等[99]利用GMM 算法獲取信道狀態信息,再將CSI 組成的信道特征矩陣輸入CNN 進行分類識別,該方案可以在較少的導頻資源下自動提取無線信道特征,從而降低計算復雜度和節約存儲資源。劉祥[100]使用2 種深度學習的算法識別無線信道場景:第一種是針對混合干擾信號建立了基于CNN 的復合干擾場景識別模型;第二種是基于測量的數據提取信道的時域、頻域及圖像域特征,引入深度信念網絡(DBN,deep belief network)模型進行分類識別。
3)先利用PCA 等方法實現數據降維,提取有效特征,再利用SVM/神經網絡/隨機森林等進行分類。Zhang 等[101]利用PCA 對仿真數據和實測的高鐵信道數據降維,利用混淆矩陣來評判識別結果,結果表明k-近鄰(k-NN,k-nearest neighbor)和SVM的準確率都超過了90%,GMM 算法的準確率可達89%。姚碧圓[102]依照圖論的知識剖析信道傳輸特性,利用PCA 對特征參數進行降維,再利用RBFNN對參數進行分類從而實現場景識別,該模型準確性較高,但無法集中存儲大量數據且模型相對復雜。陳能美等[103]根據隨機向量決策樹和多分類集成的構造原理,針對降維后的參數創建了識別信道場景的隨機森林分類模型,該模型可以高效地處理較大的數據量,但是模型準確率僅為89.9%。Wu[104]根據無線信道的特征建立了相應的決策樹分類模型,并在真實數據測試了模型,該模型可以更準確地識別出無線信道的特征。
與圖像、語音和文字等數據相比,高質量的信道測量數據很難獲取,一方面是由于信號的采集依賴于價格高昂的信號采集設備,另一方面則是在實際通信系統中,存在較多熱噪聲和突發干擾等因素,加大了信號采集的難度。而且,為了提高模型的識別范圍,多種場景、狀態下的通信數據是必不可少的。然而現在已公開的通信數據集較少,這給基于機器學習的模型訓練和測試帶來了難度,導致模型場景的識別效果很差,這就要求所建立的模型能夠從有限的數據中學習到其內在特征,同時要提高其泛化能力。因此,可以考慮將深度學習應用到信道場景識別中,這樣可以深入地挖掘信道特征,提高識別精度,比如結合圖神經網絡、遞歸神經網絡等,當然這對數據的處理也提出了較高的要求。
5 未來工作
本文綜述了機器學習應用于無線通信信道建模的理論框架。機器學習在無線通信信道建模中的科學解釋已經有了依據和理由,也帶來了更多的技術機遇。因此,與傳統的信道建模方法相比,即使人們對建模領域的機器學習提出了很高的要求,仍然可以通過采用有效的預測模型和方法來降低復雜性、提高準確性。但是,無線通信信道建模仍然存在一些需要解決的挑戰和阻礙,具體如下。
1)構建一個包含各種場景、配置、頻段的可信的海量信道數據庫。盡管一些科研組織具備的信道測量平臺及相關條件,但是不同的科研機構、單位、院校在數據的格式、標簽、整理方式上各不相同,如果將各種數據整理在統一要求的數據庫中將存在較大的挑戰。
2)特定場景下的有效信道建模,比如針對V2V信道、高鐵信道及大規模MIMO 信道的建模。與傳統場景下的信道模型相比,V2V 信道具有快速時變的特性,高鐵信道的傳播環境更復雜,大規模MIMO 信道具有空間非平穩特性,那么結合機器學習算法開發準確的參數提取算法并對不同場景有針對性地建模,有利于保證用戶有更好的情景體驗,因此如何利用機器學習的算法替代傳統的信道模型,仍是一個值得研究的課題。
3)結合大數據技術來改進信道建模,隨著5G時代的到來,天線數量、帶寬以及應用場景在不斷增加,這使信道測量和估計的數據量呈爆炸式增長,給數據的分析和處理帶來了很大的挑戰。是否可以通過結合統計分析技術和分布式計算技術來構建更高級的機器學習模型,以此提高訓練海量數據的預測準確性,還存在許多未解決的問題。
4)建立多徑簇與傳播環境散射體的匹配映射機理,掌握簇核的屬性和分布規律并實現自動匹配。利用計算機領域的數據挖掘和機器學習算法,適用于無線信道樣本中無線電磁波傳播特性的精確、高效挖掘,準確揭示出簇核在不同場景、頻段、移動速度、天線等參量下的簇核變化規律;基于簇核的信道建模理論達到“各種場景、各種配置”下的信道衰落預測的最高目標。
5)當前信道場景識別方案大都是利用監督學習的算法進行分類,然而通信數據集的標簽往往是缺失的,這對識別效果的影響很大,為了解決上述問題,也有研究使用非監督學習的算法比如GMM算法,但識別精度不是很理想,所以如何提高非監督學習算法在無線信道場景識別的精度是值得探索的。另外,目前的研究方法尚沒有對多種帶寬的場景進行討論,未來的研究可以以此來展開。
6 結束語
本文探討了機器學習在信道建模過程中的應用。首先介紹了信道多徑的分簇方法,這是為了識別出簇,進而為構建以簇為核心的信道模型的研究提供基礎,還介紹了利用機器學習優化經典的參數估計算法,從而幫助傳統參數估計算法應對信道大數據化的挑戰。其次,介紹了將神經網絡用以信道建模的優勢并總結了利用神經網絡構造大尺度衰落和小尺度衰落信道模型的過程,給出了其適用范圍和通用的模型結構。再次,提出了一種基于簇核的智能化信道建模方法,該方法結合了統計性建模和確定性建模的優勢,用以實現多種場景、配置、頻段的信道建模。最后,介紹了通過信道場景的識別,可以有針對性地根據不同場景選擇合適的模型,進而提高無線通信系統的傳輸效率。本文討論了在無線通信領域機器學習中一些有用的方法,如回歸擬合,可以得到性能更好、復雜度更低的信道參數;聚類,可以在復雜多變的環境中識別出簇;分類,對多樣的場景進行精準的分類識別。這些算法可以實現對測量數據的預處理,提取MPC 的特征,以及通過直接尋找環境和多徑簇之間的映射關系來對信道進行建模,可以有效地降低模型復雜度的同時實現準確建模。這些研究結果可以為未來5G之后的信道建模研究提供理論基礎。
到目前為止,即便學術界和工業界在利用機器學習對無線信道進行建模方面投入了大量的人力和物力,但涉及機器學習的無線信道建模領域仍處于初級階段。本文期望通過綜述機器學習在信道建模領域應用的已有研究成果,探討分析研究目標和方法,總結研究思路,從而為相關領域的研究人員提供參考和幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
