多管齊下復制網頁內容時去除多余字符
2021-03-10 08:57:48俞木發
電腦愛好者 2021年5期
俞木發
1.復制后的多余內容是怎么來的
類似從百度知道中復制網頁內容時出現的多余字符,其實是網站設置的一些代碼,增加的這些看似“多余”的字符,是制作者不希望讀者直接引用該內容,因此這些復制的內容只適合作為個人的參考資料,不適合發表。我們在使用時需要注意這個問題。
這些代碼不會在正常的網頁中顯示其內容,但復制粘貼后會顯露出來。比如圖1的例子,在網頁中右擊并選擇“查看網頁源代碼”,在打開的頁面中就可以看到在“簡單”和“來說”之間有段代碼,屬性值是“hidden”(即隱藏),代碼是“2112”(對應“bai”),這些代碼所對應的內容會在粘貼為文本形式后自動顯示(圖2)。

2.對癥下藥解決問題
既然多余字符是由于網頁中的代碼導致的,如果要解決這個問題,我們就需要根據不同的需求對代碼進行處理。
方法1:使用瀏覽器組件屏蔽代碼
現在很多瀏覽器都有“沉浸式閱讀器”,在這個模式下會自動屏蔽上述代碼。以在新核心的Edge中復制知乎頁面的內容為例,當我們在頁面上直接復制文本后,粘貼的文本沒有換行格式,而且會在內容的最后自動加上版權字段。如果在打開的頁面中點擊地址欄后的“沉浸式閱讀器”按鈕,進入該模式后再進行復制,粘貼后就不會有這些字符了(圖3)。
如果網頁(如上述的百度知道頁面)不支持“沉浸式閱讀器”,我們還可以在網頁中按下“Ctrl+A”組合鍵全選內容(或者使用鼠標選中需要復制的內容),接著在網頁中右擊并選擇“在沉浸式閱讀器中打開”,手動設置網頁使用沉浸式閱讀器瀏覽(圖4)。
此外,我們還可以使用打印模式進行復制,依次點擊Edge瀏覽器右上角的“…→打印”,接著在打開的打印窗口中進行文章的復制即可(在這個頁面中也會自動屏蔽上述代碼)(圖5)。
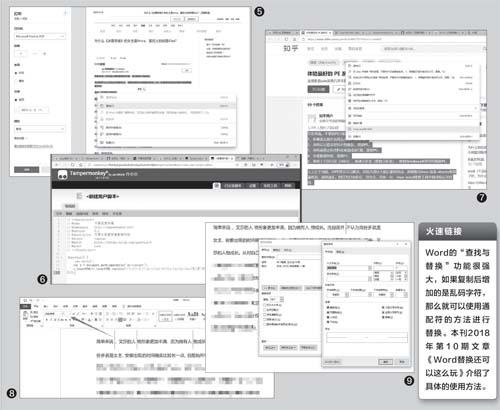
方法2:使用插件自動去除代碼
如果覺得上述的方法麻煩,那么還可以使用插件來去除。比如Edge的用戶,可在擴展商店中搜索并安裝“Tampermonkey”,啟動該插件后點擊“+”新建一個腳本,在腳本編輯頁中按下“Ctrl+A”組合鍵全選默認的內容并刪除。接著到“https://greasyfork.org/en/scripts/415814”下載腳本,下載后使用記事本打開并全選內容進行復制,接著粘貼到“Tampermonkey”的新建腳本窗口中,保存后即可使用(圖6)。之后再打開百度知道頁面,按下F5鍵刷新頁面,再次復制內容,其中就不會包含那些字符了。
如果要去除類似知乎網站復制后自帶的字符,則可以使用CopyAsPlainText插件(同樣在Edge插件商店中搜索并安裝即可)。完成插件的安裝后,在需要復制文本時右擊并選擇“CopyAsPlainText”,這樣粘貼后就是選擇的文本了(圖7)。
方法3:使用Word查找替換
很多朋友喜歡將資料粘貼到Word中保存和整理,利用Word的“查找和替換”功能也可以快速完成整理操作。比如當需要將百度知道中多余的字符刪除時,可在網頁中選中需要復制的資料,接著使用鼠標將選擇的內容拖拽到Word窗口中。拖拽完成后,在Word窗口中可以看到,其中字體為微軟雅黑、字號為1的內容就是“bai、du、zhi、dao”這類的多余字符(這里為了方便文章顯示,手動將“dao”設置成了二號字體顯示),因此要刪除這些內容,我們只要將字號為1的內容替換為空即可(圖8)。
具體方法是,點擊“ 查找和替換”,點擊“查找”下的“格式→字體”,在打開的窗口中,字體選擇微軟雅黑、字號選擇1,替換為留空,點擊“全部替換”即可(圖9)。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
科學大眾(2022年11期)2022-06-21 09:20:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
