基于不確定性感知的語音分離方法*
2021-03-12 11:24:20涂斌煒呂俊
自動化與信息工程 2021年1期
涂斌煒 呂俊
技術應用
基于不確定性感知的語音分離方法*
涂斌煒 呂俊
(廣東工業大學自動化學院,廣東 廣州 510006)
為抵御噪聲的干擾,提出一種基于不確定性感知的語音分離方法。在訓練階段,采用雙鏈路架構分別學習噪聲和語音源成分的編解碼子網和分離子網;在測試階段,以閉式解的形式自適應更新噪聲編碼子網,減小訓練與測試噪聲在特征空間的均值偏移,降低認知不確定性,并盡量保持重要參數不變,間接限制語音分離的經驗誤差。在公開數據集LibriSpeech, NoiseX和NonSpeech上的實驗結果表明:本文提出的方法能夠快速有效地提高噪聲干擾下語音分離的尺度不變信噪比。
語音分離;噪聲干擾;不確定性感知
0 引言
語音分離一詞最初源于“雞尾酒會問題[1]”,是指從混合的兩個或多個說話人的聲音中得到想要的目標說話人(一人或多人)的語音信號,廣泛應用于語音識別、情感識別或翻譯等任務的前端處理。按信號輸入的通道數劃分,語音分離可分為單通道語音分離和多通道語音分離2種。本文主要討論單通道語音分離技術。
單通道語音分離技術又分為有背景噪聲和無背景噪聲2類。無背景噪聲的單通道語音分離技術發展較早,常見方法包括基于聽覺場景分析[2]、基于非負矩陣分解[3-4]和基于深度神經網絡的語音分離方法[5-6]。這些方法推動了單通道語音分離技術的發展,但沒有考慮噪聲干擾的影響,與真實使用場景相差較大。
近年,許多專家學者逐漸關注有背景噪聲的單通道語音分離技術。文獻[7]~文獻[9]通過串聯方法將語音降噪網絡和語音分離網絡結合起來,該方法已被證明能夠改善嘈雜環境下的語音識別性能;文獻[10]通過多場景訓練方法將語音降噪和語音分離結合在一起,2個任務共用1個網絡。上述方法改善了語音分離技術在噪聲環境下的分離效果,但沒有考慮異常噪聲帶來的分布差異問題。由于噪聲具有較強的多樣性,因此測試信號中難免會出現與訓練集噪聲相差較大的噪聲信號,這些異常噪聲會嚴重影響語音分離效果。
為抵御噪聲的干擾,本文提出一種基于不確定性感知的語音分離方法(speech separation based on uncertainty perception, SSUP)。該方法采用變換域特征的均值偏移來度量預測不確定性,采取雙鏈路網絡結構,通過自適應更新噪聲編碼網絡的參數,減小噪聲帶來的均值偏移,同時采用彈性權重固化(elastic weight consolidation, EWC)策略[11],間接保持較小的訓練集經驗誤差。
1 分離網絡
1.1 問題描述
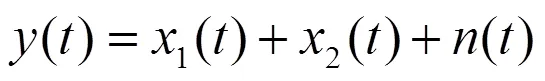
1.2 網絡結構
現有的單通道語音分離方法主要采用單鏈路架構[12-13]。但由于噪聲與語音信號的分布不一樣,采用不同的表達方式更合理。本文提出的SSUP采用雙鏈路網絡架構,如圖1所示。
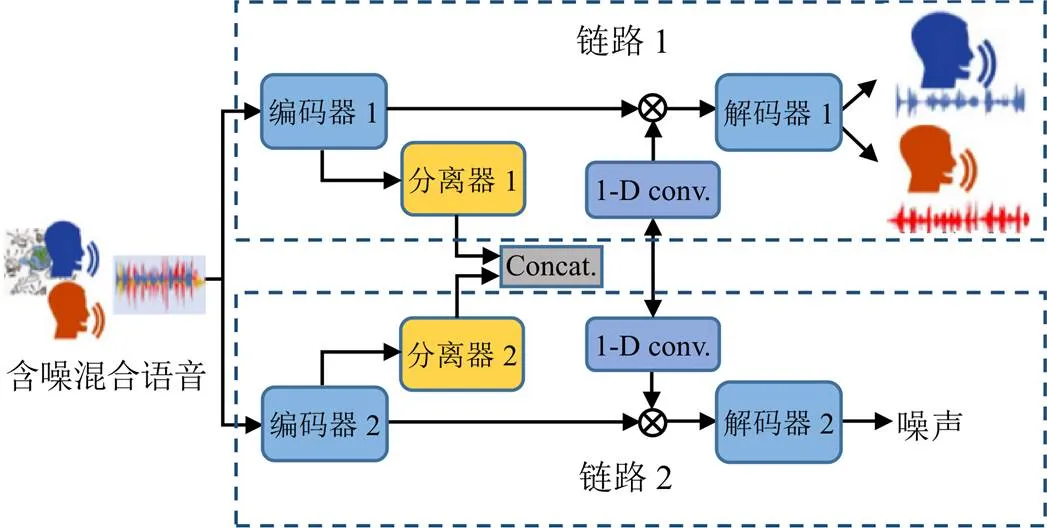
圖1 SSUP雙鏈路網絡架構
SSUP雙鏈路網絡包括網絡結構相同的2個鏈路,每個鏈路皆包含編碼器、分離器和解碼器3個主要部分。編碼器和解碼器分別為一維卷積和一維逆卷積網絡;分離器由多個雙路循環神經網絡(dual-path RNN, DPRNN)模塊組成[12]。其中,鏈路1的輸出為2個說話人的語音信號,鏈路2的輸出為噪聲信號。首先,在訓練集中訓練得到初始模型;然后,根據每條測試信號,有針對性地更新鏈路2中編碼器的參數,并保持其他參數不變。
依據驗證集的分離性能,SSUP雙鏈路網絡的參數設置如表1所示。模型訓練采用的優化器為Adam,迭代步長為10-3,迭代次數為100。
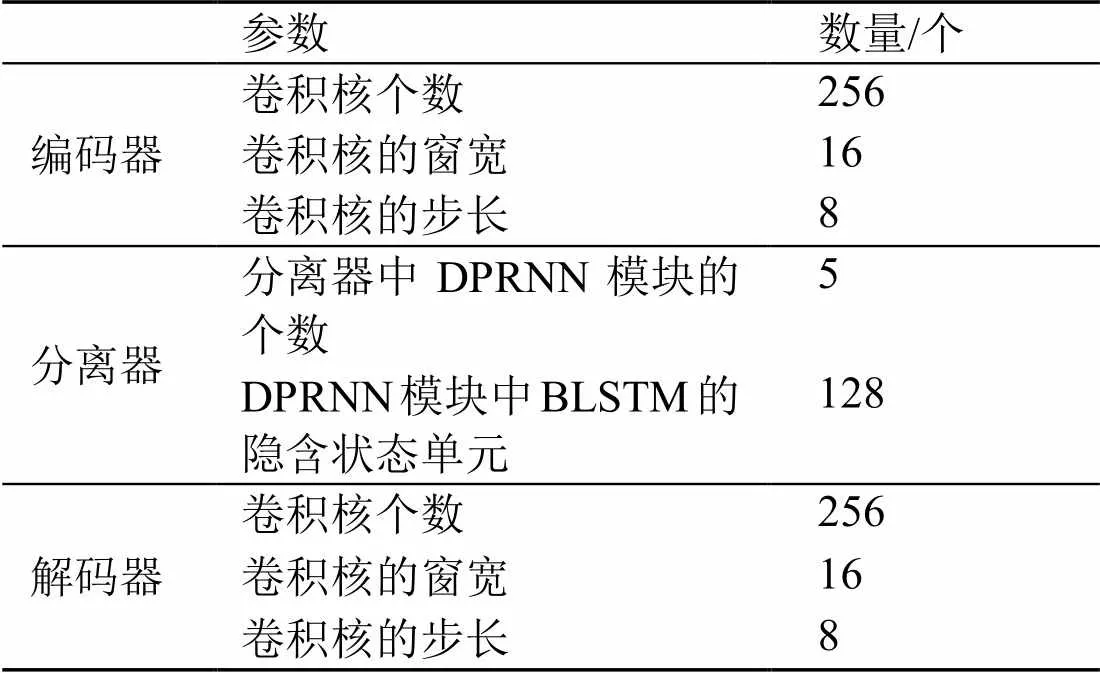
表1 SSUP雙鏈路網絡參數設置
1.3 訓練目標
網絡最終輸出是估計信號的時域波形。本文采用的訓練目標為最大化尺度不變信噪比(scale-invariant source-to-noise ratio, SI-SNR)[14]。在單通道語音分離中,標準的信號失真比(source-to-distortion, SDR)可能出現誤導性結果,即在感知上并沒有改變估計信號的情況下,僅依靠縮放估計信號便能提高SDR值,然而這種提高沒有實際意義[14]。為避免這種情況,SI-SNR取代SDR作為語音分離的評價指標[12,15],其定義為

2 基于不確定性感知的語音分離
2.1 不確定性感知
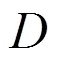
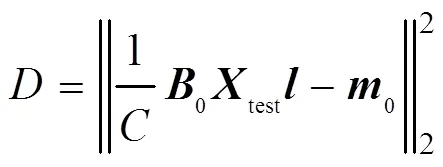
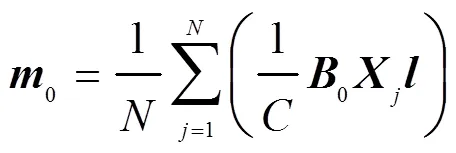
2.2 參數更新方法
測試信號與訓練集的編碼特征分布應盡量接近,以減小分離模型的認知不確定性。與此同時,采用彈性權重固化策略[11],間接保持較小訓練集經驗誤差,自適應地學習有利于目標信號實現語音分離的變換域。因此,設計代價函數為
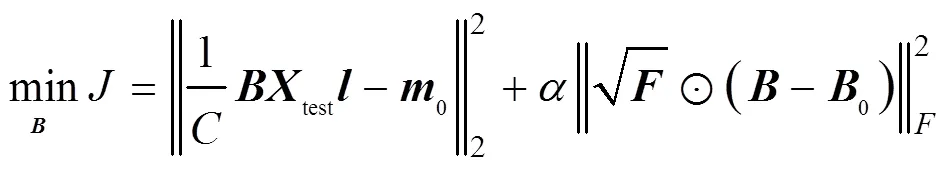

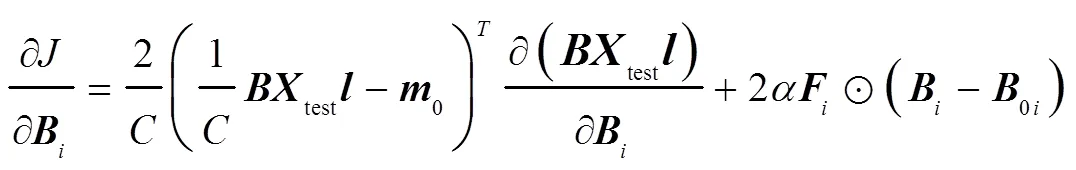
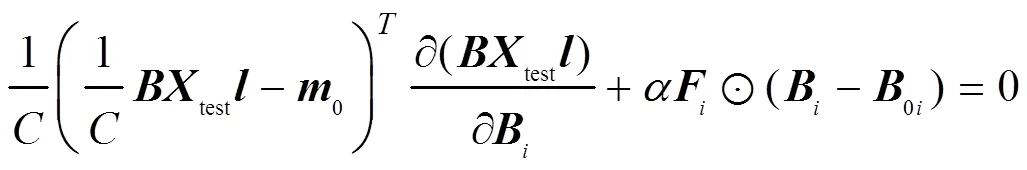
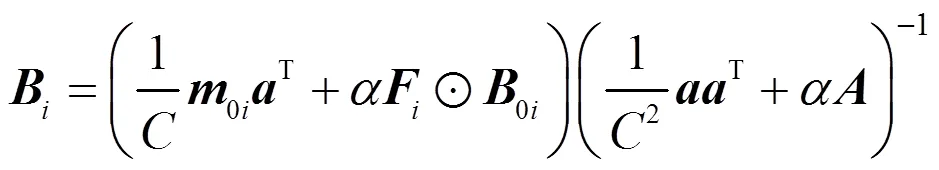
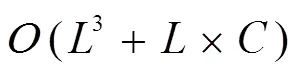
若不引入費雪信息,式(5)的最后一項是Frobenius范數正則化約束,此時式(5)可改寫為
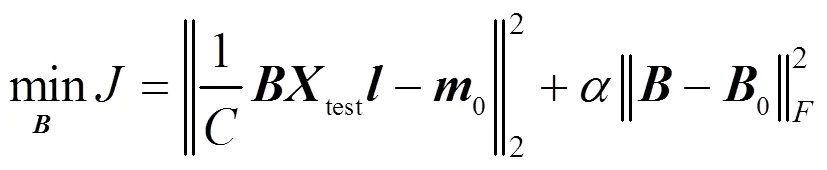
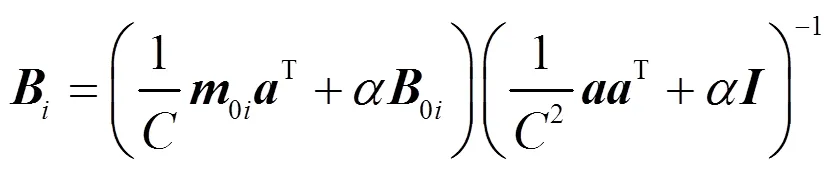
2.3 噪聲信號在特征空間上的均值偏移
為探究噪聲信號在特征空間上的均值偏移,本文從Nonspeech數據集中選取8種不同的噪聲數據[19],與語音信號生成8個測試集,每個測試集的樣本個數和所采用的語音信號皆相同。計算每個測試集的噪聲特征至訓練集噪聲特征中心的平均偏差為
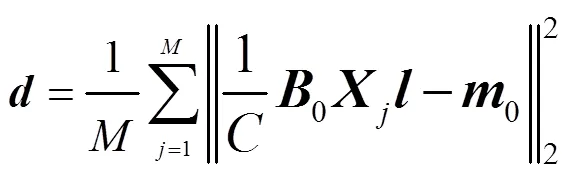
8種不同噪聲特征至訓練集噪聲特征中心的平均偏差如圖2所示。
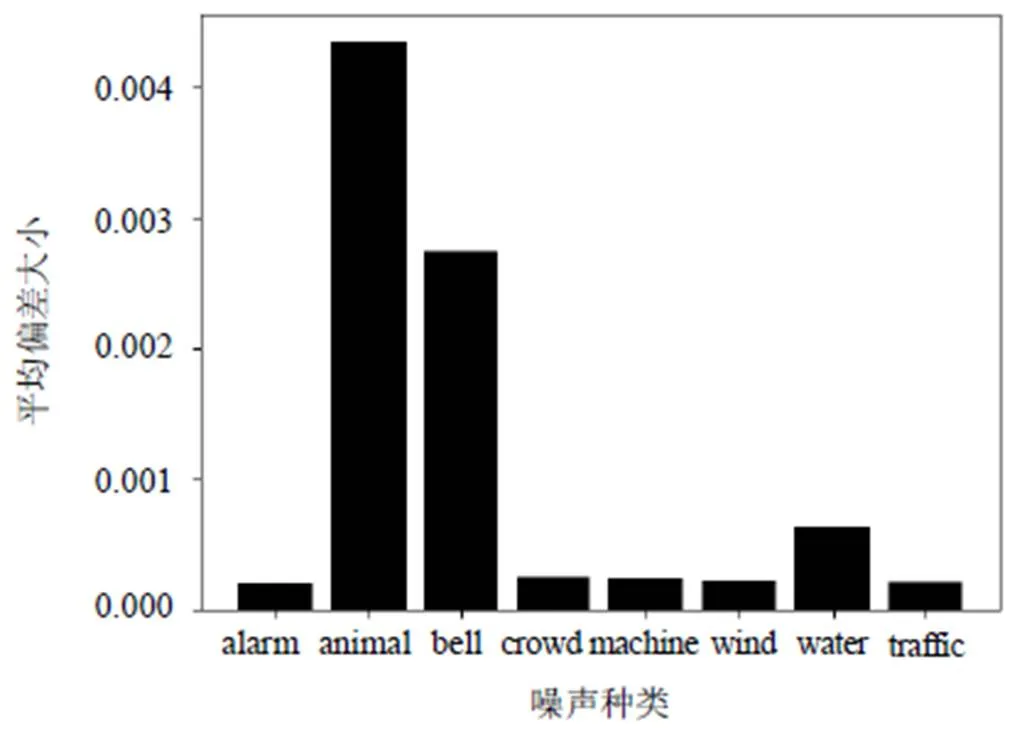
圖2 8種不同噪聲特征至訓練集噪聲特征中心的平均偏差
由圖2可知:animal和bell這2種噪聲的編碼特征偏離訓練數據均值中心0的程度非常明顯,給語音分離模型帶來較大的泛化風險;而另外6種噪聲的編碼特征偏離均值中心比較小,可見并非所有的噪聲都會在特征空間上帶來嚴重的均值偏差。因此,需要設置1個閾值,只有滿足閾值要求的測試信號才會觸發參數更新。
2.4 參數更新觸發條件
本文采用變換域特征的均值偏移來度量預測不確定性。針對不確定性較大的測試數據,將進行參數的動態調整。因此,設置了1個不確定性閾值,計算公式為
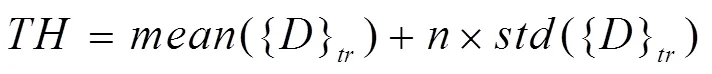
當測試信號的值大于,通過式(8)或式(10)對編碼器2的參數進行更新。
3 實驗及參數分析
3.1 實驗設置
實驗采用的深度學習框架為Pytorch,服務器CPU為8核3.90 GHz AMD Ryzen 3700X,內存為 32 GB,GPU為Nvidia RTX 2080 Ti。
本文采用公開的語音數據集LibriSpeech[20],噪聲數據集NoiseX[21]和Nonspeech[19]進行實驗。為方便網絡訓練,所有數據統一采樣率為8 kHz。本文的語音數據全部來自于LibriSpeech數據集中的“train-clean-100”子集,該子集包含了100 h來自251個不同個體的語音數據。首先,取任意2個不同說話人的語音以-2.5 dB~2.5 dB的任意比例混合,得到干凈的2個說話人的混合數據;然后,選取NoiseX數據集中的10種噪聲生成訓練集數據,同時將Nonspeech數據集中的8種噪聲生成測試集數據,詳情如表2所示。其中,噪聲與說話人聲按-5 dB~10 dB的任意信噪比混合,訓練集的樣本個數為8000,測試集中每種噪聲數據的樣本個數為3000。

表2 噪聲數據集
3.2 實驗結果
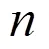

表3 4種方法的分離性能比較
由表3可知:1) BPU取得了比單鏈路更好的分離性能,說明雙鏈路網絡方法是有效的;2) FNR和FIW-FNR方法獲得的SI-SNR指標高于BPU,其中FIW-FNR是4種方法中分離性能最好的,可見本文提出的參數更新方法可以改善模型的分離性能。
3.3 參數分析
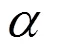
表4 取不同值時,3種方法的SI-SNR指標
表5 取不同值時,3種方法的SI-SNR指標
3.4 運行效率
針對每一條測試信號,本文提出的基于不確定性感知的語音分離方法都可以通過式(8)或式(10)閉式更新噪聲編碼網絡參數,而無需經過反向梯度傳播,從而保證了模型的運行效率。經過測試1000條數據,FIW-FNR方法平均處理一條測試信號的時間約為(0.150.01) s(每條數據長度為5 s)。
4 結語
為減小噪聲的干擾,本文提出一種基于不確定性感知的語音分離方法。針對每一條測試信號,自適應更新噪聲編碼網絡的參數,減小噪聲帶來的均值偏移,并盡量保持重要參數不變,間接限制語音分離的經驗誤差。該方法具有閉式解,執行效率高,能夠快速調整編碼網絡參數,增強語音分離模型對環境噪聲的泛化能力。
[1] BELL A J, SEJNOWSKI T J. An information-maximization approach to blind separation and blind deconvolution[J]. Neural Computation, 1995,7(6):1129-1159.
[2] WANG D L, BROWN G J. Computational auditory scene analysis: principles, algorithms, and applications[J]. IEEE Trans. Neural Networks, 2008,19(1):199.
[3] LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755):788-791.
[4] 李煦,屠明,吳超,等.基于NMF和FCRF的單通道語音分離[J].清華大學學報(自然科學版),2017,57(1):84-88.
[5] WANG D L, CHEN J. Supervised speech separation based on deep learning: an overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018,26(10):1702-1726.
[6] 劉文舉,聶帥,梁山,等.基于深度學習語音分離技術的研究現狀與進展[J].自動化學報,2016,42(6):819-833.
[7] MA C, LI D, JIAN X. Two-stage model and optimal SI-SNR for monaural multi-speaker speech separation in noisy environment[J]. arXiv preprint arXiv: 2004.06332, 2020.
[8] LIU Y, DELARIA M, WANG D L. Deep casa for talker- independent monaural speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020: 6354-6358.
[9] WANG X, DU J, CRISTIAN A, et al. A study of child speech extraction using joint speech enhancement and separation in realistic conditions[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 7304-7308.
[10] WU Y K, TUAN C I, LEE H Y, et al. SADDEL: Joint Speech separation and denoising model based on multitask learning[J]. arXiv preprint arXiv: 2005.09966, 2020.
[11] KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521-3526.
[12] LUO Y, CHEN Z, YOSHIOKA T. Dual-Path RNN: efficient long sequence modeling for time-domain single-channel speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020:46-50.
[13] LUO Y, MESGARANI N. Conv-tasnet: surpassing ideal time- frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256-1266.
[14] ROUX J L, WISDOM S, ERDOGAN H, et al. SDR half-baked or well done[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019: 626-630.
[15] LUO Y, CHEN Z, MESGARANI N. Speaker-independent speech separation with deep attractor network[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2018, 26(4):787-796.
[16] TAGASOVSKA N, LOPEZ-PAZ D. Single-model uncertainties for deep learning[C]. In Advances in Neural Information Processing Systems, 2019: 6414-6425.
[17] WELLING M, YEE W T. Bayesian learning via stochastic gradient Langevin dynamics[C]. Proceedings of the International Conference on Machine Learning (ICASSP), 2011: 681-688.
[18] GAL Y, GHAHRAMANI Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning[C]. Proceedings of the International Conference on Machine Learning (ICML), 2016: 1050-1059.
[19] HU G, WANG D L. A tandem algorithm for pitch estimation and voiced speech segregation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010,18(8): 2067-2079.
[20] PANAYIOTOU V, CHEN G, POKEY D, et al. LibriSpeech: an ASR corpus based on public domain audio books[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015: 5206-5210.
[21] VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ii.noisex-92: A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993,12(3): 247-251.
Speech Separation Method Based on Uncertainty Perception
Tu Binwei Lü Jun
(School of Automation, Guangdong University of Technology, Guangzhou 510006, China)
In order to resist the disturbances of noises, we proposed a speech separation method based on uncertainty perception. In the training phase, a two-link architecture is adopted to learn the codec subnet and separate subnet of noise and speech source components respectively. In the testing phase, the noise coding subnet is updated adaptively in the form of closed solution, so as to reduce the mean deviation of training and testing noises in the feature space, reduce cognitive uncertainty, keep the important parameters unchanged as far as possible, and indirectly limit the empirical error of speech separation. Experimental results on the public datasets LibriSpeech, NoiseX and NonSpeech show that the proposed approach can rapidly and effectively improve the scale-invariant source-to-noise ratio of speech separation under the interferences of unknown noises.
speech separation; noise interference; uncertainty perception
TN912
A
1674-2605(2021)01-0008-06
10.3969/j.issn.1674-2605.2021.01.008
廣東省自然科學基金(2018A030313306)
涂斌煒,男,1995年生,碩士研究生,主要研究方向:機器學習,語音分離。E-mail: tubinwei@mail2.gdut.edu.cn
呂俊(通信作者),男,1979年生,博士,副研究員,主要研究方向:生物信號檢測與識別。E-mail: lujun.rylj@gmail.com
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
