
基于事件提取和改進MMHC的航空旅客運輸事故征候貝葉斯網絡建模*
2021-03-12 02:30:54周志鵬諸澤宇
中國安全生產科學技術 2021年2期
關鍵詞:語義
周志鵬,諸澤宇
(南京航空航天大學 經濟與管理學院,江蘇 南京 211189)
0 引言
由于航空旅客運輸事故的偶然性以及事故后果的嚴重性,事故預防始終是各地區發展航空業的首要任務。在航空旅客運輸過程中,事故征候相較事故,出現頻率更高。事故征候指非失事而關系飛機運行,并影響飛行安全的事件。導致事故發生的致因因素同樣存在于事故征候中,事故征候與事故的差異僅在于某個偶然因素,部分條件的改變可能導致其演化為事故,進而造成人員傷亡或財產損失。
目前事故征候研究主要集中于某類特定事故征候,如跑道超限[1]、尾流[2],或某個特定飛行階段,如著陸[3]、滑行[4]。然而,事故征候之間、致因因素之間、致因因素與事故征候之間相互引起與被引起的關系,構成客觀存在的事故征候網絡,這在機場運營過程中具有一定普遍性。因此研究事故征候網絡的演化機理和風險控制措施,有利于進一步拓展和完善民航事故致因理論,同時各要素間的耦合作用的解析有助于控制事故征候風險,阻止其演變為事故,提升民航系統的安全管理水平。
基于歷史事故數據的分析和關鍵信息的提取,學者運用概率統計[5]與數據挖掘[6]技術研究事故征候機理。Arnaldo等[7]運用貝葉斯推理和層次分析,構建具有不同復雜性和目標的統計估計和預測模型,識別飛行器的異常情況。Rao等[8]基于美國國家運輸安全委員會事故數據庫中民用直升機事故案例,識別高風險致因序列,構建機上失控事故致因鏈。現有研究中致因因素數據通常直接來源于數據庫或依賴于低效的人工提取。不同數據庫、不同學者對于事故征候致因的表述方式尚未形成統一,阻礙了數據互通。如何高效準確地分析事故征候報告并提取致因信息是當前民航安全管理工作面臨的主要挑戰之一。
本文擬基于實際案例數據集與事件提取技術,提取事故征候敘述文本中的致因事件集合,運用貝葉斯網絡學習算法,解析致因事件之間、致因事件與結果事件之間的因果關系,構建航空旅客運輸事故征候貝葉斯網絡(Bayesian Network of Civil Aviation Passenger Transport Incidents,CAPTI-BN)。基于網絡建模結果,量化分析航空旅客運輸風險以及各致因事件參數特征,識別關鍵致因事件。
1 模型要素定義
貝葉斯網絡是分析事故因素間相互作用及其演化過程的有效工具[9-10]。在化工[11]、道路交通[12]等領域,學者利用模型中基于局部條件的依賴關系,進行雙向不確定性研究,對事故致因之間、事故與事故致因之間的關聯性進行量化分析[13],為風險評估、事故預測提供決策支持。在貝葉斯網絡(Bayesian Network,BN)中,基于BN中節點的有向關聯,P(XN)計算方法如式(1)所示:
(1)
式中:XN為節點集合;P(XN)為節點聯合概率分布;Xn為XN中的節點元素;Xpa(n)為節點Xn的父節點集合;P(Xn|Xpa(n))為父節點狀態已知情況下Xn的條件概率。
因此,貝葉斯網絡由節點、有向弧、概率3部分組成。CAPTI-BN中事故征候的演化機理是網絡的描述對象,致因事件和結果事件為網絡的節點。有向弧和節點概率分布則用于表征致因事件之間、致因事件與結果事件之間的因果關系。
定義1:致因事件指在事故征候演化過程中,對事件結果有直接影響的參與者行為。致因事件的主體要素包括機組成員、管制人員等機場工作人員,飛行器及其關聯設備以及飛機運行的天氣條件。因此,根據主體要素,致因事件包含人的不安全行為或狀態、飛行器的不安全動作、不良的天氣條件3種類型。
定義2:結果事件指在事故征候演化過程中致因事件引起的主體要素相應措施和狀態變化。
ASRS(Aviation Safety Reporting System)數據庫創建于1976年,是目前數據規模最大、發展最完善的航空安全自愿報告系統,是本文致因事件和結果事件類型劃分的主要參考依據。根據ASRS案例字段的分析,本文選取Human Factor,Anormal,Result 3個字段,其中,Human Factor主要記錄事故征候中人的不安全狀態。Anormal字段記錄事故征候中機組成員、飛行器、管制人員、天氣環境等主體要素的異常動作。Result字段記錄主體要素由事故征候導致的狀態和動作的變化。根據致因事件和結果事件定義,上述3個字段中,Human Factor與Anormal字段主要描述事故征候中致因事件的信息,而Result字段則描述結果事件信息。本文針對上述字段,重新進行人工分類與編碼,提出航空旅客運輸事故征候中致因事件和結果事件的類型和編碼,見表1。AE表示飛行器致因事件,HE表示人為致因事件,WE表示天氣致因事件,R表示結果事件。
此外,ASRS數據庫的Narrative字段記錄事故征候過程的敘述文本,該字段將作為后續事件提取算法的數據集。
2 事故征候貝葉斯網絡建模
2.1 致因事件提取
在自然語言處理領域,ACE[14](Automatic Content Extraction)項目對事件的定義是涉及參與者的特定事件或是事物狀態的變化。與本文的致因事件概念存在相似性。致因事件提取可認為是民航語境下的事件提取任務。因此,結合ACE中事件提取任務的定義,本文對致因事件提取任務范圍進行界定。致因事件提取的3個子任務包括事件觸發詞提取、事件參數提取以及致因事件分類,見表2。致因事件提取是1個語義識別和文本分類的過程。與文獻[15]類似,本文引入抽象語義表達(Abstract Meaning Representation,AMR)的思想,將事件中觸發詞、參數間語義關系轉化為句子成分的語法結構關系。
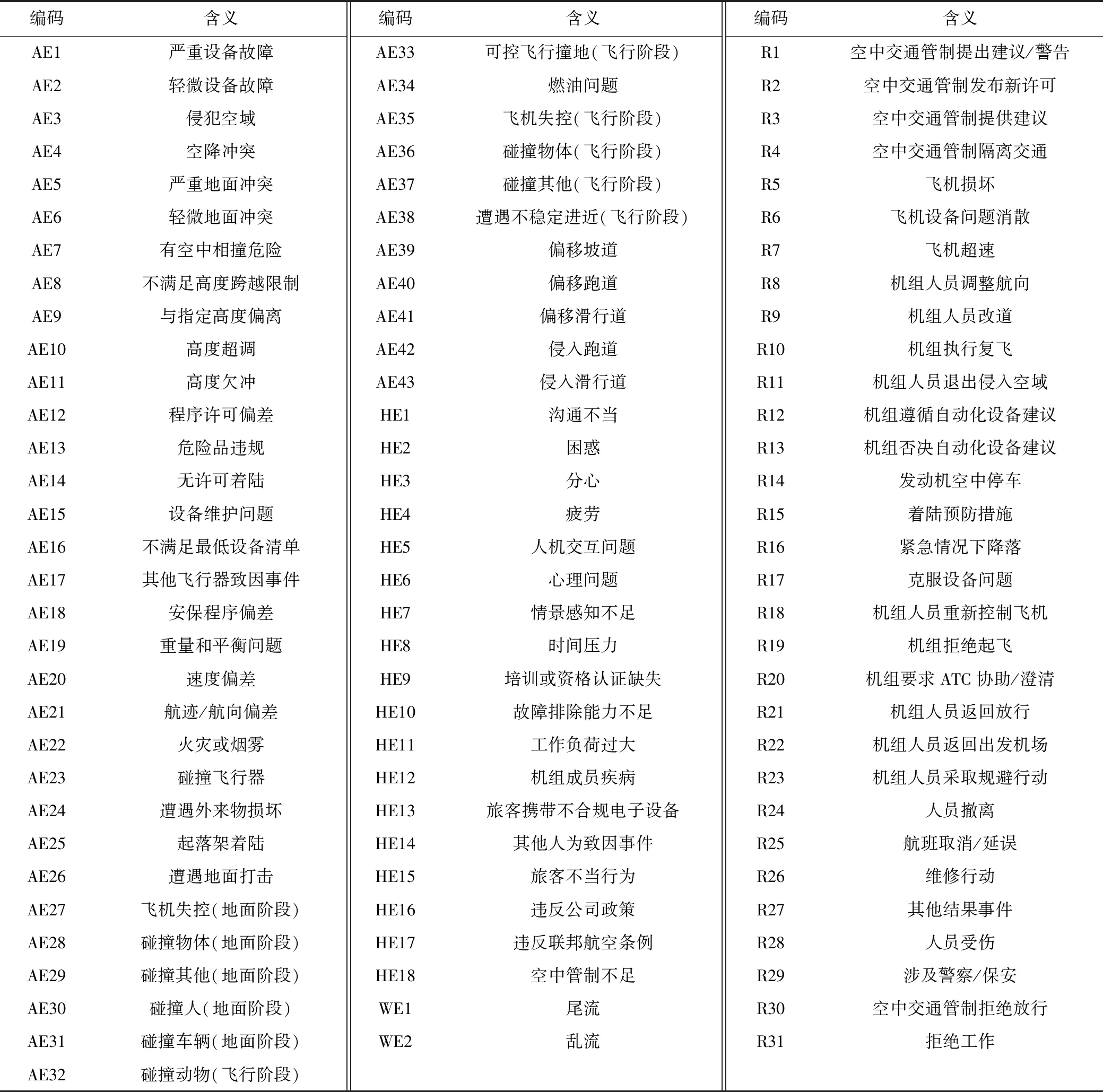
表1 CAPTI-BN節點編碼及含義Table 1 Node code and meaning of CAPTI-BN
同時,依據致因事件分類體系,人工構建致因事件類型抽象語義結構。提取算法將事故文檔中的句子解析為各語句成分的關系樹,并將不同的致因事件結構和事件敘述文本映射至同一語義空間中,以確定語義空間中最接近的事件類型。該方法將事件提取的觸發詞識別、參數識別轉化為句子結構的分類,只需少量現有事件類型的人工注釋,而無需對事件類型、觸發詞、參數的標注,節約大量人力成本。

表2 致因事件提取子任務及其內容Table 2 Extracted subtasks and their contents of causal event
事故征候敘述文本是致因提取算法的輸入數據,其語法結構較為復雜,加大了語義抽取難度。為提升算法精度和效率,本文調用StanfordParser解析事故描述文中語義成分的依存關系,簡化敘述文本。 StanfordParser引入Compositional Vector Grammar (CVG),將Probabilistic Context Free Grammar (PCFG)與遞歸神經網絡結合,以學習句子語法語義和句子成分[16]。句中謂語作為句子的中心詞和AMR結構的根,選取主語、賓語、賓語補足語、狀語4種語法成分,作為根的參數。因此,對于語句中的觸發詞t,可根據事件參數和參數關系構建事件語義結構St。對于現有致因事件類型e,將其事件類型作為根,并構建包含其預定義參數的語義結構Se。
同時,為更好表征文本中每個單詞的語義、語法和位置信息,引入Bert進行詞向量化,并將輸入文本中每個句子轉化為1個詞向量序列[17]。Bert應用Masked LM和Next Sentence Prediction 2種方法分別捕捉詞語和句子級別的語義表達。通過Bert詞嵌入,語句的事件語義結構St中參數w1,w2的關系如式(2)所示:
Vt=[Vw1;Vw2]×Mφ
(2)
式中:w1,w2為語義結構參數;Vw1,Vw2為參數w1,w2的d維向量化表示;Mφ為參數關系的矩陣化表示;Vt為參數w1,w2及其關系的向量化結果。
預定義的致因事件類型Se,同理可向量化表示為Ve。Bert的輸出結果是分類模型的輸入,計算輸入事件與事件類型的相似度,輸出相似度最高的事件類型,作為事件提取的結果,如式(3)所示:
(3)
式中:e*為語句t相似度最高的事件類型;Ve*為事件類型e*的向量化表示;E為事件類型集合;ei為E中的事件類型;Vei為ei的向量化表示。
2.2 CAPTI-BN網絡學習
基于數據驅動的貝葉斯網絡學習通常分為2階段執行。第1階段是結構學習,從數據集中學習節點間的條件獨立性規則,并構建網絡拓撲結構。第2階段是參數學習,學習網絡結構中隱含的局部分布,構建條件概率表。
在結構學習階段,條件獨立性測試和評分搜索的混合算法能夠得到更精確的計算結果,計算效率更高[18]。因此,本文通過CAPTI-BN節點定義,預設部分節點間的關系,并結合混合算法中經典的最大最小爬山算法(Max-Min Hill Climbing,MMHC),提出改進MMHC算法。算法具體執行步驟如下:
步驟1:確定黑名單與白名單。黑名單指不存在因果關系的節點對集合。由定義2可知,結果事件僅由致因事件引起,因此結果事件之間不存在有向弧,將結果事件對加入黑名單中。白名單指存在因果關系的節點對集合。白名單可根據歷史數據和管理經驗,人工構建。本文因缺少該類數據支持,暫不考慮白名單,后續研究中可進一步補充。
步驟2:前向過程。對于目標變量T,輸出其候選父、子節點集合CPC(Candidate Parents and Children)。若白名單中存在涉及T的節點對,將此類節點對中的非T變量加入CPC集合中。之后,基于CPC及其子集,得到除CPC內變量外所有變量與T最小條件關聯,并取其中的最大值,以及達到最大值的變量F,如式(4)~(5)所示:
assocF=maxx∈VMinassoc(X;T|CPC)
(4)
F=argmaxMinassoc(X;T|CPC)
(5)
式中:V為變量X的集合;T為目標變量;CPC為變量T的候選父子節點集合;assoc(X;T|CPC)為變量X與T的CPC條件關聯函數;assocF為條件關聯最大值;F為條件關聯取最大值時X的取值。
關聯值函數assoc(X;T|CPC)通過G2統計測算。計算G2統計量對應的p值,并取負值,作為關聯值函數結果。通常p值低于0.05時,X與T是條件獨立的。若F與T非條件獨立,則將變量F加入到CPC中,重復上述過程直至CPC集合不再變化,如式(6)~(7)所示:
(6)
assoc(X;T|CPC)=-p_value(G2)
(7)
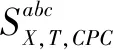
步驟3:后向過程。當給定CPC某個子集S時,若目標變量T與CPC表中元素X是獨立的,則從CPC表中剔除X。遍歷CPC中所有的變量后,輸出變量T滿足條件獨立的父節點和子節點,得到新的CPC表。
步驟4:爬山算法。運用貪婪爬山算法,對網絡結構添加新弧、刪除原有弧、改變弧的方向。其中當且僅當A屬于B的CPC集合且A→B不屬于黑名單集合時,添加新弧A→B,最終,輸出BDeu得分最高的網絡結構。BDeu評分函數假設模型滿足迪利克雷分布,計算過程如式(8)~(9)所示:
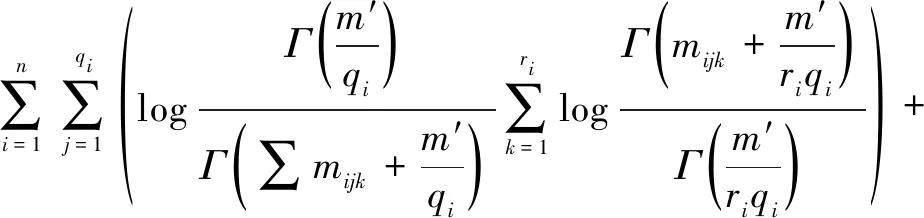
(8)
(9)
式中:G為網絡結構;D為數據集;fBDeu(G,D)為網絡結構G在數據集D中的BDeu評分結果;Γ為Gamma函數;n為節點數量;mijk為節點i的狀態為k且父節點取值為j時的樣本數量;ri為節點i狀態數量;qi為父節點取值組合的數量;αijk為迪利克雷分布參數;m′為中間統計量;P(G)為G的概率分布。
在參數學習階段,結合結構學習的父子節點分布與式(1)的變量全概率公式,計算各節點條件概率表(Conditional ProbabilityTable,CPT)。
3 結果與分析
3.1 CAPTI-BN建模結果
本文的訓練數據集包含ASRS中2017年1月至2019年12月的7 265份旅客運輸事故征候報告。
在致因事件提取階段,本文選取Stanford parser4.0版本,Bert選用uncased_L-4_H-256_A-4版本,在pytorch環境下運行算法程序。敘述文本是致因提取模型的輸入數據。該階段模型輸出為案例中致因事件集合。依據表1和ASRS的result字段,對案例中的致因事件與結果事件進行0-1編碼。遍歷所有案例后,將數據集轉化為0-1矩陣。
在貝葉斯網絡結構學習階段,0-1矩陣是貝葉斯網絡學習算法的輸入。在此階段,本文通過R中的bnlearn庫調用MMHC算法,用于學習CAPTI-BN的拓撲結構。在參數學習部分,將結構學習階段的0-1矩陣數據集與CAPTI-BN拓撲結構導入貝葉斯網絡軟件Netica,計算得到各節點CPT。
Gephi軟件是被廣泛應用的網絡可視化和分析工具,將結構學習輸出的節點超鄰接矩陣導入Gephi后,可得到CAPTI-BN的拓撲結構,如圖1所示。網絡共有94個節點和247條有向弧。
3.2 結果驗證
本文將ASRS中2016年的事故征候數據作為事件提取階段測試集,驗證事件提取算法的準確性。經計算,測試集事件提取準確率為83%。
為驗證網絡學習階段MMHC求解結果的準確性和可行性,本文引入另1種混合搜索方法RSMAX2對數據集進行貝葉斯網絡結構學習,并通過k-fold交叉驗證,比較2種算法結果與數據的擬合程度。k-fold驗證將CAPTI-BN視為1個貝葉斯分類模型,并將數據集劃分為k個子集,每次選取k-1個子集作為訓練集,剩余的1個子集作為測試集,重復k次,并運用對數損失函數表征分類準確率,如式(10)所示:
(10)
式中:logloss為對數損失函數結果;N為測試集樣本數量;M為可能類別數;yij為布爾型變量,判斷j是否為變量xi的真實類別;pij為測試集中變量xi屬于類別j的概率。
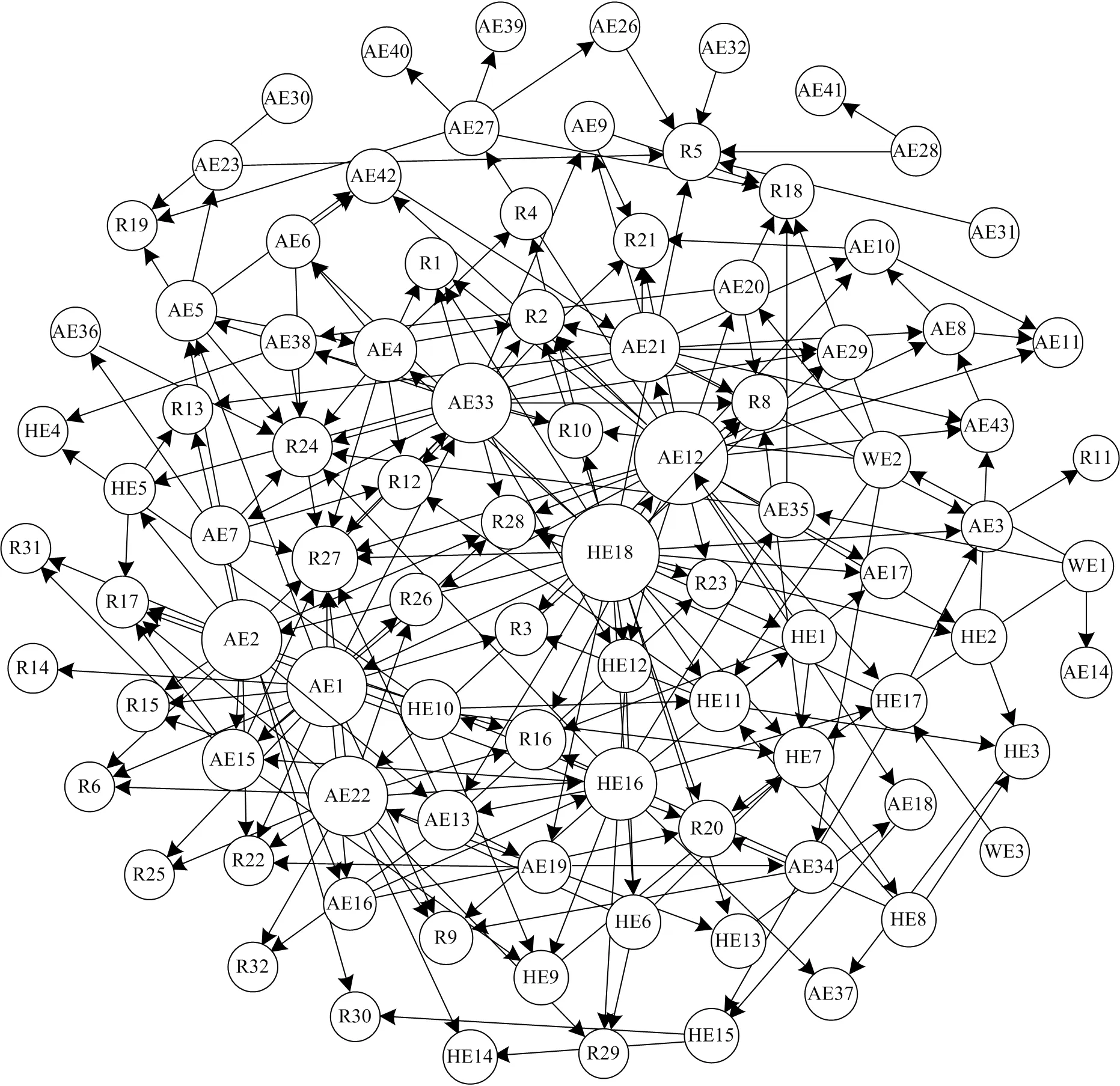
圖1 CAPTI-BN拓撲結構Fig.1 CAPTI-BN topology structure
最終取k次對數損失函數結果均值表示算法的擬合度。
交叉驗證取bnlearn中k的默認值10,交叉驗證結果如圖2所示。MMHC算法對數損失函數值更低,因此MMHC算法對于現有數據集的擬合程度更高。
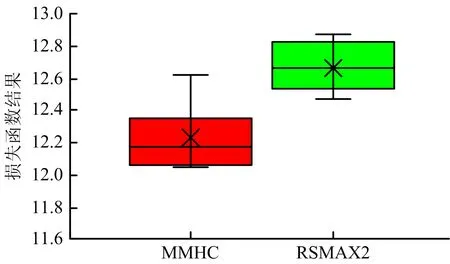
圖2 交叉驗證結果Fig.2 Results of cross validation
3.3 關鍵致因分析
本節通過致因事件和結果事件間證據敏感性測度,識別CAPTI-BN的關鍵致因事件。Zhang等[5]依據事故征候后果嚴重程度和專家意見,將ASRS數據庫中的結果事件劃分為低至高5個等級。其中高風險事故結果包括人員受傷、發動機空中停車、空中交通管制分離航道及飛機損壞,該類結果事件往往會造成高額的經濟損失和不良的社會影響。其中,發動機空中停車指飛機飛行過程中發動機停止工作。
證據敏感性分析使用熵和互信息的度量方法來評估不同條件下BN后驗概率分布的變化。基于信息熵理論,互信息指標可衡量不同變量間的依賴程度。互信息值越大,事故后果與致因事件間的關聯越強。結果事件與致因事件間的互信息,以及致因事件占比計算如式(11)~(12)所示:
(11)
(12)
式中:R為結果事件;E為致因事件;Ei為致因事件的狀態;r為結果事件的狀態;P為事件概率;I(R,E)為結果事件與致因事件間的互信息;I(R,R)為結果事件自身信息熵;Pe(R,E)為致因事件信息熵占比。
高風險結果事件最相關的5個致因事件見表3。其中空中交通管制隔離交通主要由空中交通管制不足和空降沖突引起,其余致因事件對其影響較小。飛機損壞主要原因是外物撞擊,如飛行器、車輛、動物等。發動機空中停車主要受設備嚴重故障影響。而人員受傷主要是由機組成員疾病或心理問題導致。
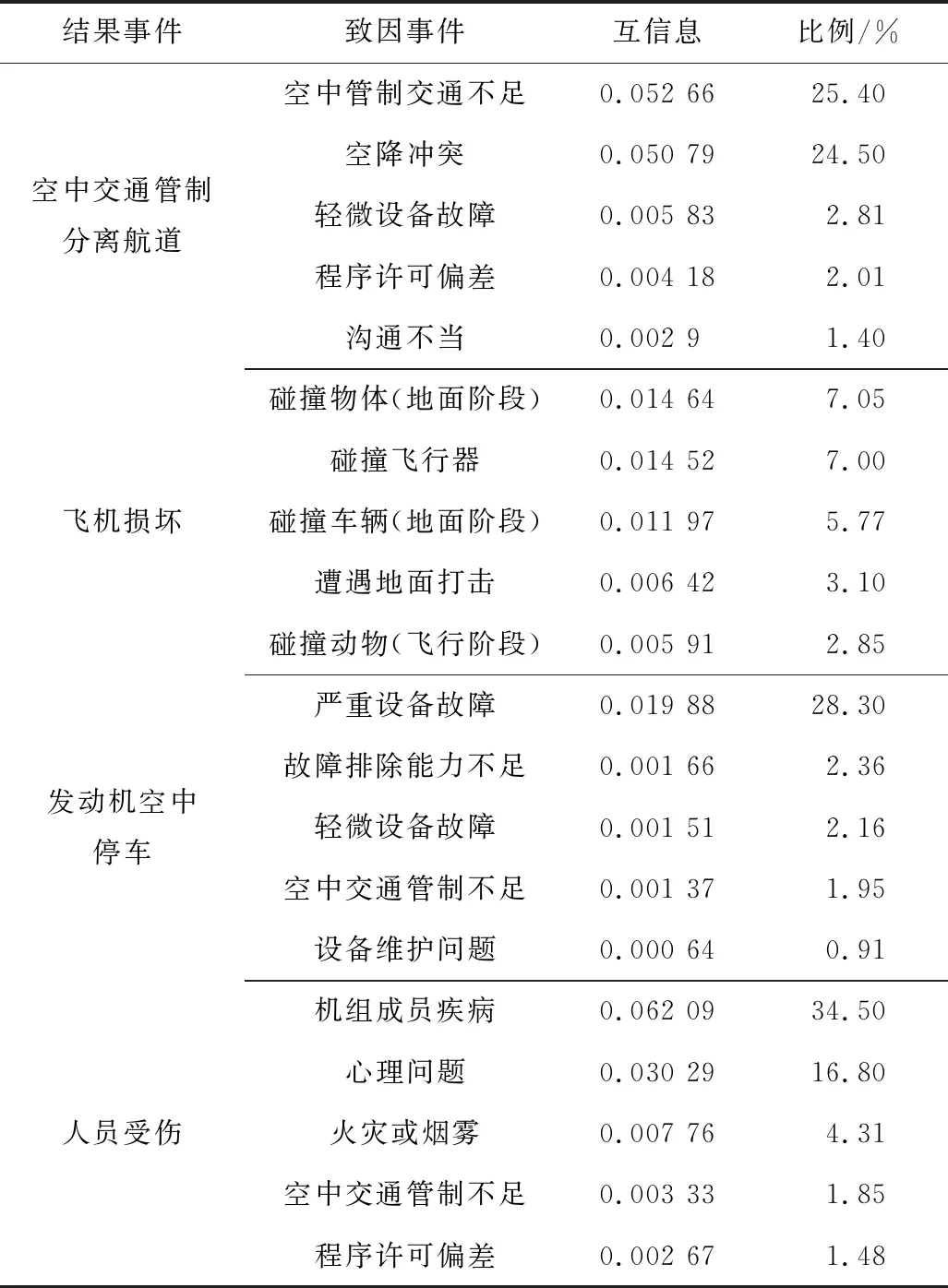
表3 高風險結果事件敏感性分析Table 3 Sensitivity analysis of high risk result events
低風險增至高風險導致的致因事件后驗分布變化,可評估事故征候演化過程中各致因事件及其狀態的重要性[17]。對于多結果的事故征候,確定每個結果的風險等級,并用其中最高的風險等級表示整個事故征候的風險程度。當風險等級由低風險轉為中風險和由中風險轉為高風險時,致因事件變量后驗概率的分布及其變化情況,如圖3所示。由圖3可知,事故征候發生時,機組成員違反公司規章(H16)是最高正敏感性的致因事件,且后驗概率始終高于50%,證明違反公司規章是目前事故征候中最普遍的人為致因事件。此外,設備輕微故障(AE2)是較為常見的飛行器致因事件。
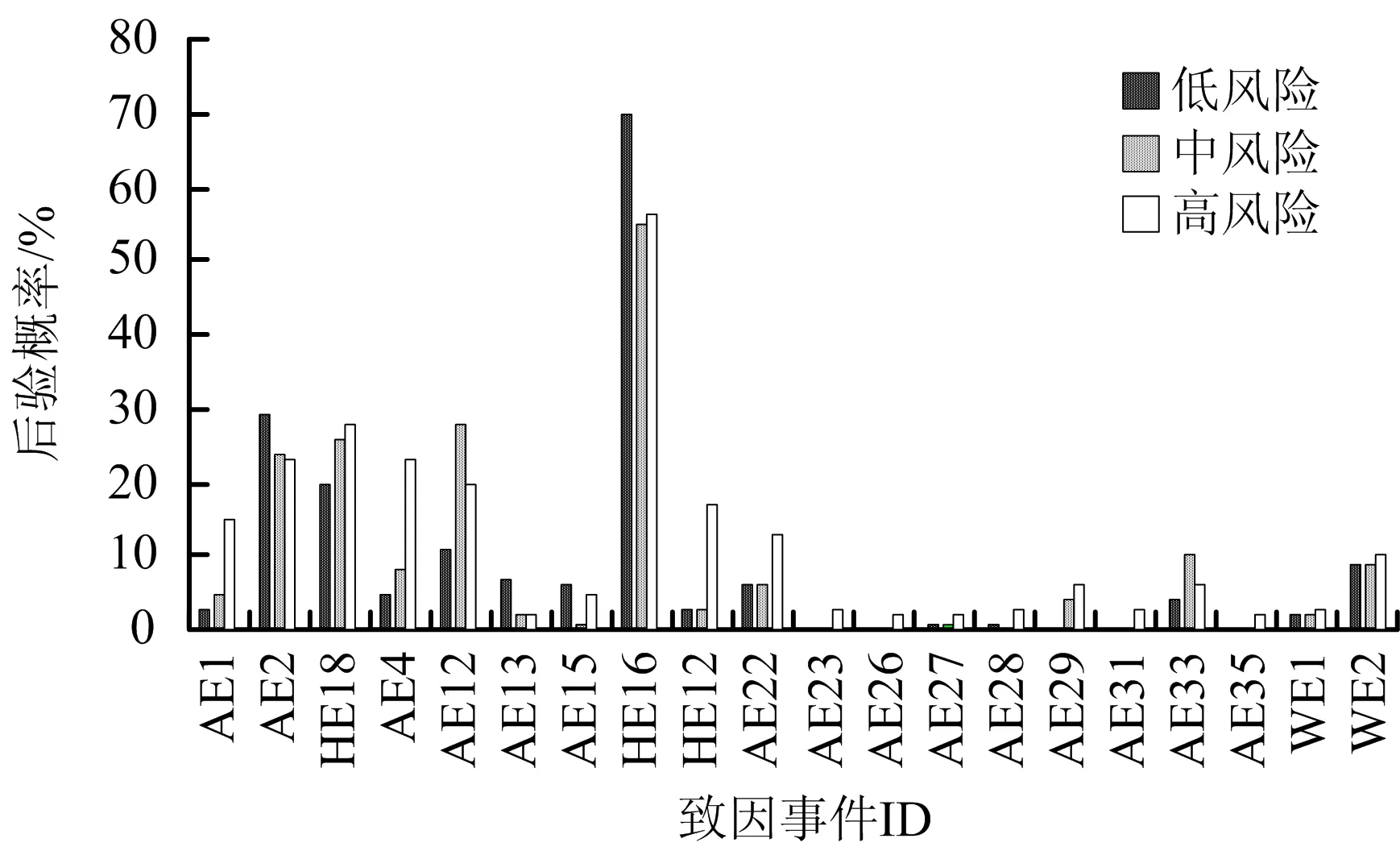
圖3 低-中-高風險等級下致因事件后驗概率Fig.3 Posterior probabilities of causal events at low, medium and high risk level
當結果事件由低風險轉為中風險時,程序許可偏差(AE12)、遭遇可控飛行撞地(AE33)及空中交通管制問題(HE18)的后驗概率增幅較大,而違反政策規定(HE16)的事件后驗概率顯著下降,上述4類事件是區分中、低風險的重要致因事件。而當風險提升至最高等級時,空降沖突(AE4)、嚴重設備故障(AE1)、機組成員疾病(HE12)及火災煙霧(AE22)的后驗概率有較大提高,該類致因事件的產生往往會導致嚴重的事故后果,與表3中高風險結果事件證據敏感性分析結論一致。此類致因事件本身具備較高風險,在安全監管過程中消除或減弱關鍵致因事件的發生,可最大程度降低事故征候的風險程度,減少次生或衍生事故發生的概率。
4 結論
1)定義CAPTI-BN中節點、有向弧及概率要素,從人、飛行器、環境3個角度,提出事故征候中直接致因事件和結果事件的分類體系。
2)利用事件提取算法分析事故征候文本,提取致因事件,并引入MMHC算法學習網絡結構,實現CAPTI-BN自動化建模,提升數據分析效率。
3)量化結果事件風險并結合證據敏感性分析,得出空降沖突(AE4)、嚴重設備故障(AE1)、機組成員疾病(HE12)及火災煙霧(AE22)是CAPTI-BN中高風險關聯的致因事件。
4)引入不同的數據集,本文的建模方法可拓展應用于其他地區與機場的航空旅客運輸風險現狀,并比較不同區域、不同機場的風險特征差異。
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
