融合時間上下文的改進協同過濾圖書推薦模型
2021-03-15 05:25:07王子嵐
科技風 2021年3期

摘 要:針對傳統的協同過濾推薦算法在高校圖書推薦場景中存在缺乏顯性評分、推薦精度低等問題,提出一種融合時間上下文的改進協同過濾圖書推薦模型。基于圖書歷史借閱記錄,首先構建基于借閱時長的讀者—圖書偏好度模型,將讀者歷史借閱記錄中隱含的借閱偏好信息轉換成顯性的讀者—圖書評分;然后考慮讀者借閱偏好隨時間動態變化因素,引入時間衰減因子對讀者—圖書評分模型進行修正,最后應用隱語義模型進行個性化圖書推薦。
關鍵詞:時間上下文;協同過濾;圖書推薦
隨著高校圖書館藏圖書資源的日益增長,面對海量館藏圖書,讀者常常陷入圖書信息過載難題[1]。現有的高校圖書借閱系統中僅提供基于信息檢索的服務,缺乏個性化圖書推薦模塊,但同時系統中累積的大量借閱記錄隱含著讀者的借閱偏好,具備了個性化圖書推薦的數據基礎。因此,如何利用好這些借閱記錄,挖掘讀者借閱偏好并進行個性化圖書推薦,是當下圖書推薦亟待解決的問題。高校圖書館中圖書數量遠大于讀者數量,基于圖書內容的推薦算法不適用[2]。在高校圖書推薦場景中,現有的研究主要是在用戶協同過濾推薦算法[3]上加以改進,該類算法僅基于目標讀者的近鄰相似讀者進行推薦,且在讀者借閱記錄稀疏的情況下推薦精度較低。同時該方法默認讀者偏好不會隨時間推移而變化,而實際上讀者在不同時間段的借閱偏好是動態變化的。基于以上分析,本研究從以讀者歷史借閱記錄出發,選擇在Netflix Prize大賽中脫穎而出的隱語義模型(latent factor model,LFM)[4]作為基本算法,考慮讀者借閱偏好動態因素,融入時間上下文以提高推薦精度。
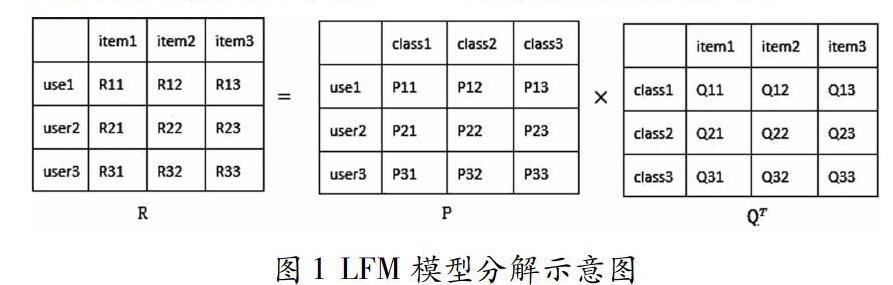
1 LFM模型
LFM模型是時下最主流的協同過濾推薦算法,是一種基于模型的協同過濾算法。其主要原理是找到用戶和項目之間的關聯,并基于此構建用戶興趣偏好進行推薦。如公式所示:
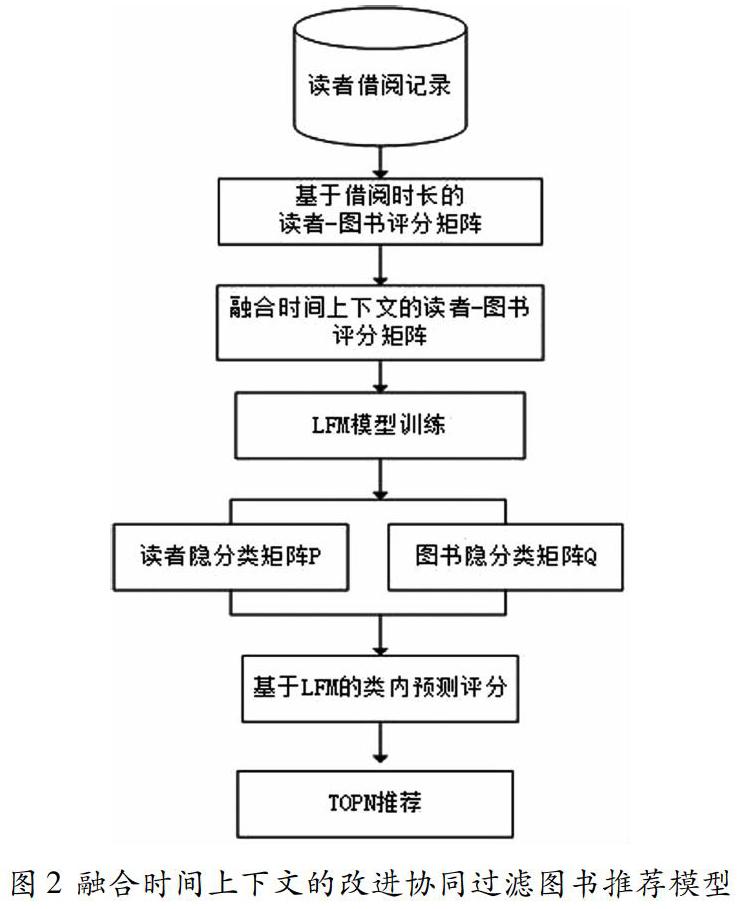
2 融合時間上下文的改進協同過濾圖書推薦模型
2.1 基于借閱時長的讀者—圖書評分模型
協同過濾算法嚴重依賴評分矩陣,但現有的高校圖書管理系統中缺乏評分模塊,因此首先需要構建讀者—圖書評分矩陣。一般來說,讀者借閱圖書的時間越長,表示其對該圖書的偏好度越高[6]。因此本文基于讀者借閱記錄,首先進行數據預處理,將借閱時間超期記錄等數據作為噪聲刪除,得到讀者—借閱圖書的時長矩陣,同時考慮讀者閱讀習慣和圖書借閱情況兩個維度構建基于借閱時長的讀者—圖書評分模型,并加權得到基于借閱時長的讀者—圖書評分模型。
(1)考慮讀者閱讀習慣,構建讀者—圖書借閱時長的評分模型如下:
2.2 融合時間上下文的讀者—圖書評分模型
傳統的協同過濾方法假定讀者偏好是靜態不變的,但實際上讀者對借閱圖書的偏好是會隨時間變化的[7]。例如受學科及教學進度影響,學生在大一時會更偏好借閱基礎課程的書籍,而大四的時候會更偏好借閱考研或就業類書籍。以讀者編號為21800300125的讀者為例,由于準備計算機二級考試,他在2018年10月10日至2018年12月17日借閱了圖書《C語言程序設計》,借閱時長累計77天,按照公式(9)可得likeui1=0.9245,同時根據公式(10)可得likeui2=0.8946,加權可得likeui=0.9095,可見該讀者對此圖書的評分很高。但隨著時間的推移,讀者學習進度的推進,直接以該評分為該讀者做當下這個時間的圖書推薦顯然并不恰當。因此,本文融合時間上下文,在原評分基礎上引入時間衰減因子,對上一節中提出的基于借閱時長的讀者—圖書評分模型加以修正,進而得到融入時間上下文的讀者—圖書評分模型。
相對來說,讀者最近借閱的圖書更能代表其當前時間的借閱偏好,這與人們的遺忘規律是相類似的。很多研究者通過各種函數擬合了艾賓浩斯遺忘曲線,本文選用了最常用的牛頓冷卻公式[8],得到時間衰減因子:
2.3 模型實現流程
基于以上研究,提出了一種融合時間上下文的改進協同過濾圖書推薦模型,首先基于借閱時長構建讀者圖書偏好度模型,將讀者歷史借閱記錄轉換成讀者—圖書顯性評分矩陣;然后考慮讀者偏好度隨時間的動態變化,融入讀者還書行為的時間上下文,應用時間衰減因子作為權重對讀者圖書評分進行修正,得到修正的讀者—圖書評分矩陣;最后應用LFM模型對目標讀者進行圖書TOPN推薦。
步驟1:根據讀者—圖書借閱記錄數據集,利用公式(11),將借閱記錄中的讀者隱含偏好信息轉換成基于借閱時長的讀者—圖書評分矩陣;
步驟2:利用公式(13),融入時間衰減因子,將讀者—圖書評分矩陣轉換為融合時間上下文的讀者—圖書評分矩陣;
步驟3:隨機初始化得到讀者隱分類矩陣P、圖書隱分類矩陣Q;
步驟4:采用SGD進行LFM模型訓練,得到的P、Q矩陣,進而得到讀者u對圖書i的基于LFM的預測評分;
步驟5:根據讀者u的預測評分輸出其TOPN本未借圖書列表進行推薦。
3 小結
提出了一種融合時間上下文的改進協同過濾圖書推薦模型。該模型的創新之處在于從讀者和圖書兩個維度構建了基于借閱時長的讀者—圖書評分模型,并考慮讀者借閱圖書偏好度的動態變化,融合時間上下文進行修正,最后應用推薦精度高的LFM模型進行圖書推薦。
參考文獻:
[1]李薛劍,劉夢雅,海健強,吳雪揚,余雪莉.基于時間效應與隱語義模型的高校圖書館的個性化推薦研究[J].計算機應用與軟件,2018,35(05):130-134+189.
[2]翁小蘭,王志堅.協同過濾推薦算法研究進展[J].計算機工程與應用,2018,54(01):25-31.
[3]Hill W,Stead L,Rosentein M,et al.Recommending and evaluating choices in a virtual community of use[C].Priceedings of CHI95.
[4]王升升,趙海燕,陳慶奎,曹健.個性化推薦中的隱語義模型[J].小型微型計算機系統,2016,37(5):881-889.
[5]汪寶彬,戴濟能.隨機梯度下降法的收斂速度(英文)[J].數學雜志,2012,32(1):74-78.
[6]魏港明,劉真,李林峰,張猛.加入用戶對項目屬性偏好的奇異值分解推薦算法[J].西安交通大學學報,2018,52(05):101-107.
[7]梁思怡,彭星亮,秦斌,林偉明,胡振寧.時間上下文優化的協同過濾圖書推薦[J/OL].圖書館論壇,1-11[2020-12-23].
[8]孫克雷,沈華理.基于用戶多種關聯信息和項目聚類的推薦算法[J].安徽理工大學學報(自然科學版),2018,38(05):57-64.
基金項目:2019年度安徽高校科學研究一般項目(項目編號:KJ2019H05);黃山職業技術學院2019年校級質量工程項目(項目編號:2019jxtd01)
作者簡介:王子嵐(1984— ),女,安徽黃山人,講師,研究方向:計算機應用技術。
