基于數據挖掘的數據庫語言查詢過程分析
2021-03-17 08:13:04侯陽青
微型電腦應用 2021年2期
侯陽青
(福州職業技術學院 阿里巴巴大數據學院, 福建 福州 350108)
0 引言
數據庫應用以及信息檢索系統的普及,為用戶帶來方便的同時,也為數據庫應用帶來了一定的挑戰。越來越多非專業用戶的參與,用戶對于數據庫操作簡單、查詢界面要易于掌握的需求越來越明顯。數據庫傳統查詢接口為圖形接口,具有較多的缺陷,例如操作過程復雜、對硬件要求高、耗費資源多和使用性能低等。這些缺陷導致數據庫應用發展較為緩慢。鑒于此,自然語言查詢接口重新出現在人們的視野之中,成了數據庫應用領域研究的熱點[1]。
數據庫自然語言界面的出現,解決了非專業用戶訪問數據庫信息的難題,用戶可以依據人類語言向數據庫發問,以此來獲取自身所需要的信息與數據,大大地提升了人機交互的容易程度,降低了數據庫系統應用的難度。自然語言查詢界面實質上指的是用戶通過自然語言對數據庫發出各種操作指令,系統將其轉換為數據庫操作語言,從而在數據庫中查詢到正確的信息,將其反饋給用戶。這種查詢方式避免了現實世界與機器世界對信息不同理解的難題,具有重要的研究價值[2]。
近幾年,國內外均對數據庫語言查詢過程進行了深入的研究與分析,并取得了一定的成果。國外代表性研究成果為LIFER系統與基于模糊集理論的語言查詢系統。LIFER系統具有通用性以及極高的自然語言處理速度,被多個領域所應用;基于模糊集理論的語言查詢系統可以定性分析語法不完整的查詢語句,提高了系統的人性化,增加了數據庫系統的易用性。但現有數據庫語言查詢過程分析方法由于詞法切分有誤,導致復雜查詢語句存在著查詢準確率低的問題。為此本研究提出基于數據挖掘的數據庫語言查詢過程分析方法研究,數據挖掘是指在通過算法在大量數據中搜索隱匿信息的過程[3],通過數據挖掘的引用,可以提升數據庫語言查詢的準確率。
1 數據庫語言查詢過程分析方法研究
1.1 查詢語句結構分析
處理自然語言查詢語句的首要任務就是要分析查詢語句結構。依據調查研究發現,在數據庫查詢時,用戶使用祈使句與疑問句的頻率較高,多語句與省略句比例較小[4]。確定查詢語句類型,如表1所示。

表1 查詢語句類型表
其中,疑問句還可以細分為選擇問句、正反問句和特質問句。需要注意的是,疑問句與是非問句在問法上存在著較大的不同,所以處理過程截然不同,故將其看作為兩類查詢問句[5]。
在語言查詢過程中,最關鍵的就是分清查詢目標與查詢條件,為此,依據查詢目標與條件為基礎,劃定查詢語句結構。以數據庫角度來看,查詢語句基本成分包括疑問詞、查找詞、連詞、語助詞、標點符號、量詞、條件類比較詞、屬性值、對象名稱、格標和領域動詞等。其中,屬性值、對象名稱和領域動詞與具體應用相關,將其稱為專用詞類,剩下的基本成分稱為通用詞類。
在實際的數據庫語言查詢語句中,專用詞類與通用詞類共同構成了查詢目標與查詢條件[6]。通過分析得到查詢語句結構主要有四種,具體情況如下。
第一種:一般祈使句結構。表示為:<查詢條件1 查詢條件2 …查詢條件m><查詢目標1 查詢目標2 …查詢目標n>;
第二種:特殊祈使句結構。表示為:<查詢條件1 查詢條件2 …查詢條件m1><查詢目標1><連詞><查詢條件1 查詢條件2 …查詢條件m2><查詢目標2><連詞>…<查詢目標n>;
第三種:一般疑問句結構。表示為:<查詢目標1 查詢目標2 …查詢目標n><查詢條件1 查詢條件2 …查詢條件m>;
第四種:是非疑問句結構。表示為:<查詢條件1 查詢條件2 …查詢條件m1><查詢目標1><動詞><查詢條件1 查詢條件2 …查詢條件m2>。
1.2 查詢語句分詞
依據上述分析得到的查詢語句結構為基礎,結合自然語言的特點,利用最大匹配法分詞處理查詢語句,如圖1所示。
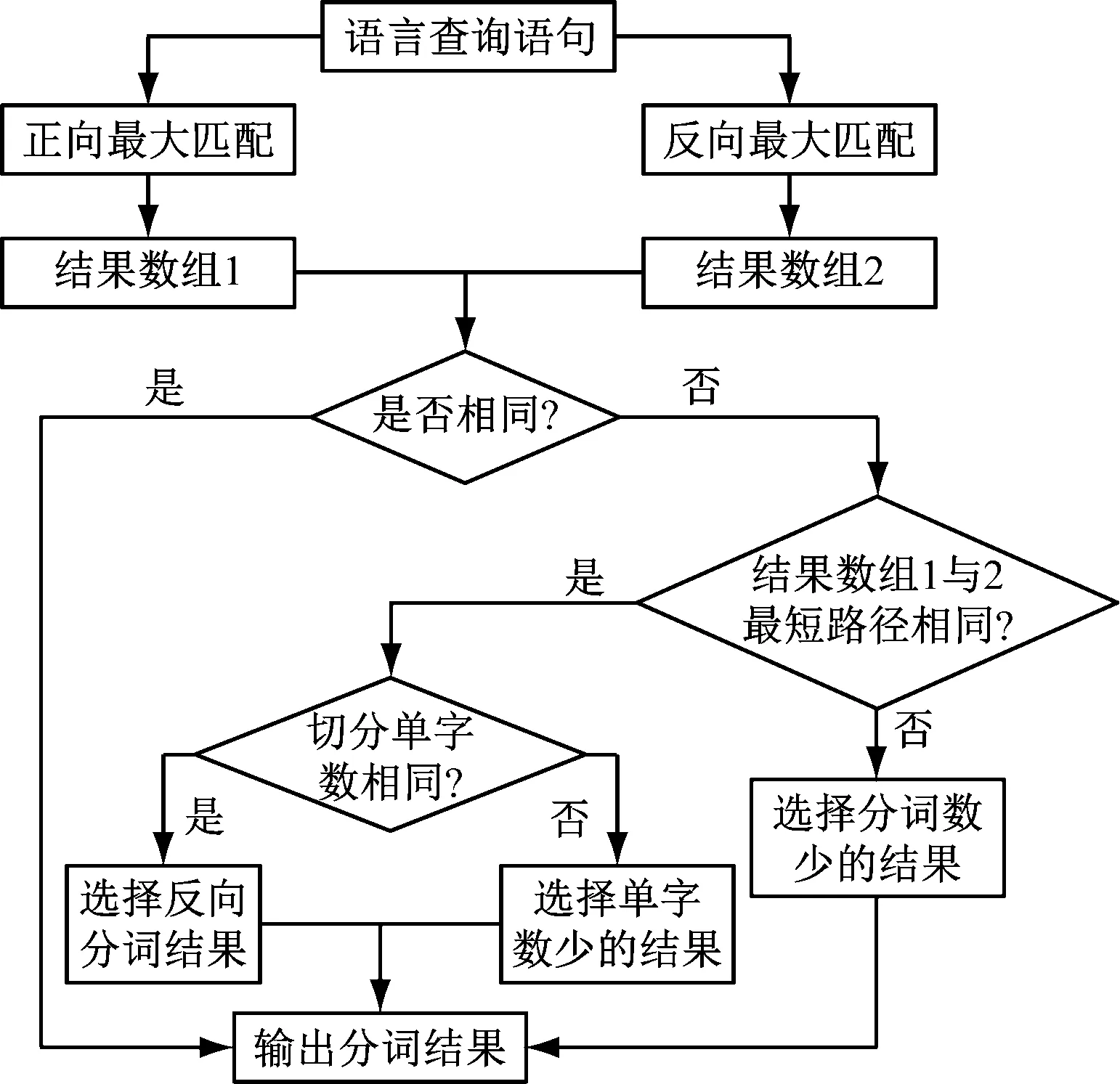
圖1 查詢語句分詞流程圖
依據圖1流程得到查詢語句分詞結果,為了保障分詞結果的準確性,需要消除歧義詞,并實時更新分詞應用過的知識庫[7]。
1.3 查詢目標與條件識別
依據查詢語句分詞結果,通過數據庫語義分析來識別查詢目標與查詢條件。查詢條件的功能是限定查詢范圍[8],查詢條件主要分為顯性條件與隱性條件。顯性查詢條件識別流程,如圖2所示。
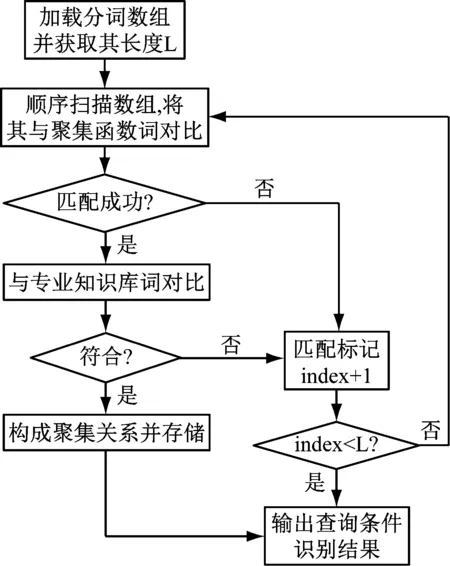
圖2 顯性查詢條件識別流程圖
隱性查詢條件識別需要依據領域專業知識庫的復合詞匯文件以及映射文件去尋找,直至找到為止;若是查詢失敗,將其定義為新詞,對系統接口進行更新。
查詢目標識別實質上是尋找用戶需求信息,查詢目標與具體數據庫具有緊密的聯系,常規情況下,查詢目標為屬性名或其函數,包括屬性詞目標、疑問詞目標、聚集目標以及復合推理目標[9]。
針對查詢語句結構特征,得到查詢目標獲取算法步驟如下。
步驟一:加載語言查詢語句分詞結果數組;
步驟二:查詢目標位置不確定,為此,以順序掃描方式掃描數組的內容,將其與疑問詞文件對比,若是匹配成功,執行疑問詞與數據庫屬性信息對應,轉至步驟五;若是匹配失敗,轉至步驟三;
步驟三:以逆序掃描方式掃描數組的內容,將其與領域專業知識庫中的邏輯推理文件、映射文件和復合詞匯文件對比,若是匹配成功,轉至步驟四;若是查詢語句沒有確切的查詢目標,數據庫系統默認所有屬性信息,轉至步驟五;
步驟四:將步驟三結果與聚集函數文件對比,若是匹配成功,將查詢目標合并為屬性名,轉至步驟五;若是匹配失敗,直接將目標屬性作為查詢目標,轉至步驟五;
步驟五:將獲取的查詢目標存儲為結構體數組。
需要注意的是,在查詢目標識別過程中,需要一定的規則支撐,例如標記符號消除規則等,由于篇幅限制,在此研究中不一一列出。
1.4 自然語言查詢到SQL語句的轉換
依據識別的查詢目標與查詢條件,構建語義依存樹,劃分為集合塊,通過綜合轉換算法轉換為SQL語句,為用戶需求數據挖掘空間定位做準備[10]。
語義依存樹構成,如表2所示。

表2 語義依存樹構成表
語義依存樹包含了查詢語句的全部信息,為了簡便自然語言查詢到SQL語句轉換的過程,將語義依存樹劃分為多個集合塊。
語義依存樹集合塊劃分算法如下。
輸入:語義依存樹DpRt;
輸出:集合塊的根SubRt;
過程:
步驟1.依據逆序形式遍歷語義依存樹DpRt,獲取當前結點,順序執行下述程序。
a.若當前結點是動詞,并具備量詞子結點,則返回集合塊根SubRt;
b.若當前結點是比較操作符,則返回集合塊根SubRt;
c.若當前結點依存父結點是動詞,并且依存子結點是聯系動詞,則返回集合塊根SubRt;
d.若當前結點是自參照屬性,并且依存父結點是本身,則返回集合塊根SubRt。
步驟2.返回語義依存樹DpRt。
語義依存樹集合塊類型,如表3所示。

表3 集合塊類型表
將劃分得到的集合塊轉換為USQL語句,如式(1)。
SB=(O,C,T)
(1)
式中,SB表示語義依存樹集合塊的USQL語句表示形式;O表示集合塊的數據庫對象;C表示復合限定條件表達式;T表示集合塊全部結點所屬表的集合。
經過式(1)轉換后,語義依存樹表示多個集合塊的線性圖SBn-…-SB2-SB1,只需要將其展開即可得到查詢語句相應的SQL語句。轉換規則,如式(2)。
(2)
1.5 數據挖掘
依據上節轉換得到的SQL語句,利用數據挖掘技術在數據庫中定位用戶需求數據,提取定位數據并反饋給用戶[11]。
用戶需求數據挖掘流程,如圖3所示。
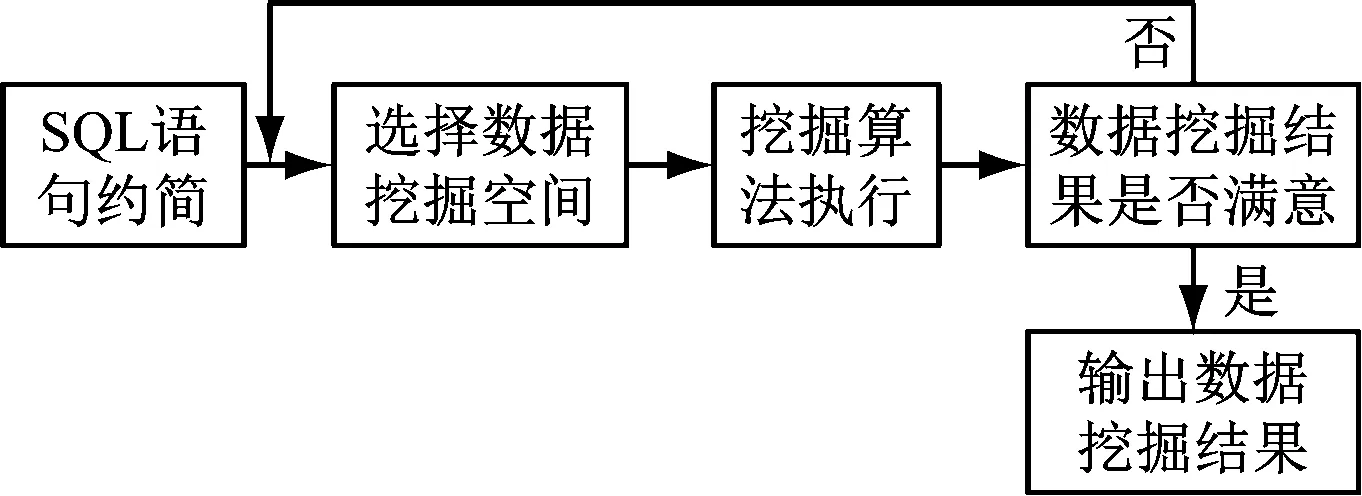
圖3 用戶需求數據挖掘流程圖
首先,利用遺傳算法約簡SQL語句,簡化數據挖掘過程[12]。假設每個SQL語句都是一個候選約簡,定義適值函數,如式(3)。
(3)
式中,F(v)表示適值函數值;N表示SQL語句的長度;Lv表示v語句中的屬性個數;Cv表示v語句區分對象組合的個數;m表示數據庫對象個數。
依據式(3)進行不斷迭代,直到滿足終止條件為止,完成了SQL語句的約減。
以式(3)結果為基礎,利用數據挖掘算法實現用戶需求數據的查詢。數據挖掘算法,如圖4所示。

圖4 數據挖掘算法示意圖
通過上述過程實現了基于數據挖掘的數據庫語言查詢過程的分析,為用戶提供更加優質、準確的服務,推動數據庫應用領域的發展。
2 查詢準確率仿真分析
為了驗證提出方法的性能,本文在LFPW數據庫上進行仿真對比實驗,通過查詢準確率判斷方法的好壞,而查詢準確率主要由查詢目標與條件識別系數、SQL語句轉換系數決定。其中,查詢目標與條件識別系數指的是查詢目標與條件識別的精確度;SQL語句轉換系數指的是SQL語句轉換的速率。常規情況下,查詢目標與條件識別系數、SQL語句轉換系數越大,表明方法的查詢準確率越高。具體實驗過程如下所述。
2.1 實驗數據庫選取
為了增加實驗結果的公平性,選取20個數據庫作為實驗對象,具體情況,如表4所示。

表4 實驗數據庫情況表
2.2 數據挖掘界面設計
基于語言查詢的數據挖掘界面,如圖5所示。
依據選取的數據庫以及設計的數據挖掘界面進行仿真對比實驗。
2.3 查詢目標與條件識別系數分析
查詢目標與條件識別系數范圍為[0,1],通過測試得到查詢目標與條件識別系數對比情況,如表5所示。
圖5 數據挖掘界面示意圖
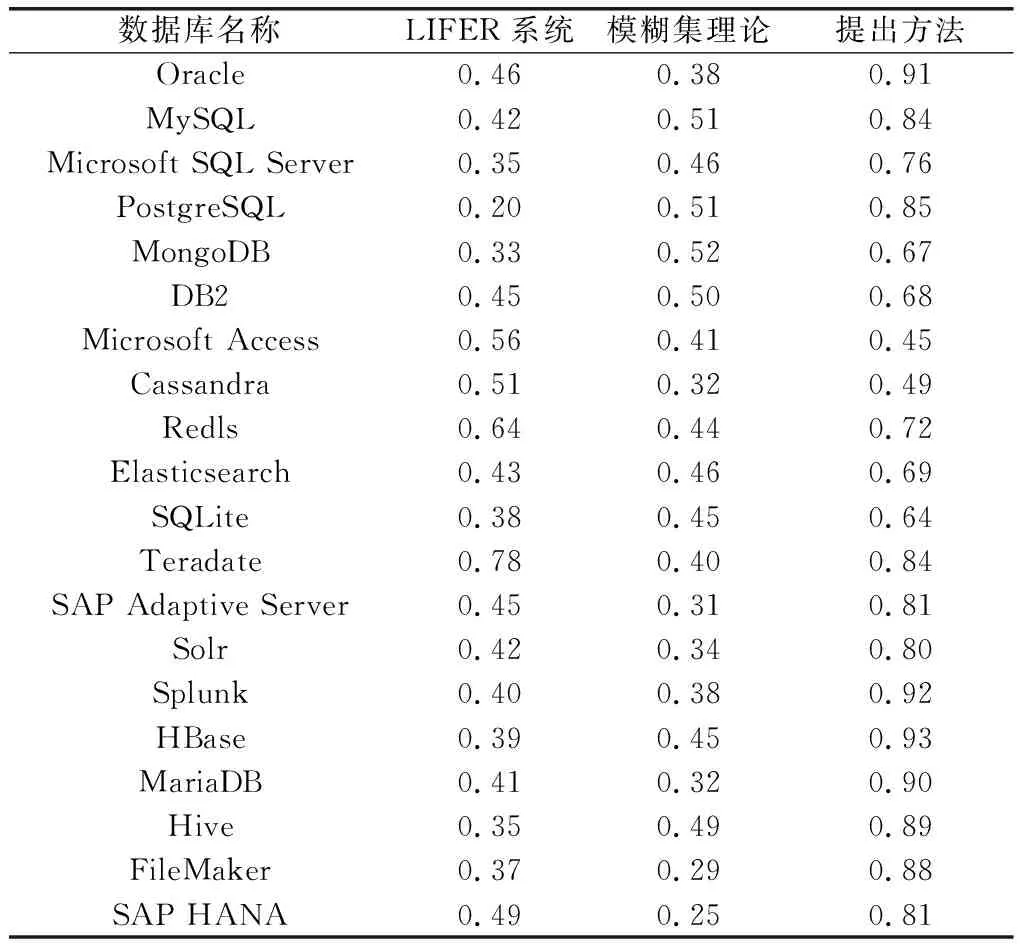
表5 查詢目標與條件識別系數對比情況表
表5數據顯示,提出方法的查詢目標與條件識別系數遠遠高于現有代表方法,其最大值為0.93。
2.4 SQL語句轉換系數分析
SQL語句轉換系數范圍為[1,10],通過測試得到SQL語句轉換系數對比情況,如表6所示。
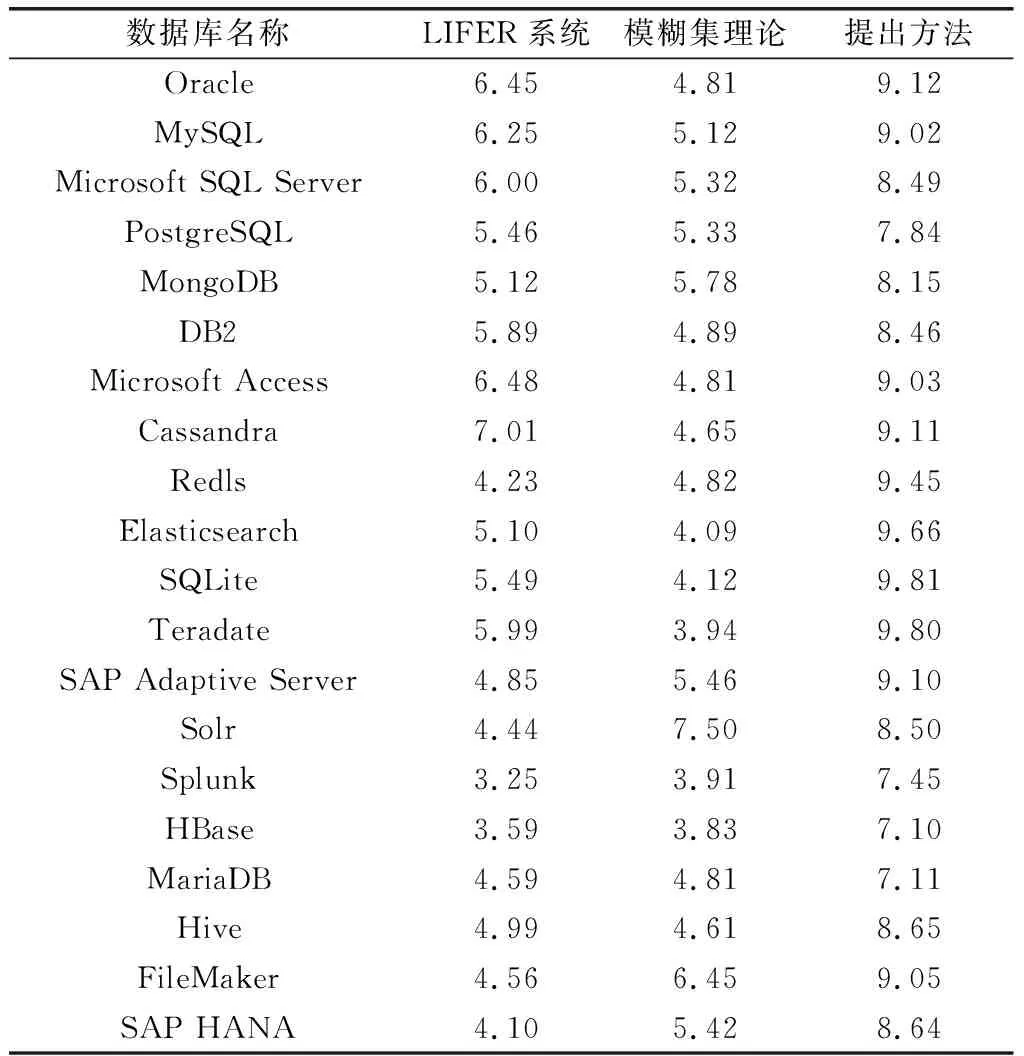
表6 SQL語句轉換系數對比情況表
表6數據顯示,提出方法的SQL語句轉換系數遠遠高于現有代表方法,其最大值為9.81。
3 總結
由上述實驗結果可知:本研究所提方法的查詢目標與條件識別系數、SQL語句轉換系數均遠高于現有代表方法,說明通過數據挖掘的引用,可以提升數據庫語言查詢的準確率,為用戶提供更加精準的數據服務。但本研究所提方法仍存在一些不足之處,如對查詢語句執行過程中查詢響應速度未考慮全面等。在保證數據庫語言查詢的準確率基礎上,縮短查詢語句執行過程中的響應速度是今后研究的重要方向。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
開放教育研究(2020年2期)2020-03-31 01:54:14
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
大連民族大學學報(2015年2期)2015-02-27 08:28:11
