基于LSTM的層次化篇章依存分析方法
2021-03-18 02:52:44賈延延程學旗
中文信息學報 2021年1期
賈延延,程學旗,馮 鍵
(1. 中國再保險(集團)股份有限公司 博士后科研工作站,北京 100033;2. 中國科學院 計算技術研究所,北京 100190;3. 中國再保險(集團)股份有限公司 信息技術中心,北京 100033)
0 引言
篇章是由詞、短語、句子和段落構成的自然語言單位,是一個有組織和層級的整體,可以表達完整的思想和意圖。篇章具有連貫性(Coherence)、銜接性(Cohesion)、信息性(Informativity)、意圖性(Intentionality)、情景性(Situationality)、可接受性(Acceptability)和跨篇章性(Intertextuality)等7種特性[1]。
基于修辭結構理論(Rhetorical Structure Theory, RST)[2]的篇章結構分析是篇章連貫性分析中的一個重要分支。在RST理論中,基本篇章分析單元(Element Discourse Unit, EDU)之間存在修辭關系。篇章成分分析通過這種修飾關系自底向上地合并分析單元,形成中間節點,直到建立包括整篇文章中所有EDU的篇章成分分析樹。目前,絕大多數篇章分析工作都采用成分分析模式。幾乎所有針對英語的篇章成分分析工作都基于經典的修辭結構理論篇章樹庫(RST DT)[3]。例如,Hernault等[4]提出了基于支持向量機的篇章成分分析器HILDA,他們采用二分類器進行結構分析,用多分類器預測修辭關系和核心附屬屬性,借助位置、長度、距離、句法分析結果、支配集等特征自底向上地建立成分分析樹;Feng等[5]為提升HILDA的分析效果,引入豐富的語言學特征。例如,規則、依存結構、語義相似度、支配節點、上下文信息等特征,構造了多達21 410個特征模板,通過互信息評價特征的貢獻將其排序;Li等[6]借助斯坦福自然語言處理工具獲得句法樹結構,利用遞歸神經網絡獲得EDU和中間分析單元的向量表示,再基于神經網絡的分類器分別判斷篇章分析樹結構和修飾關系。但是,上述無論傳統分析方法或是基于深度學習的篇章分析方法都無法避免人工特征提取。
雖然篇章成分分析較篇章依存分析[7]更受關注,但篇章依存分析的優勢不容忽視。篇章成分分析通過引入中間節點的方式,緩解“長距離依賴”這一性能瓶頸問題。然而,篇章依存分析無需增加中間節點,就可以直接分析EDU之間的關系,水平建立分析樹。因此篇章依存分析便于直接判斷篇章中任意兩個分析單元之間是否存在依存關系,其分析結果更為直觀和便捷。典型的依存分析工作如Li等[7],選擇基于圖模型的Eisner算法和最大生成樹算法進行篇章依存分析。首先,將RST篇章樹庫中的成分分析樹轉換為依存分析樹。然后,結合詞匯、詞性、長度、位置、句法分析結果、語義信息等六類特征集進行實驗,所生成的依存分析樹不包含額外引入的中間節點。然而,雖然基于圖模型的分析方法便于全局優化,且實驗效果通常優于基于轉移的篇章分析器。但是,用圖模型進行分析的算法時間復雜度較高。更重要的是,基于圖模型的分析方法依然無法克服篇章依存分析的兩大難點與挑戰問題: (1)在篇章依存分析中,長距離依賴場景的分析效果差;(2)為提高分析效果,引入大量人工特征來輔助判斷。
在實際應用場景,只有減少和規避特征提取才能提高篇章分析器的易用性和魯棒性,以避免人力浪費。若要緩解長距離依賴場景分析效果差這一瓶頸問題,單純從特征設計和后處理技巧入手勢必低效,應該考慮篇章分析基礎框架和模式。
另一方面,分層次處理的篇章成分分析框架具有啟發性。Joty等[8]分別使用兩個動態條件隨機場建立句子內部的篇章成分分析樹和句子之間的篇章成分分析樹,選擇CKY算法進行全局最優解碼,并為句內分析和句間分析分別引入豐富且有差異性的特征集進行實驗。Liu等[9]同樣分層次地進行句子內和句子間的篇章成分分析,分別用兩個線性鏈條件隨機場來建模篇章結構和關系。采用貪心策略自底向上的建立篇章成分分析樹。他們利用長短時記憶模型(Long Short-Term Memory, LSTM)[10]來建模EDU和句子的特征,并在句間篇章分析場景引入更能體現結構化特征的遞歸神經網絡來表達上下文信息。
上述兩個層次化的篇章成分分析工作都取得了不錯的實驗效果。因此,本文給出了層次化的篇章依存分析方法。這種分析方法不再一次性分析篇章中的所有分析單元,而是分層次地進行篇章分析。首先,建立句子內以EDU為葉子節點的篇章分析子樹;然后建立句子間以句子為葉子節點的篇章分析樹。最后,整合兩層分析結果,形成整篇文章的篇章依存分析樹。分層次的方式可以避免一次性分析篇章中的所有EDU,減少了篇章依存分析器所需面對長距離依賴對的數目,從而緩解了長距離依賴這一性能瓶頸問題。另一方面,該方式還帶來了可以根據不同層次的特點、設計更有針對性的分析策略的好處。與此同時,本文選取改進的長短時記憶模型,結合注意力機制來獲得分析單元的表示,避免特征提取。在RST篇章樹庫上進行實驗,結果表明,本文基于LSTM的層次化篇章依存分析方法避免了耗時的特征設計,且實驗效果超越了同類深度學習模型。
1 如何分層次建立篇章依存分析樹
本文利用層次化的依存分析方法,為整個篇章建立一棵篇章分析樹,其過程分為三個階段。
(1) 句內層次篇章依存分析: 針對每個句子,將句子中的EDU依次輸入到B中,建立句子級別的、以EDU為葉子節點的篇章分析子樹,如圖1所示。

圖1 句內篇章依存分析示例
(2) 句間層次篇章依存分析: 針對整個篇章,將句子作為一個篇章分析單元,將其向量表示依次輸入B中,建立以句子為葉子節點的篇章分析樹,如圖2所示。
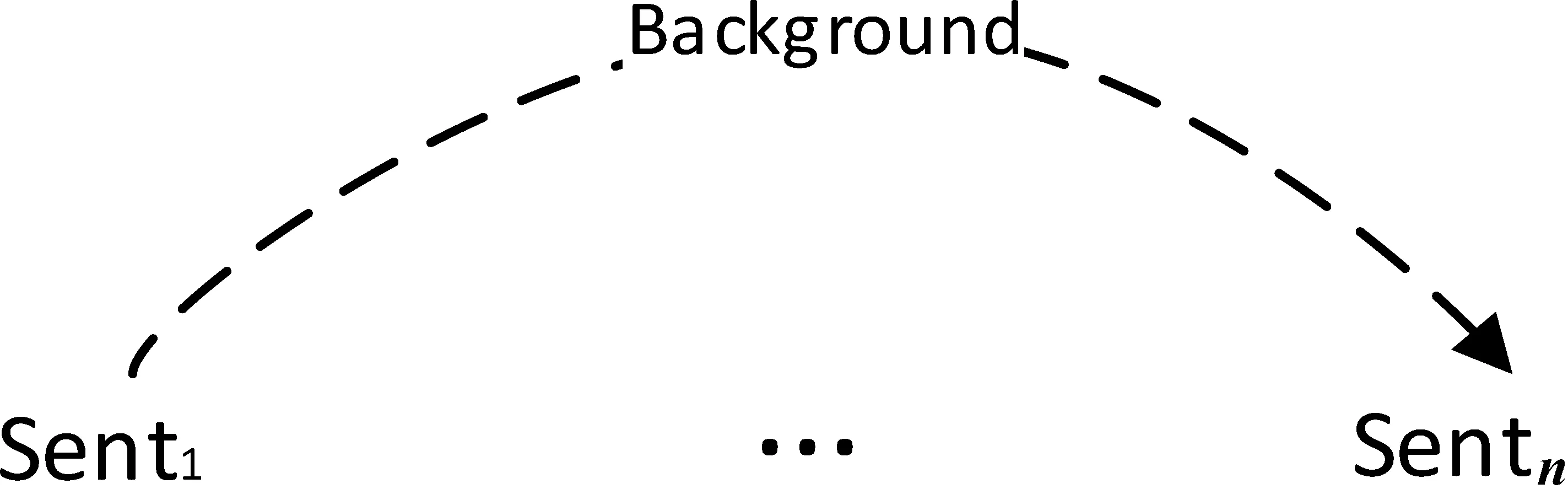
圖2 句間篇章依存分析示例
(3) 整合分析結果: 用句內層所預測的句子級別的篇章分析子樹的根節點標號代表句間層中的句子節點,整合兩層的預測結果,得到整個篇章以EDU為葉子節點的篇章分析樹,即最終篇章依存分析結果,如圖3所示。
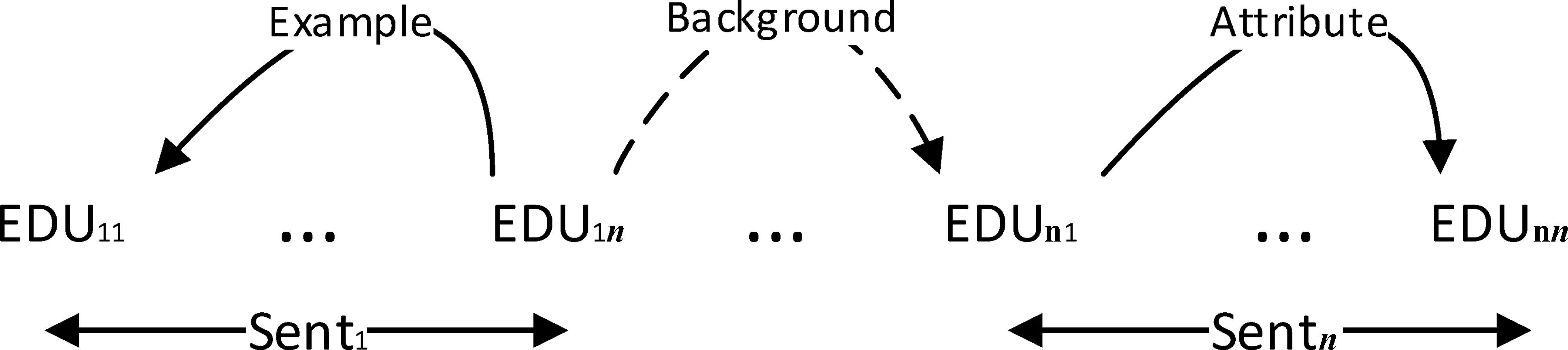
圖3 整合句內和句間篇章依存分析結果
2 基于LSTM的層次化篇章依存分析模型
2.1 長短時記憶模型
Sepp Hochreiter于1997年設計了長短時記憶模型(LSTM)緩解了長期困擾循環神經網絡(Recurrent Neural Network, RNN)[12-14]的梯度消失或梯度爆炸問題。經典的LSTM包含輸入門、輸出門、遺忘門三種門控和一個記憶單元。長短時記憶模型具有多種改進形式。例如,雙向LSTM、樹形LSTM、多層LSTM等。本文選擇雙向LSTM來提供篇章分析單元的向量表示,具體表示方法在2.4節中詳述。
2.2 基于轉移的分析方法
本文采用Arc-eager模式的基于轉移的篇章分析方法來生成篇章分析樹。Arc-eager轉移模式改進了Arc-standard[15]轉移方法的限制條件。樹節點無需找到其所有子節點就可以連接其頭節點。該分析方法包括Shift、Left-Arc、Right-Arc、 Reduce等四種轉移動作,動作轉移過程如表1所示。以本文基于RST語料的篇章依存分析為例,表1中B、S和A分別用于保存輸入的篇章分析單元序列、轉移過程中形成的子樹表示以及轉移狀態。x和y表示B和S的頭節點。Shift操作將B的頭節點轉移到S的頭元素位置;Reduce操作將S中的頭節點彈出。Left-Arc根據所預測的依存關系在S和B的頭節點之間建立依存弧,其中B的頭節點為核心節點,S的頭節點為附屬節點。動作執行后S中的頭節點被彈出,將轉移狀態保存到A中。相應地,Right-Arc根據所預測的依存關系在S和B的頭節點之間建立依存弧,其中S的頭節點為核心節點,B的頭節點為附屬節點。動作執行后B中的頭節點被推入S中,將轉移狀態保存到A中。

表1 Arc-eager模式分析方法轉移狀態
2.3 層次化篇章分析模型
2.3.1 模型結構
本文基于LSTM的Arc-eager模式篇章分析框架如圖4所示。將輸入的篇章分析單元依次存入B中。在初始狀態下,使篇章中的第一個分析單元處于B的頭元素位置,連接B中的前兩個元素來獲得輸入序列B的向量表示;將分析過程中產生的中間子樹結構存入S中,用S的頭元素構造其向量表示;對于S和B而言,這里的“元素”在句內篇章分析層次為基本篇章分析單元,在句間篇章分析層次是指句子。A用于存放篇章分析過程中產生的歷史轉移狀態,包括轉移動作和元素對之間的依存關系。連接A中的前三個轉移狀態的向量表示來構造模型的歷史轉移狀態表示。本文句內層次的篇章依存分析和句間層次的篇章依存分析都依照此模型結構進行實驗,句內和句間層次的篇章分析的輸入信息有所不同,將在2.4節中詳述。圖4中,SH代表轉移動作為Shift,RA(Li)表示轉移動作為Right-Arc,依存關系為List。
整個樣品前處理過程不需要樣品轉移就能得到經皂化、萃取、干燥、過濾后的待分析試液,大大簡化了檢測操作過程中的樣品前處理步驟,有可能引入誤差的環節也相應減少,分析結果的精密度得到明顯改善。在實際操作時,可把樣品管放到配套的試管架上,將放置有樣品管的試管架一起放入超聲振蕩器中皂化、萃取,有利于批量樣品的處理。筆者等建立的煙草中茄尼醇高通量分析檢測方法和GB/T 31758-2015方法相比,日樣品處理量可提高5倍以上,大大提高了樣品分析檢測效率。
將S、B、A三部分的向量表示連接起來,經過一個ReLU變換和兩個用ReLU作為激活函數的全連接層處理后,得到pt,即t時刻的篇章分析狀態。將pt進行仿射變換后,輸入到softmax多分類器中,預測各個轉移狀態的概率,取概率最大的轉移狀態為當前時刻的模型預測結果。本實驗采用貪心策略進行解碼,交叉熵作為損失函數。

圖4 篇章依存分析模型結構
2.3.2 模型分析過程
本節以RST語料庫中的篇章wsj_0609為例,來說明本模型的篇章依存分析過程(這里以不分層次的傳統分析方法為例,即一次性處理篇章中的所有EDU,直接得到整篇文章以EDU為葉子節點的分析樹)。該篇章包含185個EDU。這里給出其中前4個EDU所構成片段([PresidentBushinsists]E1[itwouldbeagreattool]E2[forcurbingbudgetdeficit]E3[andslicingthelardoutofgovernmentprograms.]E4)的依存分析過程。表2列出了執行完每一個轉移狀態后,A、S和B中的內容和狀態更新。狀態0代表篇章分析的初始狀態,此時A和S為空,B中存放了所有輸入EDU,從第一個EDU開始順序分析。根據當前S、B和A的狀態表示,預測轉移狀態并存入A中,即更新A的狀態。根據轉移狀態執行相應動作,并建立依存關系(Arc-eager模式),從而更新S和B中的內容;更新后的S、B和A構成了下一次預測的狀態表示基礎。直到B為空,A包含了分析整篇文章的所有轉移狀態,S中即為整篇文章的篇章依存分析樹。A中粗體轉移狀態即為根據前一狀態的向量表示所預測的轉移。
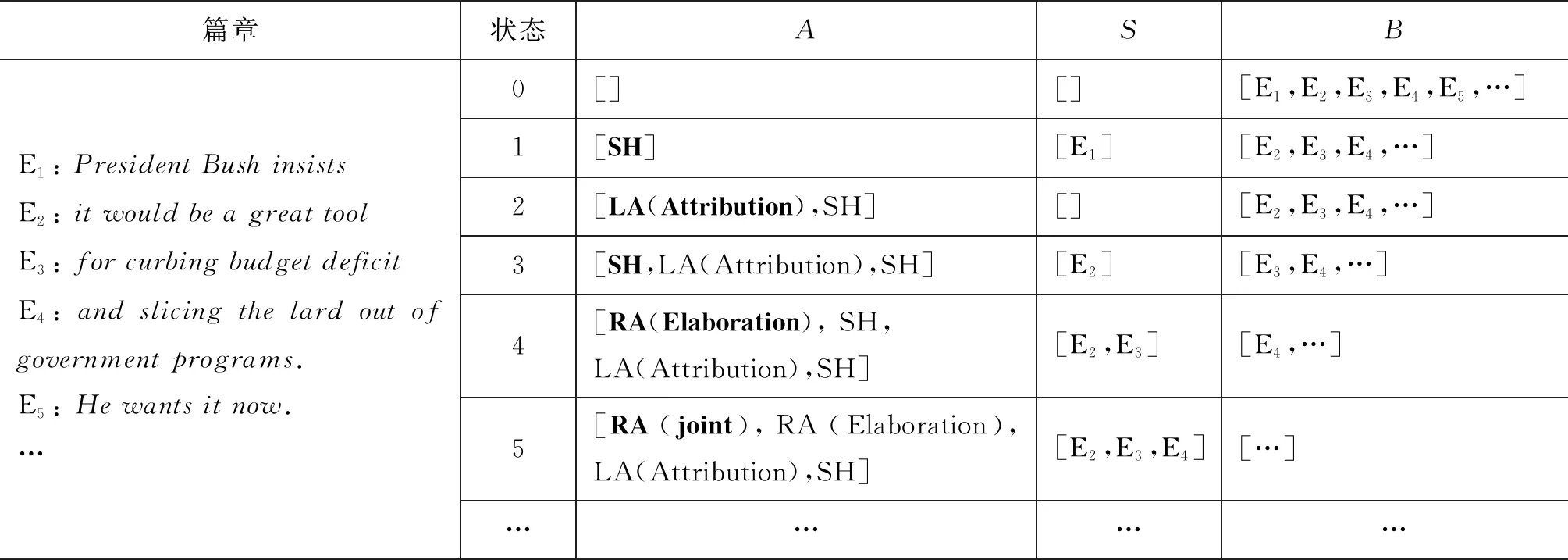
表2 模型狀態轉移過程
根據表2中的狀態轉移過程,篇章中的前4個EDU可以構成圖5中的篇章依存分析子樹。在此基礎上,通過繼續進行轉移預測和狀態更新得到整個篇章的依存分析樹。

圖5 篇章片段的依存分析子樹結構
2.4 不同層次的篇章分析單元表示方法
如圖4所示,采用雙向長短時記憶模型結合注意力機制來表示B和S中的篇章分析單元。篇章分析單元在句內層為EDU,在句間層為句子。
具體來說,本文將篇章分析單元中的單詞序列輸入到雙向LSTM中,使用注意力機制去捕捉詞序列中的重點單詞。將雙向LSTM的順序和逆序輸出連接起來,構成篇章分析單元的詞匯信息表示。采用GloVe詞向量[16]初始化篇章分析單元中的單詞的向量表示。本文通過斯坦福自然語言處理工具(Stanford CoreNLP Toolkit)[17]來獲取篇章分析單元中單詞的詞性信息。與詞匯信息的建模方式類似,本文同樣采用雙向長短時記憶模型結合注意力機制來獲得篇章分析單元的詞性信息表示。由于建模詞匯信息和詞性信息的網絡結構相同,圖4中省略了建模詞性信息的網絡結構。最后,將篇章分析單元的詞匯信息和詞性信息的向量表示連接起來構成了S和B中的篇章分析單元的向量表示。
3 實驗與分析
3.1 實驗語料
本文采用RST篇章樹庫進行實驗,RST語料庫包含385篇來自《華爾街日報》的新聞報道,包括超過176 000個單詞。最長的篇章包括2 124個單詞,平均每篇文章包含458.14個單詞,56.59個EDU。平均每個EDU包含8.1個單詞[3]。雖然RST篇章樹庫所包含的篇章數目不多,但是語料庫中的篇章篇幅較長;并且包括財務報告、故事、商業新聞、文化評論和社論等多種題材,篇章結構關系豐富且復雜。因此,幾乎所有針對英文的篇章成分分析和篇章依存分析工作都選用RST篇章樹庫進行實驗。這也帶來了實驗結果公平、易于對比的優點。
RST篇章樹庫建立在修辭結構理論框架下,首先將篇章切分為基本篇章分析單元,然后通過修辭結構來標注EDU之間的結構和修飾關系,并按照EDU的作用和重要性將其分為核心(Nucleus)和附屬(Satellite)兩種成分。其中表達中心思想和主要信息的EDU作為核心,起到補充說明和修飾作用的EDU作為附屬。本文選擇Li等[7]的方式,將RST語料庫中的成分分析樹轉換為依存分析樹,同樣選取其中380篇文章進行實驗,包括訓練集312篇,驗證集30篇,測試集38篇。同時本文選取RST篇章樹庫中的111個細粒度關系進行實驗。
3.2 評價指標
無標記正確率(Unlabeled Attachment Score, UAS)[18-19]和有標記正確率(Labeled Attachment Score, LAS)[20]是句法依存分析和篇章依存分析工作普遍采用的評測指標,便于比較各種同類工作的實驗效果。本文即采用UAS和LAS作為篇章依存分析的評測標準。以RST篇章樹庫為例,無標記正確率是指測試集中找到正確的支配節點的EDU數目占該篇章中總EDU數的比例;有標記正確率是指測試集中找到正確的支配節點,并且EDU對之間的修辭關系也預測正確的EDU數占該篇章中總EDU數的比例。其中,支配節點指在修辭關系中占據核心和主導地位的節點即核心節點;相應地,附屬節點指在修辭關系中充當附屬成分的節點。
3.3 基線方法
本文將層次化的篇章分析模型和表3中的幾種基線方法進行對比。①Basic[21]: 該方法同樣為基于轉移的篇章依存分析器,使用深度學習模型(LSTM)獲得篇章分析單元的向量表示;但是,為達到較好的實驗效果,該工作引入多種位置信息來獲得篇章分析單元的向量表示,并且采用一次性處理文章中所有基本分析單元的方式進行篇章依存分析。②Hierarchical parser(no feature): 本文層次化的篇章分析法,在句內和句間的篇章分析過程中都不引入任何特征和位置信息,采用2.4節介紹的篇章分析單元表示法來建模EDU或句子;③Refined[21]: 在Basic方法的基礎上,為緩解長距離依賴的篇章分析單元對間的結構和修飾關系難以捕捉的問題,該方法設計了一種記憶網絡,自動地捕獲篇章分析單元間的銜接性和話題線索,從而提高篇章依存分析效果。④Hierarchical parser: 本文層次化的篇章分析法。為發揮層次化的依存分析方法根據不同層次建模的優勢,在2.4節的篇章分析單元表示方法基礎上,在句間分析層次,引入待分析的句子對是否在同一段內的信息來反應篇章結構特點。⑤MST-full[7]: 該方法是目前效果最好的基于圖模型的篇章依存分析器。
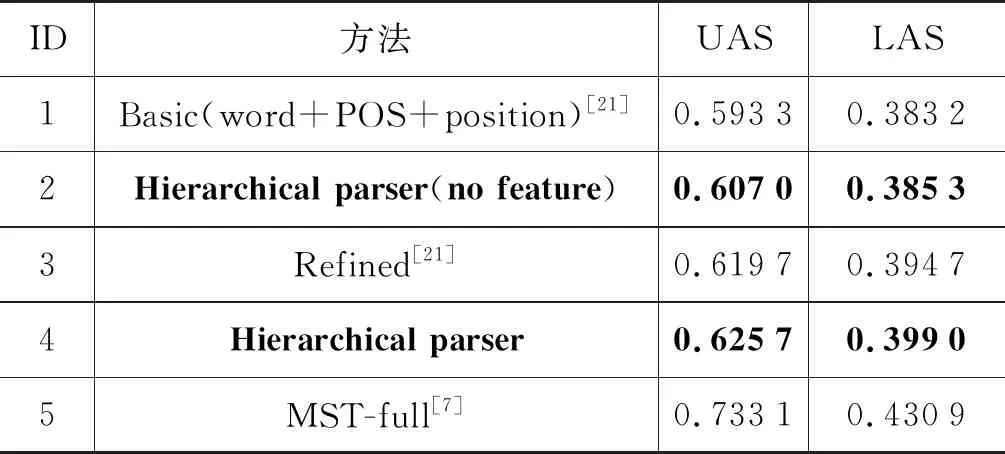
表3 篇章依存分析效果對比
3.4 實驗結果分析
本文在表3中列出了篇章依存分析結果。通過比較可以發現,使用LSTM獲取篇章分析單元的向量表示的Basic方法依然無法避免各種特征提取。采用本文層次化的篇章分析方法(Hierarchical parser(no feature)),即使在不引入任何手工或外部工具提取的特征的前提下,實驗效果在UAS和LAS上都高于Basic方法。這說明通過層次化的方式減少篇章分析器所需處理長距離依賴的數目,確實能夠提升篇章分析效果。但是,和Refined方法相比,Hierarchical parser(no feature)效果稍遜。主要原因是Refined方法不僅需要抽取多種特征,而且該方法設計了一個記憶網絡,將篇章中在向量空間上相似的篇章分析單元聚類到相同的記憶槽中,再將記憶槽的向量表示加入到篇章分析單元的向量表示中。這樣,為每一個篇章分析單元標記了其話題線索,這種話題線索反應了篇章的結構信息和分析單元對間的依存關系。為此,在Hierarchical parser中,在句間層次,本文引入待分析的篇章分析單元對(句子對)是否在同一段內的簡單位置信息來反應篇章中淺層的結構信息。雖然加入段落信息的方式比使用記憶槽捕捉話題線索的方式簡單粗略,但是,Hierarchical parser的篇章依存分析效果依然在UAS和LAS上都超過了Refined分析方法。并且,Hierarchical parser只在句間層次引入句子對是否在同一段這一種位置信息來標記篇章淺層結構,并沒有引入任何其他特征;而Refined方法中運用了多種不同特征,例如,用EDU在句子內、段落內和文章中的位置來表示篇章分析單元;還引入了EDU之間是否在一句內、是否在一段內、以及距離信息來表示EDU對之間的位置關系。Hierarchical parser所引入的結構信息遠少于Refined方法。可見,層次化的篇章依存分析模式本身較傳統的整篇文章一次性處理完成的篇章依存分析模式更有優勢。
由于現存的篇章依存分析工作較少,依存分析樹又不能一一對應的轉換為成分分析樹,因此本模型難以和其他篇章成分分析工作公平的對比實驗結果。本實驗采取同樣的實驗設置和目前效果最好的篇章依存分析實驗MST-full進行對比,雖然效果還有差距,但是MST-full運用了6個復雜特征集,包括詞匯、詞性、長度信息、位置信息、語義相似度特征、句法分析結果等。其中語義相似度和句法分析結果等特征需要引入外部資源和工具才能獲得;另外,MST-full是基于圖模型的篇章分析方法,不需要按照某個順序去判斷篇章分析單元之間的結構關系,可以搜索全局最優解。但圖模型的篇章分析方法(O(n3))具有比本文基于轉移的分析法(O(n))更高的時間復雜度。
為更好地說明分層次的篇章依存分析模型在不同細粒度關系上的分析效果,本文對表3中的Hierarchical parser(ID 為4)的實驗結果進行細化,在表4中給出語料中數量最多的前8種細粒度關系和兩種數量較少的典型關系(example和background)的UAS和LAS分析結果,并標記了這些關系在語料庫和測試集中出現的次數。可以發現,除了elaboration-additional和List兩種關系之外,語料庫中數量較多的關系,由于訓練數據豐富,實驗效果通常更好。關系elaborate-additional在語料庫中的總數量較多,但分析效果不理想的主要原因是: elaborate-additional(此關系表示附屬成分是核心成分的細化或附加詳盡說明)在關系含義上和elaboration-additional-e(當附屬成分是嵌套結構elaborate-additional變為elaboration-additional-e)以及elaboration-object-attribute-e(不同于elaboration-additional-e之處在于附屬成分是其所修飾的核心成分的本質屬性)十分相似,容易混淆。并且elaborate-additional在句內和句間層次的分布不均勻,句內層次分布較少。與其相似的elaboration-object-attribute-e在句內篇章分析層次出現了超過 2 000 次,導致篇章分析器因為“從眾”傾向,做出誤判。List關系通常標識并列語義或者結構,不同于其他關系,List關系的跨度通常較長,因此判斷難度更大。
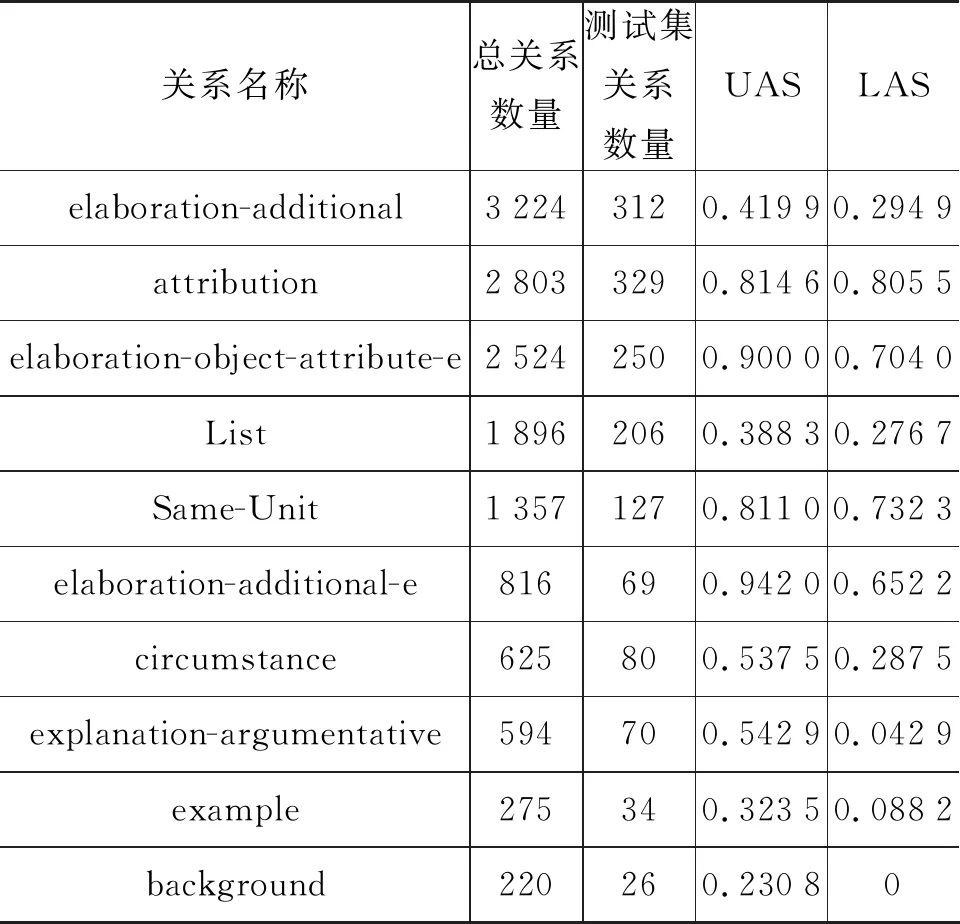
表4 不同細粒度關系的分析效果
4 結束語
本文提出了一種層次化的篇章依存分析方法,該方法通過長短時記憶模型處理篇章分析單元中的序列信息,獲得篇章分析單元的向量表示,避免了特征提取。在RST篇章樹庫上進行實驗,結果表明,層次化的篇章依存分析方法的實驗效果超過了不分層次、但提取了必要特征的同類深度學習模型。這說明分層次建立依存分析樹的方式,通過減少篇章分析器所需處理長距離依賴對的數量,緩解了長距離依賴分析效果差這一依存分析的性能瓶頸問題。實驗效果證明,這種層次化的篇章依存分析框架是一種提高篇章依存分析性能的有效途徑。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
