基于樹形語義框架的神經語義解析方法
2021-03-18 02:52:46趙睿卓高金華孫曉茜沈華偉程學旗
中文信息學報 2021年1期
趙睿卓,高金華,孫曉茜, 徐 力,沈華偉,2,程學旗,2
(1. 中國科學院 計算技術研究所 網絡數據科學與技術重點實驗室,北京 100190;2. 中國科學院大學 計算機與控制學院,北京 100049)
0 引言
語義解析的目標是將自然語言表達映射為機器可理解的邏輯表達,使得人類和機器能夠更加方便地進行交互。語義解析在問答、指令解釋和代碼生成等自然語言理解任務中均有重要的應用。為了適配不同的應用需求,目標邏輯表達的形式也不盡相同。常見的邏輯表達包括FunQL、λ演算和以SQL查詢和python代碼為代表的編程語言等。考慮到λ演算的表達能力和靈活性,本文采用λ演算作為目標邏輯表達的表示形式。
早期的語義解析方法[1]通常采用詞典和包含一系列組合規則的語法共同作用的方式生成邏輯表達。對于一個給定的自然語言表達,該類方法先根據詞典和語法規則產生目標邏輯表達的備選集,再學習一個打分函數來對備選集中的邏輯表達進行打分,并將得分最高的邏輯表達作為最終的解析結果。然而,詞典和語法通常被限制在一個特定領域并且訓練過程需要大量的特征工程。隨著深度學習的發展,越來越多的結合深度神經網絡的神經語義解析方法[2]被提出。該類方法通常采用編碼器—解碼器框架,將自然語言表達作為輸入,邏輯表達作為輸出,以端到端的方式進行訓練,在語義解析任務上取得了目前最好的效果。
神經語義解析方法面臨的關鍵挑戰在于如何捕獲蘊含在自然語言中的組合語義。大部分現有的工作從語法的角度切入,通過在序列化解碼器中引入語法限制或者模板限制來建模組合語義。然而,此類方法引入的語法或者模板是領域特定的,不能覆蓋所有的自然語言輸入。還有一類工作提出,使用樹形結構的解碼器來更好地建模邏輯表達的層次化語義結構。雖然這類模型相比于簡單的序列化解碼器取得了更好的效果,但是其忽略了語義相似的句子通常有相同語法結構的事實,如圖1(a)所示。文獻[3]提出了一個由粗到精的解碼框架來捕獲不同層次粒度的語義。該方法將邏輯表達分為包含高層次語義的語義框架(Sketch)表示和包含細粒度語義的語義細節。然而,該方法提出的高層次語義框架仍然是用序列化的方式解碼生成的,不能很好地建模語義框架的層次化結構,如圖1(b)所示。

圖1 自然語言與邏輯表達示例(a) 是兩個自然語言表達和它們分別對應的的邏輯表達;(b) 展示了兩個邏輯表達共同的語義框架和樹形結構。
本文提出生成樹形語義框架來更好地建模邏輯表達的組合語義,該模型包含兩個階段。第一階段使用一個樹形結構的解碼器自頂向下地生成自然語言的語義框架,第二階段結合生成的語義框架和自然語言輸入來解碼得到最終的邏輯表達。該模型有兩個優點。首先,采用語義框架作為中間形式,使得相似的邏輯表達能夠在不同的語義層次上共享相同的語義框架。其次,樹形結構的解碼器能夠保證語義框架中不同組成部分的解碼獨立性,進而生成更好的語義框架。大量的實驗結果表明,該模型能夠更準確地生成語義框架,并且在語義解析任務中取得更好的效果。
1 相關工作
在語義解析發展的數十年中,很多不同的方法被先后提出。現有的大部分方法主要采用監督學習的形式,通過自然語言句子和對應的邏輯表達來訓練得到語義解析器。早期的方法通常以詞典和包含一系列組合規則的語法為基礎生成邏輯表達。對于一個給定的自然語言句子,這類方法首先根據語法和詞典生成目標邏輯表達形式的備選集,再訓練一個打分函數對備選集中的邏輯表達進行打分排序,并將得分最高的邏輯表達作為最終的解析結果。常見的語法規則包括組合類型語法(CCG)[4]、同步上下文無關語法(SCFG)[5]、基于依存的組合語法(DCS)[6]等。然而,這類方法中的語法和詞典通常只能用于特定的領域或者特定的邏輯表達形式,并且訓練的過程需要大量的特征工程。相比之下,本文提出的模型以端到端的方式運行訓練,不需要進行特征工程,并且能夠靈活地遷移到不同的領域和邏輯表達形式。
最近,基于深度神經網絡的編碼器—解碼器模型已被廣泛應用到語義解析任務中并取得了較好的效果[7]。這些方法的關注點集中在建模邏輯表達的語法結構。一些工作通過引入先驗知識來限制解碼器的輸出,包括語法規則和邏輯表達模板等。文獻[8]把語法規則作為解碼器的輸出空間,文獻[9]設計了一個語法限制的解碼器來生成抽象語法樹(ASTs),文獻[10]將解碼過程設計為對預定義SQL模板進行填槽。然而,預設的語法規則和邏輯表達模板很難覆蓋整個輸出空間,限制了該類方法的實際應用場景。此外還可通過設計結構化的解碼器來捕獲邏輯表達的語法結構。文獻[7]提出一個層次化的樹形結構解碼器來建模邏輯表達的組合結構。文獻[3]提出一個由粗到精的解碼框架來建模不同粒度的語義。該方法首先生成一個粗粒度的語義框架(sketch),再將該語義框架用于指導最終邏輯表達的生成。
我們的模型也采用語義框架來建模邏輯表達的組合結構。與之前工作不同的是,該模型通過一個樹形結構的解碼器自上而下地生成語義框架。樹形結構的解碼器能夠層次化地捕獲組合語義并且保證解碼過程中不同組成部分的獨立性,進而更好地生成語義框架。
2 問題定義
語義解析任務的目標是基于自然語言輸入和邏輯表達來訓練得到最終的語義解析器。給定自然語言句子表達X=x1,…,x|x|和其所對應的邏輯表達Y=y1,…,y|Y|,語義解析任務的目標是建模條件概p(Y|X)。
這個概率被分解為以下兩個部分,如式(1)所示。
其中,S=s1,…,s|S|代表輸入句子的語義框架。第一個階段以概率p(S|X)生成語義框架S;第二個階段在輸入X和語義框架S的指導下以概率p(Y|X,S)生成最終的邏輯表達。語義框架是以自上而下的方式生成的,概率p(S|X)可以分解為如式(2)所示。
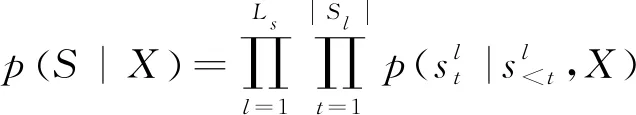
(2)
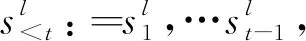
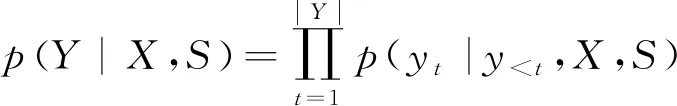
(3)
其中,y 本節主要介紹我們所提出的兩階段模型以及其訓練和推斷過程。 模型流程包含兩個階段: 語義框架生成和邏輯表達生成(圖2)。在語義框架生成階段,使用一個序列化的編碼器來編碼自然語言句子,并通過一個樹形結構的解碼器生成對應的語義框架;在邏輯表達生成階段,將生成的語義框架編碼成向量,并與輸入句子的編碼向量一起作為最終邏輯表達生成的指導信息。 圖2 模型整體流程示意圖左半部分表示樹形結構語義框架的生成過程,右半部分表示給定語義框架下邏輯表達的解碼過程。 語義框架生成部分包括一個編碼器和一個樹形結構的解碼器。編碼器把輸入的自然語言句子轉化成向量表示,然后由解碼器生成對應的語義框架。 3.2.1 自然語言句子編碼 我們采用帶LSTM單元的雙向循環神經網絡作為輸入部分的編碼器。每個詞的表達是對應的前向和后向LSTM單元的狀態合并。對于第t個詞xt,它首先由xt=WXo(xt)被映射成一個向量,其中xt代表xt的n維向量表示,o(xt)是一個代表詞xt索引的one-hot向量,WX∈Rn×|VX|是詞典VX的表示矩陣。在得到了xt的詞向量之后,它的表示et由兩個方向的隱狀態向量合并得到,計算如式(4)~式(6)所示。 3.2.2 語義框架解碼器 為建模語義框架的層次結構和組合語義,本文采用樹形結構的解碼器來生成語義框架。 該解碼器先將語義框架轉化為層次化的樹形結構形式。我們引入一些特殊的符號來刻畫語義框架的層次化結構。如圖3所示,非終止符“ 圖3 語義框架解碼器示意圖虛線框中展示了樹形解碼器的模型實現細節 解碼器以自上而下的方式逐層生成語義框架。它首先順序地生成樹形結構語義框架的最頂層,直到“”符號生成。如果中途產生“ (7) 上下文向量如式(8)所示。 (8) 其中,W0∈R|VS|×n,W1,W2∈Rn×n,b0∈R|VS|均為參數矩陣。 邏輯表達生成主要基于自然語言輸入X和第3.2節得到的語義框架S。給定X和S,邏輯表達缺失的細節需要被填補,我們同樣也用編解碼的框架來實現。 3.3.1 語義框架編碼 本文采用和自然語言編碼器一樣的結構來編碼語義框架。編碼器將語義框架S編碼成向量{α1,…α|S|}。 這些向量和由自然語言編碼器得到的向量{e1,…e|X|}共同指導邏輯表達的生成。 3.3.2 邏輯表達解碼器 邏輯表達中的詞是由循環神經網絡序列化生成的。在生成邏輯表達中第t個詞yt時,其隱狀態vt由式(11)、式(12)所示。 模型的訓練目標是最大化給定自然語言輸入下生成邏輯表達的對數似然。根據式(1),該似然可以分成語義框架似然和邏輯表達似然兩部分,如式(13)所示。 (13) 其中,D是訓練對的集合,每一個訓練對包含一個句子和對應的邏輯形式。 本文在三個數據集上進行了實驗,并將我們的方法和多個現有方法進行了對比。本節將介紹實驗使用的數據集、模型的參數設置以及實驗結果和分析。 本節簡要介紹實驗中使用的3個語義解析數據集。 JOBS 該數據集包含640個工作列表數據庫的查詢。每對訓練樣本包括一個自然語言問題及其對應的Prolog風格的查詢。我們的訓練—測試數據分割和文獻[4]一致,其中500個實例用于訓練,剩下的用于測試。為了避免低頻詞或未登錄詞帶來的學習問題,我們在三個數據集上進行了參數替換[7]。在該數據集上,變量值“company”、“degree”、“language”、“platform”、“location”、“job area”和“number”都被識別并替換成特定的符號。 GEO 該數據集包含了880個美國地理數據庫的查詢實例。它被拆分為包含680個實例的訓練集和包含200個實例的測試集。該數據集采用λ演算作為目標邏輯表達形式。在該數據集上,變量值“city”、“state”、“country”、“river”和“number”被識別并替換。 ATIS 該數據集包含5 410個對于航班預定系統的查詢。數據被分割為4 480個訓練實例和480個驗證實例以及450個測試實例。該數據集也采用λ演算來作為目標邏輯表達形式。類似地,變量值“date”、“time”、“city”、“aircraft”、“airport”、“airline”和“number”在這個數據集中被識別并替換。 在模型訓練過程中,邏輯表達需要被轉化為對應的語義框架。省去低層次的參數和變量名信息,同時保留謂語、操作符以及組合信息。此外,本文中的語義框架和文獻[3]不同。他們的方法所生成的謂詞包含左括號,但是本文中所有謂詞都保持原來的形式。這個區別在于本文所提模型能自上而下地生成層次化的語義框架,可以避免產生括號不配對等存在語法錯誤的語義框架。 預處理實驗采用和文獻[7]相同的數據預處理方式。首先根據第4.2節中描述的方法標注語義框架,然后按照第3.2節中描述的方法將其轉化為樹形結構。 參數配置在JOBS和GEO數據集上,模型的超參通過在訓練集上的交叉驗證得到,而在ATIS數據集上則是通過模型在驗證集的表現來選擇超參數。隱狀態向量和詞向量的維度從{250,300}和{150,200,250,300}中選擇,dropout rate從{0.3,0.5}中選擇。標簽平滑參數設置為0.1。模型采用GloVe預訓練詞向量作為初始化。訓練過程采用RMSProp作為優化器,并且從{0.002,0.005}中選擇學習率。為了避免梯度爆炸的問題,參數梯度被限制小于5。Batch大小設置為64。 評價指標我們選取邏輯表達的準確率作為評價指標。準確率是指自然語言句子被正確地解析成它們的邏輯表達的百分比。 在三個數據集中,我們選擇了一些之前構建的系統和方法來驗證模型效果,結果分別在表1、表2、表3中展示。注意DCS+L,KCAZ13和GUSP是在問答的設定下進行實驗,因此本文報告的準確率是生成正確答案的百分比。可以看到,神經語義解析方法普遍比之前統計學習的方法效果好。相比于現有的深度學習模型方法,本文提出的兩階段模型能夠建模語義框架不同層次和粒度的語義,而SEQ2TREE和Seq2Act只用了一層的解碼器,不能夠捕獲不同層次的語義。總的來說,本文提出的模型在JOBS和ATIS數據集上得到了最好的結果,在GEO數據集上和目前最好的效果相當。這些結果也表明了模型的有效性。 表1 JOBS數據集的準確率 表2 GEO數據集的準確率 表3 ATIS數據集的準確率 我們進一步分析了語義框架生成的準確率來解釋效果提升的原因。分別將本文模型和Coarse2fine模型生成的語義框架與標準答案進行比對,并將兩個模型的生成準確率記錄在表4中。Coarse2fine用序列化的方式生成語義框架,而我們采用了樹形結構的解碼器。在JOBS、GEO、ATIS三個數據集上,本文所提模型的生成準確率都明顯優于Coarse2fine模型。這說明樹形結構解碼器能夠更好地捕獲語義框架的層次化結構,在語義解析任務上取得更高的準確率。 表4 語義框架的準確率 我們通過一個例子說明樹形結構的語義框架能夠更好地描述邏輯表達組合語義的原因。給定一個輸入句子“whatistheearliestarriveflightfromci0toci1”,樹形解碼器通過兩個輪次生成語義框架。在第一個輪次,模型生成語義框架的最頂層“argmin#1 此外,對于這個例子,我們發現Coarse2fine[3]模型錯誤地將語義框架中的“arrival_time@1”生成為“departure_time@1”。這是因為在訓練數據中,大部分查詢都是在問詢航班離開的時間,使得序列化解碼器在生成語義框架時更傾向于生成 “departure_time@1”。相比之下,本文使用的樹形結構解碼器在不同解碼層生成序列“andflight@1from@2to@2”和“argmin#1 本文中,我們提出生成樹形結構的語義框架來更好地捕獲自然語言表達中蘊含的組合語義。首先使用樹形結構解碼器自上而下地生成語義框架,再將生成的語義框架與自然語言句子結合來指導最終邏輯表達的生成。樹形結構解碼器能更好地捕獲語義框架的層次化結構,進而生成更精確的語義框架。實驗結果顯示,模型在語義框架生成和邏輯表達生成這兩階段的準確率都有所提升。此外,我們通過案例分析進一步說明了樹形結構語義框架的好處。未來工作方面,我們將研究小標注樣本下的語義解析問題。3 模型
3.1 模型概覽
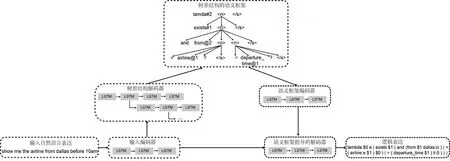
3.2 語義框架生成
”符號和“<(>”符號被分別用來標識解碼頂層語義框架和各級子樹的起始狀態,“”符號被用來標識解碼過程的終止。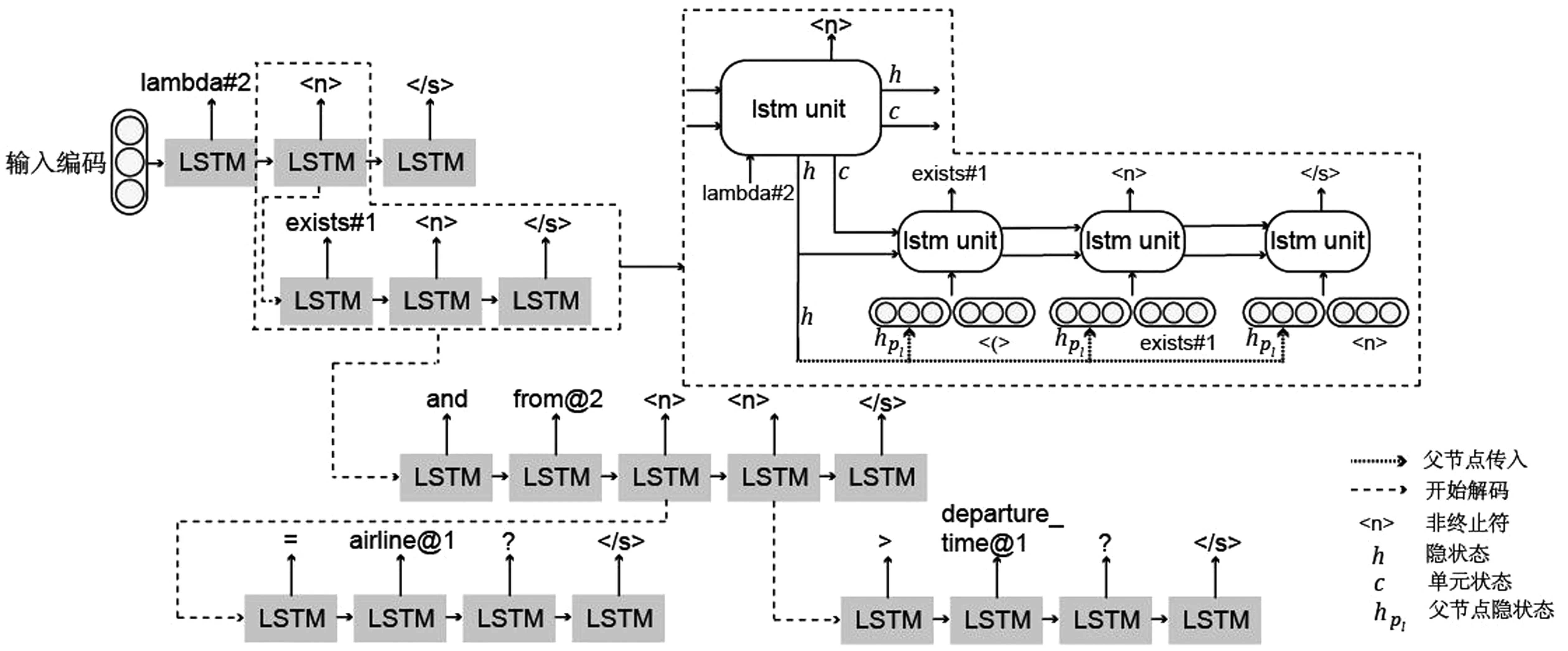
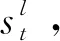
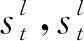
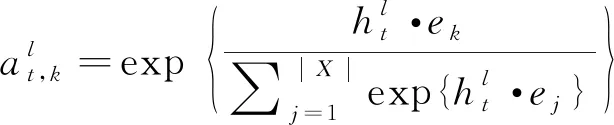
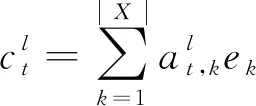
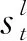
3.3 邏輯表達生成

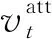
3.4 模型訓練和推斷
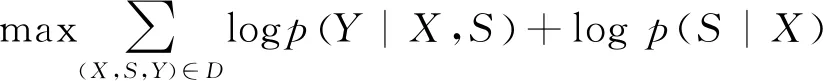
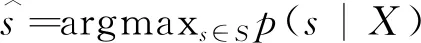
4 實驗
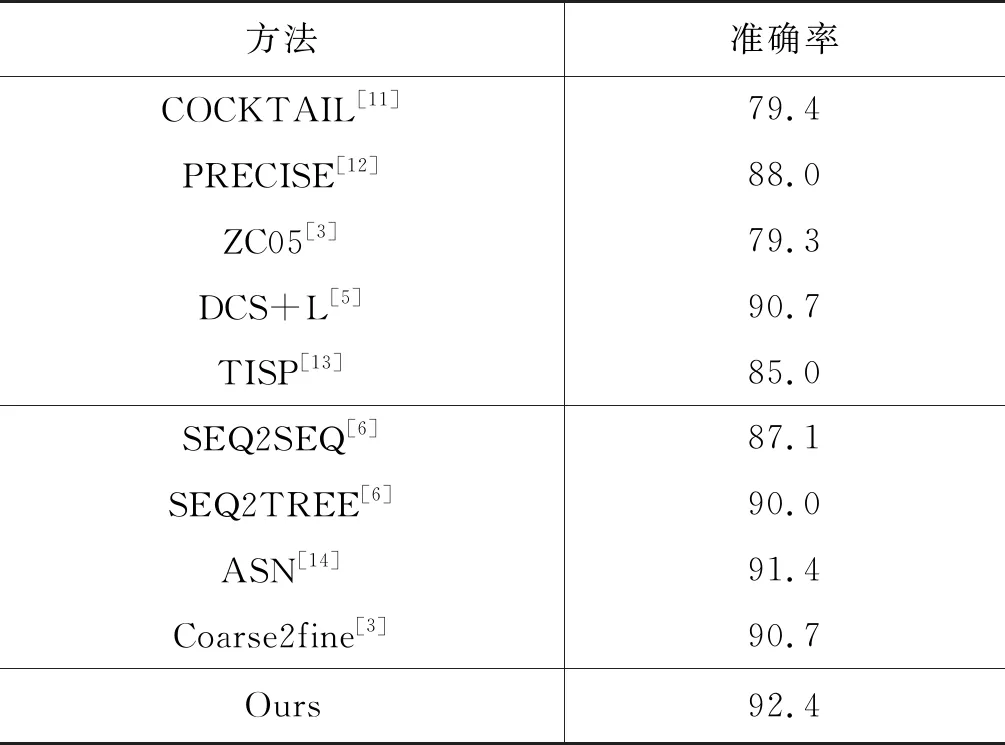
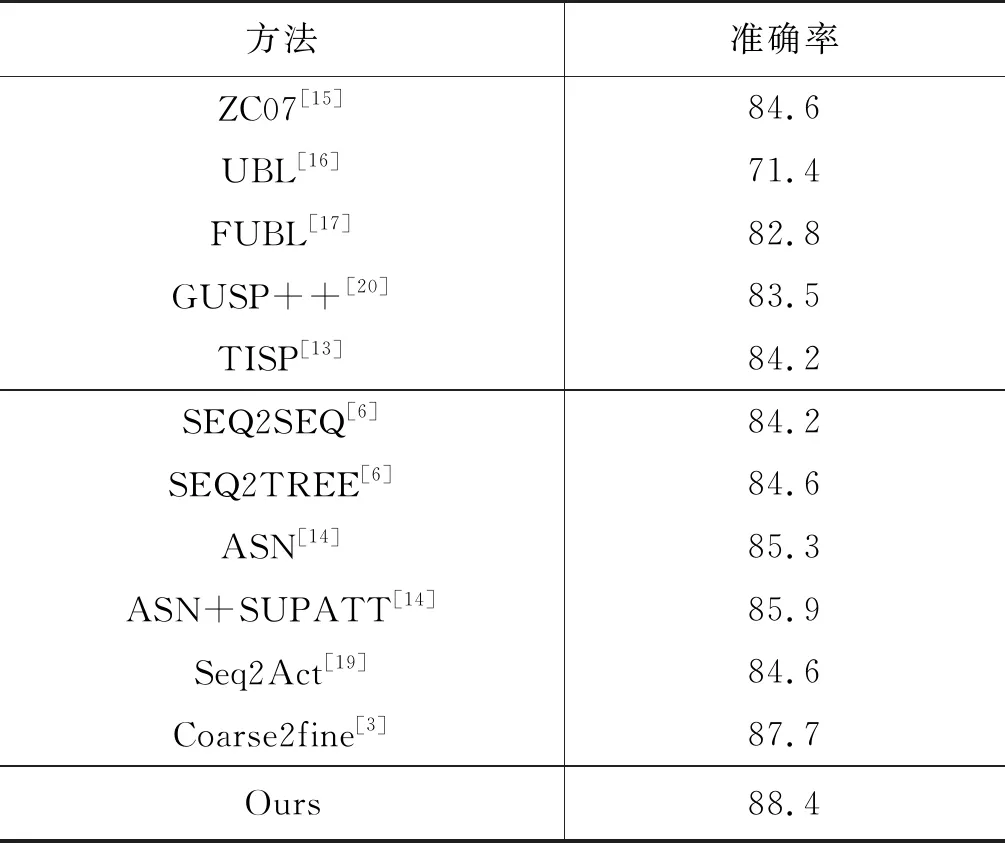
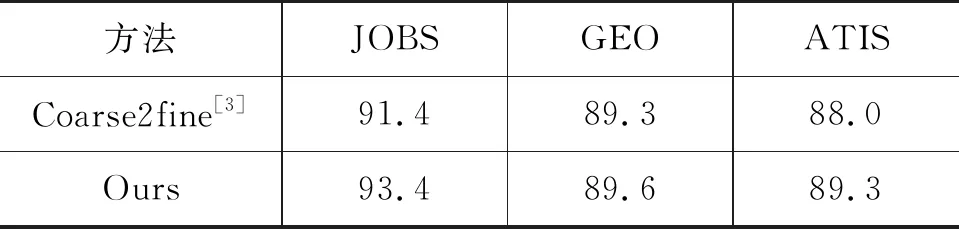
4.1 數據集
4.2 語義框架標注
4.3 實驗設置
4.4 實驗結果分析

4.5 樹形結構的語義框架分析
5 總結與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
現代企業(2015年9期)2015-02-28 18:56:50
