基于對抗補丁的交通標牌攻擊*
2021-03-20 12:49:38葛萬成
通信技術 2021年3期
葉 斌,葛萬成
(同濟大學,上海 200092)
0 引言
深度神經網絡在許多計算機視覺任務中取得了很好的性能,有時候其表現超過了人類[1-3]。基于這些良好的表現,深度神經網絡開始越來越多地應用于自動駕駛[4-5]、無人機[6-7]以及機器人[8]等控制系統,其中自動駕駛技術的日趨成熟引起了研究人員的廣泛關注。深度神經網絡具有強大的特征提取能力,在圖像分類和識別中能夠達到很好的精度。自動駕駛的環境感知系統依賴于激光雷達技術、圖像識別以及目標檢測等前沿技術,其中基于深度神經網絡的交通標牌識別是自動駕駛的重要技術之一。
雖然深度神經網絡在圖像識別上有著極好的性能,但最新的研究表明,深度神經網絡在很大程度上容易受到對抗樣本的攻擊。這些對抗樣本是攻擊者精心選擇的輸入,會導致網絡改變輸出,且這些經過攻擊者精心設計的對抗樣本通過人眼是無法區分的[9-10]。攻擊者可以通過使用一些優化策略只需對圖像少量像素進行修改,即可得到所需要的對抗樣本。通常的優化策略有L-BFGS[9]、FGSM[10]、DeepFool[11]以及PGD[12]等。其他攻擊方法如基于Jacobian 的顯著性映射[13]的攻擊方法是尋找圖像中需要修改的像素,以達到圖像中所需要修改的像素最少。有些對抗樣本已經被證實可通過物理打印機打印出來并在現實世界中起作用。Kurakin 等人[14]證明了對抗樣本在打印之后,即使在不同的光線和方位情況下仍然能夠誤導模型的輸出。Sharif 等人[15]研制出了一幅帶有對抗擾動的“眼鏡”,戴上這副眼鏡可以躲過人臉識別系統或者將佩戴者識別成另一個人。
從先前的研究可以看出,對抗樣本在數字領域是有著較強的攻擊性。但是,在現實的物理世界中,對抗樣本比較脆弱,主要存在于物理場景,面對一些挑戰。例如:現實生活中的物理場景的背景是多變的,攻擊者無法通過控制背景來攻擊;在不同的光線、距離和角度的作用下,對抗擾動會失效;擾動太小無法使圖像傳感器進行捕捉。
自動駕駛的圖像識別系統是保證自動駕駛安全性和可靠性的關鍵一環。當攻擊者意圖在真實的交通標志牌上添加擾動時,若成功攻擊圖像識別系統,將會造成巨大的安全隱患甚至災難。針對對抗樣本的物理挑戰和對抗樣本在自動駕駛領域中的應用,本文采用一種添加對抗補丁的方法來實現對交通標志識別模型的攻擊。該方法屬于白盒攻擊,在熟知網絡模型的結構參數時生成特定的補丁加入交通標牌的周圍,使得識別器對原本的交通標志做出錯誤分類。
本文主要貢獻如下:
(1)將對抗補丁的方法應用到交通識別牌識別系統上;
(2)對抗補丁的設計采用隨機位置隨機旋轉的方式,使得生成的補丁不局限于圖像的某個位置,忽略了背景的干擾;
(3)通過實驗驗證對抗補丁的方法在GTSRBVGG16 的效果,為后續的研究者提供參考。
本文第1 節主要介紹對抗補丁的方法,主要包括使用的數據集、GTSRB-VGG16 模型和對抗補丁生成的原理。第2 節主要是實驗的設計和分析,驗證了補丁方法在GTSRB-VGG16 的效果。第3 節對本文做出總結,分析對抗補丁方法在自動駕駛上應用的意義,并對未來的工作和挑戰進行展望。
1 方 法
1.1 數據集GTSRB 介紹
The German Traffic Sign Benchmark(GTSRB)德國交通標志基準是2011 年國際神經網絡聯合會議(International Joint Conference on Neural,Networks,IJCNN)舉辦的多級單圖像分類挑戰。該數據集中包含43 個交通標志類,訓練集中包含超過30 000多張圖片,測試集中超過10 000 多張圖片。圖1 為部分數據集展示。數據集中包括的各類圖片考慮了距離、光照以及模糊度等因素,第一行從左到右依次是限速20、限速30、限速70、限速60、直行左轉,第二行從左到右依次是STOP、禁止通行、左轉、直行和限速50。

圖1 GTSRB 部分數據集展示
1.2 GTSRB-VGG16 模型
本文采用的是GTSRB-VGG16 模型。GTSRBVGG16 模型與原始的VGG16 模型的主要區別在于在每一層卷積層后加入了BN 層來加快模型的訓練和防止模型訓練過擬合,且最后一層全連接層為1×1×1 000 的修改為1×1×43,以契合GTSRB 的數據訓練。GTSRB-VGG16 模型結構如圖2 所示。將GTSRB 數據集的圖像使用修改過的VGG16 模型進行訓練得到干凈的分類器,圖像輸入的尺寸為256×256×3,經過200 epoch 的訓練GTSRBVGG16 在GTSRB 測試集上的準確率達到98.01%。GTSRB-VGG16 各層網絡參數如表1 所示。
1.3 對抗補丁方法原理
產生對抗樣本的傳統策略:給定一些網絡分類模型F(y/x),輸入x∈Rn,某些攻擊者需要攻擊的目標類別y′和擾動ε,根據限定的擾動找到一個合適的輸入x′使得F(y′/x′)最大化,并對擾動加以約束||x-x′||∞≤ε。在得出F(y/x)結果的過程中,能夠訪問模型的攻擊者通過反向傳播執行梯度下降的擾動,經過多次迭代找到合適的輸入x′。這種方法可以產生很好的對抗樣本,但是需要在原圖像上進行修改。一般的攻擊都是在整個圖像上進行像素的修改,而且大多數交通標牌的攻擊只集中在標牌上,如圖3 所示。但是,在現實生活中放置的位置不是僅在交通標牌上,在交通標牌的周圍也可能出現攻擊者放置的補丁。

圖2 GTSRB-VGG16 結構

表1 GTSRB-VGG16 各層參數
本文采用的是由TOM B 等人[16]提出的在現實世界中創建通用的、目標性的對抗圖像補丁方法。經過實驗證明了該方法在ImageNet 上確實有效,在添加占原圖比20%大小的補丁后,在被測的數據集上能達到超過80%的攻擊成功率。該方法通過設計一個掩膜使得生成的補丁具有任意的形狀,在本文中只采用了方形掩膜。將掩膜提取的補丁加到原圖像上訓練各種圖像,在訓練過程中每個圖像中的補丁加入隨機位置隨機旋轉。TOM B 等人采用梯度下降進行優化,本文采用的是PGD[12]梯度下降方法進行優化。該方法的主要原理:對于一張給定的圖像x∈Rw×h×c、補丁塊p和補丁變換T(本文使用旋轉、隨機位置),定義補丁應用公式為M(p,x,T)。在向圖像添加補丁之前,先將變換T應用到補丁上,對補丁進行隨機的旋轉和隨機位置的確定,然后將補丁添加到圖像上。

圖3 交通標牌的攻擊舉例
為了獲得訓練有素的補丁,對補丁進行訓練來得到攻擊效果最佳的補丁,優化目標函數為:
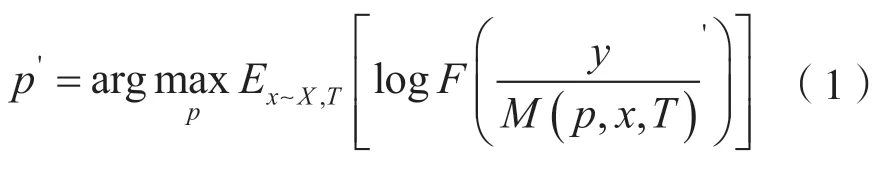
式中,X是圖像的訓練集,T是補丁變換的分布,有隨機旋轉、隨機位置等多種情況。這樣可以使得在訓練過程中網絡模型只關注于補丁,從而可以忽視補丁的背景和位置,得到可以忽視圖像背景和補丁自身位置的補丁,從而達到擾動的通用性(因為它適用于任何背景)。在有些情況下,圖像中包含了多個目標,但是分類器得出的結果只有一個目標標簽,那么這個目標被認為是真實的。在分類器看來,這張圖片對象只有這一個目標,并關注到此目標。因此,在加入補丁之后,補丁必須要學會讓自己在網絡分類中“突出”,讓分類器關注到自己。本文中期望將限速80 補丁分類為限速80。
2 實驗與分析
2.1 實驗平臺與實驗數據集
采用的實驗平臺:Ubuntu18.04.5 LTS(操作系統),32 GB(CPU),GeForce RTX 3090 24 GB(GPU),Python3.6,Pytorch1.6.0(深度學習框架)。
在訓練分類器時,采用的數據集是GTSRB 數據集,其中包含訓練集39 209 張和測試集12 587 張。訓練對抗補丁所采用的訓練數據集是從GTSRB 訓練集中每一類隨機抽取20 張,去掉要攻擊成的類,訓練集共包含42 個類,共840 張圖片。測試對抗補丁的測試數據集是從GTSRB 測試集中每一類隨機抽取10 張,去除要攻擊成的類,測試集共有420張圖片。實驗的數據集分布主要見表2。
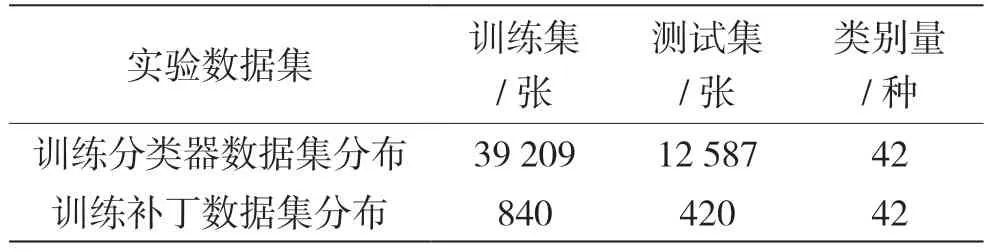
表2 實驗的數據集分布
2.2 算法偽代碼
對抗補丁算法偽代碼說明如下。
輸入:一張未加補丁的干凈圖片x,要攻擊成的類target,當前迭代次數i,最大迭代次數c,攻擊目標置信度conf
輸出:具有攻擊效果的對抗樣本x′

2.3 實驗結果分析
為了測試對抗補丁在GTSRB 上的攻擊效果,本文做了被攻擊模型泛化性測試實驗、單個模型的白盒攻擊實驗和多個模型集成的白盒攻擊實驗。泛化性測試實驗,一方面為了測試GTSRB-VGG16模型的泛化能力,另一方面是想與對抗補丁實驗形成對比。單個模型的攻擊實驗主要采用GTSRBVGG16 來訓練補丁。多個模型集成的白盒攻擊實驗主要是在原先單個白盒攻擊的基礎上加入GoogleNet和ResNet34 兩個網絡來聯合訓練,然后評估補丁在GTSRB-VGG16 的攻擊效率。在訓練和測試階段,補丁會重新隨機旋轉和隨機放置位置。
2.3.1 GTSRB-VGG16 泛化性測試實驗
泛化性是指深度學習算法對新鮮樣本的適應能力。神經網絡通過在原有的數據集上訓練學習到隱藏在數據背后的規律,對具有同一規律的數據集以外的數據,經過訓練好的分類器也能得到正確的輸出。
由于本文主要的目標攻擊類是限速80,為了測試生成的補丁的聚焦效果,采用限速80 的交通標牌作為補丁加入圖片,同時將限速80 的交通標牌進行尺寸占比的調整。本節主要采用的占圖比(限速80 占原圖比例)為5%、10%、20%和50%,由限速80 作為補丁加入到原圖上的某一個位置作為輸入數據集。衡量標準為ARSl80和UARSl80。其中,ARSl80是將該輸入數據集識別成限速80 的成功率,類似于有目標的攻擊成功率;UARSl80是指加入限速80 后分類器未能識別出原樣本的成功率,類似于攻擊中的無目標攻擊。測試的數據集是2.1 節中介紹的訓練和測試補丁的訓練集和測試集。加入限速80 標牌后部分數據集如圖4 所示。

圖4 將限速80 標牌作為補丁加入原圖
實驗效果如表3 和表4 所示。根據表3 可以看出,直接加入限速80 的標牌不能夠實現有效的帶目的性的攻擊。在占圖比達到20%時,在訓練集上識別成限速80 的只有2.74%。但是,從表4 可以看出,當占圖比為20%時,在訓練集上誤分類率達到了35.48%,說明在添加未經訓練占圖比20%的限速80 補丁后,雖然不能達到目標性攻擊,但能在一定程度上威脅到分類的準確度。由于加入的限速80 的標牌未經過分類訓練,因此猜測這與GTSRBVGG16 的泛化性能相關。

表3 不同圖占比下ARSl80結果

表4 不同圖占比下UARSl80結果
2.3.2 單個模型的白盒攻擊實驗
本節主要使用2.1 節中介紹的訓練補丁的數據集在GTSRB-VGG16 上訓練補丁并進行測試。原圖數據格式大小為256×256×3,訓練的補丁占原圖比率為5%~50%。圖5 為部分生成補丁展示。
根據圖6,在使用單個模型進行補丁訓練時,通過訓練生成的補丁在訓練集和測試集上測試的效果并不是非常理想。在補丁的占圖比達到20%時,在訓練集上攻擊的成功率是11.7%,在測試集的攻擊成功率是14.3%;在補丁的占圖比達到30%時,訓練集上的攻擊的成功率達到是43.56%,在測試集上的攻擊成率是45.12%。隨著補丁的尺寸變大,攻擊的成功率逐漸上升,當補丁的占圖比為40%時,攻擊成功率已經超過80%,說明對抗補丁的方法在GTSRB 上有一定的效果。

圖5 不同占圖比的補丁展示

圖6 不同占圖比的補丁在訓練集和測試的攻擊成功率
2.3.3 多個模型集成的白盒攻擊實驗
根據2.3.2 章節給出的結果,單個模型訓練的出來的補丁在GTSRB-VGG16上的攻擊效果還有欠缺。因此,本節設計使用GTSRB-VGG16、GoogleNet 和ResNet34 這3 個模型聯合訓練補丁,驗證由多個模型集成訓練的補丁的攻擊效果。圖7 是由3 個模型訓練得出的補丁在GTSRB-VGG16 模型上訓練集和測試集的攻擊成功率。圖8 是由3 個模型聯合訓練得出的不同尺寸的補丁,可見由3 個模型聯合訓練的占圖比為20%的補丁在GTSRB-VGG16 的訓練集上的攻擊成功率ASR20%l80(train)=18.69%,相比于單個模型訓練出來的補丁的ASR20%l80(train)提高了6.99%。在測試集上的攻擊成功率ASR20%l80(test)為21.54%,相比于單個模型的ASR20%l80(test)提高了7.24%。

圖7 集成訓練的補丁在GTSRB-VGG16 的攻擊成率

圖8 不同占圖比的補丁展示
3 結語
本文驗證了對抗補丁方法應用在交通識別模型中存在一定的威脅。產生的補丁可以忽略圖像的背景和自身的位置,對模型產生了一定的攻擊效果,生成的對抗補丁則具有一定的魯棒性和通用性。對抗補丁的方法屬于白盒攻擊方法,但是對抗補丁的方法在GTSRB 數據集上的效果并沒有在ImageNet上的攻擊效果出眾。
本文分別做了3 組大類實驗,在每大類中又按補丁不同尺寸(占圖比)做了4 類不同實驗。通過泛化性的測試實驗和單個模型的白盒攻擊實驗表明通過白盒訓練的補丁更容易使模型關注到自己,通過多個模型集成實驗表明集成訓練的補丁比單個模型訓練的補丁更有效果,魯棒性更強。這對于后續研究者研究自動駕駛中深度神經網絡的魯棒性和對抗防御具有極大的參考價值和實踐意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
