基于約束聚類的k-匿名隱私保護方法
2021-03-23 09:12:34吳夢婷孫麗萍劉援軍胡朝焱趙延年羅永龍
計算機工程與設計 2021年3期
吳夢婷,孫麗萍,劉援軍,胡朝焱,趙延年,羅永龍
(安徽師范大學 計算機與信息學院,安徽 蕪湖 241000)
0 引 言
隨著互聯(lián)網(wǎng)技術和移動設備的快速發(fā)展,人們可收集、發(fā)布和分析的數(shù)據(jù)規(guī)模越來越大,但在對海量數(shù)據(jù)進行挖掘獲得其潛在價值的同時,也給數(shù)據(jù)的安全和隱私問題帶來了極大的威脅。因此,如何在數(shù)據(jù)發(fā)布過程中降低隱私泄露的風險并提高數(shù)據(jù)可用性已經(jīng)成為了隱私保護問題面臨的極大挑戰(zhàn)[1]。
作為一種能有效保證數(shù)據(jù)真實性和安全性的隱私保護方法,k-匿名[2]技術自提出以來被廣泛應用于數(shù)據(jù)發(fā)布和位置服務場景中。Aggarwal等[3]提出將聚類思想運用于k-匿名技術后,有不少文章在基于聚類的匿名隱私保護方面研究出了顯著成果。Li等[4]提出了運用反復聚類思想完成模型要求的KACA匿名方法;Yin等[5]提出了一種基于K-member聚類的k-匿名改進模型;Pramanik等[6]提出一種增強聚類的k-匿名算法,并定義了新的數(shù)據(jù)質(zhì)量衡量標準;Jiang等[7]提出了一種貪心聚類匿名方法,根據(jù)信息損失重新定義距離,并引入貪心思想優(yōu)化數(shù)據(jù)集的劃分過程;Xing等[8]提出了一種基于k-均值聚類的隱私保護方法;Zheng等[9]提出了一種運用局部最優(yōu)聚類完成k-匿名的方法,但最終匿名質(zhì)量受“一次性”聚類影響較大;Fawad等[10]針對稀疏高維數(shù)據(jù)提出了一種基于k-均值的聯(lián)合聚類算法,利用高階隨機游走模型計算相似性,并使用多數(shù)據(jù)點擬合初始聚類中心。但現(xiàn)有的大多數(shù)數(shù)據(jù)匿名化方法嚴重依賴于預先定義的準標識符概化層關系,缺少考慮離群數(shù)據(jù)的敏感問題,使得匿名結(jié)果產(chǎn)生的信息損失較高并進一步影響數(shù)據(jù)質(zhì)量,且無法同時保障信息損失和時間效率趨于最優(yōu)。針對上述問題,本文提出了一種基于約束聚類的k-匿名隱私保護方法(k-anonymity method based on restrained clustering by threshold,KAM-RCT)。
1 問題模型與定義
1.1 基于聚類的k-匿名
基于聚類的k-匿名問題的核心思想是將k-匿名問題轉(zhuǎn)化為一種帶約束條件的聚類問題[11],問題具體定義如下:
定義1 基于聚類的k-匿名問題。將待發(fā)布數(shù)據(jù)表T(t1,t2,…,tn) 劃分成一系列的簇,使得每個簇至少包含k個元組,以滿足生成k-匿名等價類,并要求簇內(nèi)間距總和最小。基于聚類的k-匿名問題的最優(yōu)解是劃分完成后的等價類集合E={e1,e2,…,em} 滿足以下條件:
(1)?i≠j∈{1,2,…,m},ei∩ej=?;
(2)∪i=1,2,…,mei=T;
(3)?ei∈E,|ei|≥k;
1.2 距離度量函數(shù)
在聚類算法中,定義距離函數(shù)用來度量數(shù)據(jù)之間的相似度是衡量聚類結(jié)果的關鍵因素。由于準標識符屬性中包含數(shù)值型數(shù)據(jù)、二元型數(shù)據(jù)和分類型數(shù)據(jù)3種不同的數(shù)據(jù)類型,故本文以最小信息損失為目標,針對不同類型的數(shù)據(jù)分別定義其距離度量函數(shù)。
定義2 數(shù)值型數(shù)據(jù)間的距離。設D為連續(xù)型有限數(shù)值域,任意兩個屬性值vi,vj∈D,vi,vj間的距離定義為
(1)
式中: |D| 表示連續(xù)型有限數(shù)值域D中最大值和最小值之間的差。
定義3 二元型數(shù)據(jù)間的距離。二元型是指數(shù)據(jù)只用兩種值表示,分別是0和1,對于任意兩個二元型數(shù)據(jù)vi,vj之間的距離定義如下
(2)
對于分類型數(shù)據(jù),由于通常其屬性的取值是有限或離散的,且屬性值之間不具備完整的序關系,所以數(shù)值型數(shù)據(jù)和二元型數(shù)據(jù)間的距離定義并不適用于分類型數(shù)據(jù)。但是,大多數(shù)分類型數(shù)據(jù)值之間存在某種語義相關性,這種語義相關性通常可以由分類樹來體現(xiàn)。
定義4 分類型數(shù)據(jù)間的距離。設D為分類型屬性域,TD為屬性的分類樹,任意兩個分類型屬性值vi,vj∈D,vi,vj間的距離定義為
(3)
式中:H(TD) 表示分類樹的樹高,H(Λ(vi,vj)) 表示vi,vj在分類樹中最小公共子樹的高度。
基于數(shù)值型、二元性和分類型數(shù)據(jù)的距離定義,兩個元組間的距離定義如下:
定義5 元組間的距離。表數(shù)據(jù)T的準標識符為QI={N1,…,Nm,B1,…,Bn,C1,…,Ck},Nx(x=1,…,m) 表示數(shù)值型屬性,By(y=1,…,n) 表示二元型屬性,Cz(z=1,…,k) 表示分類型屬性,則任意兩個元組ti,tj∈T之間的距離定義為
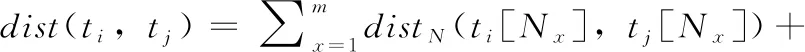
(4)
式中:ti[A] 表示元組ti在屬性A上的值。
1.3 信息損失函數(shù)
由于k-匿名聚類問題最終是要將劃分好的簇在準標識符上進行概化,得到若干個等價類。保護隱私的同時,屬性在概化過程中必然導致表數(shù)據(jù)的信息損失,最終概化得到的值越模糊,信息損失就越多。因此,為了更加合理地衡量信息損失度,本文考慮不同屬性類型的特點,分別計算數(shù)值型和分類型屬性匿名后的信息損失。
對于元組中的數(shù)值型屬性,a為某屬性原始值,[amin,amax] 表示其概化后的區(qū)間,其中amin表示該屬性在元組所在等價類中的最小值,amax表示該屬性在元組所在等價類中的最大值,設D為屬性的有限數(shù)值域,則元組中該數(shù)值型屬性的信息損失為
(5)
對于元組中的分類型屬性,依據(jù)構(gòu)建的屬性分類樹,Size表示以最大程度概化后的值為根結(jié)點的總?cè)~子數(shù),size(g)表示概化結(jié)果子樹的葉子個數(shù),則元組中該分類型屬性的信息損失定義為
(6)
定義6 等價類的信息損失。等價類的信息損失是指對簇e內(nèi)所有元組的每個準標識符進行匿名處理后造成的信息損失CIL,即為所有屬性的信息損失之和,d表示準標識符屬性的個數(shù),則等價類的信息損失定義為
(7)
基于以上定義,可定義匿名數(shù)據(jù)表的總體信息損失如下:
定義7 總體信息損失。將匿名數(shù)據(jù)表T*劃分成的等價類集合表示為E={e1,e2,…,em},則所有等價類的信息損失之和為總體信息損失,具體定義為
(8)
2 基于約束聚類的k-匿名隱私保護方法
2.1 KAM-RCT算法
針對現(xiàn)有的基于聚類的k-匿名隱私保護算法存在信息損失高、對離群數(shù)據(jù)敏感等問題,本文提出了一種基于約束聚類的k-匿名改進算法KAM-RCT。算法利用KNN算法思想進行集群初始劃分,通過引入閾值約束迭代過程,從而提升了聚類算法的性能。
如圖1所示,算法由4個基本部分組成:第1部分在待發(fā)布的數(shù)據(jù)表T中隨機選取m個初始聚類中心;第2部分利用KNN思想進行全局聚類,將距離聚類中心最近的k-1 個元組添加到相應的簇中,劃分結(jié)束后更新聚類中心;第3部分根據(jù)信息損失閾值δ對等價類進行重新劃分,計算每個等價類的信息損失,若大于閾值δ則將該等價類中元組放入待分配集合R,即去除聚類表現(xiàn)不佳的簇,然后在保證等價類的信息損失滿足閾值δ的前提下將集合R中的元組劃分到相應的簇中,每次簇內(nèi)元組發(fā)生變化后及時更新聚類中心;第4部分對每個等價類按照預先定義的規(guī)則進行匿名化處理。算法充分考慮離群點對聚類結(jié)果的影響,劃分過程始終都以信息損失最小化原則選取元組,有效減少匿名過程中的信息損失。KAM-RCT算法具體實現(xiàn)步驟如下:
算法: 基于約束聚類的k-匿名隱私保護算法
輸入: 待發(fā)布的數(shù)據(jù)表T,匿名參數(shù)k,閾值δ
輸出: 滿足約束條件的匿名數(shù)據(jù)表T*

(2) InitializeE←{ei|ei←{ci},ciis randomly picked fromT,i∈[1,m]}
(3)fori←1 tom
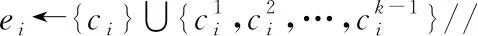
(5)endfor
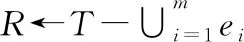
(7)foreachei∈E
(8) CalculateCIL(ei) by Equation(7)
(9)if(CIL(ei)>δ)
(10)R←R∪ei
(11)E←E-{ei}
(12)else
(13) Update the center ofei
(14)endif
(15)endfor
(16)whileLen(R)>kdo
(17)foreachrj∈R
(18)foreachei∈E
(19)ei←ei∪{rj}
(20)if(CIL(ei)<δ)
(21)R←R-{rj}
(22)else
(23)ei←ei-{rj}
(24)endif
(25)endfor
(26)endfor
(27) Update {c1,c2,…,cm}
(28)endwhile
(29)foreachei∈Edo
(30)T*←T*∪Anonymization(ei)
(31)endfor

圖1 KAM-RCT算法基本框架
2.2 KAM-RCT算法分析
2.2.1 正確性分析
本文是實現(xiàn)將包含n個元組的數(shù)據(jù)表T劃分為多個等價類,使得每個等價類中的元組數(shù)大于匿名參數(shù)k,且保證匿名后的總體信息損失TIL達到最小值。由2.1節(jié)給出的算法可知,第(2)行-第(6)行每個簇在初始化過程中會選取距離聚類中心最近的k-1個元組,保證初始生成的每個簇大小都為k,已符合k-匿名模型的元組要求。第(7)行-第(28)行根據(jù)閾值δ刪除信息損失高的簇,并將這些簇內(nèi)的元組劃分到相異度最低的簇,然后更新每個簇的聚類中心。聚類劃分過程的每一步都以信息損失度最小為目標,得到的每個簇的大小至少為k,始終滿足k-匿名模型的基本要求。第(29)行-第(31)行,對每個簇進行概化匿名處理,使得相同等價類中的元組在準標識符屬性上無法區(qū)分,最終得到滿足要求的匿名數(shù)據(jù)表T*。
2.2.2 復雜性分析
設n為原始數(shù)據(jù)表T中的元組個數(shù),d為準標識符屬性個數(shù),算法第(5)行完成后得到m個簇,有1
算法在第(3)行-第(5)行中,每生成一個新的簇ei需k-1遍掃描T,并計算T中每個元組與聚類中心ci在準標識符上的相應距離,一共生成m個簇,因此,執(zhí)行時間為O(dkmn)。
算法在第(7)行-第(15)行中,對m個簇依次計算其在準標識符上的總信息損失CIL(ei),因每個簇中至少有k個元組,故執(zhí)行時間為O(dkm)。
算法在第(16)行-第(28)行對集合R中的元組進行重新分配,集合中元組個數(shù)為 |R|,需計算每個元組依次放入每個簇后簇的信息損失,因此,執(zhí)行時間為O(|R|dkm)。
算法在第(29)行-第(31)行中,對每個簇進行匿名處理并生成匿名數(shù)據(jù)表T*,該過程需在依次遍歷所有元組的同時概化其準標識符屬性值,因此,執(zhí)行時間為O(dn)。
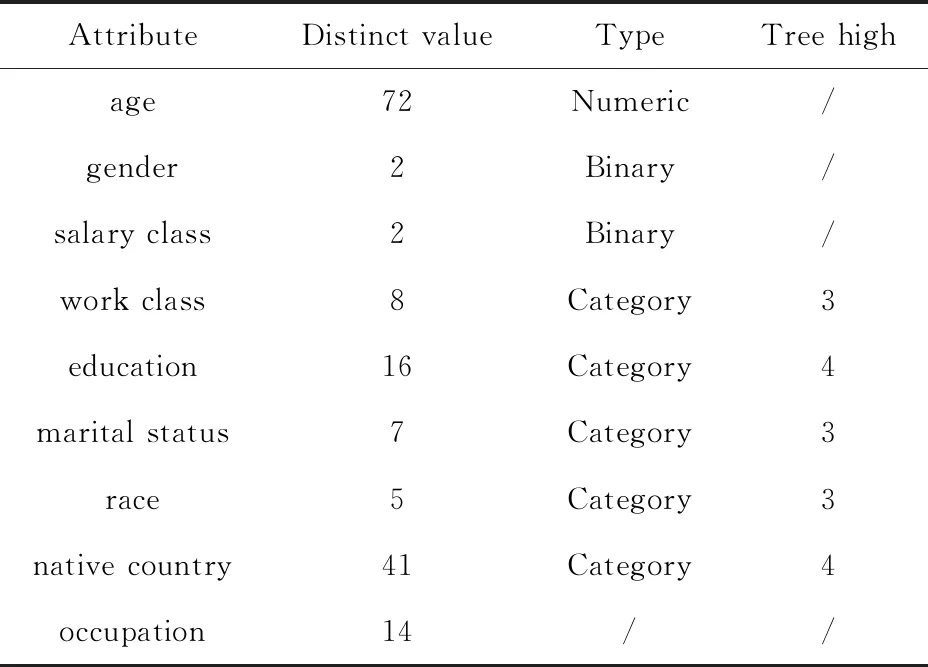
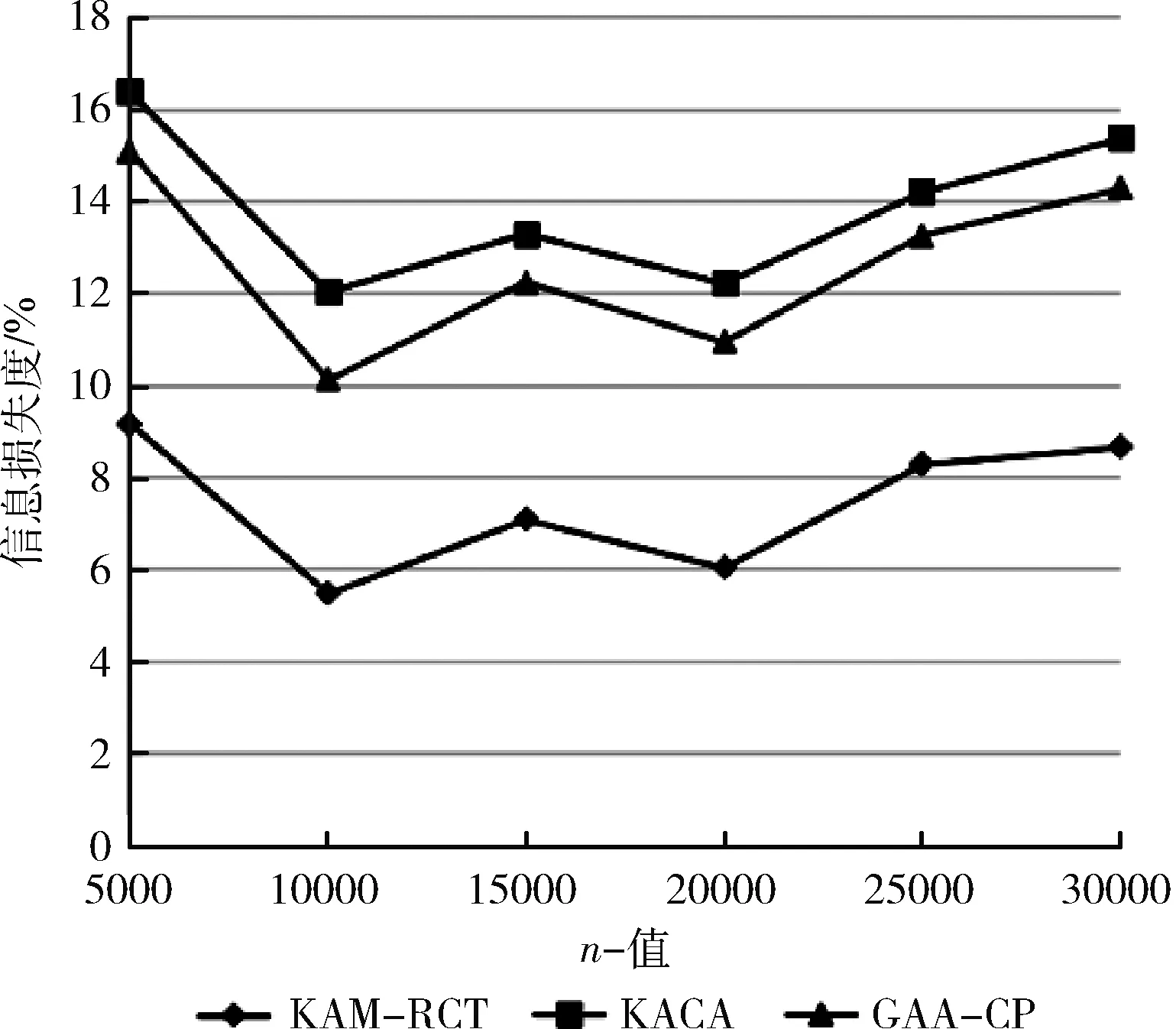
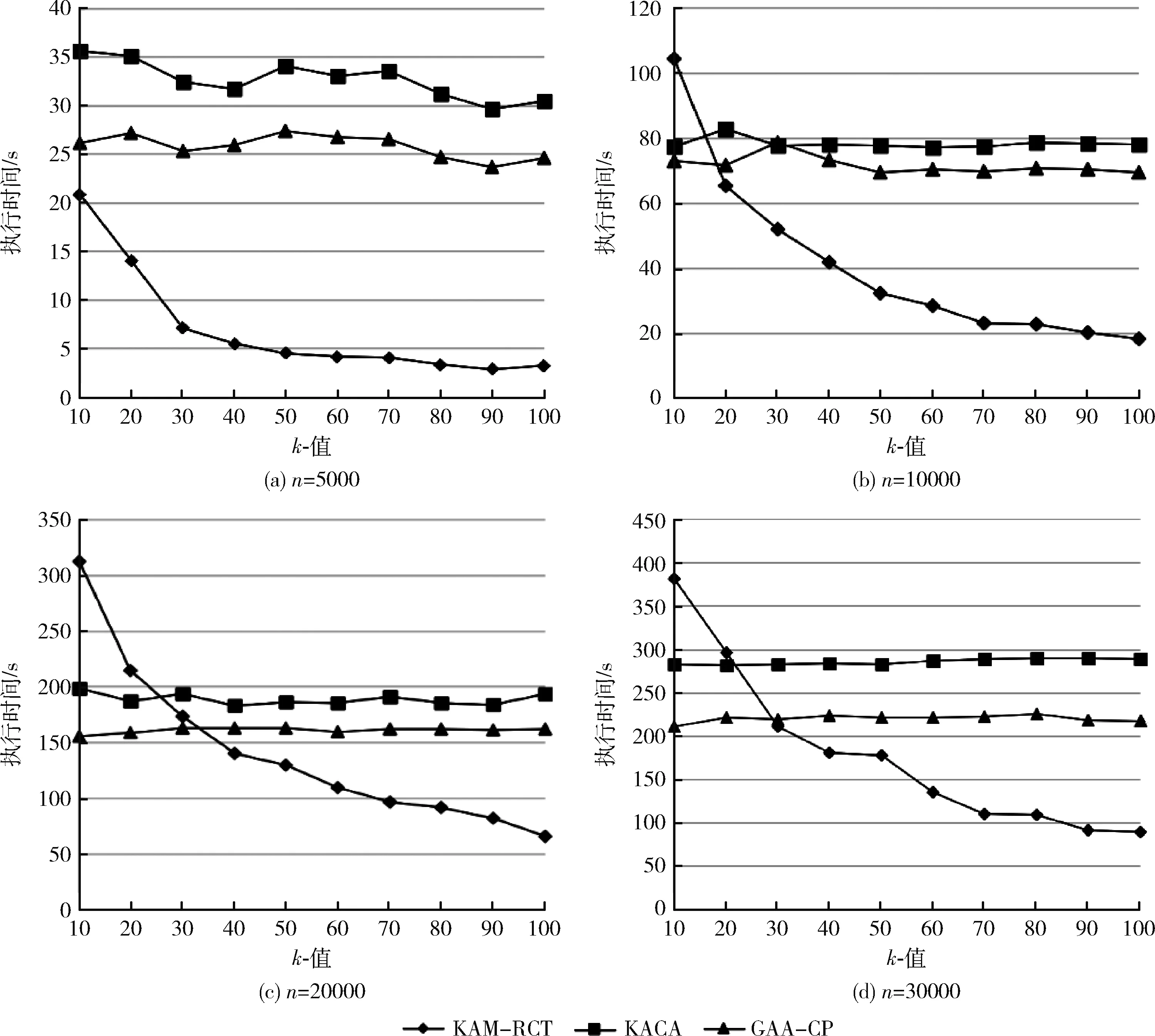
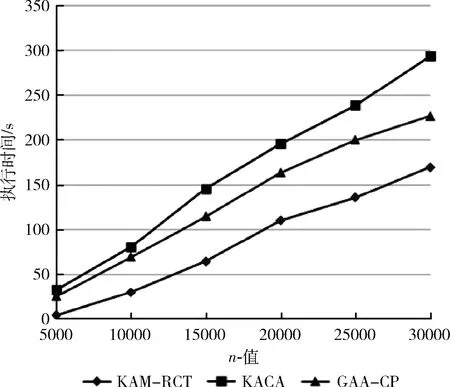
因此,KAM-RCT算法總的時間復雜度為O(dkmn)+O(dkm)+O(|R|dkm)+O(dn)=O(dkmn)。 由于km 本節(jié)通過對典型數(shù)據(jù)集進行實驗,驗證KAM-RCT算法的性能,并將其與文獻[4]中基于多維全域泛化的KACA算法和文獻[7]中貪心聚類匿名GAA-CP算法進行比較,對比分析結(jié)果表明本文所提出的基于約束聚類的k-匿名隱私保護方法在匿名數(shù)據(jù)的信息損失度方面相較于其它算法有明顯的優(yōu)勢。 本文實驗的實驗環(huán)境為:Intel Core i7-7700HQ @ 2.8 GHz,24 GB內(nèi)存,算法由MATLAB 2018b實現(xiàn),程序運行在Windows 10環(huán)境下。 本文實驗采用的Adult數(shù)據(jù)集來源于UCI機器學習庫(http://archive.ics.uci.edu/ml/),由部分美國人口普查數(shù)據(jù)構(gòu)成,目前被廣泛使用于數(shù)據(jù)匿名化隱私保護領域[12]。實驗開始前先對數(shù)據(jù)進行預處理[13],刪除了含有缺失屬性的數(shù)據(jù)后,從中隨機選取5000-30 000個元組作為此次的實驗數(shù)據(jù)集T。對于每一個元組都提取了9個屬性值,依次為age,gender,salary class,work class,education,marital status,race,native country和occupation,其中 occupation 為敏感屬性,其余8個為準標識符屬性,實驗數(shù)據(jù)信息見表1。最后,算法完成等價類劃分后,對每個等價類進行匿名處理[14]。考慮到各個算法最初隨機選取聚類中心會對最終結(jié)果有略微影響,本文中每組實驗重復進行20次,結(jié)果取其平均值。 表1 Adult數(shù)據(jù)集信息描述 在保證數(shù)據(jù)質(zhì)量和運行時間的前提下,本文使用的信息損失閾值δ由多次實驗取得,實驗在不同數(shù)據(jù)量的Adult數(shù)據(jù)集上進行,通過限制待分配集合R中的元組個數(shù)尋找最佳的閾值δ,從而得到最優(yōu)的總信息損失,實驗結(jié)果發(fā)現(xiàn)閾值δ和匿名參數(shù)k之間存在線性關系。因此,將δ和k進行線性擬合后,再用線性函數(shù)求出δ并帶入分析實驗。 為分析數(shù)據(jù)信息損失度隨著匿名參數(shù)k的改變而變化的規(guī)律,我們通過一組實驗對3種算法進行比較,圖2中的4張圖分別給出了總數(shù)據(jù)量n=5000、10000、20000和30000時,KACA、GAA-CP和KAM-RCT中k值的變化對信息損失度的影響。如圖2(a)所示,當n=5000時,本文提出的KAM-RCT算法對于任意的k值都有較低的信息損失。如圖2(b)、圖2(c)所示,當n=10000和n=20000時,KAM-RCT算法在信息損失度量方面依然優(yōu)于其它兩種算法,并且信息損失度有所降低,這是因為數(shù)據(jù)量的增加,導致聚類結(jié)果更好,匿名后等價類中的數(shù)據(jù)點更加緊湊。 圖2 k值對信息損失度的影響 考慮到數(shù)據(jù)發(fā)布場景中可能涉及的表數(shù)據(jù)信息量更大,圖2(d)使用30 000條數(shù)據(jù)進行實驗,與其它算法相比,即使n=30000,本文算法依然保持最少的信息損失。此外,隨著k值的增大,3種算法在匿名后的信息損失度也隨之增大。原因在于隨著k值的增大,等價類中包含的元組個數(shù)變多,那么要讓這些等價類的屬性值匿名后無法區(qū)分,必然導致概化程度增大,相應的整體信息損失度也就越大。 圖3給出了當匿名參數(shù)k固定不變時,數(shù)據(jù)集大小n的變化對算法信息損失度的影響。從圖中可以看出,KAM-RCT算法的匿名結(jié)果仍最佳,并且當k=50時,數(shù)據(jù)量在10 000和20 000左右,聚類效果較好,信息損失度較低。 圖3 n值對信息損失度的影響 比較n值和k值均相等時的信息損失度,本文提出的KAM-RCT算法的信息損失始終低于KACA、GAA-CP算法,這是因為本文算法重在優(yōu)化等價類的劃分過程,每一個元組的添加都按照相似性最大原則,充分考慮到數(shù)據(jù)集中離群點的存在,根據(jù)約束閾值篩選出表現(xiàn)較好的集群,從而使得劃分完成后的等價類相似性更高,匿名化所造成的信息損失更低,有效提高了數(shù)據(jù)質(zhì)量。GAA-CP算法得到的聚類結(jié)果依然對離群點敏感,相較于本文聚類效果較差,信息損失較高;KACA算法對預定義的屬性概化層次樹過分依賴,易導致過度概化的情況發(fā)生,故信息損失度偏高。 為進一步比較分析KAM-RCT算法在執(zhí)行時間上的特點,我們分別進行了以下2組實驗。第1組實驗保持數(shù)據(jù)量大小n值不變,考察3種算法在不同匿名參數(shù)k下的執(zhí)行時間變化,圖4中的4張圖分別給出了數(shù)據(jù)集大小n=5000、10000、20000和30000時,KACA、GAA-CP和KAM-RCT中k值的變化對執(zhí)行時間的影響。由圖4不難看出,KACA和GAA-CP的執(zhí)行時間均起伏變化不大,且一直保有KACA>GAA-CP。因為在一般情況下,隨著k值的增長,構(gòu)造單個等價類所需的時間會隨之增長,但由于元組總數(shù)固定不變,劃分出的等價類個數(shù)也會相應減少,因此算法的總執(zhí)行時間變化不大。 圖4 k值對執(zhí)行時間的影響 如圖4(a)所示,當元組個數(shù)較小時,KAM-RCT算法的執(zhí)行時間始終明顯優(yōu)于其它兩種算法。由圖4(b)~圖4(d)可知本文提出的KAM-RCT執(zhí)行時間隨著k值的增大而不斷減小,且k值越大相較于其它兩種算法在執(zhí)行時間方面的優(yōu)勢也越明顯。原因在于KACA和GAA-CP算法聚類過程迭代次數(shù)過多,而本文的算法致力于優(yōu)化群集過程,通過排除離群數(shù)據(jù),大大降低了聚類的迭代次數(shù)。因此,匿名參數(shù)越大,根據(jù)閾值需重新分配的簇和元組減少,等價類重新劃分所需的時間也相應減少,從而提高了算法的執(zhí)行效率,并使其更適合數(shù)據(jù)匿名場景。 分析算法執(zhí)行時間的第2組實驗結(jié)果如圖5所示,固定匿名參數(shù)k=50不變,考察數(shù)據(jù)集大小在5000-30 000個元組下的執(zhí)行時間變化。不難看出,隨著數(shù)據(jù)表規(guī)模的逐漸增大,3種算法的執(zhí)行時間也在成倍的增長,這是因為隨著元組的增多,算法的總體運算量也隨之增加,故時間成倍增長。此外,在n值相同的情況下,執(zhí)行時間一直有KACA>GAA-CP>KAM-RCT,故本文提出的KAM-RCT相較于其它兩個算法有明顯改進。 圖5 n值對執(zhí)行時間的影響 針對現(xiàn)有的基于聚類的k-匿名隱私保護方法對離群點敏感問題和匿名后數(shù)據(jù)質(zhì)量較差問題,本文提出了一種基于約束聚類的k-匿名隱私保護方法。該方法通過KNN分類思想劃分初始集群,并根據(jù)設定的信息損失閾值δ將集群進行重新劃分,劃分過程始終遵循信息損失最小化原則,有效排除了離群點對聚類結(jié)果的影響,從而有效減少匿名后的數(shù)據(jù)信息損失量。實驗結(jié)果表明了KAM-RCT算法的有效性,不僅提高了數(shù)據(jù)發(fā)布質(zhì)量,還在執(zhí)行時間和數(shù)據(jù)質(zhì)量之間找到了較好的平衡。然而該算法沒有對敏感屬性進行約束,仍存在受到同質(zhì)性攻擊的風險,因此,下一步工作準備從敏感屬性入手,設計一種能夠?qū)崿F(xiàn)大量動態(tài)微數(shù)據(jù)的匿名算法。3 實驗與結(jié)果分析
3.1 實驗環(huán)境及數(shù)據(jù)集
3.2 信息損失分析
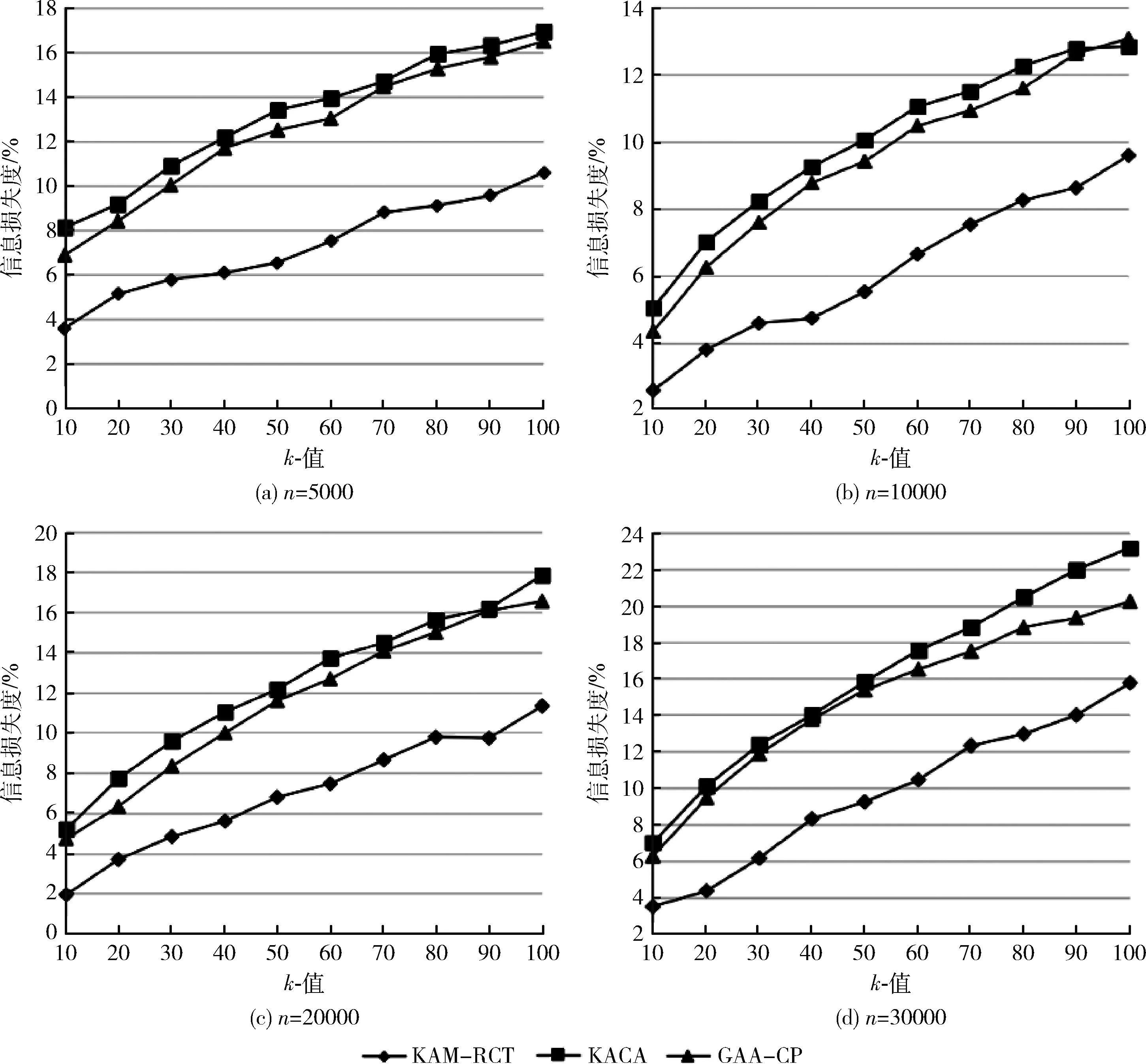
3.3 執(zhí)行時間分析
4 結(jié)束語
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
中華手工(2017年2期)2017-06-06 23:00:31
山東青年(2016年1期)2016-02-28 14:25:25
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
海外英語(2006年11期)2006-11-30 05:16:56
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
