基于PB-DBSCAN的GPS數據去噪
2021-03-23 09:13:10劉澤玲王利琴董永峰
計算機工程與設計 2021年3期
汪 鵬,劉澤玲,王利琴,3+,董永峰
(1.河北工業大學 人工智能與數據科學學院,天津 300401;2.河北工業大學 河北省大數據計算重點實驗室,天津 300401;3.河北工業大學 河北省數據驅動工業智能工程研究中心,天津 300401)
0 引 言
在公交車載GPS設備定位過程中,GPS數據的誤差來源分為GPS定位系統的內部原因和外部原因,內部原因包括信號傳播途徑問題、GPS衛星相關問題和用戶接受設備問題。外部原因主要包括公交車自身行駛特性、城市道路路況和諸多隨機因素(天氣狀況、網絡延遲、行駛速度等)。這些誤差是GPS數據產生大量噪聲點的主要原因,降低了由GPS數據生成公交行駛路線的準確度和可靠性,為減小噪聲點對生成路線的影響,提高生成路線的準確度,需要剔除異常的GPS數據。
在數據點噪聲處理領域,相關學者在基于聚類算法過濾噪聲點等方向提出大量的算法。Yang L等提出了基于自然近鄰的ENaN算法[1],根據樣本點近鄰,尋找各數據點的反向最近鄰。ENaN根據樣本點是否具有反向最近鄰來判斷該點是否為噪聲點,雖然通過這種方法實現了聚類效果,但對于噪聲量較大的數據集聚類效果往往較差甚至無法完成聚類過程;Hao SX等提出了一種基于噪聲的應用空間密度聚類(DBSCAN)和支持向量數據描述(SVDD)的噪聲數據檢測方法[2];張靖等提出一種基于空間和時間密度的抗噪聲聚合算法(DBS&TCAN)[3];李強等通過過濾低密度區域的方法優化了DBSCAN算法[4],在處理海量GPS軌跡數據時有效得到了稠密樣本點;Bryant A等提出的RNN-DBSCAN算法通過K最近鄰點的選擇實現了單個參數聚類[5],從而降低了聚類的復雜度,并且提升了簇分布不均勻的數據集的聚類效果;黃子赫等提出了BCS-DBSCAN聚類算法,該算法可以對軌跡數據切分及并行化聚類且能夠有效去除噪聲點提取最大密度簇心[6]。然而上訴方法均不適用于數據量較大的去噪處理。雖然DBSCAN在聚類速度上具有優勢并且對于有冗余點的數據集也可以很好的聚類,但是,當數據量龐大時,DBSCAN算法時間復雜度較高。
Eps和MinPts是DBSCAN算法中用來描述數據點分布密度的兩個全局參數,直接影響到聚類效果,合理的取值會顯著提高聚類效果,因此聚類參數的自適應調整成為了眾多學者研究的方向。Jian Hou等提出了一種基于DSets(優勢集)和DBSCAN的無參數算法——Dsets-DBSCAN[7];Ankush Sharma等提出了KNN-DBSCAN無參數密度聚類[8],將K近鄰學習與DBSCAN一起使用以實現無參數聚類技術;蔣華等針對CURE算法聚類過程中對噪音點敏感、聚類效率欠佳問題,提出了一種基于MeanShift核函數平移模型DBSCAN算法改進的CURE算法[9]。其中基于路徑最短原則的密度自適應參數的DBSCAN算法提高初步聚類精度和可靠性。但上述算法只適用于數據集單一、參數相同的場景,而公交車GPS數據集包含不同線路的所有數據,不同線路具有不同的數據密度,因此需使用不同的參數。
本文對Eps和MinPts參數進行動態選擇,有效解決了在不同線路公交車GPS數據聚類過程中,因固定輸入參數在不同線路的非普適性而導致的聚類結果偏差較大、聚類效果差的問題。同時為提高DBSCAN算法執行速度,本文提出一種基于像素格的PB-DBSCAN算法,該算法將聚類過程中判斷數據點與其它數據點的關系改為判斷當前像素格與相鄰像素格之間的關系,相較于傳統DBSCAN算法降低了時間復雜度,尤其在數據量較大時,算法效率有極大提升。
1 PB-DBSCAN算法
DBSCAN是Ester等提出的第一個基于密度的聚類算法。該算法以數據集在空間分布上的稠密程度為依據進行聚類,將密度相連的點的最大集合定義為簇,DBSCAN對數據集的大小沒有限制且無需預先設定簇的數量,適合于對未知內容的數據集進行聚類。
Eps和MinPts是DBSCAN算法的兩個全局參數,其中,Eps代表聚類半徑,表示目標點周圍鄰域數據點數的搜索半徑,MinPts代表聚類密度,用于判斷搜索區域是否滿足簇要求的最小點數。任選一個未被檢查過的點,檢查其Eps鄰域,若包含的點的數目不小于MinPts,則該點與其鄰域的點形成一個簇,標記該點為核心點,然后以相同的方法處理該簇內所有未被檢查的點,從而對簇進行擴展;若包含的點的數目小于MinPts,但該點本身在某一個簇內,則該點標記為邊緣點,否則該點被標記為噪聲點。
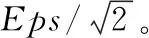
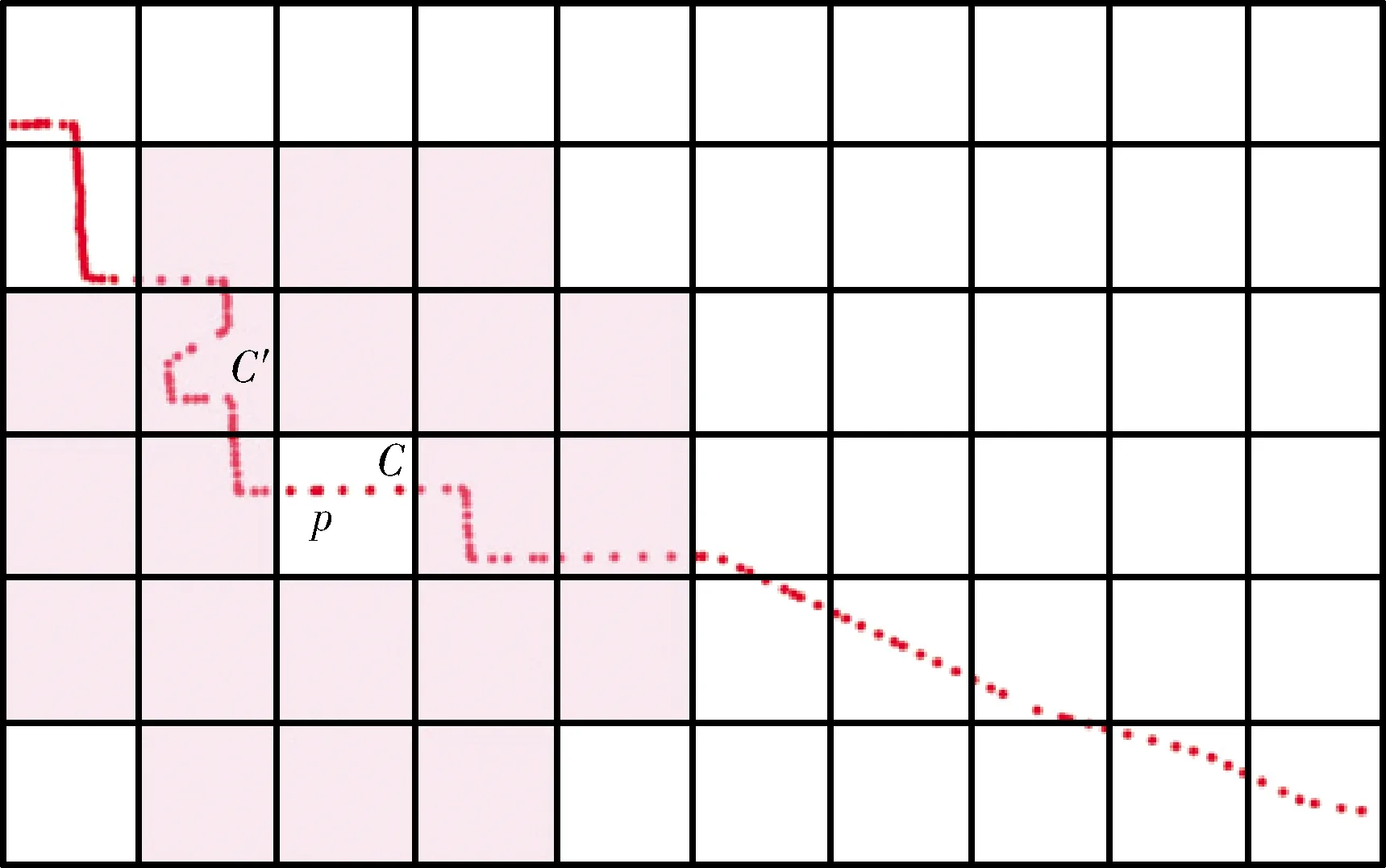
圖1 像素格
1.1 構建像素格
首先遍歷數據集中的所有點,找到這些點的橫縱坐標的最大值和最小值,從而確定像素格空間X軸和Y軸值的范圍,然后再將X軸、Y軸等分,將整個像素格空間劃分為m行n列的小像素格
(1)
(2)
將每個GPS數據點根據其橫縱坐標數值劃分到相應的像素格單元中,如圖1所示。
1.2 確定核心點
遍歷所有的非空像素格,判斷當前像素格內的點數是否大于MinPts,如果是,則將該像素格內的所有點標記為核心點,否則遍歷該像素格內的所有點,逐個判斷其是否為核心點。假設一個點p,屬于單元格C,則要確定點p是否是核心點,需要檢查p點所在像素格的相鄰像素格內的點。將p點所在像素格的相鄰像素格表示為C′,NEps(C) 定義為像素格單元C及其相鄰的像素格單元C′的集合,如果C與C′之間存在兩點之間的距離小于Eps,那么C′為C的一個相鄰像素格,如式(3)所示,dist(C,C′) 表示C和C′內任意數據點之間的最短距離
(3)
NEps(C)={C,C′|dist(C,C′)≤Eps}
(4)
如圖1陰影部分所示,NEps(C) 由和C相鄰的20個像素格組成。遍歷這些像素格中的每個點,計算其與點p之間的距離,直到所有的點都已遍歷,或點p的Eps鄰域內點數大于等于MinPts,終止查找。
1.3 合并簇
對于兩個不同的像素格,如果分別位于兩個像素格的兩個點之間的距離小于等于Eps,那么這兩個點屬于同一個簇,如圖2所示,a為相鄰的兩個像素格,且均含有4個數據點,假設MinPts=3,那么a、b內所有的點均為核心點,如果a、b之間的距離小于Eps,那么a、b內所有的點屬于同一個簇。否則,劃分為各含有4個點的兩個簇。
圖2 合并簇
1.4 確定邊界點和離群噪點
遍歷所有非核心點,如果存在NEps(C) 中的核心點,假如最靠近點p的核心點屬于簇clusters_1,那么非核心點p可以認定為簇clusters_1的一個邊界點。檢查完所有非核心點之后,既不是核心點又不是邊界點的數據會被標記為噪聲點。
通過上面的4個步驟,可以實現GPS軌跡點的快速聚類,并且標記出數據集中的噪聲點,通過剔除噪聲點來完成GPS數據的去噪處理。
2 動態參數選擇
在對不同線路GPS數據進行聚類的過程中,由于公交線路的多樣性,在Eps和MinPts的選取中,同一聚類參數無法適應所有的線路。不同線路根據同一聚類參數聚類得到的結果在公交行駛路線的后續起終點獲取中,會引起起點獲取不準確、起點周圍噪聲點刪除不全等問題,進而影響由GPS數據點生成公交行駛路線的準確度。因此本文提出一種動態參數選擇的方法,使PB-DBSCAN算法在對包含多條線路GPS數據集去噪時實現參數的自適應選取。
為實現動態參數選擇,引入聚類率ρ及最優聚類率區間 [ρmin,ρmax],聚類率如式(5)所示,反映了聚類后樣本的數據量占原始數據量的比例。
定義1 假如聚類后的所有GPS數據點個數為m,樣本總數據量為n,那么聚類率ρ為
ρ=m/n
(5)
一般而言,聚類率并不是越大或者越小越好。聚類率過大,則是在聚類參數選取過程中,聚類密度過小或聚類半徑過大,從而導致部分噪聲點未被剔除,聚類后剩余的點數過多,聚類效果較差。相反,如果聚類率過小,則是在聚類參數選取中,聚類密度過大或聚類半徑過小,從而導致部分核心點或邊緣點被剔除,聚類后剩余點數過少,聚類效果較差。因此提出最優聚類率區間。
定義2 最優聚類率區間:當聚類率落于該區間內時,大部分噪聲點得到剔除,所得簇的數量和每個簇的大小能夠滿足GPS數據的下一步處理,不會影響后續處理的準確性。
動態參數選擇迭代過程的終止條件之一為迭代后計算所得聚類率位于最優聚類區間內,通過對數據集中不同線路GPS數據的探索性實驗,得出最優聚類率區間為[0.45,0.55]。
通過對多條線路的探索性實驗,得到滿足絕大部分線路聚類效果要求時,最大迭代次數N為64。動態參數選擇聚類實現過程如圖3所示。
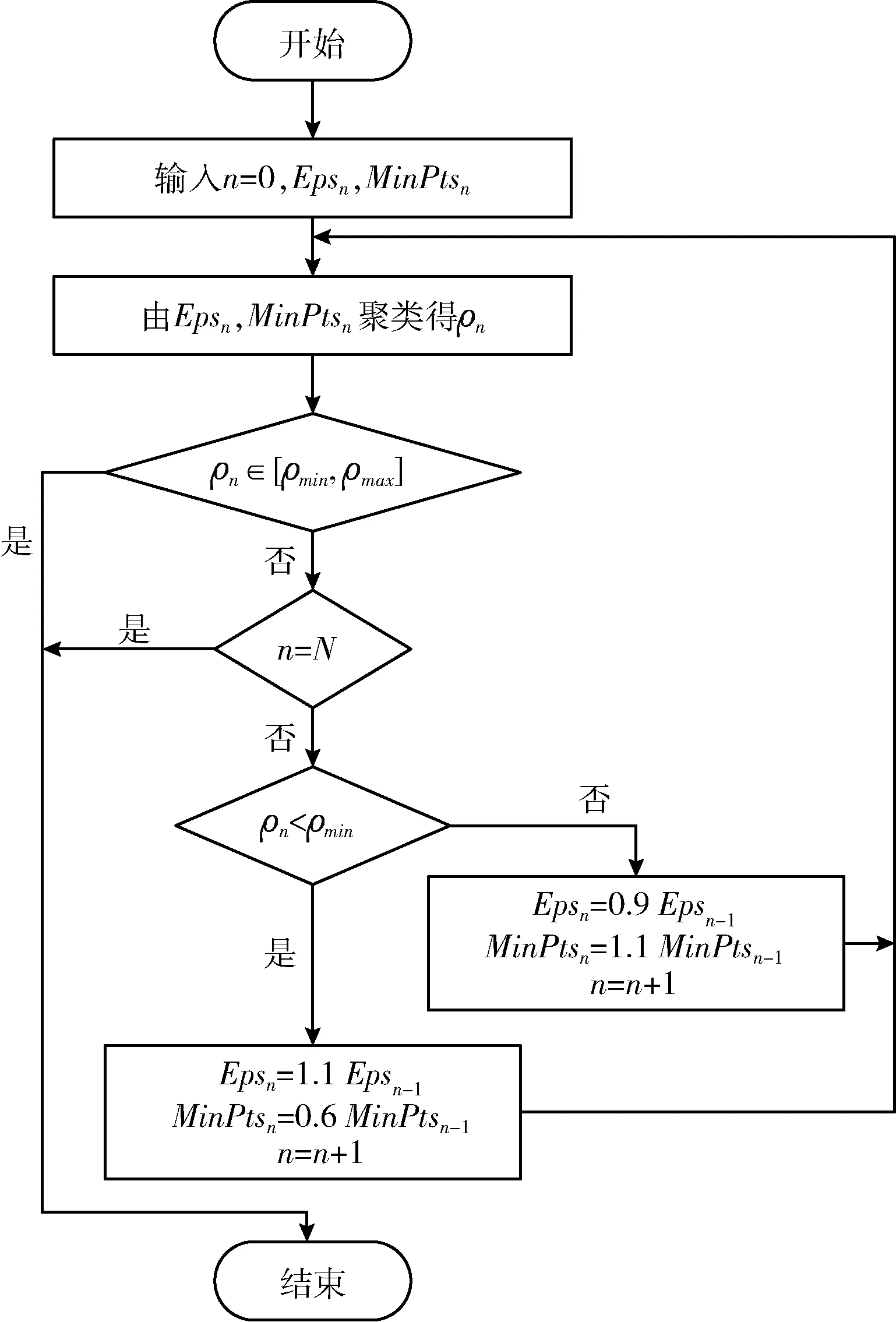
圖3 動態參數選擇流程
(1)確定初始參數。Eps0和MinPts0。迭代次數n=0。其中Eps0和MinPts0為在分別對各線路進行固定參數的預聚類實驗之后,得到的在多條線路下滿足聚類率在聚類區間內或臨近聚類區間的共同初始輸入參數;
(2)計算聚類率。根據式(5)計算聚類率ρ0,判斷ρ0是否落在最優聚類率區間 [ρmin,ρmax] 中;
(3)參數動態選擇。如果ρ0落在最優聚類率區間 [ρmin,ρmax] 中,聚類結束。否則,若ρ0>ρmax,則調大MinPts至原MinPts的1.1倍,調小Eps至原Eps的0.9倍;若ρ0<ρmin,則調小MinPts至原MinPts的0.9倍,調大Eps至原Eps的1.1倍。在調大或調小的倍數選擇中,為減少運算次數,調大倍數應越大越好,調小倍數應越小越好,過大或過小會導致兩次迭代結果的聚類率相差太大,甚至錯過最優聚類率區間,所以經過大量實驗得出最優的調大倍數為1.1倍,調小倍數為0.9倍。
(4)迭代。令n=n+1,循環(1)~(3),直至n的大小等于最大迭代次數N或者聚類率ρ位于最優聚類率區間,完成聚類。
3 實驗與結果分析
3.1 實驗數據及環境
數據采用河北省某市2018年1月-3月所有線路公交車的GPS數據,其中公交線路有223條,總數據量111 G,共818 251 686條數據。搭建偽分布式Hadoop集群存儲GPS數據,集群由一個主節點,4個從節點構成,服務器搭載兩個8核處理器,32 G內存,1 TB存儲空間。利用HIVE處理HDFS上的數據,HIVE是基于Hadoop靜態批處理的數據倉庫工具,可以通過類似SQL語句的HQL語句進行數據庫的增刪改查等操作,易于掌握。HIVE還提供了內置函數和Java API接口,開發人員可以根據這些函數去實現復雜的業務邏輯。這些HIVE的操作底層均是轉為機器學習中的MapReduce任務去執行,可以方便地實現海量數據的統計分析[10]。
3.2 評價標準
實驗評價標準采用F1值[11]及均方根標準偏差(root-mean-square standard deviation,RMSSTD)[12]。F1值是一種評價聚類結果的綜合指標,計算公式如式(8)所示。其中,正確率Precision為實驗結果簇中噪聲點與簇中總數據點的點數比;召回率Recall為簇中非噪聲點的點數與總數據集非噪聲點的點數比。例如數據集總點數為N,聚類后的簇中數據點為N′,總數據集的非噪聲點數為M,簇中非噪聲點數為M′,則
(6)
(7)
(8)
RMSSTD通過衡量聚結果的同質性,即緊湊程度,來判斷聚類效果的好壞。計算公式如式(9)所示
(9)
式中:Ci代表第i個簇,ci是該簇的中心,x∈Ci代表屬于第i個簇的一個樣本點,ni為第i個簇的樣本數量,P為樣本點對應的向量維數(例如一個簇含有10個點,則該簇的向量維數即為10)。 ∑i(ni-1)=n-NC,其中n為樣本點的總數,NC為聚類簇的個數,通常NC?n,因此∑i(ni-1) 的值接近點的總數,為一個常數。綜上,RMSSTD可以看作是經過歸一化的標準差來衡量聚類的效果好壞。
3.3 PB-DBSCAN較DBSCAN在聚類效率上的提升
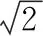
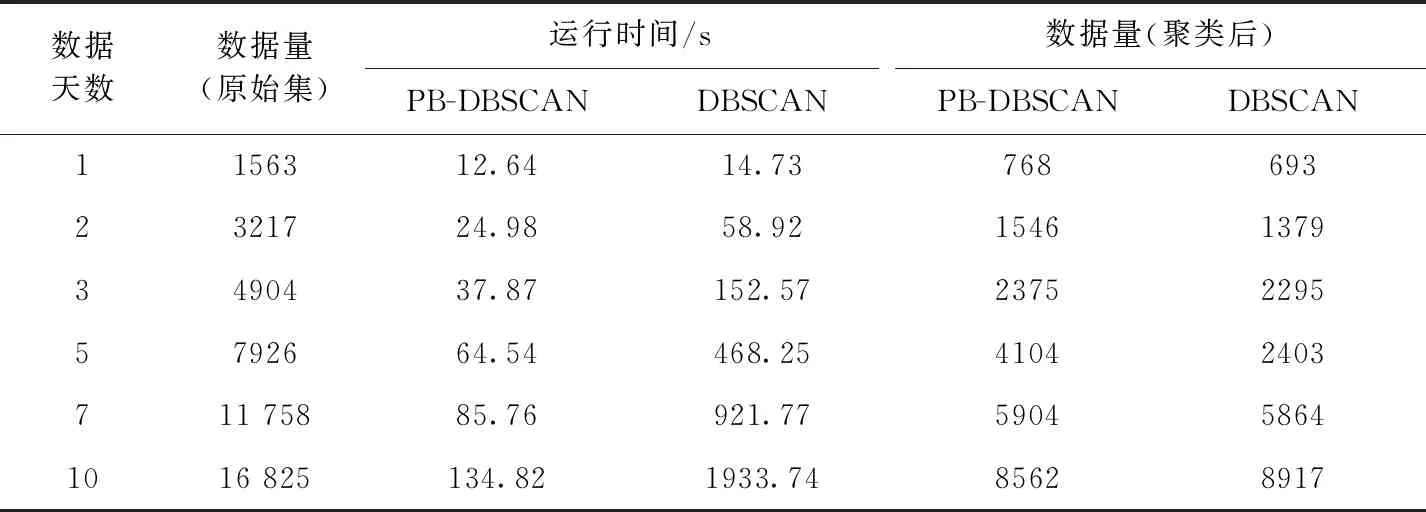
表1 PB-DBSCAN與DBSCAN聚類性能比較
傳統的DBSCAN聚類方法,假設數據集總數為n,兩個數據點計算一次距離所用時間為t,由于要遍歷所有點與未遍歷過的點之間的距離,可得所需總時間T=(n-1)t+(n-2)t+(n-3)t+…+t=n(n-1)t/2,所以傳統的DBSCAN聚類方法的時間復雜度為O(n2),PB-DBSCAN聚類方法,假設數據集總數為n,分為k個像素格,兩個數據點計算一次距離所用時間為t,每次判斷每個像素格內的點是否為核心點所用時間nkt,由于每個像素格的相鄰像素格數量為20,所以遍歷非核心點理論所需最大計算時間為20nt,可得所需總時間T=(20+k)nt,所以PB-DBSCAN聚類方法的時間復雜度為O(n)。
3.4 動態參數選擇較固定參數在聚類性能上的提升
為驗證動態參數選擇聚類方法相較于固定參數對聚類結果性能上的提升,選取石家莊106路、108路、34路、55路、56路和68路在2018年1月12日的上行GPS數據,分別使用動態參數的PB-DBSCAN算法和固定參數的PB-DBSCAN算法進行聚類,實驗結果見表2。
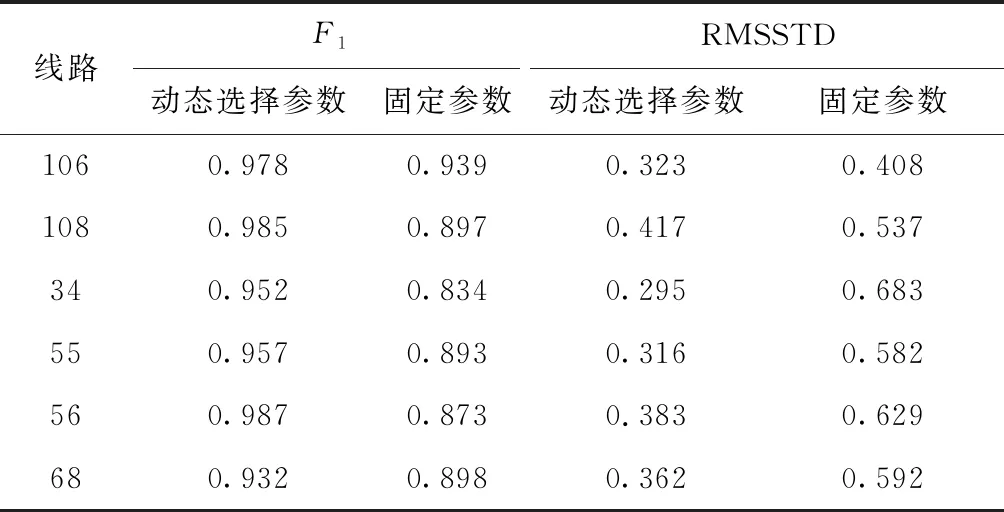
表2 自適應參數與固定參數聚類性能比較
為體現不同線路的動態參數選擇聚類過程對初始參數的自適應性,分別對這些線路進行固定參數的預聚類實驗,得到在多條線路下滿足聚類率在聚類區間內或臨近聚類區間的共同初始輸入參數:Eps0=20和MinPts0=5。
從F1值評價指標來看,在同一線路比較中,動態選擇參數的F1值均大于固定參數,與固定參數相比,F1值平均提高了10%,在不同線路比較中,動態選擇參數的F1值更加穩定;從RMSSTD評價指標來看,動態選擇參數的RMSSTD值均小于固定參數,與固定參數相比,RMSSTD值平均降低了30%。說明動態參數選擇方法的聚類過程相較于固定參數的聚類過程具有良好的穩定性與準確性。
3.5 基于PB-DBSCAN及傳統DBSCAN公交GPS去噪的可視化比較
通過對石家莊68路公交車GPS數據的處理來分析驗證基于PB-DBSCAN算法的有效性,并且與DBSCAN算法所得到的結果進行可視化比較。圖4為PB-DBSCAN算法聚類效果,圖5為DBSCAN算法聚類效果。可以看出,在拐點處或點數過密集處,DBSCAN不能很好剔除噪聲點,導致最后所得公交線路有明顯折線,偏離實際線路,尤其拐點處更是有大量折線,不符合道路實際特征,而PB-DBSCAN所得的聚類結果,由于噪聲點少,尤其在拐點處的去噪效果尤為明顯,沒有出現明顯的偏差,所得線路基本符合實際道路,因此,PB-DBSCAN聚類效果明顯優于DBSCAN。
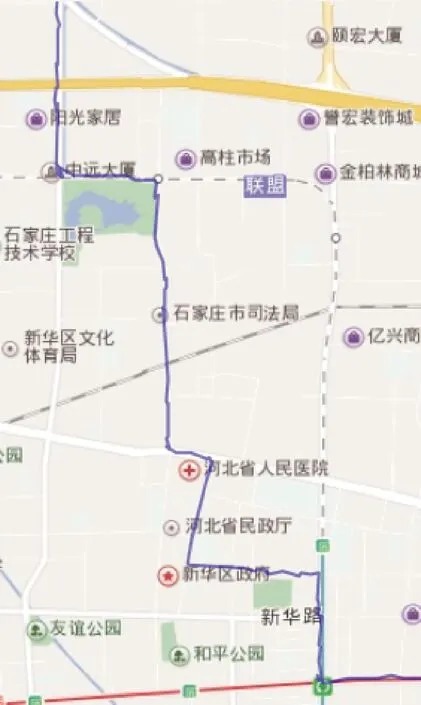
圖4 基于PB-DBSCAN的線路生成
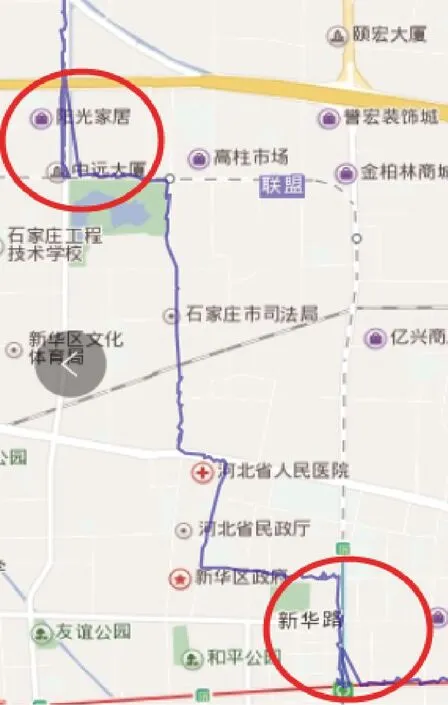
圖5 基于DBSCAN的線路生成
4 結束語
本文在DBSCAN算法的基礎上,提出了一種基于像素格的快速密度聚類算法——PB-DBSCAN算法,通過將龐大的GPS數據集使用基于像素格的PB-DBSCAN進行聚類,時間復雜度由傳統DBSCAN的O(n2) 降為O(n),提高了算法效率。同時本文通過動態參數選擇方法,解決了單一的聚類參數無法在保證聚類準確度的情況下對多個不同GPS數據集同時聚類的問題,F1值平均提高了10%,RMSSTD平均降低了30%。下一步的研究中,會對聚類后的GPS數據進行抽稀、擬合等操作,使其更好貼合實際道路,實現數據的價值。
