一種基于MySQL的數據同步中間件研究
2021-03-24 09:12:50劉麗胡曉勤
現代計算機 2021年2期
劉麗,胡曉勤
(四川大學網絡空間安全學院,成都610065)
MySQL是最流行的關系型數據庫管理系統之一,在國內互聯網中應用十分廣泛,原生的MySQL主從復制缺乏的靈活性,無法滿足源端、目標端庫表結構不一致的同步場景,也不能同步到異構數據存儲中。基于MySQL Replication協議,設計并實現一種基于MySQL的數據同步中間件,支持增量數據的自定義規則處理,提供數據同步定制能力,目標數據存儲支持MySQL、Kafka,以及其他異構數據存儲。
MySQL;數據同步;異構;中間件
0 引言
在互聯網高速發展的今天,針對MySQL的數據同步需求越來越繁雜,原生的MySQL主從復制僅支持MySQL實例之間的全量復制,且主從數據庫之間庫、表結構一致,這在一些數據遷移場景需求下無法滿足。如將源MySQL實例的A庫遷移到目標MySQL實例的B庫、在同步過程中根據某些數據字段的變化情況進行復制等,針對這些業務定制很強的場景,MySQL原生主從并不能解決。此外,在OLAP[1]場景下,往往需要將關注的MySQL增量數據采集到Kafka、ElasticSearch等異構數據存儲中,因此,也需要解決MySQL同步至異構數據存儲的問題。
針對上述問題,本文提出了一種基于MySQL的數據同步中間件,支持MySQL實例之間的單向數據同步,并提供了自定義增量數據同步規則的定制入口,能滿足所有的映射同步、過濾同步等復雜的同步場景。此外,還支持將MySQL增量數據同步至Kafka等異構數據存儲中,應用也可自行實現自己的數據存儲同步適配器,具備極高的可拓展性。
1 數據同步中間件架構
本文提出的數據同步中間件系統架構如圖1所示,整體分為邏輯層、協調層。本數據同步中間件的邏輯層包含Replicator組件和Consumer組件,Replicator組件負責從存儲層的源MySQL實例中采集增量的Binlog Event數據,經過解析、過濾后,使用自定義的數據結構封裝并保留在存儲模塊中,Consumer組件負責從Replicator組件中消費增量數據,并還原至目標MySQL實例中;協調層負責為邏輯層組件提供分布式協調服務,基于Zookeeper[2]為Replicator組件和Con?sumer組件提供狀態同步、集群管理、服務發現的分布式服務能力。
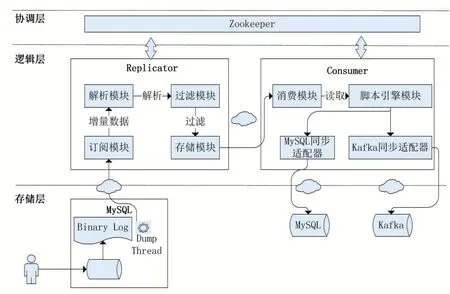
圖1 數據同步中間件系統架構
2 Replicator組件
2.1 訂閱模塊
訂閱模塊負責與訂閱的源MySQL實例進行網絡通信交互,完成增量數據的持續采集,如DML(Data Manipulation Language)和DDL(Data Definition Lan?guage)操作產生的Binlog Event數據。訂閱模塊與MySQL進行網絡交互的協議包括TCP三次握手協議、MySQL HandShake協議、MySQL Replication協議[3],交互時序如圖2所示,該交互過程中涉及到的MySQL協議均遵循原生協議規范。
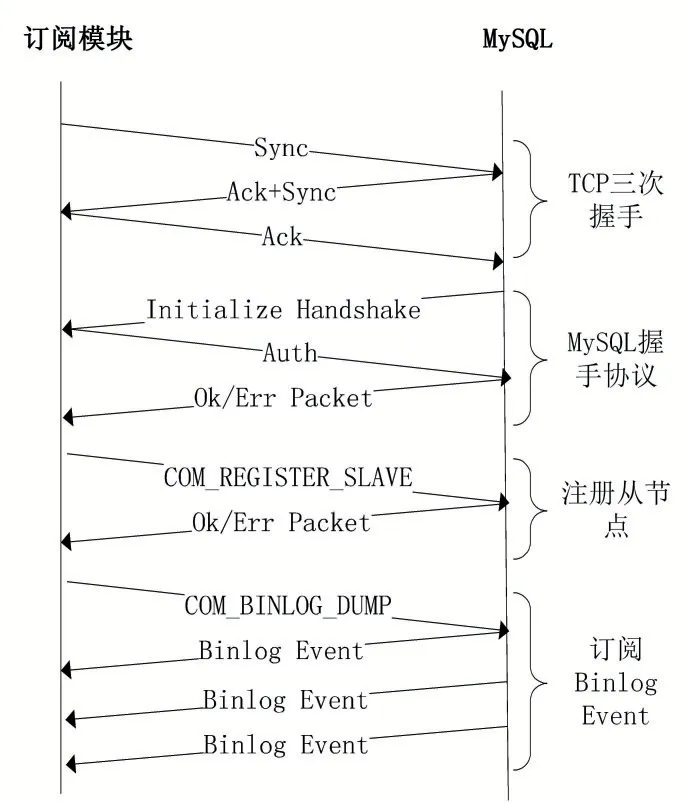
圖2 訂閱模塊與MySQL協議交互流程
(1)訂閱模塊與MySQL進行TCP三次握手,建立TCP連接;
(2)完成TCP連接建立后,MySQL會主動給訂閱模塊發送一個MySQL初始化握手數據包,訂閱模塊對該握手數據包解析后,將自身登錄使用的賬號、密碼等信息反饋給MySQL服務端;
(3)當訂閱模塊與MySQL服務端成功握手后,訂閱模塊通過MySQL Replication協議,給MySQL服務端發送COM_REGISTER_SLAVE命令,將本模塊注冊為MySQL服務端的從節點;
(4)當訂閱模塊成功注冊成為MySQL服務端的從節點后,訂閱模塊通過MySQL Replication協議,給MySQL服務端發送COM_BINLOG_DUMP命令,使MySQL服務端持續推送增量的Binlog Event數據給訂閱模塊;
完成上述的MySQL Replication協議交互后,本模塊將使用Netty框架監聽訂閱MySQL推送Binlog Event數據流的寫入事件,并將其緩存在字節緩沖區中,用于解決粘包/拆包問題,截取完整Binlog Event數據包流程如圖3所示。
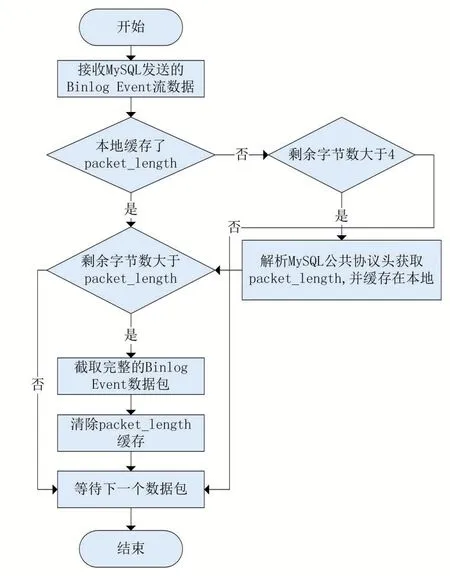
圖3 Binlog Event粘包/拆包解析流程
(1)訂閱模塊接收到MySQL服務端推送的數據包后,嘗試解析前四個字節,并獲取完整數據包的字節大小packet_length;
(2)如果本數據包剩余字節大小大于pack?et_length,說明出現了粘包現象,緩沖區中包含了完整的Binlog Event數據,則根據packet_length進行截取,獲得完整的Binlog Event數據包;如果本數據包剩余字節大小小于packet_length,說明出現了拆包現象,需要等待下一個數據包到達;
通過上述方法進行完整Binlog Event數據包的截取后,將其交給解析模塊進行深度解析。
2.2 解析模塊
解析模塊負責解析Binlog Event數據包,將其封裝成自描述的數據結構。解析模塊從訂閱模塊中獲取的Binlog Event數據包遵循原生MySQL中Binlog Event數據包協議,通過對其解析后,獲取完整的行數據變更描述。DDL(Data Definition Language,數據定義語言)語句產生的Binlog Event數據,解析后獲得其執行時的SQL語句;DML(Data Manipulation Language,數據操縱語言)語句產生的Binlog Event數據,解析后獲得行數據變更前后的數據描述,包括列名、列值、列類型等信息;
本文描述的數據同步中間件基于MySQL Server的行復制(Row-Based Replication,RBR)模式,在這種模式下Binlog Event會詳細描述行數據變更前后的狀態,可以最大限度的保證主從復制的一致性,需要MySQL服務端開啟binlog_format=ROW。基于MySQL服務端的行復制模式,當客戶端在MySQL服務端提交事務時,二進制日志中會產生QUERY_EVENT、TA?BLE_MAP_EVENT、ROWS_EVENT(WRITE/UPDATE/DELETE)、XID_EVENT四種類型的事件,如圖4所示。
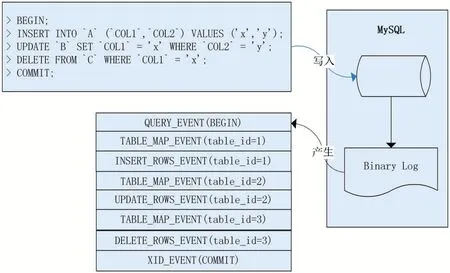
圖4 Rows-Replication事件結構圖
(1)QUERY_EVENT。當客戶端執行DML導致行數據變更時,該事件記錄了事務開始的發生,該類型的Binlog Event數據包中可以記錄諸如BEGIN、END、XA START、XA END、XA COMMIT、ROLLBACK等語義;當客戶端執行DDL語句時,該事件記錄了DDL語句操作的庫名稱以及客戶端執行的SQL語句;
(2)TABLE_MAP_EVENT。當客戶端執行DML導致行數據變更時會產生該類型的事件,該類型的Bin?log Event數據包中記錄了行數據變更的庫、表、字段信息。解析模塊在完成本類型Binlog Event數據包解析后,將在本地內存中緩存該表信息的內容,供下文解析ROWS_EVENT使用;
(3)ROWS_EVENT(WRITE/UPDATE/DELETE)。該事件類型的Binlog Event數據詳細描述了DML語句修改數據的前后狀態,ROWS_EVENT類型的Binlog Event數據包中記錄了變更行數據的表序號(table_id),結合TABLE_MAP_EVENT中解析的表信息,可以從ROWS_EVENT數據包中獲取行數據變更前后的列值信息;
(4)XID_EVENT。當客戶端在MySQL服務端提交事務時會產生該類型事件,標識了一個事務的結尾;
通過對上述類型的Binlog Event數據進行解析,解析模塊將需要的解析結果用一個定義好的對象結構RowData存儲,完整的對象結構描述如表1,RowData數據結構中存儲了本事件的語義類型(如DML、DDL、事務開始/結束等類型)、Binlog位點(Binlog文件名、偏移量)、DML語句執行后行數據變化前后的列信息,該列信息數據結構如表2所示,其中,字段名稱在Binlog Event中并未提供,需要解析模塊自行查詢源MySQL獲取。
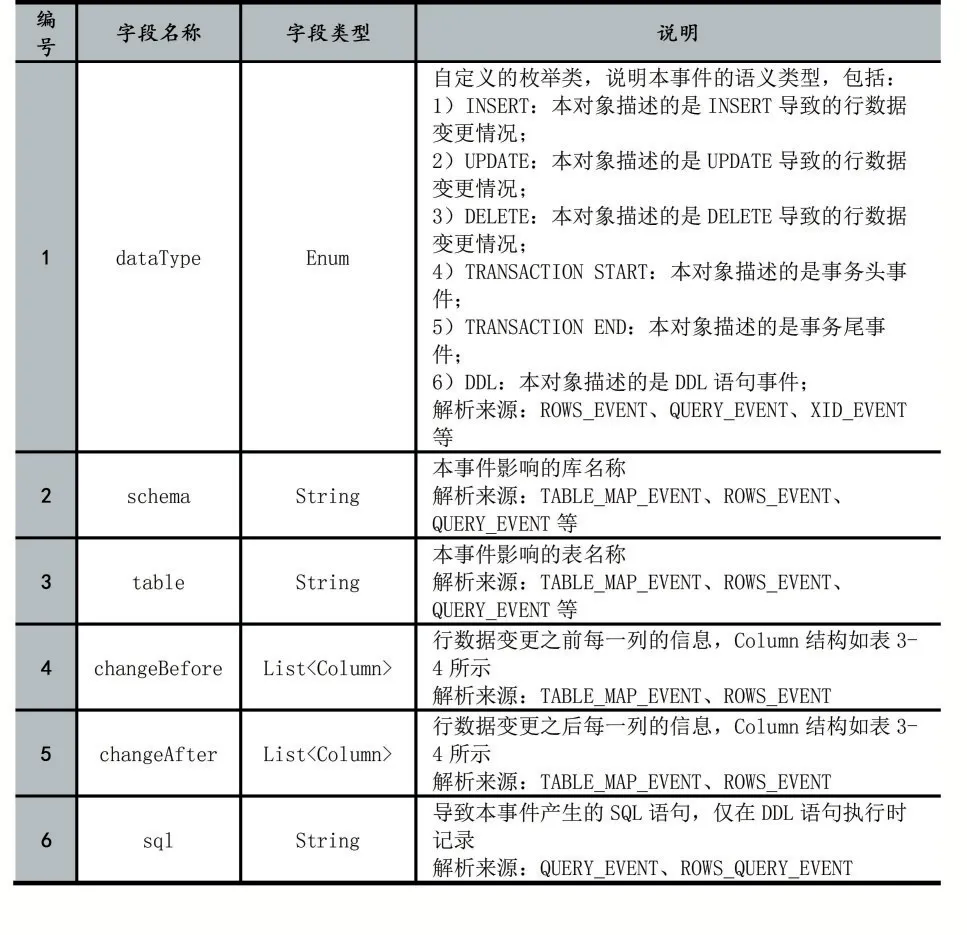
表1 Row Data對象結構
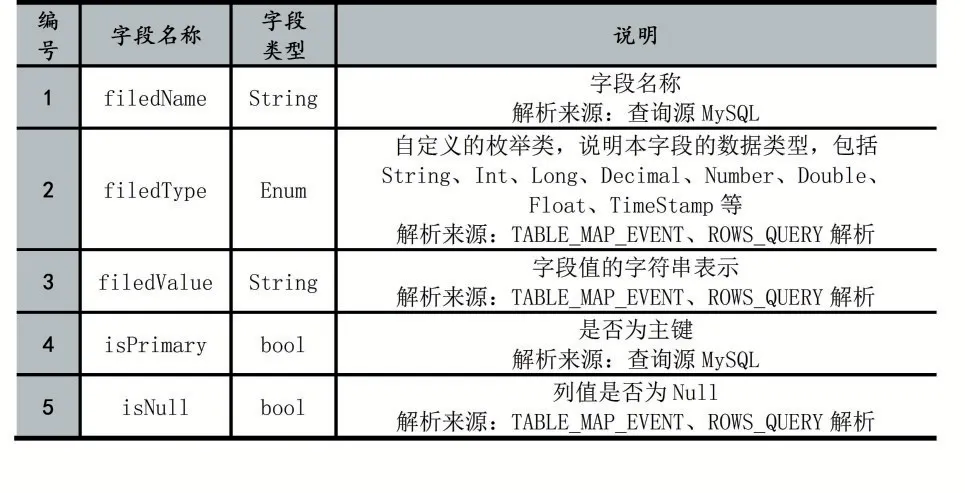
表2 Column對象結構
2.3 過濾模塊
過濾模塊負責過濾不關注的庫、表數據。本模塊使用Aviator引擎框架完成正則表達式的高性能求值,實現了Binlog Event黑白名單功能,過濾類型包括以下:
(1)Binlog Event類型過濾。本文中只保留了其中的事務開始事件、事務結束事件、DML產生的行數據變更事件和DDL產生的變更事件;
(2)Binlog Event庫表過濾。除了對事件類型進行過濾外,過濾模塊還將根據用戶指定的庫、表黑白名單對Binlog Event數據進行過濾,只保留本數據同步中間件關注的庫表Binlog Event數據,減輕下游數據處理壓力。
2.4 存儲模塊
存儲模塊負責需要同步的Binlog Event數據的管理與分發,本模塊使用分段數據文件的形式存儲被解析的Binlog Event數據,在經過前置過濾模塊的篩選后,數據文件中只保存了下游需要消費的事件數據。
數據文件使用二進制形式存儲數據,通過Proto?buf[4]序列化算法將Binlog Event數據的位點信息和事件內容信息轉換成一連串的字節描述,并使用緊湊的變長變量存儲以提高磁盤利用率。具體的,每一條事件數據的存儲結構如表3。其中,位點信息和事件內容信息為變長數據,分別使用8字節固定長度的空間存儲變長數據的字節數,并通過CRC32(循環冗余校驗)算法計算出前(8+positon_length+8+rowdata_length)字節內容的的校驗碼,用于數據訪問時做簡單的數據檢查,避免數據損失導致數據讀取異常。位點信息的數據結構如表4,包含了Binlog文件名、Binlog偏移量以及該Binlog Event的時間戳。
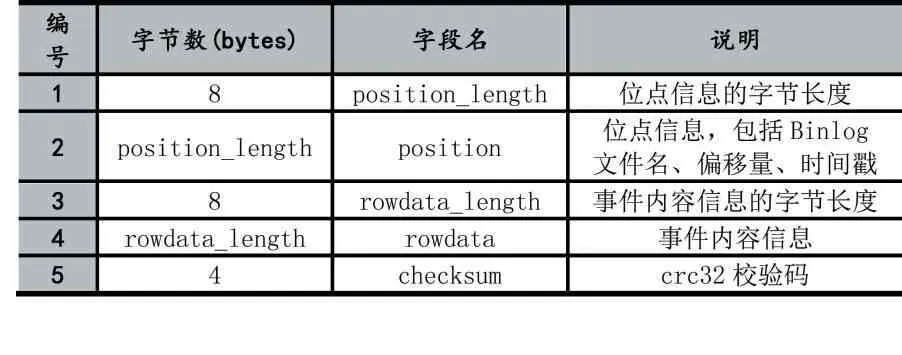
表3 數據文件Binlog Event數據存儲結構
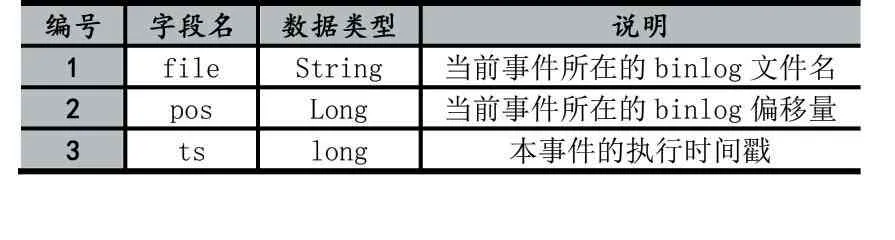
表4 位點信息數據結構
3 Consumer組件
3.1 消費模塊
消費模塊負責通過自定義RPC協議,從Replicator組件中批量獲取關注的Binlog Event數據。該消費通信遵循2PC(Two-Phase Commit protocol,兩階段提交協議)協議,第一階段中,消費模塊從Replicator組件中獲取批量數據,第二階段,消費模塊確認第一階段數據處理完成或進行消費回滾,時序流程如圖5所示。
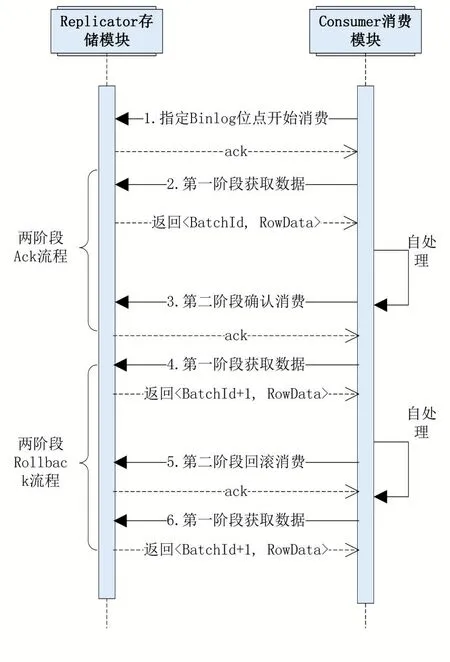
圖5 兩階段流程
(1)兩階段Ack流程。消費模塊首先進行第一階段,從存儲模塊中批量獲取RowData數據,存儲模塊將為該批次數據分配一個序號batchId,消費模塊完成該批次RowData的處理后,第二階段對該批次batchId進行確認,表示該部分數據已經消費完成,至此兩端Ack流程完成;
(2)兩階段Rollback流程。區別于Ack流程,當消費模塊沒有正確處理完該批RwoData數據,認為需要重試時,第二階段將向存儲模塊發起回滾請求,消費模塊下次獲取數據時仍從本批次開始。
3.2 腳本引擎模塊
腳本引擎模塊負責對用戶自定義規則腳本生命周期的維護,包括加載、編譯、編排、執行。基于規則腳本,用戶可以對RowData數據自定義加工處理,實現字段級數據過濾、字段加工、映射同步等功能,為業務提供靈活的增量數據加工處理入口。
在腳本引擎模塊中將解析兩種類型的文件,一種是腳本編排文件,一種是腳本規則文件,其中腳本規則文件中存儲的是用戶編寫的數據處理邏輯,本文中包括Java文件和Groovy文件,腳本編排編排文件中存儲了規則文件的編排方式信息,以Yaml格式進行存儲,每一個腳本信息的描述數據結構如表5所示,本模塊通過指定每個腳本的執行順序進行執行拓撲的編排。
基于上述的腳本編排文件格式,如圖7所示,在文件系統中存在編排文件engine.yaml以及多個規則腳本文件,腳本引擎模塊將根據編排文件中描述的腳本信息進行腳本的編譯、編排,如圖6所示。
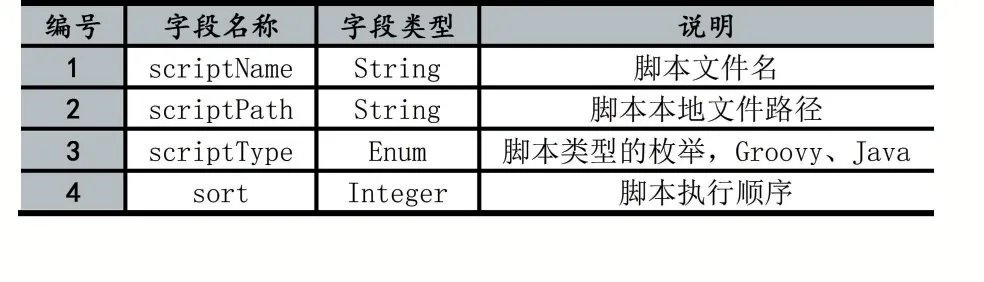
表5 腳本編排信息數據結構
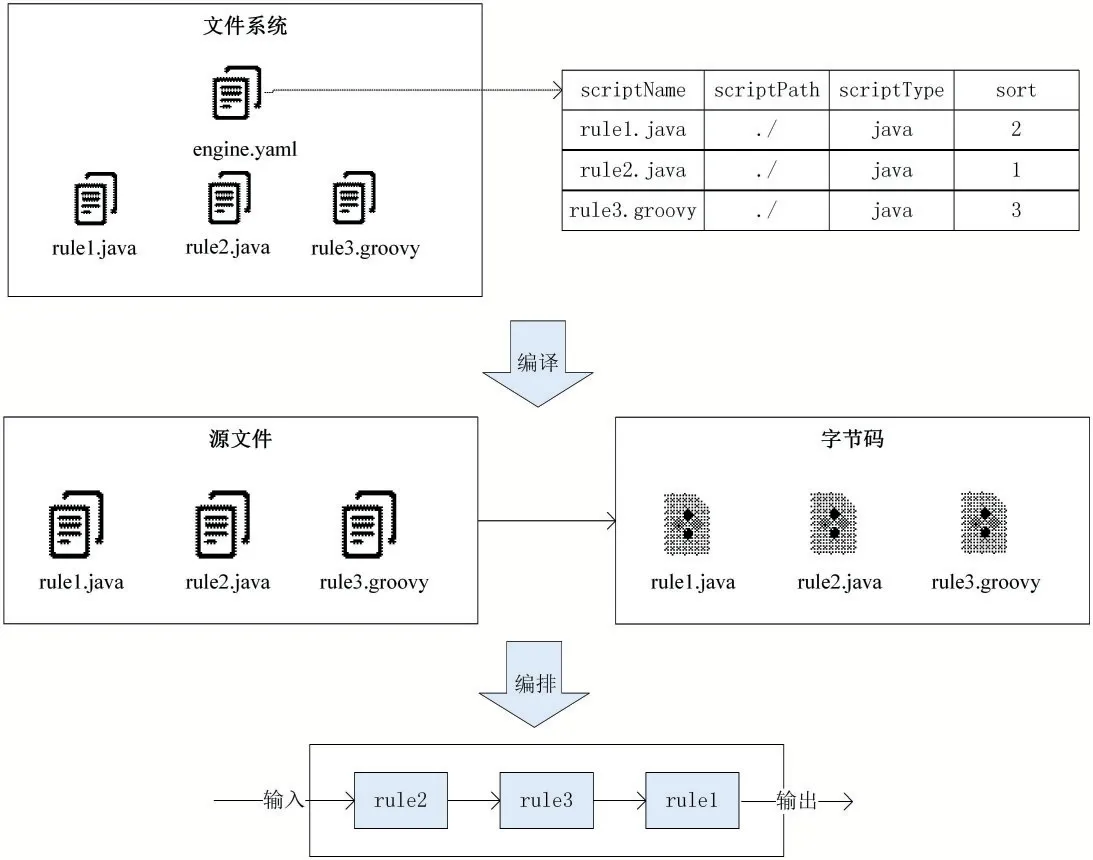
圖6 腳本引擎工作流程圖
(1)腳本引擎初始化時讀取指定目錄下的編排文件engine.yaml文件并進行解析,獲得編排文件中存儲的腳本編排信息,包括腳本文件的腳本名稱、腳本路徑、腳本類型以及執行序號;
(2)根據編排文件中的腳本信息,對涉及的規則腳本進行編譯,如果是Java類型的規則文件,則使用JDK6開始提供的JavaCompiler工具進行動態編譯;如果是Groovy類型的規則文件,則使用GroovyClassLoader加載器進行編譯,并緩存在腳本引擎模塊中;
(3)根據編排文件中描述的執行順序,對規則腳本的執行進行編排,當有數據輸入時,根據該規則拓撲進行數據加工處理。
3.3 同步適配器模塊
3.3.1 MySQL同步適配器
本中間件描述的方案基于InnoDB存儲引擎,且同步表含有主鍵。對于DDL語句,直接在目標MySQL執行RowData中記錄的SQL即可。對于DML,本中間件通過RowData合并、SQL還原以及并行復制的方式完成目標MySQL的寫入。工作流程如圖7所示。
(1)Merger對本批次RowData進行合并,在保證數據一致性的前提下,將本批次中相同主鍵的行數據變更記錄進行合并,如一條行記錄先后經歷INSERT、多次UPDATE,最終被DELETE,該行數據在結果上不需要同步到目標數據庫,即以最終結果為準,減少了目標MySQL回放的數據量;
(2)Partitioner對合并后的數據進行分區。根據行數據的庫、表、主鍵三元組進行哈希分組,將其切分成N個小批次數據,并提交到線程池;
(3)線程池調度執行,每個線程處理一個小批次的數據,通過SQL還原的方法將RowData描述的數據變化轉換成DML語句,針對每個事件類型進行如下處理:
①本事件屬于INSERT類型。使用INSERT IN?TO...ON DUPLICATE KEY UPDATE語義,該語義在目標MySQL存在該行數據時進行更新操作,不存在該行數據時進行插入操作。根據RowData的schema、table、afterChange構造SQL語句如下:
INSERT INTO`schema`.`table`(`filed_1`,...,`field_n`)VALUES(value_1,…,value_n)ONDUPLICATEKEY UP?DATE field_1=VALUES(field_1),…,field_n=VALUES(field_n);
②本事件屬于UPDATE類型。使用REPLACE INTO語 義,根 據RowData的schema、table、before?Change、afterChange構造SQL語句如下:
REPLACE INTO `schema`.`table`(`filed_1`,…,`field_n`)VALUES(value_1,…,value_n);
③本事件屬于DELETE類型。根據RowData的schema、table、beforeChange進行SQL還原,根據主鍵刪除目標MySQL數據,構造DELETE語句如下:
DELETE FROM`schema`.`table`WHERE`pri_key_1`=pri_value_1…AND`pri_key_2`=pri_value_2;
(4)多線程并行寫入目標MySQL,完成數據同步。
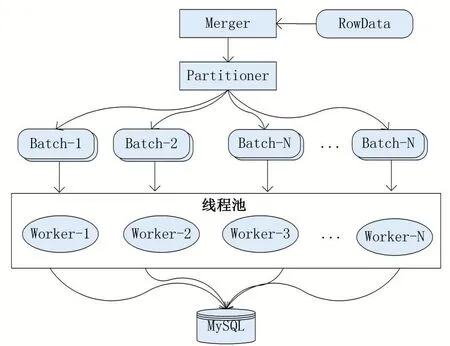
圖7 MySQL同步適配器并行復制過程
3.3.2異構同步適配器
在本數據同步中間件中,每一個異構數據存儲類型對應了一種同步適配器,適配器負責獲取MySQL增量行數據,在進行數據處理后,通過異構數據存儲的SDK完成寫入。結合本中間件提供的腳本引擎模塊,可以完成更多目標數據存儲的支持,有很高的可拓展性。當目標為Kafka等隊列存儲時,同步適配器需要著重考慮Binlog Event分發的順序性,此時提供兩種寫入策略。
(1)對于需要保證行數據級別Binlog Event順序的場景,在適配器處理數據時,根據庫、表、主鍵計算哈希值,并對寫入隊列的數量取余,將相同主鍵的行數據事件分發到同一個隊列中,只要下游應用對每個隊列啟用一個線程進行消費,則可以保證行數據級別的Bin?log Event的順序性;
(2)對于需要保證全局Binlog Event順序的場景,該適配器寫入隊列的數量只能為1,并且使用單線程寫入隊列,下游應用也只能啟用一個線程消費該隊列,吞吐量將十分有限。
4 基于Zookeeper的分布式增強
4.1 組件高可用
Replicator組件和Consumer組件的集群化,實現組件的主備切換,提供高可用服務能力。以Replicator組件為例,當多個組件啟動初始化時,分別向Zookeeper相同路徑下中注冊臨時節點,路徑為/data/sync/{task_id}/replicator/node,其中task_id為本同步任務的唯一標識,注冊時使用的值為各自組件的IP地址和服務端口。由于Zookeeper臨時節點的特性,只有一個節點會注冊成功,注冊成功的節點將作為主節點,進行正常的工作,其余節點將注冊該臨時節點的監聽事件,當該臨時節點發生刪除事件時,將會重新進行新一輪的選主過程,以此保證組件的高可用特性。對于Consum?er組件同樣采用上述邏輯實現高可用。
4.2 服務發現
當Replicator集群發生主備切換時,Consumer組件需要及時切換到新的Replicator組件節點進行訂閱消費。當Consumer組件啟動后,會在Zookeeper中查詢/data/sync/{task_id}/replicator/node是否有注冊成功的Replicator組件,如果有成功注冊的節點,則獲取節點中存儲的IP地址和服務端口,隨后通過RPC協議與Replicator組件進行2PC交互,如果沒有發現成功注冊的Replicator節點,則Consumer組件處于掛起監聽狀態,直到有Replicator組件在該同步任務下創建臨時節點,以此實現Replicator組件的服務發現。
4.3 消費位點管理
對于Replicator組件進行消費位點的管理流程如圖8所示,當Replicator接收到二階段Ack請求后,根據批次號獲取該批數據的位點信息,在更新內存消費位點后,完成本次請求后直接反饋成功,之后,Replica?tor組件由內部異步任務定時向Zookeeper中更新位點信息,位點信息在Zookeeper中的路徑為/data/sync/rep?licator/{consumer_cluster_id}/process,其 中 consum?er_cluster_id為Consumer集群的唯一標識,存入的值為本批次最后一條Binlog Event的位點。
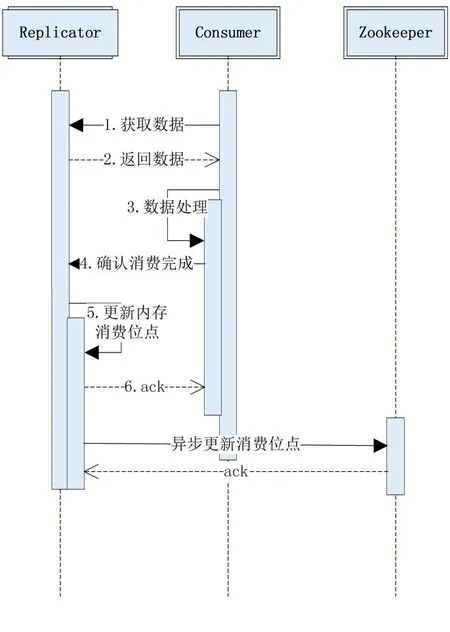
圖8 Replicator位點記錄時序圖
5 測試
測試所用的機房有兩套,分別為北京機房和廣州機房,兩個機房之間的網絡延遲約為30ms左右,環境配置如表6。
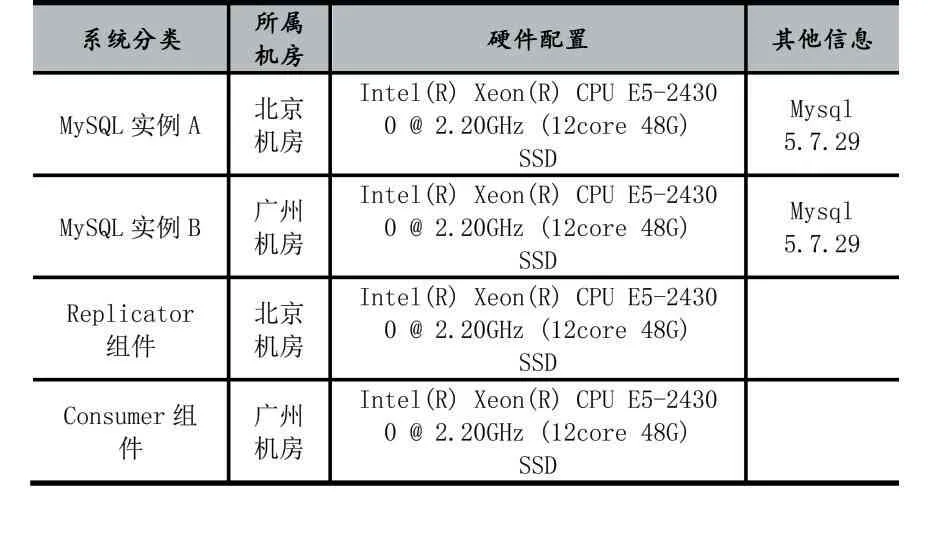
表6 測試環境配置表
本次實驗的拓撲結構如圖9所示,兩個MySQL實例間都已經打開二進制日志并設置為ROW模式。
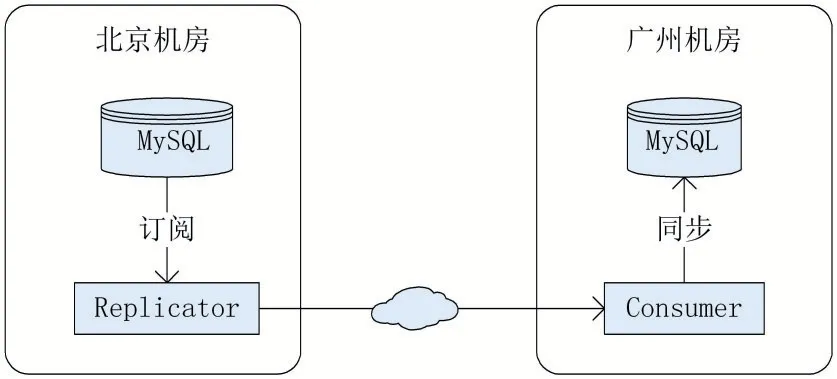
圖9 單向同步實驗拓撲圖
下面將從INSERT、UPDATE以及INSERT/UP?DATE混合三種場景下,對比單向同步復制中不同并行度下的性能表現,具體數據如表7所示。
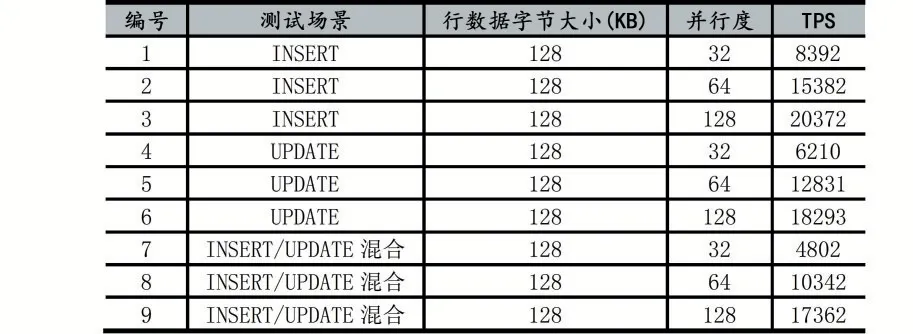
表7 單向同步并行復制性能測試報告
由上述實驗情況可知,本數據同步中間件在MySQL單向同步的INSERT場景下表現良好,主要是經過數據合并后對同表的INSERT語句使用了預編譯方式,將INSERT語句批量提交到目標MySQL中,避免了目標MySQL多次解析、優化相同的SQL語句。
6 結語
本文基于MySQL設計并實現了一個數據同步中間件,用于將MySQL中的增量數據同步至目標MySQL或其他異構數據存儲中,并支持業務自定義增量數據處理的規則腳本,幾乎滿足了各類業務的同步需求。
