基于開源處理器Rocket 的異構SoC 設計與驗證
2021-03-29 06:31:24高營,劉德,鞠虎
電子與封裝 2021年3期
關鍵詞:指令
高 營,劉 德,鞠 虎
(中科芯集成電路有限公司,江蘇無錫 214072)
1 引言
圖像處理技術的快速發展使卷積神經網絡(CNN)算法得到廣泛應用[1]。CNN 隱層數的增加需要硬件處理器具備更高的運算性能。當前,為加速神經網絡的計算主要采用GPU 或者專用硬件加速器的方法來緩解卷積運算的壓力[2]。由此,CPU 外加運算加速器的異構片上系統(SoC)是目前主要的研究熱點之一。本文設計了激活函數(ReLU)和向量點積運算(VDP)硬件加速器,同開源處理器Rocket core、開源外設項目Si-Five Blocks 搭建成一個精簡的異構SoC。該異構SoC 通過編譯軟件程序在FPGA 平臺上的演示,在一定程度上表明了對CNN 加速的應用研究價值。
2 系統架構
異構SoC 的系統架構主要由Rocket core、ITCM、DTCM、SoC 總線、BootRom、SPI、UART、ReLU 協處理器和VDP 協處理器等部分構成,具體結構如圖1 所示。
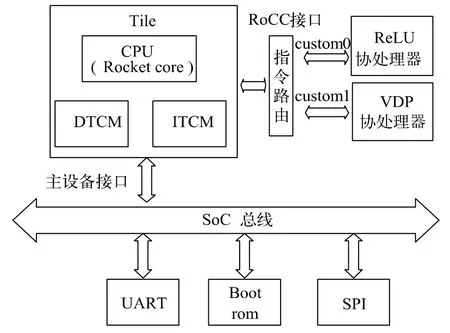
圖1 系統結構
內存的映射關系如表1 所示。
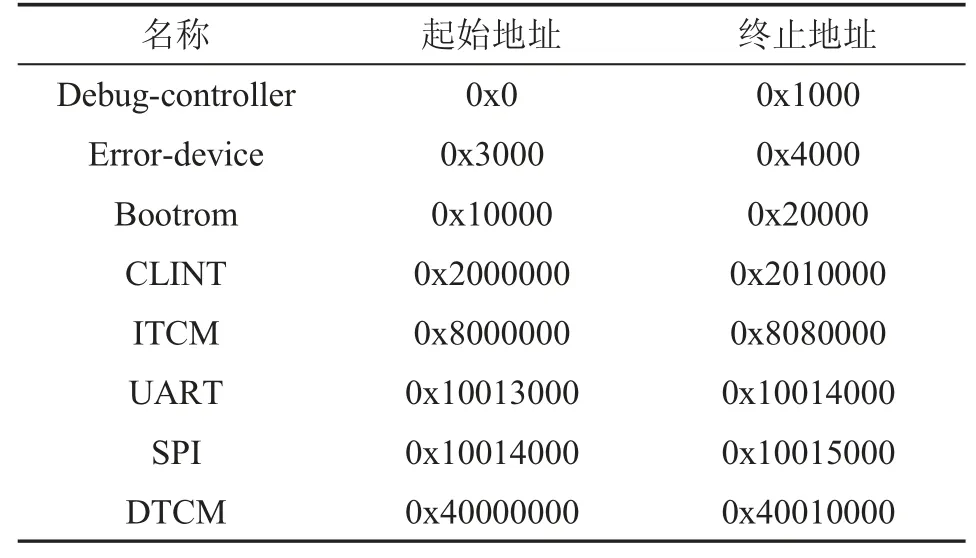
表1 內存映射
Si-Five Blocks 中通用外設 UART、SPI 等不再詳細介紹,以下主要介紹兩個加速器模塊:ReLU 激活函數協處理器和VDP 協處理器。
2.1 ReLU 激活函數協處理器
CNN 隱層主要包含卷積層、激活函數、池化層以及全連接層[3]。其中激活函數作為增加神經網絡模型非線性的手段,在算法中起到十分重要的作用[4]。當前常用的激活函數有sigmoid 和ReLU 激活函數。相對于sigmoid 激活函數計算量較大、收斂速度慢的問題,ReLU 激活函數只需判斷輸入是否大于零,計算量較小、收斂速度快且更符合生物學的神經激活機制[5],其表達式如下:
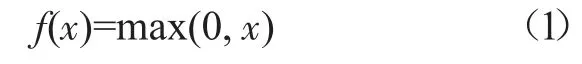
可以看出ReLU 激活函數為求最大值函數,x 小于0 時函數值為0,大于0 時函數值為x 本身,具體函數如圖2 所示。
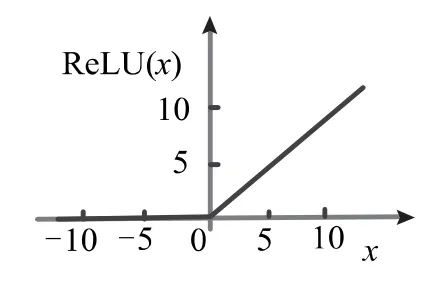
圖2 ReLU 函數
ReLU 協處理器是以RoCC 接口協議與Rocket core 進行連接。RoCC 基本接口包括與處理器傳遞狀態的CC(Core Control)接口,與一級數據緩存器(L1 DCache)傳遞數據的MEM 接口,以及與處理器傳遞指令的Core 接口;此外,還包含擴展接口:處理器獲取協處理器狀態信息的CSR 接口,協處理器與浮點運算單元(FPU)通信的接口,協處理器與頁表查找模塊(PTW)通信的接口。上述接口中,ReLU 加速器僅用到Core 接口、MEM 接口以及CC 接口,具體應用如圖3所示。
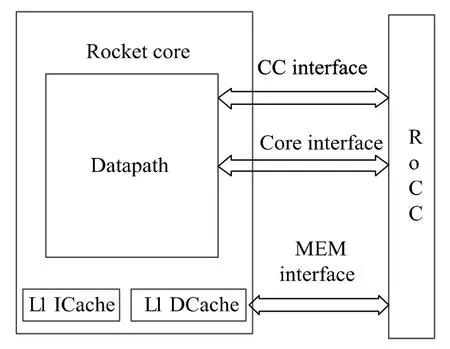
圖3 RoCC 接口結構
Rocket core 判斷是協處理器指令即ReLU 激活函數指令relui 后,通過Core 接口將該指令relui 發送到協處理器的譯碼控制單元。relui 指令格式如下:
custom0 rd,rs1,rs2,funct
custom0 為使用Rocket core 中RoCC 的首個接口(Rocket core 中默認實現了3 個自定義指令:custom0、custom1、custom2[6]),rd 為目標寄存器,rs1 和rs2 為源寄存器,funct 為額外的編碼空間,便于實現更多的指令(funct 為指令的25~31 位,因此可以編碼出128 條指令)。協處理器在計算完成后,將計算結果寫回指定地址中斷CPU,不再通過目的寄存器返回,因此rd 為零。rs1 和rs2 源寄存器的數據格式如表2 所示,表中rsltAddr 為存放計算結果數據的起始地址,srcAddr 為存放源向量的起始地址,vctSize 表示向量的大小。

表2 relui 源寄存器數據格式
ReLU 協處理器設計結構如圖4 所示,主要由譯碼控制單元和比較器構成,圖中輸入、輸出信號的定義如表3 所示。
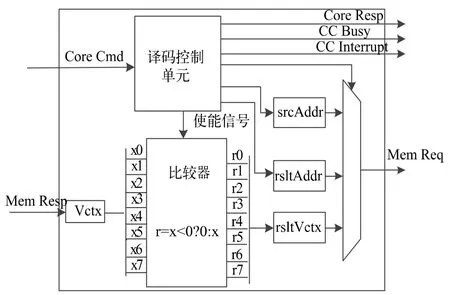
圖4 ReLU 協處理器結構
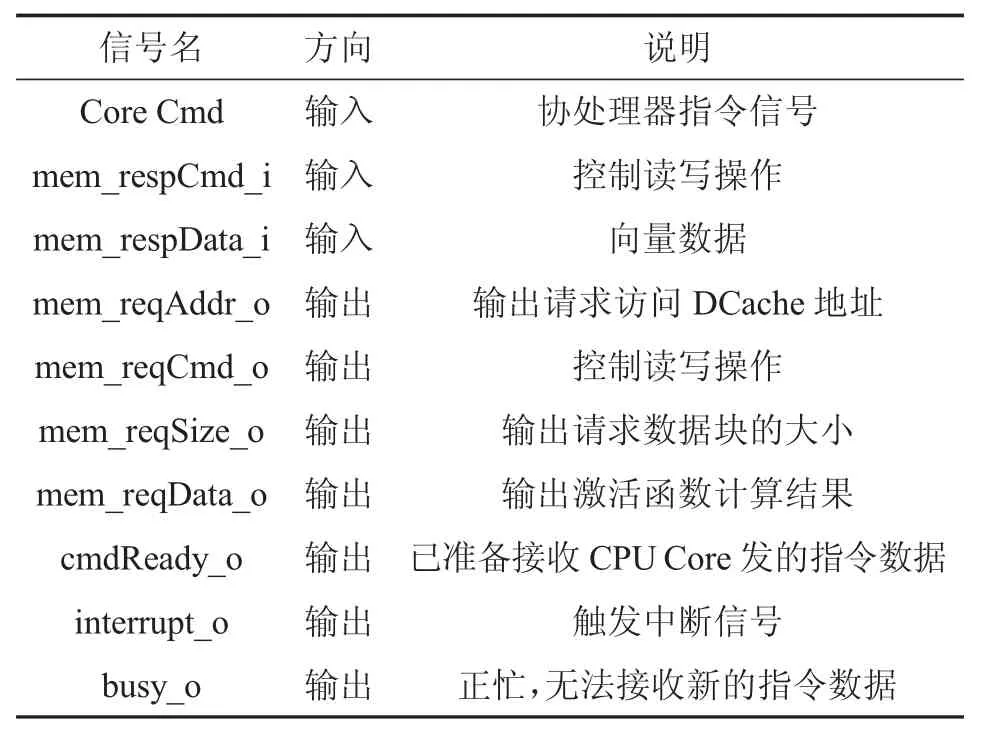
表3 ReLU 協處理器輸入輸出信號
表3 中Core Cmd 即為relui 指令格式,包含執行操作和數據。mem_resp、mem_req 為DCache 和 ReLU協處理器耦合接口(具體方式為RoCC 接口,此處不再詳述)。ReLU 協處理器工作流程如下:
接收到Rocket Core 發送過來的指令后,由協處理器譯碼控制單元解析自定義指令(Core Cmd)中的操作和源寄存器rs1 和rs2 中的數據,然后通過mem_respCmd_i 進行控制讀寫DCache 中的向量。每次從DCache 讀取8 個字節向量存放于vctx 中,每個字節看作一個有符號的8 位定點數輸入比較器。比較器判斷輸入的數是否大于零,如果小于零則輸出零,大于零則輸出數本身(ReLU 激活函數見圖2)。做完比較操作后,協處理器將計算數據結果寫回到指定地址位置,并根據rs2 源寄存器中vctSize 向量長度進行下一輪的計算操作。當完成所有的向量計算后,協處理器向Rocket core 發送一個中斷信號以便CPU 讀取計算結果。
2.2 VDP 協處理器
卷積神經網絡中最多的計算是卷積運算。加快卷積運算速度是提高卷積神經網絡計算的有效方式[7]。卷積運算的偽代碼(其中矩陣A 和B 均為m 行m 列)如下:

由上述卷積運算的偽代碼看出,可以將卷積運算分解成向量的內積(點乘)運算。卷積運算每次的計算均需要執行m2次乘法以及m2次加法。因此,卷積運算的計算復雜度為m2。將卷積分解成向量內積運算后,能夠增加運算的并行度,從而取得加速卷積運算效果[8]。
VDP 協處理器與CPU 的連接方式同ReLU 一樣,以RoCC 接口協議掛載到Rocket Core 上,vdpi 指令格式如下:
Custom1 rd,rs1,rs2,funct
Custom1 為使用 Rocket core 中 RoCC 的第二個接口,rd、rs1 和rs2 代表的意義同ReLU,這里不再贅述。VDP 協處理器也不需要將結果寫回寄存器,因此rd 為0。rs1 和rs2 為源寄存器,數據格式如表4 所示,表中vctxAddr 和vctyAdd 分別表示向量x 的地址和向量y 的地址(該地址為協處理器內部存儲地址),vctSize 為向量的大小,prdctAddr 為存放向量內積計算結果的地址(該地址為DCache 中的地址)。
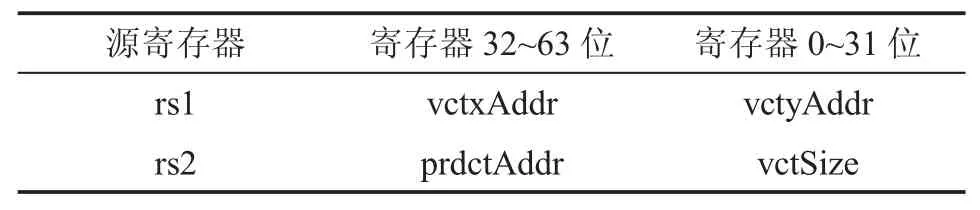
表4 vdpi 源寄存器數據格式
VDP 協處理器主要由譯碼控制單元、8 位有符號乘法單元和8 位加法器構成,具體結構如圖5 所示。
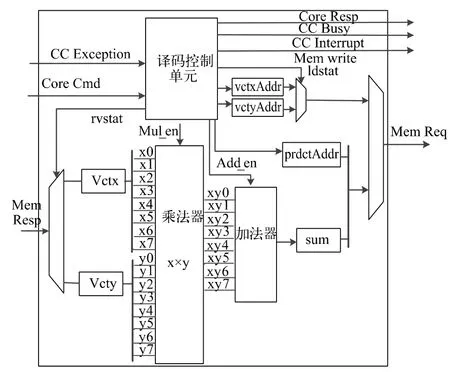
圖5 VDP 協處理器結構
運算流程如下:Rocket Core 解析指令為Custom1,將 Cmd 指令發送給 VDP 協處理器。VDP 譯碼控制單元解析Cmd 中rs1 和rs2 源寄存器的數據,然后從Mem 接口中讀取向量x 和向量y。一次讀取8個字節的數據,每個字節看作一個有符號的8 位定點數,輸入到8 位有符號的乘法運算單元,然后將對應相乘的8 個積累加到sum 中得到兩個向量的內積。根據rs2 源寄存器中vctSize 向量長度來判斷下一輪的狀態,未完成時進行下一輪讀取計算;如果判斷兩個向量的點積計算完成,則通過RoCC 的Mem 端口將計算數據寫到DCache 的指定地址,并根據Cmd 指令決定是否發送中斷給處理器。
3 FPGA 原型驗證
為檢測協處理器功能以及加速性能指標,在VC707 FPGA 平臺上進行原型驗證[9]。測試程序通過串口UART 獲取上位機(PC 機中的串口助手)發送過來的指令或者數據。當處理器接收到指令并譯碼之后,判斷這條指令是否為協處理器指令,若為協處理器自定義指令,便將指令發送給ReLU 激活函數處理單元或者VDP 加速器單元,當完成計算之后,將結果再通過串口反饋到上位機中。原型驗證如圖6 所示。
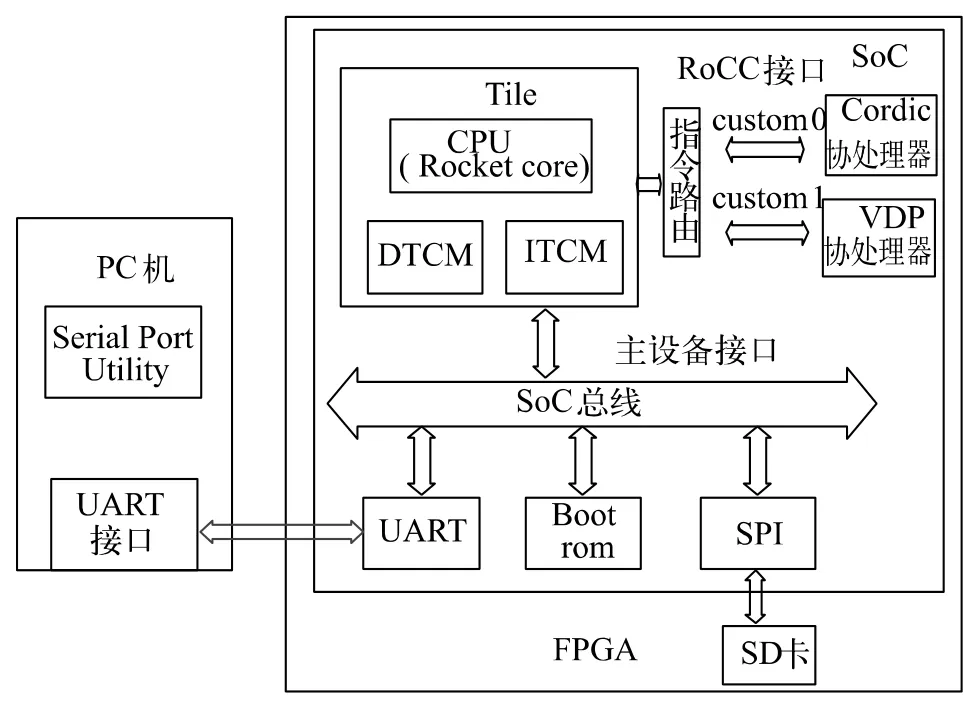
圖6 FPGA 原型驗證平臺
為更好地體現硬件加速器的加速效果,ReLU 激活函數分別用CPU 和硬件加速單元運算同一向量,來對比計算所需的時間;而向量內積則通過計算同一矩陣,來進行計算性能對比。ReLU 和VDP 加速單元均為協處理器,硬件加速需調用協處理器專用指令,具體的指令格式前文已給出,這里不再贅述。CPU 計算ReLU 激活函數的偽代碼如下:

其中m 為向量的長度,data 為計算前的向量數據,data_relu 為計算后的向量數據。CPU 計算向量內積的代碼如前文卷積計算的偽代碼,此處不再贅述。串口輸出的結果如圖7 所示。
ReLU 輸入的值為-10~14,VDP 的輸入向量 A 為0~63 即(0,1,…,62,63),求得向量內積為 A·A。由圖7 可以看出,軟硬件在功能上均實現了ReLU 和VDP計算。FPGA 原型驗證采用的輸入時鐘為50 MHz,由此 CPU(Rocket core 性能參數為 5 級流水線、64 位、單發射順序執行的處理器)的運行周期為1/(50×106)s。圖7 中串口輸出的消耗時間值即為運行的CPU 周期數,可以得出軟硬件的執行效率如表5 所示(表中同時給出了其他向量長度的運算結果,由于數據過大不利于串口顯示且限于篇幅沒有給出串口截圖),由表中的數據可以看出,針對于卷積神經網絡中的激活函數和卷積運算,ReLU 加速器和VDP 加速器相比于CPU運算均具有不錯的加速效果,且隨著向量長度的增加,加速效果越來越明顯。

圖7 驗證串口輸出
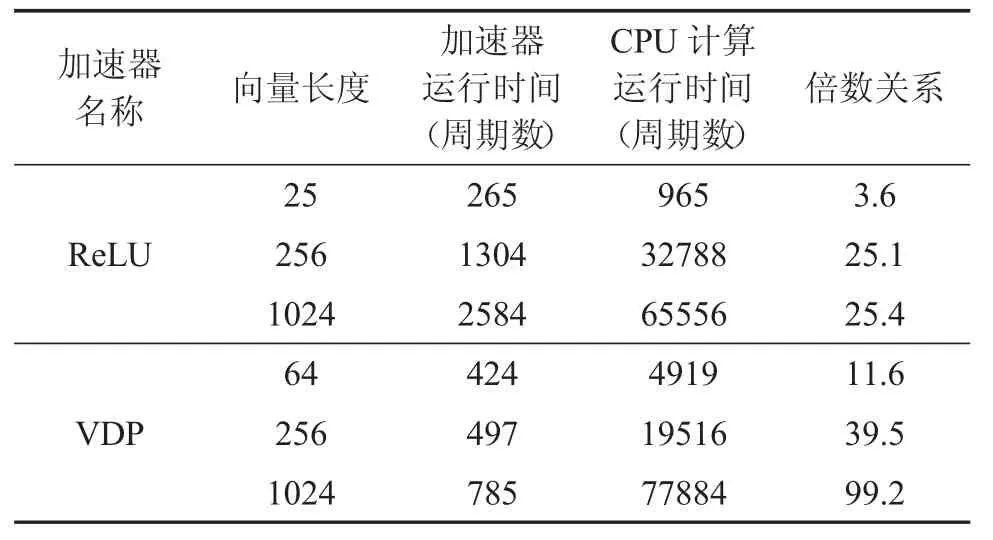
表5 運算結果對比
4 結論
本文基于開源處理器Rocket、開源項目Si-Five Blocks 添加了激活函數ReLU 加速器和VDP 加速器,搭建了簡易的異構SoC。通過FPGA 原型驗證表明,相比于CPU 的運算,ReLU 和VDP 協處理加速器能夠在一定程度上增加卷積神經網絡的運算。協處理器與CPU 緊密耦合通信消耗較小,具有很強的靈活性,因此不限應用于加速卷積神經網絡的計算,可適用于對連續地址空間非突發傳輸訪存的任何具體應用。開源處理器Rocket core 默認含有3 個協處理器接口,易于對于異構SoC 的設計和研究。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
