基于多模態視頻描述的中國手語識別
2021-04-01 13:08:08袁甜甜楊學
山東農業大學學報(自然科學版) 2021年1期
袁甜甜,楊學
基于多模態視頻描述的中國手語識別
袁甜甜,楊學
天津理工大學聾人工學院, 天津 300384
計算機視覺是目前我國新一代人工智能科技發展的重要方向,手語識別因其在連續性、復雜場景干擾等問題上的困難,導致其研究不僅可以解決聽障人對無障礙信息溝通的真實需要,還可極大的促進視頻理解及分析領域的快速發展,從而在安防、智能監控等方面也有很好的落地應用。通過比較國內外多種基于視頻描述和分析的手勢識別方法,給出了視頻手語識別和基于深度學習的視頻描述的策略分析。對使用原始視頻幀、視頻光流和目前先進的姿態估計技術等方法進行了比較,進而提出適用于中國手語視頻數據的多模態描述策略、訓練模型架構及時空注意力模型。使用具有深度信息輔助的視頻描述及訓練方法,通過實驗驗證BLEU-4值可達52.3,較前期使用的基礎方法提高約20%。但由于該方法所使用的深度信息在現實情況下并不容易獲得,因此研究由手機或電腦攝像頭獲取的普通RGB視頻的描述及識別方法是未來的發展方向。
手語識別; 視頻描述; 多模態
在基于視頻描述的手語識別領域,目前大多數的方法都是使用多模態方法,將原始視頻幀、光流和姿態估計結合在一起。與普通的Seq2Seq體系結構相比,使用注意力建模和遷移學習等技術能提供更好的性能,進而提高現有模型在本研究中的性能和準確性。
1 相關研究分析
1.1 視頻描述策略
文獻[1]研究了基于時間殘差網絡的手勢和手語識別,研究人員試圖在一個連續的大詞匯視頻流中設計手勢和手語識別模型。研究人員將此問題作為一個框架分類問題來處理,使用了深度學習的最新成果,如殘差網絡、批量標準化和指數線性單元(ELUS)等。文獻[2]基于深度學習的手語識別姿態估計方法進行研究,人體姿態估計和手部檢測是實現基于計算機視覺的手語識別(SLR)系統的兩項重要任務。然而,這兩項任務都具有挑戰性,尤其是當輸入是沒有深度信息的彩色視頻時。該方法也使用了RGB格式,而不是RGB-D,同時介紹了一種用于SLR的人體姿態估計的數據集。通過對數據集進行用戶獨立的實驗,評估了兩種基于深度學習的姿態估計方法的性能。另外還進行了遷移學習,得到的結果表明遷移學習可以提高姿態估計精度,但這只有當原始任務和目標任務之間的差異較小時才有效。
文獻[3]提出了一種用于視頻描述的多模態結構,該結構依靠記憶網絡和注意力機制。記憶網絡從二維CNN中捕捉長期的時間動態特征以幫助記憶長期的有效信息,注意力機制則有助于更為有效的提取和學習視覺概念及特征。此外,還引入了特征選擇算法來選擇相關特征。文獻[4]提出了一種針對視頻描述的多模態記憶建模,該模型建立了一個可視化的文本共享記憶模型,以模擬長期的視頻文本依賴關系,進一步指導全局注意力來描述目標。基本方法是通過與視頻和句子進行交互,通過多次讀寫操作,在存儲和檢索視覺和文本內容上附加額外的記憶。首先,將基于文本解碼的長短期記憶(LSTM)的文本表示寫入記憶,記憶內容將引導注意力模型選擇相關的視覺目標,然后將選定的視覺信息再寫入記憶,并將進一步讀出進行文本解碼。文獻[5]提出了用于多模態推理和匹配的雙重注意力網絡(DANs),它利用視覺和文本信息的聯合機制來捕獲視覺和語言之間的細粒度交互。它有兩個模型,r-DAN用于多模態推理,m-DAN用于多模態匹配,研究試圖在視覺問答工具中找到應用。文獻[6]將使用注意力模型的學習型多模態結構用于視頻描述。這種體系結構利用多模流和時間注意,在句子生成期間選擇性地關注特定元素。文獻[7]的主要工作是用于多模態推理和匹配的,研究人員使用3D CNN取代2D ConvNets以便在視頻圖案識別中取得更好的結果。
文獻[8]研究通過深度神經網絡的基于摘要的視頻描述,研究人員提供的架構類似于我們目前對手語視頻描述的研究,從CNN中提取視覺特征并將其輸入RNN。文獻提出了一種新穎的、設計良好的自動總結過程,該過程通過在句子序列圖上排序來減少噪音。該方法經過實驗驗證在視頻描述的語言生成度量和SVO準確率方面性能更好。文獻[9]中,研究人員嘗試設計一種可以調整時間注意的分層LSTM模型。具體地說,所提出的框架利用時間注意來選擇特定的框架來預測相關單詞,而調整后的時間注意則用來決定是依賴視覺信息還是語言上下文信息。此外,分層LSTM設計也同時考慮了底層視覺信息和高層語言上下文信息,以支持視頻描述生成。文獻[10]嘗試提出一種新的用于視頻表示及描述的層次遞歸神經編碼HRNE,研究人員使用分層LSTM,提出RGB數據集上的視頻描述模型。通過縮短輸入信息流的長度,并在更高的層次上合成多個連續的輸入,能夠在更大的范圍內有效地利用視頻時間結構。當輸入是非線性時,計算操作大大減少。實驗證明,研究人員的方法在視頻描述基準方面優于最新技術。值得注意的是,即使使用一個只有RGB流作為輸入的單一網絡,HRNE也擊敗了所有最近結合多個輸入的系統。文獻[11]同樣提出了一種使用多模態結構的視頻描述方法,研究人員使用原始視頻幀和光流圖像作為輸入以轉換為文本序列。該模型使用CNN提取特征,并將這些特征進一步輸入到LSTM層。
1.2 RGB-D場景下視頻理解所用的深度CNNs
1.2.1 從RGB-CNNs遷移學習文獻[12]用深度CNN對RGB-D場景進行識別。由于遷移學習沒能在訓練中提高多少準確率,因此研究人員嘗試尋找新的方法在小數據集上可以獲取更好的準確率。研究人員聲稱遷移學習幾乎不能到達底層,因此找到了另一種策略通過結合全局的圖像微調和弱監督訓練來訓練底層學習深度特征。文獻還提出了一種改進的CNN體系結構,以進一步匹配模型的復雜性和可用數據量。該模型在只有深度數據和RGB-D數據的情況下都達到了很高的精確度。
1.2.2 使用3D卷積神經網絡的手語識別文獻[13]嘗試使用3D CNN將手語轉化成文字。研究人員使用RGB-D數據集,為提高性能,研究人員將多通道的視頻流包括顏色信息、深度線索、身體關節位置等作為輸入到3D CNN,以整合顏色、深度和軌跡信息。該模型在用Microsoft Kinect收集的真實數據集上進行了驗證,并證明了其相對于傳統方法基于手語識別特征的有效性。
2 方法描述
目前與手語識別最貼近的領域是視頻描述生成 (Video Captioning),基本思想是將視頻和文本映射到同一語義空間或者兩者空間可以通過某種算法進行轉換。我們注意到目前手語視頻描述的模型不僅可以提高準確性,還可以使用更好的架構方法提高性能。通過對比研究上述文獻,我們的分析結果是:
(1)視頻描述問題有許多新的解決方法,其中包括新的特征提取方法,如輸入原始視頻、使用光流和姿態估計等。
(2)使用多模態結構結合所有這些特征將比單獨獲得這些特征會得到更好的效果。
(3)可以利用注意力模型和記憶模型從視頻中提取時間和視覺信息,以獲得比使用典型的ConvLSTM 架構更高的精度。
(4)使用3D CNN架構而不是使用帶有LSTM 的2D CNN可以獲得更好的結果。
(5)卷積Seq2Seq模型相對于傳統的Seq2Seq模型,速度更快并且性能更好。使用卷積Seq2Seq模型代替傳統版本,可以提高模型的性能,并且能更好的并行化網絡,這將提高我們研究的性能。
綜上所述,我們獲取原始視頻的多模態結構特征的具體步驟如下:
(1)用OpenPose、OpenFace及ArtTrack提取視頻中手語者的臉部、手型和身體姿態的關鍵圖片,結合手語語言學先驗知識形成圖像序列。我們提取了25個身體關節特征,如圖1(左)所示。這些標準化的骨骼關節坐標除了可以為后續圖像和骨骼處理做準備之外,還可使手語者與攝像機的距離不會成為特征提取的影響因素。除了身體關節,我們也可為每只手定位21個手指關節,并與身體關節一起正則化。之后通過預先訓練的ArtTrack模型生成了28×20×14維的特征圖,將身體及手部的正則表示形式轉化為圖像,并通過一個2×2的最大池層,將該特征映射扁平化到一個1×1680的特征向量中。這種矢量表示法使用卷積特征映射來預測不同的身體及手部關節位置,具有豐富的空間信息。由于手語動作過程中,面部表情也擁有不可忽視的表達作用,因此我們也提取了面部關鍵點和動作單元,其中面部關鍵點是由68個(x,y)坐標構成,而動作單元則是用于捕捉面部表情的關鍵信息,如抬起眉毛、撅起嘴巴、皺眉等,如圖1(右中)所示。在對身體、臉部、手指關節進行局部特征提取之后,我們還采用CNN卷積神經網絡對視頻幀提取全局特征,對視頻進行空間標注及對應文本的標注等,最后進行全連接多模融合。
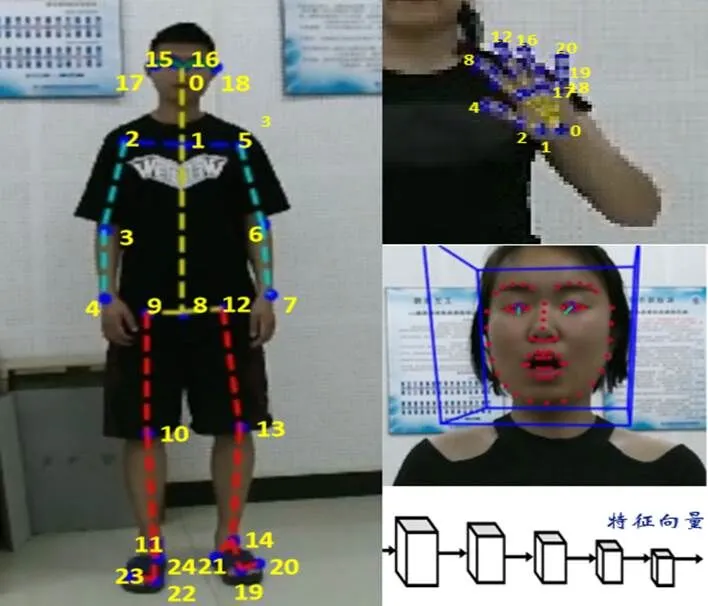
圖 1 手部、身體及臉部特征的提取
(2)將前兩步獲得的多模特征合并作為循環神經網絡的輸入,最終獲得相關的語素信息。在訓練階段采用了編碼-解碼的翻譯模式進行識別。在編碼階段,將特征提取獲取的特征向量通過分詞層預測單詞特征,即經過CNN和兩個LSTM連接最后通過HMM得到預測單詞的條件概率,通過兩個循環的RNN,最后輸出編碼后的單詞預測向量集合。在解碼階段,通過標志來表示手語語序的開始,并同編碼階段的最后一個隱藏特征向量一起進行RNN運算,然后再經過第二層RNN所得數據和編碼階段獲得的單詞特征預測向量集的加權一起,經過關注層的注意力模型運算,獲取的單詞預測概率向量經過全連接獲得最終的預測概率。根據上下文單詞關系依次翻譯出其他單詞的概率,最終解碼出所有單詞的概率(|),其中y=(1,2,…,y)是具有個詞的文本句子,=(1,2,…,x)是具有幀的手語視頻,h是解碼階段的初始隱藏矢量。
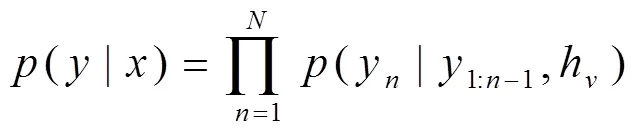
在這個過程中要進行模型選擇和超參數調節,由(|)的反饋不斷的調整編碼-解碼模型和多模特征提取,從而得到一個最優的神經網絡架構。同時通過最小化具有姿態特征P和學習參數的視頻的損失,優化了對數似然度,其中w是步驟中的單詞。

在手語圖像到語素信息、語素信息到文字信息的轉換過程中,我們將手語序列轉換為健聽人可以理解的自然語言。在特征提取的基礎上,通過HMM(隱式馬爾科夫鏈)迭代的將語素信息翻譯為正常文本。此過程將基于手語語言學,結合面部表情識別,融入音位、形態學、句法、手語習得、神經語言學等先驗知識,來有效提升手語識別效果。訓練模型架構[14]如圖2所示。
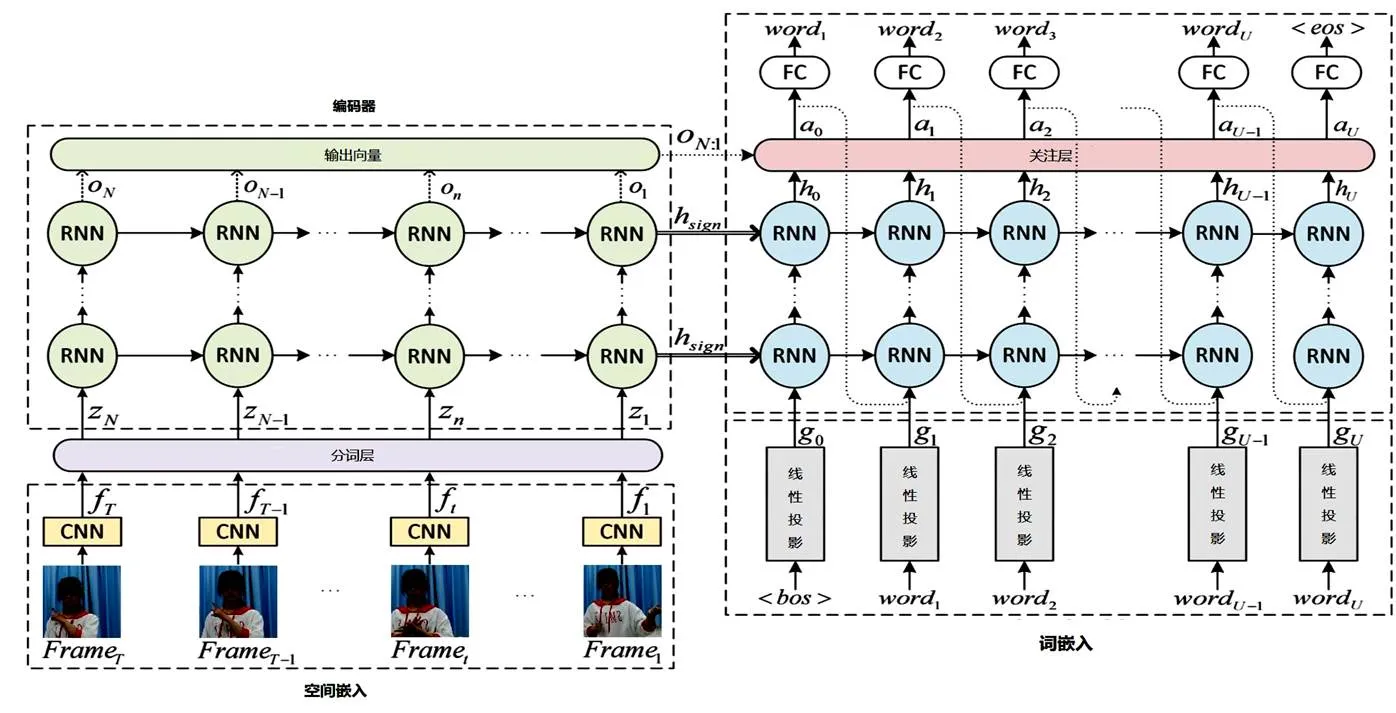
圖 2 模型架構
其中,關注層引入手部及面部表情的時空注意力模型以提升生成視頻注解的質量。訓練模型在Encode階段會在每個時間點生成一個詞語,而時刻生成的詞語取決于時刻?1生成的詞語和網絡中的隱藏狀態h?1。對于時刻,網絡的輸入為那一時刻的手勢動態特征向量z。令a,=1,...,為時刻從圖像的區域提取的注解信息。對于每個a,需計算權重α,即在生成z的過程中a應該被賦予的權重,該值為正數。使用全連接神經網絡f來計算α。如公式(1)和(2)。
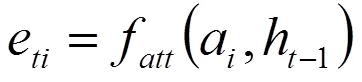
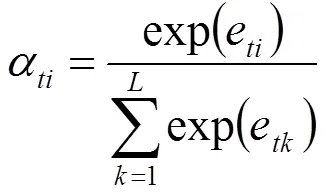
當所有權重全部計算完之后,z由公式(3)得出:
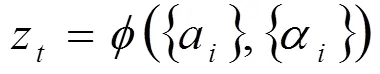
這里需使用神經網絡來學習函數。由于手語句子長度的變化,設計這種注意力模型的參數版本,可使模型處理不同長度的輸入,即模型重點關注的位置不再固定,而取決于已生成的詞語序列。
3 討論
訓練時的輸入為視頻序列和相應的標注文本對。測試期間,將來自測試視頻的幀編碼輸入到經過訓練的神經網絡中,一旦所有幀被處理,當句子開始關鍵字輸入到網絡,即會觸發單詞的生成直到出現句子結束關鍵字。我們使用文獻[15]所建立的句子級連續手語數據集進行特征提取和模型訓練。
一般在進行測試集的選取時,主要采取留出法、交叉驗證法及自助法三種[16]。留出法通常將約2/3的數據用于訓練,其他作為測試,兩集合不相交,即=∪,∩=,其中為全部數據,為訓練集,為測試集;交叉驗證法相當于是多組留出法測試結果的均值,即先將劃分為個大小相似且互斥的子集,=1∪2∪…∪D,D∩D=(≠),然后每次取-1個子集作為訓練集,剩下的一個作為測試集,從而獲得組測試結果,最后返回其均值;在上述兩種方法中,由于保留了一部分數據用于測試,導致訓練用數據少于全部數據,這有可能會讓訓練集的規模影響成為引起模型估計偏差的主要因素之一。自助法是一種比較好的解決方案,即從數據集中選取訓練數據時,當前被選取的數據并不從中移走,而下次選取時仍有可能被選到,使得中有一部分數據會在訓練集中出現多次,而同時也有一部分數據不會出現在訓練集中,這種方法在數據集較小且難以有效劃分訓練和測試集時是很有用的。
我們在實驗中對于訓練集和測試集的選取類似于自助法,且鑒于文獻[15]給出的討論,我們篩選了重復率在10次以上的包含2240個句子的集合A和隨機選取了重復率未達到10次的3000個句子的集合B進行對比訓練和分析。兩組訓練模型均使用相同的測試集,該集合共包含450個句子,為上述兩個訓練集混合后的隨機選取,即450個句子中每句來自集合A或集合B的概率相同。所有視頻均進行每240幀的等距采樣,然后利用本文第二部分的方法從每幀中提取手部骨骼、面部和姿態特征。我們使用jieba分詞工具來標記視頻對應的文本句子,并使用BLEU分數來評估預測文本和真實文本之間的性能,結果如表1和表2所示。其中BLEU-表示個字詞連續的預測效果,值越高表示預測結果與真實文本的相似程度越高,即識別的越準確。
可見我們將手部骨骼、身體矢量和面部等多模特征結合起來的預測效果較單模特征識別在手語的語法、語義理解等方面可以滿足更好識別效果的需求。因為就手語而言,只有手勢或身體姿態的識別是不能全面體現手語表達的,而手語者的面部表情信息占了語義理解的很大一部分空間。同時,從實驗結果中我們還分析得出,集合A可作為測試模型的快速檢測集合,因為其中的句子重復率使得手語詞匯的重復率基本達到了50次[15],致使這部分詞匯的預測效果要遠好于其他詞匯,從而可作為測試模型是否能夠過擬合的快速檢驗方法。而集合B可用于估計整個數據集上的訓練模型性能,因為數據集中仍有較大比例的句子是不滿足重復率要求的,使用集合B則更能體現數據集整體所提供的預測訓練效果。結果表明,雖然使用我們的多模特征視頻描述方法可在一定程度上提高手語視頻的識別效果,但仍然需要有重復率更高、質量更好的數據集作為支撐,只有重復率達到一定要求的句子,其訓練效果才可基本滿足識別要求。在后面的工作中我們需進一步擴充樣本數量,提高數據樣本的重復率和錄制質量,如保證視頻畫面的穩定性、提供已標注的對齊的RGB視頻和深度視頻、增加錄制環境的多樣性以提供復雜場景下手語識別的普適度等等。

表 1 BLEU分值

表 2 識別效果
4 結論
基于視頻描述的手語識別是一個多學科交叉的研究課題,既要懂計算機科學,還要懂手語語言學。而且手語識別與傳統語言識別有著本質差異。傳統語言的識別和翻譯建立在單模態基礎上的,而手語識別是基于多模態的,以空間計算為主。由于手語的手部形狀、位置和方向、頭部動作、面部表情及軀干姿勢等這些信息都包含語言學意義上必不可少的內容,因此手語識別需要將手語詞法、句法和語用等概念貫穿在空間建模、隱喻、語義等視頻描述、模型訓練的各個階段。目前由于聾人和聽人在交流過程中對攜帶設備的抵觸心理及設備本身的不易攜帶性,均導致由深度手語數據輔助的視頻描述和識別變得不利于廣泛應用。因此,團隊正在努力實現利用手機攝像頭收集和識別不帶有深度信息的普通RGB視頻,現已開始數據收集階段。
手語識別技術的研究將極大地促進具有自主知識產權的服務于聽障人的軟件系統的研發,符合國家在殘疾人保障及精準扶貧等各方面的政策。同時,計算機視覺是政府各部門大力支持的研究方向,將該技術運用到幫扶聽障人方面將極具先進性,也是殘聯和地方政府著力發展的領域,有廣闊的應用前景,對促進聽障人無障礙融入社會、提升聽障人就業水平等方面具有非常重要的意義。
[1]Pigou L, Van Herreweghe M, Dambre J. Gesture and sign language recognition with temporal residual networks [C]//International Conference on Computer Vision Workshop (ICCVW). Venice Italy: IEEE, 2017:3085-3093
[2]Gattupalli S, Ghaderi A, Athitsos V. Evaluation of deep learning based pose estimation for sign language recognition [C]//Proceedings of the 9th ACM International Conference on PErvasive Technologies Related to Assistive Environments (PETRA). Corfu, Island, Greece: ACM Press the 9thInternational Conference, 2016
[3]Fang XZ, Li W, GuoDS. Multimodal architecture for video captioning with memory networks and an attention mechanism [J]. Pattern Recognition Letters, 2018,105(1):23-29
[4]WangJB, WangW, HuangY,. Multimodal memory modelling for video captioning [C]//CVF Conference on Computer Vision AND pattern Recongnition. Salt Lake City, US: IEEE, 2016
[5]Nam H, Ha JW, Kim J. Dual attention networks for multimodal reasoning and matching [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017,:299-307
[6]Xu J, Yao T, Zhang YD,. Learning multimodal attention LSTM networks for video captioning [C]//Proceedings of ACM on Multimedia Conference. California: ACM, 2018
[7]Patnaik K, Siyari P, Krishnan V,. Learning hand features for sign language recognition [N/OL]. https://github.com/payamsiyari/GT-Deep-Learning-for-Sign-Language-Recognition/blob/master/Report.pdf.
[8]Li G, Ma SB, Han YH. Summarization-based Video Caption via Deep Neural Networks [C]. Proceedings of the 23rd ACM international conference on multimedia.Brisbane:ACM, 2015
[9]Song JK, Guo Z, Gao LL,. Hierarchical LSTM with adjusted temporal attention for video captioning [C]. 26th International Joint Conference on Artificial Intelligence. Melbourne:IEEE,2017
[10]Pan PB, Xu ZW, Yang Y,. Hierarchical recurrent neural encoder for video representation with application to captioning [C]. IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016
[11]Venugopal S, Rohrbach M, Donahue J,. Sequence to sequence video to text [C]. International Conference on Computer Vision. Santiago: IEEE, 2015
[12]SongXH, HerranzL, JiangS. Depth CNNs for RGB-D scene recognition: learning from scratch better than transferring from RGB-CNNs [C]. The 32ndAAAI Conference on Artificial Intelligence. New Orleans: IEEE, 2018
[13]HuangJ, ZhouWG, LiHQ,. Sign language recognition using 3d convolutional neural networks [C]. International Conference on Multimedia and Expo. Torino: IEEE, 2015
[14]Camgoz NC, Had?eld S, Koller O,. Neural Sign Language Translation [C]. IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018
[15]袁甜甜,趙偉,楊學,等.大規模中國連續手語數據集的創建與分析[J].計算機工程與應用,2019,55(11):110-116
[16]周志華.機器學習[M].北京:清華大學出版社,2016
Chinese Sign Language Recognition Based on Multimodal Video Captioning
YUAN Tian-tian, YANG Xue
300384,
Computer vision is an important direction in the development of new generation Artificial Intelligence technology in our country at present. Because of its difficulties in continuity and complex scene interference, the research of sign language recognition can not only solve the real needs of deaf people for barrier-free information communication, but also greatly promote the rapid development of video understanding and analysis, so it has a good landing application in security, intelligent monitoring and so on. By comparing many gesture recognition methods based on video description and analysis, the strategies of sign language recognition and video description based on depth learning are given. The methods of using original video frame, video optical stream and advanced attitude estimation technology are compared, and then a multi-modal description strategy suitable for Chinese sign language video is proposed, and the training model architecture and attention model are proposed. Using the video description and training method assisted by depth information, the experimental results show that the BLEU- 4 value can reach 52.3, which is about 20% higher than that of the baseline method. However, because the depth information used in this method is not easy to obtain in reality, it is the future direction to study the description and recognition method of ordinary RGB video obtained by mobile phone or computer camera.
Sign language recognition; video captioning; multimode
TP387
A
1000-2324(2021)01-0143-06
10.3969/j.issn.1000-2324.2021.01.025
2019-08-11
2019-10-24
天津市工業企業發展專項資金項目(201807111)
袁甜甜(1980-),女,博士,副教授,主要從事機器學習、深度學習、聾人高等教育等工作. E-mail:yuantt2013@126.com
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
