基于語義識別的自動化家寬報裝地址稽核方法
2021-04-03 07:47:15許學研湯斯鵬池鴻源
現代信息科技 2021年19期
許學研 湯斯鵬 池鴻源


摘? 要:受到報裝關鍵詞匹配程度的影響,對于報裝地址的稽核智能化處理存在不足。基于此,提出了基于語義識別的自動化家寬報裝地址稽核方法。通過構建語義識別自動化模型,獲取到家寬報裝地址的識別概率分類;改進清查寬帶資源方式,明確報裝小區的單元信息與寬帶資源能力;基于語義識別算法計算泛化相似詞,實現自動化家寬報裝地址的稽核目標。實驗證明,該稽核方法隨著寬帶網絡節點通信半徑的不斷增加,地址稽核的分配成功率更高。
關鍵詞:語義識別;自動化;家寬;報裝;地址;稽核
中圖分類號:TP391.4? ? ? ? ? ? ? ? ?文獻標識碼:A文章編號:2096-4706(2021)19-0151-03
Automatic Home Broadband Reported Installation Address Audit Method Based on Semantic Recognition
XU Xueyan, TANG Sipeng, CHI Hongyuan
(AI Application and Innovation Center of China Mobile Communications Group Guangdong Co., Ltd., Shantou? 515041, China)
Abstract: Affected by the matching degree of reported installation keywords, there are deficiencies in the audit intelligent processing of reported installation addresses. Based on this, an automatic home broadband reported installation address audit method based on semantic recognition is proposed. By constructing the semantic recognition automatic model, the recognition probability classification of home broadband reported installation address is obtained; improve the way of checking broadband resources, and clarify the unit information and broadband resource capability of the reported installation community; based on the semantic recognition algorithm, the generalized similar words are calculated to realize the audit goal of automatic home broadband reported installation address. Experiments show that with the increasing communication radius of broadband network nodes, the allocation success rate of address audit is higher and higher.
Keywords: semantic recognition; automation; home broadband; apply for installation; address; audit
0? 引? 言
家裝寬帶的報裝地址稽核方法是滿足用戶需求的重要渠道,由自動化家寬報裝人員建立的安裝服務工作的重要載體。傳統的地址稽核模式,稽核結果的形式存在一定的差異,受到稽核人員與報裝業務種類的影響,對于自動化家寬報裝地址的稽核具有一定的不可控性[1]。在稽核家寬地址時,受到報裝關鍵詞匹配程度的影響,對于報裝地址的稽核智能化處理存在不足[2]。語義識別處理技術通過自動判定家寬報裝地址,對于地址進行智能化分析處理,基于統一化標準要求,實現集人工與智能相協調的稽核檢查方案[3]。采用同義詞相似度計算的方式,將家寬報裝地址的關鍵詞與標準要求中的關鍵詞進行相似度類比。語義識別技術可以實現關鍵詞語義相似度計算與識別的目標。在語義識別的自動化家寬報裝地址的稽核中,通過片段模式分級,逐級分解網絡地址的結構,通過邊界識別與地址分類,使地名與網絡結構的名稱識別F1值達到總體識別結果的95%以上。在稽核過程中,語義識別的自動化稽核方法屬于垂直行業屬性,以龐大的網絡工單為稽核對象,以工單的文字內容進行特征性關鍵詞提取,基于語義自動化識別與語義泛化技術,輸出地址稽核的相似程度與工單的合規置信度數值,智能化識別升級家裝寬帶的報裝地址,完善傳統稽核方法關鍵詞識別方面的不足。
綜上所示,本文提出了基于語義識別的自動化家寬報裝地址稽核方法,基于相似度算法與語義識別算法,構建集自動化與智能化融合的關鍵詞識別機制,實現報裝地址的快速稽核目標。
1? 基于語義識別的自動化家寬報裝地址稽核方法設計
1.1? 構建語義識別自動化模型
在設計語義識別的自動化家寬報裝地址稽核方法中,首先,本文采用了語義識別分詞工具,自動化分詞處理基礎關鍵詞,綜合大量的工單數據,選擇深度gram神經網絡進行關鍵詞的向量訓練。在選用分詞工具時,綜合考慮相似度的距離與CRF算法,進行報裝地址的關鍵語義信息自動化識別。
根據報裝地址工單的標準化內容規定,明確稽核方法的主要關注目標,以及對于稽核處理結果的滿意程度與回訪結果。在稽核中,工作人員填寫的處理本文,利用自動化稽核原則,對家寬地址的特征詞進行標注,要求關鍵詞與特征詞涵蓋語義識別的全部特征。
隨機篩選報裝地址的EOMS訓練語料,通過分詞軟件對報裝地址的關鍵詞進行分詞預處理,將自動化家寬報裝地址語句分解為多個單詞的形式。統一化處理關鍵詞詞頻,獲取到報裝地址語料的關鍵詞出現次數。篩選出語料中的所有頻率較低的單詞,保留頻率較高單詞,綜合處理合并為訓練語料語義分析模型。在模型中加入相似度計算文本[4],建立在語義層次上方,計算寬帶報裝地址關鍵詞的相似程度,構建語義識別自動化模型主要依據word2Vec算法,word2Vec算法是神經網絡算法中的一種,包含輸入層、報裝地址稽核隱藏層與識別結果輸出層。模型通過預測識別結果的關鍵詞與搜索詞,在當前提示詞的指引下,完成家寬報裝地址的具體預測識別。
在家寬報裝地址的數據信息量較少時,以向量模型的訓練詞為構建的核心內容;在數據信息量較多時,使用CBOW模型原則的訓練詞作為模型的主導向量,基于識別模型的工單原始數據處理經驗,選擇適當的訓練詞構建模型。分批次地劃分模型的迭代過程,在語義識別自動化模型的基礎上,進行模型的自適應度訓練。設置取詞窗口的預測數據為k,則識別關鍵詞訓練的單詞為Wt,設置模型的整體結構中存在一定數量的關鍵詞,家寬報裝地址的一維向量隨之改變,將訓練模型中所有向量輸入到模型中。關鍵詞經過模型中的隱藏層,優化分解處理后流經輸出層。
在報裝地址的稽核預測時,自動化識別模型的隱藏層向量與輸出層的權重,經過語義識別軟件的變換作用,最終獲取到家寬報裝地址的識別概率分類。
1.2? 改進清查寬帶資源方式
基于上述構建的語義識別自動化模型,獲取到家寬報裝地址的識別概率分類,進行寬帶資源的清查工作。傳統的寬帶清查方法主要以人工清查方式為主[5],在實施過程中具有一定的限制性。本文設計的清查寬帶方法以實現自動化清查為核心目標,改善傳統清查資源方法的不足。
創建用戶的級別標準地址,建立寬帶資源數據庫腳本,利用關鍵詞搜索分析方法拆分寬帶安裝的標準地址。根據寬帶地址的省市清查人員統一整理數據,明確無規定地址要求,提交給具體的省份地址維護人員,寬帶資源清查人員進行統一的稽核驗證入庫,將拆分好的寬帶地址進行綜合擴展,將級數擴展到具體的數據層次。控制家寬報裝地址的自動集成設備,建立設備與具體安裝地址的綁定關系。建立統一標準的報裝地址庫,如圖1所示。
圖1? 統一標準的家寬報裝地址庫結構
如圖1所示,依據家寬地址標準分級,建立報裝地址標準化清洗數據庫,通過地址分級標準模型,采集報裝地址庫模板,定期稽核家寬報裝地址的準確性,按照一定的計劃要求,分批次地完成報裝地址由清洗庫到正式地址庫的轉變。利用BSS/CBSS資源管理方式,接入集成設備,改進寬帶地址管理的配套方式。基于搜索引擎庫,創建全新的索引與報裝地址字段,將所有用戶的報裝地址數據錄入到搜索引擎庫中,實現統一標準化的自動化家寬報裝地址庫的數據錄入工作。
依靠地圖搜索定位指定報裝地址的小區信息,根據地圖的定點選擇網址,匹配到報裝小區的網格,通過網格獲取小區的具體名稱與數據。再將網格小區的具體名稱輸入到搜索引擎庫中,定位具體的樓棟單元信息,連接資源能力信息接口,獲取樓棟單元寬帶的準確資源信息。
改進清查寬帶資源的方式,能夠有效地提高寬帶安裝業務辦理流程的簡便性,減少報裝地址輸入查詢消耗的時間。通過標準統一的報裝地址庫,自動匹配報裝地址的結果,不需要輸入完整復雜的地址,輸入關鍵詞即可快速地定位報裝小區的樓棟單元信息與寬帶資源能力。
1.3? 基于語義識別算法計算泛化相似詞
通過改進清查寬帶資源的方式,獲取到報裝地址小區樓棟單元的準確寬帶資源信息,利用訓練語句得到的單詞向量,結合語義識別算法[6],計算家寬報裝地址中的泛化相似詞。設置泛化相似詞的向量為A和B,向量A是[A1,A2,…,An],B是[B1,B2,…,Bn],余弦相似度計算公式為:
(1)
其中,n表示相似度常數;i表示稽核地址關鍵詞分類,對于所有的稽核地址關鍵詞來說,計算與報裝地址庫相關的自動識別相似度,根據余弦進行排序,得到若干個關鍵字單詞,作為泛化相似詞。以ZigBee網絡路由算法為基礎,設定寬帶協調器與路由節點的最大數量,計算分配報裝地址的空間,定義地址的偏移量函數。將本文構建的語義識別自動化模型中的節點進行網絡地址分配,使得所有節點將地址模塊平均分配[7]。設置最大子節點數為Cmax;接入節點數為Rmax;寬帶網絡最大深度為Lmax,寬帶網絡地址空間的計算公式為:
Cmax(d)=1+Cmax×(Lmax-d-1)? ? ? ? ? (2)
式中,d表示網絡通信節點的深度,如果寬帶網絡節點的計算結果為0時,表明網絡寬帶通信地址在空間上沒有產生偏移量,能夠作為寬帶報裝的地址塊。如果計算結果大于0時,表明其能夠作為寬帶報裝子節點接入互聯網并進行報裝地址分配。
基于語義識別算法計算泛化相似詞能夠保證地址模塊的均勻分配,適用于家寬報裝以及其他的自組織網絡,能夠在分配地址范圍內連續分配寬帶報裝地址空間。設計算法的偽代碼為:
def LFM(user_items, F, N, alpha, lambda):
#初始化P矩陣
P = InitModel(user_items, F)
#開始迭代
For step in range(0, N):
#從數據集中依次取出user以及該user喜歡的iterms集
for user, items in user_item.iterms():
#隨機抽樣,為user抽取與items數量相當的負樣本,并將正負樣本合并,用于優化計算
samples = RandSelectNegativeSamples(items)
#依次獲取item和user對該item的興趣度
for item, rui in samples.items():
#根據當前參數計算誤差
eui = eui - Predict(user, item)
#優化參數
for f in range(0, F):
P[user][f] += alpha * (eui * Q[f][item] - lambda * P[user][f])
#當優化到一定程度后,就需要放慢學習速率,慢慢地接近最優值。
2? 實驗分析
2.1? 實驗準備
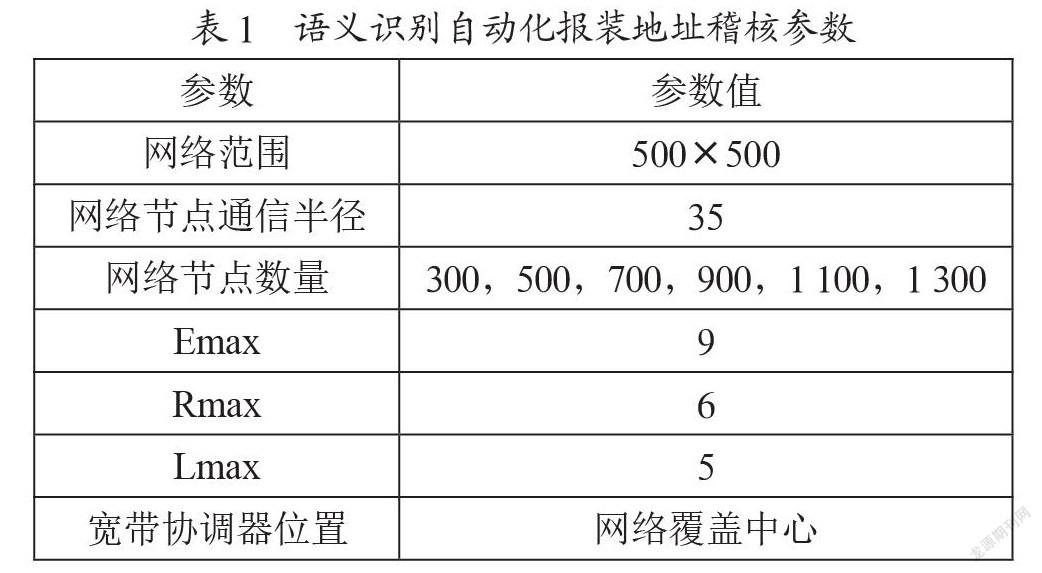
為了驗證本文提出的基于語義識別的自動化家寬報裝稽核方法的有效性,本文進行了如下實驗,通過稽核報裝地址的自動測試,檢驗語義識別自動化稽核結果的準確率與工單重派率指標。本次實驗選取遼寧省某EOMS無線寬帶網絡企業,采集2 000張報裝工單作為實驗的驗證集,報裝工單中需包含語義識別的結構化字段。保證實驗的驗證集來源的可靠性,使構建的模型能夠適應不同報裝地址的環境條件,實現報裝地址的廣泛覆蓋要求。設置寬帶網絡的覆蓋面積為500 m×500 m,在覆蓋范圍內網絡節點具有不同的密度,設置N個網絡節點隨機分布在報裝地址小區中,保證每個報裝地址環境中具有一個寬帶安裝協調器,并處于網絡覆蓋中心位置,固定語義識別自動化模型的網絡深度為8,在網絡節點通信半徑與其他參數條件不變的情況下,觀察通信網絡節點數量對寬帶安裝地址分配的影響。連續進行50次語義識別的自動化地址稽核實驗,取實驗結果的平均值作為稽核結果的實驗參數,如表1所示。
2.2? 結果分析
設置本文提出的基于語義識別的自動化家寬報裝地址稽核方法為實驗組,傳統的神經網絡地址稽核方法為對照組,對比兩種稽核方法的分配成功率結果,如圖2所示。
如圖2所示,隨著寬帶網絡節點數量的不斷增加,本文提出的自動化家寬報裝地址稽核方法的地址分配成功率上升的速度更快,寬帶節點的數量與寬帶節點通信半徑呈正相關變化,較傳統的地址稽核方法相比,地址分配成功率更加具有優勢。
3? 結? 論
本文提出的基于語義識別的自動化家寬報裝稽核方法,避免網絡寬帶安裝過程中產生孤立節點,促進報裝地址分配得更加靈活。傳統的地址稽核方法受到寬帶網絡節點不確定性的影響,在報裝地址稽核中消耗了大量的時間精力。本文提出的稽核方法,經過實驗證明,在寬帶網絡節點通信半徑的不斷增加下,家寬報裝地址的分配成功率更高,有效地提高了地址稽核的效率與成功率。然而,由于研究時間有限,本文提出的稽核方法在具體的實施過程中仍然存在一定的不足,在未來的研究中應當加以改進。
參考文獻:
[1] 黃堃,趙東明.電信運營商網絡投訴工單智能語義稽核技術 [J].電信工程技術與標準化,2021,34(7):45-49.
[2] 韋芹余.IP地址精細化管理系統建設方案研究 [J].江蘇通信,2021,37(2):63-65.
[3] 李汶澍.基于微信公眾號的家庭寬帶智能裝機助手 [J].通信世界,2021(4):37-39.
[4] 田兆豐,王歌吟.基于ElasticSearch智能搜索引擎的寬帶線上選址平臺的設計與實現 [J].通信與信息技術,2020(4):28+33+24.
[5] 王小峰.家庭寬帶光纖接入技術應用與實現 [J].中國新通信,2019,21(6):96-97.
[6] 李鐵堅.基于GIS的電信網絡資源的標準地址快速上圖方法研究 [J].通信電源技術,2019,36(2):211-212.
[7] 陶軼,許錫明,房志輝,等.運營商基于QoE的家庭寬帶指標感知體系 [J].現代電信科技,2017,47(4):68-73+78.
作者簡介:許學研(1985.04—),男,漢族,廣東汕頭人,工程師,碩士研究生,研究方向:大數據建模、數據挖掘、人工智能算法建模。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
