面向海量星表數據的高效的時序數據生成方法研究
2021-04-15 03:47:54熊聰聰付立艷
計算機應用與軟件 2021年4期
熊聰聰 付立艷 趙 青
(天津科技大學人工智能學院 天津 300457)
0 引 言
時序數據生成是天文學家進行天體時域分析的基礎,所謂時序數據生成是將來自不同拍攝時間、不同星表中數據,通過交叉證認方法對確定為同一星體的數據,按照時間順序排序生成每個天體時間序列數據[1]的過程。
時序數據的生成的難點主要包括兩點:(1) 隨著時域觀測設備的發展,數據的采集能力越來越強,具有在時間軸上頻繁采樣的特點,這導致數據量巨大[2]。如南極AST3望遠鏡,其每天數據采集量高達360 GB。再如興建中的寬視場瞬變源巡天設備地面廣角相機陣[3](GWAC),每15 s產生1.1 GB數據,每個觀測夜入庫僅星表數據高達2 TB。面對龐大的數據量,高效的時序數據生成方法成為難點,數據的存儲、查詢、證認計算等方面均需要優化設計[4]。(2) 時序數據生成需要對時間軸上每兩次觀測的數據進行證認計算,計算量高于普通天體交叉證認計算。為了實現大規模星表的交叉證認,高丹[5]提出了基于HTM索引和kd-tree的交叉證認方法,文獻[6-7]針對漏源問題,采用基于HTM和HEALPix兩種分區的混合證認計算算法,Zhao等[8-9]提出了基于MPI的多核并行交叉證認算法,通過基于位運算的快速相鄰塊編碼推導算法高效地取得誤差半徑范圍內全部需證認數據,解決了邊緣漏源問題,但仍然無法滿足批量多星表間的證認需求。徐洋等[10-11]提出基于等經緯分區二維空間網格的方法,萬萌等[12]采用列存儲內存數據庫MonetDB提高數據訪問性能,在關系型數據庫方法中取得了較好的效率。徐洋等在面向GWAC的小天區數據上實現了實時交叉證認,實時性良好,但仍難以解決千萬條以上星表數據的證認問題。趙青等[13]實現了海量數據的并行天文交叉證認,但時序數據生成的過程中的交叉證認計算不同于傳統多波段交叉證認計算,需要對時間軸上每兩次觀測的數據進行證認計算,計算量增加[5],效率要求更高。因此,在數據預處理、分布式算法設計等方面需要更精準的優化。
綜合以上問題,本文提出一種面向海量星表數據的高效的時序數據生成方法ETSDGM(Efficient Time Series Data Generation Method),其整體的設計框架圖如圖1所示。
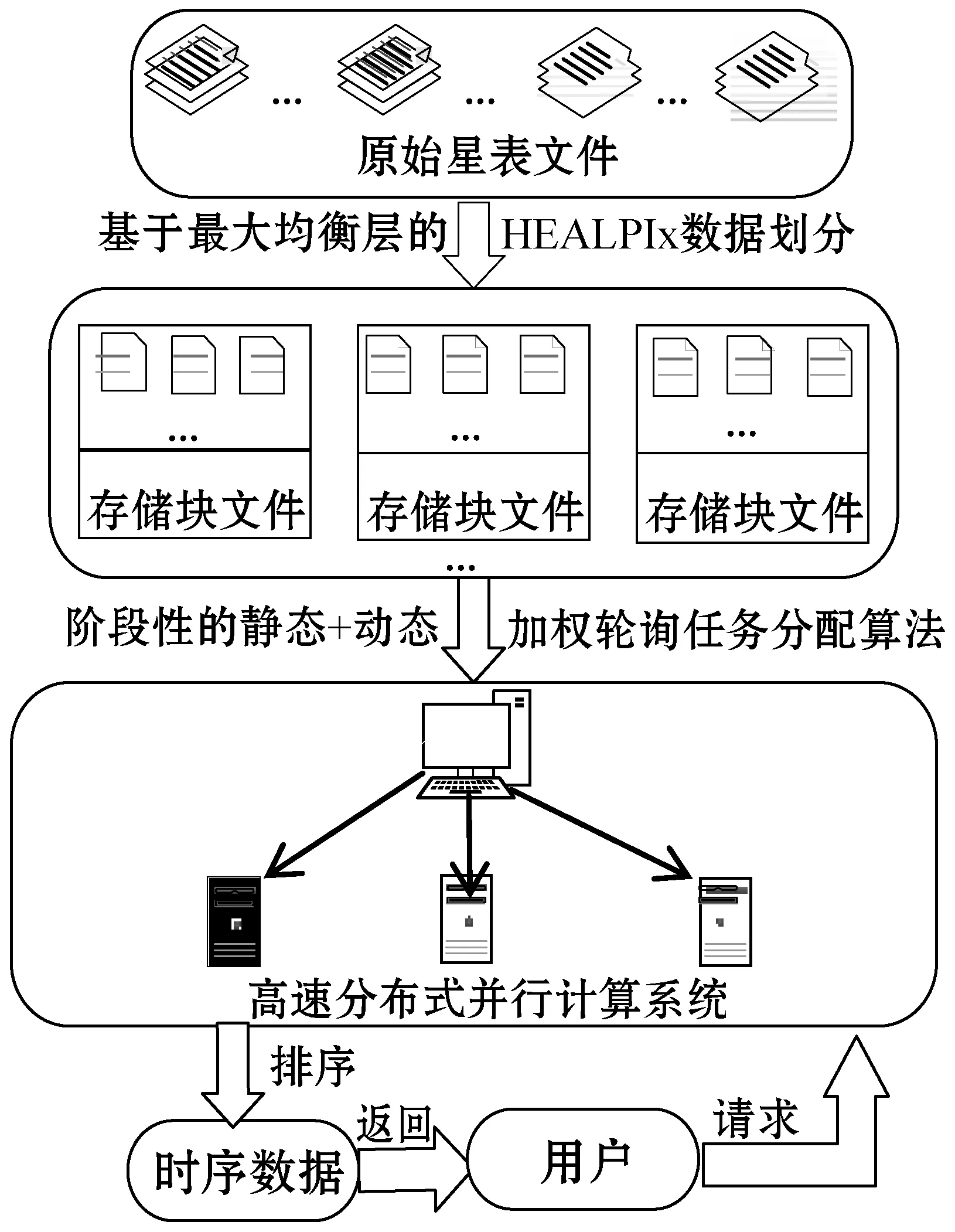
圖1 ETSDGM整體的框架圖
本文方法的設計重點分為兩個階段:
第一階段為預處理期間的訪存優化設計,重點在于基于“最大均衡層”的HEALPix數據劃分[14-15]以及分布式系統中的階段性“靜態+動態”加權輪詢任務分配算法的設計。預處理階段的設計保證索引的均衡性,實現數據的快速定位和集群中各節點負載均衡性以及節點的高度并發性,為后續實現快速證認計算提供一定的支持。
第二階段為證認計算算法優化,包括HEALPix數據過濾策略以縮減證認數據的范圍和基于傳輸與計算重疊的邊緣數據處理方法,以減少數據通信耗時。圖2為ETSDGM整體的設計內容及意義。
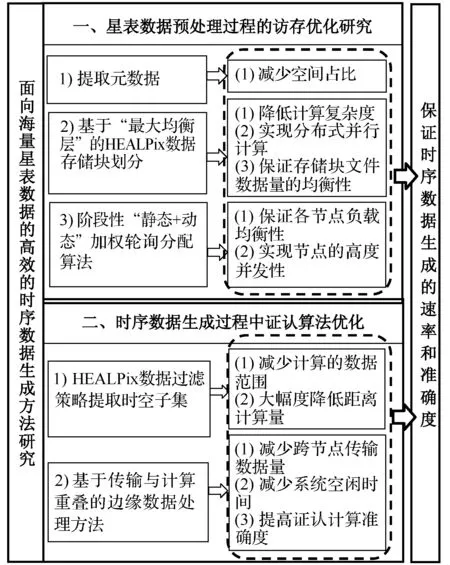
圖2 ETSDGM整體的設計內容及意義
1 原始星表數據預處理階段的訪存優化研究
在海量的天文數據面前,當只有數據的一個子集對天文學家的特定研究工作真正有用時,處理整個數據既耗時又浪費空間。通過訪存優化,快速提取時空子集,為實現指定區域高效時序生成條件。圖3給出了此階段的整體步驟。原始星表文件中每一行代表一個星體,提取證認計算需要的幾列信息定義一個適合生成時序數據的元數據文件格式。
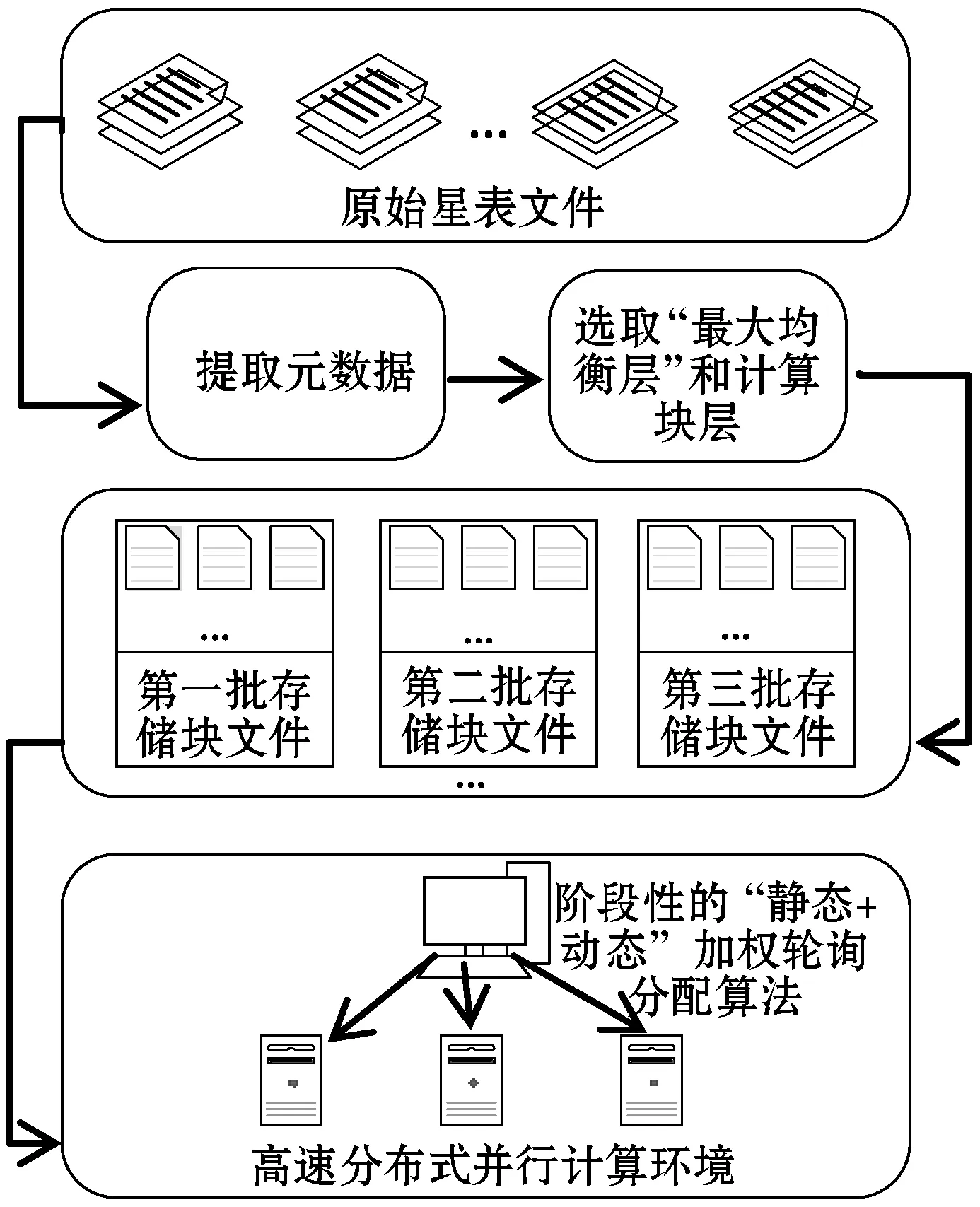
圖3 原始星表文件的預處理過程
1.1 基于“最大均衡層”的HEALPix數據劃分策略
基于“最大均衡層”的HEALPix數據劃分方法,保證索引的均衡性,從而實現時空數據的快速提取。數據劃分將原本復雜度為N×N的證認計算,通過分塊將其局限在同一位置分塊內,降低了算法復雜度;同時實現分布式并行計算,充分利用集群高性價比的存儲和計算能力,提高證認計算的效率,當用戶請求特定的時空范圍內的時序重構數據時,合理的分塊布局可以使集群中的各個計算節點負載均衡地提供所需的數據查詢、證認計算服務。
選擇HEALPix[16]偽球面索引方式,HEALPix在不同層級(Nside)下的網格劃分圖如圖4所示。其具有層次化結構、等面積劃分、等緯度分布的特點。初始層級被劃分為12個面積相等的基準球面四邊形,后續層級在此層級上進行遞歸四等分。
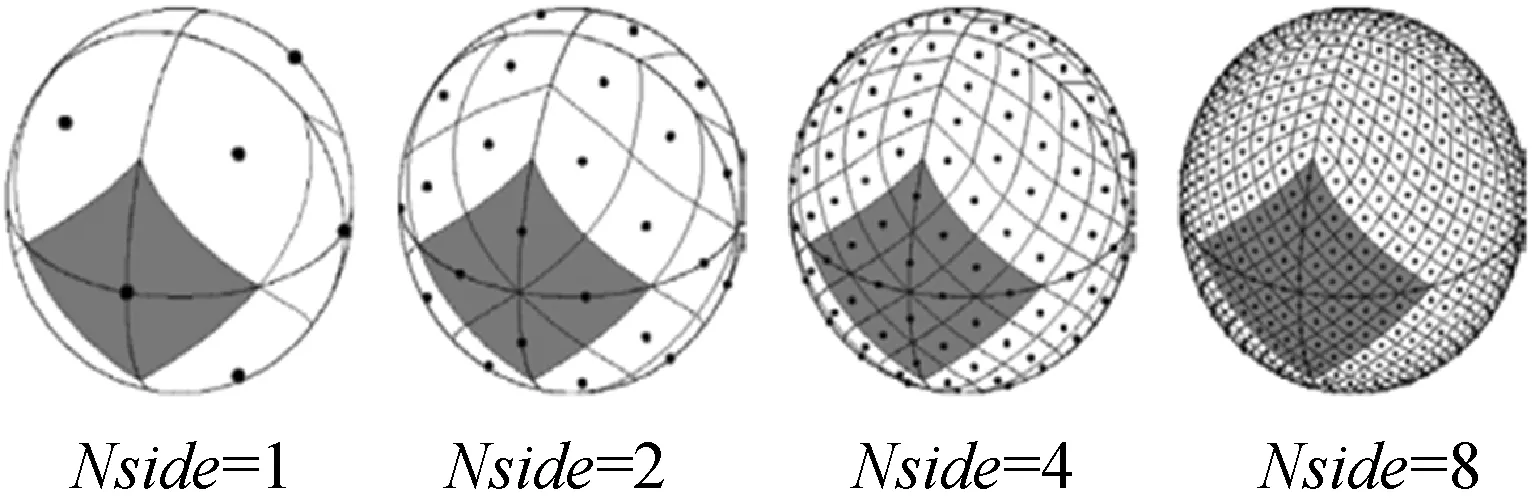
圖4 HEALPix天球分區示意圖
HEALPix索引方式的劃分具有等面積性,考慮到星體數據分布不均勻,即在同一層級中有些編碼塊中星體數據量很大,有些則很小,容易導致索引結構失衡,進而使查詢效率低下[17]。為了解決這一問題,本文采用“最大均衡層”下的HEALPix數據劃分策略,保證每個存儲塊文件中數據量盡可能均衡。具體的計算方法如下:
(1) 計算不同層級k下的包含數據的總塊數n以及相同HEALPix編碼的星體個數Xi(即每塊星體數,i=1,2,…,n)。
(3) 計算每層中HEALPix編碼個數的標準差SK:
(4) 根據平均值和標準差計算變異系數CVK,CVK最小的為最大均衡層:
1.2 階段性“靜態+動態”加權輪詢任務分配算法
原始星表文件經過預處理之后,需要利用分布式計算來提高時序數據的生成性能。天文星表數據量往往達到了TB甚至PB級,交叉證認計算屬于典型的數據密集型計算任務。這里數據量分配的多少直接決定任務量。
為了保證分布式系統中各節點任務量均衡性。采用加權輪詢任務分配算法。該算法根據服務器的不同處理能力為之分配不同權值,使其能夠接受相應權值數的服務請求,但由于該算法是一種靜態平衡算法,需要人為設置權值,難以反應服務器的實時性能,這導致負載不均衡。但如果采用純動態輪詢分配方法,每次分配后都計算當前負載,時間消耗較大,效率不高,考慮到集群節點的異構情況以及應用的實際情況,提出一種階段性“靜態+動態”加權輪詢算法。即在階段內采用“靜態”輪詢的思想,階段與階段之前引入“動態”性,修改各節點權值,增強算法對集群當前狀態的適應性。
1.2.1算法思想
(1) 根據實際的情況找初始化到各節點的初始權值SWi。
(2) 根據初始權重SWi對第一批存儲塊文件進行靜態輪詢分配。
(3) 當第一批存儲塊文件執行完成時,計算當前節點的實時剩余性能率Wi。
(4) 計算每個階段完成后的實時權值WWi。
(5) 根據實時權值,對下一批存儲塊的數據進行靜態分配,重復以上步驟,直到數據分配完成。
1.2.2算法具體過程
1) 初始權重的計算。
Ci、Di、Mi、Bi(i=1,2,…,n表示節點個數)分別為各節點初始狀態下CPU的剩余性能、磁盤IO的剩余性能、內存的剩余性能、網絡帶寬的剩余性能。集群中的所有節點的初始狀態剩余性能總和為:
SWi表示各節點的初始化的權重:
式中:KC、KD、KM、KB分別表示的是CPU、磁盤IO、內存、網絡帶寬的權值,且滿足KC+KD+KM+KB=1。
2) 靜態加權輪詢分配過程。
根據初始權重開始對第一批存儲塊進行靜態分配:
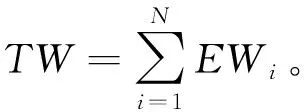
(2) 節點當前權重會一直變化,CWi=CWi+EWi,CWi等于EWi初始狀態下的選出所有節點中CWi最大的一個節點作為選中節點。
由表8可知,定芽數3、4、2之間無顯著性差異,但它們與定芽數5和定芽數1之間存在顯著性差異,定芽數5和定芽數1之間也存在顯著性差異。其中定芽數3均值最高。
(3) 選中節點的CWi=CWi-TW。
例如:假設有三個節點{A,B,C},初始權重{EW1=3,EW2=4,EW3=2},TW=3+4+2=9,現在請求7次的分配情況如表1所示。
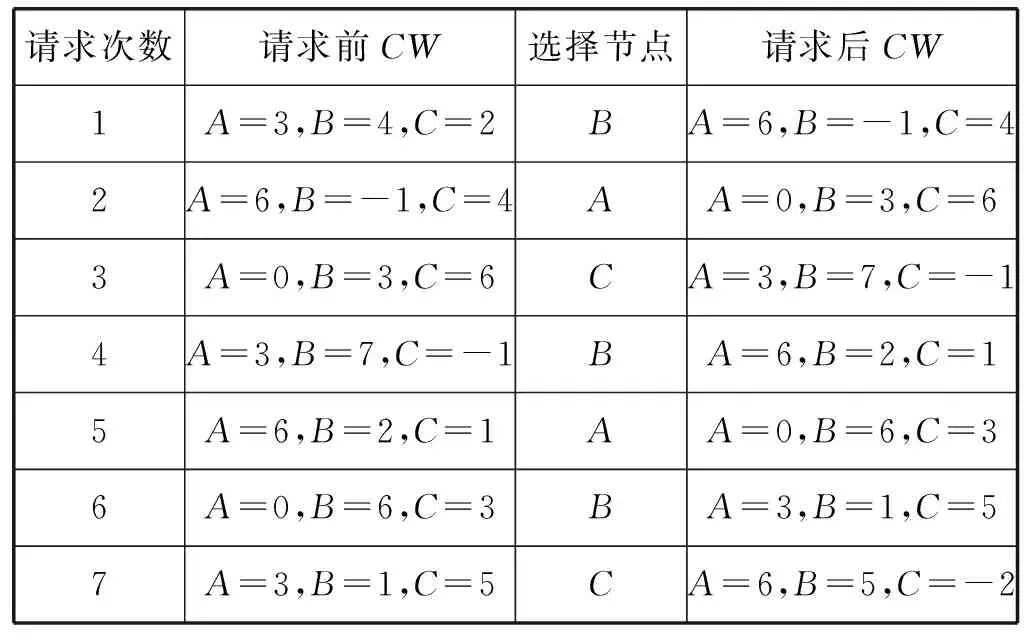
表1 靜態分配實例表
具體解釋:
第一次請求:A=3+3(EW1)=6,B=4+4(EW2)=8,C=2+2(EW3)=4,當前權重最大的B節點,所以B=8-9(TW)=-1。第二次請求:A=6+3(EW1)=9,B=-1+4(EW2)=3,C=4+2(EW3)=6,A節點為當前權重最大的點,所以A=9-9=0;以此類推。
3) 當前節點實時權重計算。
分配到節點的存儲塊進行計算任務,當計算任務快完成時計算當前節點的實時剩余性能率,根據計算出的實時權值WWi,對下一批存儲塊文件進行第二步處理,以此類推直達數據全部分配完成。
各節點的剩余性能率為:
各節點使用過程中的實時權重為:
WWi=Wi×SWi
2 證認計算算法優化
2.1 HEALPix數據過濾策略提取時空子集
為了生成時序數據,需要交叉證認來確定兩條星體是否為同一星體的數據,其原理可以概括為:星表中有兩個天體A和B。A的坐標為(ɡ1,β1),B的坐標為(ɡ2,β2)。它們之間的角距離d為:
d=arcos(sinβ1sinβ2+cosβ1cosβ2cos(g1-g2))
(1)
(2)
式中:r1和r2是兩個星表的誤差半徑。當A與B之間的角距離d滿足式(2)時,即證認成功。本實驗是同源星表不同拍攝時間數據間的證認,沿時間軸進行兩兩星表間的證認計算,計算量更大。為了解決這個問題,在布局算法完成時設計了存儲在內存中位置索引表,如表2所示,使用基于存儲塊文件的HEALPix數據過濾策略,快速定位、提取所需時空子集,減少兩兩距離計算的數據范圍,提高整個交叉證認過程的效率。
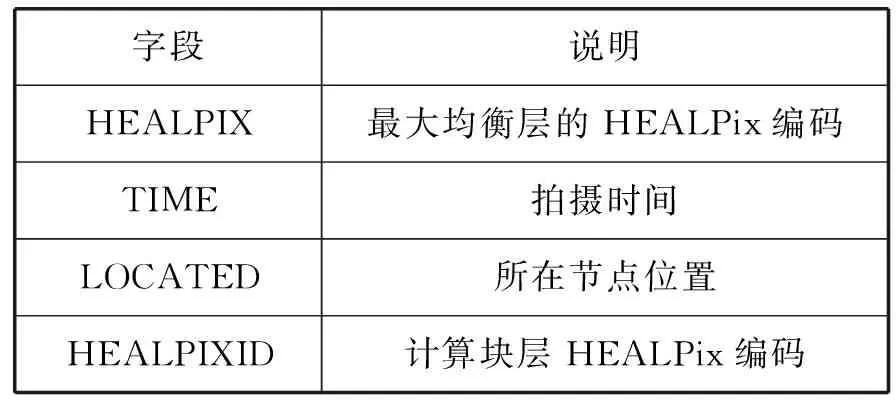
表2 索引表的結構
基于存儲塊文件的數據過濾具體步驟如下:
(1) 用戶給出檢索圓點與檢索半徑。
(2) 確定圓點在最大均衡層層級下的HEALPix編碼塊。
(3) 根據編碼塊的長度大小找到略大于檢索半徑的向外擴展的區塊對應的HEALPix編碼。
(4) 根據HEALPix編碼和內置的索引表定位到數據。
(5) 提取數據,進行錐形驗證。即計算每條數據與圓點的角距離,找到小于等于檢索半徑的數據即為提取的時空子集。數據量的減少和數據重新布局有利于計算效率的提升。
圖5為數據過濾的原理,假設索引的區域的半徑SR=4,這一層的每塊邊長大概為2,索引區域的經緯度(Ra,Dec)為錐形圓點(即圖中塊1所在中心大黑點),找到圓點所在的HEALPix塊號(圖中整個方格區塊),驗證數據。
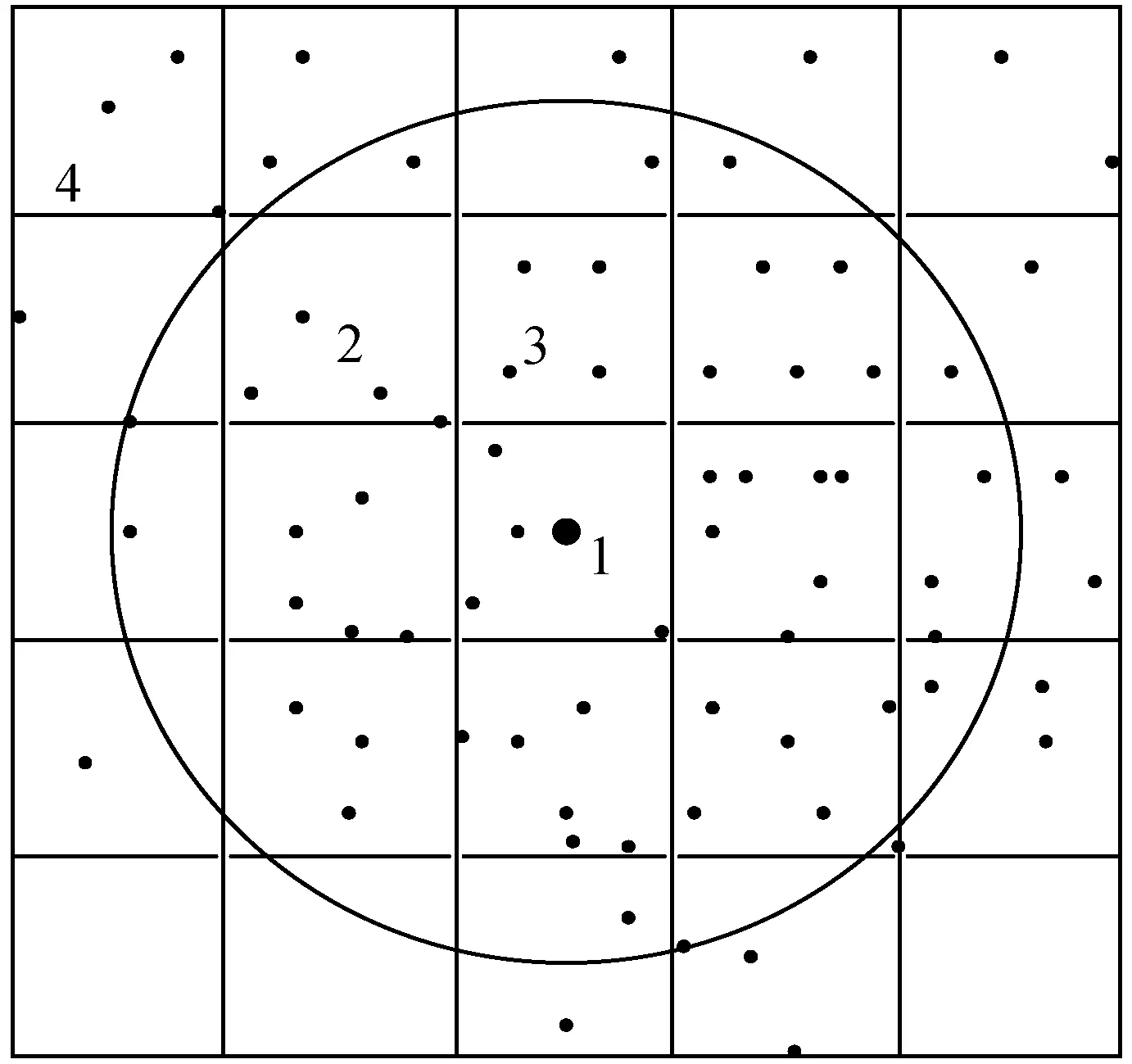
圖5 數據過濾原理
2.2 基于傳輸與計算重疊的邊緣處理方法
由于望遠鏡觀測誤差的存在,不同時間拍攝的同一個星體的數據可能會落入相鄰的兩個不同塊中,所以在進行證認計算時,為了提高證認計算的準確度,必須考慮邊緣漏源問題。邊緣漏源問題中面臨的就是數據傳輸問題,常用的解決方法是數據冗余,以空間存儲量的增加換取通信時間的減少。考慮到數據的海量性,本文提出一種基于傳輸與計算重疊的邊緣數據處理方法,此方法可以減少數據之間的跨節點傳輸,還可以使數據傳輸時間盡量與計算時間重疊,減少證認計算過程中等待傳輸數據的系統空閑時間,提高證認計算的速率與準確度。
實驗中設計兩種塊:一種是存儲塊,即最大均衡層對應的存儲塊;另一種即計算塊,計算塊就是交叉證認計算的塊單位,即在同一個計算塊內的星體數據都需要進行兩兩交叉證認計算。數據存儲是以存儲塊為單位進行存儲,證認計算是以計算塊為基礎進行計算,根據HEALPix四叉樹結構,當計算塊的層級足夠大時,一個存儲塊中會包含很多的計算塊,使得許多計算塊與其邊緣塊在同一個節點上,無須跨節點傳輸,減少節點間的數據傳輸。
存儲塊與計算塊的結合使用,減少了跨節點傳輸的數據量,只有部分邊緣數據需要跨節點傳輸,為了減少數據傳輸所需時間占比,提高總體證認速度,提出了傳輸時間與計算時間重疊的邊緣處理方法。也就是說當計算塊內的數據證認計算完成時節點間的數據傳輸也已經完成了,繼續進行邊緣塊的證認計算。通過對不同層級下邊緣數據傳輸時間以及不同劃分力度下的計算塊證認計算的對比,找到證認計算時間略大于邊緣塊數據傳輸時間的層級,即為HEALPix計算塊層,進行證認計算。
圖6為存儲塊與計算塊之間的關系,整個圖6是兩個不同拍攝時間的同一個存儲塊,整個存儲塊被劃分為許多小的計算塊,白色計算塊的所有邊緣塊都包含在此存儲塊中,即在同一個節點上,只有灰色計算塊的邊緣塊上的數據需要跨節點傳輸,同樣顯示了由于觀測誤差的存在,同一星體A落于不同計算塊中的情況。
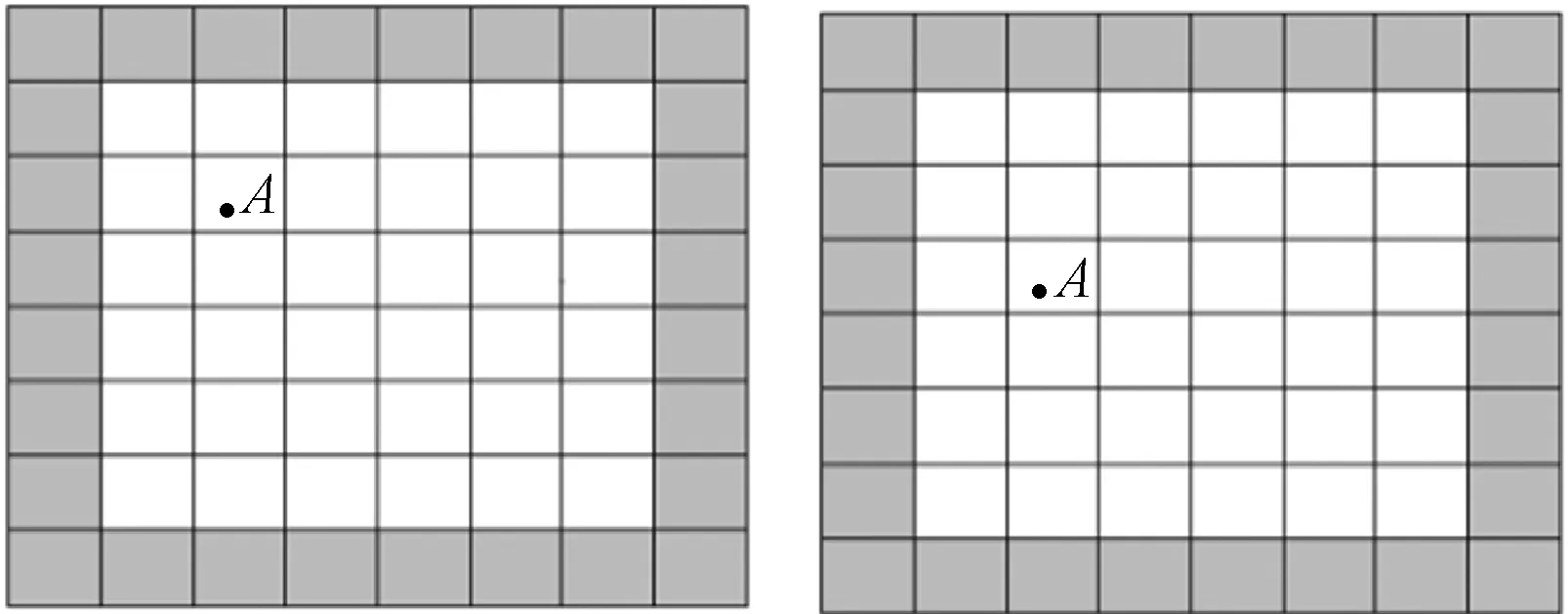
圖6 計算塊與存儲塊的關系圖
3 實驗分析
3.1 軟硬件環境
本文實驗的數據選取了中國虛擬天文臺網站上公開的AST3上的一部分數據集,用來驗證TSDGM方法的性能。數據大小為24.1 GB,包含4千萬條星體信息。實驗中,使用了一臺Intel Core i5-4790 3.60 GHz的計算機作為Master CPU,它有8 GB內存;3臺Intel Core i5-4590 3.30 GHz的計算機作為Worker CPU,內存為4 GB。操作系統是Ubuntu 14.04 LTS(64位),Linux內核為4.4.0-31-generic。基于MPI技術實現分布式集群系統。
3.2 預處理階段訪存優化提取時空子集的測試
最大均衡層保證存儲塊中數據量相對均勻分布,保證索引結構均衡性和查詢效率,實現時空子集的快速提取。本文實驗的原始數據是從AST3數據集中提取的,經過對原始文件的預處理得到了按最大均衡層HEALPix編碼排序的存儲塊文件,利用階段性的“靜態+動態”輪詢式任務分配算法存入各節點。根據1.1節給出的實驗方法,通過對原始數據每層塊內星體數據量平均值和標準差的計算,根據圖7變異系數CV的顯示,整體數據量分布最好的為8層,所以實驗測定第8層作為“最大均衡層”是最優的選擇。
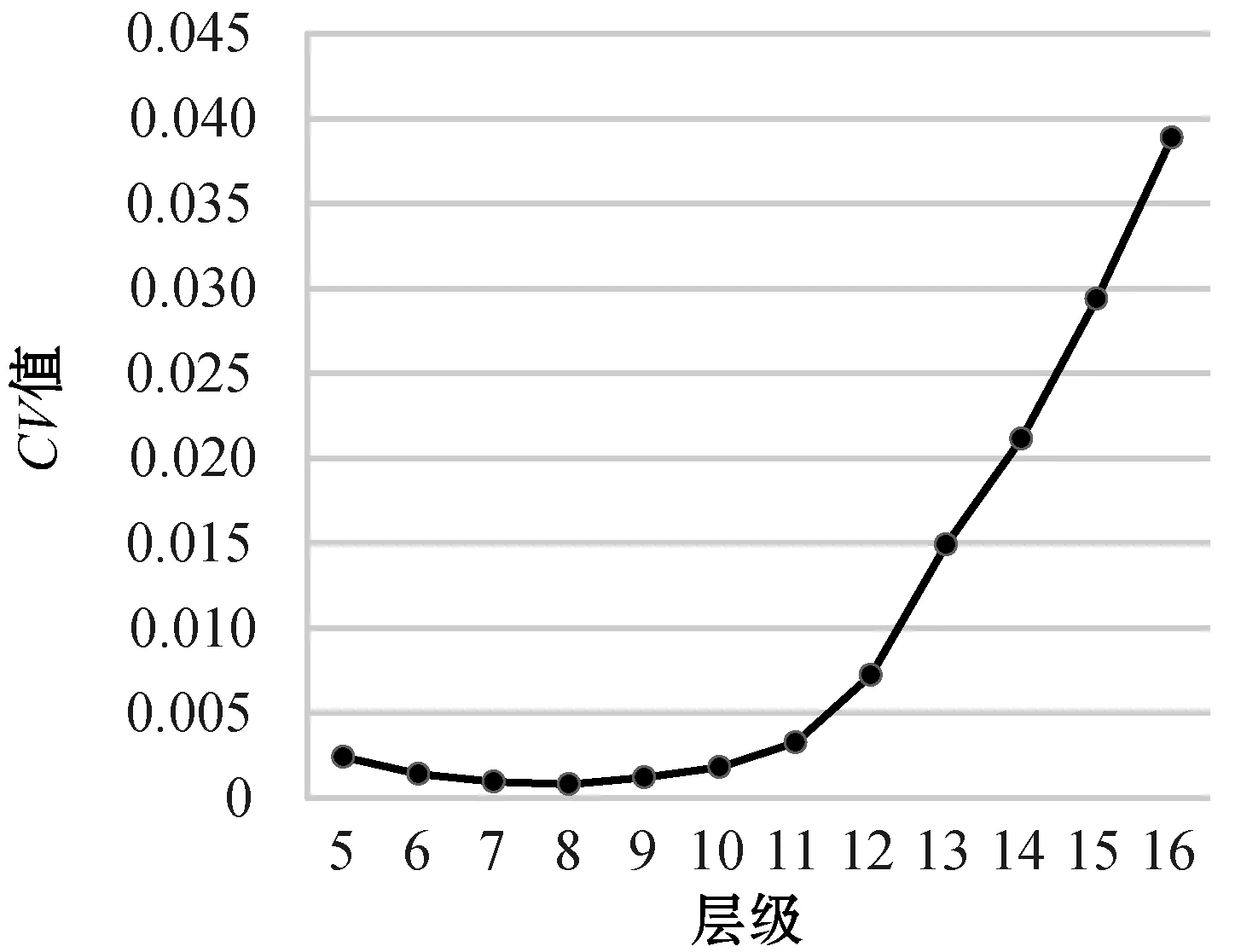
圖7 不同層級下對應的變異系數
圖8中三條曲線分別為不同層級下當搜索半徑等于0.2 rad、0.1 rad、0.05 rad下經過10次實驗提取時空子集的平均時間,提取時空子集的時間等于相鄰HEALPix編碼計算時間、數據定位提取時間與錐形檢索驗證時間之和。當錐形檢索半徑弧度等于0.2時,第8層提取時空子集時間最少,原因是第8層的編碼塊長度略大于檢索半徑0.2 rad,只需要提取錐形圓點相鄰一圈的HEALPix編碼塊進行錐形檢索驗證即可。對于第8層以前的層級,編碼塊的長度是8層編碼塊的長度的兩倍,即與第8層一樣只需要提取周圍一圈編碼塊,即相鄰的HEALPix編碼的計算時間相近,但是,根據HEALPix四叉樹結構,上一層級的編碼塊面積是下一層級的4倍,同樣提取錐形圓點一圈周圍編碼塊,提取區域面積增加了4倍多,數據量相對也增加4倍多,導致數據定位提取時間和錐形驗證時間增加。8層以后的層級,編碼塊長度小于檢索半徑的長度,導致提取相鄰編碼塊的計算時間增加,層級劃分越細,每次數據量相差不大,所以提取的數據和檢索驗證時間不會發生太大的變化。當檢索半徑弧度等于0.1 rad時,9層邊長略大于檢索半徑,為提取時空子集時間最少的層級。當檢索半徑弧度等于0.05 rad時,10層邊長略大于檢索半徑,為提取時空子集時間最少的層級。還可以看出,在最大均衡層(第8層)時,搜索區域越大,相對的搜索時間卻相對減少,即在最大均衡層下每個存儲塊文件的數據均衡分布,根據索引表進行數據定位時較好地實現了快速定位并進行數據提取的目的。

圖8 不同層級下提取時空子集的時間
3.3 證認計算優化的測試
存儲塊與計算塊的結合使用直接提取邊緣數據,邊緣數據總的傳輸時間等于邊緣數據的提取時間與數據的傳輸時間的總和,圖9為不同HEALPix層級下計算塊的邊緣數據的傳輸完成時間,圖10為不同層級下的計算塊證認時間與邊緣數據傳輸時間對比,實驗結果顯示第11層時計算塊的證認計算時間略大于數據傳輸時間。即選取11層為計算塊層,存儲塊與計算塊結合使用直接提取邊緣數據,不會出現多余的節點之間的通信時間,節點不會出現空閑的時間等待數據傳輸,減少了時間消耗,提高了證認速度。
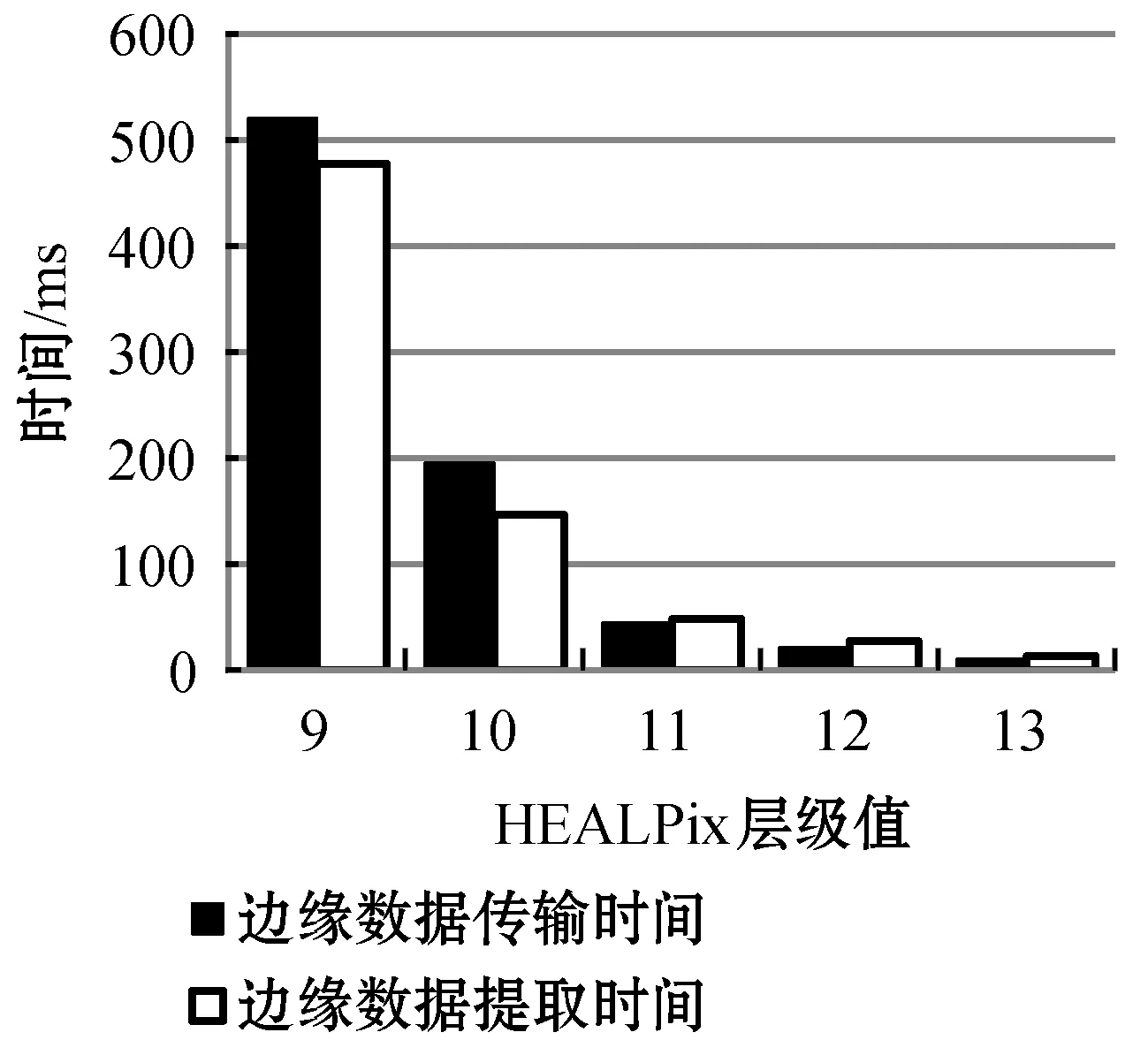
圖9 不同層級下一個計算塊邊緣數據傳輸完成時間
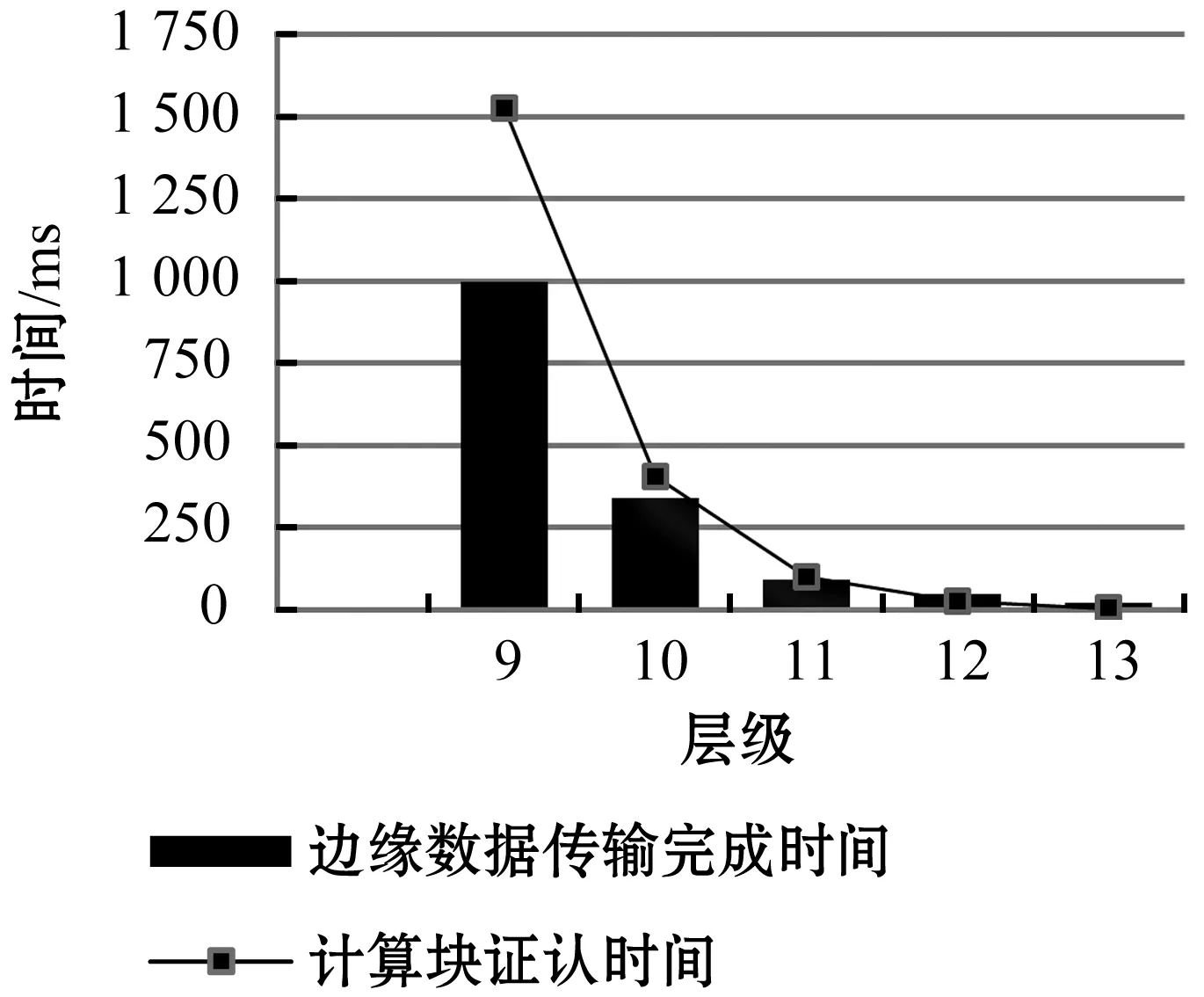
圖10 不同層級下計算塊證認時間與邊緣數據傳輸時間
3.4 綜合測試
時序數據生成傳統方法是將FITS文件導入數據庫,并在此過程中對不同時間的數據通過交叉證認的結果對天體記錄進行matchID標記,再從數據庫中找到具有相同匹配ID的記錄,并將它們導入到文件中。最后可以根據這些文件中生成時序數據。為了顯示ETSDGM方法的性能,選取了AST3拍攝的HD88500、HD117688、HD136485文件中數據量分別為2.30 GB、6.38 GB、8.30 GB的數據,采用一個節點的情況下,與傳統時序數據生成時間進行了對比測試。結果如表3所示。

表3 ETSDGM方法和一般方法的時間比較
表3中的時間是形成時序數據的總時間,可以看出即使在一個節點的情況下,TSDGM方法形成時序數據也比傳統方法更加有效,數據量越大TSDGM方法效果越明顯。在一個節點的情況下,不用考慮任務分配算法,在預處理階段,最大均衡層的設計讓存儲塊文件中的數據量均衡分布與HEALPix區塊過濾策略,確保了索引結構的合理性,快速定位提取時空子集,計算階段存儲塊與計算塊文件的結合使用,減少了跨節點傳輸的數據量,減少了系統等待數據傳輸的空間時間,兩個階段的結合提高證認速度,減少了時序數據總的生成時間。
圖11為對不同節點下生成時序數據的時間測試。圖12為不同節點下不同數據量的加速比。
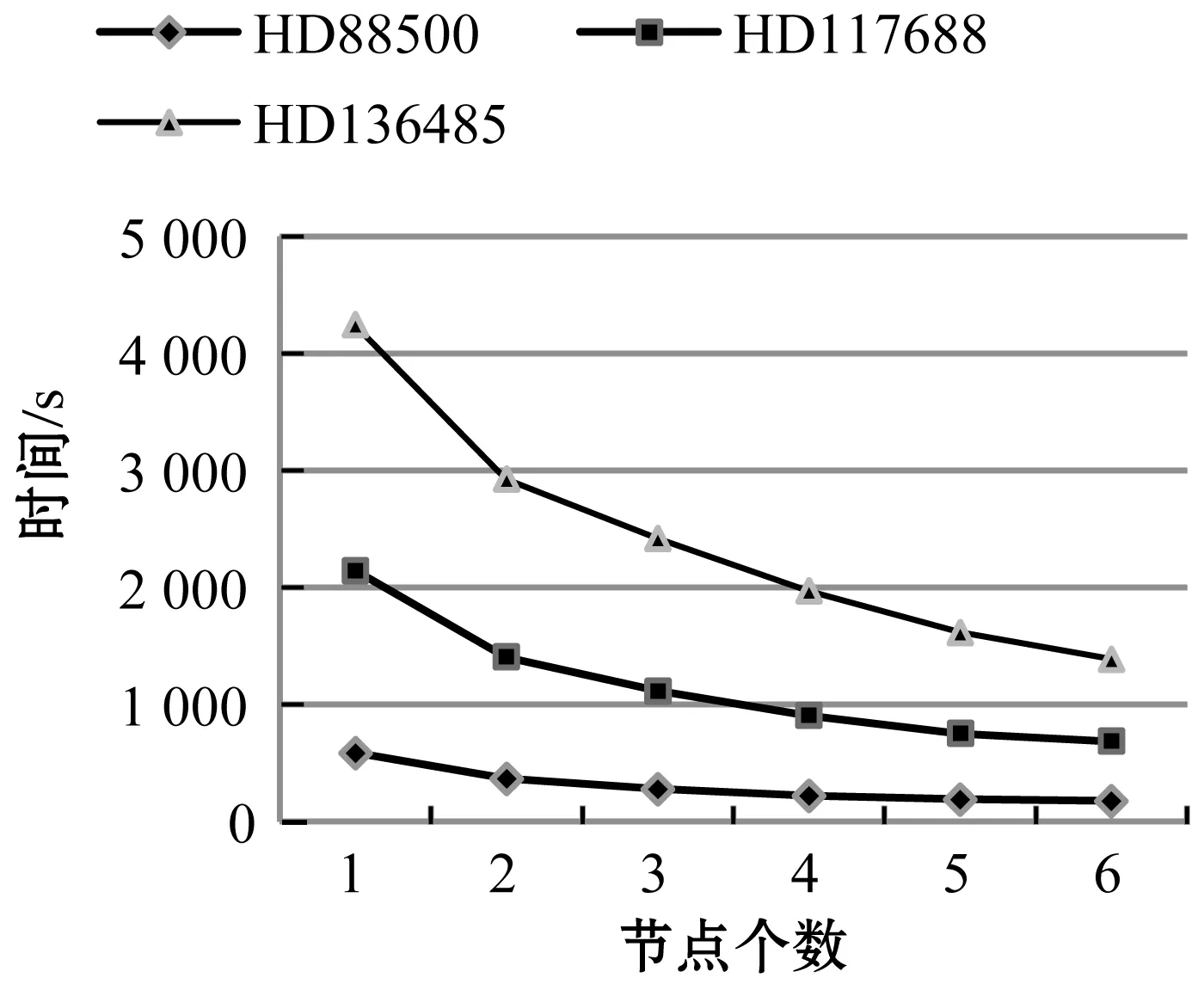
圖11 不同節點下ETSDGM運行時間
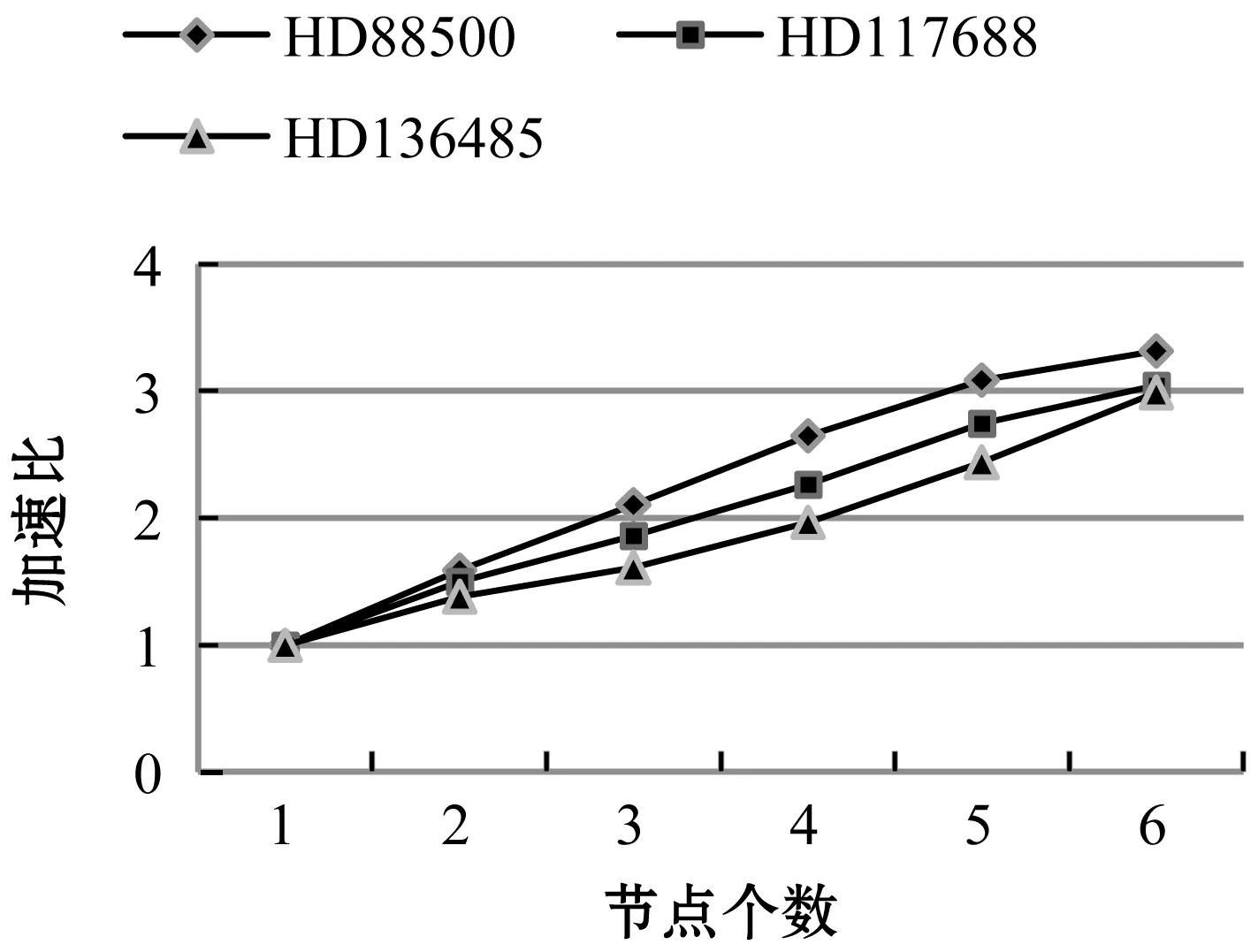
圖12 不同節點下加速比
4 結 語
本文設計一種面向海量星表數據的高效時序數據生成方法ETSDGM,整體分為兩個階段,預處理階段的訪存優化設計與證認計算算法的優化設計。其中第一階段對原始星表文件進行了訪存優化,主要是進行數據劃分和集群中任務均衡分配,實現數據的快速提取;第二階段主要是針對證認計算過程優化傳輸與計算耗時,進一步提高證認計算速率。實驗結果表明,與以往的工作相比,ETSDGM可以實現更好的性能改進,特別是在數據量較大的情況下。本文設計的高效時序數據生成方法對加快天文學家進行時域分析具有良好的應用價值。
