一種多源統(tǒng)一爬蟲框架的設計與實現
2021-04-18 23:45:40潘洪濤
軟件工程 2021年4期

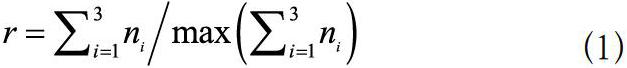
摘? 要:面向深層網數據的爬蟲技術與反爬蟲技術之間的對抗隨著網站技術、大數據、異步傳輸等技術的發(fā)展而呈現此消彼長的趨勢。綜合對比當前主流的爬蟲和反爬蟲技術,針對高效開發(fā)、快速爬取的需求,MUCrawler(多源統(tǒng)一爬蟲框架)被設計成一種可以面向多個網站數據源,以統(tǒng)一的接口形式提供爬蟲開發(fā)的Python框架。測試結果顯示,該框架不但能夠突破不同的反爬蟲技術獲取網站數據,在開發(fā)效率、魯棒性和爬取效率等方面也體現出較好的運行效果。
關鍵詞:Python開發(fā);網絡爬蟲;瀏覽器行為;HTTP請求
中圖分類號:TP311.1? ? ?文獻標識碼:A
文章編號:2096-1472(2021)-04-30-03
Abstract: Confrontation between crawler technology for deep web data and anti-crawler technology has waxed and waned with development of website technology, big data, and asynchronous transmission technology. This paper proposes to develop a Multi-source Uniform-interface Crawler (MUCrawler) framework after comprehensively comparing current mainstream crawler and anti-crawler technologies and considering the needs of efficient development and fast crawling. MUCrawler framework can face multiple websites data sources and provide Python framework of crawler development in the form of a uniform interface. Test results show that the proposed framework can not only break through different anti-crawler technologies to obtain website data, but also show better operating results in terms of development efficiency, robustness, and crawling efficiency.
Keywords: Python program; web crawler; browser behavior; HTTP (High Text Transfer Protocol) request
1? ?引言(Introduction)
網絡爬蟲(crawler,也稱spider、robot等)是面向互聯(lián)網,能夠通過URL(Uniform Resource Locator,統(tǒng)一資源定位器)自動獲取Web頁面數據的程序[1]。高性能的網絡爬蟲搜集互聯(lián)網信息是搜索引擎(如Google、Baidu等)的基礎。網絡爬蟲也是大數據和人工智能訓練的一個重要數據來源,如社交網絡情緒分類[2]、農業(yè)物資分析[3]或金融市場分析[4]等數據就可以采用網絡爬蟲從對應網站中采集。
無限制的網絡爬蟲可能對網站造成流量壓力,因此,許多網站采用反爬蟲技術對網頁的自動化爬取進行限制,由此導致很多爬蟲程序失效[5]。反爬蟲技術的發(fā)展要求爬蟲程序必須不斷改進才能突破反爬蟲限制獲取網頁內容。本文針對當前流行的爬蟲和反爬蟲技術進行對比分析,在綜合各種爬蟲技術的基礎上提出了一種針對多數據源,提供統(tǒng)一接口的Python網絡爬蟲框架MUCrawler(Multi-source Uniform-interface Crawler,多源統(tǒng)一爬蟲框架),并針對招聘網站進行測試。
2? 網絡爬蟲功能分析(Functional analysis of network crawler)
2.1? ?功能分類
依據數據存儲展現方式的不同,Web網站可以分成表層網和深層網[6],針對兩種網絡設計的爬蟲程序也稱為表層網爬蟲和深層網爬蟲。在當前的網絡中,以靜態(tài)頁面為主要存儲展現的網站(表層網)越來越少,更多的網站則是使用數據庫存取的動態(tài)頁面、AJAX(Asynchronous JavaScript and XML,異步的JavaScript和XML)數據加載、JSON(JavaScript Object Notation, JavaScript對象簡譜)數據傳輸的深層網,因此,深層網爬蟲應用最廣泛。
依據爬取Web數據的范圍,網絡爬蟲可以分為通用型爬蟲和主題型爬蟲兩類。通用型爬蟲是對互聯(lián)網所有Web信息進行遍歷獲取,這種爬蟲主要作為搜索引擎的信息采集工具,具有全面性、高效率、高并發(fā)、海量存儲等特點[7]。與通用型爬蟲不同,主題型爬蟲則是針對某一個或幾個網站,進行特定主題信息的獲取[8]。主題型網絡爬蟲在當前大數據分析領域應用較為廣泛。
2.2? ?基本功能
網絡爬蟲必須能夠模擬瀏覽器行為,針對URL自動完成HTTP請求,并能夠接收服務器傳回的HTTP響應信息。Web服務器響應的信息一般為HTML(Hyper Text Markup Language,超文本標記語言)、XML(Extensible Markup Language,可擴展標記語言)或者JSON等格式的數據,也可能是圖像或者視頻格式文件。因此,網絡爬蟲需要將服務器相應的信息按照語法結構進行解析,從中過濾出有用的信息。
網絡爬蟲還要具有迭代查找或者構造URL的功能。當前多數網站是信息存放在數據庫的動態(tài)網站,網絡爬蟲需要通過自動表單填寫和提交,使用POST方法來獲取新的URL以及分析網站URL結構,也可以通過字符串拼接方式構造GET方法的URL。如果網站響應信息為HTML響應信息,也可以從頁面信息中過濾“href”“src”等標簽或屬性獲取更深層次的URL。
能夠實現網絡爬蟲基本功能的Python擴展庫包括:Urllib、Requests實現HTTP請求和響應處理,Beautifulsoup、PyQuery、lxml等實現響應文檔解析。
2.3? ?擴展功能
網絡數據的大規(guī)模爬取、存儲和處理,要求網絡爬蟲除了具備上述基本功能,還需要具備并行調度、數據去重和數據存儲等功能[9]。短時間內獲取海量網絡數據需要提高采集效率,在Robots協(xié)議允許范圍內,采取多線程并發(fā)的方式是主要途徑[10]。網絡信息中存在大量重復的URL或冗余數據,獲取這些數據不但會浪費寶貴的計算資源、帶寬資源和存儲資源,還會給服務器造成不必要的壓力,因此,去除這些重復URL和冗余數據對于提高網絡爬蟲效率至關重要。侯美靜等基于DOM(Document Object Model,文檔對象模型)結構計算頁面相似度,實現智能URL去重提高爬取效率[11]。存儲爬取數據的方式有多種,如數據庫存儲等結構化存儲、JSON等半結構化存儲及文本圖像視頻等非結構化存儲,因此網絡爬蟲還應具備多種存儲方式的接口。
2.4? ?反爬蟲技術及對應策略
數據已經成為互聯(lián)網寶貴的資源,多數大型網站對自己的數據都有防范措施,即采用反爬蟲技術對網站爬取進行限制。常用的反爬蟲機制和應對策略如表1所示[12-13]。
2.5? ?爬蟲框架
隨著搜索引擎,尤其是大數據技術的發(fā)展,網絡爬蟲技術的應用越來越廣泛。采用Python基本功能庫(如Requests)編碼實現網絡爬蟲,可以靈活定制爬蟲功能,但開發(fā)效率較低。因此,許多組織或個人開發(fā)了網絡爬蟲框架作為中間件來提高開發(fā)效率[14-15],如Scrapy、Pyspider、Crawley等,其中應用最廣泛的就是Scrapy,文獻[16]就是基于Scrapy設計開發(fā)就業(yè)推薦系統(tǒng)。
Scrapy是一個高層次的、快速開源的網絡爬蟲框架,用于爬取網站并從頁面中提取數據。Scrapy以Scrapy engine為中心,實現發(fā)起HTTP請求、接收響應、迭代提取URL等網絡爬蟲功能,并通過URL列表、數據列表輸出的統(tǒng)一調度來控制并發(fā),提高系統(tǒng)效率。但是,Scrapy針對使用AJAX等動態(tài)加載數據的反爬取技術的應對策略不足,無法突破高級反爬蟲技術的屏蔽。
3? 多源統(tǒng)一爬蟲框架(Multi-source uniform-interface spider structure)
綜上分析,各種網絡爬蟲技術均有自己的優(yōu)勢和不足,尤其是針對不同的反爬蟲技術,有些爬蟲技術受到限制而另外一些卻能突破。大型網站的結構和內容在不斷地變化,針對網絡爬蟲所采取的反爬蟲措施也在不斷強化。例如,2019年針對知名招聘網站A開發(fā)的網絡爬蟲技術,在2020年已經失效。因此,本文結合各種爬蟲與反爬蟲技術開發(fā)一種面向多數據源的統(tǒng)一爬蟲框架。
3.1? ?設計原則
周德懋等提出高性能網絡爬蟲應該具有可伸縮性、提高下載質量、避免下載垃圾問題的特點[9],于成龍等還補充了禮貌爬行、并行性等特點[17]。這些特點都是本框架設計的原則,突出的主要有四點:
(1)多源通用:針對采用了各種不同反爬蟲技術的網站,框架均具有適應性,且需要屏蔽采取爬蟲技術底層細節(jié),為用戶提供統(tǒng)一的URL請求接口。
(2)提高性能:以客戶端計算資源和帶寬資源為基礎,在框架中采用多線程網絡爬蟲實現并發(fā)數據采集。不同的網絡爬蟲技術采取不同的并發(fā)度,如Requests針對大型網站多主題數據爬取采用大量線程(線程數>10);針對中小型網站的多主題數據爬取采取少量線程并發(fā)(線程數≤10);針對Selenium等模擬瀏覽器運行AJAX數據加載的網絡爬蟲則采取單線程,避免出現錯誤。
(3)適度采集:網絡爬蟲爬取信息會擠占網站的計算資源和帶寬資源,對同一網站無限制的并發(fā)大量請求連接會消耗其資源,影響正常用戶的訪問。因此,本框架采取“禮貌”爬取方式,限制單位時間內并發(fā)的請求連接數量以及兩次請求之間的時間間隔。
(4)統(tǒng)一存儲:用戶對爬取的數據可能采取MySQL等數據庫存儲,也可能采取csv文件甚至文本文件存儲。因此,本框架封裝多種存儲方式接口,調用方式統(tǒng)一,參數各異。
3.2? ?框架結構
本框架包括下載、分析、存儲和調度四個模塊,其結構如圖1所示。
3.3? ?框架模塊說明
(1)下載模塊:下載模塊是MUCrawler框架體現“多源統(tǒng)一”特點的模塊。“多源”即多個數據源(Web網站),這些Web網站可能采取不同的反爬蟲策略;“統(tǒng)一”即針對不同數據源,MUCrawler封裝了不同的爬取技術,如Requests、Selenium等,只需要設置網站域名(host)、對應的方法名和headers參數即可。
(2)分析模塊:除了有用數據,頁面包括大量的HTML標簽、CSS樣式、JavaScript代碼等。分析模塊的功能是從已經下載的頁面中過濾出有用信息,主要采用Beautifulsoup、Selenium等技術,將特定標簽或屬性中的信息提取出來。在MUCrawler中,用戶只需要設定標簽或者屬性與信息的對應關系,同時設置該條數據的名稱,即可通過鍵值對的方式存入數組。
(3)調度模塊:形成URL隊列,通過對URL的入隊和出隊操作實現對URL請求進度的控制。當配置高并發(fā)的時候,會同時出隊多個URL發(fā)送到下載模塊來請求頁面;當配置低并發(fā)或單線程時,每次只彈出少數幾個甚至一個URL發(fā)送到下載模塊來請求頁面。通過設置兩個URL請求間隔時間控制訪問速度。
(4)存儲模塊:Web數據存儲可以有多種形式,如文本文件存儲、csv或excel文件存儲、數據庫存儲等。針對這些形式,MUCrawler框架封裝了文本文件存儲接口,接口參數包括命名規(guī)則、文件大小限制等;csv或excel文件存儲,接口參數包括命名規(guī)則、sheet設定、列名、文件大小限制等;數據庫存儲接口包括MySQL、NoSQL等多種,接口參數包括數據庫連接參數、字段對應關系、重復數據判定字段等,封裝了select、insert、delete等操作方法。
4? MUCrawler框架應用測試(MUCrawler application and test)
招聘類網站是典型的數據密集、更新快速的深層網網站。為了測試應用效果,MUCrawler框架針對招聘類網站進行了采集實踐[15]。
4.1? ?測試環(huán)境
MUCrawler基于Python環(huán)境,軟硬件配置如下:
服務器:DELL PowerEdge R210 II;CPU:Intel(R) Xeon(R)E3-1220,3.1 GHz;內存:8 GB;硬盤:1 TB;操作系統(tǒng):Windows Server 2008 R2。
VMware虛擬機:CPU:1顆2核;內存:2 GB;硬盤:20 GB。
操作系統(tǒng):Windows 7 professional 64 bit。
軟件環(huán)境:Python 3.7.7 64 bit。
網絡環(huán)境:100 MB以太網物理網絡,NAT虛擬網絡設置。
4.2? ?測試方案
MUCrawler框架的測試目標主要是功能測試、開發(fā)效率測試、魯棒性測試和爬取效率測試等。為了對比框架運行效果,選擇其他主流方法、庫或框架進行對比。選擇了三家知名的招聘網站作為測試對象,分別以L、W、Z表示。按照不同的關鍵字進行搜索,每個網站得到100個URL鏈接,將這300個鏈接作為測試URL庫。框架測試對比項目如表2所示。
4.3? ?測試結果
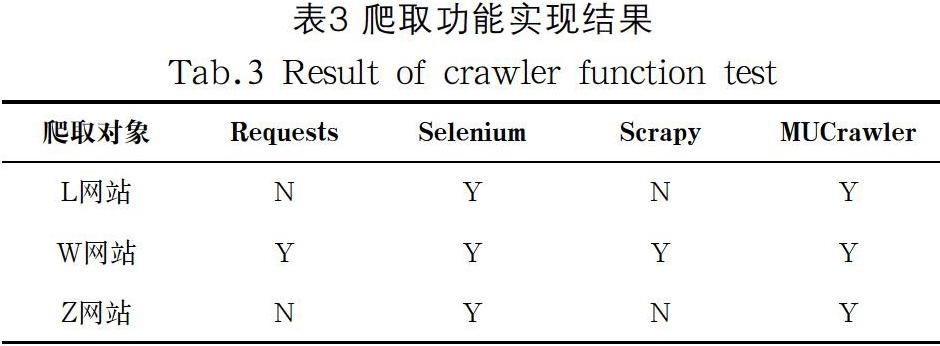
按照測試方案,功能測試針對L、W和Z網站的URL分別進行爬取,爬取功能實現結果如表3所示,“Y”代表成功爬取,“N”代表爬取失敗。
分別采用Requests、Selenium、Scrapy和MUCrawler四種技術對三個目標網站的URL鏈接庫進行開發(fā)效率測試、魯棒性測試和爬取效率測試。為了便于對比,本文將測試結果進行歸一化,如公式(1)所示,其中為第個網站的測試值。
四種技術的開發(fā)效率、魯棒性和爬取效率的測試結果經過歸一化處理,均轉換為0—1的小數,數值越小性能越優(yōu),結果如圖2所示。
4.4? ?結果分析
圖2所展示的測試結果表明,在性能上Scrapy的開發(fā)效率、魯棒性和爬取效率均為最優(yōu),其次是Requests,MUCrawler第三,而Selenium則在這些方面均處于劣勢。但結合表1的功能測試,針對部分網站的反爬措施,只有Selenium、MUCrawler能夠實現三個網站的Web信息爬取,且MUCrawler針對三個測試網站的爬取效率高于Selenium。
5? ?結論(Conclusion)
MUCrawler網絡爬蟲框架綜合各種Python爬蟲技術的優(yōu)勢,能夠突破常用爬蟲技術的限制實現信息的爬取。然而,MUCrawler并非Python原生開發(fā)的類庫,只是基于Requests、Selenium等技術進行的二次開發(fā),因此在爬取性能上還不能做到最優(yōu)。
參考文獻(References)
[1] BRIN S, PAGE L. The anatomy of a large-scale hypertextual web search engine[J]. Computer Networks, 1998, 30(1):107-117.
[2] 彭紀奔,吳林,陳賢,等.基于爬蟲技術的網絡負面情緒挖掘系統(tǒng)設計與實現[J].計算機應用與軟件,2016,33(10):9-13;71.
[3] TIAN F, TAN H, CHENG Z, et al. Research and construction of the online pesticide information center and discovery platform based on web crawler[J]. Procedia Computer Science, 2020, 166:9-14.
[4] LIU P, XIA X, LI A. Tweeting the financial market: Media effect in the era of big data[J]. Pacific-Basin Finance Journal, 2018, 51(7):267-290.
[5] 張曄,孫光光,徐洪云,等.國外科技網站反爬蟲研究及數據獲取對策研究[J].競爭情報,2020,16(01):24-28.
[6] 曾偉輝,李淼.深層網絡爬蟲研究綜述[J].計算機系統(tǒng)應用,2008(05):122-126.
[7] ARASU A, CHO J. Searching the web[J]. ACM Transactions on Internet Technology, 2001, 1(1):2-43.
[8] 林椹尠,袁柱,李小平.一種主題自適應聚焦爬蟲方法[J].計算機應用與軟件,2019,36(5):316-321.
[9] 周德懋,李舟軍.高性能網絡爬蟲:研究綜述[J].計算機科學,2009,36(08):26-29;53.
[10] BEDI P, THUKRAL A, BANATI H, et al. A multi-threaded semantic focused crawler[J]. Journal of Computer Science and Technology, 2012, 27(6):1233-1242.
[11] 侯美靜,崔艷鵬,胡建偉.基于爬蟲的智能爬行算法研究[J].計算機應用與軟件,2018,35(11):215-219;277.
[12] 胡立.Python反爬蟲設計[J].計算機與網絡,2020,46(11):48-49.
[13] 余本國.基于Python網絡爬蟲的瀏覽器偽裝技術探討[J].太原學院學報(自然科學版),2020,38(1):47-50.
[14] LI J T, MA X. Research on hot news discovery model based on user interest and topic discovery[J]. Cluster Comput, 2019, 22(7):8483-8491.
[15] PENG T, HE F, ZUO W L. A new framework for focused web crawling[J]. Wuhan University Journal of Natural Sciences, 2006, 11(9):1394-1397.
[16] 陳榮征,陳景濤,林澤銘.基于網絡爬蟲和智能推薦的大學生精準就業(yè)服務系統(tǒng)研究[J].電腦與電信,2019(Z1):39-43.
[17] 于成龍,于洪波.網絡爬蟲技術研究[J].東莞理工學院學報,2011,18(03):25-29.
作者簡介:
潘洪濤(1979-),男,碩士,副教授.研究領域:網絡安全,軟件開發(fā)和計算機職業(yè)教育.
