國家食品安全標準圖譜的構建及關聯性分析
2021-04-20 14:06:50郝志剛李國亮
計算機應用 2021年4期
關鍵詞:標準
秦 麗,郝志剛,李國亮*
(1.華中農業大學信息學院,武漢 430070;2.湖北省農業大數據工程技術研究中心(華中農業大學),武漢 430070)
0 引言
食品標準的重要性不言而喻。在眾多的食品標準中,最重要的當屬食品安全標準,它是唯一強制執行的食品標準。食品安全標準分為國家標準和地方標準兩大類,其中食品安全國家標準又包括通用標準、產品標準、生產經營規范、檢驗方法與規程四種,主要涵蓋了8 個方面的內容:食品、食品添加劑、食品相關產品中的致病性微生物、農藥殘留、獸藥殘留、生物毒素、重金屬等污染物質以及其他危害人體健康物質的限量規定。從農田到餐桌,食品安全標準既是食品生產經營者必須遵循的最低要求,也是食品能夠合法生產、消費的通行證,更是政府監管部門執法時的依據準則。但食品安全標準內容龐雜,數量繁多,覆蓋內容廣泛,并且相互引用形式多樣,普通人難以理清其中的關系,閱讀起來非常困難。雖然國家對于食品安全問題的研究也從未間斷過,但是對于食品安全標準的系統性分析和結構研究卻幾乎沒有。本文針對食品安全標準的內容與彼此之間的引用關系,借助知識圖譜技術進行內容抽取與相關性分析,實現食品安全標準的圖譜化,并在此基礎之上構建一個問答系統,完成基于自然語言的食品安全標準的知識檢索與推理。
1 相關工作
自從Google 在2012 年提出知識圖譜(Knowledge Graph,KG)這一新的技術以來,知識圖譜以及相關技術的研究取得了長足的發展。在統計學、計量學、信息科學等方面知識圖譜這一技術有著廣泛的應用。知識圖譜本質上是一種稱為語義網絡的知識庫[1],旨在描述客觀世界的概念、實體、事件及其間的關系[2]。
目前,對于知識圖譜的研究和應用多為知識圖譜的構建和存儲。國內現有的知識圖譜資源有Zhishi.me[3]等,國外資源有DBpedia[4-5]、Yago[6-7]、Wikidata[8]等;國內的圖數據庫有北京大學的gStore[9],國外的有neo4j[10]、jena[11]、GraphDB(Simple graph API for SQL Server)等。而知識圖譜的應用則相當廣泛,但是為食品安全國家標準建立知識圖譜的研究卻少有涉及,其中的主要原因是食品安全標準數量繁多,既有國家標準,又有地方標準,還有行業標準,且標準間的形式與定義規則皆不統一,特別是不同部門對基礎食品的分類與名稱定義也有較大的出入,這對采用自動化技術進行概念與關系識別帶來很大困難。目前,學術上無論是食品領域還是農業領域都沒有可以參考的專業詞庫,少量的農業與食品方面的詞匯庫也都是從公共網絡上采集的,實體名與關系名稱既不準確也不完備,且存在相互不一致的地方很多,讓人無法處理,這也給需要大量準確訓練數據的自動化知識抽取技術帶來很大困難,所以目前的研究需要更多地從專業文檔入手,梳理標準文檔之間的關系,建立統一的食品分類方式或者編碼方式以及適用于食品安全領域的專業本體,從而達到使用更先進的自動化技術來進一步完善相關知識圖譜的目的。但在本體完善之前,還需要使用一些傳統的方法來追求概念與關系抽取的準確性與專業性。本文主要研究如何將知識圖譜技術應用到食品安全國家標準的內容抽取與關系挖掘上。本文收集了截至2019 年8 月的1 263 項食品安全國家標準,并對這些標準按照文本結構與語法特點進行分類,針對每類標準制定不同抽取策略與算法,以實現它們的知識圖譜化。
2 食品安全標準知識圖譜構建
本文對食品安全國家標準進行知識與關系抽取,主要包括食品標準之間的引用關系與食品安全標準中的食品安全規定與限定內容。在抽取知識時,主要采用基于句法分析與關鍵字匹配的方法進行,因為食品安全標準文件種類繁多,且各個部門對食品安全相關概念及食品名稱沒有統一的描述與分類,尤其農業部門、食品生產與檢驗部門在食品分類與名稱上的描述差異比較明顯,所以到現在為止也沒有食品相關的專業詞庫與本體可以使用,這使得在使用一些被廣泛研究的新文本分析技術時,會因為缺乏準確而統一的訓練集而失去準確性與專業性要求,這對于食品安全領域來說,是十分重要的,所以在針對食品安全標準進行知識提取時,還是采取了抽取結果比較準確的傳統方法來實現,而一些文獻中所提出的基于機器學習和深度學習[12-14]的方法經過實驗,在知識抽取上還有較大的不足,所以沒有采用,本文關于食品安全國家標準的知識抽取與關系挖掘過程如圖1所示。

圖1 知識圖譜構建流程Fig.1 Knowledge graph construction process
2.1 數據采集
從網上收集的1 263項食品安全國家標準,經過整理與篩選后,去除一部分加密文檔以及一些圖片形式的文檔,得到1 142 個食品安全標準文本文件作為實驗初始數據集。這些食品安全國家標準分為通用限量標準、檢驗標準、生產經營規范標準與食品產品標準,針對不同的標準類型采用不同策略進行三元組提取。
2.2 三元組抽取
三元組(s,p,o)表示的是一個事實陳述句,其中,s是主語,p是謂語,o是賓語。(s,p,o)表示s 與o之間具有聯系p,或者s具有屬性p且取值為o。對于這樣一句陳述“小明獲得了學位證書”,可以用〈小明〉〈獲得〉〈學位證書〉來進行表示。在工作中,將抽取三類三元組:引用關系三元組、標準規定內容三元組、其他內容三元組等。
2.2.1 引用關系三元組抽取
引用關系在食品產品標準和通用限量標準、食品產品標準和生產經營規范標準之間較為常見,所以主要對這些標準進行引用三元組的提取。提取方式是常見的基于規則與正則表達式的匹配。引用關系三元組中的兩個實體皆是食品安全國家標準的名稱,其形式多為“GB”“SN”以及數字組合而成,采用正則表達式可以較為準確地得到食品標準名稱。實體之間的關系則是這兩個標準之間的參考項目名稱。比如,食品產品標準與通用限量標準之間的參考項目多為“污染物限量”“真菌毒素限量”“食品添加劑”“農藥殘留量”等,可以將這些常見的參考項目構建成一個關鍵詞庫。三元組的抽取依據是判斷兩個實體之間是否有對應的關鍵詞,如果有,則將其抽取成三元組進行輸出。如:在對標準文檔中的各級標題進行提取后得到文本“GB 2713—2015 食品安全國家標準淀粉制品1 范圍……3.3 污染物限量污染物限量應符合GB 2762 的規定。3.4 微生物限量3.4.1 即食淀粉制品的致病菌限量應符合GB 29921 中糧食制品類的規定……”,從這段文本中提取出的三元組為:〈GB2713—2015〉〈污染物限量〉〈GB2762〉,〈GB2713—2015〉〈微生物限量〉〈GB29921〉。
2.2.2 標準規定內容三元組抽取
食品安全標準中的通用限量標準規定了各類食品在食品添加劑、農藥殘留等方面的具體限值,因此本文主要對這一部分限值及內容進行三元組抽取。由于這部分標準的內容多以表格的形式展示,而目前對于PDF表格的處理并不十分理想,故這部分三元組數據的提取主要依靠自動化表格字符提取技術加上人工校驗的方式進行。其中,將食品類型作為三元組的頭實體,把檢測項目名稱作為實體關系,而檢測項目的限值作為三元組的尾實體。
2.2.3 其他三元組抽取
除了上面所提到的三元組,本文還對食品安全標準文件名稱進行了三元組提取。如《GB2713—2015 食品安全國家標準淀粉制品》,利用正則表達式將“GB2713—2015”和“淀粉食品”提取出來作為三元組的頭實體和尾實體,實體間關系為“標準內容”。
2.3 三元組質量評估
為了保證所抽取的三元組數據的準確性,本文對抽取的實體與關系進行質量評估,評價方法為將一部分自動抽取的三元組與通過人工閱讀所抽取的數據進行比較,查看自動抽取三元組的準確率。其中,70 個“食品產品標準”經過人工抽取后有235 條三元組,而自動抽取三元組為194 條,三元組的缺失率為17.4%,正確率為100%,這表明這種基于規則的三元組抽取有著極高的準確率,但是由于提取規則數量不足以及提取規則內容不完善導致所提取的三元組數量有限,這只能通過不斷完善提取規則來提升三元組提取數量與質量。另外對1 142 個國家食品安全標準文件名進行三元組提取與人工讀取的三元組數目一致,準確率為100%,這表明目前的抽取方法對于特征明確的三元組抽取在數量上與質量上都有保證。
2.4 基于HACCP標準的食品生產過程本體
危害分析關鍵控制點(Hazard Analysis Critical Control Point,HACCP)[15]作為食品生產過程的重要參考依據,與食品安全標準緊密相連。因此,對HACCP 中的概念及其關系進行本體構建[16]可以將食品安全標準與生產過程進行關聯,可用于項目后期的知識推理,其建立方法與流程在本項目之前的研究文獻[17]中已經討論。HACCP 中最為重要的類是“關鍵控制點”和“危害分析”,其中危害分析包括“化學危害”“物理危害”和“生物危害”,這些內容與食品安全標準的聯系較為緊密,基于HACCP 的食品生產過程本體也主要圍繞這些內容進行構建。本體結構如圖2所示。
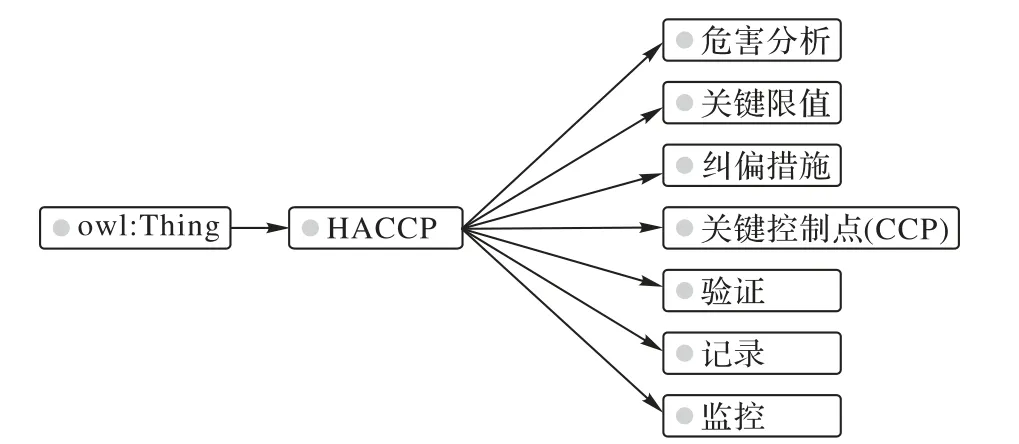
圖2 基于HACCP的食品生產過程本體Fig.2 Food production process ontology based on HACCP
在構建圖2 本體的過程中,需要對HACCP 規范文檔以及國家食品安全標準文檔中的術語、概念與關系進行抽取,特別是對國家食品安全標準文檔中的各種檢驗項目名稱、食品分類以及各種檢測項限量進行三元組抽取。由于文檔中存在大量的不規則表格,本文融合了多種抽取方式,包括基于標題格式的實體抽取、基于句法分析與關鍵詞匹配的關系抽取;此外為了保證本體的準確性,還結合了部分的人工抽取。目前本文實驗系統已完成對HACCP 規范文檔以及部分涉及危害分析的國家食品安全標準文檔的抽取工作,其中國家食品安全標準文檔主要涉及《GB2761 食品安全國家標準食品中真菌毒素限量》《GB2762 食品安全國家標準食品中污染物限量》《GB2763 食品安全國家標準食品中農藥最大殘留限量》和《GB2760 食品安全國家標準食品添加劑使用標準》。根據前面的工作,已完成的本體有2 400 多個實體,6 大類不同的關系,這還有待進一步完善。
2.5 實體對齊
在實體抽取過程中,來自來不同文件的實體會有表達形式不一致的問題。如“山梨酸鉀”與“山梨酸及其鉀鹽”意思相近,但表達形式不完全一致,這時需要進行實體對齊。進行大規模實體對齊的常用方法有詞向量分析法[18]和embedding[19]等方法。本文嘗試將食品安全標準文檔轉換后的文本數據作為Word2Vec的訓練集來實現實體的詞向量化,但由于轉換后的訓練集不夠,所以得到的結果不理想。embedding方法則需要較多的實體以及屬性來進行訓練,由于目前尚無合適的訓練集可以使用,且本文所涉及的“食品添加劑”類實體的屬性單一,因此也無法完成訓練工作。基于上述的嘗試效果皆不理想,所以目前本文通過人工建立同義詞庫的方式解決這個問題,但未來隨著本體中的實體數量的增加,應該可以通過現有實體的訓練完成新實體的對齊。
2.6 數據存儲
知識圖譜的存儲工具多為圖數據庫,本文使用gStore 存儲三元組數據。gStore 是北京大學研發的面向資源描述框架(Resource Description Framework,RDF)知識圖譜的開源圖數據庫系統,支持SPARQL(SPARQL Protocol and RDF Query Language)1.1 標準,單機可以支持5 Blilion 三元組規模的數據管理任務,支持有效的“增刪改查”操作。現將已抽取出的所有三元組以nt格式保存,使用gStore系統中的gbuild命令建立知識庫,命令格式如下:bin/gbuild+知識庫名稱+數據文件路徑。知識庫構建完成后,可以通過命令終端或者利用應用程序接口(Application Programming Interface,API)編寫相應程序來訪問管理知識庫,整個管理流程如圖3所示。

圖3 gStore數據管理Fig.3 gStore data management
利用SPARQL 語言[20-22]對食品安全標準GB2760 的被引關系進行查詢得到如表1所示數據。

表1 三元組數據表(部分)Tab.1 Triplet data table(part)
表1 中:Subject 是三元組的主語,Object 是賓語,Predicate是它們之間的關系。如第1條數據表示的含義是:GB10136—2015在食品添加劑方面引用了GB2760。
3 食品安全標準社區發現
本文將所有食品安全國家標準的引用數據進行數字編碼,使用Louvain 算法[23]進行社區劃分,然后結合節點入度與出度的統計,試圖找出這些食品安全標準間引用關系的中心點。
3.1 Louvain社區劃分算法
3.1.1 算法原理
Louvain 算法將所有初始節點獨立為一個社區,連邊權重為0,接下來的工作分為兩個步驟:1)掃描所有節點,針對每個節點遍歷該節點的所有鄰居節點,計算將其加入的鄰居節點所在社區后的模塊度增益值,選擇其中最大值所對應的鄰居節點,將該節點加入到相應社區中,迭代這一過程直到每個節點的歸屬不再發生變化;2)將每個社區當作一個節點,并計算新社區之間的連邊權重,以及社區內所有節點之間的連邊權重之和,完成后重新回到1)。
3.1.2 相對增益
在第一個步驟中要判斷一個節點所加入的社區需要根據相對增益ΔQ值,當節點與某一個社區之間的ΔQ為最大時,該節點加入到相應的社區中。ΔQ的計算公式如式(1)所示:

其中:ki,in代表由節點i連接社區C中所有邊權重之和;代表所有節點連接社區C的總權重(包括社區C內邊的總權重);ki代表連接節點i的所有邊的總權重;m是所有邊的權值之和。
3.1.3 模塊度
迭代結束的條件取決于模塊度Q,其計算公式為:

其中:Aij代表節點i和節點j之間邊的權重;ki是所有與節點i相連的邊的權重之和;ci是節點i的社區編號;δ(ci,cj)函數表示若節點i和j在同一個社區內則返回值為1,否則返回0。在一輪迭代后若Q沒有變化,則停止迭代。
3.1.4 算法實現


3.2 社區劃分結果
在對邊的權重進行賦值時,不同的節點關系所獲得的權重不同。設食品產品類標準與通用限量標準之間的邊權值為3,食品產品類標準與檢測類標準之間的邊權值為2,其余的邊權值為1。這樣設的含義是權值越高的邊代表的關系在進行抽取時人工參與的程度越高,可信度也越高,在進行社區劃分時占據的比重也更大。經過對1 142 個文檔中的三元組進行讀取(去除了少量不完整的內容),得到引用關系圖如圖4所示,共有1 105 個節點和2 593 條邊,劃分后共得到66 個社區。其中,同一社區的節點被標記為同一種顏色(若社區內節點數目占比太小,該社區內節點全部設為灰色),并且依據連接該節點的其他節點數目,調整節點標簽的顯示大小。連接數目較大的節點,其顯示的標簽則越大;反之,則越小。

圖4 國家食品安全標準引用關系圖Fig.4 Reference relationship diagram of national food safety standards
通過對這一食品標準引用關系圖譜(圖4)的觀察發現,GB5009.12、GB/T14454、GB2763、GB/T11540 等這些食品安全國家標準的節點顯示較為清晰,其中GB5009這類標準屬于理化檢驗方法標準,規定了檢測食品中化學物質的檢測方法和達標量;GB/T14454、GB/T11540 這類標準規定了香料的測定方法;GB2763 屬于通用限量標準,規定了食品中的農藥最大殘留限量。這些信息表明,在所有食品安全標準中,被引用次數較多的標準多為各種檢測標準以及規定了食品常見不合格項目的通用限量標準。同時,這些標準之間又存在著相互引用關系,是所有標準中影響力較大的食品安全標準。
4 問答系統
為了方便利用知識圖譜進行檢索與推理,本文在此基礎上構建了基于自然語言的問答系統。問答系統可以根據用戶提供的食品類別、食品添加劑名稱以及使用者類別(檢測機構、食品生產企業以及消費者)檢索食品安全國家標準的內容及其引用關系。針對不同的關鍵詞,系統可根據預先設定好的推理機制,完成圖譜內的推理,并將結果以圖表的形式展示在網頁上。問答系統結構如圖5所示。
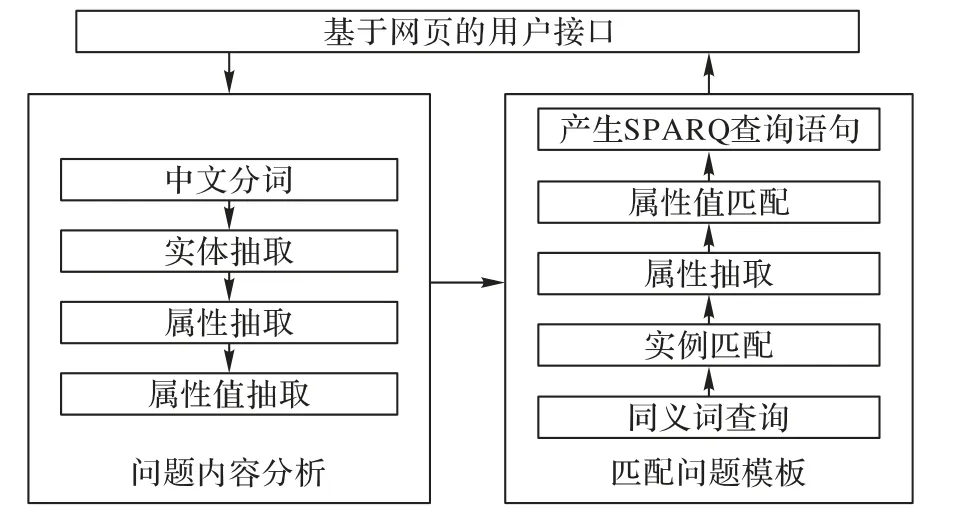
圖5 問答系統處理流程Fig.5 Processing flowchart of question answering system
4.1 基于自然語言的檢索
4.1.1 食品類型
在檢索欄輸入“食品分類:食品類型”,如“膨化食品”“面筋制品”“淀粉制品”。此類檢索主要涉及食品產品標準以及通用限量標準。如對“膨化食品”進行檢索,返回結果如圖6所示。其中第1排的“DB17401-2014”為“膨化食品”的食品安全標準,而其后內容則是此標準引用的食品安全標準,具體內容包括“DB17401-2014”所引的參考項目、標準名稱與參考項目的限量值,相應的知識圖譜如圖7所示。
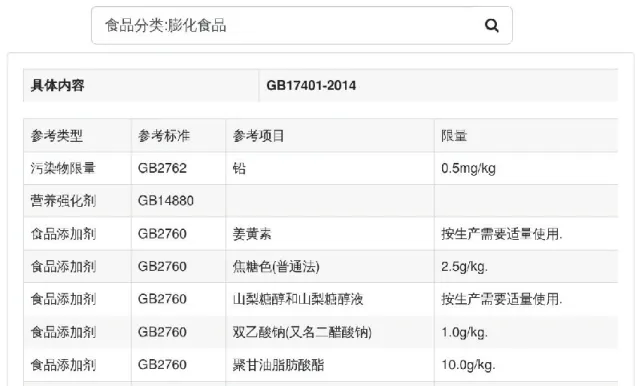
圖6 “膨化食品”查詢結果(部分)Fig.6 “Puffed food”query results(part)

圖7 “膨化食品”知識圖譜Fig.7 “Puffed food”knowledge graph
結合圖表數據來看,“膨化食品”在生產過程中主要是使用多種添加劑,針對不同的添加劑,食品安全標準GB2760 對其限量都有相應的規定,而食品安全標準GB17401—2014 的主要內容就是有關“膨化食品”的所有規定,GB17401—2014除了參考食品安全標準GB2760 外,還參考了GB14880 以及GB2762,因此,對于“膨化食品”來說,與之相關的較為重要的食品安全標準包括GB17401—2014、GB2760、GB2762 和GB14880。
4.1.2 添加劑類型
以常見的添加劑“氫氧化鈣”為例進行檢索。此類查詢涉及食品產品標準、食品添加劑相關標準、檢測標準以及基于HACCP的食品生產過程本體。結果如圖8所示。首先給出了“氫氧化鈣”所屬的添加劑類型-“酸度調節劑”,然后還給出了會使用“氫氧化鈣”作為添加劑的食品名稱及其所對應的食品安全標準,生成的相應知識圖譜如圖9 所示。結合圖表數據,“氫氧化鈣”作為食品添加劑在食品生產過程中主要用于酸度調節,與之相關的重要食品安全標準有GB25191—2010、GB25572—2010等。

圖8 “氫氧化鈣”查詢結果Fig.8 “Calcium hydroxide”query results

圖9 “氫氧化鈣”知識圖譜Fig.9 “Calcium Hydroxide”knowledge graph
4.1.3 用戶類型
以“食品生產企業”作為用戶類型進行檢索,這里主要涉及食品經營規范標準。系統首先會檢索所有生產經營規范標準,如GB31646—2018 是速凍食品生產和經營衛生規范,GB20799—2016 是肉和肉制品經營衛生規范等。選擇“GB20799—2016”繼續查詢,結果如圖10所示。

圖10 “GB20799—2016”查詢結果Fig.10 “GB20799-2016”query results
圖10給出了“GB20799—2016”參考的項目名稱以及所對應的參考標準名稱,相應的知識圖譜如圖11所示。

圖11 “GB20799—2016”知識圖譜Fig.11 “GB20799-2016”knowledge graph
結合圖表數據,食品生產企業的食品經營規范主要參考食品安全標準GB14881—2013,其內容主要包括食品生產企業在生產過程中的各項規定,包括管理制度和人員、衛生管理等,因此,對于食品生產企業的生產經營規范來說,GB20799—2016是其重要的食品安全標準。
4.2 推理方法
本文的推理方法主要采用基于規則方法實現,即通過不同的需求設計相應的檢索模板,檢索模板包括需要的條件、檢索的方式與結果的反饋方式。在獲得用戶需要后,將檢索模板所需要條件通過“:”的方式放入本次檢索中,由系統識別,并分別讀取,針對多跳檢索,會將上次的檢索的結果與本次檢索的結果進行自動匹配。如搜索“膨化食品”的相關信息時,會將“食品分類”作為檢索類型,獲取食品分類檢索模板,并將其后的內容作為檢索關鍵字。如果有多個條件,多個條件通過“:”進行拆解,并利用食品分類檢索模板生成SPARQL 檢索語句。如對于“膨化食品”的檢索,系統根據“食品分類”檢索模板生成的SPARQL語句是通過下面的步驟實現的。
1)對關鍵字內容進行分割,得到part1“食品分類”與part2“膨化食品”。
2)對part1進行判斷,選擇相應的推理模板,并將part2作為參數進行傳遞。
3)SPARQL 根據推理模板生成搜索語句:如對SELECT*WHERE{?s?p?o.?s <食品分類>obj.}中的obj進行替換,將得到最終的查詢語句:
SELECT*WHERE
{?s?p?o.?s <食品分類><膨化食品>.}
該SPARQL 語句限制了?s 的屬性為“食品分類”,相應的屬性值為“膨化食品”,同時又查詢與?s 相關的其他三元組作為結果返回。
基于“添加劑類型”與“用戶類型”的檢索模板,是通過下面的步驟實現的。
對于“氫氧化鈣”的檢索,系統會檢查該關鍵詞的分類,將“添加劑分類:氫氧化鈣”作為本次檢索的類型,找出所有涉及“氫氧化鈣”這一實體的相關三元組數據,其SPARQL 生成的步驟如下:
1)對關鍵字內容進行分割,得到part1“添加劑分類”與part2“氫氧化鈣”。
2)對part1進行判斷,選擇相應的推理模板,并將part2作為參數進行傳遞。
3)SPARQL 根據推理模板生成搜索語句:如對SELECT*WHERE{?s?p?o.?x?p2?s.?s <添加劑分類>obj.}中的obj進行替換,將得到最終的查詢語句:
SELECT*WHERE
{?s?p?o.?x?p2?s.?s <添加劑分類><氫氧化鈣>.}
該SPARQL 語句限制了?s 的屬性為“添加劑分類”,相應的屬性值為“氫氧化鈣”,同時又查詢與?s相關的其他三元組,其中?s作為頭實體或尾實體。
而對于“食品生產企業”的檢索,系統會檢查該關鍵詞的分類,將“用戶分類:食品生產企業”作為本次檢索的類型,找出所有的生產經營規范標準返回給用戶,當用戶從這些標準中選取“GB20799—2016”時,系統會將該標準的相關信息與“用戶分類:食品生產企業”合并成新的檢索“用戶分類:食品生產企業:肉和肉制品經營衛生規范:GB20799—2016”,其SPARQL生成的算法如下:
1)對關鍵字內容進行分割,得到part1“用戶分類”,part2“食品生產企業”,part3“肉和肉制品經營衛生規范”,part4“GB20799—2016”。
2)對part1 進行判斷,選擇相應的推理模板,并將part2、part3、part4作為參數進行傳遞。
3)SPARQL 根據推理模板生成搜索語句:由于參數中給出了標準的名稱,而標準實體名稱是獨一無二的,可以忽略其他限制條件,對SELECT*WHERE{?s?p?o.?s <標準名稱>obj.}中的obj進行替換,將得到最終的查詢語句:
SELECT*WHERE
{?s?p?o.?s <標準名稱><GB20799-2016>.}
該SPARQL 語句限制了?s 的屬性為“標準名稱”,相應的屬性值為“GB20799—2016”,同時又查詢與?s 相關的其他三元組作為結果返回。
本系統的檢索模板是通過用戶的需求人為定義的,所以隨著需要的增加和改變,檢索模板的定義也會有變更,但隨著項目的進展,會根據用戶需要設計自動生成檢索模板的方法。
4.3 問答系統結果評價
問答系統的目的是站在不同任務的角度,根據用戶的需要,發現對用戶來說比較重要的標準以及與該標準關聯比較緊密的其他標準,這對于標準使用者或者制定者來說,能幫助他們迅速得關注到標準的核心點及與其他標準之間的關聯關系,能起到指導使用與優化建設的輔助功能。從目前問答系統得到的檢索與推理結果來看,所有的結論在常識上與專業上都是可以解釋的,符合食品安全與食品檢驗的基本規律,所以本文的食品安全標準圖譜與問答推理系統能有效地反映標準間的引用關系并發掘不同任務、不同需要下重點標準與相關標準間的關系。但由于目前考慮到的任務與需求還比較少,所以推理方式也較單調,后期的實驗與系統也會考慮到更多、更復雜的情況。
5 結語
本文通過對現有收集到的食品安全國家標準進行內容實體與引用關系的抽取,構建了食品安全國家標準圖譜,整個圖譜包括1 105 個節點和2 593 邊,其中如“GB2763”這類通用限量食品安全標準以及“GB5009”這類檢測標準所生成的節點連接度最高,表明這些標準在所有標準中重要程度更高。本項目建立了基于HACCP 的食品生產過程本體并完成了實體對齊,本體使得圖譜間知識的聯系更加清晰與完整,并為未來的更自動化的知識抽取提供基礎與依據。然后基于知識圖譜搭建了基于自然語言的問答系統,對圖譜進行檢索與推理,以此來挖掘不同標準間的相關性,找出不同需求下最具影響力的食品安全國家標準。實驗結果表明,這種方式具有可行性,能實現“核心”標準的發現,對于研究食品安全國家標準的結構與內容分布有較好的指導作用。但是,未來還存在一些待優化的問題:一方面,由于缺乏可用的專業詞庫,知識抽取的自動化程度有待提高,未來隨著項目自建的本體的完善,可以通過對其中實體與關系的訓練來使用更快速、更新的技術來優化知識抽取的方法;另一方面,推理規則的生成還不能實現自動化,現在還需要通過人的分析來生成推理模板,未來將研究規則的自動生成方法。
猜你喜歡
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
當代陜西(2019年8期)2019-05-09 02:22:48
上海建材(2019年1期)2019-04-25 06:30:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
家庭影院技術(2018年4期)2018-05-09 07:07:52
專用汽車(2016年4期)2016-03-01 04:13:43
質量與標準化(2015年9期)2015-12-31 11:41:40
中國質量與標準導報(2014年4期)2014-03-11 19:54:25
中國質量與標準導報(2014年10期)2014-02-28 22:25:47
中國質量與標準導報(2014年7期)2014-02-28 22:24:39
