基于注意力融合網絡的視頻超分辨率重建
2021-04-20 14:06:52卞鵬程鄭忠龍李明祿何依然王天翔張大偉陳麗媛
計算機應用 2021年4期
卞鵬程,鄭忠龍,李明祿,何依然,王天翔,張大偉,陳麗媛
(浙江師范大學數學與計算機科學學院,浙江金華 321004)
0 引言
超分辨率(Super-Resolution,SR)技術的主要目的是通過對低分辨率(Low-Resolution,LR)圖像填充丟失的細節信息重建出對應的高分辨率(High-Resolution,HR)圖像。超分辨率技術可以分為單幅圖像超分辨率(Single Image Super-Resolution,SISR)[1-6]重建、多幅圖像超分辨率(Multi-Image Super-Resolution,MISR)[7-8]重建和視頻超分辨率(Video Super-Resolution,VSR)[9-12]重建。SISR 重建技術主要是通過利用圖像先驗或者圖像內部的自相似性進行重建,而VSR 重建技術不僅可以利用幀內的空間信息,也可以通過顯式或隱式的特征對齊進行運動估計和運動補償,挖掘相鄰幀與參考幀之間的時間關系,用于指導目標幀的重建。超分辨率技術應用廣泛,主要應用領域有醫學影像處理、視頻監控、遙感衛星圖像處理、刑事案件偵破和超高清產業[13]。
由于超分辨率重建是一種不適定問題,對于單一的低分辨率圖像或者視頻幀,可能存在許多不同的高分辨率圖像與之對應。利用深度學習算法,模型可以直接學習從低分辨率圖像到高分辨率圖像的端到端映射函數,從而對生成高分辨率圖像的過程進行指導和約束。目前,由于深度學習的不斷發展,出現了很多基于深度學習的超分辨率重建方法,研究人員在特征提取、非線性映射和重建的架構,以及損失函數、學習策略和評價指標等各個方面開展了廣泛的研究,也取得了不斷的突破[14]。
現有的基于深度學習的視頻超分辨率方法一般有特征提取、對齊、融合和重建四個步驟,特征對齊和融合主要是對多幀進行顯式或隱式的運動估計和運動補償,當視頻中存在遮擋、復雜的運動等問題時,特征對齊和融合的策略對視頻幀重建的質量起著關鍵的作用[12]。由于相鄰的視頻幀存在大量的冗余信息,為了充分挖掘視頻幀內的空間關系以及幀間的時間關系來達到更好的特征融合,不僅需要深度網絡盡可能地增大參考幀特征的感受野來提取不同層的空間特征,也需要有選擇地利用不同的相鄰幀所提供的不同信息量。以往的方法在特征對齊和融合方面存在很多不足。例如,在使用光流進行運動估計和運動補償時,往往很難得到精確的光流,不精確的運動估計會嚴重影響后續的超分辨率重建效果;在進行特征融合時,沒能充分利用特征間的關系。
針對以上的問題,本文以反向投影架構作為骨干網絡,迭代地學習特征之間的映射關系,并使用多種注意力機制對幀內信息和幀間信息關系進行利用,構建了一個統一的基于注意力機制的超分辨率網絡。通過學習和融合幀間信息和幀內信息,聚合提取到的特征來增強模型的表征能力。值得注意的是,本文提出的注意力模塊也可以應用到其他的視頻超分辨率網絡結構中。最后,在兩個公開的數據集上與一些主流的視頻超分辨率方法進行對比實驗,結果表明本文提出的模型在視覺質量和量化指標上都有很好的競爭力;同時,相關的消融實驗也驗證了注意力融合模塊的有效性。圖1(b)展示了本文的注意力融合網絡(Attention Fusion Network,AFN)對雙三次插值下采樣后的LR 視頻幀進行4 倍超分辨率重建后的結果。

圖1 雙三次插值、AFN和4倍放大高分辨率對比Fig.1 Comparison of bicubic interpolation,AFN and 4-times high-resolution
1 相關工作
1.1 基于深度學習的視頻超分辨率
隨著深度學習的發展,深度學習方法在計算機視覺任務中的應用也越來越廣泛。圖像和視頻超分辨率重建是一種底層計算機視覺任務,較早基于深度學習的超分辨率方法是2014 年Dong 等[15]提出的超分辨率卷積神經網絡(Super-Resolution Convolutional Neural Network,SRCNN)。相較于圖像超分辨率,視頻超分辨率的研究更加關注幀間顯式或隱式的對齊和多幀融合:Kappeler 等[16]首次使用光流進行運動補償,然后將多幀串聯送入卷積網絡;Caballero[17]提出的視頻高效亞像素卷積神經網絡(Video Efficient Sub-Pixel Convolutional neural Network,VESPCN)也使用光流進行運動估計和運動補償,并使用亞像素卷積進行上采樣;Tao 等[18]提出了亞像素運動補償模塊,并使用編碼解碼結構結合卷積長短期記憶(Convolutional Long-Short Term Memory,ConvLSTM)網絡[19]加速訓練和細節融合;Liu等[20]提出時間自適應網絡選取最優范圍的時間依賴來處理不同運動;Sajjadi 等[11]提出了幀循環視頻超分辨率網絡(Frame Recurrent Video Super-Resolution network,FRVSR)去逐步融合多幀,以確保時間連續性;Jo 等[21]提出的動態上采樣濾波視頻超分辨率網絡(Video Super-Resolution network using Dynamic Upsampling Filter,VSR-DUF)構建了一個三維卷積[22]模塊,并采用動態上采樣濾波器對目標幀進行重建;Haris等[23]提出的循環反向投影網絡(Recurrent Back-Projection Network,RBPN)采用循環編碼解碼結構,利用反向投影機制估計隱式的幀間運動以及LR 視頻幀和HR 視頻幀之間的映射關系;Yi 等[24]提出的非局部時空關系漸進融合視頻超分辨率網絡(Progressive Fusion video super-resolution network via exploiting Non-Local spatiotemporal correlations,PFNL)采用非局部注意力機制(Nonlocal Attention)[25]挖掘時空關系,并采用漸進的方式逐步融合特征;Wang 等[12]提出的增強可變卷積視頻恢復框架(Video Restoration framework with Enhanced Deformable convolutions,EDVR)采用可變卷積進行特征對齊,結合金字塔結構進行時間和空間信息融合。傳統的采用光流作為特征對齊的方法不僅費時而且不精確的光流估計會影響后續的特征融合和重建。本文采用反向投影原理,對特征進行隱式對齊,并結合多種注意力機制進行特征融合,以克服傳統光流法的不足。
1.2 注意力機制
注意力機制模仿人類視覺機制,通過選取局部重點關注區域進而提取主要特征,忽略次要特征。近幾年,注意力機制在計算機視覺和自然語言處理等領域都取得了重要的突破。通過在多種視覺任務中嵌入注意力機制,可以提升深度學習模型的表現性能。根據注意力關注的域,可以分為空間域、通道域、時間域和混合域。Jaderberg 等[26]提出的空間變換網絡(Spatial Transform Network,STN)使用空間域注意力將原始圖像的空間信息變換到另一個空間并保留了關鍵信息;Hu等[27]在擠壓激勵網絡(Squeeze and Excitation Network,SENet)中提出通道注意力,研究特征通道之間的關系,對通道維度的信息進行利用;Wang 等[28]提出的高效通道注意力網絡(Efficient Channel Attention Network,ECA-Net)通過改進SENet,在提升性能的同時,更加輕量化;Wang 等[29]提出的殘差注意力網絡通過上采樣、下采樣和殘差模塊,形成了空間域和通道域的混合注意力。非局部注意力網絡[25]通過捕獲長范圍的特征依賴性,分析了當前像素與全局的其他像素之間關系權重。在超分辨率任務中引入注意力機制的研究也有很多;Liu等[30]提出使用注意力機制區分圖像的紋理與平滑區域;Zhang 等[31]提出的殘差通道注意力網絡(Residual Channel Attention Network,RCAN)使用殘差注意力來提高模型的表征能力;Liu等[32]提出的基于注意力的反投影網絡(Attention based Back-Projection Network,ABPN)采用非局部注意力來獲取圖像內部像素之間的空間關系;Liu等[33]提出殘差特征聚合網絡結合增強空間注意力來提高圖像超分辨率重建的效果;EDVR 采用時間空間注意力來進行特征融合,并采用金字塔結構增加注意力感受野。本文提出采用時間、空間和通道注意力對特征的相關關系進行更充分的挖掘和利用,提高模型的特征處理能力。
2 注意力融合網絡
2.1 整體框架

本文利用反向投影原理,結合多種注意力機制和融合策略,構建了一個統一的用于視頻超分辨率重建的注意力融合網絡(AFN),整體網絡框架如圖2 所示,模型主要包括反向投影模塊、注意力融合模塊和重建模塊,分別用于特征的提取、融合和重建。

圖2 注意力融合網絡(AFN)整體框架Fig.2 Overall framework of Attention Fusion Network(AFN)
具體的反向投影模塊和注意力融合模塊的結構將在2.2節、2.3 節進行詳細介紹。通過兩個反向投影模塊,可以迭代地最小化重建損失,學習高頻特征和低頻特征的映射關系,對參考幀的高頻特征進行恢復和隱式的特征對齊與提取。然后,將兩個模塊得到的特征分別輸入到注意力融合模塊中,通過使用時間、通道和空間混合注意力,使模型能夠更加充分地利用多維度信息,進而提升模型的特征表達能力。最后,通過對融合后的特征進行重建,得到高分辨率的視頻幀。
2.2 反向投影模塊
反向投影機制是一種能夠有效最小化重建損失的迭代過程[34],將反向投影機制應用于超分辨率主要是基于高分辨率圖像下采樣后得到的低分辨率圖像應該與原來的低分辨率圖像盡可能相似的假設,通過采用迭代的上采樣和下采樣方式去計算不同網絡深度每個階段的重建錯誤[35]。本文采用了兩個反向投影模塊,兩個模塊的整體處理流程一致,只是模塊的輸入不同。
第一個反向投影模塊中,輸入是經過雙三次插值下采樣得到的t時刻低分辨率參考幀首先通過兩個卷積層進行特征提取,得到初始的特征圖

其中Conv(·)表示卷積操作。
第i(i∈{1,2,…,n})階段的輸入是前一個階段i-1 的低分辨率特征圖采用上投影和下投影的結構,先將特征圖依次通過反卷積操作和卷積操作進行上采樣和下采樣,得到的特征圖與原來特征圖大小相同,然后將兩個特征圖相減得到殘差,即重建損失。第i階段上投影過程得到的特征圖為


通過重復多個階段的反向投影過程,不斷迭代計算重建錯誤,最后將每個階段通過反卷積放大得到的特征圖串聯在一起,經過卷積后得到特征Ht:
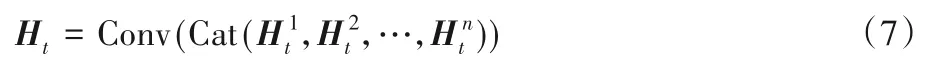
其中Cat(·)表示串聯操作。

然后采用和第一個投影模塊類似的機制,不斷迭代優化個階段特征的差異et-i,每個階段產生的特征為Ht-i,具體的實現過程如圖3所示。

圖3 反向投影模塊Ⅱ中的上采樣和下采樣投影操作Fig.3 Up-sampling and down-sampling projection operations in back projection module Ⅱ
2.3 注意力融合模塊
在2.2 節中提到的兩個反向投影模塊迭代產生了多個階段的特征圖:第一個反投影模塊通過反向投影機制學習HR特征圖和LR特征圖之間的映射關系,并獲取多階段的誤差反饋;第二個反投影模塊由于結合了多個相鄰幀的特征以及相鄰幀與參考幀之間的運動而產生的光流信息,在保留低頻信息的同時,能夠獲取一些運動信息并進行迭代的特征對齊,避免了顯式的光流對齊操作,在減少運算量的同時可以較好地產生一些高頻信息。但是如果只是將多個階段的特征圖簡單融合在一起,并不能對這些特征充分利用,因為前后不同鄰幀包含的信息量對參考幀的參考價值是不同的。例如,距離參考幀越遠的鄰幀與參考幀的特征相似度越低,而在視頻的幀中存在運動模糊、遮擋、光線變化等問題時,需要同時考慮不同距離的鄰幀,更加關注一些有益于參考幀重建的鄰幀,而忽略掉一些存在問題的鄰幀特征。同時,幀內特征的空間信息和通道信息也存在沒有被充分地挖掘和利用的問題。
針對上面提到的視頻超分辨率重建過程中存在的一些問題,本文提出了注意力融合模塊。第一個模塊在特征融合時采用了通道注意力和空間注意力,第二個模塊考慮了時間信息,將時間注意力、通道注意力和空間注意力進行結合,共同指導特征的融合。與以往采用的空間注意力和通道注意力不同,本文采用了改進的空間注意力和通道注意力,分別稱為增強空間注意力(Enhanced Spatial Attention,ESA)和高效通道注意力(Efficient Channel Attention,ECA),通過融合多種注意力機制產生的特征,能夠充分利用視頻幀內和幀間信息,為鄰幀特征和幀內特征分配不同權重,共同指導特征有選擇地進行融合。在第二個注意力融合模塊中,時間注意力、通道注意力和空間注意力的組合方式如圖4 所示。先通過時間注意力機制對多幀特征進行融合,然后使用通道注意力機制和空間注意力機制分別在通道維度和空間維度處理融合后的特征。

圖4 注意力融合模塊ⅡFig.4 Attention fusion module Ⅱ
時間注意力機制用于計算參考幀的特征與多個鄰幀特征之間的相似度。相似度越高,鄰幀包含的信息量越多,對參考幀的重建參考價值越大。特征在嵌入空間的相似度計算可以使用卷積實現。首先將反向投影模塊產生的特征{Ht-n,Ht-n+1,…,Ht+n}進行卷積,然后再將Ht卷積后的特征分別與{Ht-n,Ht-n+1,…,Ht-1,Ht+1,…,Ht+n}卷積后的特征進行點積運算,最后通過Sigmoid 激活函數使輸出{At-n,At-n+1,…,At+n}的值在0 到1 之間,以使訓練穩定。At+i可以表示為:

其中:i∈[-n,+n];σ(·)表示Sigmoid激活函數。
得到{At-n,At-n+1,…,At+n}之后,需要將其與原來的特征{Ht-n,Ht-n+1,…,Ht-1,Ht+1,Ht+2,…,Ht+n}按元素相乘,然后將經過時間注意力處理后的結果串聯并進行一次額外的卷積操作得到融合后的特征Hf:

其中:⊙表示按元素相乘。
得到融合特征Hf后,將其作為ECA 模塊的輸入。在ECA模塊中,先將Hf進行全局池化(Global Pooling,GP)來獲取全局上下文,包括全局平均池化(Global Average Pooling,GAP)和全局最大池化(Global Max Pooling,GMP);然后由通道維度的映射自適應選擇一維卷積核的大小k并經過卷積生成通道權重,這樣可以在沒有維度約簡的情況下實現跨通道交互。在本文中,k和Hf的通道數C的關系為:

其中:| · |odd表示取最接近的奇數。
通過將ECA 融入本文的注意力模塊中,能夠高效利用特征的通道信息,提升深度網絡對視頻幀進行重建的性能。圖5是通道注意力和ECA之間的結構對比。

圖5 通道注意力和ECA的對比Fig.5 Comparison of channel attention and ECA
在ESA 中,如圖6 所示,為了在獲得更大的感受野的同時能夠輕量化,首先將經過ECA處理后的特征通過1× 1卷積降低通道維度,然后采用跨步卷積和全局平均池化來獲得更大的感受野。在經過一組卷積以后,采用上采樣和1× 1卷積恢復空間和通道維度,同時,使用殘差連接將通道縮減之前的特征與上采樣之后的特征相加,最后使用Sigmoid激活函數得到空間權重。
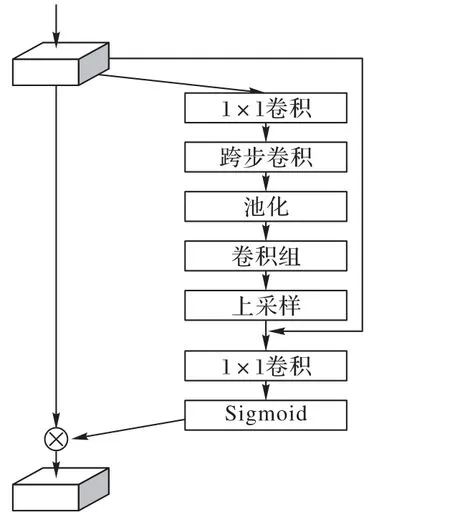
圖6 ESA模塊Fig.6 ESA module
與非局部注意力相比,ESA 在獲取長范圍特征依賴的同時更加輕量化,因此也可以將多個ESA 模塊分別放在多個階段反向投影模塊的殘差塊后面,從而實現讓殘差特征更加關注重要的空間信息以及能夠獲得更大的感受野。
在卷積塊注意力模塊(Convolutional Block Attention Module,CBAM)[36]網絡中,討論了通道注意力模塊和空間注意力模塊連接的順序和方式對模型性能的影響。相關實驗結果表明,兩個模塊按順序連接產生的注意力圖比并聯方式產生的注意力圖更加精細,并且先使用通道注意力模塊比先使用空間注意力模塊的性能表現稍好。借鑒CBAM 中注意力模塊的連接方式和連接順序,本文中第一個反向投影模塊產生的特征以及時間注意力模塊融合后的特征,先進入ECA 模塊進行處理,再進入ESA模塊,兩個注意力模塊按順序連接。
3 實驗與結果分析
3.1 數據集與實現細節
本文采用Vimeo-90K[37]作為訓練數據集,Vimeo-90K 是一個大規模、高質量的視頻數據集,包含了多種場景和運動,該數據集總共包括64 612 個7 幀視頻序列,每幀的大小為448×256。通過對高分辨率的視頻幀使用雙三次插值下采樣,得到對應的低分辨率視頻幀,并對視頻幀使用了隨機裁剪、旋轉等數據擴增技術。測試數據集采用Vid4[9]、SPMCS[18]。Vid4 數據集共有4 個不同場景的視頻片段,包含多種運動和遮擋;SPMCS數據集總共包含30個不同的視頻場景,每個視頻有31幀。對于4 倍超分辨率,使用的輸入幀是112 × 64 大小的低分辨率視頻幀進行裁剪得到的64 × 64大小的圖像塊,批次大小為8。
在第一個反向投影模塊,首先通過兩個卷積層進行初始的參考幀特征提取,經過第一個卷積層后特征通道數為256,經過第二個卷積層通道數變為64,然后使用了編碼解碼的結構,包含卷積和反卷積操作用于對特征圖進行上采樣和下采樣,總共迭代了三次。第二個反向投影模塊使用了殘差模塊進行特征提取以及使用反卷積進行上采樣,每個殘差模塊包含5 個殘差塊。所有的卷積和反卷積操作的參數都使用了Kaiming初始化[38]方法。在第二個注意力融合模塊中,將反投影模塊中各個階段的特征堆疊,首先使用時間注意力對多個高分辨率特征進行融合,然后使用高效通道注意力,最后使用增強空間注意力,經過注意力融合模塊后的高分辨率特征通道數為64,需要再經過一個卷積層恢復3個通道,最后得到高分辨率的目標幀。由于經過反卷積層生成的特征圖大小與目標幀的大小一致,因此不需要再進行上采樣操作。本文在Ubuntu 18.04 操作系統上使用PyTorch 框架實現了網絡的搭建,在4 塊NVIDIA Tesla V100 顯卡上進行模型的訓練,訓練時使用了L1損失函數,定義為:

3.2 與主流方法的對比實驗
實驗中對視頻幀進行4 倍超分辨率重建,使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[40]和結構相似性(Structural SIMilarity,SSIM)[41]作為量化指標來度量重建視頻幀的質量,PSNR 基于對應像素點間的誤差衡量圖像質量,SSIM 分別從亮度、對比度和結構三方面度量圖像相似性,PSNR 和SSIM 的指標越高,表示重建視頻幀的質量越好。分別在Vid4 和SPMCS 數據集上對視頻序列在YUV 顏色空間中的Y(亮度)通道上進行測試,并與一些主流的視頻超分辨率重建方法進行了對比實驗。同時,為了驗證提出的注意力融合模塊的有效性,本文進行了相關的消融實驗。
首先通過對Vid4 數據集上的四個視頻片段進行測試,比較了AFN、VESPCN、SPMC、FRVSR 和RBPN 方法的性能。根據以往的指標計算方法,在測試時去除了每個視頻序列中的前兩幀和后兩幀,測試的結果如表1 所示。通過分析在Vid4數據集上每個視頻序列測試的結果以及最后的平均指標,可以看到,與其他視頻超分辨率重建方法相比,本文方法整體上在PSNR 和SSIM 指標方面有所提高。圖7 展示了不同方法對Vid4數據集中的Foliage視頻片段進行4倍超分辨率后的視覺效果對比,可以看到VESPCN 和SPMCS 等方法產生的圖像過于模糊且存在一定程度的結構失真,本文的方法產生的視頻幀包含更少的噪聲,紋理方面恢復得較好。雖然FRVSR 方法在恢復車輪的結構細節時處理得比較好,但是圖像整體上比較模糊,且包含一些噪聲,使得圖像不夠清晰。

表1 在Vid4數據集上進行4倍超分辨率的PSNR和SSIM結果Tab.1 PSNR and SSIM results of 4-times super-resolution on Vid4 dataset

圖7 對Vid4數據集上的Foliage視頻片段進行4倍超分辨率的視覺效果對比Fig.7 Visual effect comparison of 4-times super-resolution of Foliage video clip on Vid4 dataset
在SPMCS 數據集上,選取了11 個視頻片段用于比較AFN、SPMC、VSR-DUF和RBPN方法進行4倍超分辨率重建的性能表現。在計算PSNR 和SSIM 指標時,去除了每個視頻序列中的前6 幀和后3 幀。測試的結果如表2 所示。在視覺效果方面,與SPMC相比,如圖8所示,本文方法產生的視頻幀在物體的邊緣紋理方面更加清晰,能夠更好地恢復視頻幀內的細節和結構信息。

圖8 在SPMCS數據集上進行4倍超分辨率的視覺效果對比Fig.8 Visual effect comparison of 4-times super-resolution on SPMCS dataset

表2 在SPMCS數據集上進行4倍超分辨率的PSNR結果 單位:dBTab.2 PSNR results of 4-times super-resolution on SPMCS dataset unit:dB
通過以上的對比實驗可以發現,與一些主流的視頻超分辨率重建方法相比,本文方法重建的視頻幀在客觀評價指標和主觀視覺效果方面有進一步的提升。
3.3 消融實驗
為了驗證本文提出的注意力融合機制的有效性,將移除了注意力融合模塊的網絡作為基線模型并進行模型訓練與測試。相關的實驗結果如表3所示,其中w/和w/o分別表示有和沒有注意力融合模塊。

表3 注意力融合對AFN重建視頻幀PSNR和SSIM的影響Tab.3 Effect of attention fusion on PSNR and SSIM of video frames reconstructed by AFN
與基線模型相比,AFN 在Vid4和SPMCS數據集上重建視頻幀的PSNR 值分別平均提高了0.24 dB 和0.31 dB,SSIM 值分別平均提高了0.011和0.024,驗證了本文提出的注意力融合機制在超分辨率重建過程中的有效性。
消融實驗的結果也說明在對特征進行融合時,幀內的空間信息、通道信息和幀間的時間信息應該可以被更好地進行探索和利用。
4 結語
本文提出了一個視頻超分辨率重建模型,稱為注意力融合網絡(AFN)。通過采用反向投影原理,結合多種最新的注意力機制和融合策略,AFN 能夠更好地利用視頻幀內和幀間信息,充分挖掘幀內特征和幀間特征的相關關系,從而有效處理包含多種運動和遮擋的視頻。通過進行相關的對比實驗,與一些主流的視頻超分辨率重建方法相比,本文模型具有更優的客觀性能指標和更好的視覺效果,并通過消融實驗驗證了部分網絡模塊的有效性。在未來的工作中,我們將致力于不斷改進網絡模型結構,在提高網絡模型性能的同時,使模型更加輕量化。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
