基于自編碼器的多視圖屬性網絡表示學習模型
2021-04-20 14:07:02王慧敏
計算機應用 2021年4期
關鍵詞:信息
樊 瑋,王慧敏,邢 艷
(中國民航大學計算機科學與技術學院,天津 300300)
0 引言
隨著互聯網的進步與發展,信息網絡成為生活中最為常見的一種信息載體,對信息網絡的研究與分析具有極高的學術價值和潛在應用價值。網絡中最基本的元素為節點和邊,邊可以連接任意兩個節點,能夠體現兩個節點之間的關系。在有關網絡的研究中,一個重要的問題就是如何合適地表示網絡信息。
網絡表示學習從原始網絡中去除噪聲和冗余信息,自動識別出網絡中有價值的信息進行保存,并將這些信息編碼到低維、稠密、連續的向量空間中,以獲得節點表示向量。網絡表示學習廣泛應用于網絡應用任務中,如節點分類[1]、節點聚類[2]、鏈接預測[3]、可視化[4]等。
早期的網絡表示學習方法通過構造特征矩陣得到網絡表示向量,但這些方法通常時間復雜度較高,隨著數據規模的增大,性能會變得很差。隨著深度學習方法的發展,涌現出大量基于神經網絡的表示學習方法,但這些方法沒有充分利用節點屬性信息或挖掘節點之間的隱藏屬性網絡結構,導致網絡信息利用并不充分。
為了更好地利用節點屬性信息,本文提出了一種基于自編碼器的多視圖屬性網絡表示學習模型(Auto-Encoder based Multi-View Attributed Network Representation learning model,AE-MVANR),具體框架如圖1 所示。該模型利用網絡結構信息和節點屬性信息構造兩個視圖:將網絡的拓撲結構信息作為拓撲結構視圖(Topological Structure View,TSV);通過計算節點間相同屬性共現頻率,構造屬性結構視圖(Attributed Structure View,ASV)。將TSV 和ASV 有效融合,深度挖掘不同節點間的內在聯系。在TSV 和ASV 上,分別利用隨機游走算法得到若干節點序列,再將序列輸入到基于長短期記憶(Long Short-Term Memory,LSTM)網絡的自編碼器中訓練,最終得到融合了結構信息和屬性信息的節點表示向量。
為了更好地驗證本文所提算法AE-MVANR 的性能,在幾個真實數據集上分別進行了分類和聚類任務。實驗結果表明,AE-MVANR 性能優于網絡表示學習中常用的僅基于網絡結構與基于網絡結構和節點屬性信息的網絡表示學習方法。
1 相關工作
傳統的網絡表示學習方法是指基于譜方法的網絡表示學習方法。該類方法利用數據的譜特征構建關系矩陣,通過計算關系矩陣的前k個特征向量來得到k維的節點表示向量。譜特征一般為特征值或特征向量,關系矩陣的構建至關重要,由特定的方法設計,一般為鄰接矩陣、節點相似度矩陣、拉普拉斯矩陣等。例如,局部線性嵌入(Locally Linear Embedding,LLE)[5]假設節點從同一個流行空間中采樣得到,且每個節點可由其近鄰點的線性加權組合構造得到。LLE 使用鄰接矩陣作為關系矩陣,保持了高維數據原有的拓撲結構。拉普拉斯特征映射(Laplacian Eigenmaps,LE)[6]假設高維空間中的兩個相似節點,在低維表示向量空間中距離也應該相近。LE 同樣使用鄰接矩陣作為關系矩陣,反映了數據內在的流形結構,解決了LLE對噪聲敏感的問題。然而,基于譜方法的網絡表示學習方法求解過程復雜,并且需要將關系矩陣整體存于內存中,時間和空間復雜度較高,因此難以應用于大規模網絡中。
隨著深度學習的發展,無監督表示學習方法在自然語言處理領域得到廣泛的學習與應用。Word2Vec[7-8]將單詞轉化為詞向量,不僅挖掘了單詞之間的語義關聯,使得語義上相似的詞語的詞向量也具有較高的相似度,而且在一定程度上也挖掘了單詞之間的抽象關系。受Word2Vec啟發,DeepWalk[9]利用隨機游走策略在網絡中獲得一系列節點序列,然后將每個節點序列視為一個句子輸入到Skip-Gram模型中,通過最大化預測節點上下文的概率學習該節點的低維向量表示。相較于基于譜方法的網絡表示學習方法,DeepWalk 算法不再使用關系矩陣,使得時間復雜度大幅降低,能夠適用于大規模網絡的表示學習。基于DeepWalk,大規模信息網絡嵌入(Largescale Information Network Embedding,LINE)[10]進一步挖掘了網絡中節點之間的關系。LINE 將節點之間的直接連接關系定義為一階相似性,將存在共同鄰居卻不直接相連的節點關系定義為二階相似性。通過引入二階相似性,LINE 極大緩解了網絡中的數據稀疏問題,最大限度地保留了局部網絡結構和全局網絡結構。不同于DeepWalk 中類似深度優先的隨機游走策略,node2vec[11]結合深度優先和廣度優先方法,使抽樣的路徑能更大程度上同時保存網絡的局部特征和全局特征。
不同于以上基于淺層神經網絡的網絡表示學習算法,GraRep[12]構造并分解了K個狀態轉移概率矩陣,將全局網絡結構信息融入到網絡表示學習的過程中。結構深層網絡嵌入(Structural Deep Network Embedding,SDNE)[13]利用深度神經網絡捕捉節點之間的高度非線性關系,并將自編碼器的中間層作為節點的向量表示,獲得的節點表示向量因此包含了網絡局部和全局結構特征。
然而,上述方法都只利用了網絡的拓撲結構信息,忽略了網絡中節點的屬性信息。基于矩陣分解的網絡表示方法可以將網絡結構信息和其他信息有效地融合在一起。結合文本信息的DeepWalk(Text-Associated DeepWalk,TADW)[14]基于矩陣分解框架將節點的文本特征引入了網絡表示學習;加速屬性網絡嵌入(Accelerated Attributed Network Embedding,AANE)[15]同樣基于矩陣分解框架,通過屬性相似度矩陣和鄰接矩陣將屬性信息和網絡結構信息融合到網絡表示學習過程中;二值化屬性網絡嵌入(Binarized Attributed Network Embedding,BANE)[16]利用Weisfeiler-Lehman 核方法編碼網絡結構和節點屬性信息,生成相似度矩陣,通過分解該矩陣,得到二進制的節點表示向量。
隨著網絡規模的增大,基于矩陣分解的網絡表示學習方法的時間復雜度也急劇上升,因此難以應用于大規模網絡中。神經網絡具有融合不同信息的特性,因此許多學者轉而研究基于神經網絡的網絡表示學習。最大邊緣DeepWalk(Max-Margin DeepWalk,MMDW)[17]在DeepWalk的基礎上將標簽信息融入到網絡表示學習過程中;深度屬性網絡嵌入(Deep Attributed Network Embedding,DANE)[18]利用圖卷積神經網絡(Graph Convolutional Network,GCN)學習屬性網絡中的節點表示向量;自翻譯網絡嵌入(Self-Translation Network Embedding,STNE)[19]利用基于雙向LSTM 的自翻譯機制實現了網絡結構和內容信息的無縫融合;屬性社交網絡嵌入(Attributed Social Network Embedding,ASNE)[20]將社交網絡中豐富的節點屬性信息融入到網絡表示學習過程中;多視圖網絡嵌入(Multi-View network Embedding,MVE)[21]使用自注意力機制為網絡中不同視圖下的多個節點表示向量投票,最終得到結果最優的節點表示向量;不同于MVE 的投票方式,基于生成對抗網絡的多視圖網絡嵌入(Generative Adversarial Network for Multi-view network Embedding,MEGAN)[22]使用生成器將不同視圖下的節點表示向量進行融合。
然而,以上大多數方法都只是簡單將節點的屬性信息作為特征矩陣,沒有根據屬性信息進一步挖掘節點之間的隱含聯系。TADW[14]在矩陣分解框架下,將節點的文本信息轉化為文本特征向量矩陣;上下文感知的網絡嵌入(Context-Aware Network Embedding,CANE)[23]利用卷積神經網絡對一條邊上兩個節點的文本信息進行編碼;Net2Net[24]基于自翻譯機制,使用LSTM 融合節點的結構特征和文本特征。但是以上方法挖掘的屬性信息均為文本信息,而非離散化的二值數值。為充分挖掘離散數值屬性信息,本文提出了一種基于自編碼器的多視圖屬性網絡表示學習模型(AE-MVANR)。
2 AE-MVANR模型
2.1 相關定義
定義1屬性網絡。給定一個屬性網絡G=(V,E,X),其中V={v1,v2,…,vn}表示網絡中節點的集合,n=|V|表示網絡中節點的數量;E={eij}表示網絡中邊的集合,m=|E|表示網絡中邊的數量;X∈Rn×t表示所有節點的屬性矩陣,Xi表示節點i的屬性向量,維度為t。
定義2屬性網絡的表示學習。給定屬性網絡G,屬性網絡表示的目的是學習一個映射函數f:i→yi∈Rd且i∈V。其中,d是向量維度且d?|V|,向量yi和yj的關系能夠反映出G中節點i和j的關系。
定義3拓撲結構視圖(TSV)[25]。該視圖由屬性網絡G生成,能夠反映網絡中節點間原有的邊關系。TSV=(V,A),其中,A表示鄰接矩陣,Aij取值為1 或0。若Aij=1 則表示節點i和節點j之間存在連接關系,否則表示兩節點之間不直接相連。
定義4屬性結構視圖(ASV)[25]。該視圖挖掘節點間屬性信息,通過節點相似性矩陣S構造而成。ASV=(V,S),其中,S是節點的相似性矩陣,為對稱矩陣。0 ≤Sij≤1 表示節點vi和vj之間的相似性程度,值越大說明節點間的相似性越高。
2.2 AE-MVANR整體框架
AE-MVANR 深度挖掘不同節點間屬性的內在聯系,通過屬性特征探索節點之間隱含的結構關系,其整體框架如圖1所示。屬性網絡G有4 個節點和3 條邊,每個節點有6 個屬性。AE-MVANR 首先根據網絡中節點間固有的連邊關系,得到TSV,根據節點的屬性信息挖掘隱含結構信息構造屬性結構視圖ASV;然后,分別在兩個視圖上執行隨機游走算法,得到基于TSV和屬性結構視圖的節點序列;最后,將序列輸入到基于LSTM 的自編碼器中,通過訓練不斷迭代,得到融合了結構和屬性特征的節點表示向量。

圖1 AE-MVANR框架Fig.1 Framework of AE-MVANR
2.3 屬性結構視圖的構造
鄰接矩陣A體現了網絡中節點固有的拓撲結構。然而,網絡中不直接相連的節點也會存在一定的相似關系。例如圖1 中,節點1 和節點2 之間沒有連邊,節點2 和節點3 有連邊。分析它們的屬性特征可以發現,節點2和節點3擁有一個共同屬性(屬性d),同樣地,節點1 和節點2 也擁有一個共同屬性(屬性d),據此可推斷出節點1 和節點2 具有較高的相似性。
為了更加全面真實地刻畫網絡中節點之間的關系,AEMVANR 利用節點間相同屬性的共現頻率作為衡量節點相似性的指標,對網絡中隱藏的屬性結構信息進行深度挖掘。如式(1)~(2)所示,兩個節點間屬性的共現頻率越高,表明兩個節點越相似。根據節點間的屬性共現頻率可進一步構造生成節點相似性矩陣S,具體構造方法如算法1所示。


其中:第1)~5)行計算了節點屬性共現矩陣F,此時Fij≥0;第6)行將F進行歸一化,此時0≤Fij≤1;第7)~10)行對每個節點篩選了與其共現頻率最高的前c個節點,本文默認c取網絡平均度avgk的上整;第11)行返回節點相似性矩陣S。
AE-MVANR 通過節點間的屬性共現頻率計算生成節點相似性矩陣S,并根據該矩陣構造生成ASV,參數c的取值意味著每個節點最多可添加c條邊,此舉不僅挖掘了隱藏屬性網絡的結構信息而且極大簡化了ASV。如圖1 所示,ASV 中有4個節點和4條邊。
2.4 隨機游走算法
節點相似性矩陣S體現了節點之間的隱含屬性結構關系,是對鄰接矩陣A的重要補充。為了充分利用網絡中原拓撲結構信息和隱含的屬性結構信息,AE-MVANR 在TSV 和ASV上分別采用隨機游走算法[11]進一步提取網絡中節點之間的關系。具體策略如式(5)~(7)所示。

式(5)表示在給定當前節點i,訪問下一個節點j的概率。其中:πij是節點i和節點j未歸一化的轉移概率;Z是歸一化常數;wij是節點i和節點j之間邊的權重;Sij是節點i和節點j之間的相似度;distance(k,j)是節點k和節點j之間的最短距離。參數p控制回到原節點的概率,p越高訪問原節點的概率越低。q控制跳到其他節點的概率:若q>1,隨機游走傾向于廣度優先;若q<1,隨機游走傾向于深度優先。
AE-MVANR 將TSV 和ASV 分別輸入到該隨機游走算法中,可得到基于兩個視圖的節點序列;然后把這兩種序列輸入到基于LSTM 的自編碼器中進行訓練;最終可得到融合結構信息和屬性信息的節點表示向量。
2.5 基于LSTM的自編碼器
為了更好地捕捉節點序列的先后關系、網絡結構信息和節點屬性信息,AE-MVANR 采用基于LSTM 的自編碼器作為網絡表示學習模型,基于LSTM的自編碼器結構如圖2所示。

圖2 基于LSTM的自編碼器結構Fig.2 Framework of LSTM-based auto-encoder model
如圖2 所示,自編碼器由三部分組成:輸入層、隱藏層和輸出層。輸入層和隱藏層之間為編碼過程,隱藏層和輸出層之間為解碼過程。輸入層和輸出層具有相同規模。AEMVANR 采用LSTM 構造編碼解碼過程。LSTM 是一種時間循環神經網絡,適用于處理和預測時間序列中間隔和延遲非常長的重要事件,詳細介紹可參見文獻[26]。
如圖1 所示,AE-MVANR 首先將在原拓撲結構視圖和隱藏屬性結構視圖獲得的節點序列向量化,經LSTM 編碼,獲得一種通用的編碼表示,然后經過解碼獲得輸入序列的重構,最后通過最小化重構誤差函數不斷優化學習效果,并提取隱藏層中的信息作為節點的表示。AE-MVANR 定義的目標函數如式(8)~(12)所示:


由于網絡的稀疏性,輸入向量非零元素遠遠少于零元素。式(8)對零元素引入懲罰項,其中⊙指Hadamard 乘積。為防止函數過擬合,式(11)引入正則化的L2 范數,式(12)進一步采用權重參數α來權衡兩個不同的部分。
3 實驗與結果分析
3.1 數據集
本文采用兩個規模不同的網絡數據集WebKB和citeseer,其中WebKB 包含4 個小數據集texas、washington、cornell 和wisconsin。由于本文討論的是無向網絡的節點表示學習,所以將這些數據集中的有向網絡轉化為無向網絡。經處理后的各數據集的相關統計信息說明如表1 所示。其中,t代表屬性維度,#label代表標簽個數,avgk表示網絡的平均度。

表1 數據集詳細信息Tab.1 Detailed information of datasets
3.2 對比方法
為了評估本文所提算法AE-MVANR 的性能,本文實驗中分別與七種現有的網絡表示學習方法和兩種基于AEMVANR改進的算法進行了比較。
3.2.1 基于拓撲結構的網絡表示學習算法
1)DeepWalk[9]。該算法利用隨機游走策略在網絡中獲得一系列節點序列,然后將每個節點序列視為一個句子,輸入到Skip-Gram 模型中,通過最大化預測節點上下文的概率學習該節點的低維向量表示。
2)node2vec[11]。該算法基于DeepWalk 模型,結合深度優先和廣度優先方法,使抽樣的路徑能更大程度上同時保存網絡的局部特征和全局特征。
3)LINE[10]。該算法基于DeepWalk 模型,進一步挖掘了網絡中節點之間的關系。它將節點之間的直接連接關系定義為一階相似性,將存在共同鄰居卻不直接相連的節點關系定義為二階相似性。通過引入二階相似性,LINE 極大緩解了網絡中的數據稀疏問題。
4)SDNE[13]。該算法使用深層神經網絡對節點間的非線性關系進行建模,更好地捕捉了網絡中高階非線性特征,最終將深層自編碼器的中間層作為節點的表示。
3.2.2 綜合運用拓撲結構和節點屬性的網絡表示學習算法
1)TADW[14]。該算法基于矩陣分解,將富含文本屬性信息的矩陣加入到矩陣分解的過程中,最終得到融合了兩種信息的節點表示向量。
2)ASNE[20]。該算法將結構信息和離散屬性信息同時輸入深度神經網絡,并采用前融合對兩種信息進行深度融合,學習每個節點的低維表示向量。
3)STNE[19]。該算法基于seq2seq 的模型框架,利用雙向LSTM的自翻譯機制將內容信息序列翻譯為對應的結構序列,從而將內容信息和結構信息無縫融合到隱藏層的潛在向量中,可更加高效地表示節點。
3.2.3 基于AE-MVANR改進的相關算法
1)AE-MVANR(RW)。為了驗證隨機游走算法對于AEMVANR 的影響,本文將隨機游走算法部分刪除,得到其刪減版本AE-MVANR(RW)。
2)AE-MVANR(AE)。為了驗證基于LSTM 的自編碼器對于AE-MVANR 的影響,本文將基于LSTM 的自編碼器替換為自編碼器,得到其簡易版本AE-MVANR(AE)。
3.3 參數設置
為保證算法對比的公平,本文將WebKB 數據集中節點表示向量維度統一設置為d=64,citeseer 數據集中節點表示向量維度統一設置為d=128,其余參數設置為默認值。
AE-MVANR 參數設置:每個節點添加的邊條數c=3,節點序列條數w=1,節點序列長度l=10。WebKB 數據集批次大小b=32,迭代次數r=30;citeseer 數據集批次大小b=64,迭代次數r=50。
3.4 實驗環境
硬件環境為Intel Core i5-2400 CPU@3.10 GHz,4.00 GB內存;軟件環境為ubuntu18.04.2 LTS系統,Python 3.7.1。
3.5 節點分類
節點分類指利用已分類節點的信息,為未分類節點標記一個類別,它是節點特征學習效果衡量的一個常見任務。為了評估算法準確性,本文將實驗數據集隨機且獨立地分為訓練集和測試集,將數據中的70%用作訓練集,剩余數據用作測試集。采用邏輯回歸(Logistic Regression,LR)作為分類算法,評價準則采用準確率(Accuracy)。表2 是各算法在WebKB和citeseer數據集上的分類結果。

表2 不同算法的節點分類準確率對比Tab.2 Node classification accuracies of different algorithms
從表2 中可以看出,AE-MVANR 及其相關算法在WebKB數據集中準確率均優于對比算法,在citeseer 數據集中和TADW 算法表現相同。這可能是因為WebKB 的網絡規模較小,AE-MVANR 及其相關算法深度挖掘到的隱藏網絡結構信息在較大程度上補充了其原拓撲結構信息的不足。AEMVANR(RW)在cornell 數據集中準確率優于AE-MVANR,在wisconsin 數據集中準確率與AE-MVANR 相同,這可能是因為這兩個數據集的網絡密度較小,隨機游走算法在這兩個數據集中得到了較多的冗余節點序列信息,反而導致AE-MVANR表現不佳。相較于AE-MVANR 和AE-MVANR(RW),AEMVANR(AE)在WebKB 和citeseer 數據集上表現較差,這可能是因為基于LSTM 的自編碼器能夠更好地挖掘節點之間的潛在結構關系。
3.6 節點聚類任務分析
節點聚類將網絡中的節點劃分為若干集群,使得同一集群內的節點相似而不同集群的節點相異。本文采用經典的聚類方法K-means 方法對各個數據集進行聚類實驗,WebKB 的聚類個數設為5,citeseer的聚類個數設為6。評價指標采用標準化互信息(Normalized Mutual Information,NMI)、輪廓系數(Silhouette Coefficient)和戴維森堡丁指數(Davies Bouldin Index,DBI)。其中,NMI 的取值范圍是0 到1,值越大表明聚類結果越好;Silhouette Coefficient 的取值范圍是-1 到1,值越大表明聚類結果越好;DBI 的取值最小是0,值越小表明聚類結果越好。聚類結果分別如表3~5所示。
表3 展示了不同算法在WebKB 和citeseer 數據集上的聚類效果,評價指標為NMI。可以看出,AE-MVANR 在texas、washington 和citeseer 數據集上聚類效果明顯優于其他算法。AE-MVANR(AE)在cornell 數據集中表現最佳,這可能是因為該數據集網絡密度較小,在隨機游走算法中得到了較多的冗余節點序列信息,然而這些冗余信息更加突出了節點間的聚類特征。AE-MVANR(RW)在wisconsin 數據集中表現最佳,這可能是因為AE-MVANR 在隨機游走算法中得到了較多的冗余節點序列信息,使得基于LSTM 的自編碼器在訓練過程中受到影響,因此導致AE-MVANR表現欠佳。
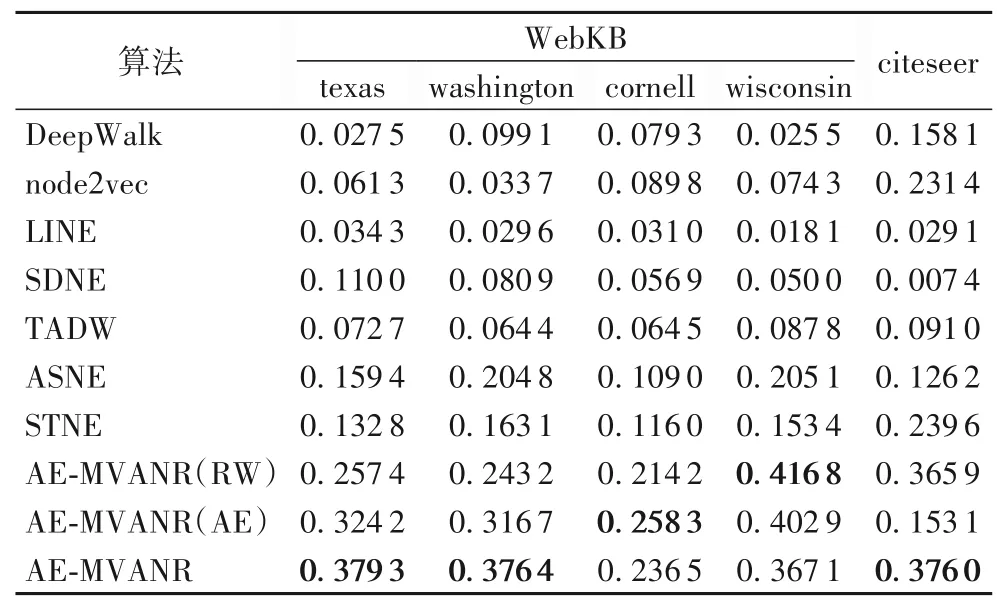
表3 不同算法的節點聚類結果的NMITab.3 NMI performance of node clustering results of different algorithms
表4 展示了不同算法在WebKB 和citeseer 數據集上的聚類效果,評價指標為Silhouette Coefficient。可以看出,AEMVANR 在texas 數據集上聚類效果明顯好于其他算法。AEMVANR(RW)在cornell、wisconsin 和citeseer 數據集上表現最佳,這可能是因為這三個數據集的網絡密度較小,而AEMVANR(RW)沒有隨機游走算法過程,不必對大量重復冗余序列進行訓練,結果反而更好。AE-MVANR(AE)在washington 數據集上表現最佳,這可能是因為washington 數據集的網絡平均度較高,隨機游走算法可以更加全面地捕捉網絡中的信息。

表4 不同算法的節點聚類結果的Silhouette CoefficientTab.4 Silhouette Coefficient performance of node clustering results of different algorithms
表5 展示了不同算法在WebKB 和citeseer 數據集上的聚類效果,評價指標為DBI。可以看出,AE-MVANR算法在texas和cornell 數據集上聚類效果明顯優于其他算法。AE-MVANR(RW)在wisconsin 數據集中表現最佳,這可能是因為該數據集網絡密度較小,AE-MVANR(RW)缺少隨機游走過程,使得LSTM 在訓練過程中沒有出現過擬合現象。AE-MVANR(AE)在washington 數據集中表現最佳,這可能是因為隨機游走算法在平均度較高的網絡中可以更加全面地捕捉信息。

表5 不同算法的節點聚類結果的DBITab.5 NMI performance of node clustering results of different algorithms
總結以上聚類實驗可以看出:DeepWalk、node2vec、LINE和TADW 算法表現較差,這可能是因為它們不適合聚類任務;結合外部信息的網絡表示模型TADW、ASNE、STNE 在大多數數據集上的聚類效果優于基于網絡結構的網絡表示算法DeepWalk、node2vec、LINE、SDNE,這也在一定程度上表明綜合運用拓撲信息和屬性信息比僅利用拓撲信息更能保持網絡結構及網絡信息。
3.7 參數敏感性分析
為了驗證AE-MVANR 的參數敏感性,本文對節點表示向量維度d、節點序列條數w和構造ASV每個節點添加的邊條數c的取值進行對比分析,并基于WebKB 數據集做分類實驗。圖3 給出了它們對分類準確率的影響。從圖3 可看出:texas數據集隨著d的增長,準確率逐漸趨于穩定,說明texas對參數d的敏感性較低;washington、cornell和wisconsin 三個數據集隨著d的增長,準確率浮動在一定范圍內,但沒有明顯規律,說明這三個數據集對參數d較為敏感。
隨著w的增加,wisconsin 和washington 數據集的準確率并無明顯上升,而texas 和cornell 的準確率有較明顯的上升,這可能是因為wisconsin 和washington 中節點的平均度較高,隨機游走算法可以在序列條數較少時獲得較為全面的網絡結構信息,當序列條數變多時,冗余信息反而增加;而texas 和cornell 中節點平均度相對較低,隨機游走算法在序列條數增多時可獲得更多網絡結構信息。
隨著c的增加,texas、washington、cornell、wisconsin 數據集的準確率沒有受到影響。這可能是因為數據具有稀疏性,相似性較高的節點對較少,所以當c取值較小時,也可以獲得較全面的網絡結構信息。

圖3 WebKB上參數敏感性對分類結果的影響Fig.3 Influence of parameter sensitivity on classification results on WebKB
4 結語
本文提出了一種基于自編碼器的多視圖屬性網絡表示學習模型AE-MVANR,該模型利用屬性網絡中的網絡結構信息和節點屬性信息分別構造拓撲結構視圖和屬性結構視圖,基于拓撲結構視圖和屬性結構視圖深度挖掘不同節點間的內在聯系。然后利用隨機游走算法在兩個視圖上分別獲取節點序列,再通過基于LSTM 的自編碼器進行訓練,最終得到融合了結構信息和屬性信息的節點表示向量。分類和聚類實驗結果表明,AE-MVANR 學習到的節點表示向量能更好地保持網絡的不同特性,更好地完成后續任務。
現階段由于服務器配置限制,只在中小規模數據集上對本文算法進行了驗證,在后期的工作中,將引入更大數據量的數據進行性能展示。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
