基于坐標(biāo)逆映射的增強(qiáng)型車輛三維全景影像
2021-04-20 14:07:28譚兆一陳白帆
計算機(jī)應(yīng)用 2021年4期
譚兆一,陳白帆
(1.中南大學(xué)自動化學(xué)院,長沙 410083;2.倫敦大學(xué)學(xué)院計算機(jī)科學(xué)系,倫敦WC1E 6BT,英國)
0 引言
隨著汽車高級駕駛輔助系統(tǒng)(Advanced Driver Assistance System,ADAS)的發(fā)展,用于解決車輛盲區(qū)問題的車輛三維全景影像系統(tǒng)(下文簡稱為“三維全景影像”)越來越普及[1]。這類系統(tǒng)通過安裝在車身四周的魚眼相機(jī)來采集圖像,經(jīng)過魚眼相機(jī)參數(shù)標(biāo)定,利用合成算法將采集到的圖像生成為虛擬場景,并允許駕駛員調(diào)整觀察角度[2-7]。三維全景影像系統(tǒng)能夠較好地彌補(bǔ)二維全景影像系統(tǒng)[8-10](又稱“360 度倒車影像”,即合成一幅鳥瞰全景圖)中觀察角度有限、顯示范圍不夠大、三維物體顯示失真等問題。但由于三維全景影像使用的投影模型中還存在有“地面”部分,所以仍然會對靠近自身的三維物體如車輛和行人產(chǎn)生顯示畸變,使駕駛員無法準(zhǔn)確判斷這些物體位置。而行車過程中,靠近自身的物體往往都具有較大安全隱患,對這些物體的顯示不當(dāng)實則會降低系統(tǒng)的實用性,如圖1中箭頭所示。

圖1 三維全景影像系統(tǒng)對三維物體的顯示畸變Fig.1 Display distortion of 3D objects in 3D surround view system
目前,有少量研究對此缺陷進(jìn)行了改進(jìn)。文獻(xiàn)[11]預(yù)先建立了不同長寬比、不同大小的投影模型,后利用雷達(dá)感知車身周邊環(huán)境深度信息,選取最符合當(dāng)前場景的投影模型,使靠近自身的三維物體投影至模型的“墻面”上而不是“地面”上,從而減少對三維物體的顯示畸變。但該方法只可粗略地估計車身周圍環(huán)境,當(dāng)環(huán)境中出現(xiàn)了多個三維物體時則無法對每個三維物體都做到顯示優(yōu)化。文獻(xiàn)[12]結(jié)合雷達(dá)信息與雙目測距原理,共同估計出精確的環(huán)境三維信息后,建立符合當(dāng)前場景的專一性投影模型后進(jìn)行投影。該方法可以更精確地解決每個大型三維物體的顯示畸變問題,但由于需要動態(tài)改變投影模型形狀導(dǎo)致實時性降低,且形狀特殊的投影模型還可能會對其他景物造成投影畸變。
上述兩種方法中,都是利用可變式投影模型來解決投影畸變問題,且共同使用了雷達(dá)傳感器用于測量景深[13-14],這樣不僅造成了系統(tǒng)成本的上升還使處理過程復(fù)雜化。通過分析可知,行車過程中駕駛員最關(guān)心的三維物體只有其他車輛和行人兩類(下文將其二者合稱為“感興趣物體”),所以本文綜合應(yīng)用場景特點,提出了一種增強(qiáng)型三維全景影像的合成方法,結(jié)合物體檢測和坐標(biāo)升維逆映射,將提前預(yù)制的感興趣物體的三維模型渲染顯示在估計位置上,從而解決了上述問題。對比現(xiàn)有解決方案,本文方法具有以下優(yōu)勢:1)可以直觀且突出地顯示車身周圍其他車輛及行人的位置;2)在顯示感興趣物體時不會對其他景物造成投影畸變,整體觀感舒適;3)不需要借助其他深度傳感器;4)由于可使用固定投影模型,故可利用查找表(Look Up Table,LUT)保證實時性;5)能最大化地在顯示中保持地面道路的平直性。綜合以上,本文方法具有較高的應(yīng)用價值。
本文將首先介紹基礎(chǔ)三維全景影像的合成算法并淺析其顯示畸變成因,之后提出本文的增強(qiáng)型三維全景影像合成方法,最后通過實驗驗證本文方法的各項性能指標(biāo)。
1 基礎(chǔ)三維全景影像合成算法
基礎(chǔ)三維全景影像的合成算法主要包括兩大步驟:魚眼相機(jī)標(biāo)定和投影模型的映射。
1.1 相關(guān)參數(shù)
映射過程需要基于三個坐標(biāo)系,分別是世界坐標(biāo)系、相機(jī)坐標(biāo)系和像素坐標(biāo)系。先將世界坐標(biāo)系下的點通過相機(jī)外參轉(zhuǎn)換至相機(jī)坐標(biāo)系,而后通過相機(jī)內(nèi)參再轉(zhuǎn)換至像素坐標(biāo)系。通過兩次坐標(biāo)變換,建立真實世界中的位置坐標(biāo)與圖像中位置坐標(biāo)的映射關(guān)系。
相機(jī)外參反映了相機(jī)的安裝姿態(tài),負(fù)責(zé)世界坐標(biāo)系向相機(jī)坐標(biāo)系的映射,映射過程實質(zhì)為兩個三維坐標(biāo)系的平移旋轉(zhuǎn)變換。變換關(guān)系如式(1)所示:

其中:下標(biāo)w 表示世界坐標(biāo)系;下標(biāo)c 表示相機(jī)坐標(biāo)系;[R|T]∈R3×4表示外參矩陣,由旋轉(zhuǎn)和平移兩部分構(gòu)成。
廣義的相機(jī)內(nèi)參包括相機(jī)內(nèi)參矩陣和相機(jī)畸變參數(shù)兩部分,其反映的是相機(jī)內(nèi)部光學(xué)結(jié)構(gòu),與相機(jī)自身的特性有關(guān),主要負(fù)責(zé)相機(jī)坐標(biāo)系向像素坐標(biāo)系的映射過程,是三維到二維的映射過程,同時也是物理長度單位向像素長度單位轉(zhuǎn)換的過程。魚眼相機(jī)內(nèi)參反映的變換如下:
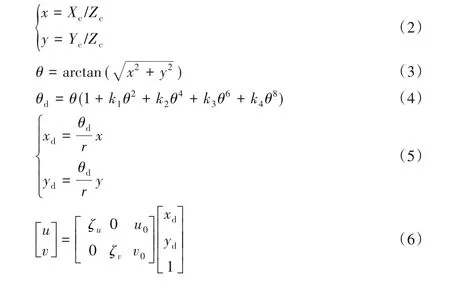
其中:下標(biāo)c 表示相機(jī)坐標(biāo)系;下標(biāo)d 表示各變量在魚眼相機(jī)畸變下的表示;k1~k4表示魚眼相機(jī)畸變參數(shù);(u,v)表示像素坐標(biāo)系下的坐標(biāo)點;ζu、ζv是在u軸與v軸方向上的長度單位轉(zhuǎn)換因子;u0、v0表示坐標(biāo)原點平移量,一般分別為圖像長寬的一半。
基于上述轉(zhuǎn)換原理,利用張正友標(biāo)定法,借助相機(jī)標(biāo)定棋盤格分別標(biāo)定出四路魚眼相機(jī)的內(nèi)參、外參矩陣及畸變參數(shù)[15]。
1.2 投影模型映射
投影模型建立了一個虛擬的車身周邊環(huán)境,其上的點作為世界坐標(biāo)系下的點,通過上述映射關(guān)系得到對應(yīng)的像素坐標(biāo)(即四幅圖像中的點),并將對應(yīng)圖像點的RGB(Red,Green,Blue)信息渲染在投影模型上即可完成基礎(chǔ)三維全景影像的合成工作。投影模型一般為固定的“碗狀”或“船形”模型,根據(jù)車輛行駛過程中周邊環(huán)境的一般特點而建立,即車身四周較近區(qū)域為“地面”,而遠(yuǎn)離車身區(qū)域為立體的“墻面”,如圖2 所示。使用這樣的投影模型可以在多數(shù)情況下,能恰到好處地將路面投影至模型“地面”,將車輛等三維物體投影至模型“墻面”,保證物體投影關(guān)系正確從而不產(chǎn)生畸變。

圖2 三維全景影像使用的投影模型Fig.2 Projection model used for 3D surround view
1.3 畸變分析
由于基礎(chǔ)三維全景影像所使用的投影模型是預(yù)先按照經(jīng)驗建立的,不可能適應(yīng)于所有場景,所以當(dāng)車輛所處的真實三維環(huán)境和模擬創(chuàng)建出的投影模型不匹配時將導(dǎo)致顯示畸變。畸變主要分為以下兩類:第一類是將真實世界中的三維物體錯誤地映射至投影模型的“地面”區(qū)域引起的,從而導(dǎo)致三維物體的劇烈拉伸,如圖3(a)所示;第二類是將真實世界中的地面錯誤地映射至投影模型的“墻面”而引起的,會改變地面道路的平直性,參考圖3(b)中道路雙黃線的顯示彎折。

圖3 兩類畸變示意圖Fig.3 Illustration of two types of distortion
簡單地通過改變投影模型大小的方式往往難以同時優(yōu)化這兩類畸變。當(dāng)擴(kuò)大投影模型時可以緩解道路彎折畸變,但會讓更多車輛及行人等三維物體落入投影模型的“地面”區(qū)域從而加重物體拉伸畸變;反之,縮小投影模型雖然可使多數(shù)三維物體投影在“墻面”上保證正確,但卻無法保證地面道路的平直性,且在動態(tài)調(diào)整模型的過程中容易出現(xiàn)顯示畫面跳動,影響顯示效果。
2 車輛增強(qiáng)型三維全景影像
由上述分析可知,自適應(yīng)投影模型方法在解決畸變問題時往往容易“顧此失彼”,所以本文針對顯示畸變問題和當(dāng)前解決方案的不足,提出了一種增強(qiáng)型三維全景影像的合成方法,借助YOLOv4(You Only Look Once v4)檢測網(wǎng)絡(luò)和本文提出的坐標(biāo)升維逆映射方法,在不動態(tài)改變投影模型的基礎(chǔ)上,將車輛周邊的三維物體以虛擬合成方式重新呈現(xiàn)出來。本文的研究重點將在于如何將感興趣物體檢出并通過圖像估計出其準(zhǔn)確的世界空間位置。步驟如下:首先把四路相機(jī)拍攝到的原始圖像作為物體檢測網(wǎng)絡(luò)的輸入,識別并框選出所有感興趣物體;之后利用物體的像素坐標(biāo),通過本文提出的坐標(biāo)升維逆映射方法估計出此物體在世界坐標(biāo)系中的位置;而后對估計位置進(jìn)行一系列數(shù)據(jù)處理后,得到精確的物體位置;最后再把提前建立好的車輛及行人通用模型放置并渲染在估計位置上,它將覆蓋顯示被錯誤映射在“地面”上的三維物體。總流程如圖4 所示。本文方法可以在解決“物體拉伸畸變”的同時盡量削弱“道路彎折畸變”,在提供準(zhǔn)確的物體位置信息的同時使顯示更自然。

圖4 車輛增強(qiáng)型三維全景影像合成方法流程Fig.4 Flowchart of enhanced vehicle 3D surround view synthesis method
2.1 感興趣物體檢測
近年來,卷經(jīng)神經(jīng)網(wǎng)絡(luò)在物體檢測任務(wù)中體現(xiàn)出了不可比擬的優(yōu)勢。其中YOLOv4 物體檢測網(wǎng)絡(luò)將物體檢測與分類工作都放在一個神經(jīng)網(wǎng)絡(luò)中完成,同時很好地兼顧了大、中、小各種尺寸的物體的檢測效果,在檢測速度極快的同時也保證了極高的準(zhǔn)確率與召回率[16]。
本文中,由于物體檢測網(wǎng)絡(luò)將應(yīng)用在畸變較大的魚眼相機(jī)圖像中,因而需要針對魚眼相機(jī)圖像訓(xùn)練專一性的檢測模型。訓(xùn)練類別分為行人和車輛兩類。訓(xùn)練數(shù)據(jù)由直接采集和軟件合成兩部分組成。在使用神經(jīng)網(wǎng)絡(luò)對感興趣物體進(jìn)行預(yù)測時,只保留極高置信度的物體邊界框,在損失一定召回率的基礎(chǔ)上保證較高的檢測準(zhǔn)確率。將邊界框記作其中(u1,v1)和(u2,v2)分別表示邊界框左上角與右下角的像素坐標(biāo)。而后將邊界框位置信息送入下一階段工作——世界位置估計。
2.2 基于坐標(biāo)升維逆映射的世界位置估計
世界位置估計是本文的核心內(nèi)容,它是由一系列坐標(biāo)逆映射來完成的。由于成像過程中,從三維至二維的降維映射會造成信息損失,所以理論上無法完成從像素坐標(biāo)系到世界坐標(biāo)系的升維逆映射。但本文根據(jù)應(yīng)用場景特點,利用感興趣物體在多數(shù)情況下都符合“處于地面上”的特征,補(bǔ)充條件Zw=0(下標(biāo)w 表示世界坐標(biāo)系)從而使升維逆映射得以完成。
首先對應(yīng)于補(bǔ)充條件,取檢出邊界框的下邊緣中心點作為物體的“觸地點”進(jìn)行位置估計。觸地點像素坐標(biāo)(ug,vg)可由ug=(u1+u2)/2和vg=v2計算得出(下標(biāo)g表示“觸地點”)。
而后,根據(jù)式(6)的逆變換,將“觸地點”像素坐標(biāo)轉(zhuǎn)換為xd與yd。此步驟是像素長度單位向物理長度單位的轉(zhuǎn)換,同時也是坐標(biāo)原點從圖像左上角移動至圖像中心的過程。轉(zhuǎn)換如式(7)所示:

之后需要將畸變圖像坐標(biāo)轉(zhuǎn)換至非畸變圖像坐標(biāo),即將(xd,yd)轉(zhuǎn)換為(x,y)。聯(lián)立式(5)中兩個等式,可計算出θd:

后將θd代入式(4)中。由于式(4)為關(guān)于未知量θ的一元高次方程,且為奇次方程,故存在一個實根,可通過二分法迭代求解出未知量θ[8]。而后結(jié)合式(3)、(5),完成向非畸變圖像坐標(biāo)系下的轉(zhuǎn)換,如式(9)所示:

之后,將(x,y)代入式(2)繼續(xù)求逆變換的過程中,如上所述,由于缺少景深信息Zc,使用數(shù)學(xué)方法則無法完成此步驟。而本文可通過補(bǔ)充的條件Zw=0 計算出Zc,從而完成從二維到三維坐標(biāo)的逆映射。
由補(bǔ)充條件Zw=0 計算出Zc的過程是基于式(1)的逆運(yùn)算完成的。為了求逆,先將非方陣形式的外參矩陣[R|T]補(bǔ)全為齊次矩陣表示為D,如式(10)所示:

之后對矩陣D求逆,將求逆結(jié)果記作矩陣A,則式(1)的逆過程如式(11)所示:

將已知條件Zw=0 代入,只觀察式(11)中Zw的生成過程,可單獨(dú)列寫出如下方程:

結(jié)合式(2),可將式(12)繼續(xù)改寫為:

至此,關(guān)鍵附加條件Zc便可獲得,而后便可獲得此像素點在相機(jī)坐標(biāo)系下的表示,如式(15)。升維逆映射工作完成。

在求得感興趣物體中心“觸地點”在相機(jī)坐標(biāo)系下的表示后,最終通過式(11),可完成最后一步:從相機(jī)坐標(biāo)系到世界坐標(biāo)系的轉(zhuǎn)換。通過上述步驟,最終可以利用像素坐標(biāo)點初步估計出感興趣物體在世界坐標(biāo)系下的位置。
2.3 重影位置合并
當(dāng)感興趣物體同時出現(xiàn)在兩相機(jī)的交叉視野中且被檢出時,兩相機(jī)會根據(jù)2.2 節(jié)的位置估計方法分別估計出一個對應(yīng)的世界位置。由于魚眼相機(jī)畸變及檢測框不準(zhǔn)確等原因?qū)е聝蓚€估計位置一般不重合,則還需對同一物體的兩個位置進(jìn)行合并。
根據(jù)感興趣物體類別,本文使用歐氏距離通過設(shè)定不同的距離閾值對小于閾值的兩位置點進(jìn)行合并。如車輛類,若場景中真實存在兩輛汽車且被檢出,則兩個估計點的位置間距應(yīng)至少大于車輛的長或?qū)挘∮谲囕v長寬的兩位置點則大概率為重復(fù)估計點。所以對于車輛類,將車輛長寬平均值設(shè)置為合并距離閾值,對于小于閾值的兩點通過計算二者平均位置進(jìn)行合并,合并效果如圖5(b)所示。圖5(a)為前后左右四路魚眼相機(jī)拍攝原圖及檢測結(jié)果,圖5(b)是對應(yīng)于圖5(a)的感興趣物體位置估計結(jié)果。圖5(b)中,中央正方體表示本車,P1位置兩圓點為車輛估計位置,兩點之間的點為車輛合并位置,P2位置的點表示行人估計位置。由圖5(a)可看出由于越野車模型同時在后方、右側(cè)相機(jī)圖像中被檢出,因而有兩個估計位置點,而兩點位置過近,則需要合并。

圖5 感興趣物體的位置合并Fig.5 Position merging of objects of interest
2.4 路徑濾波
在單幀進(jìn)行估計位置合并后,便可得到連續(xù)幀中感興趣物體的運(yùn)動軌跡。由于檢測網(wǎng)絡(luò)在每一幀的表現(xiàn)差異,如在某些幀的漏檢、誤檢,會造成同一物體點在幀與幀之間的位置跳動,因此設(shè)計一個路徑濾波器對跳動點進(jìn)行平滑濾波。
路徑濾波器主要由兩部分構(gòu)成:數(shù)據(jù)預(yù)測和數(shù)據(jù)融合。
數(shù)據(jù)預(yù)測工作是建立在統(tǒng)計前n次物體位置的變化規(guī)律上的。在地面建立二維坐標(biāo)系xoy,則預(yù)測值可由式(16)推導(dǎo)出:
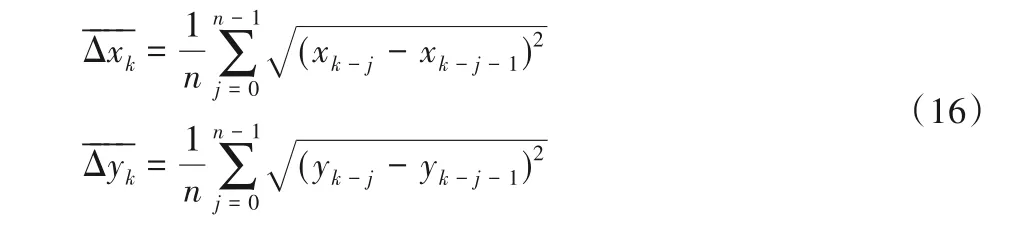
其中:k表示當(dāng)前幀的序號;n是設(shè)定的平滑值數(shù)量,表示當(dāng)前預(yù)測值需要依賴于前n幀的物體平均變換規(guī)律得出。數(shù)值越大,平滑效果越好,但預(yù)測的滯后性偏大。數(shù)值越小,會損失一定的平滑性但可以提高跟隨性能,考慮到系統(tǒng)的實時性要求,設(shè)定n=3。之后利用變化量平均值預(yù)測下一點的位置,如式(17)所示:

把通過邊界框估計出的位置記為測量值,將由前幾幀變化趨勢預(yù)測出的位置記為預(yù)測值,則需要在每幀權(quán)衡預(yù)測值與測量值之間的關(guān)系進(jìn)行數(shù)據(jù)融合。參考卡爾曼濾波原理,使用動態(tài)權(quán)重方法來權(quán)衡輸出值的構(gòu)成比例。由于精度要求不高,將權(quán)重設(shè)為兩檔離散型。利用每幀測量值和預(yù)測值的歐氏距離作為衡量標(biāo)準(zhǔn),并確定合適的閾值,當(dāng)距離大于此閾值時,便認(rèn)為測量值出現(xiàn)錯誤,動態(tài)調(diào)整測量值的權(quán)重為一個很小的值,使其對輸出的影響降至最小;反之恢復(fù)正常權(quán)重比。閾值根據(jù)幀率按類別設(shè)定。如車輛類,若已知幀與幀間隔時間為t,車輛行駛平均速度估計為vˉ,則設(shè)定距離閾值為·t。
圖6 展現(xiàn)了使用路徑濾波器對物體運(yùn)動軌跡進(jìn)行濾波的效果。圖6(a)為不使用路徑濾波器對車輛及行人運(yùn)動軌跡估計的結(jié)果,圖6(b)為使用路徑濾波器后的輸出軌跡。結(jié)果顯示濾波器對誤檢測點有很好的過濾作用,保證了感興趣物體運(yùn)動軌跡的連貫性。

圖6 路徑濾波器對兩次運(yùn)動軌跡的濾波結(jié)果Fig.6 Filtering results of two motion trajectories using path filter
2.5 模型放置與渲染
本文使用3ds Max 對需要虛擬顯示的車輛和行人進(jìn)行建模。由于四路魚眼相機(jī)安裝在車身四周且向外拍攝,則無法獲取當(dāng)前自身車輛的圖像,因而需要提前建立本車模型并放置在場景中心以遮蓋合成場景中圖像信息缺失部分。而后,對其他車輛和行人兩類物體建立通用模型,并結(jié)合上述估計出的位置將通用模型放置并渲染在三維場景中,用于更好地展現(xiàn)被錯誤映射而產(chǎn)生畸變的相應(yīng)三維物體。
3 實驗與結(jié)果分析
3.1 實驗平臺
本文方法在實現(xiàn)時共分為兩大部分:對三維場景的生成和對神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。筆記本電腦負(fù)責(zé)完成場景生成工作,硬件配置為CPU:i7-7500U,GPU:Nvidia GeForce 940MX 2 GB顯卡,運(yùn)行內(nèi)存8 GB。臺式服務(wù)器用于訓(xùn)練神經(jīng)網(wǎng)絡(luò),配置為CPU:AMD Ryzen5,GPU:Nvidia RTX2080 8 GB顯卡,運(yùn)行內(nèi)存16 GB。
軟件配置方面,場景生成工作借助于OpenCV 和OpenGL共同完成。在OpenCV 中完成相機(jī)標(biāo)定、相機(jī)圖像讀取、地面二維全景圖像合成工作,在OpenGL 中借助OpenCV 生成的地面貼圖和讀取的四路相機(jī)圖像完成三維環(huán)境的渲染工作,基于開發(fā)平臺Visual Studio 2017,使用C++語言編寫;神經(jīng)網(wǎng)絡(luò)訓(xùn)練基于PyTorch 框架,基于開發(fā)平臺PyCharm,使用Python語言編寫,并使用 CUDA(Compute Unified Device Architecture)加速。
魚眼相機(jī)視場角為180°,使用分辨率640×480,幀率為30 frame/s。光屏傳感器型號為CMOS 1/2.7,成像距離為2 cm至無窮遠(yuǎn)。
搭建了模擬道路為測試環(huán)境,使用長寬高分別為400 mm×300 mm×200 mm的箱子固定四路魚眼相機(jī),使用汽車和行人模型進(jìn)行檢測實驗。如圖7是搭建的實驗環(huán)境。

圖7 實驗環(huán)境Fig.7 Experimental environment
3.2 模型訓(xùn)練
由于輸入圖像為魚眼相機(jī)畸變圖像,所以需要在YOLOv4 預(yù)訓(xùn)練模型的基礎(chǔ)上微調(diào)訓(xùn)練以適應(yīng)于本研究的應(yīng)用場景。訓(xùn)練數(shù)據(jù)來源于兩部分:一部分為采集到的四路魚眼相機(jī)的視頻流,以5 frame/s 幀率保存四路相機(jī)圖片,最終共獲得約860 張圖片并進(jìn)行手動標(biāo)注;另一部分來源于計算機(jī)的自動生成。式(2)~(6)描述了從小孔相機(jī)模型至魚眼相機(jī)模型的映射關(guān)系,因而可以將普通非畸變圖像利用上式轉(zhuǎn)換為魚眼相機(jī)圖像,并與多種背景相融合,可批量快速生成大量帶有標(biāo)注的訓(xùn)練數(shù)據(jù),尤其適合在傳統(tǒng)大型數(shù)據(jù)集的基礎(chǔ)上快速生成大量魚眼相機(jī)訓(xùn)練數(shù)據(jù),如ImageNet、MS COCO(MicroSoft Common Objects in COntext)實驗中通過此方法共生成約3 000 張圖片。如圖8 所示,無畸變的原始圖片通過調(diào)整參數(shù)可分別獲得具有不同畸變程度和不同畸變位置的魚眼圖像,從而模擬真實魚眼相機(jī)拍攝到的圖像。

圖8 計算機(jī)自動生成的模擬魚眼畸變圖像Fig.8 Simulated fisheye distortion images generated by computer automatically
最終總計獲得約3 800 張訓(xùn)練數(shù)據(jù),將其以1∶10 比例分成驗證集與訓(xùn)練集。實際訓(xùn)練代數(shù)(epoch)為200。由于物體檢測不是本文的研究重點,同時也受限于微縮模型下車輛與行人種類少的因素,所以訓(xùn)練集數(shù)據(jù)量偏小,但最終模型檢測效果達(dá)到要求。
3.3 主觀評價指標(biāo)
圖9 對比了使用與沒有使用本文方法時,在同一視角、同一場景下的顯示效果。圖9(a)為使用本文的增強(qiáng)型三維全景影像合成方法生成的畫面,行人和車輛都通過三維模型在場景中清晰地呈現(xiàn)了出來,可以極大地方便駕駛員觀察。圖9(b)表示使用基礎(chǔ)三維全景影像系統(tǒng)的顯示效果,當(dāng)車輛或行人處于投影模型的“地面”區(qū)域時,系統(tǒng)則會對這些物體造成投影畸變,使駕駛員無法準(zhǔn)確獲取車身周邊物體的位置信息,甚至無法看清物體。

圖9 同一場景下的兩方法的顯示效果對比Fig.9 Comparison of display effects of two methods in same scene
圖10 對比了當(dāng)其他車輛分別以不同距離經(jīng)過本車側(cè)邊的顯示效果。本文方法同樣將這種距離的差別反映在了模型的位置上,驗證了本文中位置估計方法的精確度和可靠性。

圖10 其他車輛以不同距離經(jīng)過車身側(cè)面時的顯示效果Fig.10 Display effects when another vehicle passing by vehicle body with different distances
同時,對比起現(xiàn)有解決方案[11],本文方法由于無須通過縮小投影模型的方法使三維物體顯示正確,因此可以最大化地擴(kuò)大模型中的地面部分,從而可以更好地削弱“道路彎折畸變”,即盡可能地保持路面的平直性。如圖11 所示:圖11(a)是使用本文方法的顯示效果,投影模型大小設(shè)置為3 000 mm×3 000 mm,可通過觀察路面雙黃線得知道路基本平直。而現(xiàn)有解決方案(自適應(yīng)模型法)只能通過縮小投影模型方法使三維物體映射在“墻面”上,如圖11(b)所示。此時投影模型的大小為700 mm×700 mm,雖然對側(cè)方車輛做到了良好的顯示,但圖像中明顯對路面造成了極大的彎折。每幅圖左下角為當(dāng)前投影模型大小展示。
圖12 進(jìn)一步地探究了當(dāng)本文系統(tǒng)工作于復(fù)雜環(huán)境時的表現(xiàn)。圖12(a)為本文系統(tǒng)工作于多車輛復(fù)雜場景中的顯示效果,圖12(b)為與之對應(yīng)的基礎(chǔ)三維全景影像的顯示效果,可知系統(tǒng)在處理多個車輛位置時也能夠保證每個車輛位置估計的準(zhǔn)確性。圖12(c)、(d)為當(dāng)系統(tǒng)工作在雨天環(huán)境下,攝像頭上出現(xiàn)水滴時的物體檢測情況。由于YOLOv4 算法中使用了例如模糊、透明疊加等多種數(shù)據(jù)增強(qiáng)方法,因而在多數(shù)情況下都能將車輛正確檢出,如圖12(c)中檢出的兩輛已經(jīng)被水滴模糊的汽車;而在少數(shù)情況下,如圖12(d)所示,由于水滴造成車輛形變過大,檢測網(wǎng)絡(luò)則無法檢出,但當(dāng)車輛動態(tài)行駛不斷改變位置時,未被檢出車輛仍有可能在前后幀中被檢出。

圖11 兩方法在解決三維物體顯示失真問題上的效果Fig.11 Display effect of two methods in solving 3D object display distortion problem

圖12 本文系統(tǒng)在復(fù)雜場景下的表現(xiàn)Fig.12 Performance of proposed system in complex scenes
3.4 客觀評價指標(biāo)
由于需要在行車過程中實時顯示車輛周邊情況,所以要求畫面不能出現(xiàn)卡頓現(xiàn)象,因此給本文影像生成方法的實時性提出了很高的要求,所以將首先驗證本文方法的實時性。而后再對本文方法中物體檢測及位置估計的準(zhǔn)確性做定量測試。
在場景生成中共分為兩部分:使用OpenCV 生成地面部分,使用OpenGL 渲染場景部分。前者在使用OpenCV 逐點生成“地面”時,使用查找表(LUT)方法,將映射關(guān)系的計算放在程序初始化時完成并保存,實時渲染時只需查表即可,從而降低了單幀處理時間。表1 顯示了在不同“地面”分辨率下的相關(guān)生成時間。

表1 投影模型“地面”部分生成用時 單位:sTab.1 Time taken of generating“ground”part of projection model unit:s
而對于后者OpenGL 渲染三維場景部分,對比起基礎(chǔ)三維全景合成算法,由于本文方法在場景渲染時需要額外渲染行人、其他車輛等模型,因而需要耗費(fèi)更多時間。表2 為渲染時間對比,共隨機(jī)選取5 幀。對比起基礎(chǔ)算法的渲染時間,本文方法渲染時間確實有所增加,但渲染時間仍處于較低水平,不對實時性造成影響。

表2 渲染時間對比 單位:msTab.2 Comparison of rendering time unit:ms
最后,在300×300 的地面分辨率下,結(jié)合YOLOv4 網(wǎng)絡(luò)檢測時間、位置估計時間、數(shù)據(jù)處理時間及上述場景生成時間,本文方法單幀平均處理時間為0.033 9 s,幀率約為30 frame/s,滿足實時性要求。
在實時性滿足要求后,繼續(xù)驗證本文方法中物體檢測與位置估計的準(zhǔn)確性。物體檢測由YOLOv4 網(wǎng)絡(luò)完成,相較于前代YOLOv3 網(wǎng)絡(luò)[17],在保證檢測速度基本不變的同時提高了檢測準(zhǔn)確度。實驗中使用相同訓(xùn)練數(shù)據(jù)分別訓(xùn)練了YOLOv4 與YOLOv3 網(wǎng)絡(luò),并選取50 幀圖片,每幀圖片中包含四幅圖像與若干感興趣物體,兩個網(wǎng)絡(luò)對感興趣物體的檢測效果如表3 所示。其中:晴天/雨天檢出率等于正確檢測出的物體次數(shù)除以物體出現(xiàn)總次數(shù);晴天誤檢率為檢測錯誤次數(shù)除以檢出總數(shù)。

表3 YOLOv4與YOLOv3網(wǎng)絡(luò)檢測準(zhǔn)確率對比 單位:%Tab.3 Comparison of network detection accuracy rates between YOLOv4 and YOLOv3 unit:%
之后測試本文方法位置估計的準(zhǔn)確性,通過拉動模型車輛使其按照提前設(shè)定好的路徑經(jīng)過車身,然后計算整個過程中估計位置與實際位置的平均誤差來實現(xiàn)。實驗中,共測試了三條路徑,并將三條路徑的直線方程通過建立地面二維坐標(biāo)系表達(dá)了出來,如圖13 所示:每幅圖中心長方形表示本車位置,離散的點為本文方法對模型車輛每幀的估計位置,圖片下方的直線方程為上述模型車輛的實際運(yùn)動軌跡。最終在三條測試路徑下,位置估計的平均誤差見表4,并按照誤差比例計算出實際道路使用時的真實估計誤差。

圖13 本文方法對三條路徑的估計結(jié)果Fig.13 Estimation results of three paths by using proposed method
表4 中:測試路徑分別為圖13(a)、(b)、(c)中的三條路徑。誤差比例等于估計值平均誤差/模型車寬(300 mm),道路誤差通過誤差比例合理外推到真車比例,以普通乘用車寬(1 800 mm)乘以誤差比例得到。考慮到本文方法中對其他車輛及行人的顯示主要以輔助駕駛為目的,且小于10 cm的位置誤差在高速行車時仍可忽略,因此在位置估計精度方面同樣滿足要求。

表4 三條路徑中位置估計平均誤差Tab.4 Average error of position estimation in three paths
4 結(jié)語
本文在現(xiàn)有車輛三維全景影像合成算法的基礎(chǔ)上提出了一種基于坐標(biāo)升維逆映射的增強(qiáng)型車輛三維全景影像合成方法,用于解決原系統(tǒng)中對周邊三維物體的顯示畸變問題。本文方法首先利用YOLOv4 網(wǎng)絡(luò)檢測每幅圖像中的感興趣物體位置,之后利用魚眼相機(jī)標(biāo)定參數(shù)結(jié)合補(bǔ)充條件推導(dǎo)出從像素坐標(biāo)系轉(zhuǎn)換到世界坐標(biāo)系的坐標(biāo)升維逆映射方法,從而初步估計出感興趣物體在世界坐標(biāo)系中的位置。而后對估計位置進(jìn)行合并、濾波操作后得到最終估計位置,并將提前建立好的模型放置和渲染在對應(yīng)位置完成增強(qiáng)顯示。本文方法對比起現(xiàn)有解決辦法,具有成本低、運(yùn)算量少、顯示效果好等諸多優(yōu)點,同時生成速度滿足實時性要求,位置估計也滿足精確度要求。能夠進(jìn)一步提高車輛全景影像的顯示質(zhì)量和使用價值。后續(xù)可進(jìn)一步將實驗擴(kuò)大至真實車輛,以測試此系統(tǒng)在真實道路上的顯示表現(xiàn)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
