基于雙目視覺的障礙物識別研究
2021-04-20 09:30:40冀將孟立凡
電子設計工程 2021年6期
冀將,孟立凡
(中北大學儀器與電子學院,山西太原 030051)
在移動式機器人、無人小車及無人機等諸多應用場景下避障技術都至關重要,而障礙物識別是避障技術的前提。目前針對障礙物探測采用的主要方法有激光雷達探測、超聲波探測以及基于單目攝像頭的視覺識別等。傳統方法中的激光雷達具有精度高、采集速度快等優點,但其費用較高難以應用于小型開發;超聲波測距需要對行進方向上不同高度的障礙物信息分別進行采集,且測量范圍小;而基于單目相機的視覺識別易受環境光照影響,且需大量數據集以完成計算,這些因素使得傳統探測方法在越加廣泛的實際應用領域難以施展拳腳。與此同時,將計算機視覺應用于障礙物識別具有實時性高、成本較低且不易受外界干擾的優點,故更適應于當下應用[1-2]。
雙目立體視覺利用左右攝像頭分別以各自角度出發對同一場景進行采集得到場景圖像對,其后在圖像對對應點之間位置差異的基礎上通過數學推導得到場景中物體的三維信息[3]。隨著雙目立體視覺理論的成熟,該技術已廣泛應用于工業生活中的各個領域。文中基于雙目立體視覺原理,利用雙目相機對目標場景成像以獲取其立體圖像對,并通過算法匹配出相應像點,隨后利用對應像點間的視差信息計算得到目標場景對應的深度信息,并最終實現障礙物的識別。
1 雙目相機標定
雙目相機的標定是指得到和確定相機自身各類內外參數的過程,雙目相機的內參是指各種與相機本身特性相關的參數,如焦距、投影中心、傾斜系數、畸變系數等;雙目相機的外參是指諸如左右攝像頭相對位置及相機平移、旋轉向量等轉換參數[4-5]。通過標定得到內外參數后,便可將被測物體從空間三維坐標系中“轉移到”相機成像平面的像素坐標系上。
文中在對各類標定方法進行對比實驗后選用張正友標定法對雙目相機進行標定,該方法選用標準棋盤格作為參考物,在利用世界坐標系位置的自由度獲取各角點空間坐標,并基于像素坐標系獲取各角點對應像素坐標,便可以計算得到相機內參,并求解出相機各類轉換矩陣的值[3]。綜合考慮,文中選用CMOS 型OV9714 攝像頭模組建立雙目系統如圖1所示。

圖1 雙目相機
標定工作分為單目標定與雙目標定兩個階段,首先,分別進行左右單目標定,為提高標定精確度,利用左右攝像頭從不同位置角度對棋盤格進行拍攝得到14 張標定圖像,然后,利用Matlab 對這些圖像進行全部讀取,讀取結果如圖2 所示。
圖像讀取結束后,通過逐個點擊定位棋盤格圖像的4 個邊界角點(角點處于相鄰4 個方格的交點)獲取棋盤格邊界,然后,根據實際尺寸及角點橫縱排列可實現圖像中所有角點的定位。
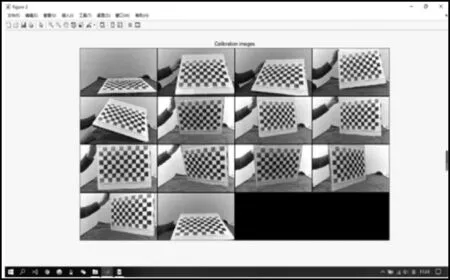
圖2 棋盤格圖片讀取
攝像機拍照功能的實現是通過透鏡將實物投影到成像平面上,但是在透鏡的制造和組裝過程中由于精度等技術上的偏差會引入畸變,最終在投影時引起圖像的失真[6]。為避免畸變帶來的影響,文中通過輸入預估畸變系數對圖像角點進行二次定位,標定工具箱會根據輸入的預估畸變系數調節定位位置,所有圖像角點提取完成后即完成單目標定。分別完成左右攝像頭單目標定獲得內參文件并利用內參實現相機的雙目標定。
其中左攝像頭內參如表1 所示,相機外參如表2所示。
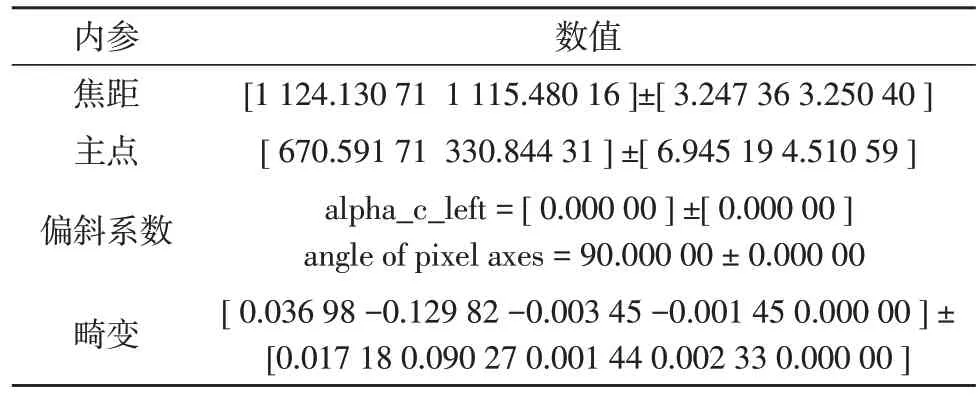
表1 左攝像頭內參數
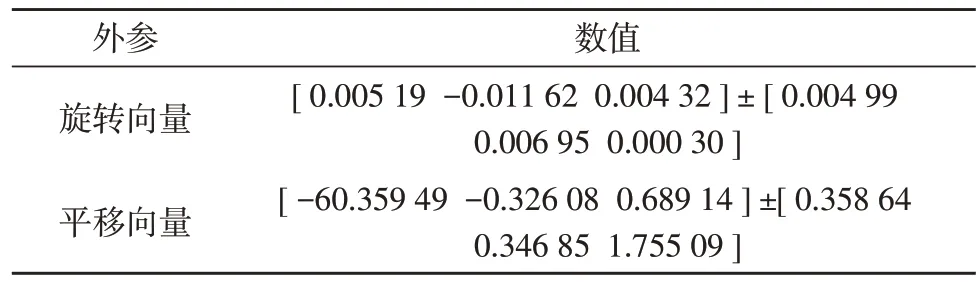
表2 雙目相機外參數
2 圖像預處理
在圖像處理過程的諸多環節(如輸入、采集、處理等)中會引入各類噪聲(主要體現為椒鹽噪聲及高斯噪聲),這些因素會極大得影響到后續圖像匹配的精度[7]。
文中利用中值濾波和高斯濾波對圖像進行去噪操作。其中,中值濾波的主要原理是以圖像目標區域內灰度值的中值代替該區域中心點處的灰度值,對椒鹽噪聲去除效果較為明顯[8-9]。該方法通過創建一個包含目標區域所有像素的濾波模板并進行排序處理,最終在序列中找到灰度中值完成替代工作。此二維序列中值濾波輸出為:
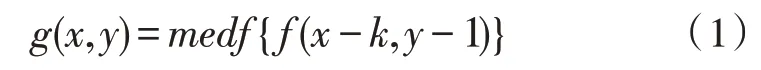
其中,f(x,y)和g(x,y)分別是原圖像和處理后的圖像;k∈w,w為輸入的二維模板。
高斯濾波的主要原理是以圖像目標區域內灰度值加權平均處理后的結果代替中心點灰度值[8-9],其中一維高斯分布以及二維高斯分布分別表示為:
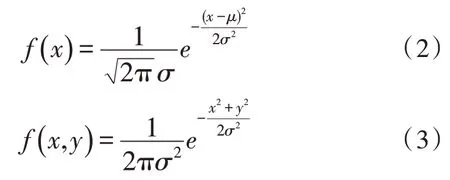
文中選用σ=1.5 時的5*5 高斯模板對圖像進行了處理,較為完整地去除了圖像中存在的高斯噪聲。
由于雙目攝像頭兩個鏡頭之間內部參數的差異以及拍攝時由于位置差異導致的接受光照強度的不同,會使得左右兩張圖像之間存在像素灰度差異,即產生了亮度差。文中使用直方圖均衡化方法進行亮度差消除。在實際情況下,首先,需要將獲取的彩色圖像轉換為灰度圖,一般情況下圖像的灰度級范圍為0~255,通過以下線性變換可將圖像灰度壓縮到區間[0,1][9]。

得到和灰度圖后,計算圖中每個灰度值所含的像素個數占圖像總像素的比例并對其進行累加,隨后根據概率值對圖像各灰度值所包含像素進行重新分配得到新圖像。累加值計算公式如式(5)所示,其中k表示灰度級數。
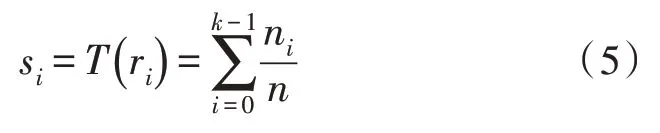
改變圖像中某一個特征的同時很有可能會引起圖像其他特征的變化,在對圖像進行去噪及去除亮度差處理等平均或積分運算后,會造成圖像某些信息的丟失。圖像的銳化處理正是以上運算的逆處理過程,其目的是加強圖像邊緣、輪廓線等細節,因此,該文在上述處理后對圖像進行了拉普拉斯銳化以恢復圖像細節信息。
經以上各處理過程后,雙目系統所拍攝圖像的前后處理效果如圖3 所示,可見此時圖像噪點減少,對比度及細節度得到提升。
3 立體匹配與深度恢復

圖3 圖像預處理
立體匹配的基本原理是利用圖像對中對應點之間的視差,結合標定過程中得到的雙目相機參數實現圖像三維坐標的恢復。雙目相機成像的模型如圖4 所示。
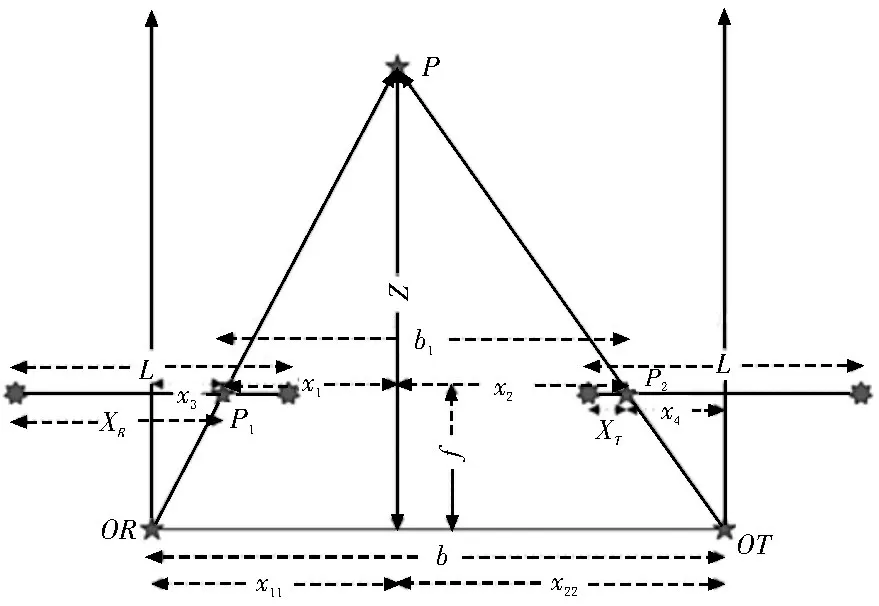
圖4 相機成像模型
圖4中P點表示被測目標空間位置,P1和P2分別為P點在左右攝像頭像平面的成像位置,f表示焦距,XR和XT分別表示成像點P1和P2在像面上距離平面左邊緣的距離,可見此時左右光軸處于平行狀態[10-11]。由此可得視差和被測物體深度之間的關系式:

式中,Z為被測物體深度,可推導得到:
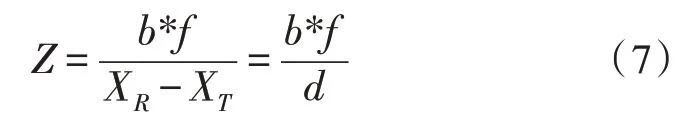
可知雙目立體視覺的深度恢復建立在雙目系統理想狀態下,故在立體匹配之前需對系統進行立體校正以解決圖像非共面行對準問題。文中在相機標定中已經通過畸變系數去除了鏡頭畸變帶來的影響,在此基礎上利用標定所得內外參數進行極線校正即可使相機達到理想狀態[12-13]。極線校正結果如圖5 所示。

圖5 極線校正
立體匹配的目的是利用圖像中某些特征實現左右圖像中對應像素點的匹配,最終得到圖像視差,本質上是從二維的圖像對中得到三維信息。匹配過程可以看作是對圖像對之間最大對應概率的求解,并尋求最小復雜度的求解算法(能量最小化)。經典的全局匹配算法通過構造一個能量函數E=Edata+Esmooth(其中,Edata表示圖像匹配程度,Esmooth表示定義場景的約束)求得其最小值,以完成圖像最佳匹配。對能量函數的最小化求解方法很多,包括動態規劃,模擬優化算法,置信度擴展及圖割等[13]。
OpenCV 中基于局部及全局匹配原理提供了3 種匹配算法,為找出適合本系統的匹配算法,分別利用BM 算法及SGBM 算法對此前處理后的圖像對進行了匹配實驗,實驗結果顯示BM 算法耗時314.132 ms,SGBM 算法耗時189.677 ms。圖6(a)為BM 算法匹配結果,圖6(b)為SGBM 算法匹配結果。

圖6 目標場景深度圖
通過圖6 中的對比可見SGBM 算法所得深度圖更為稠密,其包含的目標場景深度信息也更為完整。基于障礙物探測角度考慮,BM 與SGBM 算法匹配時間均在0.5 s 以內,為系統可接受范圍;兩種算法匹配所得三維信息都較為準確,但BM 算法所得深度圖空洞較多,輪廓較為模糊,丟失了較大一部分信息,而SGBM 算法所得深度圖輪廓較為清晰,圖像信息保留也較為完整。BM 算法匹配完整度不足會直接影響到后續障礙物分割的效果,故文中選擇SGBM 算法進行圖像匹配作為后續圖像分割的基礎。
4 障礙物分割識別
搭載雙目系統的運動載體在運動過程中會獲取其行進方向上所有靜態和動態物體的深度信息,故需對這些深度信息做出判斷。首先,需要設定一個障礙物判定標準,通常以行進路線上物體與雙目系統之間的距離關系進行定義,即根據雙目系統工作范圍、運動載體行進速度及運動時的躲避速度設定出一個距離閾值Sm。將運動載體與物體間距離定義為S,視S與Sm之間的關系做出判斷,只有當物體與運動載體之間距離S≤Sm且處于運動載體行進路線上時,該物體才會被視作為障礙物。根據實際需求文中設定0.5 m 為障礙物距離閾值,障礙物分割識別需基于此進行判斷。設立判斷標準后,文中利用數據聚類算法對SGBM 算法獲得的深度圖進行障礙物分割[14]。
圖像分割的目的是將圖像區域化從而突出圖像中有價值的目標,其實質是對圖像像素數據集的聚類處理。K-means 算法是一種數據聚類算法,該算法會將一個大型數據集聚類成k個簇,并通過不斷優化調整得到各點與所屬簇中心距離平方和為最小值時的最佳簇中心分布[15-16]。但將該算法應用于圖像分割時具有一些天然的缺陷,由于此算法必須提前確定聚類數量且聚類數量會直接影響到最終分割效果,通常無法預先估計并給定一個合理值,這極大地制約了算法的準確度;而在算法復雜度方面,由于該算法需要對簇中心不斷地進行調整以實現新的聚類,因此,時間復雜度與空間復雜度均較高。
為提高原始K-means 算法的分割效率[17-18],文中改進了其初始中心點的選取方式,改進后算法首先在給定的數據集中隨機選取一個點作為第一個簇中心,然后,計算數據集中所有點與所有簇中心之間的最短距離以挑選下一個簇中心點,重復此過程直到選出k個簇中心。此時算法避免了預估聚類數量,最終結果較原算法更為穩定,簇中心選取最壞的情況下復雜度下降,算法效率得到很大提升。利用改進后算法對SGBM 算法所得深度圖的分割效果如圖7所示。可見改進后算法可以較為準確的在目標場景深度圖中分割識別到障礙物。

圖7 障礙物分割
5 結論
文中采用雙目系統對目標場景進行障礙物分割識別,實驗結果表明該系統可較為快速準確的獲取目標場景的深度信息,并利用聚類算法實現了最終的障礙物識別,這為系統運動載體的后續避障提供了有效信息,達到了預期的實驗目標。但使用SGBM 算法圖像匹配得到的深度圖中仍存在少數空洞,在紋理性比較弱的場景下會導致誤差增大,故在后續研究中需進一步對圖像匹配算法做出改進。
