基于卷積神經網絡和關鍵詞的目標檢測系統
2021-04-22 16:10:08施懿浦昕鑫沈劉潼徐也
電腦知識與技術 2021年8期
施懿 浦昕鑫 沈劉潼 徐也


摘要:該文以互聯網上的圖片數據為訓練數據,結合使用深度學習技術,實現了一種基于卷積神經網絡和檢測關鍵詞的目標檢測系統。系統根據用戶輸入的檢測關鍵詞,利用網絡爬蟲技術搜集圖像用于訓練。對每張圖像,使用預訓練的神經網絡模型提取圖像特征,并采用金字塔池化技術得到圖像表達向量。系統基于圖像表達向量學習分類器,并利用分類器對用戶上傳的圖片進行目標檢測。系統的實現具有實際意義,理想情況下可對任意具體目標實現檢測(如行人、車輛、動物等)。
關鍵詞: 計算機視覺;目標檢測; 卷積神經網絡; 網絡爬蟲; 檢索關鍵詞
中圖分類號: TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)08-0162-03
Abstract:This paper proposes a novel object detection system, which utilizes the images stored on the Internet as training images, and adopts the deep learning technology to achieve the object detection tasks. According the keywords typed by users, this system runs the web crawlers to gather the images related to the keywords. For each image, a pre-trained convolutional neural network model is used to extract the features from this image, and then the pyramid pooling technology is applied to generate the image representation vector of this image. This system learns a binary classifier on the image representation vectors, and uses it to detect the objects in the images uploaded by users. Ideally, this system is capable of detecting any object such as pedestrian, car, animal and so on.
Key words:computer vision; object detection; convolutional neural network; web crawler; keyword
目標檢測[1]是計算機視覺領域中重要的研究方向之一,是計算機識別圖像、理解圖像的基礎,亦是計算機進行判斷、推理和決策的前提。它廣泛地存在于安防中的遙感圖像敵軍目標檢測,醫療中的計算機輔助診斷, 紅外目標跟蹤與識別工作, 智能視頻監控等諸多應用領域。目前已經出現了很多基于深度學習技術的目標檢測系統。例如,陳辰[2]等人提出了一種基于FPGA的深度學習目標檢測系統。王俊強[3]等人基于深度學習技術,提出了應用于遙感圖像領域的目標檢測定位系統。盧虹竹[4]等人提出了基于深度學習算法的人臉識別管理系統。
通過分析發現,現有的系統并沒有利用互聯網上海量的圖片數據作為訓練數據來源,并且也不支持對未包括在訓練數據種類中的類別進行檢測。針對這一情況,本文以互聯網上海量的圖片數據為訓練數據來源,結合使用當前流行的深度學習技術,設計并實現了一種基于卷積神經網絡和檢測關鍵詞的目標檢測系統。該系統支持用戶輸入任意檢索關鍵詞,對用戶上傳的批量圖片進行目標檢測。例如,當用戶輸入“熊貓”檢測關鍵詞后,系統對用戶上傳的每張圖片進行目標檢測,并將檢測結果展現給用戶。
本系統實現的關鍵功能包括了:1)根據用戶輸入的關鍵詞,利用網絡爬蟲技術搜集訓練圖片;2)使用預訓練網絡(如ResNet[5])提取圖像特征,并在卷積層應用金字塔池化技術得到圖像表達向量;3)基于圖像表達向量和種類標簽信息訓練分類器;4)利用分類器對用戶上傳的圖片進行目標檢測。本系統采用Python語言開發,利用Scrapy爬蟲框架實現訓練圖像數據的獲取,利用Pytorch框架實現圖像特征的提取和分類器學習,利用Django框架實現Web系統。本系統的實現具有實際意義,理想情況下可對任意具體目標實現檢測。
1 系統設計
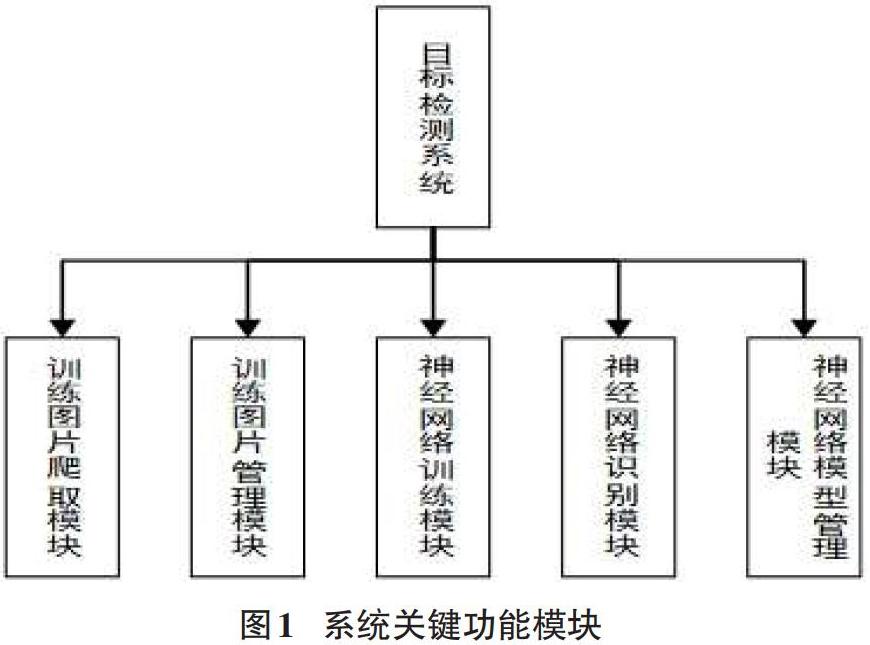
本系統基于Django框架按照MVC模式進行設計。圖1顯示了系統的關鍵功能模塊。下面依次介紹各個模塊。
1.1 訓練圖片爬取模塊
訓練圖片爬取模塊基于Scrapy框架進行實現。該模塊在獲得用戶輸入的檢索關鍵詞后,通過程序訪問現有的圖片搜索網站(如、百度圖片搜索、谷歌圖片搜索等),爬取這些網站依據關鍵詞檢索出的圖片。爬取的圖片交由訓練圖片管理模塊進行存儲。模塊在實現過程中,利用了瀏覽器偽裝、代理服務應對反爬蟲技術,利用了Selenium模擬用戶操作瀏覽器。該模塊允許用戶設置爬取的目標網站、圖片張數、圖片大小、圖片格式等參數。爬蟲在爬取過程中依據用戶設置的參數對圖片進行篩選。
1.2 訓練圖片管理模塊
訓練圖片管理模塊使用MySQL數據庫存儲圖片文件信息,支持用戶進行圖片的增刪查改。該模塊支持人工篩選數據,允許用戶刪除圖片質量差、與關鍵詞語義匹配度低的圖片。此外,該模塊還支持用戶上傳訓練圖片以應對訓練圖片質量差、數量少的情況。
1.3 神經網絡訓練模塊
神經網絡訓練模塊基于Pytorch框架進行實現。該模塊利用預訓練卷積神經網絡抽取訓練圖像的圖像特征,然后在卷積層應用金字塔池化技術[6]得到圖像表達向量,最后基于圖像表達向量和種類標簽信息學習分類器。訓練所需的數據集由10000張背景圖片和爬取的圖片構成,其中,爬取的圖片作為正例,背景圖片作為負例。預訓練模型采用當前流行的深度卷積神經網絡,如VGG-16[7]、ResNet[5]等。在本系統中,預訓練模型作為特征提取器被使用。通過在位于末尾的卷積層上應用金字塔池化技術得到固定長度的圖像表達向量。在獲得所有正負樣本的圖像表達向量后,學習一個二類分類器,如SVM、羅杰斯特回歸。訓練完成的模型交由神經網絡模型管理模塊進行保存。
1.4 神經網絡識別模塊
神經網絡識別模塊利用預訓練卷積神經網絡和分類器,對用戶上傳的圖片進行目標檢測。該模塊采用了SPP-Net[6]的識別方式。具體地,對于每張圖片,第一步,利用候選框生成算法[6]在該圖片上生成大量的候選框(如2000個);第二步,利用卷積神經網絡進行特征提取,并計算每個候選框對應的特征圖區域;第三步,采用空間金字塔池化技術對每個特征圖區域包含的特征分別進行池化,得到每個候選框所在區域的圖像表達向量;第四步,利用訓練得到的分類器對每個候選框對應的圖像表達向量進行分類,并保留判定結果為正例的候選框;第五步,利用非極大值抑制技術對上一步得到的候選框進行進一步的過濾,剩下的候選框作為該圖片的識別結果。
1.5 神經網絡模型管理模塊
神經網絡模型管理模塊使用MySQL數據庫對訓練完成的模型進行管理,支持用戶進行模型的新增(訓練新模型)、刪除、修改(重新訓練模型)和查看操作。該模塊支持用戶直接使用系統中訓練完成的模型進行識別,避免了模型的重復訓練。如果系統提供的模型不能滿足需要,則用戶可以訓練新模型。
2 工作流程
圖2顯示了用戶使用本系統進行目標檢測的工作流程。
3 系統效果
圖3顯示了用戶上傳圖像后,進行目標檢測后的系統截圖。用戶在輸入“貓”關鍵字并點擊“檢測”按鈕后,系統將圖片中的“貓”用矩形框進行標識。
4 結論
本文以互聯網上海量的圖片數據為訓練數據來源,結合使用當前流行的深度學習技術,設計并實現了一種基于卷積神經網絡和檢測關鍵詞的目標檢測系統。該系統支持用戶輸入任意檢索關鍵詞,對用戶上傳的批量圖片進行目標檢測。在實驗中發現,目標檢測的檢測效果非常依賴于訓練圖片的質量和數量。對于一些較常見的目標(如貓、狗等),因為容易獲得大量高質量的訓練圖片,檢測效果較好,而對于一些不常見的目標,爬取的訓練圖片質量低,還需要人為補充訓練圖片來提高檢測效果。
參考文獻:
[1] 袁功霖.基于卷積神經網絡的目標識別技術[D].北京:中國電子科技集團公司電子科學研究院,2019.
[2] 陳辰,嚴偉,夏珺,等.基于FPGA的深度學習目標檢測系統的設計與實現[J].電子技術應用,2019,45(8):40-43,47.
[3] 王俊強,李建勝,程相博,等.基于深度學習的目標檢測定位系統設計與實現[J].測繪與空間地理信息,2020,43(1):133-136,144.
[4] 盧虹竹.基于深度學習算法的人臉識別管理系統[J].信息技術,2019,43(12):121-124,130.
[5] He K,Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, 2016.1-12.
[6] He K,Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 37(9): 1904-1916.
[7] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[C].IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014.1-14.
【通聯編輯:唐一東】
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
