改進TextRank 的文本關鍵詞提取算法
2021-04-23 05:50:26王俊玲
軟件導刊 2021年4期
王俊玲
(山東科技大學計算機科學與工程學院,山東青島 266500)
0 引言
關鍵詞提取(Keyword Extraction,KE)是指使用一個詞或多個詞對文本內容進行高度總結與概括,在文本摘要[1]和文本分類[2]中都發揮著重要作用。隨著社交網絡的發展及用戶數量的急劇增加,每天都產生大量需要處理的文本信息。面對海量信息進行處理與分析,如果能夠準確提取文本內容的關鍵詞,即能很好地對文本進行分析與概括,從而節省大量時間,提高效率。
隨著研究的不斷深入,傳統人工方法已經無法滿足用戶需要。傳統方法效率低下,實現過程復雜,無法很好地展現文本關鍵信息,因此對算法進行改進,找到更簡單、便捷的方法成為研究熱點。本文提出一種改進的TextRank[3]算法,將傳統按句子劃分的方法轉變成按照部分進行劃分,并結合圖的概念,在每個部分中構建關鍵詞圖,最后根據設定的評價指標進行關鍵詞提取打分,確定最終關鍵詞,本文算法適應于較長的文本。
1 相關工作
關鍵詞提取方法主要分為兩類:有監督和無監督的提取方法。利用有監督方法提取關鍵詞的步驟可概括為原始數據收集、文本預處理、數據集構建、特征構建、模型分類及對其進行評估。有監督方法包括基于傳統機器學習的方法,如Frank 等[4]提出的KEA3 方法使用樸素貝葉斯模型(Naive Bayes,NB)對候選詞進行了分類;Turney[5]在關鍵詞提取任務中對比了遺傳算法與C4.5 決策樹的效果;Wang等[6]采用支持向量機(Support Vector Machine,SVM)篩選關鍵詞,使用的特征包括單詞的詞頻與位置信息。后來人們對該方法進行了改進,如Turney[7]在NB 模型中加入點互信息(Point-wise Mutual Information,PMI),該方法提高了關鍵詞提取準確率,但忽略了上下文語境。
利用無監督方法提取關鍵詞的步驟可概括為原始數據收集、文本預處理、候選詞集合確定、候選詞排序以及評價打分確定最終關鍵詞。無監督方法又可細分為:①基于簡單統計的方法。其對候選詞的一些特定指標進行統計,根據統計結果對候選詞進行排序,如使用N-gram[8]、TFIDF[9]、詞頻[10]、詞共現、詞性、詞的位置等屬性為指標設置不同權重,該方法的優勢在于應用簡單、計算量小,但其只能涵蓋單詞表層信息,很難發現單詞之間深層次的聯系;②基于圖的方法。該方法中有3 個要素,分別是節點、節點間的連接規則、節點間權重計算方法,其中的典型代表是TextRank,此后又出現了SingleRank、SGRank、Position-Rank、TopicRank 等模型方法。基于圖的方法可體現候選關鍵詞之間的聯系,缺點是準確率有限且不適用于較短文本。
本文算法對原有的TextRank 算法進行改進,將傳統按句子劃分的方法轉變成將文本分成幾部分,在每個部分構建關鍵詞圖,最后根據相應評價指標進行綜合打分,確定最終關鍵詞。
2 改進的TextRank 算法
TextRank 算法用一個有向加權圖G=(V,E)表示TextRank 普通模型,由點集合V 與邊集合E 組成,E 為V×V 的子集。用Wij表示任意兩點Vi、Vj之間邊的權重,對于一個給定的點Vi,ln(Vi)表示指向該點的點集。
2.1 文本劃分
首先根據給出的文本T 進行劃分,由于傳統的TextRank 算法以句子為單位進行劃分,使得句子與句子之間的聯系被割裂,所以本文的劃分不是以句子為單位,而是根據文本長度劃分成相應的部分,每一部分P 由若干個句子Si組成,且每一部分的字數大體相同。分段公式為:

其中,P 為部分數量,Z 為單詞數量,S 為句子數量。
2.2 文本預處理
在已劃分好的部分進行分詞與詞性標注處理,并對文本中的信息進行過濾。因為文本中包含了許多無用信息,需要對文本作進一步處理,從數據集中去除無意義的符號、停用詞等,從而提取出有效關鍵字。預處理步驟如下:
(1)刪除無意義的符號。有些數據集,例如在某話題討論中經常出現“#”等符號,在轉發該信息時就會將此符號帶上,這意味著任意用戶分享過程中將包含轉發符號及字段。這些轉發符號對關鍵字提取沒有任何意義,并且起到噪聲的作用。因此,這些無意義的符號都將被刪除。
(2)停用詞刪除。創建一個標準的停用詞列表,然后將這些停止詞從集合中刪除。
(3)移除不重要的單詞。數據集中有很多單詞相對不重要,是關鍵詞的概率較小,因此本文建立一種機制識別與刪除這些相對不重要的單詞,即小于平均出現頻率的單詞將從候選關鍵詞集合中刪除,使其不會在關鍵字提取階段相互競爭,從而提高了關鍵詞提取效率。
2.3 關鍵詞圖構建
G(V,E)中V 代表圖的節點(候選關鍵詞),E 代表節點之間的共現關系邊,使用滑動窗口確定節點之間的聯系,一般設計滑動窗口大小為2~10。如果兩個詞在滑動窗口中出現共現關系,則兩個詞之間建立聯系且賦值為1,若再次出現共現關系則其值再加1,最后構造出每一部分的關鍵詞圖,如圖1 所示。
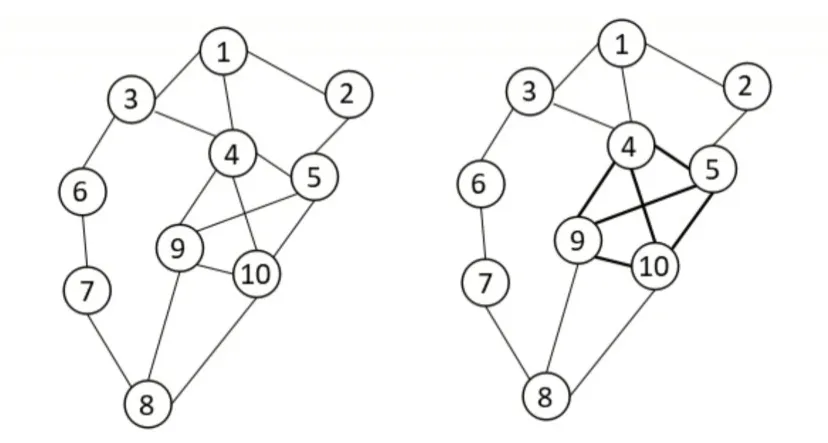
Fig.1 Keyword map圖1 關鍵詞圖
將圖中節點按照所連接邊的數量由大到小進行排序,選取連接邊數最多的前30%的節點作為該部分關鍵詞。如果出現相同節點連接的邊數相同,則比較共現值大小,選擇共現值較大的節點,最終得到一個部分的關鍵詞。其余部分關鍵詞圖的構成相同,最終確定N 個關鍵詞圖,將從這N 個關鍵詞圖提取出來的關鍵詞放在一起比較,結果如表1 所示。
在表1 中,Financial crisis、America、financial industry、the whole world、financial market 幾個關鍵詞出現頻率最高,而且在這幾個詞中,Financial crisis、the whole world 為名詞。從表中可以看出,名詞、動詞、形容詞出現頻率最高,所以在提取關鍵詞時,名詞、動詞和形容詞是需要提取的重要單詞。

Table 1 Comparison of extracted keywords表1 提取關鍵詞比較
2.4 特征提取與單詞評分
由于每個節點的重要性取決于多種因素,計算節點權重的參數如下:
定義1 詞頻(CP):表示節點Vi的詞頻,即該單詞出現次數占所有單詞的百分比。
定義2 詞長度(CC):關鍵詞中的單詞個數,如financial industry,其詞長度為2。單詞個數評分如表2 所示。

Table 2 Word number score表2 單詞個數評分
定義3 單詞位置(CW):單詞在每部分出現位置不同,有的在開頭,有的在中間,有的在結尾。根據單詞出現位置的不同給予不同分數,具體評分情況如表3 所示。

Table 3 Word position score表3 單詞位置評分
定義4 詞性(CX):即選出的單詞是名詞、動詞、形容詞、副詞或其他。由于在一段文本中,經過濾后剩下的詞多為名詞、動詞、形容詞等,根據詞性的重要程度對其進行打分。詞性的評分情況如表4 所示。

Table 4 Part of speech score表4 詞性評分
定義5 單詞最終得分Score:一個單詞的整體性得分是提取關鍵詞的最終指標。本文假設以上所有因素的乘積對文檔中的單詞有重要影響,且在這些因素中詞性的影響比其他影響大,并且通過實驗驗證了所提出評分函數的有效性。因此,定義候選關鍵詞(節點)的最終得分為:
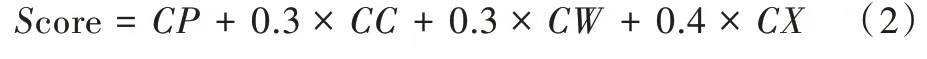
3 實驗與分析
本實驗采用3 個基準數據集Hulth2003、Krapivin2009和Semeval2010,3 個數據集中包括訓練集和測試集。由于本文不需要進行訓練,因此采用測試集進行實驗。由文獻[11]可知,3 個數據集在窗口大小為2 以及對文本進行預處理的實驗中效果最好,因此設置本文滑動窗口大小為2。相關數據集信息如表5 所示。
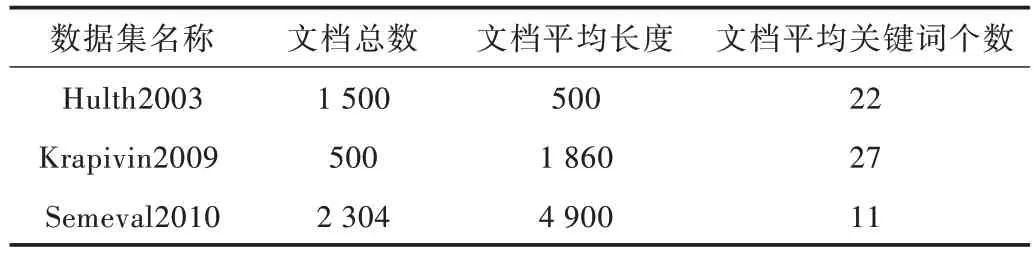
Table 5 Dataset description表5 數據集描述
為驗證本文算法在關鍵詞提取方面的性能,本文采用準確率(PR)、召回率(RR)、F-Measure(F)作為關鍵詞提取評價指標。準確率、召回率、F-Measure(F)計算公式分別如下:

式中,nm表示算法提取的關鍵詞與人工給定關鍵詞相匹配的個數,na為算法提取的總關鍵詞數量,nu為人工給出的關鍵詞數量。
實驗1:關鍵詞提取數量對本文算法的影響。本文以Krapivin2009 數據集為例,從基準數據集中提取K 個關鍵詞,K 的范圍為20~34(Krapivin2009 文檔平均關鍵詞為27),使用準確率、召回率和F 值3 個評價指標比較不同K 值對關鍵詞提取效果的影響。實驗結果如表6 所示。

Table 6 The influence of the number of keywords extracted on the algorithm in this paper表6 關鍵詞提取數量對本文算法的影響
從表6 的實驗結果可以看出,隨著關鍵詞數量的增加,本文算法的準確率不斷下降,召回率不斷上升,F 值先增加后減小,在關鍵詞數量為26 時達到最大值。因此,對于該數據集而言,當關鍵詞數量為26 時,本文算法性能最好。
實驗2:文本長度對本文算法的影響。為了驗證本文算法在提取長文本方面的性能,本文從基準數據集中篩選出平均長度分別為500、1 000、2 000、3 000、5 000、6 000 的文檔各100 篇,構建6 個測試數據集,分別記為C1、C2、C3、C4、C5、C6。采用本文算法和TextRank 算法進行性能對比實驗,本文提取了6 個數據集中共26 個關鍵詞,并計算準確率、召回率和F 值。實驗結果如表7 所示。
從表7 可以看出,隨著文本長度的增加,本文算法與TextRank 算法的各項指標都在下降。從變化速度來看,TextRank 的下降速度明顯加快。為了更清楚地表示文本長度與關鍵詞提取算法之間的關系,本文給出了采用兩種關鍵詞提取算法隨著文本長度增加的F 值變化曲線,如圖2所示。其中,定義橫坐標為文檔長度,縱坐標為F 值。
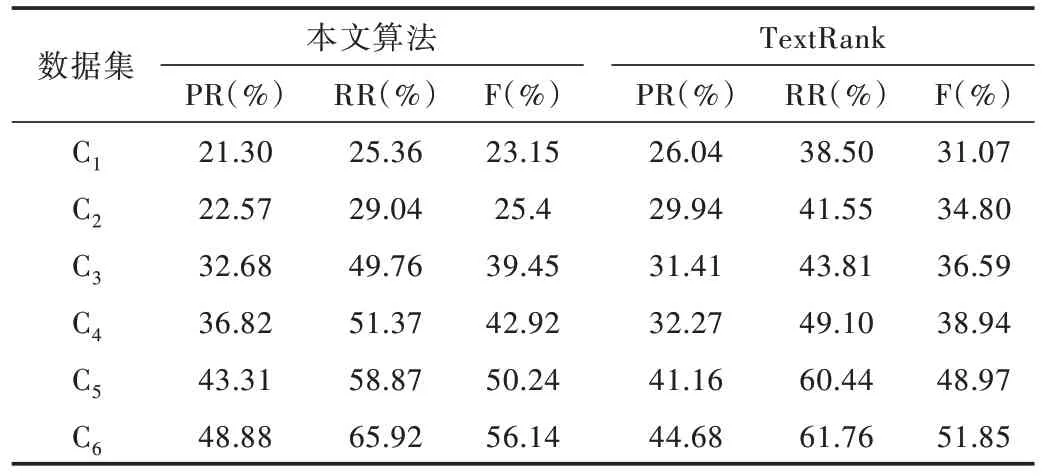
Table 7 Influence of text length on algorithm表7 文本長度對算法的影響
從圖2 可以看出,在文本長度<2 000 時,TextRank 算法的關鍵詞提取效果優于本文算法。但隨著文本長度不斷增加,本文算法效果開始優于TextRank 算法。

Fig.2 F change graph圖2 F 值變化曲線
實驗3:本文算法與TextRank 算法的關鍵詞提取性能對比。將本文算法與TextRank 算法在Hulth2003、Krapivin2009 和Semeval2010 3 個數據集上進行關鍵詞性能對比實驗,并分別計算準確率、召回率和F 值,實驗結果如表8所示。

Table 8 Comparison between this algorithm and TextRank algorithm表8 本文算法與TextRank 算法對比
通過實驗可以看出,本文算法的關鍵詞提取性能明顯優于TextRank 算法。
4 結語
關鍵詞提取是文本研究的重要任務。本文針對較長的文本提取關鍵詞改進了TextRank 算法,該算法由文本劃分、文本預處理、關鍵詞圖構建、特征提取與單詞評分4 部分組成。通過3 個實驗可得出本文算法明顯優于原始TextRank 算法。本文算法對于較長文本的關鍵詞提取具有一定優勢,但仍然存在不足,比如針對較短文本提取的關鍵詞精確度還不夠高。因此,針對較短文本的關鍵詞提取還應作進一步研究,找到一種可適應于各種文本的算法。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
