基于TF-IDF-MP 算法的新聞關鍵詞提取研究
2021-04-24 09:09:16曹義親盛武平周會祥
華東交通大學學報 2021年1期
曹義親,盛武平,周會祥
(華東交通大學軟件學院,江西 南昌330013)
文檔關鍵詞體現了文檔主題與內容,是理解文檔內容的最小單位。 文檔關鍵詞抽取,也稱關鍵詞提取或關鍵詞標注,是從文本中把與該文本所表達的意義最相關的一些詞或短語抽取出來,文檔的自動關鍵詞抽取是識別或標注文檔中具有這種功能的代表性的詞或短語的自動化技術[1]。 在文本分類中,文檔通常使用向量空間模型(vector space model,VSM)[2]表示,然后通過有監督的機器學習方法將待分類文本劃分到預定義的類別中。 根據VSM 模型可知,每個文檔都被表示為一個特征向量,由文本語料庫中提取的許多術語(詞或特征)的權重組成。 因此,如何給特征詞賦予合適的權重是文本分類任務中的一個基本問題,直接影響到分類的準確性。
在文本分類過程中, 特征提取是一個關鍵步驟。 首先采用某個特征評估函數計算每個特征的數值,然后根據數值對特征排序,最后選取若干個數值最高的作為特征詞。 它的主要作用是在不丟失文本關鍵信息的前提下盡量減少待處理詞語數量,以此來降低向量空間維數,從而簡化計算,提高分類的速度與效率。 常用的特征提取的方式有4 種:①采用映射方法將高維的特征向量變換為低維特征向量; ②從原始特征中挑選出一些最具代表性、分類性能好的特征;③根據專家知識選擇最具有影響力的特征;④采用數學方法找出最能體現分類信息的特征。
Uysal A K 提出了一種改進的全局特征選擇方法, 對通用特征選擇方法的最后一步進行了修改,使用局部特征選擇方法根據特征對類的區分能力來標記特征, 并在生成特征集時使用這些標記[3]。2018 年,他在原先研究的基礎上,從不同的角度對文本分類的兩階段特征選擇方法進行廣泛的分析,研究基于濾波的局部特征選擇方法與特征變換相結合的特征選擇方法。 實驗結果表明,采用主成分分析方法獲得的準確率相比較其他方法更高[4]。Wan C 等提出了一種基于文本結構的復合特征提取算法,既可以用于測量文本相關性又可以增加復合特征的值,并采用支持向量機和樸素貝葉斯分類器在3 個數據集上進行實驗,驗證了該方法的有效性[5]。 Agnihotri D 等采用關聯評分法,它結合單詞之間的相互信息與強聯系來對文本進行分類,在Webkb, 20Newsgroup, Ohsumed10 和Ohsumed23 4 個標準文本數據集上分別進行實驗, 實驗結果表明Macro_F1 值取得了顯著的提高[6]。Zhang L G 等人基于樸素貝葉斯文本分類器提出了兩種自適應特征加權方法,實驗結果表明,該特征加權算法有效地提升了分類的準確率,保持了最終模型的簡單性并縮短了執行時間, 但對輸入數據的表達形式很敏感,分類決策存在一定的錯誤率[7]。Haj-Yahia Z 等提出一種無監督的方法,通過結合通用和特定領域的人類專業知識和語言模型來豐富類別標簽,文本分類實驗效果要比采取簡單的監督方法更好些,但model 不同的trick 在不同數據集表現有差異性,而且采用貝葉斯算法作比較,充分性不太夠[8]。Habibi M 等解決了從會話中提取關鍵字的問題,并使用關鍵字為每個簡短的會話檢索少量可能相關的文檔,從而達到文檔推薦的目的[9]。Wu Q W 等提出了一種新的基于隨機森林的集成方法ForesTexter,包括特征子空間選擇和分割準則,將要素分為兩組,并為要素生成有效的術語權重,實驗結果證明了提出的ForesTexter 方法的有效性[10]。
詞頻-逆文檔頻率 (Term Frequency-Inverse Document Frequency,TF-IDF)算法是一種經典的特征權重算法,在一定程度上,這個算法可以較好的反映出某個特征詞在文本分類過程中區分文本屬性的重要程度,但是其理論依據存在一些不足[11]。為此, 國內外許多學者針對TF-IDF 算法中存在的問題進行了改進,有效地提升了特征權重算法的準確性和效率。
羅燕等采用齊普夫定律結合特征詞在文檔中的詞頻,推導出同頻詞的計算公式并計算出各頻次詞語的比例,結合TF-IDF 算法提取文檔關鍵詞[12]。 牛永潔等綜合考慮特征詞的位置、詞性、詞語關聯性、詞長和詞跨度等因素, 結合TF-IDF 算法提取關鍵詞[13]。 Ghosh S 等基于TF-IDF 算法提出一種受監督的功能構建方法,結合不同災難場景下發布的信息對推文進行分類[14]。Chen K 等比較研究許多不同的術語加權方案,利用了跨不同類別文本的細粒度術語分布,提出了一種新的術語加權算法TF-IGM[15]。張瑾提出基于TF-IDF、 詞位置和詞跨度的關鍵詞自動提取的方法, 加入位置權值及詞跨度權值,在情報關鍵詞提取中有廣泛的應用價值[16]。 高楠等提出了一種融合語義特征的短文本關鍵詞提取方法,該方法從統計信息和語義層面分析了詞語的重要性,并結合特征詞的詞頻、長度、位置和語言等特征提取出最相關的關鍵詞集合[17]。
雖然這些文獻對關鍵詞提取算法都進行了有效改進,但是都沒有同時考慮文檔中特征詞的位置信息與主題的關聯程度以及該算法在樣本不均衡的數據集上的差異。本文在TF-IDF 算法的基礎上,結合特征詞詞頻均值化與特征詞位置信息對權重算法進行改進,提出了TF-IDF-MP(Term Frequency-Inverse Document Frequency-Mean term frequency and Position weighting)算法。 采用Sigmoid 函數對詞頻與詞頻均值的差進行處理,同時,根據相關文檔中某些位置的關鍵段落賦予一定的權重調節因子,最后結合TF-IDF 計算特征詞的權值。實驗也證明了TF-IDF-MP 算法有效地提高了分類精確率、召回率和F1 值等評價指標。
1 相關算法
TF-IDF 的基本思想來自語言建模理論,常用于信息檢索與文本分類,同時也是一種統計方法,用來判定單個字詞對一個文檔集合或一個文檔的重要程度。 一個字詞在文檔中出現的頻率越高,則其重要程度應成正比例增加, 但若出現在語料庫其他文檔中的頻率也很高,則其重要程度應成反比例下降。
TF-IDF 的主要思想是: 如果一個字詞在一篇文檔中出現的次數很多,而在語料庫其他文檔中出現的次數很少,那么就可以認為該字詞具有良好的分類效果,適合當作分類關鍵詞。
1) 詞頻。TF 表示詞頻,即某個詞出現在文檔中的次數, 為了減少文檔詞數差異對結果造成的誤差,通過對詞頻進行歸一化處理(即用詞頻除以文章總詞數),如下

式中:tfi表示詞i 歸一化處理后的值;Ni,d表示詞i出現在文檔d 中的總次數;分母表示文檔d 中全部詞語的總個數。
2) 逆文檔頻率。 IDF 表示逆文檔頻率,如果包含詞i 的文檔在語料庫中比較少, 則表明詞i 在區分文檔類別時可以起到良好的效果。 計算一個詞的idfi,可使用語料庫中文檔總數量去除以所有包含該詞的文檔數量,然后對結果取對數。 如下

若一個詞區分類別效果比較好,則這個詞應該賦予較大權值,反之就賦予較小權值,一個詞的tfidf 值就是

3) 樸素貝葉斯算法。樸素貝葉斯分類器是一種基于貝葉斯定理的簡單概率分類器, 對條件概率分布做了獨立性假設, 通過將條件概率彼此相乘來計算最大后驗概率從而對文檔進行分類[18]。樸素貝葉斯算法的流程可以描述如下: 由多個特征詞組成的文檔d 表示為式(4),并根據貝葉斯規則其對應的類別標簽為式(5)[19]
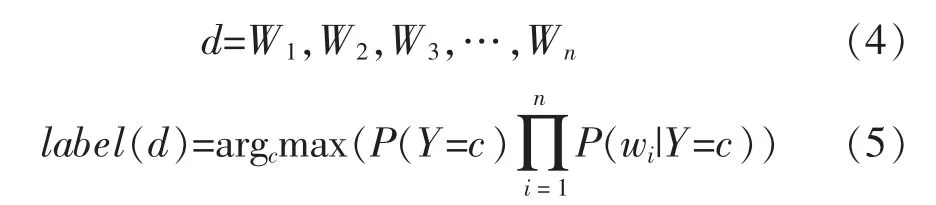
在這種情況下,對于給定的類別c,P(Y=c)是類別c的概率,而P(wi|Y=c)是特征詞wi的概率。多項式模型和多元伯努利模型在式(5)中的P(wi| Y=c)的計算上有所不同。 根據多項式和多元伯努利事件模型,概率計算分別為式(6)和式(7)
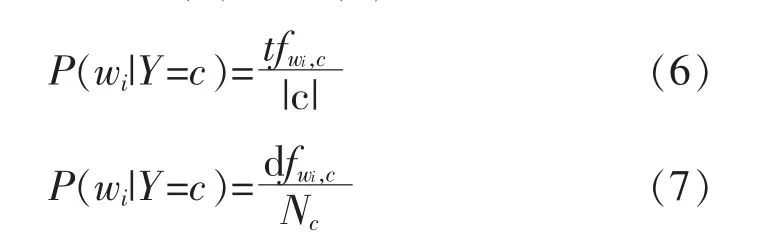
式中:tfwi,c是類別c 中wi的詞頻;|c|是類別c 中詞頻的總和;dfwi,c是類別c 中wi的文檔頻率;Nc是類別c 中的文檔總數。如果文檔d 中不存在單詞wi,則概率公式對于特征詞wi變為式(8)
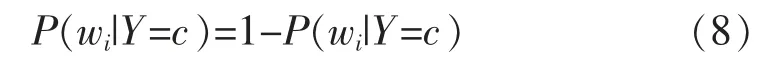
在本文中,將多元伯努利事件模型用于樸素貝葉斯分類。
2 TF-IDF-MP 算法
2.1 均值化詞頻
傳統的TF-IDF 算法根據特征詞詞頻和特征詞的逆文檔頻率的乘積來進行權重計算,簡單的認為詞頻高的特征詞應該賦予較高權值。 但一些日常用詞,如“的”、“雖然”、“一些”等,在文檔中出現的次數比較多,對分類會產生負效果,賦值較大是不合理的。
首先根據特征詞在單個文檔中出現的次數與該特征詞在語料庫所有文檔中出現的平均次數進行比較,若某個特征詞在單個文檔中出現的次數大于出現在語料庫文檔的平均次數,則說明該特征詞對這個文檔的重要程度要比其他文檔更高,應該賦予更大權重,反之賦予較小權重;然后采用Sigmoid函數對兩者的差值進行處理。
Sigmoid 函數的圖像是一條單調遞增平滑曲線,易于求導,值域在0 和1 之間,可以用來做二分類,在特征相差不是很大時結果比較好。Sigmoid 函數的公式如下

圖像如圖1 所示。
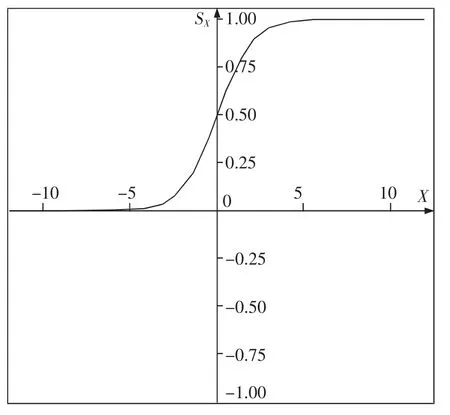
圖1 Sigmoid 函數圖像Fig.1 Sigmoid function image
從圖1 可以看出,當橫坐標為0 時,縱坐標為0.5。 在本算法中,若直接將Sigmoid 函數中的X 替換為上述兩者的差值, 可發現當兩者的差值相等時,即橫坐標為0,特征詞詞頻縮小為原先的二分之一,特征詞的權重也縮小為原先的二分之一,這是不合理的,根據前面的描述,此時該特征詞對這個文檔的重要程度應與其他文檔一致。
本算法將Sigmoid 函數進行了改進, 修改后的公式如下

式(10)的圖像如圖2 所示。
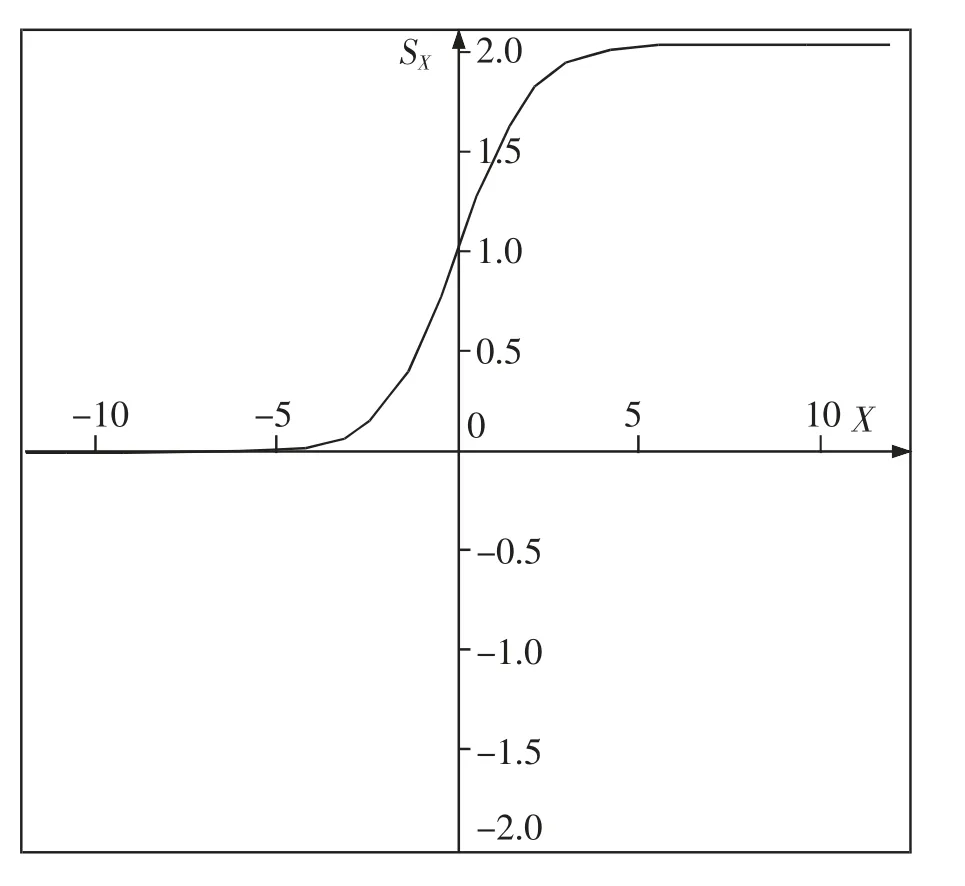
圖2 式(10)對應的函數圖像Fig.2 Function image corresponding to Formula 10
當上述兩者的差值相等時,此時縱坐標的值為1,表示特征詞的權重與根據TF-IDF 計算出的權重一致;當兩者差值大于0 或小于0 時,此時縱坐標的值相應的大于1 或小于1,符合本實驗的要求。若將Sigmoid 函數的分子改為3 或者更大, 可發現特征詞的權重被放大很多倍,實驗誤差較大。 為此,本算法中將Sigmoid 函數的分子改為2,可以有效地縮小特征詞詞頻之間差異,使得關鍵詞提取算法更加準確。
為此,均值化詞頻(Mean Term Frequency,M)公式如下

式中:Ni,d為在文檔d 中特征詞i 出現的次數;Ni為特征詞i 在語料庫文檔中平均出現的次數。
若特征詞出現單個文檔中的次數低于該特征詞出現在語料庫文檔中的平均次數, 那么M 值小于1,則最終權重降低,反之則權重增加。通過對詞頻均值化處理, 可以降低常用詞在詞頻上造成的影響。
2.2 特征詞位置加權
特征詞位置信息的權重賦值法是將特征詞在文檔中的位置信息作為位置權重因子, 并結合詞頻-逆文檔頻率計算特征詞最后的權重。 TF-IDF 算法并未將特征詞位置信息作為權重影響因素加入公式中計算, 但事實上特征詞在文檔中位置的不同,對整個文檔內容的重要性也有較大差異的。
在新聞網站中,基本上文章的主題都會在第一段和最后一段表現出來, 所以從分類角度來看,文章的開始和結束部分一般都會出現關鍵詞,比較重要, 所以應該賦予這兩部分的特征詞更高的權值。為此,本文采用jieba 分詞并進行詞性標注,將文章第一段和最后一段出現的名詞的位置權重因子設為P,其余特征詞位置權重因子為1,定義位置權重因子Pi如下

2.3 均值化詞頻-特征詞位置加權
本文在TF-IDF 算法的基礎上, 考慮文檔中特征詞的位置信息與主題的關聯程度以及樣本不均衡數據集上的差異,加入均值化詞頻和特征詞位置信息等參數, 最終計算特征詞權重的TF-IDF-MP公式如下

將式(1),式(2),式(11),式(12)代入式(13),得到
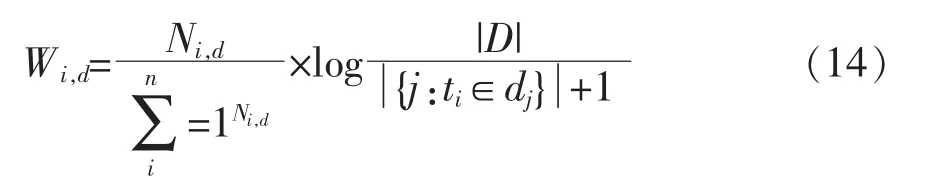
3 TF-IDF-MP 算法在新聞分類中的應用
3.1 實驗設計
實驗步驟示意圖如圖3 所示。
1) 數據集選擇。本實驗采用的是搜狗新聞數據集, 包含health,house,news,business 等14 個類別的新聞,不同類別的新聞數量差異較大,存在樣本不均衡特性。 數據格式如下:

然后根據
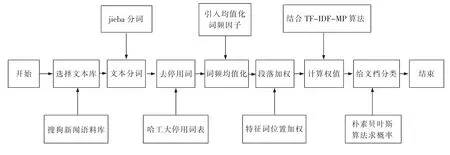
圖3 實驗步驟示意圖Fig.3 Schematic diagram of experimental steps

圖4 分類后的新聞文件列表Fig.4 List of classified news files
接下來選取每篇字數不低于200 字的新聞文檔,每個新聞類別選400 篇,選10 個類別一共4 000 篇文章進行實驗,其中選擇10 個類別文檔各300 篇共3 000 篇為實驗訓練集, 剩下的1 000篇為實驗測試集。
2) 文本分詞。 采用jieba 分詞工具對每篇文檔內容分詞后再標注詞性。
3) 去停用詞。使用哈工大停用詞表對數據集中的文檔去除停用詞。
4) 詞頻均值化。根據特征詞在單個文檔中出現的次數與該特征詞在語料庫文檔中出現的平均次數進行比較, 然后采用Sigmoid 函數對特征詞權重進行增加或者減少處理。
5) 段落加權。在初始范圍內分類的精確率隨段落中名詞位置權重因子的增加而提高,但當位置權重因子達到一定數值時,該名詞對文章實際的作用效果被夸大,降低分類精確率,因此位置權重因子存在一個精確率峰值。 為此,選取100 篇新聞按照本文實驗步驟進行實驗,給文檔第一段和最后一段出現的名詞設置不同的權重因子Pi,并使用精確率為評價指標尋求最合適的權重因子,計算不同P 值測試得到的精確率的平均值。 實驗中, 權重因子P在1 到2 之間遞增選取,取0.05 為步長,依次進行實驗,將實驗結果整理繪制成圖5。根據圖5 可知該數據集的Pi最優取值為1.2, 因此將文檔第一段和最后一段出現的名詞的位置權重因子設為1.2,其余特征詞位置權重因子為1。
6) 計算權值。 結合TF-IDF-MP 算法計算權值并按照權值大小從大到小排序。
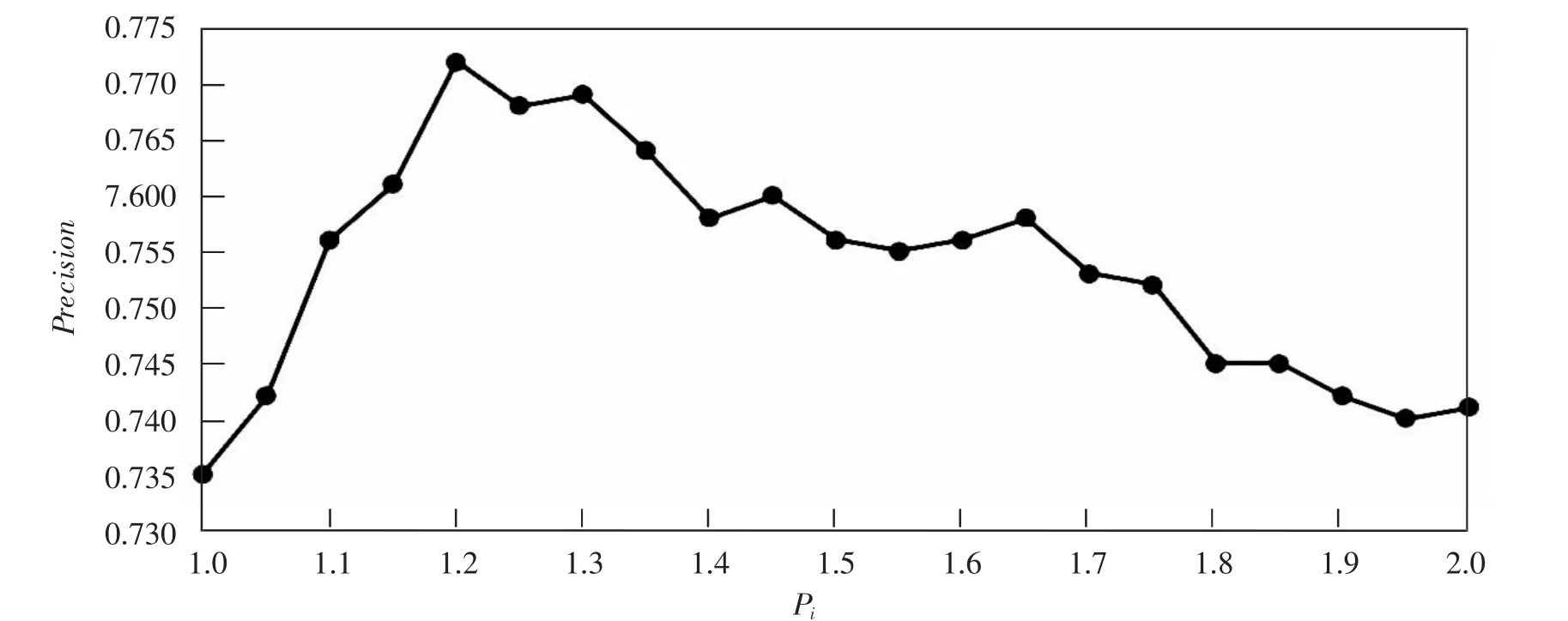
圖5 不同Pi 值對Precision 值的影響Fig.5 The effect of different Pi values on the Precision value
7) 分類。選取每篇文檔中權值最大的5 個特征詞,將其權重值添加到樸素貝葉斯算法中,計算出每篇文檔屬于各分類的概率,選擇分類概率中的最大值作為最終類別。
8) 對比分析實驗結果。
3.2 評價指標
為驗證新算法的有效性, 本實驗選取health,house,news,business 等10 個 類 別 不 同 的 文 檔 各100 篇作為測試集,使用TF-IDF、文獻[13]中算法、文獻[16]中算法和本文算法進行對比實驗。 采用精確率、召回率和F1 值來評價函數性能,其定義如下。
1) 精確率(Precision)。 表示分類結果全部預測為正的文檔中正確的數量在總數的占比,計算公式如下
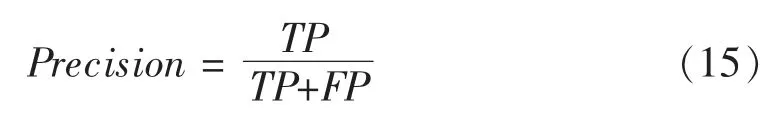
2) 召回率(Recall)。 表示分類結果全部預測為正的文檔中正確的數量占實際為正總數的比例,計算公式如下
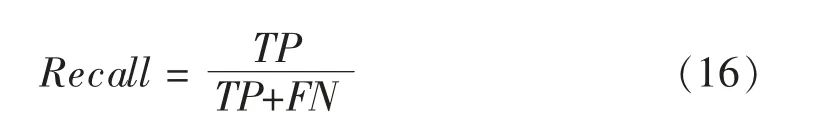
3) 綜合評價指標(F1)是精確率和召回率的調和均值, 相當于精確率和召回率的綜合評價指標,計算公式如下
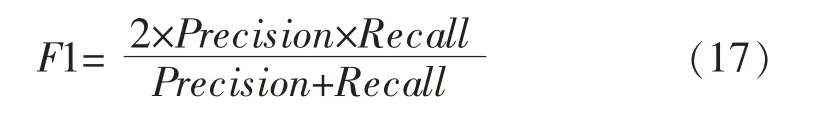
上述3 個公式中,TP 代表將實際為正類樣本分類成正類樣本的個數,TN 代表將實際成負類樣本分類成負類樣本的個數,FP 代表將實際為負類樣本分類成正類樣本的個數,FN 代表將實際為正類樣本分類成負類樣本的個數。
3.3 實驗結果和分析
通過精確率、 召回率和F1 值這3 個評價指標對TF-IDF 算法、文獻[13]改進算法、文獻[16]改進算法與本文改進算法對提取關鍵詞進行比較分析,結果如表1 所示。

表1 TF-IDF 算法、文獻[13]算法、文獻[16]算法和本文改進算法提取關鍵詞的實驗結果Tab.1 TF-IDF algorithm,Ref[13]algorithm,Ref[16]algorithm and the experimental results of this algorithm %
通過精確率、召回率和F1 值這3 個評價指標對TF-IDF 算法、文獻[13]改進算法、文獻[16]改進算法與本文改進算法采用樸素貝葉斯算法分類后進行比較分析,結果如表2 所示。

表2 TF-IDF 算法、文獻[13]算法、文獻[16]算法和本文改進算法采用樸素貝葉斯分類后的實驗結果Tab.2 TF-IDF algorithm, Ref [3] algorithm, Ref [16] algorithm and experimental results of the improved algorithm in this paper after using Naive Bayes classification %
通過表1 可以發現, 本文提出的TF-IDF-MP算法在提取關鍵詞時要比TF-IDF 算法、 文獻[13]中的算法和文獻[16]中的算法性能更優,3 個評價指標都有了明顯的提高, 從而也驗證了本文算法的合理性。
通過表2 可以發現,采用樸素貝葉斯算法對提取的文檔關鍵詞進行分類后,精確率、召回率和F1評價指標值整體有一定提升。 這是因為,本文的文檔數量雖然比較多,但只是對每篇文檔中5 個權值較大的特征詞進行分類,數據規模比較小,分類效率穩定,符合樸素貝葉斯的應用場景。
在文獻[13]中,綜合考慮了特征詞的位置、詞性、詞語關聯性、詞長和詞跨度等因素,但并沒有考慮因詞頻差異帶來的問題,沒有去掉文檔中的停用詞,不同位置的權重設置也不太合理,一篇文章中首段和尾段的位置權重應該設為一致,而且最后的權重計算應該是各個影響因素相乘, 而不是相加,權重相乘更能減少特征詞權重的差異,提高實驗準確率。 在文獻[16]中,綜合考慮了位置權值及詞跨度權值,但不同位置設置的權重值相差過大,也沒有考慮特征詞詞頻因素,容易增大實驗誤差。
TF-IDF-MP 算法結合特征詞在語料庫中詞頻的分布情況和在特征詞文檔中的位置信息,對那些在文檔中出現高于特征詞詞頻均值的特征詞和更能體現文檔主題的文檔第一段以及最后一段的名詞賦予較高的權重,而對那些低于特征詞詞頻均值的特征詞降低權重, 使得TF-IDF-MP 算法在提高關鍵詞提取效果與文本分類方面起到了積極作用。
4 結論
1) TF-IDF-MP 算法在TF-IDF 算法中加入均值化詞頻與特征詞位置權重因子等參數來調節特征詞權重以提取文檔關鍵詞。
2) 新算法根據特征詞在單個文檔中出現的次數與該特征詞在語料庫所有文檔中出現的平均次數進行比較, 采用Sigmoid 函數調整特征詞權值大小,然后根據標注好詞性的特征詞,將文章第一段和最后一段出現的名詞的位置權重因子設為1.2,據此對TF-IDF 算法進行改進。 實驗結果驗證了本文提出的改進算法的合理性和可靠性, 較相關算法,精確率、召回率和F1 值均得到較好的提升。
3) 該算法還有一些待進一步深入研究的問題。在設置特征詞位置權重因子時,應該做進一步深入的研究分析, 以期得到更合理更全面的權重因子,進一步提高實驗結果的可靠性。 在接下來的研究過程中,筆者將不斷進行研究實驗來尋找最適合本算法的權值因子,并結合特征詞類內間分布和根據詞語相似度合并同類詞語來增加文本分類的精確率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
