基于全局與局部融合的相關性對齊跨模態檢索
2021-04-25 05:23:24張勇
現代計算機 2021年6期
張勇
(貴州師范大學,貴陽550000)
1 介紹
跨模態檢索[1-5]以不同模態間語義關聯為基礎,通過建立不同模態的共同表征,實現以一種模態輸入搜索語義相似的其他模態樣本,其關鍵問題是不同模態的表征及匹配對齊。隨著社會數字化的快速發展,如何通過一種模態的輸入查詢到語義相似的其他模態的信息成為亟需解決的問題。
由于跨模態數據呈現底層特征異構、高層語義相關的特點。如何表示底層特征、怎樣對高層語義建模以及如何對模態間的關聯建模,這些都是跨模態檢索面臨的挑戰。不同模態數據擁有不同的數據形式,數據特征的結構和分布都存在一定的差異,實現跨模態檢索需要解決模態之間的異構性問題,使得不同模態數據可以進行相互比較。如今,實現跨模態檢索的方法越來越多,檢索準確率越來越高。現有研究在基于哈希變換上做了大量工作,主要思想是利用不同模態樣本之間的信息,通過將不同模態樣本的表示映射到一個公共的漢明(Hamming)空間中,然后在這個空間中實現不同模態的跨模態檢索。
基于哈希變換的跨模態檢索可分為傳統方法和深度學習方法。傳統方法是特征提取過程獨立于哈希代碼學習過程,這意味著手工制作的特征可能不能最優地與哈希代碼學習過程兼容。因此,現有的手工特征的CMH 方法在實際應用中可能無法取得令人滿意的性能。代表性的方法如:Bronstein 等人[6]提出的交叉模態相似敏感哈希(CMSSH)等。深度學習方法則更為復雜,它利用神經網絡強大的建模能力,構建多層神經網絡模型,使用激活函數進行非線性映射,優化損失函數學習映射方法,將原始特征映射到公共漢明空間中進行哈希學習。代表性的方法如:蔣等人[1]提出的深度跨模態哈希(DCMH)等。但是他沒有考慮異構數據的相關性,對于跨模態檢索來說至關重要。為了更好地利用異構數據的相關性,從而提高檢索的準確性,本文提出了一種端到端的方法。用于圖像和文本模態的兩個深度神經網絡都包含語義層和散列層,因此將學習兩個散列函數。對圖像和文本網絡我們分別學習全局特征和局部特征,并分別對全局特征和局部特征的非均勻分布進行對齊,以很好地挖掘模態間相關性。
2 相關工作
跨模態檢索的目的是學習一個共同的表示空間,在該空間中可以直接測量不同模態樣本之間的相似性。根據特征表示的類型,學習公共表示空間的方法通常可以分為兩類:實值表示學習[10-11]和二進制值表示學習[12-13]。本文使用的方法屬于后者:二進制值表示學習,也稱為交叉模式哈希學習。跨模態散列方法將不同模態的數據投影到公共漢明空間中,用于跨模態相似性檢索。最近,已經提出了各種跨模式散列方法。布朗斯特等人[6]提出了CMSSH,它采用增強技術來保持模態內的相似性。張等人[7]提出的模式匹配算法利用標簽信息重構語義相似度矩陣,以保持模式間的最大相關性。由丁等人[8]提出的CMFH 使用集合矩陣分解來學習不同模態的統一散列碼。林等人[9]提出SePH,該算法將異構數據的語義信息轉換成概率分布,并最小化庫勒貝克-萊布勒散度來學習哈希碼。上述跨模式散列方法都是基于手工特征的方法。這些方法的一個缺點是特征提取過程獨立于哈希學習。最近,利用神經網絡的深度學習已經被廣泛地用于從零開始的特征學習,并且具有良好的性能。因此,他們也提出了一些基于深度學習的跨模式散列方法。DCMH[1]在端到端深度框架中同時學習了深度功能和散列函數。然而,DCMH 只使用全局特征,丟失了局部細節所攜帶的語義信息,從而降低了其檢索結果的準確性,同時沒有關注語義相關性對齊。為此我們提出了關于關注全局信息和局部信息的網絡框架,同時我們還關注我們提取到的異構信息的語義相關性對齊。
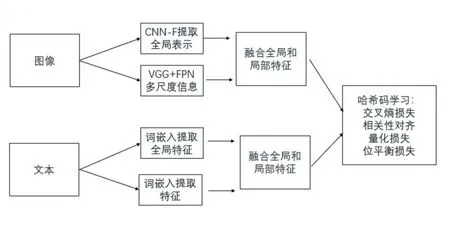
圖1 我們所提出方法的框架圖
3 方法提出
我們提出的方法的概述如圖1 所示。圖像和文本模態分別有兩種網絡。對于成對的圖像和文本,將圖像的原始像素輸入到圖像網絡中學習哈希碼,同時將文本的單詞包特征輸入到文本網絡中學習哈希碼。通過使用反向傳播算法和小批量隨機梯度下降來訓練網絡,將學習到高效的散列函數。
3.1 符號說明
3.2 網絡結構
對于全局特征,圖像我們使用CNN-F 來提取全局特征f1,文本使用BOW 來提取文本全局特征g1,以獲得整體的信息。對于局部特征部分,圖像使用VGG 結合目標金字塔網絡來提取高語義高分辨的多尺度特征f2,文本使用長短時記憶網絡(LSTM)來提取文本局部特征g2,以獲得局部細節信息。
3.3 哈希碼學習
設融合全局特征和局部特征,得到圖像全部特征為f,文本所有特征為g。
為了挖掘語義相關性,在學習過程中保留了模態間的相似性,并將兩個樣本特征的相似概率定義為:
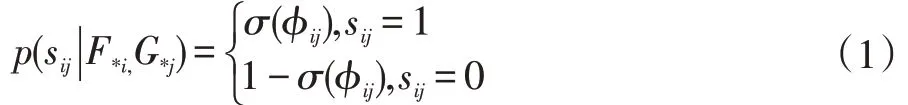
首先,我們使用交叉熵損失來保持來自圖像和文本模態網絡的散列碼的模態間相似性:
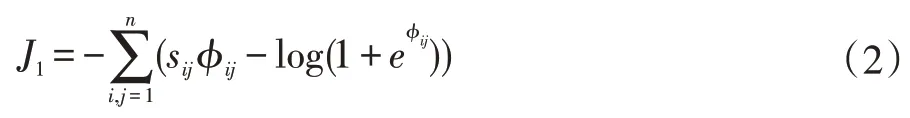
其次,為了更好地挖掘模態間相關性,將非均勻數據的分布對齊如下:

其中Cx和Cy分別表示圖像和文本模態的協方差矩陣,它們被定義為:
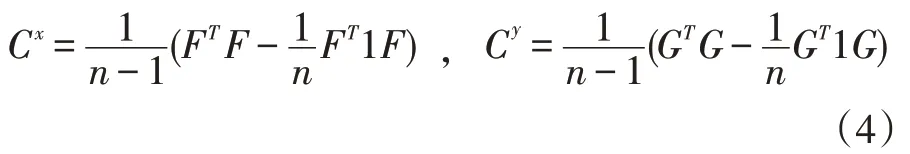
其中1 ∈?n是所有元素都為1 的向量。
此外,為了通過輸入成對的圖像和文本使兩個網絡的輸出接近相同的散列碼B,有:
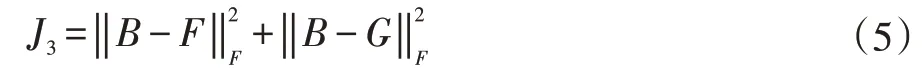
最后,添加位平衡約束來平衡“+1”和“1”的數量,這意味著哈希碼的每個位都有“1”或“1”的均等機會,因此語義信息可以在不同的漢明維數上均勻分布[1]。

基于上述分析,目標函數如下:
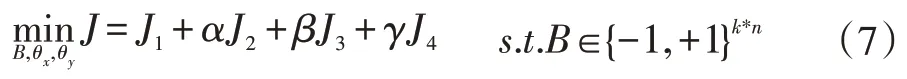
其中α,β,γ是三個超參數。這里總結一下目標函數中各個項的作用:J1可以保留語義相關性,J2保證相關性對齊。J3可以保持哈希碼的相似性,而J4可以平衡哈希碼。
4 實驗
我們提出的方法是在NVIDIA GTX 1080 TI GPU上用開源PyTorch 框架實現的。在兩個多標簽數據集上的實驗驗證了其有效性。
4.1 數據集
為了充分評估我們的方法的有效性,我們在MSCOCO 數據集公共多標簽數據集上進行了測試。數據集詳細介紹如下:MS-COCO 數據集最初是為圖像理解任務收集的,包含82783 個訓練圖像和40504 個驗證圖像。每個圖像都有相應的文本描述和預定義的81維語義標簽。在實驗中,包括所有具有類別信息的圖像(87081 個圖像),并且使用2000 維單詞包向量來表示文本。具體來說,隨機抽取5000 對作為查詢集和結果集。對于訓練集,我們從檢索集中隨機抽取10000 對。
4.2 比較方法和評估指標
我們的方法與CCA、CMSSH、SCM、STMH、CMFH、SePH、DCMH 方法進行比較。由于深度方法的圖像特征是原始像素,而淺層方法不能直接輸入原始像素,而是需要輸入提取的特征,為了公平比較,淺層方法的圖像特征是從圖像神經網絡的fc7 層提取的。在這項工作中,我們驗證了我們提出的方法兩個檢索任務:圖像檢索文本(I2T)和文本檢索圖像(T2I)。此外,我們使用平均精度(mAP)、召回率曲線來評估我們方法的最終性能。
4.3 實驗結果和分析
表1 顯示了我們方法的mAP 分數在MS-COCO數據集上相比其他方法最好,最好的方法加粗,其中散列碼長度從16 位到128 位。從表中我們可以看出,基于深度學習的方法比那些應用淺層模型的方法獲得更好的性能。此外,我們提出的方法在MS-COCO 數據集上獲得了最好的性能,而DCMH 獲得了相對較低的性能。與我們的方法相比,這是因為我們同時采用了全局特征和局部特征融合的信息以及相關性對齊,可以有效地提高檢索精度。我們可以看到,在大多數比較方法上,T2I 檢索任務的性能優于I2T 檢索任務。這意味著文本可以比圖像編碼更多的鑒別信息。
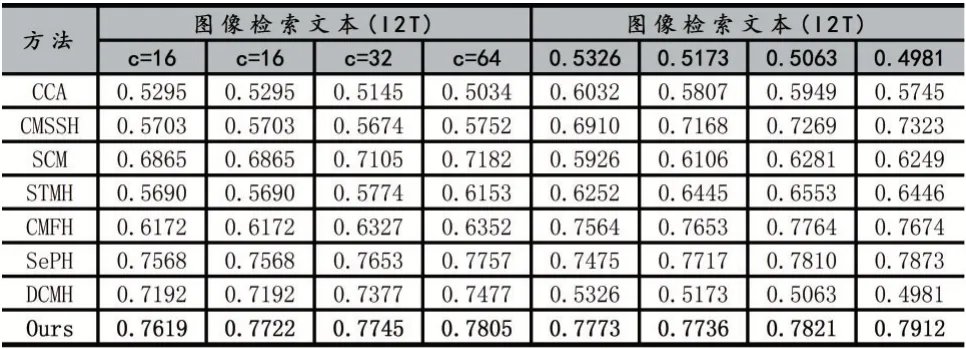
表1 與基線相比在MS-COCO 數據集上的mAP,最好的性能用粗體表示
圖2 顯示了128 位哈希代碼的在MS-COCO 數據集上不同方法的兩個檢索任務的精度-召回率曲線。從圖中,我們可以看到我們的方法達到了最好的性能。
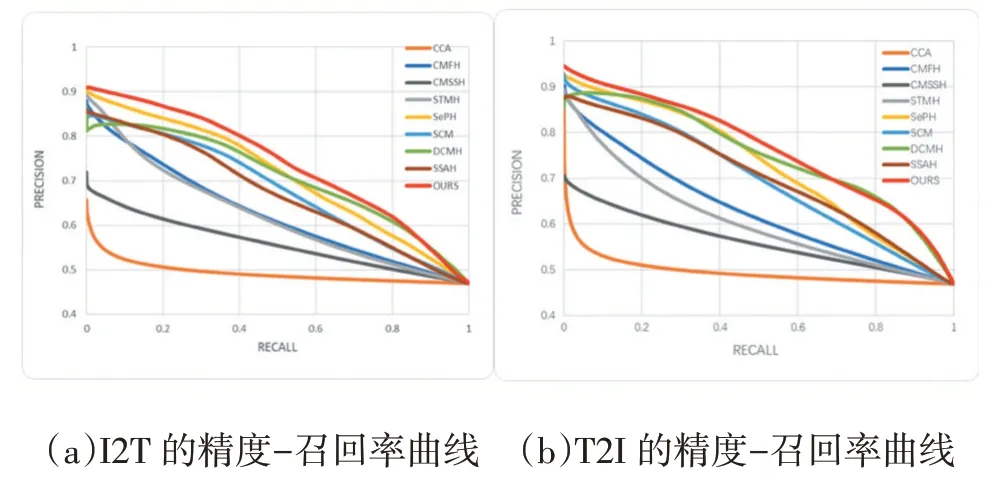
圖2
5 結語
在本文中,我們提出了一種端到端的方法——具有局部和全局的相關對齊的深度跨模態散列法。基于DCMH,我們首先構造利用全局與局部信息來挖掘語義,然后采用相關對齊的方法來挖掘模態間的相關性,最后學習得到區分性哈希碼。在MS-COCO 數據集上的實驗表明了該方法的優越性。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
