大數據環境下深度學習行人再識別技術研究與應用*
2021-05-07 08:47:34馬吉忠馬全海武文魁李文琪
南方農機 2021年8期
關鍵詞:特征
馬吉忠 , 謝 一 , 馬全海 , 武文魁 , 李文琪 , 李 玥
(甘肅農業大學信息科學技術學院,甘肅 蘭州 730070)
0 引 言
隨著大數據時代的到來,攝像機網絡越來越多地部署在每個角落。人們通過智能視頻應用實現目標跟蹤、異常行為檢測等需求變得日益強烈。而Re-ID應用和研究意義在社區中也變得越來越流行,但Re-ID仍然面臨許多挑戰,例如人物姿勢,照明和背景雜亂的變化很大。而深度學習則不同,它與人工提取特征的方式不同,它的適應性很強,可以很好地挖掘數據的深層特征,建立深層網絡之間的相互聯系,從原始圖像數據中學習更加高級的語義特征,使得特征更具辨識能力和魯棒性。而此次研究中對于行人再識別技術,通過基于屬性標簽和ID標簽的互補性,提出了一個基于屬性的人識別(APR)網絡。
1 研究方法及成果
Person Re-ID和屬性識別都意味著在視頻監控中有著關鍵的應用。在本文中,通過使用屬性標簽的補充提示來提高大規模Re-ID的性能。
其中屬性標簽的有效性有三方面:1)使用屬性標簽進行訓練可以提高Re-ID模型的判別能力。通過相似性來區別這些人,這可以用相似的彼此靠近,不相似的彼此遠離。2)詳細的屬性標簽明確指導模型通過指定的人文特征學習人的表征。通過屬性標簽,該模型能夠通過關注一些局部語義描述來學習并對行人分類,從而極大地簡化了模型的訓練。3)可以使用屬性來加速Re-ID的檢索過程,其主要思想是篩選出一些與查詢屬性不同的圖像。
2 基于CNN的Person Re-ID
隨著深度學習發展,基于CNN的方法正在主導Re-ID社區。學塔爾提出了PPA的建議,以從基礎網絡中提取身體部位的注意特征。然后,身體部位的特征被進一步重新加權,產生最終的特征向量[1]。有人轉移生成對抗網絡(PTGAN)被提議從一種數據集向另一種轉移圖像風格,同時保持身份信息以彌合領域差距[2]。這使用了一種字典學習方案通過對象識別和人檢測(源域)學習的功能轉移到人Re-ID(目標域)中。近來,已經提出了一些半監督方法和非監督方法來解決關于Re-ID的數據問題[3]。
Person Re-ID的屬性。以前屬性被用作輔助信息以改善低級功能。最近,朗哥(Franco)等人提出了一種由粗到細的學習框架,該框架由一組混合深度網絡組成。該框架對網絡訓練的時候可能會忽略ID標簽和屬性標簽的互補性[4]。為此,首先在具有屬性標簽的獨立數據集上訓練網絡,然后使用帶有三元組損失的唯一身份標簽對網絡目標數據集進行微調。最后,將目標數據集的預測屬性標簽與獨立數據集相結合,以進行最終的微調。該屬性也可用作無監督學習。而無監督的Re-ID方法通過從標記源數據中學習到的屬性來共享源域知識,并通過跨域的聯合屬性標識學習將這樣的知識轉移到未標記的目標數據中。
3 使用方法
3.1 準備工作
令SI={(x1,y1),...,(xn,yn)}是行人身份標簽數據集,其中xi和yi分別表示第i張圖像及其身份標簽。對于每個圖像xi∈SI,具有屬性注釋其中aji是圖像xi的第j個屬性標簽,m是屬性類。令SA={(x1,a1),...,(xn,an)}為標記為集合的屬性。請注意,集SI和SA共享公共行人圖像{xi}。基于這兩個SI和SA集,有以下兩個基準:
1)區分嵌入(IDE)。采用IDE來訓練Re-ID模型,該模型將Re-ID訓練過程視為圖像身份分類任務。僅在身份標簽數據集SI上對其進行訓練。為IDE提供以下目標函數:

其中ф是嵌入函數,由θI參數化,以從數據xi中提取特征。CNN模型通常使用嵌入函數ф。fI是通過wI進行參數化的身份分類器,用于將嵌入圖像特征ф(θI; xi)分類為維度身份置信度估計,其中n是身份的數目。?表示分類器預測與其基本事實標簽之間的損失。
2)屬性識別網絡(ARN)。與用于身份預測的IDE基準相似,提出了用于屬性預測的屬性識別網絡(ARN)。ARN僅在屬性標簽數據集SA上訓練。為ARN定義以下目標函數:
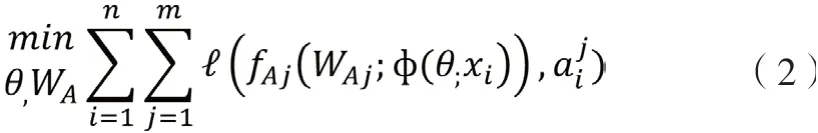
其中fAj是由wAj參數化的第j個屬性分類器,用于將嵌入的圖像表示ф(θ; xi)分類為第j個屬性預測。將輸入圖像xi上m個屬性預測所有遭受損失的總和作為第i個樣本的損失。
3.2 屬性人識別網絡
3.2.1 架構概述
APR網絡包含兩個預測部分,一個用于屬性識別任務,另一個用于身份分類任務。給定輸入的行人圖像,APR網絡首先通過CNN提取器、ф提取人的特征表示。隨后,APR根據圖像特征預測屬性。在這里,通過屬性預測和地面真相標簽來計算屬性損失。而本地屬性有益于全局識別,將屬性預測作為身份預測的其他線索。具體來說,為了更好地利用屬性,給定輸入圖像,APR網絡首先計算M個單獨的屬性損失。然后,將M個預測得分連接起來,并輸入到屬性重加權模塊(ARM)中。然后將ARM的輸出與全局映像功能連接起來,以進行ID損失計算。最終識別是建立在連接的局部全局特征基礎上,如圖1所示。

圖1 APR網絡概覽
3.2.2 優化
為了利用屬性數據SA作為Re-ID任務的輔助注釋,提出了屬性行人識別(APR)網絡。在身份集SI和屬性集SA的組合數據集S上訓練APR網絡,即S={(x1,y1,a1),...,(xn,yn,an)}。對于行人圖像xi,首先通過嵌入函數ф(θ;xi)提取圖像特征表示。根據圖像表示ф(θ; xi),同時優化兩個目標函數:
屬性預測的目標函數,屬性預測是輸入圖像特征上的一組屬性分類器獲得的,即{fAj(wAj;ф(θ; xi))}。然后,針對與等式相同的屬性預測優化目標函數。
識別的目標函數,為了能夠將屬性引入身份預測,則通過收集屬性預測的方法即{fAj(wAj;ф(θ; xi))},并將屬性重加權模塊對其進行加權。結合重新加權的屬性預測ai和圖像全局特征ф(θ;xi)來形成局部全局表示身份分類。因此,具有以下用于身份預測的目標函數:
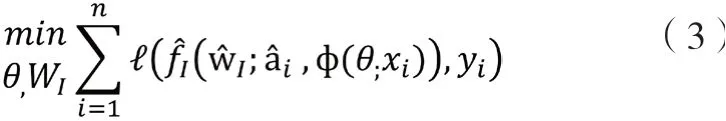
總體目標函數,考慮到屬性識別和身份預測,定義了所有對象。功能如下:
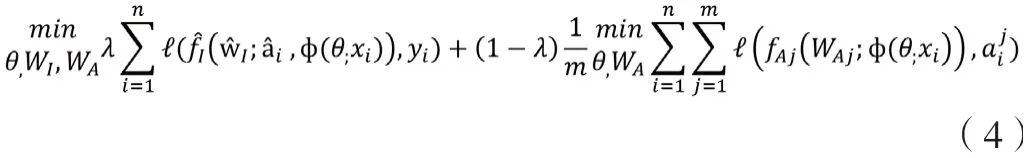
4 實驗結果
在實驗中,分別采用ResNet-50 和CaffeNet作為CNN骨干。網絡由ImageNet預先訓練的模型初始化。以ResNet-50為例,在pool5層之后附加一個512維的全連接層,然后添加批處理歸一化,這是一個具有0.5的跌落率和ReLU的退出層。512維的完全連接層與27維(對于Market-1501)屬性預測核心串聯。539維(512+27)功能用于身份分類。基于CaffeNet的實驗也以類似方式進行。最后,使用具有k個類節點的分類層來預測身份。對于每個屬性,在“pool5”層之后采用完全連接的層作為屬性預測的分類器。當評估APR網絡在此處的ID任務時,將嵌入特征的垂直連接和加權屬性預測作為每個圖像的最終特征表示。在Market1501的經驗研究中,通過將閾值設置為0.7,檢索過程加快了10倍以上,但準確率降低了2.92%。
5 結論
在深度學習的基礎下,通過討論屬性學習的集成來改進Re-ID。將屬性標簽和ID標簽進行補充,提出了一個屬性人識別(APR)網絡,ARN網絡學習Re-ID嵌入并在相同框架下預測行人屬性。系統地研究了人員Re-ID和屬性識別如何相互受益。還考慮到人的屬性之間的依賴性和相關性,對屬性預測重新加權。為了展示方法的有效性,在兩個大型Re-ID基準測試中的實驗結果表明,與最新技術相比,APR通過學習更具區分性的表示,可以實現具有競爭力的Re-ID性能。還使用APR加快了Re-ID的檢索過程三倍以上。在后期可以研究行人屬性的可傳遞性和可伸縮性。例如,可以將Market1501上學習的屬性模型改編為其他行人數據集。其次,也可以研究屬性檢索相關行人圖像的系統。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
