基于嵌入并行注意力機制的YOLOv3 模型高原動物種類檢測算法*
2021-05-10 03:10:10拉毛措安見才讓拉毛杰
微處理機 2021年2期
拉毛措,安見才讓,拉毛杰
(1.西藏大學信息科學技術學院,拉薩850000;2.青海民族大學計算機學院,西寧810007)
1 引 言
目標檢測與識別技術是數字圖像和視覺領域中的研究熱點之一[1],被廣泛應用于人臉識別、動物管理、植物種植、交通管理等應用領域中[2-4]。其中的YOLO 算法近年來得到了廣泛的應用。但YOLO 算法將目標檢測任務作為回歸問題來處理,沒有區分前景與背景區域的差異,從而產生了較高的誤檢和漏檢率。Faster-RCNN 目標檢測算法[5]在生成感興趣區域時就將可能含有待檢測物體的區域基本標記下來,提高了分類準確率,也節省了分類過程的處理時間。當前對目標檢測算法的改進主要包括:采用含有更多特征的、功能更強的基礎神經網絡和融合多尺度的目標特征來進行目標檢測。溫捷文等人[6]移除了YOLOv2 模型的Dropout 網絡層,對特征提取的網絡部分進行規范化處理,從而比原來YOLO v2 模型獲得了更高的檢測精確率和更短的訓練時間。Lin 等人[7]利用人工卷積神經網絡的多尺度特征,提出了一種橫向連接、自上而下的具有金字塔形狀的網絡結構,它融合多層的特征圖,用不同的特征尺度分別進行目標檢測。胡杰等人[8]提出通道注意力機制,將其分別應用到ResNet 及ResNeXt 等網絡上,使在ImageNet 2012 數據集[9]上分類實驗的top-1 及top-5 的錯誤率降低了最多1.80%和1.11%,并在基于COCO 2014 數據集[10]的實驗中獲得 mAPIoU = 0.5,比原來提升1.6%。Woo 等人[11]對卷積操作的通道關系和空間關系加權,更優地篩選出所需的關鍵特征。在YOLO v3 檢測模型提取出卷積特征,但未對卷積核中不同的特征位置進行加權處理。徐誠極等人[12]提出通道注意力及空間注意力機制串行地加入特征提取網絡之中,使用經過篩選加權的特征向量來替換原有的特征向量進行殘差融合,同時添加二階項來減少融合過程中的信息損失并加速模型收斂。但在實際應用場景中,圖像中待檢測物體的四周存在著復雜而關鍵的語義信息,如果對目標區域的特征加上相應信息及權重,模型將能更好地抽取待檢測目標的關鍵定位信息。鑒于此,提出基于并行注意力機制的改進YOLO v3 算法。在網絡殘差連接中加入并行注意力機制,可使加入注意力后的梯度能進入更遠的網絡中。
2 相關工作
深度學習的訓練需要大量高原畜牧業動物圖像,但目前尚未有關于青藏高原畜牧動物的數據集資料公開發布過,創建工作須從頭展開。模型訓練前,首先要到農牧區進行實地采集不同季節、不同動物、不同草場的動物圖像,并對圖像進行篩選。最后用圖像標注工具進行數據標注,建立青藏高原畜牧動物數據集。
圖像數據采集后,每類動物有3000 多張圖像,總數共計10060 余張,篩選后,圖像數量還有減少。顯然此類規模的數據集不算大,為提高性能和魯棒性,在此采用數據增強技術。數據增強技術包括:旋轉、平移、縮放、翻轉、添加噪聲、增加對比度等。
深度學習神經網絡訓練的數據集不但要采集真實的圖像,還需要作詳細的標注,并生成文件。在此使用LabelImage 標注工具,對圖像中的牦牛、藏系羊和馬作出詳細的人工標注。對牦牛的標注情況如圖1 所示。

圖1 對牦牛的詳細人工標注情況
3 嵌入并行注意力機制的改進模型
3.1 YOLO v3 算法
YOLOv2 算法提出了一種同時使用訓練目標檢測數據集和圖像分類數據集的方法,并且使模型識別未曾標注過的數據。YOLOv3 具有與YOLOv2 一樣的快速與精準,并且更適合小目標物體的檢測和識別。YOLOv3 算法對檢測對象定位不準等問題做了改進,主要包括:種類檢測從單標簽改為多標簽,改善了分類性能;在三個尺度上充分利用圖像中關鍵特征進行檢測;使用殘差連接的網絡來提取特征。
YOLOv3 主要完成的工作有:①輸入圖像,提取特征;②檢測邊界框與類別;③清除置信度低的候選框;④計算分類概率與坐標誤差。
3.2 YOLO v3 的核心網絡
作為YOLOv3 的核心的Darknet-53 網絡,是在Darknet-19 的基礎上增加殘差模塊開發起來的,其結構見圖2。圖像數據在網絡中傳播時,每次用步長為2 的卷積核作卷積,從而使新圖像的大小比原圖像減小一半。

圖2 Darknet-53 網絡結構圖
如圖2 可見,經過這樣的5 次卷積后,特征圖大小為原來的1/32。因此,輸入圖像大小必須為32 的倍數,此處設為 416×416(416=32×13)。在 YOLO v3中取消了池化層和全連接層。為解決網絡中可能出現梯度爆炸或消失的問題,Darknet-53 網絡結構中采用了residual 結構,能夠更好地控制梯度問題。
3.3 基于通道和空間注意力機制的殘差結構
YOLO v3 增加了殘差模塊,以此緩解隨著深度增加造成的梯度消失問題,效果是能夠在訓練成百上千的深度神經網絡的同時不會伴隨有錯誤數量的迅速提升。殘差中的1×1 卷積,減少了卷積通道數、參數量和網絡的計算量[13]。此處對Darknet-53采用改進的殘差模塊,主要考慮到要融合并行的通道注意力和空間域注意力。改進的殘差單元如圖3所示。
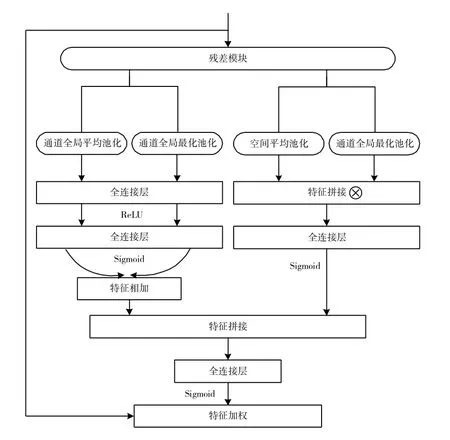
圖3 Darknet-53 改進的殘差單元
算法需要做全局平均池化和全局最大池化。設通道全局平均池化和全局最大池化的輸出分別為CAtt avg及 CAttmax,且 CAttavg∈R1×1×c,CAttmax∈R1×1×c。一維的權重向量CAttavg可以篩選出圖像中目標物體的全局信息,CAttmax可以篩選出圖像中目標物體的顯著特征。設X=[x1,x2,...,xc],其中xc表示的是第c 個卷積核的參數,詳細如下式:
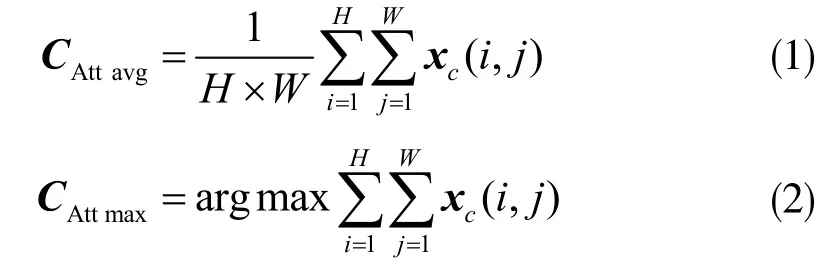
接著,設有:
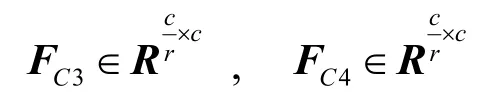
分別為兩個全連接層的共享參數,其中r 為降維比例,取r=16。則通道注意力模塊的輸出為:
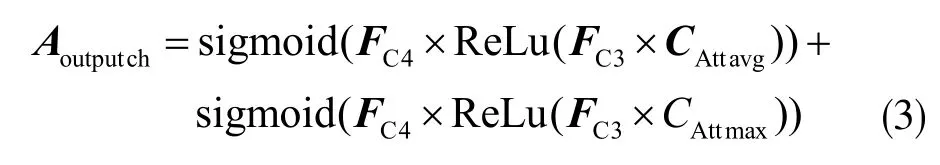
同時,并行注意力機制的空間注意力又需要將xc輸入到模塊中。
設空間域全局平均池化和全局最大池化的輸出分別為 SAttavg及 SAttmax:
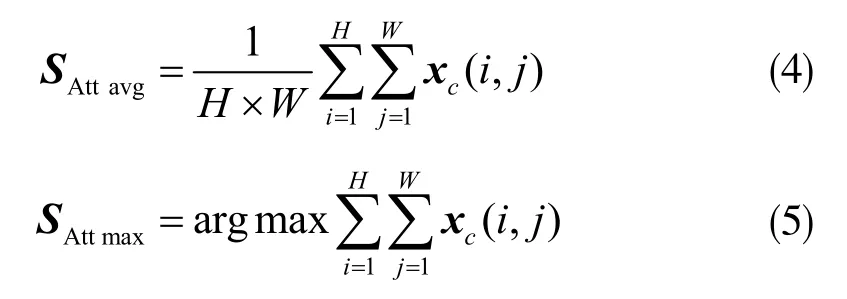
接著,對特征SAttavg和SAttmax進行拼接,并做全連接處理,則空間域注意力模塊部分的輸出為:
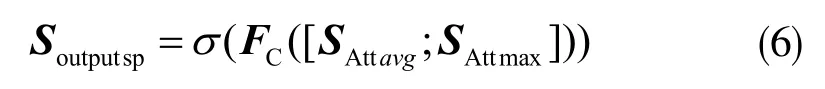
進一步對通道注意力特征Aoutputch和空間注意力Soutputsp進行拼接,接著做全連接處理,得到最終融合通道和空間注意力的權重:

再次,通過輸入矩陣xc和注意力權重矩陣Aoutputatt做內積完成對輸出矩陣xc的加權操作:
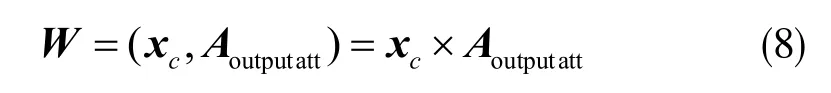
最后,并行注意力機制模塊的輸出為:

此處輸出模塊的特征向量的維度與輸入的維度一致,沒有對YOLOv3 的Darknet-53 網絡結構進行大幅度的修改,而只對殘差模塊做了調整。由于改進后的網絡結構較復雜,運行速度較原網絡稍慢。
3.4 多尺度與動物種類預測
輸入一張符合尺寸的圖像并且分成S×S 網格,在改進的YOLOv3 上運行得到特征圖,卷積層進行三次支路預測,輸出為:y1:(13×13),y2:(26×26),y3:(52×52)。在每個分隔的圖像網格上預測bounding box(邊界框)及其confidence(置信度),每個 bounding box 都會產生中心坐標(x,y)及寬高坐標(w,h)。置信度具體計算如下:
其中,IOU表示真實框和邊界框的交集與并集之比。Pr(·)為預測網格上是否有目標,計算方法如下:

在改進YOLOv3 中不但檢測邊界框和置信度,還要檢測種類概率Pr(·|·)。當網絡模型訓練完而進行測試時,邊界框的類別概率乘以置信度的值得到邊界框的種類置信度,如下式所示:
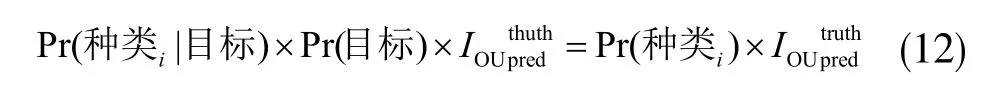
邊界框的動物種類置信度大于閾值0.5,那么該邊界框的目標就屬于該種類。
4 實驗結果與分析
為驗證所提出的改進YOLO v3 模型對高原牦牛、藏系羊和馬等動物圖像識別準確率,抽取531張圖片作為測試集,其中牦牛213 張,藏系羊200張,馬108 張,采用mAP 值作為評價指標進行實驗。實驗結果如表1。可見,改進的YOLOv3 網絡模型的mAP 為89.4%,與原來相比,提高了1.6%。
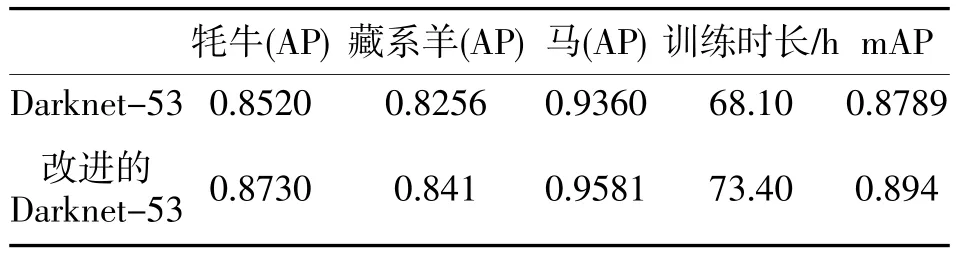
表1 動物識別實驗結果
5 結 束 語
融合并行注意力機制的改進YOLO v3 目標檢測識別算法繼承了YOLOv3 的優點,并在模型提取的特征向量上引入并行通道和空間域注意力機制,進行有重點的關注和修正,使整個網絡能更好地檢測和識別動物種類。該模型對畜牧業動物圖像中動物檢測、種類識別準確率有一定提高,在數據集上的實驗表明,在沒有增加太多參數量的情況下,改進YOLOv3 算法比原始算法具有明顯優勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
