融合社交關系與代價敏感的興趣點推薦算法
2021-05-12 08:29:26張進孫福振王紹卿徐上上
山東理工大學學報(自然科學版) 2021年4期
張進,孫福振,王紹卿,徐上上
(山東理工大學 計算機科學與技術學院,山東 淄博 255049)
近年來社交網絡應用的一個明顯進步是引入空間技術,促進了基于位置的社交網絡location-based social network, LBSN)的蓬勃發展,如Foursquare, Twinkle和GeoLife。在LBSN中,基于空間技術的位置也被稱為興趣點(point-of-interest, POI),例如餐館、商店和博物館等。然而,LBSN的興趣點推薦面臨很多的問題,例如矩陣稀疏、推薦精度不高、模型性能不高等。選擇合適的上下文信息與推薦方法是提高推薦精度、更好地挖掘用戶偏好的一種方法。在LBSN中,興趣點推薦融合多種上下文信息,Jamali等[1]提出了SocialMF算法,將社交關系融合矩陣分解,集成信任傳遞機制,緩解了冷啟動問題。Du等[2]將L1正則融入ListMLE算法損失函數中,緩解了排序列表的稀疏問題。Xu等[3]探究了基于Group的列表級排序學習算法,將關聯性高和關聯性低的標簽劃分為組的形式,結合無監督學習生成更準確的標簽。Yu等[4]探究高斯建模用戶簽到分布,利用BPR優化泊松矩陣分解過程,Zhang等[5]使用高斯核密度估計計算用戶的地理因素對興趣點推薦的影響。
近年來,有研究者將排序學習方法融入推薦過程中。排序學習是利用機器學習方法對物品或興趣點進行排序,輸出符合用戶偏好的興趣點列表。按照訓練數據的形式不同分為點級排序學習、對級排序學習以及列表級排序學習。Yin等[6]基于用戶隱式反饋使用點級排序學習方法挖掘隱含特征矩陣。Pan等[7]考慮用戶傾向于物品之間的偏序關系,在物品對集合上定義損失函數并學習排序模型。Li等[8]利用列表級方法ListNet處理特征矩陣,對比排序性能的差異。Chen等[9]將列表級排序應用到餐廳推薦中,利用排序模型學習基模型產生的結果,為垂直搜索提供了查詢與推薦方案。上述算法融入不同的上下文信息,大部分采用矩陣分解的方式計算用戶潛在特征向量,存在一定的局限性:僅僅考慮單個物品或兩個物品之間的關系,未能考慮推薦列表整體的特性。對于分布不均勻的數據,物品對或興趣點對的差異過大,從而對推薦精度的影響程度存在差異。
為挖掘個性化的用戶偏好,從推薦列表整體出發,考慮用戶推薦列表中不同位置的關注度存在差異。本文改進列表級排序學習方法,把ListMLE[10]引入興趣點推薦,并融合社交信息作為打分函數計算方式,采用代價敏感方式賦予列表不同位置不同權重,最終得到排序模型,為用戶產生推薦結果。
1 ListMLE算法

設定一個隨機初始化打分函數Score對這n個興趣點列表進行評價:
(1)
Sort函數呈降序排列,則它們對應的人工排名為
(2)
將集合表示為T={(U,H),Y},此集合作為ListMLE的訓練集。將用戶的興趣點列表表示為向量x(j),每個向量都由打分函數得出對應分數。因此將訓練集改寫為T={X,Y}。

依據Plackeet-luce模型,定義排序模型中序列的概率為
(3)
式中:w為模型參數;y(i)和y(k)為排序列表中第i和k個興趣點。因此排序似然函數為
(4)
對似然函數求導得梯度公式(5):
(5)
根據公式(5)使用梯度下降算法求得參數w,通過訓練獲取排序模型后,可以對用戶的興趣點列表進行排序后進行推薦。ListMLE算法的步驟如下:
1)首先預處理數據,將數據預處理成列表形式{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))} ,同時定義學習率η以及容忍誤差ε。
2)其次初始化神經網絡參數w,開始循環,將所有的樣本輸入到神經網絡中,并計算梯度Δw,通過梯度依次更新參數w,直至所有樣本已經訓練完成。
3)每次循環計算訓練集的損失,直至損失小于設定的容忍誤差ε。循環結束后輸出訓練好的神經網絡參數w并產生推薦結果。
在數據的處理過程中,ListMLE算法一般采用隨機初始化函數Score的方式對每個列表進行初始化的打分,在基于位置的社交網絡中,上下文信息是解決初始化問題以及冷啟動問題的有效途徑,本文接下來采用用戶之間的社交關系信息作為初始化列表分數的依據,同時針對用戶對于列表前后部分的關注度存在差異的問題,使用代價敏感的方式賦予列表中不同位置的興趣點不同的權重,以此作為基于社交信任與代價敏感的得分函數。
2 融合社交關系與代價敏感的推薦算法
社交關系是基于位置社交網絡環境下的一個重要的上下文信息,存在社交關系的用戶在不斷地相互影響他們之間的興趣偏好。據此在訓練前假設用戶的興趣愛好完全由社交關系決定,即用戶A喜歡的興趣點對于他的朋友用戶B同樣喜歡。在實際應用中,排序列表中不同的位置代表了用戶對興趣點不同的偏好程度,排名越靠前代表用戶對于此興趣點的興趣越大,但列表中不同位置興趣點排序出現錯誤的代價不同,用戶往往關心排序列表前面的興趣點,對于排序列表靠后的興趣點的關心程度有一定的下降,代價敏感學習也是基于此原理。
2.1 社交關系影響
2.1.1 社交相似度計算
首先采用皮爾森相關系數計算用戶之間的相似度,如公式(6)所示:
sim(u1,u2)=
(6)

2.1.2 信任度計算
在傳統的社交關系矩陣Ru1,u2,用戶u1與用戶u2存在社會關系,則對應元素值為1,反之為0。社交關系集合為U{u1,u2|Ru1,u2=1}。
對于社交關系集合,本文利用信任度計算衡量用戶之間的社交關系遠近。信任度是由用戶共同簽到數量與用戶簽到質量決定。共同簽到數量比值T1計算見公式(7):
(7)
式中Nu1u2表示用戶u1與用戶u2之間的共同的興趣點數量。簽到質量是具有社交關系用戶對于興趣點的頻率與其他用戶對于此興趣點的簽到頻率之差是否小于一個閾值δ。簽到質量T2計算見公式(8)和公式(9):
(8)
式中:Qu1,i表示用戶u1對興趣點i的簽到頻率;δ表示閾值。
(9)
用戶之間信任度T計算見公式(10):
T=T1+T2。
(10)
2.2 代價敏感打分函數
融合社交相似度與信任度表示打分函數中社交關系的影響,公式如下:
Social_Score(u,i)=sim(u1,u2)·
T(u1,u2)·Uu,i。
(11)
代價敏感學習賦予排序列表中每個興趣點不同的權重,計算排序列表時為列表中每個興趣點學習權重αi,權重αi之和為1且隨著排序列表興趣點位置變化,權重由前向后不斷降低。將計算出的社交關系影響與代價敏感方法結合得出打分函數的計算見公式(12):
(12)
式中:L表示興趣點列表的長度;u表示用戶;i表示興趣點。
2.3 改進的ListMLE推薦算法
所提推薦算法考慮到用戶信任關系,將用戶間社交關系信息作為初始化列表分數的依據;同時考慮到列表前后關注度差異,使用代價敏感的方式賦予列表中不同位置的興趣點不同的權重。為提升推薦質量,將社交關系與代價敏感打分函數融合到ListMLE算法中,算法偽代碼描述如下:
輸入:用戶-興趣點簽到數據,用戶-社交關系數據集,用戶-興趣點-地理位置信息數據集。
輸出:TOP-K推薦列表
步驟1 數據預處理,依據數據集為每個用戶生成一定數量的推薦列表 。
步驟2 社交關系影響計算。通過公式(6)計算興趣點的相似度。通過公式(7)—公式(10)計算興趣點之間的信任度,并最終通過公式(11)計算社交關系對每個用戶每個興趣點的影響。
步驟3 基于代價敏感設置推薦列表中每個興趣點的權重,選取不同代價敏感列表長度,學習不同列表興趣點的權重,依據評價標準選取最優參數作為推薦列表的最終得分
步驟4 將步驟2中得到社交關系影響與步驟3得到推薦列表長度與權重融合生成推薦列表分數即公式(12)。
步驟5 將推薦列表與分數輸入神經網絡,依據公式(4)排序損失函數利用梯度下降算法計算更新參數w,產生推薦結果。
3 實驗數據分析
3.1 實驗數據集與實驗環境
實驗所用數據集為Gowalla數據集。Gowalla是基于位置的社交網站,在此網站上用戶通過簽到分享位置,數據集源自SNAP網站,包括18 737個用戶對于32 510個興趣點的簽到信息。
實驗環境為Intel(R) Core(TM)i7-6700HQ,2.6 GHZ CPU 24 GB RAM,在Window10系統下采用Python3.6實現算法,選取PyCharm (Community Edition)作為開發平臺。
3.2 實驗對比
3.2.1 模型與其他模型對比
實驗選取準確率、召回率作為算法評價標準[11],比較融合了社交關系與代價敏感的改進ListMLE、RankGEOFM[12]、ListNet[13]與對級排序學習方法BPR-MF[14-15]四種算法在Gowalla數據集下的評價標準的差異,討論分析了融合社交關系與代價敏感打分函數的影響。
1)為探究列表級排序學習方法與對級排序方法在興趣點推薦領域中的推薦精度差異, BPR-MF算法特征向量長度為10。四種模型在Gowalla數據集下的精度對比如圖1和2所示。

圖 1 改進ListMLE與其他模型在Gowalla數據集中準確度對比圖Fig.1 Comparison of ListMLE and other models of accuracy in Gowalla dataset

圖 2 改進ListMLE與其他模型在Gowalla數據集中召回率對比圖Fig.2 Comparison of ListMLE and other models of recall in Gowalla dataset
2)改進ListMLE算法和ListNET算法隨著TOP-K值的變化呈穩定下降趨勢,而BPR-MF算法在TOP-K值為[10,20]之間出現了一定程度的波動,驗證了列表級排序學習的健壯性和穩定性。當TOP-K值為5、10、15、20、25時,改進ListMLE算法相比于BPR-MF算法分別提升了18.8%、65.8%、29.7%、34.7%、51.2%。BPR-MF算法是基于對級排序學習的興趣點推薦方法,訓練數據是以用戶與兩個興趣點的偏序關系對的形式,通過對比兩種算法的準確度,改進ListMLE在準確度上相比BPR-MF算法有明顯的提升,同時對比改進ListNET算法,RankGEOFM算法和BPR-MF算法,可以看出列表級的排序學習方法在推薦精度上比對級的排序學習方法在興趣點推薦中有明顯的提升,驗證了將訓練數據以列表的形式輸入更符合實際的理念和貼近用戶的偏好。此外,通過四種算法召回率的對比,改進的ListMLE算法在召回率上也優于其他四種算法。
3.2.2 融合社交關系與代價敏感的打分函數對比
為驗證融合社交關系的代價敏感函數對于ListMLE算法的影響,設計實驗選取Gowalla數據集,設置TOP-K值為5、10、15、20。對比未加入代價敏感權重的ListMLE算法與加入代價敏感權重的ListMLE算法的準確度,實驗結果見圖3。有代價敏感的ListMLE算法在準確度上相對于沒有加入代價敏感學習的ListMLE算法分別提升了16.3%、15.2%、12.5%、14.5%。在準確度的對比下,代價敏感學習對于推薦結果有較為顯著的提升,驗證了代價敏感學習的意義,即用戶往往對于排序列表前面的興趣點更為看重,對于排序列表后面的興趣點的關注程度會有一定的下降。
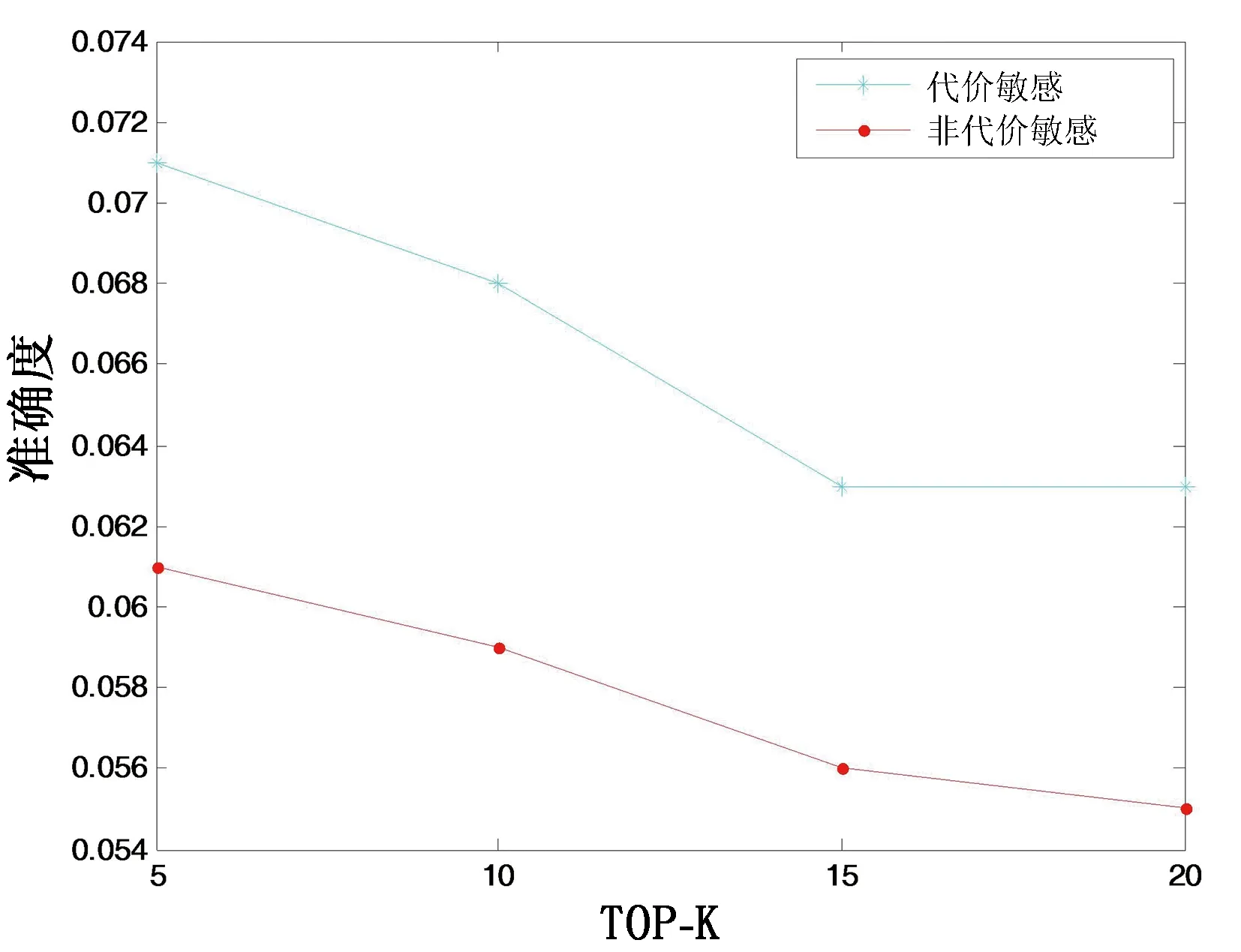
圖 3 代價敏感函數與非代價敏感函數準確度對比Fig. 3 Comparison of cost-sensitive function and non-cost-sensitive function in precision
3.2.3 代價敏感的排序列表長度
圖4表示在Gowalla數據集下改進ListMLE算法在不同的興趣點列表長度下的準確度和召回率。首先選取實驗區間[4,12],設置步長變化為1,改進ListMLE算法的準確度在權重賦值列表長度為6時取得最優值0.071,召回率取得最優值0.042,在4時準確度取得次優值0.068,召回率為0.04,之后呈現不斷下降趨勢。由圖4可以看出,用戶對于排序列表的重視僅限于排序列表中的頭部位置,隨著列表長度的增加,用戶對于興趣點的重視也在不斷下降,側面反映了用戶的偏好,也驗證了代價敏感的思想的有效性。
實驗表明在代價敏感函數中,將興趣點列表的長度設置為6時,ListMLE算法的推薦精度達到最優。
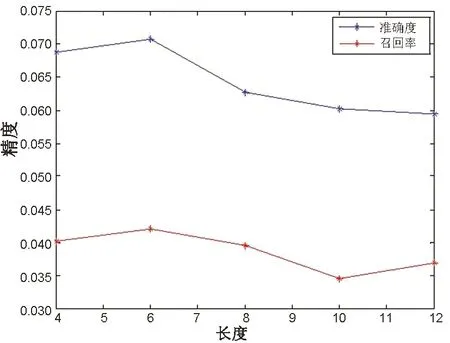
圖4 代價敏感列表長度Fig.4 Length of list with cost-sensitive
4 結束語
為緩解興趣點推薦過程中的數據稀疏問題,進一步提高推薦精度,提出一種融合代價敏感與社交關系的改進ListMLE推薦算法。針對ListMLE算法中打分函數不能很好地擬合用戶興趣偏好問題,提出了融合社交信任的方式作為打分函數的依據,并依據用戶對于推薦列表的不同位置存在不同的關注程度,將代價敏感學習融入打分函數,生成基于社交信任與代價敏感的打分函數應用到興趣點推薦過程中。實驗結果證明,改進的ListMLE算法在興趣點推薦領域中不同數據集下的準確度和召回率優于基線算法。
未來將嘗試對多種上下文信息融合展開深入研究,并使用深度學習模型與算法結合,以進一步提高推薦性能。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
