
基于協處理器的HBase分類二級索引設計
2021-05-12 04:34:00陳順舉鄭林江
重慶理工大學學報(自然科學) 2021年4期
關鍵詞:實驗
陳順舉,鄒 喆,劉 銳,陶 濤,汪 超,鄭林江
(1.重慶市公安局渝北區分局交通巡邏警察支隊,重慶 401120;2.重慶大學計算機學院,重慶 400044)
隨著物聯網和傳感器技術的快速發展,產生了海量的多源異構數據,針對這些大數據的儲存和管理逐漸成為了研究的熱點。傳統關系型數據庫由于存儲能力和擴展性等方面的不足,無法滿足海量數據實時的查詢處理需求[1]。近年來,非關系型數據庫的應用和發展為海量數據的存儲管理帶來了新的研究思路[2]。HBase[3]作為其中的代表,是一種被廣泛應用、高效的分布式數據庫。它在行鍵上建立了類B+樹的索引,可以支持基于行鍵的快速查詢。但對于非行鍵列的查詢,由于缺少索引能力,需要對全表進行掃描。全表掃描在海量數據下的查詢時延是難以接受的,極大地影響了HBase非行鍵列的查詢性能。
為了提升HBase對非行鍵列的查詢性能,研究提出二級索引方案,建立非行鍵列和行鍵之間的索引。在查詢非行鍵列時,先從二級索引中查詢對應的行鍵集合,再通過得到的行鍵集在HBase中查找最終結果。近年來,各類二級索引技術相繼提出,為HBase快速查詢提供了解決方案。但由于應用場景和HBase特性的限制,這些方案仍然存在數據不一致、維護代價高等問題,并且在設計中未充分考慮通信開銷和索引結構的分類和優化。
基于上述問題,設計一種基于協處理器的HBase分類二級索引方案。該方案提出一種基于協處理器的索引管理和并行查詢機制,通過Observer在內存中建立并維護索引,使得索引和數據始終存儲在同一個RegionServer中,能有效降低通信時間開銷,保證數據和索引的一致性;同時,通過Endpoint設計Region級別的并行查詢算法,進一步提升了HBase的查詢性能。針對索引結構單一,未充分利用內存性能的問題,本文提出一種分類內存索引模型。根據非行鍵列的基數大小和有無范圍查詢需求,設計并優化3種索引結構。在構建二級索引時,選擇恰當的結構,可以有效平衡查詢性能和索引性能。
1 相關研究
研究領域常采用二級索引方案來提升HBase的查詢性能。通過對待索引列建立與行鍵對應的二級索引,將非行鍵列的查詢轉換成查詢二級索引對應的行鍵和通過所得行鍵在HBase中查詢結果2個步驟[4]。圖1中對列族 CF下的 id列和time列分別建立屬性值到對應行鍵的映射關系。為滿足組合條件下的查詢需要,可以選擇性的維護組合條件查詢的索引結構。根據索引存儲方式的不同,二級索引方案又可分為基于客戶端、基于HBase內部機制和基于內存的方案。

圖1 HBase二級索引結構
1)基于客戶端的方案:ITHBase[5]是由開源社區開發的一款帶索引的事務型HBase擴展,其通過客戶端邏輯構建并維護索引表,一個查詢請求需要2次遠程的過程調用。近年來,基于Solr構建HBase二級索引的方案[6]受到業界廣泛應用。Solr[7]是一款高效的基于Lucene的企業級全文搜索引擎,通過將HBase中的數據以HTTP請求的方式發送到Solr服務器,即可建立非行鍵列到行鍵的二級索引結構。在查詢索引時,得益于Solr高效的檢索性能,只需通過Get請求即可得到對應的索引結果。此類方案將索引存儲于HBase集群之外的客戶端或第三方平臺中,需要額外建立和維護索引,會出現索引維護困難,數據不一致等問題。
2)基于HBase內部機制的方案:隨著HBase功能的加強,HBase 0.92版本以后引入了協處理器的概念。它可以將用戶自定義的代碼放在服務器上運行,允許用戶執行Region級的操作[8]。協處理器又分為 Observer和 Endpoint兩類,其中Observer與觸發器類似,當特定事件發生時會觸發回調函數的執行;Endpoint則更像存儲過程,支持將用戶自定義的操作添加到服務器端。用戶可以組合Observer和Endpoint實現特定的功能,極大豐富了HBase的可用性。Hindex[9]是華為基于協處理器對HBase二級索引的實現,其核心思想是保證索引表和主表在同一個RegionServer上,能有效降低節點間的數據傳輸開銷。Zou等[10]提出了互補聚簇式索引CCIndex,其通過在索引表中額外存儲詳細的數據信息,能節省結果查詢帶來的時間開銷,從而提升數據查詢性能。現有的這些基于HBase內部機制的方案,通常只利用Observer協處理器建立和維護索引。在查詢時需要修改scan函數并添加過濾器,未能有效利用Endpoint的并行處理能力,減少通信時間消耗,且需要額外建立索引表,會導致插入性能下降,索引空間開銷過大等問題。
3)基于內存的方案:隨著內存性能的提升和價格的下降,內存在實時數據處理中發揮了越來越重要的作用。目前,用內存計算提升大數據處理性能已成為公認的發展方向[11]。廣泛應用的內存索引有:T樹、CSS/CSB+樹、哈希、BD樹以及它們的改進結構。其中,T樹[12]是針對主存訪問優化的索引技術,能有效節省空間占用,但由于較高的TBL失配率會影響其查詢效率;基于緩存敏感的CSS樹/CSB+樹[13]減少了高速緩存對索引的影響,提高了查詢效率,但會導致更新性能差等問題;哈希索引則具有極好的隨機查詢性能,但存在空間利用問題,改進的可擴展哈希、鏈接桶哈希[14]等結構可以提升其整體性能;BD樹[15]將樹形結構與哈希表結合,既對緩存作了優化,又實現了范圍查詢。基于這些內存索引結構,越來越多的研究選擇將部分或全部二級索引存放在內存中,極大地提升了索引的管理和查詢性能。葛微等[16]提出了一種名為HiBase的基于分層式索引的設計方案,在持久化索引表的基礎上,對熱點數據在Redis內存數據庫中進行緩存,并利用熱度累積策略替換緩存,有效提高了查詢效率。Ye等[17]針對傳感器數據提出了基于協處理器的索引方案,在內存中建立并維護HT樹索引,顯著提升了索引數據的檢索速度。此類方案利用了內存查詢處理的速度優勢,但仍存在索引結構單一,未充分考慮待索引列的數據特征和查詢需求等問題。
2 基于協處理器的分類二級索引
2.1 整體框架
基于協處理器的HBase分類二級索引方案的整體框架如圖2所示,主要由數據表模塊、索引模塊和查詢模塊3個部分組成。其中,數據表模塊通過設計滿足存儲需求的行鍵和列族,更好地持久化原始數據。索引模塊則通過基于Observer的索引管理機制,在數據插入和更新的同時,構建并維護每個Region中的二級索引。查詢模塊通過基于Endpoint的并行查詢算法實現對非行鍵列的快速查詢。此外,為防止內存索引斷電丟失,索引結果會定期序列化并存儲至HDFS。
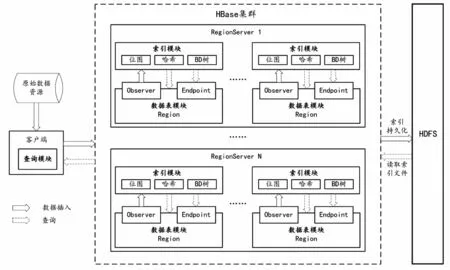
圖2 整體框架
1)數據表模塊:數據表模塊用于持久化需要存儲的數據,在構建時主要考慮行鍵和列族的設計。設計行鍵時,需要選擇能反映數據重要特征的字段組合成行鍵,使其滿足唯一、長度較短、熱點分散等特性。設計列族時,為避免過多列族帶來額外的IO操作,導致系統性能下降的問題,通常僅需設計一個列族,用于存儲一行原始數據的所有值。設計表時,為實現對讀寫請求的負載均衡,可以對數據表進行預分區。
2)索引模塊:索引模塊用于管理Region級別的索引,在內存中為每個Region分別構建分類二級索引。采用基于Observer的索引管理機制,在數據插入時,按數據特征和查詢需求,選擇位圖索引、哈希索引和BD樹索引中的一種結構構建二級索引。在Region發生分裂或遷移時,對應的索引也需要分裂或遷移,從而保證索引和數據始終在同一RegionServer中。
3)查詢模塊:查詢模塊用于接收客戶端的查詢需求。采用基于Endpoint的并行查詢算法,在該表所有在線的Region中并行查詢二級索引獲取行鍵集合后,在對應Region中直接批量獲取結果,并返回至客戶端。客戶端接收所有結果后,進行匯總。
2.2 基于協處理器的索引管理和并行查詢機制
為了實現高效的索引管理和數據查詢,本文提出一種基于協處理器的索引管理和并行查詢機制,包括基于Observer的索引管理機制和基于Endpoint的并行查詢算法。
2.2.1 基于Observer的索引管理機制
索引管理機制流程如圖3所示,包括索引構建和索引維護兩部分。構建索引時,根據數據輸入方式的不同,可分為面向流式數據和面向歷史數據2類。
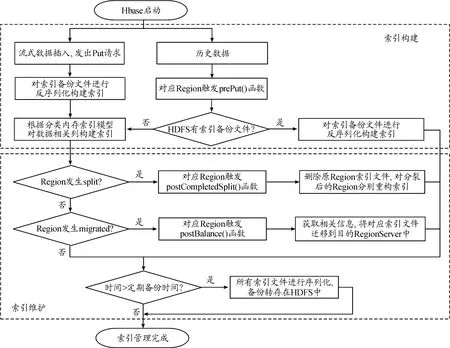
圖3 索引管理流程框圖
對于流式數據的索引構建方法,本文重寫Observer提供的回調函數prePut,每插入1條數據前會被觸發調用。prePut函數根據索引信息對用戶發起的Put操作進行分析,當Put操作的數據包含索引列時,根據分類內存索引模型對其構建索引。由于索引存儲于內存中,為了防止掉電丟失,需要對索引文件進行序列化,定期轉存在HDFS中。歷史數據一般相對較大,且已存于HBase數據庫中,為了加快這些歷史數據的索引構建速度,本文重寫Observer提供的回調函數postOpen,當Region加載完成后被觸發調用,若HDFS中有存儲完整的索引文件,可以直接對文件進行反序列化操作構建索引。否則,需要遍歷Region中的所有數據,重新構建索引。
在索引構建完畢后,為了保證索引與數據存儲在同一RegionServer中,需要對索引進行維護。主要體現在2個方面,即Region的split和migrated,這里同樣利用Observer相關的回調函數進行維護。當Region發生split操作時,1個Region會分裂為2個新的Region。通過重寫觸發調用的postCompletedSplit函數,刪除原Region的索引文件,并對分裂后產生的Region重新讀取數據,分別構建索引。當 Region發生migrated操作時,1個Region會被分配到其他RegionServer中。通過重寫觸發調用postBalance函數,根據從Region計劃參數中獲取到待分配Region,源RegionServer和目的RegionServer等信息,把索引文件遷移到對應的目的RegionServer中。為了提高框架的查詢效率,發揮協處理器處理Region級別操作的優勢,需要根據數據特點和查詢需求構建適合的索引結構,這將在2.3中具體討論。
2.2.2 基于Endpoint的并行查詢算法
由于查詢條件是否包含行鍵對查詢時間影響很大,本文在客戶端中對行鍵的查詢和非行鍵列的查詢分別進行處理。對于含有行鍵的查詢,直接使用HBase自帶的Get和Scan函數處理即可。對于含有非行鍵列的查詢,為了充分利用HBase分布式特性,提升查詢效率,本文實現了基于Endpoint的并行化查詢算法。相較于MapReduce框架,Endpoint更加輕量級,查詢效率更高,花費的構建時間和資源也更少,非常適用于本文的查詢環境。Endpoint的實現包括了基于Protobuf的RPC定義,協議接口實現和調用函數實現等步驟[18]。
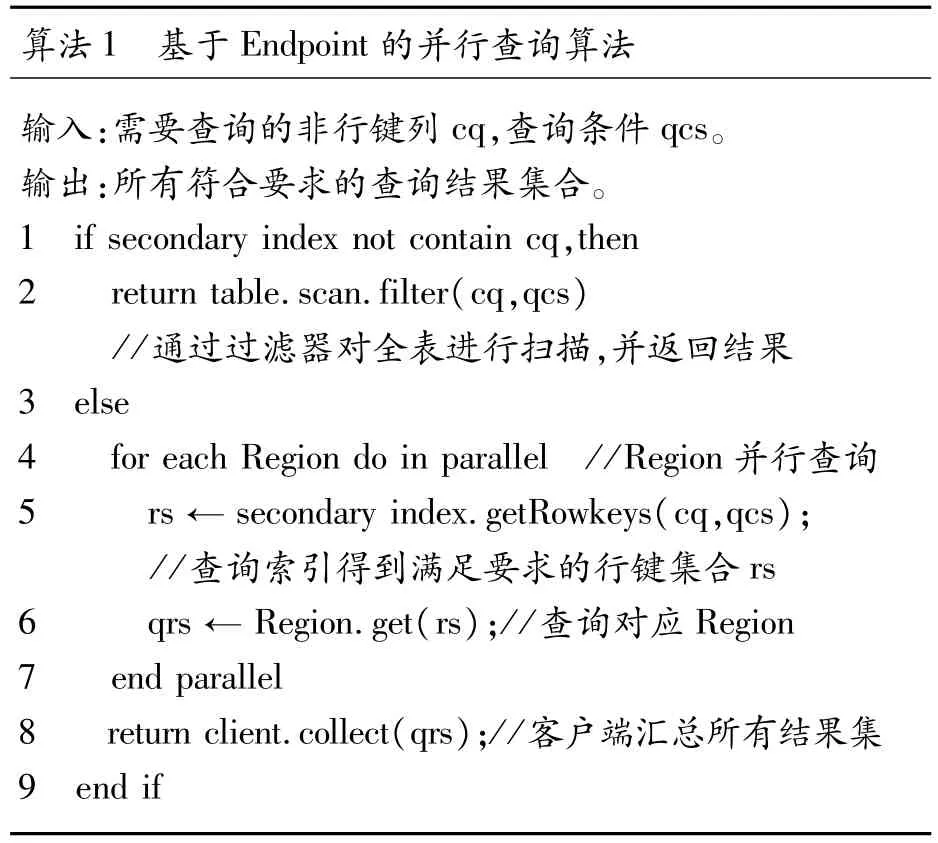
算法1 基于Endpoint的并行查詢算法輸入:需要查詢的非行鍵列cq,查詢條件qcs。輸出:所有符合要求的查詢結果集合。1 if secondary index not contain cq,then 2 return table.scan.filter(cq,qcs)//通過過濾器對全表進行掃描,并返回結果3 else 4 for each Region do in parallel //Region并行查詢5 rs← secondary index.getRowkeys(cq,qcs);//查詢索引得到滿足要求的行鍵集合rs 6 qrs← Region.get(rs);//查詢對應 Region 7 end parallel 8 return client.collect(qrs);//客戶端匯總所有結果集9 end if
對非行鍵列的查詢如算法1所示。當系統未對查詢列建立二級索引時,需要利用查詢條件設置過濾器并掃描全表以獲得查詢結果集合。當查詢列包含相應二級索引時,行4~7描述了所有Region并行執行Endpoint中設計的函數。在每個Endpoint查詢過程中,先查詢對應的二級索引以獲得滿足要求的行鍵集合rs,再根據rs訪問Region中的數據,得到結果集qrs返回至客戶端。在這里由于查詢在每個Region中并行執行,可以獲得高效的查詢效率。加之索引和數據維護在同一個RegionServer中,在得到行鍵后可以直接在對應Region中查找到數據,能有效減少傳輸開銷,進一步提高查詢效率。最后,客戶端只需要匯總從Region接收到的結果即可。
2.3 分類內存索引模型
列的基數大小和有無范圍查詢需求直接影響了索引結構的選擇,構建符合數據特征和查詢需求的索引可以節省索引開銷,穩定查詢時間,從而平衡索引性能和查詢性能。為此,本文根據待索引列的基數大小和有無范圍查詢需求,構建了3種不同的二級索引結構。分類內存索引模型如圖4所示。針對基數較小的列,在每個Region中分別構建位圖索引。針對基數較大但無范圍查詢需求的列,構建哈希索引。針對基數較大且有范圍查詢需求的列,則構建BD樹索引。索引存儲在Region的內存中,詳細的維護和查詢過程見2.2節。
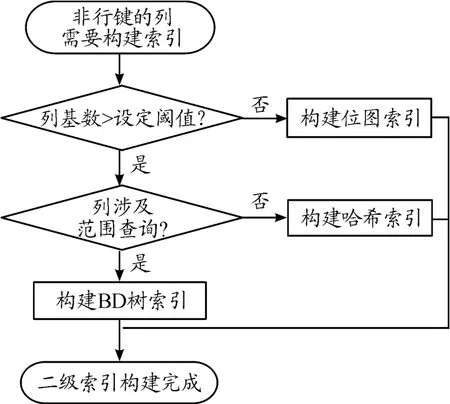
圖4 分類內存索引模型
2.3.1 基數較小列的位圖索引
列基數是指該列具有的不相同屬性值的個數,通常將基數小于總行數0.1%的列認定為基數較小列[19]。例如,在作為實驗數據集的出租GPS數據中,運營狀態這一列有空車、載客2種值,列基數為2,屬于基數較小列。對此列建立索引時,由于屬性的重復值非常多,樹形結構索引非但不能提升數據的查詢性能,還會帶來額外的空間開銷。故本文選擇位圖索引結構為基數較小列構建二級索引。
位圖索引是一種使用位向量表示數據信息的索引結構,其由比特位0和1組成。檢索時,通過將查詢條件轉換為布爾邏輯運算,能有效提升索引的查詢性能[20]。設有一個含有n行記錄的數據表,其上有一個基數大小為m的基數較小列。針對該列構建位圖索引時,需要創建m個長度為n的位向量。其中,每個屬性值b對應1個位向量Y,Yi用于記錄數據表中第i行記錄在該列的取值情況。若該列屬性值等于b,則Yi=1;否則,Yi=0。對出租汽車GPS數據表中運營狀態這一列建立位圖索引,如圖5所示。由于運營狀態的列基數為2,故需要構建2個長度為N的列向量。

圖5 出租車GPS數據表運營狀態位圖索引
位圖索引采用比特位存儲數據信息,由此帶來的索引空間開銷很小。8條某個屬性值的取值情況對應8個比特位,只需占用1個字節的空間。例如,在800萬條實驗數據中對運營狀態為載客的情況構建位圖索引,僅有不到1 MB的索引空間開銷。此外,位圖索引還可以將多個基數較小列的組合查詢轉換為高效的布爾邏輯運算。例如實驗數據中,要查詢運營狀態為“載客”,行駛方向為“30”的行車記錄,只需要將運營狀態列中屬性值為“載客”的位向量與行駛方向列中屬性值為“30”的位向量進行按位與運算,得到該組合查詢對應的位向量Z。再對Z進行遍歷,查詢Zi=1對應的第i條記錄即為所需的行鍵值。
2.3.2 基數較大但無范圍查詢需求列的哈希索引
待索引列的基數較大時,可以使用哈希索引或樹形結構索引。但當該列無范圍查詢需求,即可根據確定的屬性值進行等值查詢時,一般選擇哈希索引可以獲得更好的索引性能。
本文選擇鏈接桶哈希對基數較大但無范圍查詢需求的列構建二級索引。鏈接桶哈希索引由一組鏈表構成,每一個鏈表稱為一個桶,桶中元素具有相同的哈希碼并通過單鏈表進行組織。插入數據時,先通過關鍵字生成哈希碼,從而確定所屬桶位置;然后在該桶對應的鏈表頭部插入數據即可。這種采用鏈式結構處理哈希沖突的方法,能較好地適用于海量數據頻繁插入的情況。查詢索引時,同樣通過哈希碼先確定桶的位置,然后遍歷對應的鏈表,直到查詢到指定記錄的行鍵。桶的數量對鏈接桶哈希索引的性能影響較大。若桶的數量過多,會導致索引空間開銷增大,帶來內存空間的浪費;若桶的數量過少,則會導致同一桶中鏈接的數據增多,進而造成查詢性能的降低和退化。由于本文對每個Region分別構建哈希索引,可以根據Region大小事先確定桶的數量,從而解決上述空間浪費和性能下降的問題。此外,為了進一步降低哈希索引帶來的空間開銷,本文適當提高了負載因子。負載因子的提高意味著索引結構更加緊湊,需要構建的桶數量隨之減少。雖然在一定程度上會增加索引查詢的時間,但這是對索引性能和查詢性能的綜合考量,在可接受范圍內。實驗數據中,車輛eid就屬于基數較大但無范圍查詢需求的列。對該列進行索引查詢時,通過在內存中對不同Region的哈希索引進行并行檢索,能獲得非常理想的查詢性能,且不會隨著數據量的增大而發生陡變。
2.3.3 基數較大且有范圍查詢需求列的BD樹索引
哈希索引無法支持屬性值的范圍查詢,故本文選擇BD樹對基數較大且有范圍查詢需求的列構建二級索引。BD樹由上下2層構成:其中,上層的非葉子節點為樹形結構,通常采用B+樹進行實現;下層的葉子節點為哈希表,由n個哈希桶組成。其結合了B+樹索引和哈希索引的優點,能實現快速的索引查詢。此外,各個葉子節點通過指針按順序鏈接,可以滿足范圍查詢的需求。
在構建BD樹時,先通過關鍵字找到對應的葉子節點。然后通過計算哈希碼確定哈希桶的位置,并將對應的行鍵值插入到該桶中。若桶中數據未滿,則插入操作完成;否則,需要對BD樹進行分裂操作。即將原葉子節點中所有記錄按關鍵字大小分配到2個新的葉子節點中,通常將原葉子節點中關鍵字的最大值和最小值的均值作為分界點。葉子節點分裂后可能會引發BD樹索引的調整,故在插入1個新的葉子節點時需要判斷對應BD樹結構是否正常。若正常,則分裂完成;否則,需要對非葉子節點進行相應的分裂操作,即對上層B+樹的結構進行修改,從而指向新的葉子節點。詳細過程可以參考文獻[21]。
在檢索BD樹時,針對單值查詢,先通過關鍵字在B+樹中定位到葉子節點對應的哈希表,然后通過計算哈希碼對哈希表進行查詢,可以很快得到索引結果。針對范圍查詢,假設某個查詢的關鍵字范圍為[qs,qe],首先找到關鍵字 qs所在的哈希表記為U,再找到關鍵字qe所在的哈希表記為V,則U和V間的哈希表的所有值,以及U中關鍵字大于qs對應的值和V中關鍵字小于qe對應的值均為該范圍查詢的結果。
3 實驗與結果分析
3.1 實驗環境與數據集
本文從查詢性能和索引性能等多個方面驗證所提方案的有效性。默認實驗環境共有5個節點,搭建的HBase集群包含1個Master節點和4個RegionServer節點。為了進行對比實驗,本文還搭建了Solr集群和Redis集群,并實現了基于Solr和HiBase的二級索引方案。實驗環境的節點配置信息見表1。

表1 實驗環境節點配置信息表
實驗采用的數據集是出租車行車GPS數據,其來源于重慶市智能交通系統。表2展示了原始數據部分樣本,其中各字段的含義分別是:每行數據在表中的id號、車輛eid(已脫敏處理)、GPS時間、經度、緯度、速度、行駛方向和運營狀態(1為載客、0為空車)。

表2 原始數據
二級索引方案中,非行鍵列的查詢由查詢二級索引對應的行鍵和通過所得行鍵在HBase中查詢結果2個步驟組成。從而有公式:Ttotal=Tindex+Tresult,即整體查詢時間 Ttotal等于索引查詢時間Tindex和結果查詢時間Tresult之和。為了更充分詳盡地驗證所提方案的查詢性能,本文對索引查詢和結果查詢2個部分分別進行實驗,并對比了本文方案和基于Solr以及HiBase方案的整體查詢性能。此外,在實時的查詢速度之上,我們期望方案有較好擴展性和數據插入性能,以及合理的內存占用大小,故對方案的擴展性以及索引的構造時間和內存占用情況也進行了實驗和分析。
3.2 索引查詢對比實驗
本文所提方案根據數據特征和查詢需求在位圖索引、哈希索引和BD樹索引中選擇適合的結構構建二級索引。為驗證這3種不同類型索引的查詢性能,在十萬、百萬、千萬數量級的數據下進行對比實驗。圖6的橫坐標是索引查詢結果的數據量,縱坐標分別是3種索引的查詢時間Tindex。每組實驗測試100次并取平均值作為最終結果。對比實驗中,HiBase方案的索引查詢時間取熱查詢下的最優值,即每次索引查詢均在內存中命中。由于基于Solr的方案時間消耗較大,等比例坐標無法很好地展示,這里使用指數坐標。

圖6 索引查詢時間對比
3.2.1 位圖索引實驗
實驗數據中,行駛方向這一列的基數為360,小于總行數的0.1%,屬于基數較小的列。在對該列的值構建索引時,采用位圖索引。在查詢行駛方向為“360”的行車記錄實驗中,索引查詢時間Tindex如圖6(a)所示。可以看出,位圖索引查詢時間優于基于Solr的方案,但略高于HiBase的熱查詢時間(最優值)。這是因為位圖索引存儲在內存中能獲得高效的查詢性能,但其需要對位向量進行遍歷,相較于HiBase的熱查詢需要更多的時間。隨著數據量增大,本文方案中索引分布式的優勢體現,查詢性能逐漸接近HiBase熱查詢的水平。
3.2.2 哈希索引實驗
實驗數據中,車輛id屬于基數較大但無范圍查詢需求的列,可以在該列上建立哈希索引來獲取相應行鍵。在查找車輛id為“7115”的行車記錄實驗中,索引查詢時間Tindex如圖6(b)所示。可以看出,哈希索引的查詢性能優于基于Solr和HiBase的方案。這是由于使用了基于Region的哈希索引和并行化的查詢方式,查詢時間隨著數據的增長能保持較好的穩定性。
3.2.3 BD樹索引實驗
實驗數據中,速度這一列屬于基數較大且有范圍查詢需求的列,可以在該列上建立BD樹索引來獲取相應行鍵。在查找行駛速度在80~81 km/h的行車記錄實驗中,索引查詢時間Tindex如圖6(c)所示。可以看出,BD樹索引查詢時間是毫秒級的。由于其索引結構的復雜性,故查詢時間稍長但仍優于基于Solr和HiBase的方案。
3.3 結果查詢對比實驗
在通過二級索引獲得查詢對應的行鍵后,需要根據行鍵集合在HBase中查詢結果。為驗證方案中基于協處理器的索引管理和并行查詢機制的有效性,對本文所提方案和基于Solr以及HiBase方案的結果查詢時間進行對比實驗。圖7中的橫坐標是查詢獲得的結果集大小,縱坐標是結果查詢時間Tresult。每組實驗測試100次并取平均值,同樣使用指數指標。可以看出,本文方案的結果查詢性能大大優于對比方案。這是因為基于Solr和HiBase方案都需要在第三方平臺查詢到行鍵集合后,再建立與HBase的連接進行批量的結果查詢,故兩者的結果查詢時間相當。而在本文中,得益于基于Observer的索引管理機制,在得到行鍵集合后可以直接查詢對應Region獲得結果,極大程度地降低了通信開銷。加之基于Endpoint的并行查詢算法在每個Region中進行并行化查詢,本文方案的結果查詢性能相較于對比方案隨著結果量的增加而不斷提升。
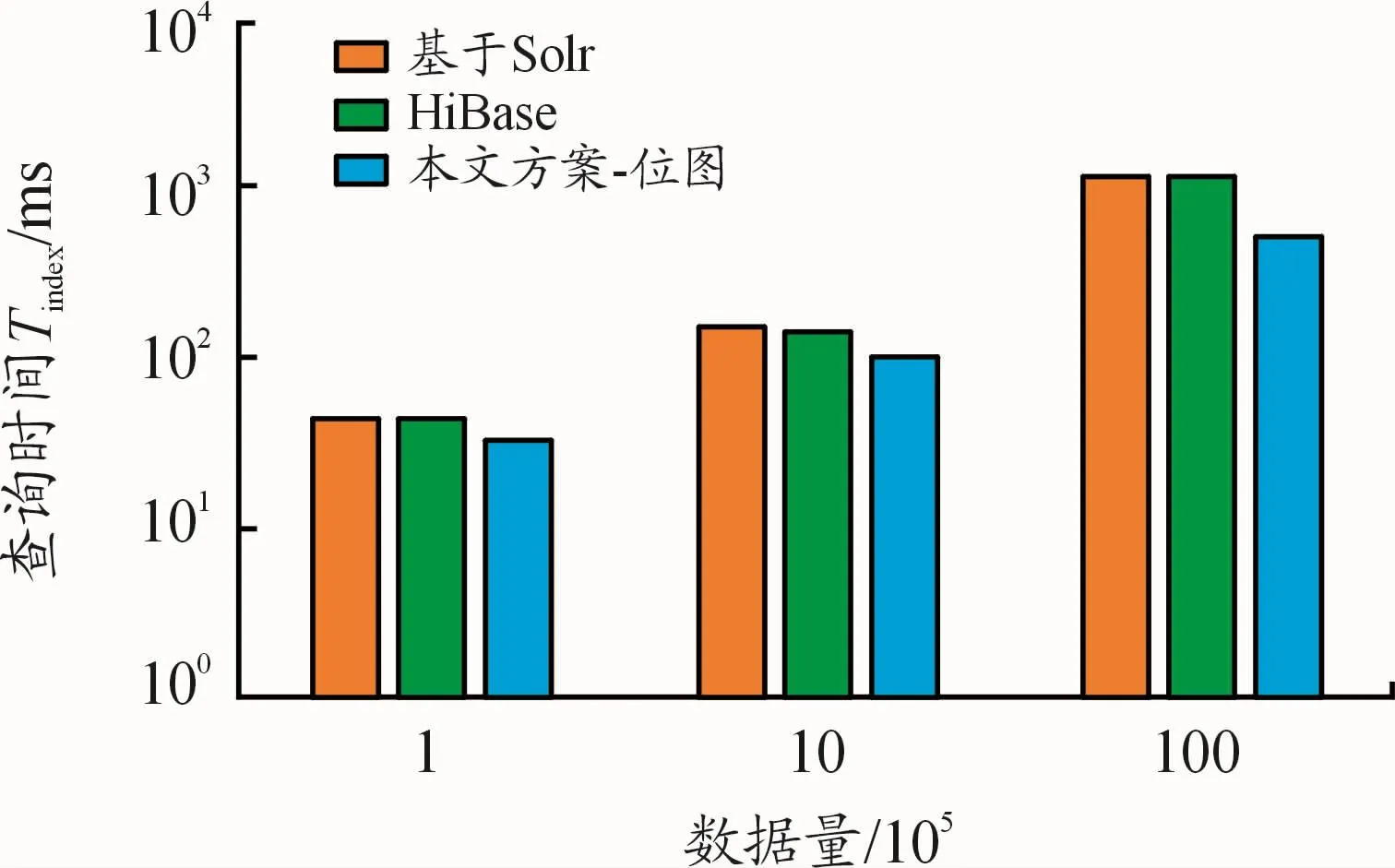
圖7 結果查詢時間對比
3.4 整體查詢性能對比實驗
在對索引查詢和結果查詢分別進行實驗分析后,對本文方案、原生HBase、基于Solr以及HiBase方案的整體查詢性能進行了對比實驗。針對分類索引,對3種不同條件的查詢分別進行100次并取平均值。圖8中的橫坐標是HBase的數據量,縱坐標是整體查詢時間Ttotal,使用指數指標。可以看出,本文方案的整體查詢性能明顯優于對比方案。在數據量較少(10萬量級)的查詢中,方案的查詢性能相較于基于Solr的方案提升了97%,相較于HiBase提升了45%。在數據量較大(1 000萬量級)的查詢中,方案相較于基于Solr的方案查詢性能提升達3.6倍,相較于HiBase性能提升約1.1倍。不僅如此,本文方案隨著數據量的增長表現出穩定的查詢性能,適用于海量數據下的實時查詢。
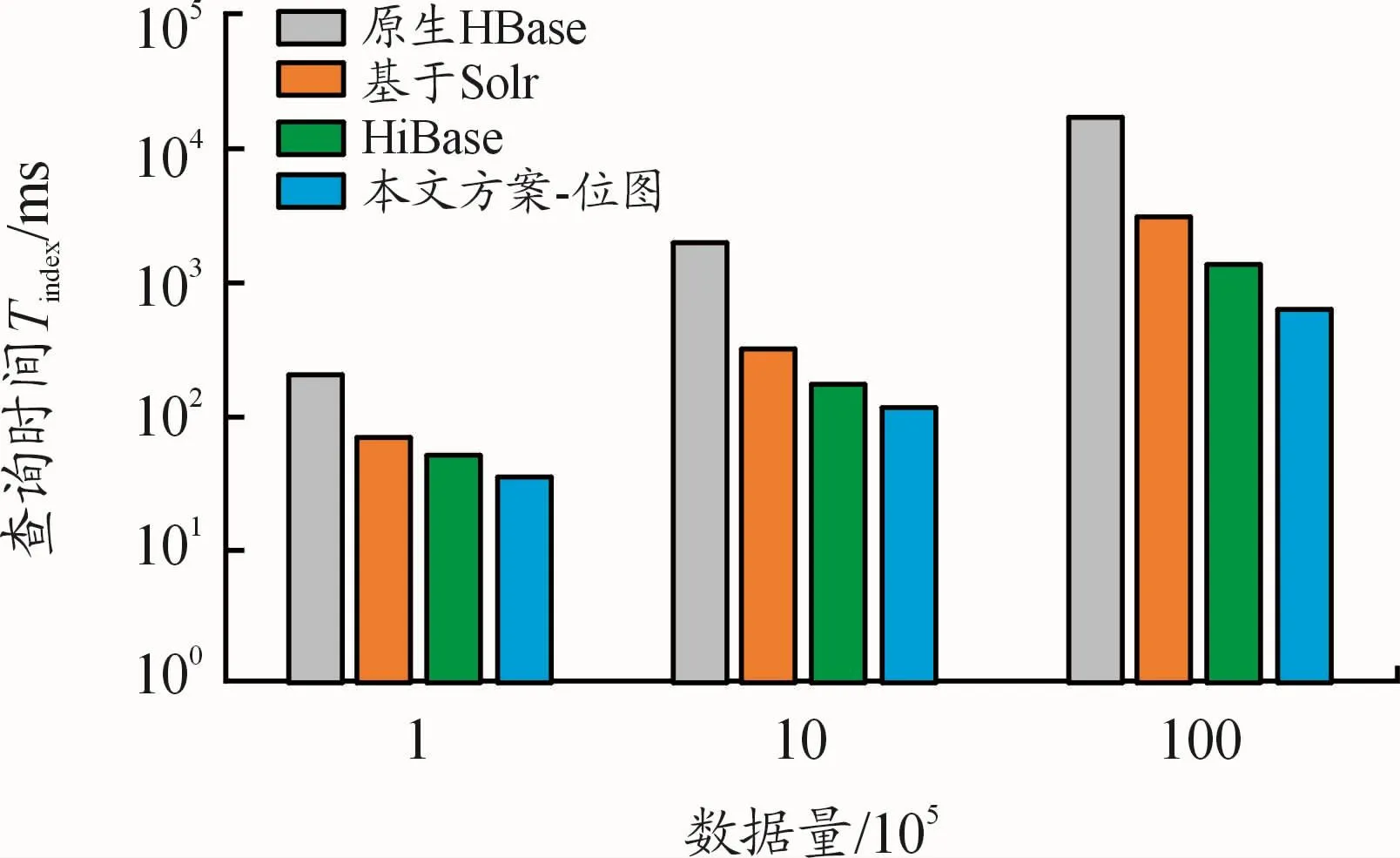
圖8 整體查詢時間對比
3.5 集群擴展實驗
為了驗證本文方案的集群擴展性能,在千萬數量級的數據下對節點數量為3、5、7、9個的集群進行了可擴展性測試。圖9中的橫坐標是集群的節點數量,縱坐標是3種查詢平均的整體查詢時間,每組實驗測試100次并取平均值。可以看出,隨著節點數量的增長,整體查詢時間逐漸降低。這是因為索引查詢和結果查詢均是在RegionServer中并行執行,隨著節點數量的增多,RegionServer增加,故整體查詢時間逐漸降低。
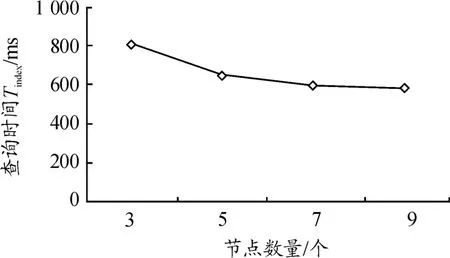
圖9 集群擴展查詢時間
3.6 索引構建時間和空間開銷實驗
二級索引方案是在數據導入階段創建索引的。分別在十萬、百萬、千萬的數據集上對3種不同條件下的查詢建立索引,并測試本文方案的數據導入時間來衡量索引構建時間開銷。同時還測試了原生HBase、基于Solr和HiBase方案的數據導入時間,每組實驗重復10次取平均值。索引構建時間的實驗結果如圖10所示。從中可以發現,原生HBase的導入性能最好,這是由于原生HBase在數據導入時無需構建和維護索引,而其他方案需要基于協處理器觸發索引插入操作。隨著數據量的增長,本文方案的索引構建性能仍然優于對比方案。這是因為索引插入操作全部發生在內存中,消耗時間較少。HiBase方案則需要并行地構建索引記錄并插入到索引表中,較為耗時。基于Solr的方案在對插入數據構建索引記錄之后,需要將其發送至Solr集群并插入到索引表中,故耗時最長。實驗結果表明,本文方案為建立索引所帶來的時間開銷是可以接受的。
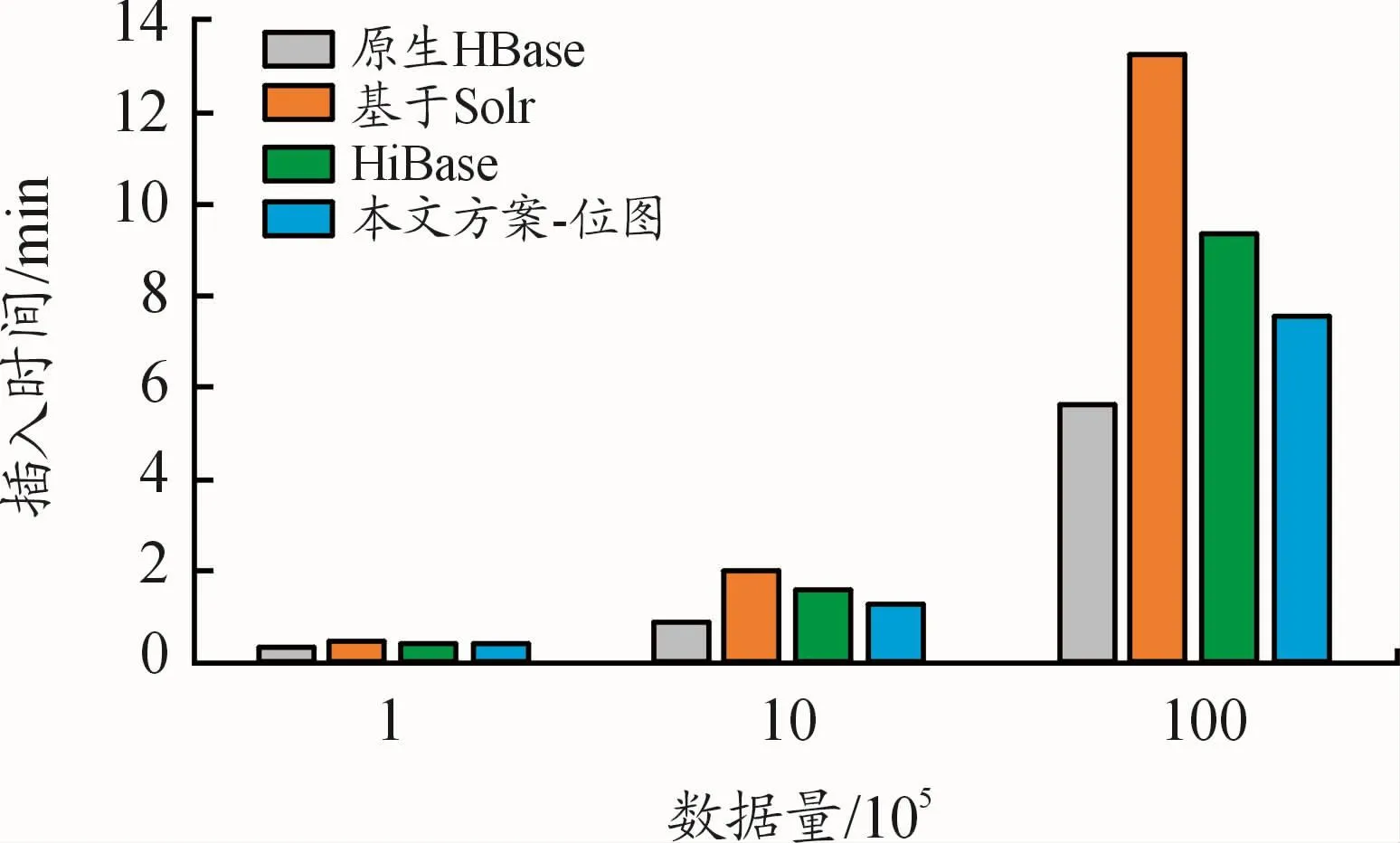
圖10 索引構建時間對比
空間開銷上,由于基于Solr和HiBase的方案占用的內存不是絕對固定的,依賴于用戶的設置,故在此不作對比實驗。對于本文方案,在千萬數量級的數據上建立整體的二級索引(包含關于行駛方向的位圖索引,關于車輛id的哈希索引以及關于速度的BD樹索引),其占用空間的大小約為500 MB,對于采用廉價分布式存儲、具有良好存儲空間可擴展性的Hadoop和HBase系統來說,本文方案占用內存空間以換取更快的查詢性能是可取的。
4 結論
本文研究并實現了一種基于協處理器的HBase分類二級索引方案。其充分利用協處理器機制,在內存中管理索引,并將查詢過程并行化,較大程度上提升了查詢效率。同時,根據數據特征和查詢需求構建不同結構的二級索引,進一步平衡了查詢性能和索引性能。實驗結果表明,本文方案的查詢管理性能優于基于Solr和HiBase方案。下一步,針對海量數據下索引空間開銷較大的問題,會進一步研究緩存機制和替換策略,從而提供更為經濟穩定的查詢可選方案。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
