面向AI 的數據管理技術綜述*
2021-05-18 11:28:26李國良周煊赫
軟件學報 2021年1期
李國良,周煊赫
(清華大學 計算機科學與技術系,北京 100084)
人工智能技術已經滲透到各行各業中.2019 年,中國人工智能核心產業規模接近570 億元,涉及安防、金融、醫療、教育等諸多領域.面向不同的應用需求,人工智能技術已經衍生出了多種不同的機器學習算法,如深度學習、主動學習、強化學習等等.然而人工智能在落地過程中還面臨著3 個挑戰性問題.
? 第一,AI 使用門檻較高.人工智能算法實際的落地情況并不容樂觀.在不同領域下,我們需要構建獨立的人工智能系統來執行操作.如TensorFlow 框架中,我們首先需要用Python 語言書寫程序,然后調用相應的機器學習庫實際執行模型.整個程序設計和執行流程都需要專門的人力和資源投入,開銷比較大.如谷歌公司進行大規模神經網絡學習時,曾需要用有255 臺計算節點的集群單獨訓練具有5.57 億個參數的AmoebaNet-B 模型,每個節點上配備1 024 個TPU 組成的芯片組.此外,這類機器學習框架難以與現有數據庫兼容,存在數據轉換和傳輸的額外開銷;
? 第二,AI 訓練效率較低.首先,現有的AI 系統缺少執行優化技術(如大規模緩存、數據分塊分區、索引等),不僅會導致大量的計算、存儲資源上的浪費,而且會提高程序異常的發生率(如內存溢出、進程阻塞等),嚴重影響了單個任務的執行效率;其次,傳統AI 的執行方式缺少靈活性,芯片(如CPU、ARM、GPU 等)、算法優化(如優化函數、評價指標等)都需要人為指定,不僅提高了對使用人員編程能力的要求,而且難以最大限度地發揮硬件資源優勢,如沒有動態調度機制,很多AI 任務會被阻塞,直到GPU 資源滿足要求為止,降低了整體的執行效率;
? 第三,AI 依賴于高質量的訓練數據.傳統的數據治理工作非常繁雜,需要大量人的參與,并消耗了大部分的資源和時間.首先,大規模機器學習算法需要大量的數據進行訓練,一方面,來自真實場景的原始數據大多不能直接使用,存在大量的缺失值、錯誤值和異常樣本等;另一方面,一個訓練集可能有多個數據源,數據源融合存在格式不一致、冗余信息多、連接開銷大等問題.以圖1 為例,我們可以看出,現有機器學習的整個數據處理流程還存在很大的優化空間.

Fig.1 Problems in the lifecycle of machine learning圖1 機器學習的生命周期及存在的問題
數據庫管理系統經過近60 年的發展,積累了很多較為成熟的數據查詢和管理技術.以一條查詢語句的處理流程為例:首先,基于聲明式語言,用戶只需在查詢語句中聲明高層次條件(如數據列表、屬性約束等);其次,數據庫經過邏輯和物理優化生成執行計劃,利用索引、內存計算、分布式處理等技術高效地執行查詢處理操作.此外,關系型數據庫基于關系表對數據集進行建模,利用外鍵等保證數據一致性.通過結合這些數據管理技術,我們可以有效地解決以上3 個難題:其一,聲明式語言(類SQL)可以降低AI 使用門檻;其二,數據庫優化技術(如索引、計劃選擇、視圖緩存等)可以提升訓練速度,降低資源使用率;其三,數據治理技術可以提升數據質量和AI訓練質量.因此,面向AI 的數據庫技術得到了廣泛關注.
本文從如下4 個層次來介紹數據管理技術如何支持和優化人工智能技術(如圖2 所示).
? 第1 層,用聲明性的語言模型簡化AI 的使用.其一,討論如何用聲明性的SQL 語言代替傳統的AI 高級語言,降低AI 的使用門檻;其二,調研面向AI 的SQL 完備性相關的工作,分析如何細化SQL 支持AI 的粒度;其三,調研面向AI 的SQL 的智能推薦技術,即:對SQL 層進一步進行邏輯封裝,利用可視化等技術進一步提高AI 的易用性(見第1 節);
? 第2 層,用算法優化引擎優化AI 的執行邏輯.其一,調研面向AI 的優化引擎,分析如何支持AI 算法中不同的算子類型;其二,分析AI 算子的代價估計技術,為AI 算法選擇提供基本資料;其三,基于聲明性的語言模型,同一個AI 問題的描述(如類SQL 語句)可以被解析成多種不同類型的AI 算法.因此,這里我們調研AI 算法的自動生成技術,分析如何根據AI 問題選擇、組裝基本的AI 算子,生成高效的執行邏輯;其四,調研AI 模型的版本管理技術,利用數據庫在管理時間序列數據上的經驗,幫助數據分析師高效地組織歷史訓練結果(見第2 節);
? 第3 層,用異構執行引擎提高AI 的物理執行效率.在第2 層中,我們調研了從邏輯層面對AI 算子進行建模的方法,然而在物理層面(如芯片、加速器、單機架構),數據庫技術仍然存在著很多局限性:其一,調研異構的AI 計算方法,分析數據管理技術在硬件優化、優化函數優化、執行邏輯優化這3 個方面的工作;其二,調研數據庫如何基于分布式加速架構(如Hadoop、Spark 等)計算AI,提供大規模的并行計算能力;其三,分別從數據庫內核、AI 芯片、新型數據庫架構這3 個方面調研AI 執行的優化技術(見第3 節);
? 第4 層,用智能數據治理引擎優化數據的管理效率.因為AI 算法嚴重依賴于數據,數據庫在高效支持AI 計算的同時,還需要解決AI 數據收集、融合、清洗等多個方面的問題:其一,真實數據中經常存在大量的錯誤和不一致性,調研面向AI 的數據發現技術;其二,繁雜的數據清洗工作需要消耗大量的人力,調研面向AI 的數據清洗工作;其三,多源異構數據的融合開銷比較大,調研面向AI 的數據融合技術(見第4 節).
最后,我們對未來基于數據庫的人工智能優化技術的發展方向加以展望(見第5 節).
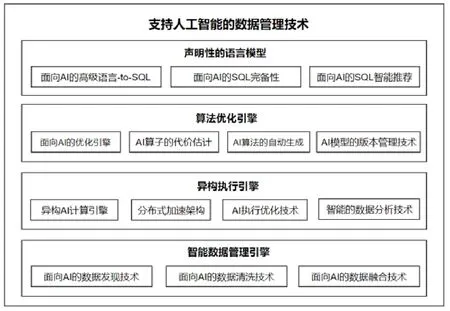
Fig.2 Database management techniques for artificial intelligence圖2 面向人工智能的數據管理技術
不同于已有的綜述文獻[1-3]主要關注人工智能在傳統數據庫技術上的應用,本文創新性地從語言模型、邏輯執行優化、物理執行優化、數據管理這4 個方面綜述數據庫技術如何優化人工智能的使用和執行效率,并給出未來人工智能技術與數據庫內核相結合所面臨的挑戰和機遇.
1 聲明性的語言模型
機器學習繁雜的編程語言已成為普惠AI 的重要障礙.相同的機器學習算法有著多種不同的實現版本,用戶如果沒有足夠的編程經驗,很難快速理解、使用、修改.而SQL 作為高級編程語言,只需聲明輸入數據之間的關系和需要的數據,就可以方便地為用戶所使用.因此,如果可以為用戶提供基于SQL-like 接口調用機器學習模型的方法,用戶使用AI 技術的門檻便會大為降低.本文中,我們分別從3 個方面分析如何更好地建立聲明性的語言模型:(1)高級語言-to-SQL.實現用類SQL 語言聲明機器學習算法;(2)AI-SQL 的完備性.根據機器學習算法不同階段的特點,合理設計SQL 語法,提高語言模型的擴容能力和執行效率;(3)聲明性的智能分析服務.在SQL 上進一步封裝操作,簡化模型定義的同時,提升對不同計算引擎的支持能力.
1.1 面向AI的高級語言-to-SQL
傳統的機器學習算法大多基于Python、R 等命令式的編程語言,需要程序員定義好完整的執行邏輯.但是,用聲明性語言SQL 來簡化人工智能技術使用的同時,也面臨著一定的難度和挑戰:首先,目前人工智能和數據查詢有不同的執行引擎,我們需要設計一個統一的SQL 解析引擎來兼容不同的執行平臺,并提供跨計算引擎優化能力;其次,人工智能程序需要完整地給出算法邏輯,我們需要通過邏輯抽象簡化人工智能技術的使用方法.
最直接的方法是將SQL 翻譯成不同語言的腳本,再分發到不同平臺上執行.如BigQueryML[4]通過在SQL語法中直接增加“CREATMODEL”字段,用于定義常見的機器學習模型(如線性回歸、邏輯回歸等).然后,對于帶有“CREATE MODEL”字段的查詢,BigQuery 直接將類SQL 語句轉換為等價的TensorFlow 腳本執行.局限于傳統SQL 語法的表示能力(如張量操作通過嵌入Python 腳本實現),BigQueryML 目前能夠支持的機器學習算法有限(如線性回歸、二元邏輯回歸、多項式邏輯回歸等).
針對上述問題,SQLFlow(https://sql-machine-learning.github.io/)在 SQL 解析引擎(如 MySQL、Hive、SparkSQL 等)和人工智能的算法庫(如TensorFlow、Keras 等)之間建立一套靈活、開放的語言翻譯機制.如圖3所示.其一,它們主要使用SELECT 語句,通過擴展選項關鍵詞定義TensorFlow 估計器(“TRAINDNN”),使系統與SQL 引擎之間保持松耦合,避免增加如“CREATE MODEL”這樣的一級關鍵詞;其二,它們提供更加開放的模型定義方式,允許用戶設置估算器屬性(如Python 類的構造函數的參數;模型訓練、評估、預測的參數等),用戶可以選擇使用默認值,或者將超參數估計的研究成果集成到系統中,以自動優化參數的默認值;其三,SQLFlow 翻譯機制(SQL→SQLParser→extended SQL→code generator→execution engine)默認用從tf.estimator.estimator 派生出來的估計器估計不同張量流圖的開銷,從而自動生成較優的數據流圖.SQLFlow 并不限制底層機器學習工具包必須是張量流,而只需估算器提供訓練、評估和預測的方法.這種方式下,SQLFlow 就不需要關心它是否調用TensorFlow[5]或xgboost[6]框架,從而能夠更好地兼容不同的機器學習框架.

Fig.3 The definition of a DNN classifier in SQLFlow圖3 在SQLFlow 上定義一個DNNClassifier 分類器
1.2 面向AI的SQL的完備性
面向AI 的SQL 的完備性主要包括兩方面的內容:一方面,SQL 語言模型需要有獨立的描述AI 問題的能力,不需要用戶額外嵌入其他語言腳本;另一方面,支持全過程的AI 操作,即:基于SQL 語句就可以完成所有的數據和模型操作,不需要在底層將其轉換為其他語言后再執行.
MADlib 系統[7]將AI 算子嵌入到數據庫系統中,提供完備的SQL 翻譯機制.MADlib 的核心是將常用的機器學習庫兼容到數據庫系統(如PostgreSQL)中:一方面,用戶可以完全依靠SQL 語句調用機器學習算法,包括數據的獲取、連接、抽樣和模型的定義、訓練、調用等;另一方面,由于傳統數據庫一般不支持在矩陣上進行大量的線性變化操作,因此,MADlib 有針對性地提供面向AI 的數據操作和訓練模式.
? 面向AI 的數據操作:在SQL 級別上,MADlib 智能地將矩陣劃分成塊,將這些塊加載到各個節點的內存空間.一旦進行了分區,就可以使用SQL 來協調這些塊在一臺或多臺機器上的內存進出.傳統的查詢優化器或數據庫設計工具不具有智能劃分矩陣模式,因此,MADlib 通過在SQL 語法中增加數據劃分功能,使數據庫引擎可以精心安排分區的數據移動和各階段的中間結果.此外,MADlib 提供新的用戶自定義聚合函數.由于數據庫系統主要使用聚合函數處理并行的流式數據,基于聚合函數定義的機器學習算法可以更高效地被執行;
? 訓練模式:為了更好地支持不同機器學習算法的訓練模式,MADlib 通過迭代訓練對模型進行優化,引入如梯度下降、馬爾可夫鏈、蒙特卡洛等優化算法:(1)通過虛擬表計算迭代次數,聲明一個具有n行的虛擬表(例如通過PostgreSQL 的generate_series_table函數),并將其與表示單個迭代的視圖連接起來;(2)遞歸查詢,使用SQL 的遞歸特性來執行任意停止條件下的迭代計算;(3)驅動函數,上述方法不具備通用性和可移植性,因此在MADlib 中,我們通過在Python 中編寫驅動程序UDF 來實現更復雜的迭代方法,從而控制迭代和迭代傳遞狀態.類似工作還有SAPPAL[8]、MLlib[9]、MLog[10]等.
1.3 面向AI的SQL智能推薦
對于SQL 語言本身,其核心“SELECT…FROM…WHERE…GROUP BY…”是一種非常強大的工具,可以支持跨一個或多個處理器和磁盤協調數據的批量處理.但是,使用SQL 仍然有一定的學習和使用成本,而且對于普通用戶來說仍然不夠直觀.所以,另一類研究進一步將SQL 封裝成動態圖、電子表格等,利用可視化技術提供更加智能的推薦服務.
? AI 工作流的可視化推薦
對于人工智能來說,數據工作流的主要任務是讓機器對已有數據進行發現、清洗、融合和分析,從而使機器能夠對新的數據進行合理的判斷.數據工作流設計是一個復雜的過程,涉及諸多數據工程技術,即使使用SQL語句,也需要很高的專業經驗和時間投入.因此,通過將數據工作流的設計過程可視化,我們可以進一步簡化AI的使用.代表性工作如BigQueryML.首先,數據融合控制中心允許用戶將數據工作流拖放到控制中心統一管理,無需編碼就可以基于可視化界面瀏覽和管理所有數據集和數據工作流.在 Telus Digital 的研發架構中,BigQueryML 提供:(1)預置的連接器,用于同步不同的數據源(如用戶網上行為、用戶交易數據、經濟社會環境數據等);(2)數據轉換集合(如數據收集技術、數據轉換技術等),作為生成數據工作流的基礎工具庫,方便用戶快速地獲取結果.此外,通過提供直觀的可視界面和工作流抽象,相比于SQL 語言,進一步降低了數據融合的門檻.這種增強的可訪問性允許數據分析師和科學家“自助服務”,而無需云或軟件工程專家的幫助.其次,在數據分析方面,面向谷歌公司云上EB 級的智能數據分析.每天,谷歌的用戶都會上傳PB 級的數據到BigQuery 上,因此,BigQuery 需要在EB 規模的、無服務器模式的數據倉庫上提供智能分析服務.BigQueryML 采用一種簡單的方法對海量數據進行機器學習分析,分為Cloud DataflowSQL 和DataflowFlexRS 兩部分:CloudDataflowSQL 用于啟動數據流水線和調度作業,還可以自動檢測批處理或流數據處理的需要.CloudDataflowSQL 使用的SQL 語法與BigQuery 中使用的相同,這允許數據分析師使用BigQuery UI 中的DataflowSQL,將云發布/子流與數據基礎結構中的文件或表連接起來,然后直接實時查詢合并的數據.這意味著用戶可以生成實時查詢分析并創建“儀表板”以可視化結果.DataflowFlexRS 則通過靈活的調度,批處理要執行的作業.它可以根據用戶優先級、需求程度動態地調度任務,如若用戶正在處理非時間敏感的數據,它的執行優先級會被自動后調,但是能夠從可搶占的資源定價中獲益.此外,FlexRS 考慮了成本效益,允許隔夜執行作業.
? 交互式的SQL 生成技術
大量的業務用戶將電子表格作為數據分析不可或缺的工具,因此,BigQueryML 提供一種虛擬電子表格技術Connected Sheets:一方面,它結合了電子表格界面的簡單性和機器學習算法的擬合能力;另一方面,Connected Sheets 沒有行限制,可以使用來自BigQuery 的完整數據集.無論是數百萬還是數十億行的數據,都能以一種虛擬電子表格的方式呈現給用戶.用戶在表格上進行的數據操作都會被自動地轉化成SQL 語句發送到數據庫執行,并基于分布式處理技術優化查詢效率.它的優勢包括:
1)方便使用:用常規工作表功能(包括公式、數據透視表和圖表)即可進行分析,并將結果數據可視化為工作表呈現給用戶.如亞洲航空公司(AirAsia)就用這套方法實現數據平民化,即:分析師和業務用戶能夠直接創建圖表,并利用它們在海量數據集上的現有技能(如審計、數據統計等方法)訪問BigQuery 中的基礎數據,同時還可以實現最細粒度數據(列/行級)的訪問,而完全無需調用SQL 語句;
2)安全:基于可信數據管道,允許用戶與組織中的任何人安全地共享電子表格上的數據,進行實時的多人在線分析.
2 AI 算法優化引擎
在傳統的數據管理系統中,優化引擎根據查詢樹生成實際使用的執行計劃.隨著聲明性AI 語言模型的快速發展,同一個AI 問題(如圖片分類、人臉識別等)也可能會有多個算法、參數的組合供選擇,而且不同組合對執行性能和表現可能有很大的影響.因此,本節中,我們調研數據庫優化引擎中的技術,分別從面向AI 的優化引擎、AI 算子的代價估計、AI 算法的自動生成、AI 模型的版本管理這4 個方面進行綜述和分析.
2.1 面向AI的優化引擎
面向AI 的優化引擎主要是指根據查詢樹生成統一的執行計劃,對于異構的計算平臺,根據計劃中的算子類型下發到指定的計算平臺上分別執行;否則,由數據庫計算引擎直接執行.下面我們分別綜述這兩類技術.
? 異構的計算平臺
前面提到的機器學習工具SQLFlow 的代碼生成器(CodeGenerator)負責執行計劃的生成和轉發.首先,代碼生成器根據解析結果(SQL 關鍵字匹配)判斷該SQL 是AI 操作還是數據庫查詢,如果是AI 操作,代碼生成器先通過ODBC 驅動程序將查詢中的標準SELECT 部分傳遞給MySQL,獲取需要的數據;然后,它進入一個循環,反復從SELECT 語句的運行中讀取輸出結果.如果是訓練階段,則用于優化模型,否則用經過訓練的模型進行預測.此外,在每個訓練階段,SQLFlow 都要依賴TensorFlow 算法包來更新TRAIN 子句中指定模型的參數.如果是數據庫查詢,則直接下發到優化器繼續執行.SQLFlow 的核心優勢包括:(1)基于SQL 降低機器學習算法的使用門檻;(2)一條擴展的SQLFlowSQL 就可以包含數據查詢和機器學習操作,并行執行可以提高處理效率.然而,其缺點是:(1)數據傳輸開銷沒有得到改善,數據和模型計算仍然集成在不同的平臺上;(2)半自動化的問題聲明,仍然需要用戶定義大部分的執行操作,代碼生成器對于執行算法的優化空間較小.
? 統一的數據庫計算引擎
MADlib 根據機器學習算法流程進行有針對性的計劃優化.以k-means 的一個實現為例[11].MADlib 主要使用驅動函數,迭代地調用用戶定義的聚合函數(user defined aggregate,簡稱UDA)執行操作.UDA 中有兩個狀態:迭代間狀態代表UDA 最終函數的輸出,迭代內狀態代表由UDA 的轉換和合并函數維護的狀態.在聚合期間,轉換狀態包含兩個迭代內狀態,但只修改迭代內狀態.
1)第1 步,它將k個分類中心存儲在兩種狀態中,并將訓練點到各個分類中心的賦值視為默認給出的;
2)第2 步,在遷移函數中,它首先計算出當前點與迭代狀態開始運算時最接近的分類中心.為了簡化運算,首先,它需要計算上一次迭代中最接近的分類中心,然后計算當前迭代中最接近的中心.如果它顯式地存儲最近的點,則可以避免最近質心計算的一半.然后,再迭代內部狀態更新分類中心.只有作為聚合的最后一步,迭代內狀態才成為新的迭代間狀態;
3)第3 步,將點存儲在一個關系表中,該表包含該點的坐標屬性和當前最近的分類中心.迭代狀態將每次所有的分類中心的位置存儲在一個矩陣中.MADlib 提供了一個UDF:close_column(a,b),表示在a矩陣中距離向量b最近的向量,用SQL 語句表示為
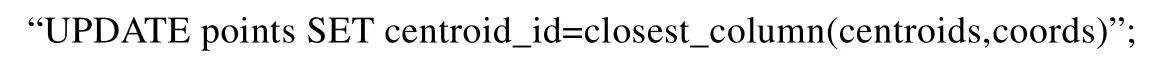
4)第4 步,數據庫會逐個處理查詢(并且不執行跨語句優化),因此,每k均值迭代需要對數據進行兩次傳遞,直到確定一個樣本的分類中心.
我們可以看到,MADlib 完全將人工智能算法的執行邏輯內嵌到數據庫中,提供運行時優化.此外,計算和數據傳遞都在同一個數據庫系統中進行,也進一步提升了執行效率.但缺點是邏輯優化比較復雜,不方便遷移到新的數據庫系統上.
2.2 AI算子的代價估計
AI 算法中存在大量不同類型的算子,如標量、向量、大規模張量等操作.面對聲明性的AI 問題,如果有多個實際的AI 算法可以解決,那么評估這些AI 算法的執行代價對于提高解決問題的效率就有很大的意義.目前,這方面的工作還比較少.如在Kumar 等人提出的基于線性回歸模型優化數據源的連接操作[12]中,他們主要研究用于連接操作的混合哈希算法,快速估計所有方法的I/O 和CPU 成本.這種成本估計的思想很簡單,如當關系表R的散列表可以容納在主內存中時,它分別估計基于線性回歸模型的索引連接、傳統排序合并算法的執行成本.
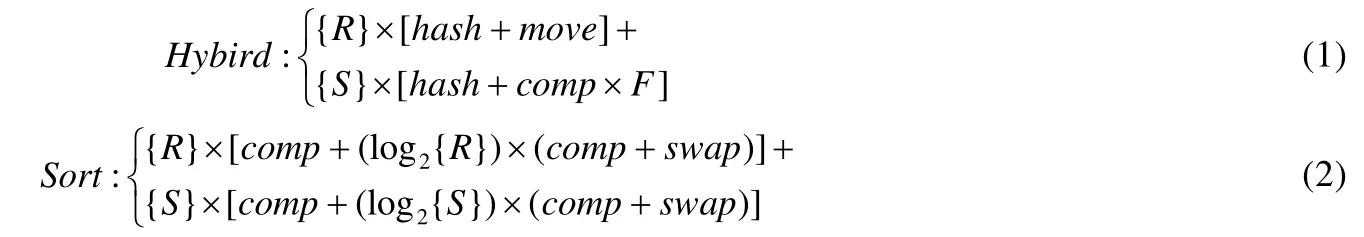
其中,R和S是要進行連接操作的兩張關系表,hash指的是在內存中給一個屬性建立索引的時間,move指的是將一行數據拉入內存的時間,comp指的是在內存里比對兩列屬性的時間,swap是將以行數據換出內存的時間,F是增量系數.因為當R的散列表可以容納在實際內存中時沒有I/O 成本,所以很明顯,混合哈希將優于排序合并算法.作進一步擴展后可知,由于任何AI 操作主要包括數據搜索、運算等基本操作,我們可以先用計算開銷(CPU成本)和數據移動開銷(I/O 成本)估計基本操作的代價,再綜合起來對不同的AI 操作進行評估.但是,這種基于經驗公式的方式局限性很大,未來需要有普適性更強的模型來代替這套方法.
2.3 AI算法的自動生成
基于需求自定義AI 算法是一件麻煩的事情.通過向用戶暴露機器學習模型的數學結構,TensorFlow、Theano 和Caffe 等機器學習框架可以構造出各種靈活且具有表現力的機器學習模型.然而,一方面,用戶需要掌握大量的數學、算法方面的知識才能進行程序書寫;另一方面,由于沒有聲明性的數據管理層,用戶需要處理這些系統中的數據加載、移動和批處理等繁瑣且往往容易出錯的任務.因此,人們推出了Keras、PyTorch 等更高層的機器學習庫,用戶只需要聲明性地給出數據之間的邏輯關系,而不再需要具體解釋為了得到最終模型需要做哪些數據操作,如Json 格式轉換、張量計算操作等.然而,這只解決了前一個問題.他們仍然不能為像numpy數組這些數據提供智能管理,用戶仍然需要處理低層編程細節,例如需要考慮這些數組是否適合內存,需要自定義經典數據庫功能,像跨進程重用計算、基于時間戳的數據快照管理等等.此外,Keras 不能集成到承載大多數企業數據的標準關系數據庫生態系統中.于是,我們綜述了數據管理技術在AI 算法自動選擇和組裝中的應用.
首先,基于數據庫的關系代數自動生成人工智能算法.在Mlog[10]中,他們用數據庫系統管理所有的數據移動、數據一致性、數據持久化和機器學習相關的優化方法(如SGD、Adam 等).
1)其一,他們基于傳統數據庫(如SciDB)構建標準數據模型,避免重復數據庫系統在數據管理上進行的工作,包括構造relational table schema、建立索引、外鍵等.因為傳統數據庫缺少針對大規模張量數據的索引結構,Zhang 等人[13]提出了一種新型的數據結構(LinearArrayB-tree,簡稱LAB-tree).他們主要利用線性函數,針對不同維度之間的關系建立B-tree,然后將B-tree 映射到一維向量上,再對這個一維向量進行索引,從而在索引中同時體現了數據結構和數據特征;
2)其二,Mlog 通過擴展查詢語法支持用戶利用傳統關系型視圖和關系型查詢來聲明機器學習模型.首先,他們提供一種基于張量視圖的新型查詢語言,它具有與現有關系型數據模型和查詢語言兼容的形式語義.
(1)數據模型:Mlog 的數據模型是基于張量的,所有操作都是張量上線性代數的子集.在Mlog 中,張量與關系模型密切相關.實際上,從邏輯上講,張量被定義為一種特殊的關系類型.設t為維數dim(T)的張量,每個維數j的索引范圍為{1,…,dom(T,j)}.邏輯上,每個張量T對應一個關系R;
(2)關系代數:我們在張量上定義了一個簡單的關系代數,并就關系R定義了它的語義,這使得我們能夠將張量上的操作緊密集成到關系數據庫中,并生成統一的語義.這個關系代數與支持線性代數操作的擴展的數據立方體非常相似.比如:對于切片算子,用于選擇輸入張量的子集,包括不同的維度區域等;對于線性代數算子,它支持一系列線性代數運算符,包括矩陣乘法和卷積.這些操作符都有op(T1,T2)的形式等.這套關系代數將SQL 轉換成Mlog 程序,然后他們使用文本靜態分析技術自動地將Mlog 程序編譯成本機TensorFlow 程序,生成實際的執行邏輯.
這類工作還有DataRobot(https://www.datarobot.com/)、Zylotech(https://www.zylotech.com/)和谷歌公司的AutoML 等等,他們不僅能夠基于用戶需求自動生成或重用機器學習模型,而且能夠自動匹配合適的優化方法.
其次,基于內置的AI 算子對人工智能算法進行選擇.LogicBlox 提供了類SQL 語言LogiQL[14],基于對傳統SQL 語句封裝更好的支持機器學習等數據分析技術.下面我們分別以規定性分析和預測分析為例,分析LogicBlox 如何利用LogiQL 生成機器學習算法.
? 規范性分析(prescriptive analysis)
通過添加一個語言特性,可以將LogiQL 擴展支持數學優化和規范性分析.其思想是,謂詞R[x1,…,xn]=y可以聲明為自由二階變量,這意味著系統負責用元組填充它,從而滿足完整性約束.此外,可以將R[*]=y形式的派生謂詞聲明為最小化或最大化的目標函數.假設我們希望自動計算股票金額,以實現利潤最大化,那么將以下內容添加到程序中就足夠了:“lang:solve:variable(‘Stock);lang:solve:max(‘totalProfit).”.其中,第1 句是一個二階存在量詞的簡寫,它指出股票的謂詞Stock 應該被當作我們正在解的一個自由二階變量;而第2 句則指出謂詞總利潤totalProfit 是一個需要最大化的目標函數(服從完整性約束).在算法優化引擎中,程序被轉換成線性規劃(LP)問題,并傳遞給適當的解算器[15].LogicBlox 通過自動合成另一個logiQL 程序(將變量謂詞上的約束轉換為可由求解器使用的表示),以類似于馬爾可夫鏈[16,17]的方式將問題實例中的量詞排除.此外,它利用LogicBlox 系統中的所有查詢評估機制(例如查詢優化、查詢并行化等),提高了模型落地的可擴展性.系統調用適當的解算器,并用結果填充存在量化謂詞的值(將未知數值轉換為已知數值).此外,邏輯增量地保持對解算器的輸入,使系統可以增量地(重新)解決受輸入更改影響的問題部分.如果更改示例應用程序,使股票謂詞現在定義為從產品到整數的映射,則LogicBlox 將檢測更改并重新編寫問題,以便調用不同的解算器(支持混合整數編程(MIP)).
? 預測分析(predictive analysis)
預測分析主要是指從已有數據中對未來事件進行預測.LogicBlox 中的預測分析最初是通過一組內置的機器學習算法來支持的,這是通過特殊的“預測型”P2P 規則實現的.該規則有兩種模式:學習模式(在學習模型的地方)和評估模式(在應用模型進行預測的地方).假設希望預測分公司產品的月銷售額,我們有一個謂詞sales[sku,store,wk]=amount以及一個謂詞feature[sku,store,featurename]=value,它與每個sku,store和featurename關聯一個對應的feature值.學習規則(如SM[sku,store]=m←predict〈〈m=logist(v|f)〉〉Sales[sku,store,wk]=v,Feature[sku,store,n]=f)為每個sku及其分支學習一個邏輯回歸模型,并將生成的模型對象(它是模型表示的句柄)存儲在謂詞sm[sku,store]=model中.
此外,面對快速變化的人工智能技術,LogicBlox 還支持實時編程.在這種情況下,傳統的編輯-編譯-運行周期被放棄,取而代之的是對程序運行時行為進行實時反饋,提供更具交互性的用戶體驗[18].例如,在零售計劃應用程序中,我們允許用戶動態定義和更改模式和公式.這些更改會觸發對數據庫服務器中應用程序代碼的更新,而挑戰是需要快速地更新用戶視圖以同步這些更改.
2.4 AI模型的版本管理技術
構建機器學習模型是一個迭代的過程(時間序列).數據分析師在達到既定的表現標準之前,可能要設計大量的模型進行嘗試(如線下覆蓋面積、準確度等),而這些模型和相關數據在構建新的模型方面有很大的參考價值.然而,當前模型的版本管理依賴于用戶手動組織,浪費了人力和學習資源.因此,我們對基于數據庫的AI 模型的版本管理技術進行了調研.
Vartak 等人提出了一套管理機器學習模型的端到端系統ModelDB[19].建立機器學習模型是一個迭代的過程.一個數據科學家在達到某些驗收標準(例如AUC 截止曲線)之前需要建立數十到數百個模型.然而,當前的模型構建方式是比較隨意的,數據科學家缺少科學的工具來管理隨時間構建的模型.這導致出現了如下3 個問題.
1)想要復現歷史版本的模型或結果非常耗時,有時難以實現;
2)要求數據科學家“記住”模型先前版本的結果和參數.例如,數據科學家必須記住已測試的參數或特征的組合及其結果,以便得出見解并通知下一個實驗;
3)數據科學家很難回答有關不同版本的具體差別.例如,數據科學家經常在某一點上發現代碼或數據中的差異,然后必須重新運行代碼或數據下游的所有分析.然而,在缺乏模型版本控制的情況下,識別實驗非常困難.
為了解決以上問題,ModelDB 基于數據庫系統,在訓練模型時接收模型和相關的元數據,以結構化的格式存儲模型數據,并自動跟蹤本機環境中構建的機器學習模型,智能地為其編制索引,允許通過SQL 和可視化界面靈活地瀏覽模型.這樣,ModelDB 可以幫助數據科學家高效地進行歷史版本管理,提高模型構建和重現的效率.
另一種方法則是基于鏈式結構進行版本控制.SimSQL[17]是一個基于SQL 語法規范的數據庫管理系統,它提供大規模分布式的模擬數據庫值(整個數據庫數據的抽象)的馬爾可夫鏈,鏈的值在任何時間節點上都包含整個數據庫的內容.SimSQL 采用了許多最初在蒙特卡洛數據庫系統(MCDB)[20]中提出的想法,允許用戶定義除普通數據庫表之外的隨機數據庫表.在隨機表中,有些條目是具有相關概率分布的隨機變量(不一定以閉合形式已知),而其他條目則是普通的、確定性的數據值.從概念上講,當發出包含隨機表的SQL 查詢時,SimSQL 使用偽隨機數生成技術來實例化每個隨機數據值.查詢可以在生成的數據庫實例上運行.這一過程以蒙特卡洛方式重復多次,以獲得查詢結果的經驗分布.SimSQL 通過使用“元組包”方法共享公共成本,同時以高效的方式實例化和處理許多可能的數據庫實例.
3 AI 異構執行引擎
上一節中,我們主要從邏輯層面介紹了數據庫優化技術在AI 領域的應用.而在物理層面,為了原生支持AI計算,我們仍然面臨著一些挑戰.傳統數據庫執行引擎用于實際地對指定數據進行處理,目前已經可以實現行級并行處理.但是傳統執行引擎支持的算子運算比較單一,如基本的Aggregate、HashJoin 等數據庫算子.所以,為了用數據庫執行引擎原生地支持AI 操作,我們分別從算子實現(異構的AI 計算引擎)、并行優化(分布式加速架構)、執行優化(AI 執行優化技術)、智能數據分析這4 個方面綜述執行引擎對AI 計算的支持.
3.1 異構AI計算引擎
本節中,我們分別介紹如何基于數據管理技術更好地支持人工智能算法中異構的操作算子.AI 算子主要有兩類特點:(1)種類多樣,包括標量、向量、大規模張量等不同操作;(2)計算密集型,大規模的張量計算對芯片(算力)和存儲(數據)的性能要求很高.針對以上特點,我們分別從調研數據管理技術在硬件優化、優化函數優化、執行邏輯優化這3 個方面展開工作.
首先,一些數據庫系統集成了異構的計算框架和大規模內存計算能力,可以有效提高處理人工智能算法的能力.例如,ColumnML[21]系統可以在執行 ML 任務之前方便地對復雜模式進行預處理和非規范化:首先,ColumnML 集成專門的硬件加速器,用FPGA、GPU 等新硬件對常用子運算符(如哈希、分區、排序、高級分析等)進行專門化處理,從而提高DBMS 中的處理效率;其次,在大多數這類系統中,將數據移動到加速器需要高效的I/O,否則性能優勢將不復存在,所以ColumnML 基于內存型列式存儲,面向列的處理使得從內存中移動數據變得更加容易.同時,仍然能夠利用硬件中的可用并行性,特別是在壓縮列時,可以提高I/O 效率.最后,這種列式存儲的方式不完全適用于機器學習算法,特別像隨機梯度下降(SGD)等優化函數,它們經常同時訪問一個元組的所有屬性,逐行處理元組,存在大量的“行操作”.但是它們仍然可以在列存儲上執行SGD:由于DRAM 的行緩沖區位置的原因[22],為了使從內存中的遠程地址讀取更加有效,必須批量讀取:從一列讀取多個緩存線,將它們存儲在緩存中,再從下一列讀取.這實際上是一種動態的列存儲到行存儲的轉換,是不利的,所以它需要與數據集中的功能數量成比例地緩存空間和較大的批處理大小,以便盡可能地按照順序讀取[23,24].
為了解決ColumnML 等列式存儲系統中行式計算低效的問題,Shwartz 等人[25]引入了一種新的優化函數——隨機坐標下降算法(stochastic coordinate descent,簡稱SCD),并在運行時提供一個邊界以進行聚合.SCD 的核心思想是:保持一個包含模型與樣本之間內積結果的向量,然后可以始終將所做的更改應用于模型的一個坐標,也可以應用于該內積向量,這將在所有樣本和對應的優化梯度之間保持最新的內部積.該模型要求對所有樣本只訪問一個坐標,這相當于按列訪問模式.我們通過在每次迭代中隨機地(不替換)選擇一個特性來執行SCD.模型x初始化為0,因此內積向量z也從0 開始.一個epoch 對應于處理整個數據集:完全訪問每一列,以計算Lasso[26]邏輯回歸的部分漸變.然后,利用局部梯度更新模型的相應坐標.最后,進行內積向量更新,以使z中的內積保持最新,通過對損失函數的估計,對優化問題進行多個階段的求解,直至收斂.此外,他們還使用了SCD 的分區版本(partitioned version of SCD),靈感來自于Jaggi 等人引入的Cocoa 算法[27].Cocoa 的目標是:在執行分布式雙坐標提升時,降低通信頻率.PSCD 的主要目標是減少中間狀態的保留量.由于緩存位置的存在,可以降低內存訪問的復雜性.
此外,數據管理技術可以提供細粒度的數據操作優化.前面我們介紹了MADlib 是如何在邏輯層面上實現AI 算法自動化生成的,而在物理層面上,
? 一方面,MADlib 的數據庫引擎可以利用線性代數例程來處理其獲取的核心數據片段.為此,它需要快速地調用經過優化的線性代數方法.除了執行塊的粗粒度管理之外,數據庫引擎還必須有效地調用執行算術計算的單個節點上的代碼.對于在行級操作的UDF(可能每行多次),標準方法是在C 或C++中實現之.當進行密集矩陣運算時,這些函數會對開放源代碼庫進行本地調用,如Lapack[27]或Eigen[28];
? 另一方面,稀疏矩陣在標準數學庫中沒有很好地得到處理,需要進行更多的定制,以便在磁盤和內存中有效地加以表示.他們選擇用C 語言為MADlib 編寫自己的稀疏矩陣庫,利用C 語言中的基本算術循環進行編碼.
3.2 分布式AI加速架構
傳統單機上的AI 優化方法已經不能滿足大規模機器學習的需求,分布式計算引擎可以從兩個方面進一步優化機器學習的執行效率:首先,通過水平擴展,我們可以將機器學習的訓練任務下發到多個物理節點上,利用物理并行方式加速AI 算法的執行效率;其次,由于很多機器學習的優化算法需要頻繁讀寫數據,如批量隨機下降算法的每輪訓練需要計算所有樣本的損失值,我們通過數據壓縮,將盡可能多的數據放到內存中進行計算,從而進一步提升整體執行效率.下面我們分別從分布式任務并行和分布式內存計算兩個方面綜述這類技術.
? 分布式并行計算
單機數據庫的性能面臨著瓶頸,越來越多的數據庫系統支持分布式架構,如MPP、NUMA,以解決臨界資源帶來的瓶頸問題,為AI 技術提供大規模的并行數據處理功能.同時,很多研究考慮如何利用分布式數據庫系統加速機器學習算法,如Kinetica[29]基于MPP 架構支持大規模的機器學習訓練.首先,它在分布式節點上進行大規模的統計和分析查詢;其次,在這個規模下,機器學習模型可以同時基于原始數據的多個子集進行訓練,對每個子集,模型學習到一種狀態之后就將這部分數據丟棄在數據倉庫中(節省空間);最后,基于自定義函數(CDF),用戶可以定義模型的訓練方式.另一種方法是重新定義分布式機器學習庫,如MLlib 基于Spark 的分布式執行框架執行機器學習算法.首先,它提供一套開源的分布式機器學習庫,算法包括樸素貝葉斯、決策樹、k-means 等[30].該庫還提供了許多用于凸優化、分布式線性代數、統計分析和特征提取的低級原語和基本實用程序,并支持各種I/O 格式,包括對libsvm 格式的本機支持、通過spark-SQL 進行數據集成用于模型導出的MLlib 的內部格式.在最底層,Spark Core 提供了一個通用的執行引擎,有超過80 個算子來轉換數據,例如進行數據清理和特征化.相似工作還有RHEEM[31],從更細粒度層次支持分布式的執行算子.為了實現無縫的分布式執行,RHEEM 的邏輯層算子(UDF 中)經過優化(任務并行化、部署細節)轉換成實際執行算子,再分發到各個節點上執行.它將數據單位細化到行/列級,允許我們在更高的并行度上設計操作并獲得更好的表現.
? 分布式內存計算
分布式內存計算是將盡可能多的數據經過壓縮存儲在主內存中,通過避免頻繁的I/O 操作加速AI 的計算效率.在分析和商業智能數據庫(business intelligent DB)中,廣泛地采用這種模式來加速數據分析的效率.如MLWeaving 進一步提供了一種緊湊的內存表示,它通過將具有數據拆分到比特級別,對具有指定值的不同的比特位在大規模內存上獨立存儲,從而方便且靈活地進行并行數據處理.然后,數據分析平臺Kx 通過結合基于內存的時間序列數據庫kdb+,提高數據處理效率的同時減少資源開銷.首先,Kx 具有管理、吸收、存儲和分析大型數據集的能力,是深度神經網絡的理想執行引擎;其次,基于內存中的流分析功能,適合快速進行數據集的采樣、聚合和連接操作.
3.3 AI執行優化技術
在當今數據中心里,機器學習已經成為一種重要負載,如廣告定位、內容推薦等.如上一節所述,目前已存在很多支持人工智能技術的平臺.但是,傳統系統多把AI 技術當成一種數據服務型負載的擴展,錯過了重要的表現優化的機會.比如,研究型系統Clipper、商業系統AmazonSagemaker 和微軟的AzureML 等系統,將模型當成黑盒使用,或只提供普通的系統優化手段,如輸入緩存、批量處理等等.像Pretzel 則只能為傳統編譯器提供端到端的優化方法.然而,提高機器學習模型的訓練效率對于AI 技術的落地和運行時優化至關重要.這一部分包括模型的訓練、優化、管理等諸多方面,有很大的性能提升空間.現有數據庫技術主要從3 個方面來加快機器學習的訓練效率:(1)基于數據庫內核執行AI 操作,提高執行效率;(2)基于AI 芯片優化AI 算子的執行,提高計算效率;(3)基于新型數據庫系統支持AI 技術,對整個執行流程進行優化.
? GPU+數據庫技術
GPU 數據庫是最早興起的一批AI 數據庫系統,相關工作包括Kinetica[29]、MapD[32]、PG-Storm(http://heterodb.github.io/pg-strom/)、Blazegraph(https://www.blazegraph.com/)等等.Kinetica 是一款基于GPU 加速執行引擎的數據庫系統.傳統CPU 的每個核心具有取指和調度單元構成的完整前端,因而其核心是多指令流多數據流(multiple instruction multiple data,簡稱MIMD),每個CPU 核心可以在同一時刻執行自己的指令,與其他核心完全沒有關系.但是這種設計增加了芯片的面積,限制了單塊芯片集成的核心數量.GPU 的每個流多處理器才能被看作類似于CPU 的單個核心,每個流多處理器以單指令流多線程方式工作,只能執行相同的程序.盡管GPU運行頻率低于CPU,但是由于其流處理器數目遠遠多于CPU 的核心數,因此我們稱其為“眾核”,其單精度浮點處理能力達到了同期CPU 的10 倍之多.因此,集成了上千個處理核(目前最多能達到6 000 核并行)的GPU 芯片可以提高大規模并行計算的效率.為了充分發揮GPU 的優勢,Kinetica 支持用戶定義函數(user defined function,簡稱UDF)框架,允許自定義算法和代碼直接在數據庫中的數據上運行.UDF 使得在數據庫中運行自定義計算和數據處理成為可能.這提供了一種高度靈活的方法,可以通過網格計算在規模上執行復雜的高級分析,將網絡中每臺計算機的空閑處理能力連接起來,以承擔一個被劃分為多個任務的作業.數據庫業務和AI 工作負載可以在同一個GPU 加速數據庫平臺上一起運行.用戶定義的函數可以用C++、Java 或Python 編寫.Kinetica 還提供捆綁式TensorFlow,用于機器學習和深度學習用例.而微軟的Azure 還提供基于云架構的機器學習訓練服務,用戶可以根據不同的需求快速訂制GPU 集群,批量執行AI 作業.
? FPGA+數據庫技術
隨著微軟公司利用FPGA 芯片提高模型訓練的靈活性和效率,FPGA 數據庫也逐漸興起[33].如MLWeaving提供一套基于數據庫(如DoppioDB[33,34])和FPGA 的硬件加速技術[35],主要用于提高低精度輸入數據的處理效率.FPGA 可以簡單地被認為是包含低級基礎芯片的電路板,例如AND 和OR 門,通常使用硬件描述語言(HDL)指定FPGA 配置,可以配置成與特定任務或應用程序的需求相匹配的方式.此外,FPGA 能夠最大限度地提高并行性和資源利用效率,已被Intel 用于加快深度學習網絡的實施.MLWeaving 支持FPGA 主要是因為其在探索可能的算法和設計方面提供了更高的通用性,面對快速演進的機器學習算法具有很大的意義.MLWeaving 主要提供兩個方面的優化:(1)支持在任何精度級別上高效地檢索輸入數據的內存布局;(2)基于FPGA 的設計,提供硬件加速,以加速SGD 優化算法.而不在意使用的精度如何.SGD 是一次一個樣本地進行評估,即在計算梯度之前讀取樣本的所有特征.在完全精確的情況下,讀取與數據點對應的行可以訪問該樣本的所有特性.而MLWeaving在位級別上垂直地劃分每個數據點(表中的一行),以便連續存儲數據點所有特性的第1 位,然后存儲第2 位等.這提供了兩個好處:首先,讀取值所需的內存訪問數與所用的精度成正比,低精度會導致更少的內存訪問;第二,該格式允許以位流的形式將數據序列化到硬件加速器中,從而提高內存帶寬利用率.而 Swarm 64 系統(https://www.swarm64.com)還提供CPU+FPGA 的異構芯片支持服務,利用CPU 陣列處理傳統的關系型事務,利用FPGA 模型訓練機器學習模型,更好地提高事務處理的效率和資源的利用率.
? 端到端的執行優化系統
傳統的機器學習使用方式是一種流水線式的:將輸入數據處理成數值型的向量,然后在特征向量上執行ML 模型.計算特征的代價比較高,是一個重要的瓶頸.
一方面,一些工作主要從最終訓練目的的角度預估執行代價,自動生成ML 執行流水線,如Kraft 等人提出了一套為人工智能模型提供端到端優化的系統Willump[36].機器學習不同于傳統負載:首先,很多情況下,系統不必計算所有的輸入數據,可以選擇更加“廉價”的模型來預估原有模型,如不計算所有的輸入特征,從而加速訓練;其次,不同于傳統SQL 查詢封裝機制,機器學習算法大多直接被高層應用所調用.針對以上特點,
1)Willump 使用一個完整的程序數據流分析算法和一個成本模型來識別重要但計算成本低的特性,從而有效和準確地加速模型的執行.利用這些特性,Willump 自動訓練一個近似模型,該模型可以識別和分類“簡單”的數據輸入.例如,毒性評論分類的近似模型可能會將帶有詛咒詞的評論分類為毒性,并將其他評論級聯到更強大的模型中;
2)Willump 提供查詢感知優化.單個數據輸入的并行計算是困難的,因為ML 流水線可能不會自然地并行化,并且通常采用缺乏低延遲多線程的語言編寫.Willump 使用一種數據流分析算法來解決這些挑戰,該算法識別ML 流水線的計算獨立組件,并編譯為低延遲多線程框架,將延遲提高4 倍.
此外,Willump 將這兩方面的優化方法與標準編譯器優化方法和傳統計算圖構建方法相結合,提供自動的ML 流水線快速推理代碼的特征緩存方案,即迭代式地增加參與計算的特征,直到表現足夠滿意.
另一方面,一些工作設計集成式的執行管理系統,幫助執行引擎更好地完成訓練任務.例如,Amazon SageMaker(https://aws.amazon.com/cn/sagemaker/)允許用戶方便地創建、訓練、部署任意規模的機器學習模型,優勢包括:
1)避免基礎設施管理.SageMaker 運行用戶定制訓練集群(EC2 類型,節點數目),由系統自動進行配置,并在訓練任務結束時自動終止進程;
2)降低訓練開銷.EC2 Spot Instance 利用全管理Spot 訓練技術(managed spot training),包括內置AI 算法、自定義AI 模型、模型調優等,進一步降低近90%的訓練開銷;
3)快速異常恢復.SageMaker 利用Checkpoint 機制,保證程序在異常終止時迅速地從最近鏡像中恢復.
3.4 智能數據分析技術
數據分析技術具有非常廣泛的領域,包括數據處理、分析、預測等諸多方面[37].傳統的數據分析技術存在很大的局限性,如算法適應性差、局限性大等.人工智能為數據分析技術提供了新的算法和思路,在數據分析的優化中做出了很大的貢獻[38,39].然而,基于AI 的數據分析技術仍然有很大的優化空間[40].根據前3 節的工作,我們進一步調研了基于智能數據庫的數據分析技術.
? 可擴展的數據分析框架
預測性分析日益成為企業預測需求的重要方式,如估計客戶需求或安排日常維護.數據倉庫通常為企業存儲最有價值的數據集,但這些分析能力傳統上是機器學習專家的領域,多是大多數數據分析師或業務用戶無法共享的技能.BigQuery ML[41]推出具有擴展的機器學習模型,使數據分析師能夠使用熟悉的 SQL 直接在BigQuery 內部的大型數據集上構建和部署機器學習模型.此外,BigQuery 集成了經典的機器學習模板,如k-均值聚類和矩陣分解,以進行客戶身份的細分并給出產品建議.客戶也可以通過BigQueryML 建立和直接導入基于TensorFlow 框架的深度神經網絡模型.Geotab 利用100 多萬輛聯網車輛的匯總數據提供新的智能城市解決方案.我們能夠使用BigQuery 的地理信息系統來了解交通流模式,而BigQuery ML 幫助我們深入了解根據惡劣天氣預測城市危險駕駛區域.另外,還將機器學習應用于表格數據而不必編寫單行代碼.并非所有能夠從機器學習分析中獲益的人都是SQL 專家.為了使得存儲于BigQuery 和云存儲中的結構化數據上更容易應用ML,我們提供AutoML 表,以便數據科學家、分析師和開發人員等任何用戶只需點擊幾下,就可以在結構化數據上自動構建和部署最先進的機器學習模型,從而將所需總的時間從幾周縮短到幾天,而無需編寫一行代碼.
? 智能的近似查詢
對于很多用戶來說,非精確但快速響應的數據庫查詢是傳統查詢的替代方法.形式概念分析(FCA)的使用,使人們能夠對經典數據庫管理系統(DBMS)提供的答案做出近似的回答[42].然而,靈活的查詢在響應質量上可能代價高昂(尤其是需要計算聚合函數“sum”“avg”“count”“var”等).因此,Tlili 等人提出了一種機器學習與近似查詢處理技術(AQP)相結合的查詢處理方法[43]:(1)對于聚合查詢,他們仍然使用FCA 生成層次結構的數據路由方法,允許用戶將這些響應個性化為多個級別;(2)為了降低響應時間,他們使用近似查詢處理(AQP),犧牲準確性以降低響應時延;(3)為了提高回答的準確性,他們同時采用在線聚合技術[44],在運行應用程序時逐漸接近答案.此外,在線聚合技術包括對數據庫的初始數據應用已知的樣本信息,以最小化磁盤訪問,平衡響應時間和回答的準確性.
4 面向AI 的數據治理引擎
AI 算法和模型依賴于高質量的數據,但在現實中,數據存在著大量的錯誤和不一致信息.傳統的數據管理技術包括數據發現、清洗、融合等工作,涉及多模數據管理、多源數據融合等諸多復雜的問題,但是仍然還存在一些不足,例如質量不高、仍然需要大量的人力投入.因此,在數據管理系統支持AI 算法時,面對海量異構的訓練數據和模型數據,我們需要提供更加高效的數據存儲和分析技術.智能數據管理引擎[45,46]通過結合AI 技術優化數據庫組件,可以為大規模的數據發現、清洗、融合提供更加智能的服務.
4.1 面向AI的數據發現技術
多源異構數據中可能存在大量的信息丟失現象.此外,很多數據都是稀疏的,不容易發現真正有意義或敏感的數據.這些問題由于缺少統一的評價規則、數據結構復雜、信息不對稱等挑戰而變得非常難以解決.故此,下面我們分別介紹如何結合數據管理系統和分布式計算平臺,更好地實現數據發現.
? 統一的數據處理架構
Teradata-for-DL 平臺提供了統一的數據處理架構[47],重新記錄不同的數據是如何被存儲、管理、分發和持久化的.雖然Teradata 數據庫是一個傳統的關系數據庫,它使用ASTER 分析系統進行數據發現,這包括對非結構化或半結構化數據的“極端SQL”分析和高級分析(非SQL).此外,Aster 引入了不同類型數據需要的計算平臺,包括引入MapReduce 提供分布式計算能力;引入圖形引擎和NPath 分析等.這樣,Teradata-SQL-for-DL 能夠更好地混合、使用不同的數據源(如傳統的關系型數據存儲在企業數據倉庫中、實時數據流存儲在Hadoop 中,等等),供深度學習模型學習,如給銀行客戶的信用進行打分.此外,它還提供在線的Web 服務,用戶可以利用Restful 框架,方便地自定義數據處理的方式.
? 數據編排
隨著來自不同系統、業務流程數據的容量、速度、多樣性的增長,企業需要面對更加復雜的數據訪問、發現、管理、安全等問題,導致查找和驗證數據集變成一個復雜的手動過程.并且,不斷增加的法規和合規性要求使其變得更加重要.因此,BigQueryML 提供了數據目錄技術,用于數據發現、管理和簡化.為了幫助企業快速發現、管理和理解他們的數據資產,數據目錄提供完全管理和可擴展的元數據管理服務.數據目錄為數據發現提供了一個簡單易用的搜索界面,由支持Gmail 和Drive 的相同Google 搜索技術提供支持,并為捕獲技術和業務元數據提供了一個靈活而強大的編目系統.在安全和數據治理方面,它與云DLP(data loss prevention)系統集成,用戶可以發現、編目敏感的數據資產.此外,它基于谷歌云支持源訪問控制列表(ACLs),簡化用戶訪問和管理數據,使用戶在企業級數據平臺上以可信方式管理數據.
4.2 面向AI的數據清洗技術
傳統的數據清洗非常繁雜,包括噪聲過濾、異常值檢測、去重處理等很多方面的工作(數據工作流),用傳統的數據庫系統需要結合大量的人力投入.而人工智能算法中對數據清洗質量和效率的要求較高,所以我們分析利用AI 優化的數據庫技術[48]提供數據清洗的工作.
? 自動生成數據流水線
Shang 等人提出了一款迭代式生成數據工作流的工具Alpine Meadow[48],他們的工作主要是將數據工程平民化(democratization),即幫助沒有足夠專業知識的用戶高效地進行數據清洗工作.它需要顯著減少構建機器學習流水線式架構所需的專業知識.理想情況下,用戶應該能夠指定一個高級任務(例如,根據數據預測標簽X),然后,系統自動組成一條機器學習流水線來完成該任務,包括所有必要的數據清理、功能工程和超參數調整步驟.Meadow 的核心設計思想是,通過模擬經驗豐富的數據科學家的決策過程來解決ML 問題.一個有經驗的數據科學家如何處理一個問題?首先,他會檢查數據,并根據自己的經驗,對特征縮放、嵌入、數據清理等做出高層決策.Meadow 把這個過程映射為一個“數據處理流水線”,并將所有可能抽象成一個有向無環圖上的搜索空間.基于數據庫中存儲的大量數據處理相關的經驗,它自動學習構建數據處理流水線的規則.其次,數據科學家可能會使用可靠且經常成功的模型族,例如隨機森林,并檢查最常見的錯誤(例如標簽不平衡或重復標簽列).在初始結果產生之后,數據科學家將開始通過添加更復雜的處理步驟、更改模型族、添加/刪除特性、增加樣本大小等操作來修改流水線框架.在Meadow 中,每個邏輯流水線的超參數空間都有一個關聯的性能模型,用于查找有潛力的配置.如果從未使用過邏輯流水線,則沒有與之關聯的任何模型,因此我們開始使用默認或隨機配置.一旦收集到第1 個結果,我們的系統就開始選擇下一個基于貝葉斯優化的超參數.通過評估不同的物理流水線,我們收集了當前數據集的一些經驗,可以使用這些經驗更新我們的成本和質量模型以選擇邏輯流水線,并使用貝葉斯優化模型來選擇物理流水線.這是一個迭代和增量的過程.類比數據科學家的工作方式,Meadow 結合數據庫的數據管理能力和機器學習模型的學習能力共同完成復雜的數據清洗工作.
? 自動化數據管理
智能數據庫系統[42]可以為大規模共享數據提供智能管理服務:其一,智能數據庫系統集成了AI 組件,幫助實現數據搜索的各類智能操作(AI 優化數據庫組件);其二,智能數據庫系統集成了大量數據優化技術,幫助更好地融合不同數據(數據庫優化技術).以異常值檢測為例,異常值檢測廣泛用于特征工程、對異常數據進行過濾.其復雜度隨單元的磁盤算法中的單元數呈指數增長,性能會隨著單元數和數據點數的增加而降低.一方面,我們可以利用數據庫優化技術優化AI 算法,如Zhao 等人提出利用索引結構CDTree 對異常點檢測進行優化[49].CDTree 只存儲非空的單元格,并使用聚合技術將同一單元格中的數據對象存儲到連續的磁盤頁中,從而大大提升了異常值檢測的表現.另一方面,我們可以用AI 克服數據多樣性的挑戰,如目前數據庫系統會綜合性地存儲多模數據,Xu 等人提出了基于希爾伯特指數的異常檢測算法[50],將不同的數據類型抽象到度量空間中,實現更高的檢測速度.
4.3 面向AI的數據融合技術
復雜的AI 算法需要大量的數據作為訓練集.一個訓練集往往有多個數據來源,如社交評論、訪問信息、交易信息等,存在大量不同的數據格式,如csv、json、jpg 等.對這些異構數據直接進行建模、類型轉換、連接等開銷較大,所以我們分析利用AI 優化的數據庫技術[46]提供數據融合的工作.
? 降低數據生成開銷
在大規模訓練場景下,訓練集往往來自多個數據源,因此需要SQL 提供多源數據融合服務.對于任何機器學習算法,我們通常假設數據集是一個單一的表.但現實生活中,數據集往往是由多個存在主外鍵依賴的表組成的.將它們直接連接再進行特征選擇,非常浪費時間.而且特征數量的增加可能會使分析人員更難探索數據,而且還會增加機器學習算法和特性選擇方法的執行時間.因此,Kumar 等人[51]提出了一種分析主外鍵(key-ForeignKey)對機器學習表現和準確度影響的方法.首先,他們基于信息論的方法增加價值評估功能,評估每個原始特征對于模型的“有用程度”.然而,被評定為“冗余(redundancy)”的特征可能在預測有用特征方面有價值.因此,之后他們評估特征之間的相關性(relevancy),基于模型特點在冗余-相關性之間加以折中.最后,面對核心問題:如何預測一個先驗,即判斷一個與r表的連接是否是可以安全避免的,他們從使用“受控”數據集的模擬研究開始,以驗證理論分析,并精確測量當改變標準化數據的不同屬性時誤差的變化情況.最后,他們解釋得出的決策規則以及如何使用模擬測量來調整特征join 方式.這種方法可以在提高機器學習模型表現的同時不喪失準確性,并幫助將機器學習算法應用在數據庫的數據處理流程中.此外,Kumar 等人還提出了基于線性回歸模型優化數據源的連接操作.對于一個稱為廣義線性模型(GLMs)的大型通用ML 技術類,可以在不犧牲質量和可伸縮性的情況下學習連接并避免冗余.他們主要研究用于連接操作的混合哈希算法,用于快速估計所有方法的I/O和CPU 成本.此外,他們提出了3 種在單節點RDBMS 中的連接上運行批量梯度下降(batch gradient descent,簡稱BGD)的替代方法:流、流重用和分解學習.每種方法都避免了某種形式的冗余:流避免寫入關系表,并可以保存在I/O 上;流重用利用了BGD 的迭代特性,并避免了在第1 次迭代后重新劃分基關系.但是,這兩種方法都不能避免BGD 計算中的冗余.因此,他們設計了避免計算冗余的因式分解學習方法.分解學習法通過交錯連接操作與BGD 的計算和I/O 來實現這一點.我們的方法都不影響模型的質量.此外,使用用戶定義的聚合函數(UDAFs)的抽象,很容易地在RDBMS 中得以實現,這提供了可伸縮性和易于部署的能力[52].
? 簡化數據建模
數據庫研究的一個主要目標是,將附加語義合并到數據模型中.經典的數據模型由于無法表示和處理許多實際應用中可能出現的不精確和不確定的信息而受到影響.因此,模糊集理論已廣泛應用于各種數據模型的擴展,滿足復雜對象不精確和不確定性建模的需要.為了更恰當地描述這種關系并更好地利用現有值,Lai 等人提出了一種不完全數據建模方法來輸入缺失值[50].該方法利用不完全記錄和完整記錄建立Takagi-Sugeno(TS)模型.在這個過程中,不完整的數據集被分成幾個子集,并且只包含重要變量的線性函數被建立起來,以描述每個子集中屬性之間的關系.這套方法能為存在一定缺失值的數據集很好地建立起數據模型,并提高數據的準確性.
? 智能數據融合
訓練集數據的結構和價值可能存在很大差異.企業數據池大多基于Hadoop 等大數據引擎,需要將大量業務相關的數據源聚合在一起,然而這種數據聚合的速度對于機器學習來說太慢了.基于如Kinetica、IBM Watson Analytics(https://www.ibm.com/watson-analytics)等結合人工智能數據庫的平臺,首先,我們可以利用大規模GPU芯片組快速進行數據編/解碼和類型轉換;其次,IBM Watson Analytics 還允許直接查詢各種數據庫,包括Cloudera Impala、MySQL、Oracle、PostgreSQL 等.它有32 個連接器,可以方便地使用來自這些源的數據,近乎實時地進行數據同步和融合.該工具使那些具有深厚數據科學技能的人們能夠跳過數據融合的復雜工作,直接進入到模型設計階段.
5 研究展望與未來趨勢
5.1 面向AI+DB的統一的數據模型
目前,數據庫系統支持AI 操作存在數據模型不一致的問題.數據庫中的數據大多是關系型數據,而AI 操作存在大量張量型數據.這導致在用數據庫管理AI 時存在大量的數據存儲開銷,如存在格式轉換、數據丟失等問題;而且會降低執行效率,如在用機器學習做圖片分類問題時,圖片都是張量格式,而在進行類別判斷(如“刪掉標簽‘貓’”等)時,需要進行一些標量計算,導致執行引擎需要在不同的數據模型上分別操作,增加了執行開銷.所以,未來我們需要研究用統一的數據模型同時支持標量、向量、大規模張量等不同類型的數據操作,更好地支持AI 計算和數據庫查詢.但是現有的數據模型(如關系表、鍵值對、時間序列等)都有著各自的局限性,所以Idreos等人提出了一種學習型數據結構設計引擎Data Alchemist[53].它混合不同粒度的數據結構的設計原則,構成一般化的設計空間.通過在設計空間中對不同的組合、調優和性能進行分析,自動生成合適的數據結構.
5.2 面向AI的優化器
盡管已有工作利用聲明性的語言模型支持AI 算法,但在優化器生成實際AI 操作階段仍存在很多問題.一種方法是直接把類SQL 程序轉化成Python、R 等語言執行(如SQLFlow、Rheem 等),不僅增加了語言轉化開銷,也沒有對算法流程進行優化.而另一種方法是預先針對AI 算法定義了新的算子(如MADlib 等),借助代碼生成器將類SQL 語句翻譯成AI 算子序列,但是不同于傳統數據庫查詢生成執行計劃,沒有對算子類型選擇以及算子之間的連接關系進行有效的優化.因此,未來我們將研究面向AI 的優化器:首先,統計AI 執行相關的物理信息(如芯片頻率、磁盤讀寫速度等),建立AI 算子的代價估計機制.其次,設計針對AI 的執行計劃選擇機制.因為不同于數據庫查詢,除了數據建立的聯系外,AI 算子之間還存在環境、計算等依賴關系,或沒有顯式關系(泛化為“執行森林”).所以計劃選擇算法(如泛化的動態規劃、強化學習算法等)需要基于代價估計的結果,智能地選擇合適的運行環境、算子類型、組織邏輯等,在算法的優化程度和選擇效率之間實現平衡.
5.3 AI+DB聯合優化
AI 和數據庫融合技術有非常大的發展潛力.
? 首先,通過結合AI 技術(AIforDB),智能數據庫系統可以實現組件學習化,包括智能參數調優[54-56]、優化器[57,58]、物理設計[59,60]、表現預測[61]等等.比如:學習型參數調優[54,56]通過理解不同負載特點,動態地調整參數來實現整體吞吐量和單條查詢執行效率之間的平衡;智能計劃選擇[58]利用機器學習模型,從歷史數據中學習對不同連接方式的代價估計方法,進而選擇合適的執行計劃;動態索引選擇[60]基于強化學習等算法,針對不同的查詢和數據特點選擇合適的索引,平衡索引建立開銷和查詢的執行效率.因此,AI 技術可以全方位地提高數據庫處理海量查詢、異構場景的能力;
? 其次,前面我們已經介紹了基于傳統數據庫對AI 易用性、執行效率、數據質量進行優化的方法,而基于智能數據庫系統,我們可以進一步提供智能靈活的AI 解決方案,包括:
1)智能的AI 語言模型:結合NLP 等方面的研究成果,數據庫可以支持自然語言級別的SQL 翻譯,允許基于用戶對問題的模糊描述給出較為精確的分析結果,進一步實現AI 平民化;
2)智能的AI 算法優化引擎:目前,生成類數據庫的AI 執行計劃仍然是很具挑戰性的,包括對大量不同的AI 算法統一建模、在大規模算子空間中進行算法匹配等等.利用深度學習、強化學習等算法,可以更快、更好地學習算法組織策略,并根據需求變化,智能地調整優化目標;
3)智能的AI 執行引擎:目前,數據庫執行引擎需要調度不同類型的AI 算子和傳統數據庫算子,負擔較大.結合AI 技術,智能AI 執行引擎可以預先估計AI 算法可能的計算、存儲需求,節省資源輪詢的開銷.此外,通過智能地調配空閑資源,允許等待的任務提前執行,更加充分地使用不同的硬件資源,提高整體訓練效率;
? 再有,AI 和數據庫融合技術為下一代計算方法指明了方向.面對海量異構數據,傳統的計算方法存在用時長(普通數據庫處理查詢)、結果不夠準確(AQP)等問題,通過結合深度學習等技術,我們可以在一個KB 級神經網絡中壓縮TB 級數據信息,根據問題,在毫秒級別給出計算結果(前向傳播),為傳統計算方法帶來革命性的創新和優化.AI 原生數據庫通過結合AI 較強的學習、計算能力和數據庫系統的數據處理、管理等經驗,在降低AI 使用門檻的同時,可以大幅度地提升數據庫各方面的性能,為下一代數據庫和AI 技術的發展指明了一個方向.
5.4 大規模參數調優
在今天的機器學習任務中,隨著訓練數據和模型的增長,很難在單個服務器上執行訓練過程,這就需要分布式機器學習方法(distributed machine learning)在多個服務器之間劃分工作負載[62].比如,訓練數據的實際數量如果在1TB~1PB 之間,就可以創建具有109~1012個參數的強大和復雜的模型,這些模型通常由所有工作節點全局共享,在執行計算以優化共享參數時,這些工作節點必須經常訪問共享參數.為了更好地管理、優化、分析這些共享參數,目前有一些參數服務器方面的研究[62,63]支持大規模參數的分布式存儲和協同.但是這些工作大多需要基于獨立的服務器,或搭載在主流的分布式機器學習系統上(如TensorFlow).而目前已有很多比較成熟的分布式數據庫系統(distributed DBMS),通過在事務工作負載中利用并行性可以實現更高的性能[64].未來,如果用分布式數據庫支持參數服務器,我們可以將機器學習訓練任務作為負載下發給分布式數據庫系統:一方面,由數據庫自動地進行任務調度和執行,簡化分布式機器學習算法的實現;另一方面,將全局共享參數表示為關系型數據,幫助算法在更細粒度上實現并行操作,提高訓練任務的執行效率.此外,利用數據庫的可靠性控制機制(如自動診斷、錯誤容忍、自動恢復等),我們可以有效地解決參數更新同步等問題,避免數據不一致帶來的更多的資源開銷和結果誤差[57].
5.5 錯誤容忍的深度學習系統
深度學習模型訓練不具有錯誤容忍能力,進行分布式訓練時,一個進程崩潰,整個任務就會失敗.而且,放在內存中的數據更容易出現這類問題.因此,未來我們可以結合數據庫系統的錯誤容忍技術,提高深度學習的魯棒性.為了確保在可預見和不可預見的人為或自然災害下業務的連續性,數據庫系統都必須從以下兩個方面保證容錯和災難恢復能力.
? 首先,由相同或等效系統備份的硬件系統.例如,可以通過使用并行運行的相同服務器,將所有操作鏡像到備份服務器,使服務器具有硬件上的容錯性;
? 其次,由其他軟件實例備份的軟件系統.例如,具有客戶信息的數據庫可以連續地復制到另一臺機器上(復制集).如果主數據庫關閉,操作可以自動地重定向到第2 個數據庫.此外,目前還有在流式處理系統上提供的近似錯誤容忍技術[35,65],通過適應性地發布備份(如僅當錯誤超過用戶定義的可接受級別時才發出備份操作),以確保故障時的誤差受到理論保證的限制.
5.6 大規模分布式訓練
分布式機器學習包括多節點的機器學習算法和系統,用于提升執行性能、提高計算精度、擴展到更大的輸入數據(幫助顯著減少學習的錯誤率)[66-68],因此,已被廣泛應用在真實生產環境中,幫助公司、研究人員和個人從大量數據中得出有意義的結論.然而,分布式機器學習仍然面臨著很多亟待解決的問題,如它不支持彈性調度.比如一個有N個GPU 的集群上在運行一個作業,使用了一個GPU.此時,一個新提交的作業要求使用N個GPU,因為空閑GPU 個數是N-1,所以這個新的作業不能開始執行,而是得一直等數小時甚至數天,直到前一個作業結束、釋放那個被占用的GPU.在如此長的時間里,集群利用率<1/N,導致集群利用率很低.所以,我們可以結合數據庫系統,提供多方面的系統性能上的優化.
1)一致性:數據庫系統能夠有效地保證訓練一致性,如在多個節點為同一個任務工作時,確保在不同分區的同一套全局數據的一致性;
2)容錯性:如上節討論的,當我們把一個負載任務分發到10 000 個計算節點上,在一個節點宕機時,仍然能夠保持訓練(如根據最近的歷史鏡像回退),以避免重新訓練;
3)通信:分布式機器學習涉及大量的I/O(如磁盤讀寫)和跨節點數據傳遞過程.基于數據庫的存儲引擎,我們能夠高效地調度不同類型環境(如單節點磁盤系統、分布式文件系統等)上的I/O 操作,提供無阻塞的數據處理過程;
4)資源管理:構建和維護一個計算集群的成本較高,因此,一個集群通常由許多用戶共享.基于數據庫的負載調度機制,在最大化利用率的同時,幫助管理集群,并適當地分配資源以滿足每個人的請求(個性化定制).
6 總結
本文綜述了支持人工智能的數據管理技術.針對人工智能技術中存在的使用門檻高、數據密度高、算力要求高等問題和挑戰,我們從數據管理系統的層次角度出發,分別分析不同層級數據管理方法如何優化人工智能算法.首先概述了支持人工智能的數據管理技術的整體架構,給出了不同層級的主要內容.然后,針對每一層級分別展開綜述.在聲明性語言模型方面,分別概述聲明性SQL 語言的擴展、邏輯封裝與優化技術;在算法優化引擎優化AI 方面,分別概述算子代價估計與選擇、算法組裝與選擇、模型管理等技術;在異構執行引擎方面,分別從新硬件和分布式架構兩方面概述異構AI 算子的計算和優化方法;在智能數據治理方面,分別概述多模、多源數據存儲和基于智能數據庫的數據查詢優化、數據分析優化和數據建模簡化方面的工作.最后,討論了支持人工智能的數據管理技術的發展方向,并給出進一步的展望.
致謝本文由國家自然科學基金(61925205,61632016)、華為公司、好未來教育公司給予大力支持.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
