基于視頻和人體姿態(tài)估計的老年人摔倒監(jiān)測研究*
2021-05-18 09:39:56黃展原李庚浩
計算機工程與科學 2021年5期
黃展原,李 兵,李庚浩,3
(1.對外經濟貿易大學信息學院,北京 100029;2.東北大學計算機學院,加州 圣荷西 95136,美國;3.中國人民大學漢青經濟與金融高級研究院,北京 100872)
1 引言
據中國國家統(tǒng)計局2018年發(fā)布的統(tǒng)計數據顯示,我國目前老年人(65歲及以上人群)超過1.58億人。這一數字在未來幾年將持續(xù)增長。老年人由于平衡能力和視力等身體機能的退化,摔倒事件經常發(fā)生。具體來說,每年約有三分之一的老年人發(fā)生過摔倒[1]。摔倒對年輕人來說并不要緊,但對老年人卻是非常危險的。它可能導致一些嚴重的疾病,如髖部骨折、頭部受傷或心臟病發(fā)作。故而,摔倒成為中美兩國老年人因傷致死的頭號原因[2]。幸運的是,就醫(yī)時間與摔倒死亡率之間存在明顯的正相關。換句話說,如果能在很短的時間內就醫(yī),摔倒的老人可能不會有嚴重的后果。因此,自動化的摔倒監(jiān)測越來越受到研究者和醫(yī)護人員的關注。它可以在監(jiān)測到老年人摔倒時自動發(fā)出警報,其家人或附近的醫(yī)院可以迅速做出反應,以挽救生命或降低摔倒受傷的嚴重程度。
摔倒監(jiān)測并不是一個全新的研究領域,早在20世紀80年代就有學者做過關于老年人摔倒的統(tǒng)計研究[2]。進入21世紀以來,也有學者借助機器學習方法,嘗試實現(xiàn)自動化的摔倒監(jiān)測[3,4]。最近兩年,隨著硬件能力的提升和深度學習的崛起,摔倒監(jiān)測重新受到人們的關注。一些學者借助新出現(xiàn)的人工神經網絡提升摔倒監(jiān)測的準確率[5]。從目前摔倒監(jiān)測的3種主流方法看,基于穿戴式傳感器的方法和基于環(huán)境傳感器的方法,都有設備復雜昂貴、操作不方便以及識別率低等缺陷;而基于3D視頻的摔倒監(jiān)測方法,由于計算復雜度較高導致處理速度過慢,實時性較差。基于2D視頻的摔倒監(jiān)測研究作為一個新興的研究方向,具有計算量小、處理速度快等特點,但積累的數據集規(guī)模較小,模型的泛化能力和實際應用效果都有待于在實踐中進一步驗證和提升。總之,與包含深度數據的3D攝像頭相比,基于2D視頻的摔倒監(jiān)測性價比更高,并且可以直接應用于現(xiàn)有的監(jiān)控系統(tǒng)當中,更具實際價值。本文基于2D視頻來進行摔倒監(jiān)測研究,并將人體姿態(tài)特征[6]引入到摔倒監(jiān)測中,嘗試對本文算法的敏感性和實效性進行提升。
2 相關工作
目前,摔倒監(jiān)測有3種主流方法,包括基于穿戴式傳感器的方法、基于環(huán)境傳感器的方法和基于視頻的方法。
2.1 基于穿戴式傳感器的方法
基于穿戴式傳感器的摔倒監(jiān)測方法的設備又可以分為按鍵設備和自動式設備。按鍵嚴格意義上不算傳感器,它在老年人摔倒后被按下,類似一鍵報警設備。按鍵式設備在老年人摔倒喪失行動能力后不適用,自動式的穿戴傳感器則更具實用價值。其中,自動式的穿戴傳感器監(jiān)測又可以分為基于人工設定閾值的方法和基于機器學習的方法。早在2007年,Chen等人[7,8]就已經相繼提出了基于人工設定閾值的方法。他們通過對三軸加速度傳感器數據設定閾值,進而進行摔倒事件的判定。Zhang等人[9,10]則相繼提出了基于機器學習的摔倒監(jiān)測方法。他們利用SVM對加速度傳感器的數據進行訓練,建立可靠的分類器。基于可穿戴傳感器的方法經過多年的研究,可以實現(xiàn)相對可靠的監(jiān)測,但其本身固有的缺點依然存在。比如雖然它的漏檢率較低,但是容易出現(xiàn)假陽性,即容易將坐下、蹲下和躺下等動作判定為摔倒。同時,移動設備的攜帶和充電也是一個問題。這并不適合應用在老年人的摔倒監(jiān)測上,因為老年人可能會忘記佩戴設備及為其充電。
2.2 基于環(huán)境傳感器的方法
基于環(huán)境傳感器的方法由于不影響老年人的生活,曾經受到許多關注。在2006年,Alwan等人[11]就引入了一種基于地面振動的摔倒監(jiān)測方法,它幾乎不會影響老年人的正常生活。Rimminen等人[12]也采用了地面?zhèn)鞲衅鳎媒鼒龀上襁M行摔倒監(jiān)測,在少量數據的測試中取得了90%左右的敏感性和特異性。這些環(huán)境傳感器被安裝于地面下方。盡管這類研究取得了較高的準確率,但由于每臺設備成本過高、監(jiān)測范圍小,很難將其應用于現(xiàn)實環(huán)境中。因此,我們可能需要性價比和準確率更高的方法。Zhuang等人[13]使用遠場話筒將摔倒與家庭環(huán)境中的其他噪音區(qū)分開來,并利用高斯混合模型分類,但該研究的準確率并不高,在實驗室環(huán)境中也只能達到67%左右的準確率,同樣無法在現(xiàn)實環(huán)境中使用。
2.3 基于視頻的方法
基于視頻的摔倒監(jiān)測研究由來已久,不少學者將精力放在3D視頻的摔倒監(jiān)測上。早在2010年,Zambanini等人[3]利用多個攝像頭進行3D建模,嘗試引入人體的3D特征來提高準確率,但效果差強人意。一年之后,Rougier等人[14]把人體形狀輪廓和3D建模結合起來,達到了看似精準的檢測效果,但由于當時用于測試的數據集太小,并沒有很強的說服力。Rougier等人[15]嘗試提出魯棒性更好的算法,即通過計算3D人體加速度來減小摔倒事件將要結束時被家具遮擋的影響。2015年,Stone等人[16]別出心裁地使用了Microsoft為Xbox游戲機開發(fā)的Kinect體感設備來進行摔倒監(jiān)測,并取得了不錯的效果。但是,基于3D視頻的摔倒監(jiān)測有很大的局限性,首先,成本較高;其次,若利用成本較低的深度攝像頭,又會受限于它對被測物體位置的嚴格要求;最后,計算復雜性高,會導致處理速度過慢。
另一個研究思路是基于2D視頻的摔倒監(jiān)測研究。Chen等人[17]在2010年就將前景提取算法應用于2D圖像,并將人體形狀輪廓的變化作為摔倒的主要特征進行摔倒監(jiān)測,但由于測試數據過少,我們很難評判這種方法在現(xiàn)實場景中的應用效果。Liu等人[18]利用KNN分類器將人體輪廓邊界的高度和寬度的比值和臨界時間差進行分類,對跌倒和躺下事件檢測的準確率為80%左右。Charfi等人[19]手動選擇了一些基于人體邊界框的高度和寬度及比例、人體的軌跡及其方向等特征,并利用SVM分類器分類,取得了超過90%的準確率。然而與此同時,他們的研究是基于自己制作的小規(guī)模數據集,這導致其模型并沒有很好的說服力。但是,這些研究在特征選擇和分類器的多樣性上仍然取得了不小的進步。總之,與包含深度數據的3D攝像頭相比,基于2D視頻的摔倒監(jiān)測性價比更高,實時性更好,并且可以直接應用于現(xiàn)有的監(jiān)控系統(tǒng)當中,更具實際價值。本文也將基于2D視頻來進行摔倒監(jiān)測。
在2016年,Wang等人[20]提出了一個全新的研究框架,即把摔倒監(jiān)測分為2個階段。第1步訓練一個靜態(tài)分類器,即將每一幀圖像用支持向量機進行分類并為其標注相應的3種標簽,包括未摔倒、摔倒中和已摔倒。第2步訓練一個動態(tài)分類器,即將上一步驟生成的標簽序列作為第2個支持向量機的輸入,進而達到分類視頻的目的。這個序列的長度因研究而異,該研究的序列速度被設定為30 fps,而另一項研究的序列速度被設定為16 fps[19]。Wang等人[20]的研究使用了當時較為流行的神經網絡PCANet作為特征提取算法。最后他們在公開的摔倒數據集上實現(xiàn)了89.2%的敏感性和90.3%的特異性。一年之后,Wang等人[21]嘗試改進這個方法,他們將方向梯度直方圖和局部二值模式提取的低層特征和用Caffe提取的高層特征相結合,再進行二階段摔倒監(jiān)測。然而,這項研究對結果的提升并不顯著。2018年,Zerrouki等人[22]認為摔倒是一個與時間序列緊密相關的事件,在利用支持向量機作為分類器的基礎上,將隱馬爾可夫模型引入摔倒監(jiān)測領域。在實驗中,他們只給出了測試集最后的總體準確率,沒有足夠說服力。
綜上,基于視頻的摔倒監(jiān)測具有成本低、實時性好和可靠性高等優(yōu)點,且不需要老年人佩戴外部設備或為其充電,方便快捷;但另一方面,一些調查指出,可能會有部分老年人在實際應用中有一種被監(jiān)控的不適感。總體來說,在利大于弊的同時,基于2D視頻的摔倒監(jiān)測方法仍然有一定的提升空間。先前的大部分研究都沒有考慮到人體姿態(tài)對摔倒的影響,故本文引入人體姿態(tài)特征,嘗試對本文算法的敏感性和實效性進行提升。
3 數據基礎
3.1 人體姿態(tài)信息抽取數據集
本文在基于2D視頻的摔倒監(jiān)測研究中,需要將人體關節(jié)位置信息作為特征項,引入到摔倒監(jiān)測模型中。本文利用OpenPose提取原始數據中人體關節(jié)的位置[6],該數據集和開源框架是由卡內基·梅隆大學的感知計算實驗室建立的,可以檢測包含多人圖像(2D和3D)中的人體關節(jié)點。該數據集和開源框架可以提供2D多人實時人體關節(jié)點監(jiān)測,是第1個可以同時檢測人體、手、面部和足部關鍵點(總共135個關鍵點)的實時多人系統(tǒng)。
3.2 模型效果驗證數據集
為了驗證引入人體姿態(tài)數據的模型準確性和泛化能力,本文選取了3個在摔倒監(jiān)測領域常用的公開數據集進行模型效果驗證,如表1所示。
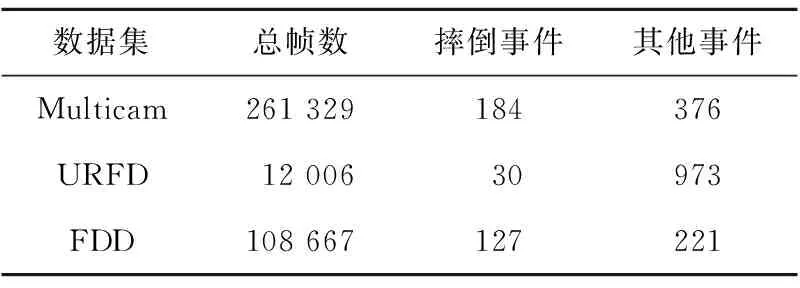
Table 1 Fall dataset statistics表1 摔倒數據集統(tǒng)計信息
第1個數據集Multicam(Multiple cameras fall dataset)包含24個不同的場景,每個場景的視頻都由8個不同方位的攝像頭進行錄制[23]。其中22個視頻包含了摔倒事件,剩下2個視頻只有一些迷惑性的事件,比如坐下、蹲下和躺下等。這些視頻拍攝的速率為30 fps,分辨率為720×480,每段視頻長度在30 s~1 min不等,共31.2 GB。每個場景的1~7號視頻都被作為訓練集,而8號視頻則作為測試集。
第2個數據集URFD(UR Fall Detection)包含70個視頻序列,其中30個視頻中包含摔倒事件,剩余40個視頻是一些日常生活中的迷惑性事件,比如坐下、蹲下和躺下等[24]。這些視頻拍攝的速率為30 fps,分辨率為640×480,每段視頻長度在3 s~30 s不等,共8.5 GB。隨機選取50個視頻序列作為訓練集,剩余20個視頻作為測試集。
第3個數據集FDD(the Fall Detection Dataset)包含191個視頻序列,有家庭、咖啡館、辦公室和教室等場景[25]。這些視頻是以25 fps的速率錄制的,分辨率為320×240,每段視頻長度在30 s~1 min不等,共16.3 GB。隨機選取130個視頻作為訓練集,剩余61個視頻作為測試集。
4 技術方案
4.1 技術路線
基于視頻的摔倒監(jiān)測通常都由3個步驟實現(xiàn),分別是數據預處理、特征提取和分類。本文提出的基于2D視頻的摔倒監(jiān)測方法的技術路線如圖1所示。具體步驟如下:
(1)數據預處理,即規(guī)范圖像大小并合理去除部分冗余的幀數,以提升整體實驗的效率。
(2)特征提取,即利用OpenPose提取原始數據中人體關節(jié)的位置[6]。
(3)構建靜態(tài)分類模型,即利用這些具有增強特征的數據和支持向量機分類每一幀的狀態(tài)[4]。
(4)構建動態(tài)分類模型,即引入時間維度的特征進行摔倒監(jiān)測。
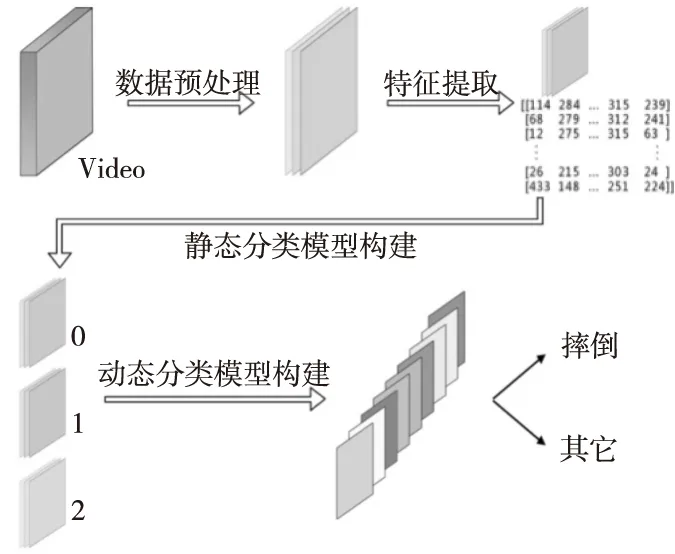
Figure 1 Research technology roadmap圖1 研究技術路線圖
4.2 關鍵步驟
4.2.1 數據預處理
在摔倒監(jiān)測的問題中,數據預處理是最重要的步驟之一[20,21]。本文的數據預處理共分為2個步驟,如圖2所示。
第1步,將所有原始數據切分為單幀圖像,以便于后續(xù)處理。
第2步,對原始數據的幀進行抽取,以加速訓練和測試過程。通過對原始數據的研究,我們發(fā)現(xiàn)摔倒事件的完整展現(xiàn)并不一定需要每秒25幀或30幀。在很多情況下,保留大約一半的幀數便可以區(qū)分摔倒與否。如圖2所示,按照每相鄰2幀保留1幀的方式刪除多余的幀數,在不大幅降低準確率的前提下,最大化地提升本文算法運行效率。
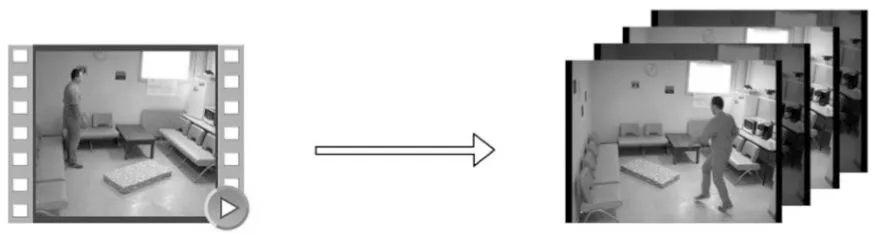
Figure 2 Schematic diagram of data preprocessing圖2 數據預處理示意圖
通常來說,許多研究會在數據預處理階段采用各種前景提取算法將動態(tài)的人體和靜態(tài)的背景區(qū)別開[3,17],比如混合高斯模型和ViBe算法[26,27]。
4.2.2 特征提取
在特征提取部分,將經過預處理的每一幀圖像(如圖2所示)作為輸入,利用OpenPose開源庫,輸出效果圖和15個關節(jié)點的坐標。其中,效果圖是為了用于檢驗結果,而坐標數據是用于構建靜態(tài)分類模型。
如圖3所示,3個數據集中每個人的15個關節(jié)點位置均可正確表示。盡管這些數據集中圖像序列只包含一個人,但本文提供的算法可以在一個房間中進行多人監(jiān)測。當人們跌倒時,他們的身體關節(jié)點開始劇烈扭曲,姿勢非常不自然。這導致了OpenPose輸出的關節(jié)坐標會發(fā)生異常,這可能是一個很好的特征。

Figure 3 Feature extraction diagram圖3 特征提取效果圖實例
4.2.3 靜態(tài)分類模型構建
摔倒是在一段連續(xù)時間內發(fā)生的事件,要想直接分類并不容易。通過對比各種算法對計算資源和數據集規(guī)模的要求[4,20,28 - 30],以及相應的評價效果等,本文確定了采用2個SVM分類模型實現(xiàn)時間和空間維度上分類的方案。建立靜態(tài)分類模型,即對每一幀圖像進行分類。由于摔倒是一個過程,每一幀都有一種狀態(tài)。在本文中,狀態(tài)可以分為3種,包括正常狀態(tài)、摔倒進行中的狀態(tài)和摔倒已結束的狀態(tài)。
靜態(tài)模型的核心算法為支持向量機SVM[4]。在許多實際問題中,樣本并非線性可分的,因此可以采用基于核方法的SVM[1]。核方法即利用一些核函數將樣本從原始的特征空間映射到更高維度的空間中,使得樣本線性可分。本文研究的摔倒監(jiān)測問題,由于特征維數并不多且樣本適中,在沒有足夠先驗知識的情況下,在實驗中選擇使用高斯核函數(RBF)[1]。
在摔倒監(jiān)測的問題中,樣本類別是不均衡的。例如,圖4中狀態(tài)1(摔倒中)和狀態(tài)2(已摔倒)在視頻中占幀數的百分比大致為3%~7%,所以需要采用不同方法平衡分類器。通常可以從樣本和算法2個角度入手,比如可以通過欠抽樣,即只使用部分多數類樣本進行訓練。但是,目前已有的摔倒數據集樣本量較小,因此本文考慮從算法層面來進行處理,即利用懲罰系數和類別權重參數分別控制對錯分樣本的損失度量和不同類別樣本的權重。同時,按照樣本數據集的大致比例,來緩解樣本不平衡和過擬合所帶來的問題。

Figure 4 Data schematic diagram of static classification model圖4 靜態(tài)分類模型的數據示意圖
4.2.4 動態(tài)分類模型構建
建立動態(tài)分類模型即對多幀序列進行分類。靜態(tài)分類模型已經將每一幀圖像分類至某種狀態(tài),包括正常狀態(tài)0、摔倒進行狀態(tài)1和摔倒已結束狀態(tài)2。根據這3種狀態(tài),可以描述視頻中的所有過程,比如標簽“0011122”很可能表示一個摔倒事件的發(fā)生。而對于整個視頻,其間可能發(fā)生了若干次摔倒,則動態(tài)模型每次只需要將視頻中一段時間所包含的內容進行分類即可。通過計算發(fā)現(xiàn),在數據集中發(fā)生摔倒的平均所需幀數為14幀左右(視頻錄制條件為每秒30幀),考慮到要讓動態(tài)模型分類必須保證每次輸入的幀數包含一部分摔倒前和摔倒后的影像,所以每次輸入20幀左右即可。同時考慮到數據預處理中只保留了視頻中一半的幀數,則每次輸入10個連續(xù)的標簽序列即可。
動態(tài)模型的核心算法依然為支持向量機。動態(tài)模型與靜態(tài)模型的訓練沒有前后關系,因為原始數據集中已經標注好了0,1或2的標簽,所以本文在訓練階段不使用由靜態(tài)模型產生的標簽序列,而直接使用原始數據集中的標簽(ground truth)進行訓練,即可最大化地避免靜態(tài)模型的錯誤分類結果影響動態(tài)模型的建立。
5 實驗評估
本文選取3個摔倒監(jiān)測領域常用的公開數據集Multicam、URFD和FDD進行實驗驗證。實驗硬件平臺為一臺Windows 10 64位操作系統(tǒng)的筆記本電腦。處理器為Intel i7-4710mq,4核8線程,最大頻率為3.5 GHz。搭配三星 8 GB DDR3內存和NVIDIA GTX960m顯卡。硬盤為1 TB機械硬盤搭配128 GB固態(tài)硬盤。實驗使用Python 3.6.5版本,并預先安裝好實驗所需的OpenCV,OpenPose, cntk, Scikit-learn和NumPy等開源庫,同時搭建了基于Visual Studio Code代碼編輯器的開發(fā)環(huán)境。整個實驗過程如下所示:
第1步,將所有以視頻形式存儲的原始數據按幀切分成圖像,并按照每相鄰2幀保留1幀的方式刪除多余的幀。
第2步,在特征提取部分,將經過預處理的每一幀圖像作為輸入,利用OpenPose開源庫輸出效果圖和15個關節(jié)點的坐標。每一幀圖像的關節(jié)點坐標為一個包含2×15個整數(int)類型的對象,將每個數據集的對象合并為若干個文件(.json),以便分類步驟使用。
第3步,在靜態(tài)分類模型構建階段,首先,將上一步驟得到的坐標數據對象作為模型的輸入;其次,對輸入的特征進行縮放(Feature Scaling),以減少取值范圍對模型結果的影響;再次,調整本文算法參數,對于實驗中的不平衡樣本,需要調整不同類別的權重,使得損失函數能夠更好地發(fā)揮作用,即讓每一次漏檢摔倒中1和摔倒后2類別的損失變得比漏檢摔倒前0(或者說是正常狀態(tài))要大很多。在實驗中,經過反復地調參優(yōu)化后,將3個類別的權重分別設為0.05, 0.45, 0.45。其中損失函數loss采用默認的Hinge損失函數,核函數選取默認的RBF Kernel,即高斯徑向基核函數。對于RBF Kernel,必須選擇合適的Gamma參數,因為它決定了核函數的形狀,即數據映射到新的特征空間后的分布。Gamma值越大,則支持向量越少,反之則支持向量越多。懲罰參數默認為1.0,如果增大即表示對分類錯誤容忍更小,但過大將增加模型過擬合的可能性。對于懲罰參數和Gamma的確定,最穩(wěn)妥的方式應該是采用網格搜索(Grid Search)進行枚舉,但由于本文實驗數據集較小,若使用交叉驗證法,很可能會由于沒有足夠的數據訓練造成過擬合等現(xiàn)象,故本文參考Charfi等人[19]和Wang等人[20]的一些實驗方法和參數,將懲罰參數設置為5,Gamma設置為默認值。

Figure 5 Data schematic diagram of dynamic classification model圖5 動態(tài)分類模型的數據示意圖
在摔倒監(jiān)測研究中,由于數據集本身的不平衡,傳統(tǒng)的準確率無法作為可靠的性能指標來衡量算法的效果。敏感性將成為本文研究的重點,因為對于摔倒監(jiān)測,本文的首要任務就是把摔倒事件的發(fā)生檢測出來,即召回。由于在靜態(tài)分類模型構建中有3個類別,本文重點關注標簽1和標簽2,即摔倒中和摔倒后的分類效果。這里的召回率即標簽1和標簽2樣本的平均召回率,如式(1)所示:
(1)
其中,TP表示真正例的個數,即被模型預測為正的正樣本個數;FN表示假負例的個數,即被模型預測為負的正樣本個數。
3個數據集上的實驗結果如表2所示。URFD數據集取得了最好的分類效果,這可能是由于URFD數據集統(tǒng)一由一個攝像頭在固定位置固定場景進行拍攝,所以訓練與測試并沒有很大區(qū)別;FDD數據集的表現(xiàn)一般,這可能是由于FDD數據集包含了辦公室、教室和臥室等不同場景,雖然錄制角度相差無幾,但仍然影響分類器效果;而Multicam數據集表現(xiàn)稍遜,這可能是由于Multicam數據集中每一個視頻序列都是由8個不同攝像頭拍攝,導致數據集噪聲較大。
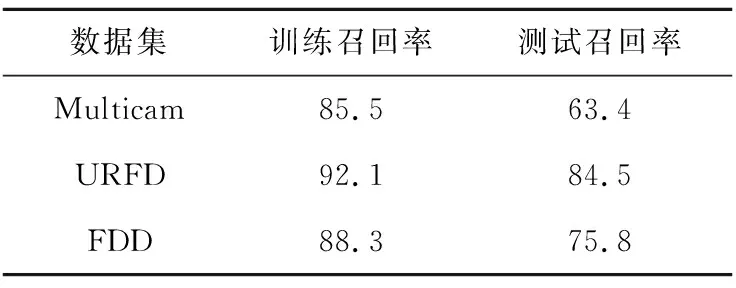
Table 2 Recall rate of static classification model表2 靜態(tài)分類模型召回率 %
對于本文沒有檢測出的摔倒事件,我們人工地分析了部分錯誤案例產生的原因:(1)有過半的錯誤案例并沒有出現(xiàn)特殊干擾,因此我們認為除了人體姿態(tài)特征以外,還需要引入其他重要特征。(2)有少部分將摔倒中判定為摔倒前(即正常)的案例是由于出現(xiàn)了家具等遮擋物,導致一開始的特征提取就出現(xiàn)了問題。
第4步,在動態(tài)分類模型構建階段,將10個連續(xù)的輸入作為特征,進行二分類,即對同一個滑動窗口,每10幀對應一個分類結果,即摔倒或是未摔倒。動態(tài)分類模型所用視頻幀如圖5所示。實驗調用sklearn包實現(xiàn)SVM算法,以用于分類[31]。對于實驗中的不平衡樣本,需要調整類別權重,使得損失函數能夠更好地發(fā)揮作用,即讓每一次漏檢摔倒事件(標簽為1)的損失變得比未摔倒事件(標簽為0)要大很多。具體實驗中,經過參數優(yōu)化將2個類別的權重設置為0.9和0.1。損失函數與核函數在前文研究框架中有詳細解釋,其中損失函數loss采用默認的Hinge損失函數,核函數參考其他研究,選取線性核函數(Linear Kernel)[19,20]。在確定好相關參數后還需要導入靜態(tài)模型,以便測試最后的動態(tài)模型分類效果。測試結果用敏感性(召回率)作為衡量指標,如表3所示。
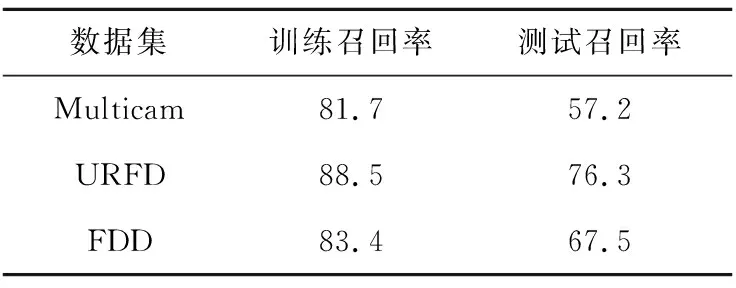
Table 3 Recall rate of dynamic classification model表3 動態(tài)分類模型召回率 %
本文人工分析了部分錯誤分類的案例的原因:(1)從特征提取部分就開始出錯,即由于家具的遮擋無法正確識別人體姿態(tài);(2)有不少摔倒前的滑動窗口中,坐下或蹲下的情況被判定為摔倒,這樣在動態(tài)分類時輸入的本來就是錯誤結果,最后的動態(tài)分類結果自然也不會正確;(3)最后的動態(tài)分類出錯,比如在摔倒事件發(fā)生之前就判定摔倒開始,在摔倒事件結束后很多幀才判定摔倒結束。
對于整個摔倒監(jiān)測流程而言,動態(tài)模型的構建完畢也就標志著整個實驗的結束。更進一步地,本文通過上限分析(Ceiling Analysis)發(fā)現(xiàn),動態(tài)分類模型的提升空間并不大,而特征提取和靜態(tài)分類模型部分有更大的提升空間,這可能也是接下來需要改進的部分。因為許多研究并未公布每個數據集的準確率,而是公布了3個數據集的平均準確率,所以我們很難參考和對比他們的研究成果。但總的來說,本文僅使用人體姿態(tài)特征就取得了不錯的分類效果,因此,進一步結合其他特征的摔倒檢測研究值得期待。
除了對模型的分類效果進行評估以外,本文對模型的實時性也進行了評估分析。因為摔倒監(jiān)測的實時性對于人工干預效果具有較大影響,因此模型測試運行的實時性也是一個重要指標。由于實驗條件的限制(單機普通筆記本電腦的情境下),數據處理速度為30 fps,大概有3倍左右的延遲,即視頻播放1 s,判斷摔倒與否的結論會在3 s后得出,無法實現(xiàn)完全實時的摔倒監(jiān)測。如果在云計算平臺應用該方法,視頻連接到互聯(lián)網進行摔倒監(jiān)測,應該能夠實現(xiàn)實時的摔倒監(jiān)測。這也是未來的研究方向之一。
6 結束語
本文提出了一種基于人體姿態(tài)估計的2D視頻摔倒監(jiān)測算法。首先,使用OpenPose提取原始數據中人體關節(jié)的位置;其次,利用這些具有增強特征的數據和支持向量機算法構建靜態(tài)分類模型,以有效區(qū)分每一幀的狀態(tài);最后,構建動態(tài)摔倒監(jiān)測分類模型。本文算法在3個公共摔倒數據集上進行摔倒監(jiān)測,取得了不錯的效果。
本文的主要貢獻有:(1)將人體姿態(tài)估計方法引入到2D摔倒監(jiān)測領域;(2)采用基于人體狀態(tài)特征的靜態(tài)分類和動態(tài)分類相結合的方法進行摔倒監(jiān)測研究。
基于視頻的摔倒監(jiān)測是一項非常有潛力的研究。在未來,將從以下方面深入研究摔倒監(jiān)測問題:(1)搜集更多的真實環(huán)境下的摔倒視頻,這是目前所缺乏的;(2)引入神經網絡的方法提取一些高層特征,以提高召回率。同時,采用并行計算技術,將可能在更短時間內得出監(jiān)測結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
