基于K最近鄰回歸預測的高能效虛擬機合并
2021-05-20 06:50:34王諾,李艷
計算機工程與設計 2021年5期
關鍵詞:資源
王 諾,李 艷
(河北傳媒學院 信息管理中心,河北 石家莊 051430)
0 引 言
云數據中心中,動態的虛擬機合并實現了運行時虛擬機在不同主機間的在線遷移[1,2],尤其在主機處于較低負載或超載狀態下時,遷移將具有諸多好處。因此,通過遷移操作會使得數據中心內的資源管理更加靈活。然而,虛擬機在線遷移對于運行在虛擬機上的應用任務的性能具有負面影響[3]。由于在云服務提供者與其用戶間提供相應的服務質量是至關重要的,所以動態虛擬機合并應該著重考慮優化虛擬機遷移次數。此時的服務質量需求通常以服務等級協議SLA來描述,根據吞吐量或服務的響應時間上的性能表現來定義[4]。
比較已有工作最小化主機利用數量,本文將設計一種啟發式算法同步最小化虛擬機遷移次數和SLA違例。所提算法進行動態虛擬機合并主要由兩個階段組成:①嘗試將負載最低主機上的所有虛擬機遷移至負載最大主機上;②從當前超載或預測在近期會變為超載的主機上遷移出部分虛擬機以防止可能的SLA違例。同時,提出的算法可以根據當前和未來的資源請求將遷移虛擬機分配至合適主機上。為了預測負載,本文設計了一種基于K最近鄰回歸KNNR模型的預測方法,對未來資源利用率進行預測,該預測方法優于線性回歸方法。為了訓練和測試預測模型,本文通過運行IaaS云環境中的多種現實負載生成歷史數據集,并通過實驗驗證了所提動態虛擬機合并算法的有效性。
1 相關工作
動態虛擬機合并可以增加資源利用率和提高數據中心能效,已有很多相關研究。文獻[5]提出一種動態服務器遷移和合并算法,在給定負載狀態和支持SLA違例的條件下可以降低物理能力的使用量,算法利用了裝箱啟發式方法和時序預測技術最小化主機利用量。然而,算法并沒有考慮新部署中虛擬機遷移次數。文獻[6]利用蟻群系統尋找最優解,同步考慮了休眠主機量和遷移次數。文獻[7]為了避免性能下降,設置門限值防止主機CPU達到100%占用率,將CPU占用率限定在門限值之內。然而,靜態的門限值設置無法處理動態的云負載環境,此時主機上運行的負載類型是多樣的。因此,門限值應該針對不同的負載類型作出相應改變,并允許有效的任務合并。文獻[8]根據歷史數據的靜態分析設置了自適應的上下限值,而文獻[9]則根據數據中心內不同的應用類型,以最大化資源利用率和負載均衡為目標,提出了新的虛擬機部署算法。
虛擬機合并問題可以形式化為裝箱問題,裝箱問題即是將若干物品裝入有限數量的箱子內,并最小化箱子數量。每臺虛擬機可視為一個物品,每臺主機即為一個箱子。由于裝箱問題的NP難屬性,有效求解方法為啟發式方法。如:首次適應算法FF將物品放入可容納該物品的第一個箱子中;最佳適應算法BF將物品放入空間最合適的箱子中。此外,FF和BF算法可進一步改進為降序首次適應算法FFD和降序最佳適應算法BFD。然而,經典的裝箱方法并不能直接應用于虛擬機合并問題。原因在于:①虛擬機和主機擁有多個維度資源,如CPU、內存和網絡帶寬。若考慮CPU和內存資源的約束,虛擬機合并問題就是典型的二維裝箱問題;②虛擬機合并問題可修正為可變箱子(主機)大小的裝箱問題,不同于經典的等同能力箱子的裝箱問題;③經典裝箱方法僅最小化箱子數量,即單目標優化。而本文考慮的目標包括虛擬機遷移次數和SLA違例問題。文獻[10]設計了BFD的改進算法,可以節省部分能耗。文獻[11]利用FFD的改進算法在功耗和遷移代價間取得均衡。文獻[12]利用改進的FF和BF算法在未考慮性能下降的情況下最小化主機利用量。然而,以上算法多是考慮優化比較單一的目標,沒有在能效和服務性能上作出綜合的考量。
本文提出了融合了負載預測機制的改進BFD算法,命名為利用率預測感知的降序最佳適應算法UP-BFD,與已有研究相比具有以下幾點優勢:①算法可以得到能效和SLA違例間的最優均衡解,實現動態的虛擬機合并;②為了降低虛擬機遷移量,算法可以根據當前和未來的資源需求分配遷移虛擬機至目標主機;③為了降低SLA違例,算法選擇從當前超載主機或最近未來會變為超載的主機上遷移部分虛擬機,避免無用虛擬機遷移;④算法利用了K最近鄰回歸方法對負載進行預測,可以基于歷史數據預測主機和虛擬機的CPU占用率,實現了前瞻性的虛擬機合并。
2 問題的提出
虛擬機合并可以優化虛擬機部署,減少活躍主機利用量,這其中需要考慮兩個因素:SLA違例率和虛擬機遷移量。基于未來負載預測可以強化兩個優化目標。以兩個實例描述未作負載預測下傳統虛擬機合并方法的局限性。如圖1和圖2所示,現有2臺主機和3臺虛擬機的部署需求。如圖1(a)所示,Host1和Host2的CPU利用率分別為0.35和0.6。由于Host1擁有足夠資源部署虛擬機VM3,傳統虛擬機合并將VM3遷移至Host1以減少主機利用量,并將Host2轉換為休眠。在時間t+1,VM3的CPU請求從0.6增加至0.75,如圖1(b)所示。由于Host1沒有VM3請求的空閑能力,Host1出現超載,發生SLA違例。因此VM3遷移至Host2以避免SLA違例,如圖1(c)所示,此次即為無用遷移。因此,如果遷移前可以預測資源請求,虛擬機合并就可以避免非必要虛擬機遷移并降低SLA違例。
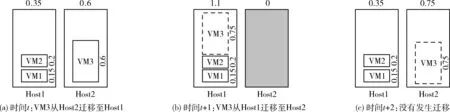
圖1 示例1:未作資源利用率預測
如圖2所示,在當前時間t,VM3遷移至Host1,由于Host1擁有足夠空閑資源部署VM3,如圖2(a)所示。如圖2(b)所示,Host2轉換為休眠,僅Host1為活躍主機。由于VM2的請求CPU利用率增加,此時出現熱點主機。VM3遷移至之前的目標主機以避免SLA違例,如圖2(c)所示。因此,若虛擬機合并算法可以根據主機的未來資源占用率情況對虛擬機進行遷移分配,將極大減少遷移次數和SLA違例。
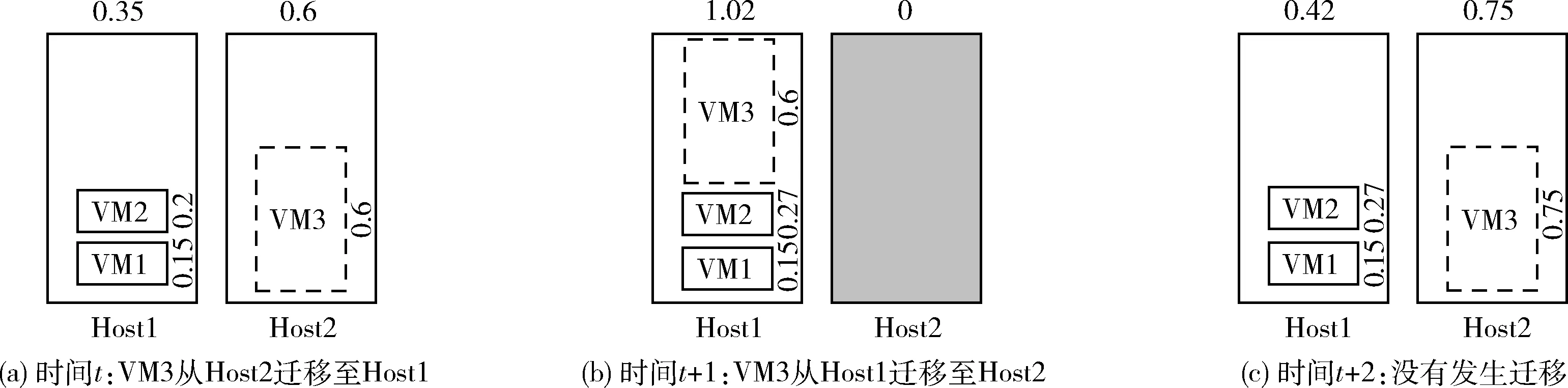
圖2 示例2:作資源利用率預測
3 系統模型
動態虛擬機合并可以形式化為裝箱模型,是NP問題。由于裝箱問題僅能在給定物品下最小化箱子數量,直接應用于虛擬機合并中擁有一定局限性。很多算法也以裝箱思路求解過虛擬機合并問題。然而,這會產生過多的非必要虛擬機遷移,增加SLA違例風險。虛擬化是云計算數據中心的主要技術,利用虛擬化技術可以在物理服務器上部署多個不同性能的虛擬機,以提高整體的資源利用率。虛擬化的一個主要優勢是在數據中心內可以進行動態的虛擬機合并來降低能耗,通過將虛擬機合并到更少數量的物理主機上,并將閑置主機轉換為睡眠模式以提升能效。圖3是虛擬機合并與遷移系統模型。云數據中心由M臺異構主機構成,可通過虛擬機監視器VMM部署N臺虛擬機。每臺主機擁有不同的資源屬性,包括CPU、內存和網絡帶寬。在給定的時間,數據中心可服務于多個同步的用戶需求。用戶通過虛擬機請求方式發送需求,每個需求的長度以百萬指令數MI描述,CPU性能以每秒百萬指令數MIPS描述。模型包括兩個代理Agent:一個是主節點上的全局代理GA(global agent),一個是主機上分布的本地代理LA(local agent)。所提出的動態虛擬機合并算法每次迭代中的任務處理次序如下:
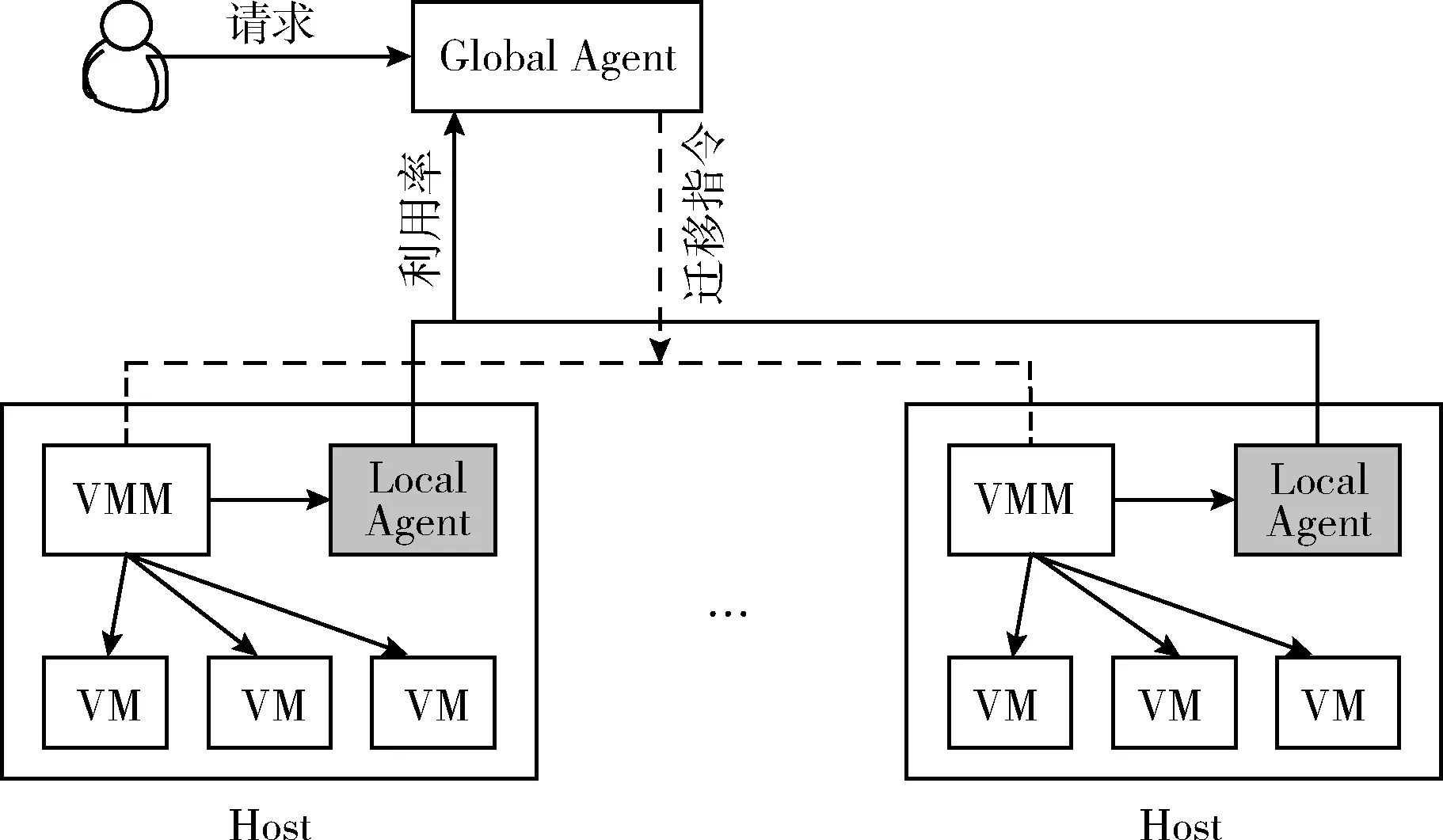
圖3 系統模型
(1)每個LA監測主機的資源利用率,并利用K最近鄰回歸預測主機短期的CPU利用率;
(2)GA收集LA的利用率數據,利用UP-BFD算法建立遷移計劃(算法詳細設計中描述);
(3)GA發送遷移指令至VMM,執行虛擬機合并任務。該指令指定了虛擬機的遷移目標主機;
(4)在接收GA的遷移指令后,VMM執行實際的虛擬機遷移。
4 UP-BFD算法的詳細設計
4.1 符號說明
初始時,虛擬機通過傳統的BFD算法將虛擬機分配至主機上。BFD算法首先根據資源利用率請求的降序序列將所有虛擬機進行排序,然后選擇每個虛擬機分配至一個主機上,使得主機擁有最少的剩余空閑能力。由于虛擬機的資源利用率會隨著時間發生變化,即動態負載,初始的虛擬機部署需要周期性地通過虛擬機合并算法進行不斷修正。為了實現該目的,本文設計了利用率預測感知的降序最佳適應算法UP-BFD,可以根據當前和未來的資源請求,優化虛擬機部署。為了方便算法設計的描述,表1給出相關參數說明。

表1 參數說明
4.2 負載計算與約束說明
為了降低數據中心能耗,UP-BFD算法通過釋放冷點的方式將最低負載主機(冷點)上的虛擬機遷移至負載最高主機(熱點)上。如果最冷點主機上的所有虛擬機無法遷移至其它主機上,則全部都不遷移。因此,未釋放冷點上的虛擬機遷移并不會實施,這樣可以消除不必要的虛擬機遷移。由于將一臺虛擬機分配至主機需要確定的主機資源量,有效的虛擬機合并算法必須感知資源維度,這意味著資源利用比例(CPU和內存資源)在決定虛擬機部署過程中就需要在每臺主機上予以確定。由于主機的CPU和內存能力是表示負載等級的主要因素,本文的算法也主要考慮CPU和內存利用率兩個資源維度。將主機負載定義為每個資源維度的總利用率,即
Lh=RCPU(h)+RMEM(h)
(1)
(2)
(3)
其中,RCPU(h) 定義為主機h上已經分配的CPU能力 (UCPU(h)) 除以主機的總體CPU能力 (CCPU(h)),RMEM(h)
定義為主機h上已經分配的內存能力 (UMEM(h)) 除以主機的總體內存能力 (CMEM(h))。
UP-BFD算法能夠決定主機上的哪些虛擬機需要遷移至其它主機上,算法會選擇主機上所有虛擬機中最高負載的虛擬機作為遷移目標,由于負載越大的虛擬機越難以插入至其它主機上。虛擬機v的負載Lv定義為
Lv=RCPU(v)+RMEM(v)
(4)
(5)
(6)
其中,RCPU(v) 和RMEM(v) 分別表示虛擬機v的CPU和內存利用率,UCPU(v) 和UMEM(v) 分別表示虛擬機v請求的CPU和內存利用率,CCPU(u) 和CMEM(v) 分別表示虛擬機的總體CPU和內存能力。
為了尋找遷移虛擬機的目標主機,UP-BFD算法使用兩種約束避免SLA違例和非必要的遷移。第一個約束是:若主機hd擁有足夠的資源部署虛擬機,則可允許虛擬機v遷移至主機hd。由于某些資源利用率可能達到100%而引起SLA違例的風險,算法引入門限值T限制主機上虛擬機的CPU資源請求量。因此,第一個約束條件可表示為
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(7)
第二個約束確保目標主機hd在虛擬機v遷移過來后不會變為短期可能的超載主機。考慮該原因,UP-BFD算法考慮了主機和虛擬機的未來CPU請求。UP-BFD算法利用K最近鄰回歸方法對CPU利用率進行預測,詳細過程見4.3節說明。由于負載的動態變化,UP-BFD算法將側重于短期的負載預測,以下資源能力約束用于將虛擬機v分配至主機h上
PUCPU(hd)+PUCPU(v)≤T×CCPU(hd)
(8)
其中,PUCPU(hd) 表示主機hd的預測CPU利用率,PUCPU(v) 表示虛擬機v的預測CPU利用率。主機和虛擬機的預測CPU利用率限制在總體能力的門限值以內。如果T=0.5,則表示主機hd和虛擬機的總體預測利用率不能超過總體能力的50%。因此,基于以上兩個約束條件,算法在選擇目標主機時,需要該主機在當前時刻以及未來均擁有足夠的可用資源。
此外,UP-BFD算法還需要從超載和可預測超載主機上遷移部分虛擬機以降低SLA違例。如果當前CPU利用率超過主機能力,則該主機可視為超載主機集合Hover中的成員。因此,部分虛擬機需要從該超載主機上遷移至其它主機以降低SLA違例可能。此外,UP-BFD算法可以根據主機的預測CPU利用率預測到主機何時會成為超載主機。若預測利用率大于可用CPU能力,則該主機可視為預測超載主機集合Hover’中的成員。因此,部分虛擬機也需要從預測超載主機上遷移出去以降低SLA違例。
4.3 基于K最近鄰回歸的負載預測
負載預測過程分為兩個步驟:第一步是確定近鄰樣本的最優k值;第二步是基于最優k值和樣本數據對CPU利用率進行預測。算法1給出最優k值的求解過程。算法輸入m個樣本的歷史利用率數據集X,對于每一個可能的k值(步驟(3)),先將該k值的預測損失值初始化為0,即步驟(4)。然后,遍歷m個樣本數據(步驟(5)),數據集中所選樣本作為測試樣本,剩余樣本用于訓練數據集,即步驟(6)~步驟(7)。然后,調用算法2,基于當前的k值、測試樣本和訓練數據集,預測在當前測試樣本下的利用率,即步驟(8)。預測準確度通過每個k值的損失值的總和進行評估,即步驟(9)。遍歷所有可能k值和所有樣本,擁有最小損失值的k值被選擇為k最近鄰回歸模型的最優k值,如步驟(12)。最后,可以在步驟(13)~步驟(14)根據所選最優k個最近鄰樣本預測最終的資源利用率。
算法1: KNN-UP算法
(1)Input:datasetXwithmsamples
(2)Output:predictedUtil
(3)fork=1 tomdo
(4)loss[k]←0
(5)fori=1 tomdo
(6)TestSample←xi//選取測試樣本
(7)TrainingDataset←X-{xi}//選取訓練樣本
(8)yi’←KNN(TestSample,TrainingDataset,k)
(9)loss[k]←loss[k]+power((yi’-yi),2)
(10)endfor
(11)endfor
(12)kbest←argminkloss[k]//得到最優k值
(13)predictedUtil←KNN(currentUtil(host),kbest)
(14)returnpredictedUtil
算法2的目標是根據當前已有的訓練數據集、當前k個最近鄰數據和樣本序列預測下一個CPU利用率,算法總共分3步進行。第一步計算樣本xq與訓練集中其它所有樣本間的歐氏距離,即步驟(3)~步驟(8),第二步選擇樣本xq的k個最近鄰數據,即步驟(10)~步驟(12),最后第三步通過計算其k個最近鄰的均值估算CPU資源利用率,即步驟(13)~步驟(17)。
算法2: KNN算法
(1)Input:query-samplexq, training dataset, number of nearest neighborsk
(2)Output:the label of samplexq(y’)
(3)forj=1 tomdo//步驟(1)
(4)distance[j] ←0
(5)fori=1 tondo
(6)distance[j]←distance[j]+(xqi-xji)2
(7)endfor
(8)distance[j]←sqrt(distance[j])
(9)//sort distance array
(10)fori=1 tokdo//步驟(2)
(11)nearestSet[i]=distance[i]
(12)endfor
(13)sum←0//步驟(3)
(14)forallz∈nearestSetdo
(15)sum←sum+yz
(16)y’ ←sum/k
(17)returny’
4.4 UP-BFD算法過程
算法3給出了UP-BFD算法實現的詳細過程,由兩個階段組成:①嘗試從最低負載主機上遷移所有虛擬機,并關閉該主機以節省能耗;②從超載和預測超載主機上遷移部分虛擬機以降低SLA違例。在第一個階段中,即步驟(2) ~步驟(21),步驟(2)根據負載等級的降序對主機進行排序,并將排序后的主機存入列表H中。UP-BFD算法將H中最后一個主機(最低負載主機)考慮為源主機hs(步驟(3)),遷移其上所有虛擬機并釋放hs。為了選擇從主機hs上需要遷移的第一個虛擬機,算法將主機hs上的所有虛擬機根據負載降序進行排列,并將排列后的虛擬機存入列表Vm中(步驟(4))。為了尋找遷移虛擬機的合適目標主機,UP-BFD算法從H中除了源主機hs以外的第一個主機(擁有最高的負載)依次掃描,直到找到第一個能滿足遷移需求的主機為止,即步驟(5)~步驟(7)。UP-BFD算法選擇目標主機hd需要滿足在當前和短期未來遷移虛擬機的資源請求,即步驟(8)。最后,新的虛擬機部署被添加至遷移決策M,即步驟(9)。遷移計劃為一個三元組 (hs;v;hd),hs為源主機,v為遷移虛擬機,hd為目標主機。步驟(10)對源和目標主機的已經利用CPU利用率進行更新,以反映出遷移后的結果。變量success用于檢測是否源主機上的所有虛擬機已被遷移。僅在所有虛擬機能夠遷移的情況下才作出遷移決策,否則不作遷移。因此,如果success為失效,算法將移出遷移計劃中的所有元組元素并恢復源主機和目標主機的CPU能力,即步驟(16)~步驟(18)所示;否則,源主機上的所有虛擬機遷移后,該主機將轉換為休眠,不再部署任何虛擬機,即步驟(20)。
在第二個階段,步驟(22)~步驟(40)中,算法首先遍歷超載和預測超載主機列表,步驟(23)~步驟(24)根據負載等級的降序對主機上的虛擬機進行排列,并開始遷移請求最大能力的虛擬機。當前CPU利用率或預測CPU利用率超過主機總體能力時,虛擬機v需要遷移至其它主機,即步驟(25)。然后,算法基于兩個約束條件尋找遷移虛擬機v的目標主機,即步驟(27)。最后,新的虛擬機部署被添加至遷移計劃M中,即步驟(28)。如果算法在所有活躍主機中無法找到部署遷移虛擬機的目標主機,則重新開啟一臺休眠主機,即步驟(33)~步驟(35)。UP-BFD算法的輸出為遷移計劃M,GA將發送遷移計劃指令至虛擬機監視器VMM執行具體虛擬機遷移。
算法3: UP-BFD算法
(1)M=NULL
(2)H←sort all hosts in descending loadLh
(3)hs←last host inH
(4)Vm←sort VMs on hosthsin descending loadLv
(5)forv∈Vmdo
(6)success=false
(7)forhd∈H-hsdo
(8)if(UCPU(hd)+UCPU(v)≤T×CCPU(hd)) and (PUCPU(hd)+PUCPU(v)≤T×CCPU(hd))then
(9)M=M∪{(hs,v,hd)}
(10) updateUCPU(hs) andUCPU(hd)
(11)success=true
(12)break
(13)endif
(14)endfor
(15)endfor
(16)ifsuccess=falsethen
(17)M=NULL
(18) recoverUCPU(hs) andUCPU(hd)
(19)else
(20) switchhsto the sleep mode
(21)endif
(22)forhs∈[Hover,Hover’]do
(23)Vm←sort VMs on hosthsin descending loadLv
(24)forv∈Vmdo
(25)if((UCPU(hs)≥CCPU(hs))‖(PUCPU(hs)≥CCPU(hs))then
(26)forhd∈H-[Hover,Hover’]do
(27)if(UCPU(hd)+UCPU(v)≤T×CCPU(hd)) and (PUCPU(hd)+PUCPU(v)≤T×CCPU(hd))then
(28)M=M∪{(hs,v,hd)}
(29) updateUCPU(hs) andUCPU(hd)
(30)break
(31)endif
(32)endfor
(33)if((UCPU(h)≥CCPU(h))‖(PUCPU(h)≥CCPU(h))then
(34) switch on a dormant host
(35)endif
(36)else
(37)break
(38)endif
(39)endfor
(40)endfor
5 性能評估
5.1 實驗環境
為了評估動態虛擬機合并算法UP-BFD的性能,利用仿真平臺CloudSim[13]實現了高能效的虛擬機合并算法。仿真環境中,構建由800臺異構主機組成的云數據中心,選擇平臺支持的具有代表性的兩種主機配置:HP ProLiant ML110 G4(Intel Xeon 3040,2cores×1860 MHz,4 GB)和HP ProLiant ML110 G5(Intel Xeon 3075,2cores×2660 MHz,4 GB)。每臺服務器主機的網絡帶寬設置為1 GB/s。虛擬機數量由負載類型決定,實驗中測試了兩種類型負載:隨機型負載和現實負載。隨機型負載中,用戶發送800個異構虛擬機請求,每臺虛擬機運行一種應用負載,應用負載對于CPU的占用服從均勻分布。現實負載中,選擇CoMon工程項目中一個時間段內的負載數據,見表2,該數據由PlanetLab平臺[14]監測得到。監測數據中,CPU利用率數據是從多于一千臺虛擬機上每隔5 min監測得到的結果。虛擬機部署于全球超過500個地理位置,這也是較為典型的Amazon EC2式的基礎設施云服務環境下的負載類型。
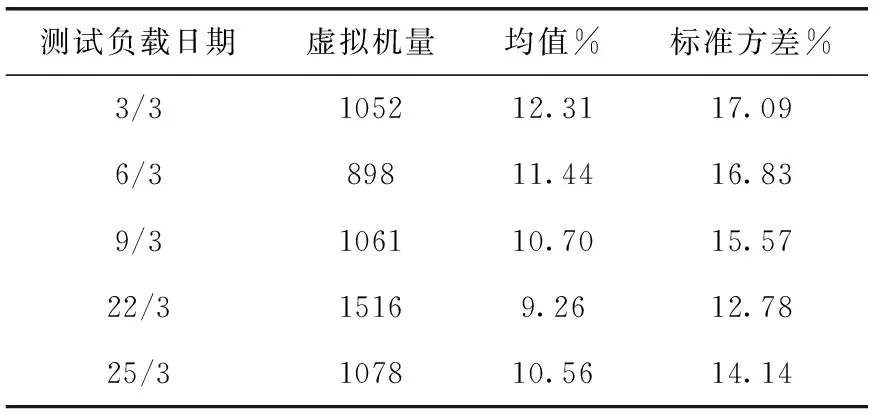
表2 現實負載的虛擬機請求量
5.2 評估指標及時間復雜度分析
(1)SLA違例SLAV指標。SLAV是一種獨立的負載指標,用于評估虛擬機部署中SLA的交付情況。SLAV包括主機超載導致的SLA違例SLAVO和由于遷移導致的SLA違例SLAVM。對于云環境中的虛擬機合并問題而言,兩種SLA違例具有同等的重要性,因此,綜合的SLA違例指標可考慮為兩個參數的乘積,表示為
SLAV=SLAVO×SLAVM
(9)
其中,SLAVO表示活躍主機經歷CPU利用率100%所占的時間比例,表示為
(10)
其中,M表示主機數量,Tsi表示主機i經歷的CPU利用率100%(導致SLA違例)的總時間,Tai表示主機i活躍狀態的總時間。
SLAVM表示由遷移導致的虛擬機性能下降,度量為
(11)
其中,N表示虛擬機數量,Cdj表示由于遷移導致的虛擬機j性能下降的估算,Crj表示整個周期中虛擬機j的總CPU請求量。
(2)能耗指標。該指標表示數據中心中物理主機執行負載消耗的總體能耗。主機能耗取決于CPU、內存、存儲及網絡帶寬的利用率。研究表明,相比其它資源類型,CPU消耗了最多能源。因此,簡化能耗模型后,主機能耗可表示為其CPU利用率的關系式。實驗中根據SPECpower試驗床[15]中現實的功耗數據。表3給出了在不同的負載條件下兩類主機HP G4和HP G5的功耗情況。

表3 不同負載條件下主機的功耗/W
(3)虛擬機遷移量。在線虛擬機遷移涉及在源主機上的CPU處理、源和目標主機間的鏈路帶寬以及遷移時的服務停機、遷移時間等多重代價,因此,虛擬機合并過程中需要最小化虛擬機遷移量。
算法時間復雜度分析。UP-BFD算法的實現由兩個階段構成,第一階段嘗試從最低負載主機上遷移所有虛擬機,第二階段從超載和預測超載主機上遷移部分虛擬機。假設M為主機數量,N為虛擬機數量。第一階段最差情況下需要遍歷所有主機上的所有虛擬機,故其時間復雜度為O(M×N)。 第二階段同樣需要遍歷超載和預測超載主機上的虛擬機,預測超載過程利用K最近鄰回歸預測方法KNN,而此時KNN的最差時間復雜度為O(M×N)。 綜上,UP-BFD算法的時間復雜度為O(M×N+M×N)=O(M×N)。
5.3 比較基準
完成以下啟發式算法與本文的虛擬機動態合并算法UP-BFD進行對比分析:
(1)改進降序最佳適應算法MBFD。該算法利用一個門限值限定目標主機的CPU利用率,在虛擬機和主機所利用的總CPU能力不超過總體CPU能力的情況下,部署遷移虛擬機至擁有最小剩余能力的主機上,即
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(12)
(2)改進降序首次適應算法MFFD。該算法將遷移虛擬機分配至滿足資源需求且不超過CPU能力約束的第一臺主機上,即
UCPU(hd)+UCPU(v)≤T×CCPU(hd)
(13)
(3)主機資源利用率預測的降序最佳適應算法HUP-BFD。該算法通過K最近鄰回歸預測了主機的資源請求。算法利用預測模型和門限值T限定主機利用率。若預測主機利用率與虛擬機請求的CPU利用率不超過總的CPU利用率,則將虛擬機v遷移至目標主機hd,即
PUCPU(hd)+UCPU(v)≤T×CCPU(hd)
(14)
(4)虛擬機資源利用率預測的降序最佳適應算法VMUP-BFD。該算法通過K最近鄰回歸預測虛擬機的資源請求。若主機CPU利用率與預測虛擬機請求CPU利用率不超過總CPU利用率,則將虛擬機v遷移至主機hd,即
UCPU(hd)+PUCPU(v)≤T×CCPU(hd)
(15)
5.4 結果分析
第一個實驗中,通過均勻分布的隨機負載進行實驗。較高的CPU利用率門限值會導致較高的性能下降和虛擬機遷移量,而較低的門限值會導致更高的能耗。因此,為了考慮多個指標系數間的均衡優化,需要尋找一個合適的門限值。實驗中設置門限值在50%-100%之間以觀察資源利用門限值對于性能指標的影響。圖4是在不同的門限值下,5種算法的SLA違例情況。UP-BFD算法比其它算法可以有效降低SLA違例比率,這是由于算法會將遷移虛擬機重新部署至短期未來不會變為超載的主機上,而不是僅考慮主機當前時刻不是超載,這說明K最近鄰回歸預測是有效可行的。此外,UP-BFD算法可以從當前超載和預測超載主機上進行虛擬機遷移,前瞻性地避免了SLA違例機會。圖5顯示本文提出的UP-BFD算法能夠比其它算法總體降低約28%的能耗,這是由于該算法可以通過將虛擬機裝箱至高負載主機上的方式最小化活躍主機數量,進而優化了能耗。圖6顯示了隨機負載條件下虛擬機合并過程中出現的虛擬機遷移量。UP-BFD算法由于更好的資源利用預測,比對比算法更好減少了虛擬機遷移量。
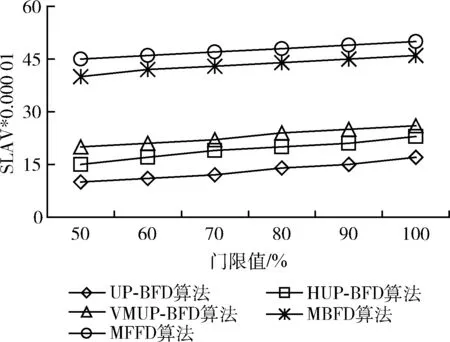
圖4 隨機負載下的SLA違例
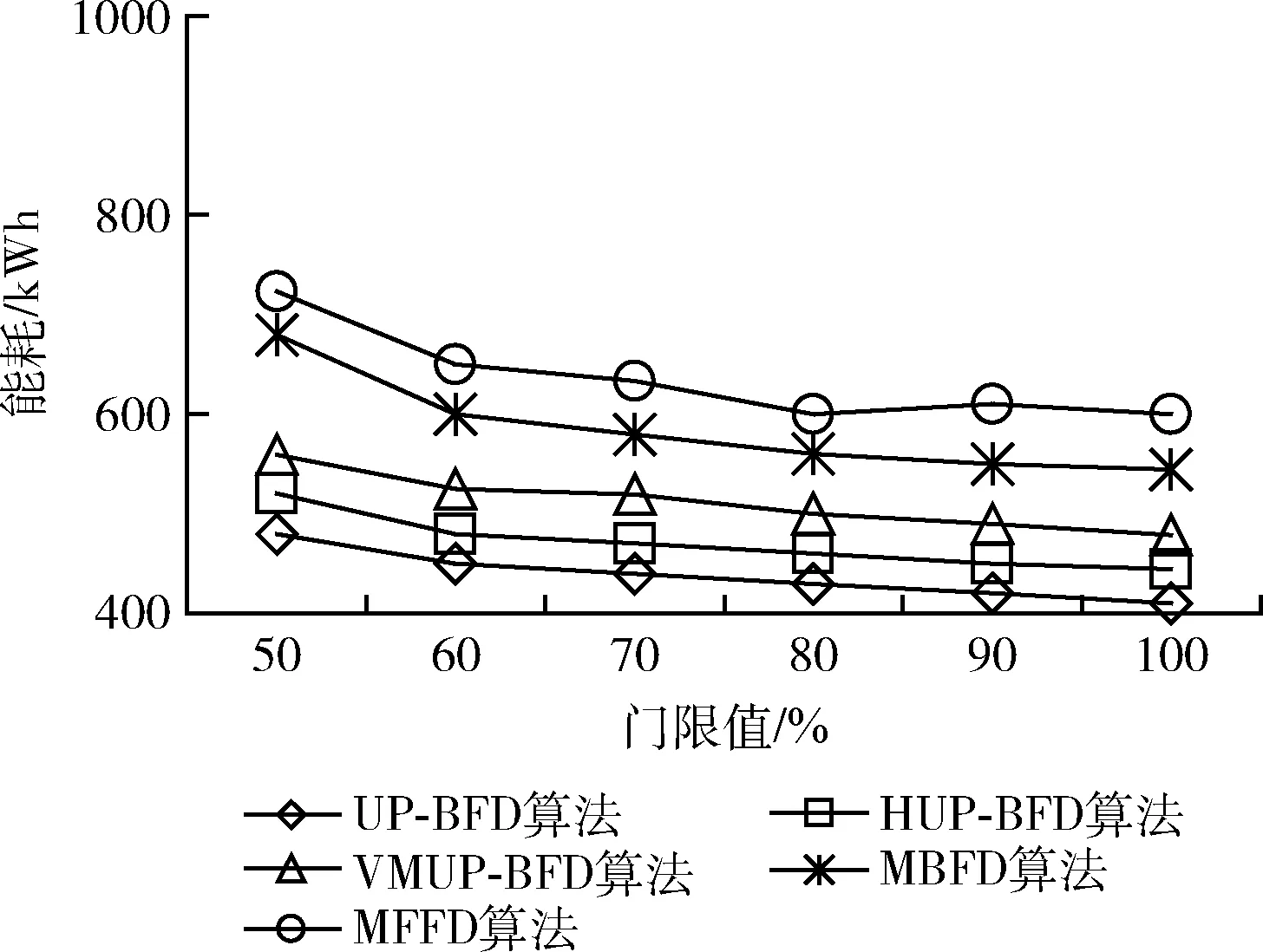
圖5 隨機負載下的能耗
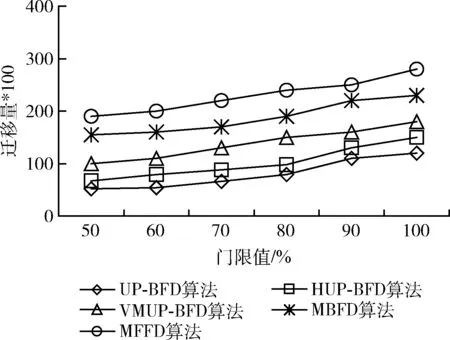
圖6 隨機負載下的虛擬機遷移量
第二個實驗運行現實負載對算法性能進行評估。實驗中每臺虛擬機上隨機分配一個負載流。圖7顯示UP-BFD算法比4種對比算法具有更低的SLA違例,這是由于UP-BFD算法通過主機和虛擬機的資源利用預測可以防止SLA的違例,確保了遷移的目標主機在虛擬機遷移后不會再次變為超載主機。圖8顯示UP-BFD算法在現實負載下比其它算法也節省了更多的能耗,這是由于該算法通過裝箱虛擬機至更少量主機上,并釋放了最低載主機,降低了能耗。同樣地,在圖9中,本文的UP-BFD算法也擁有最少的虛擬機遷移量,這是由于算法可以根據未來的資源利用率將遷移虛擬機進行重新部署,而大大降低了目標主機最次出現超載的概率,帶來不必要遷移的可能。
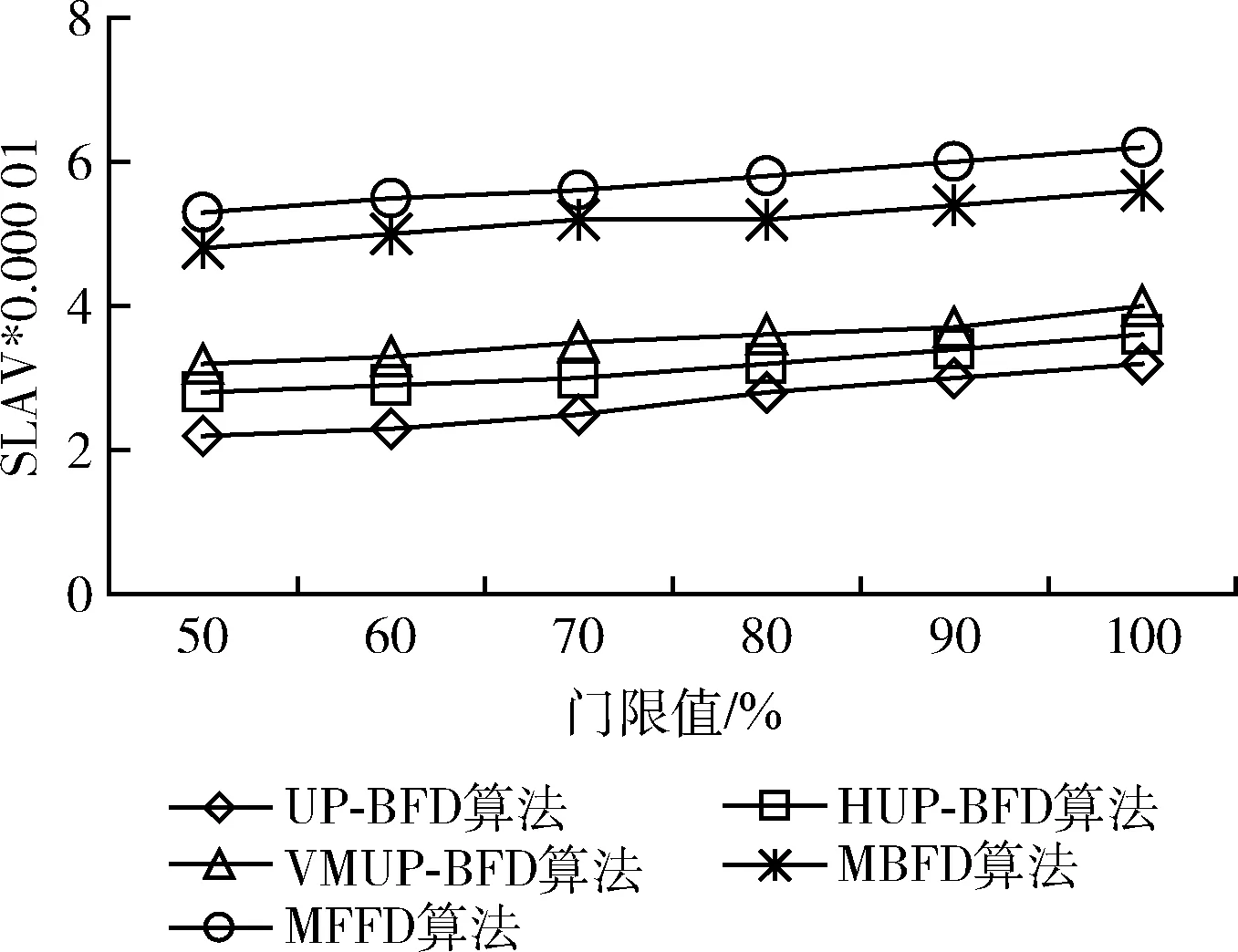
圖7 現實負載下的SLA違例
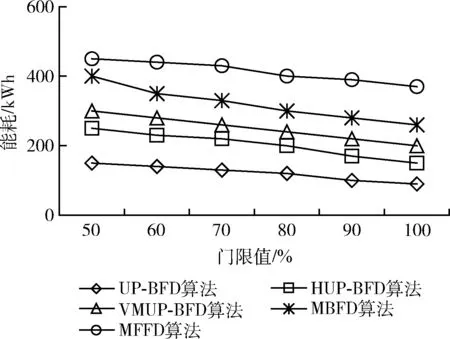
圖8 現實負載下的能耗
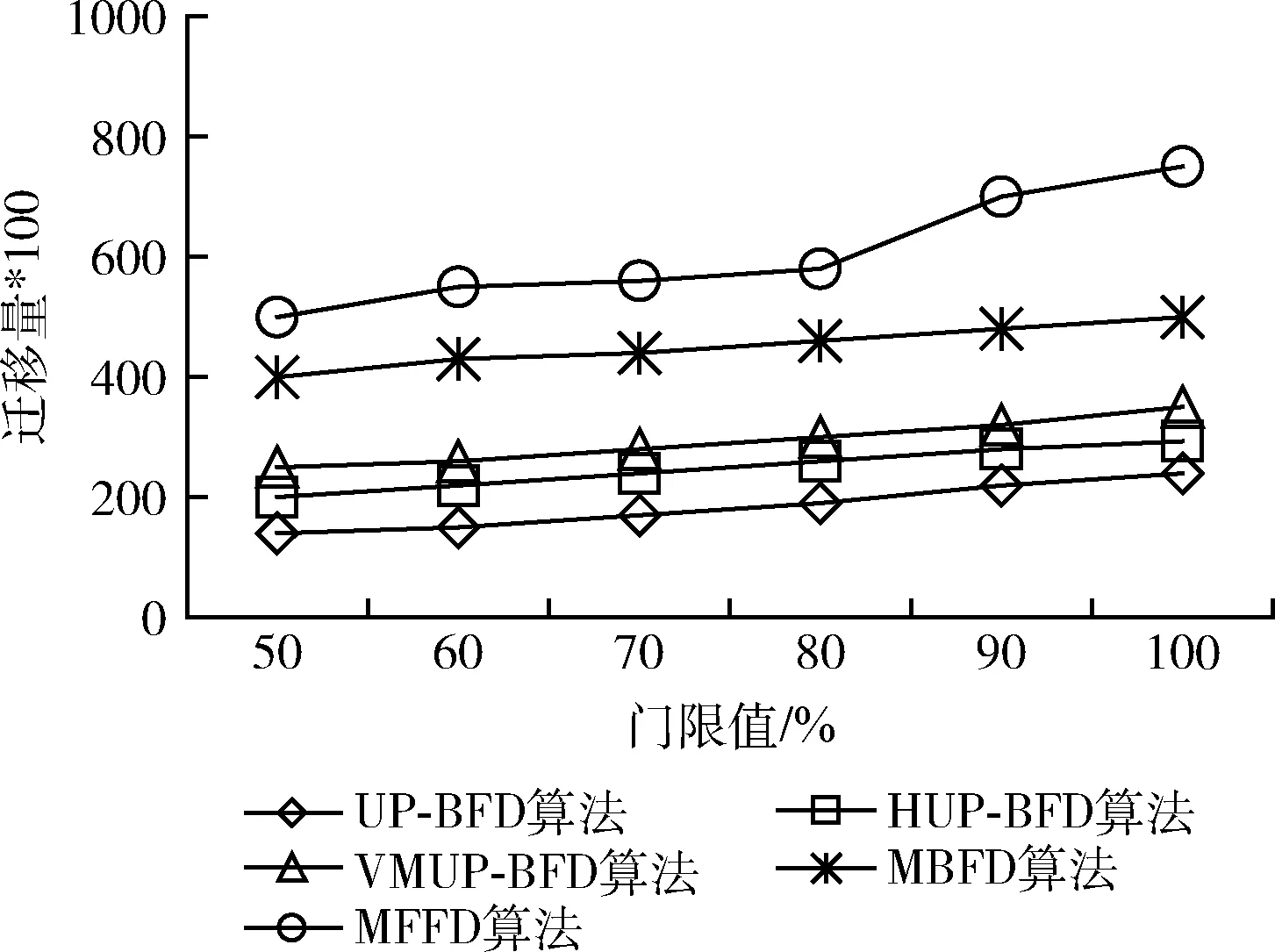
圖9 現實負載下的虛擬機遷移量
綜合兩個實驗結果來看,本文算法在實現虛擬機合并過程中較好實現了能耗與SLA違例間的均衡。同時,若門限值取值較大,虛擬機遷移量和SLA違例會有所提高,但UP-BFD算法在門限值接近于100%時仍然完成了更好的能耗節省。
6 結束語
云數據中心中,動態的虛擬機合并和遷移雖然可以有效降低能耗和提高資源利用率。然而,若僅考慮當前資源利用率會帶來許多非必要的虛擬機遷移,增加SLA違例風險。提出了一種動態的虛擬機合并算法,算法可以通過K最近鄰回歸方法預測主機和虛擬機的資源利用率,從而減少非必要的虛擬機遷移,并降低SLA違例風險。在虛擬機遷移選擇上,算法可以通過預測模型從當前的超載和預測超載主機上進行虛擬機遷移。通過大規模的仿真實驗對比,驗證所提算法不僅可以降低主機能耗,還可以同步最小化SLA違例和虛擬機遷移量。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
