圖嵌入算法的分布式優化與實現?
2021-05-23 13:16:28張文濤張智鵬
軟件學報 2021年3期
張文濤,苑 斌,張智鵬,崔 斌
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(騰訊科技(北京)有限公司數據平臺部,北京 100193)
圖數據在現實生活中普遍存在,例如社交網絡、交通網絡、電商網絡等等.隨著人工智能時代的到來,研究人員開始越來越多地使用機器學習技術挖掘圖上的信息[1?3],例如圖嵌入(graph embedding)技術.另外,隨著數據來源的增加,例如電商、傳媒、社區、論壇等,人們所面臨的數據規模也在不斷增加.據統計,谷歌與臉書的數據已經達到PB 量級,每日數據增加量可達幾十到幾千TB.因此,在這種環境下,對大數據的處理與迭代能力顯得極為重要.
在這種大數據和機器學習的雙重背景下,大規模的圖嵌入算法也越來越受到人們的關注與重視.伴隨著人們對業務場景時間要求的緊迫性與互聯網提供服務的及時性,研究分布式圖嵌入算法的性能優化也是當下的趨勢.開發高效、大規模的分布式圖嵌入系統需要考慮通用性和高效性兩個方面.
? 通用性:目前,研究人員針對不同的場景開發了各種各樣的圖嵌入算法.在進行圖嵌入算法的選擇時,往往需要互相比較,互相借鑒,選擇最適用當前場景的算法進行使用.另外,在開發新算法的同時,需要更多地考慮如何進行改進采樣的部分,以適應更好的業務需求.針對以上需求,需要對現有的算法進行總結與歸納,通過抽象,將采樣模塊暴露給用戶,并透明化后續訓練模塊,需要支持后續算法更好的可擴展性,需要讓算法的更新與維護變得更加方便快捷;
? 高效性:互聯網線上場景的需求需要算法的及時更新與快速迭代,往往對訓練時間提出了更緊迫的要求,因此需要更好的分布式策略作為支撐[4,5].此外,工業界的集群數目眾多,機器數目多達幾千臺,在這種集群規模下,需要更好的可擴展性.目前,在工業界針對圖嵌入算法有兩種主流的分布式策略:一種為圖簡易嵌入分布式策略,另一種為圖點積嵌入分布式策略.其中:圖點積嵌入分布式策略缺乏良好的可擴展性(scalability),而圖簡易嵌入分布式策略具有性能瓶頸,需要進一步地優化方案.
為了解決以上兩個挑戰,本文首先總結了目前基于隨機游走的算法和其他類型的一部分算法,包括深度游走算法(DeepWalk)[6]、大規模信息網絡嵌入算法(LINE)[7]、非對稱性臨近可擴展圖嵌入算法(APP)[8]、圖節點向量算法(Node2Vec)[9]等.筆者發現:利用點對描述進行圖嵌入表示的輸入是一種良好的抽象,這種抽象能夠與目前的主流詞向量[10]與負采樣[11]模型完美兼容,并基于此提出了基于高性能高可復用性的分布式框架.該框架目前支持DeepWalk,LINE,APP 這3 種采樣算法,并且在對后續算法的更新上起到很好的支持作用.另外,筆者針對參數服務器上的分布式實現提供了性能優化的策略,對已有的兩種在Angel[12,13]上實現的工業界級別的分布式策略進行了詳細的分析(此外,高維度圖計算平臺還有AliGraph[14]).提出了一種模型劃分的策略,支持更好的可擴展性.
本文的貢獻可以概括如下:對目前多種圖嵌入算法進行了抽象,通過將采樣和訓練兩部分解耦,提出了一套高可復用性的圖嵌入框架;通過對已有兩種分布式策略實現的分析,發現這兩種策略在擴展性上表現不足,進而提出了一種基于圖分割嵌入分布式策略;實現了一套分布式圖嵌入算法的原型系統,并用充分的實驗證明了圖分割嵌入分布式策略的高效性.
本文第1 節介紹相關工作.第2 節介紹高可復用性的圖嵌入框架.第3 節介紹圖分割嵌入式策略.第4 節介紹實驗結果.最后,第5 節總結全文.
1 相關工作
深度游走算法是圖嵌入算法中較早提出來的基于隨機游走的算法,其借鑒了詞向量算法.首先選擇某一特定點為起始頂點,通過深度優先搜索或者寬度優先搜索得到圖的序列;再將該序列送入詞向量算法進行學習,得到該點的表示向量.DeepWalk 算法解決了兩大問題:(1)隨機游走采樣節點的序列,形成圖節點序列;(2)利用Skip-gram[15]算法結合負采樣進行圖節點向量的計算.
非對稱臨近可擴展性圖嵌入(scalable graph embedding for asymmetric proximity)提出一種保留圖的非對稱結構的基于隨機游走的圖嵌入方法,并通過理論推導證明了該嵌入式方法保留了根網絡排名(rooted pagerank)值,DeepWalk 算法和節點向量算法都無法保留圖的非對稱性結構(有向圖和無向圖).
LINE 是圖嵌入算法中較常用的算法,其適用任意類型的信息網絡、無向圖、有向圖、無權圖、有權圖等,優化了目標函數,使得其能夠保留局部和全局網絡結構.LINE 還提出了邊緣采樣算法,解決了經典隨機梯度下降的局限性,提高了算法的效率和有效性.
分布式的圖嵌入算法利用參數服務器[16?19]進行實現,目前在工業界的應用有兩種:一種為圖簡易嵌入分布式策略,另一種為圖點積嵌入分布式策略.兩種策略將在第3 節詳細說明.
2 高可復用的圖嵌入框架
2.1 已有圖嵌入算法分析
圖嵌入算法很多,例如DeepWalk、LINE、APP、節點向量算法等.其原始訓練流程如圖1 所示,以3 種算法為例,其采樣算法模塊與后續訓練模塊相互耦合,從而導致代碼復用性差,重復度高.
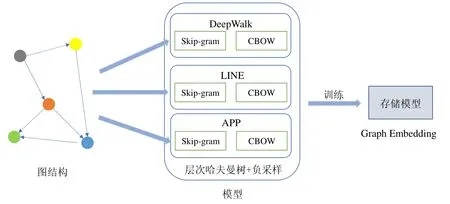
Fig.1 The original training process圖1 原始訓練流程
DeepWalk 基于圖上的隨機游走進行采樣,生成一系列的序列信息,利用采樣得到的序列信息進行圖嵌入算法的訓練.LINE 采用的采樣算法與DeepWalk 截然不同,其收集邊信息,利用每條邊直接生成點對信息,利用邊信息進行訓練.而APP 的計算過程來源于網頁排名值,在網頁排名值中會設定一個停留率(stoprate),通過制造隨機數與停留率進行比較,來決定當前頁面是否停留,收集起始點與終點從而生成點對信息.
得到點對信息后,進入模型訓練的流程.在訓練時,采用對損失函數進行求導.通用的損失函數結合負采樣算法,通過隨機梯度下降法對模型進行更新,其模型主要包括兩個部分:第一部分為圖節點向量,第二部分為負采樣節點向量.
我們發現:在上述這3 個算法過程中,均能夠生成點對的信息,接下來可以統一利用點對的信息進行計算.因此,可以將基于詞向量與負采樣模型的圖嵌入算法歸納出先采樣后訓練的模式,從而將采樣邏輯協同訓練邏輯相互獨立,對訓練的邏輯進行單獨的優化,形成單獨的模塊.一般新算法的提出往往是在采樣的模塊進行更改,優化的模塊對于用戶是透明的,用戶只需要修改采樣的代碼即可完成新算法的修改.
2.2 高可復用的分布式圖嵌入框架
基于上文中的分析,筆者構建了一種基于采樣的框架,將各種圖嵌入的算法進行統一,提出一個高可復用的分布式圖嵌入框架.
如圖2 所示,算法的流程是:首先輸入為原始圖,以邊為單位,通過處理原始圖,利用不同算法進行采樣,將這些采樣信息處理為Skip-gram 能夠接受的格式,即點對信息.在Skip-gram 與負采樣訓練過程中,其輸入是處理完畢的點對信息,將這些點對分成批次進行訓練,每一次訓練均通過隨機梯度下降算法收斂得到最后模型.結合圖3 介紹高可用的分布式圖嵌入框架.
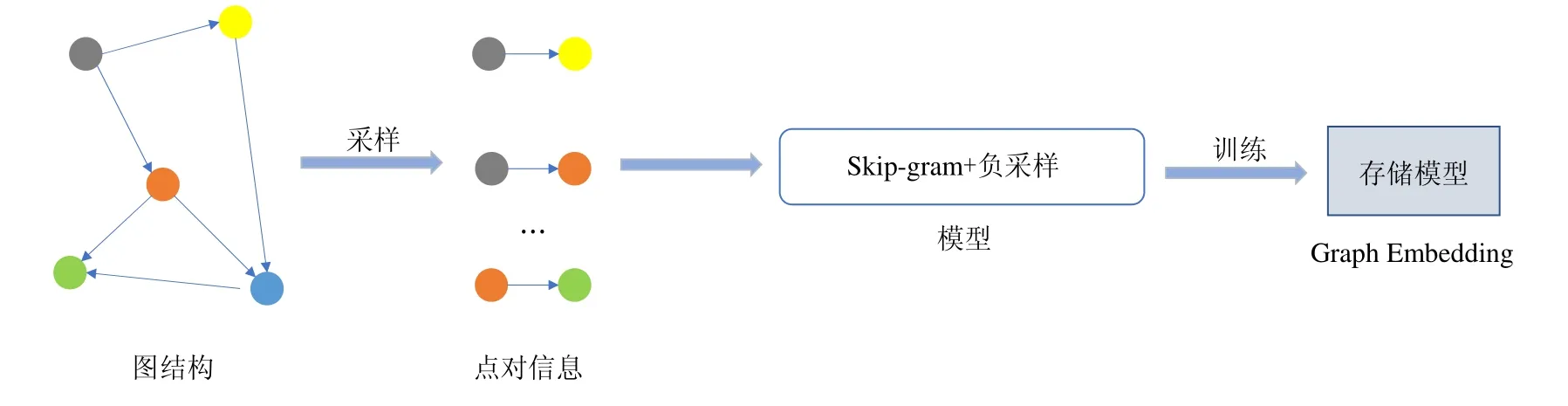
Fig.2 The training process of single-machine圖2 單機訓練流程

Fig.3 The distributed training framework圖3 分布式訓練框架
分布式的訓練流程主要分為兩個部分:第一部分為采樣流程,第二部分為訓練部分.采樣流程和訓練流程均與單機不同,接下來介紹這兩個部分.
? 采樣流程:數據輸入為一張圖,在圖上會運行一些采樣算法,通過分布式的機制進行采樣.實際原理是將其轉化為Spark[20]上的RDD 算子運算,通過將數據分發給不同的運算節點來處理得到結果,減少采樣時間;
? 訓練流程:在分布式訓練模塊中,輸入為點對信息,不同策略對點對信息進行分組,放置在不同計算節點上.計算節點拿取到點對信息后,會分批次進行分布式訓練.通過在參數服務器上放置模型位置的不同,可將分布式策略分為兩種:一種在參數服務器上存儲所有模型,另一種在參數服務器與計算節點同時存儲模型.在參數服務器上存儲所有模型有兩種:圖簡易嵌入分布式策略和圖點積嵌入分布式策略,這兩種策略是目前業界常見的實現策略.
以深度游走為例,其采用深度優先遍歷的方式,從某個節點出發,通過多次深度優先游走記錄下節點遍歷的路徑,從而將路徑轉化為一條序列.這種做法稱之為采樣.采樣得到的序列再經過SKIP-GRAM 的格式變化之后,可以處理為點對信息.在輸入采樣算法具有相似的目標函數的作用下,分布式訓練可以獨立于采樣算法本身,性能優化交給分布式訓練的模塊,訓練模塊只需顧忌自身的訓練性能以及收斂精度即可.完成最終的模型訓練,與原先的算法得到同樣好的收斂結果.
最終的框架具有良好的可擴展性,解除了算法采樣與訓練之間的耦合關系,使得該框架成為一種高度內聚的實現.當有新的算法加入時,只需要將其采樣的部分改寫為框架所支持的代碼即可.大多數的算法往往會在采樣上做出新的調整,而訓練的損失函數變動不大.當目標函數與框架不同時,只需要對分布式的訓練模塊進行簡單的處理,通過繼承或者接口注入的方式改寫目標函數相對應的類即可,用戶無需對新的算法進行大量的調參,也無需對其進行分布式上網絡通信的優化(如圖4 所示).
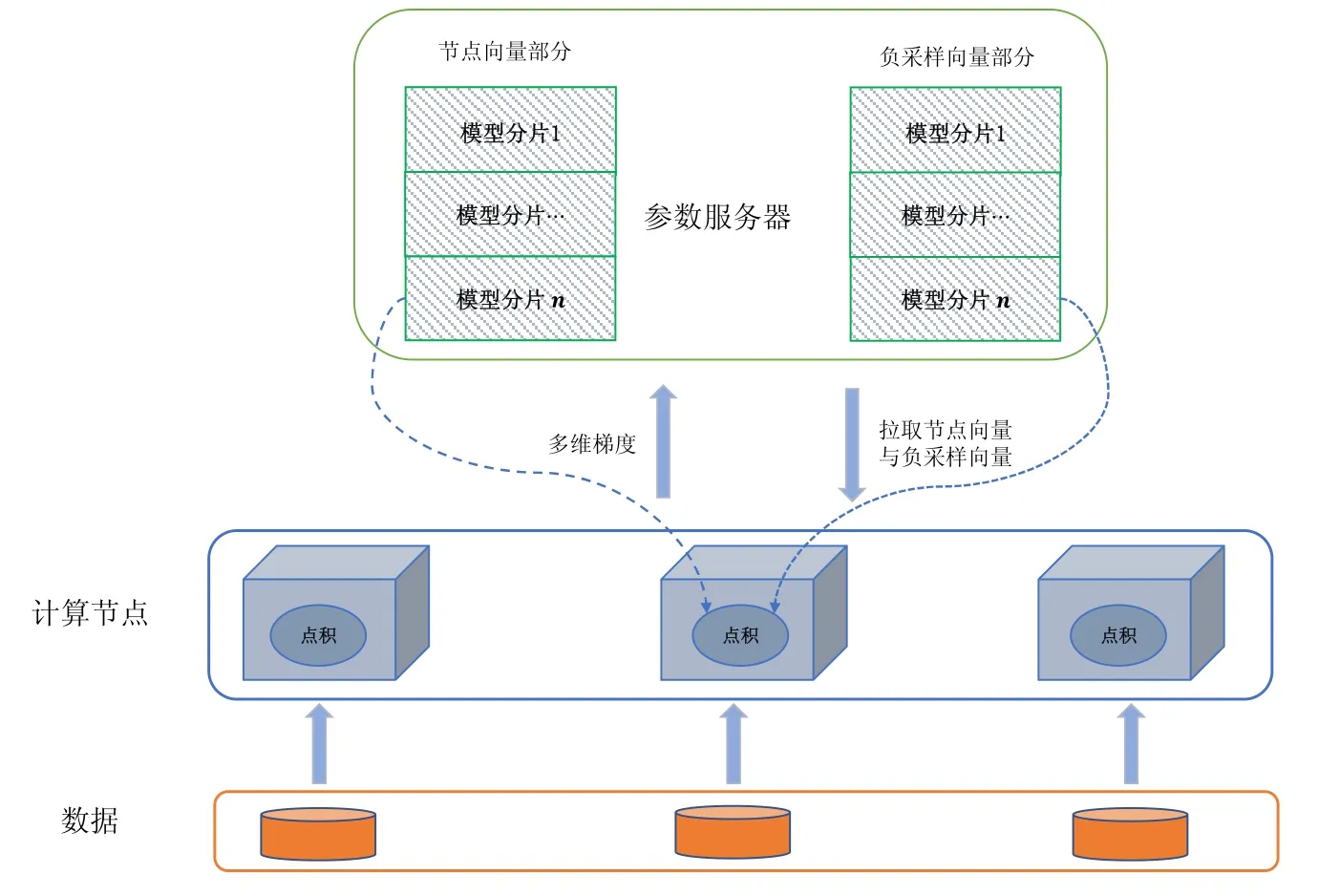
Fig.4 The distributed execution process of the simple graph embedding strategy圖4 圖簡易嵌入分布式策略的執行流程
3 基于高性能的分布式解決方案
3.1 已有的分布式策略分析
目前,工業界已有兩種很常見的分布式實現策略,它們都是在參數服務器上存儲所有模型.根據在計算節點和參數服務器上點積的不同運算方式,可以分為圖簡易嵌入分布式策略與圖點積嵌入分布式策略:圖點積嵌入分布式策略缺乏良好的可擴展性;而圖簡易嵌入分布式策略具有性能瓶,需要進一步的優化方案.本節簡要介紹這兩種常用的分布式策略.
3.1.1 圖簡易嵌入分布式策略
? 數據與模型存儲
圖簡易嵌入分布式策略將點對數據獨立劃分在分布式文件系統[21]上,利用參數服務器進行節點向量與負采樣向量模型的存儲.每個點的嵌入信息完全存放在一臺機器上,不存在單點嵌入的切割,這里與圖點積嵌入分布式策略加以區分.圖簡易嵌入分布式策略與圖點積嵌入分布式策略的執行流程分別如圖4 和圖5 所示.
? 訓練流程
步驟1.圖簡易嵌入分布式策略進行本地的數據讀取,得到需要參與計算的模型索引,模型索引即為每個圖頂點的索引值.預先對模型索引進行挑選,選取需要用到嵌入信息的頂點.在第2 步中,拉取只需拉取需要的模型向量;
步驟2.根據這些模型索引,從參數服務器上拉取需要的模型.只有部分模型需要參與一個批次的計算,參與計算的模型索引在步驟1 中計算完畢,需要拉取的模型參數為節點向量模型與負采樣向量模型的部分模型,通信開銷為O(2mD),m為每一個批次下參與計算的獨立節點個數(去除重復節點之后的結果);
步驟3.圖簡易嵌入分布式策略利用Skip-gram 中的損失函數進行求導,進行梯度的計算,這里需要涉及到節點向量和負采樣向量兩個模型,采用的算法統一為負采樣.
步驟4.計算完畢之后,將梯度傳遞回參數服務器.因為節點向量和負采樣向量均需要傳遞D維度的參數,因此這里的通信開銷是O(2mD).模型在參數服務器的更新采用的是累加的模式.
總通信開銷為拉取與推送這兩個操作帶來的模型傳輸和梯度傳輸,一個批次下需要的通信量為O(4mD).
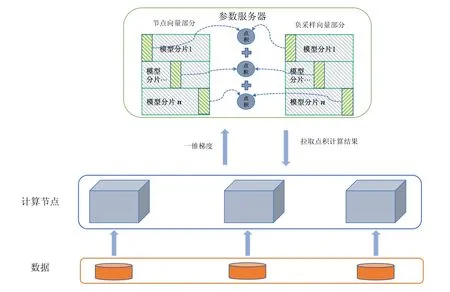
Fig.5 The distributed execution process of the dotted graph embedding strategy圖5 圖點積嵌入分布式策略執行流程
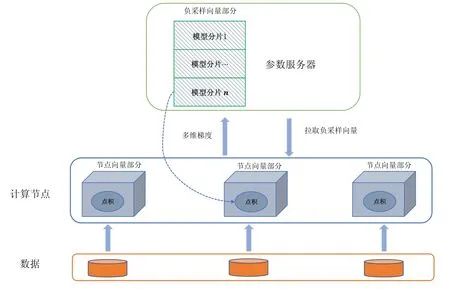
Fig.6 The distributed execution process of the partitioned graph embedding strategy圖6 圖分割嵌入分布式策略分布式訓練執行流程
3.1.2 圖點積嵌入分布式策略
? 數據與模型存儲
數據劃分同圖簡易策略,模型分為節點向量與負采樣向量.一個節點向量的不同列存放在不同的機器上,與圖簡易嵌入分布式策略不同.
? 訓練流程
步驟1.計算節點進行本地的數據讀取,得到需要參與計算的模型索引;
步驟2.計算節點根據獲取到的模型索引,從參數服務器上拉取需要的模型.需要拉取的結果為點積計算之后的結果,點積計算在參數服務器上完成,無需進行通信,只需將點積計算結果傳遞給計算節點.傳輸的維度也從D維變為了1 維度.因此,通信開銷為O(2m);
步驟3.計算節點進行梯度計算,計算一維梯度,將一維梯度推送回參數服務器,參數服務器可利用一維梯度更新每個維度;
步驟4.計算完畢后,將一維梯度傳遞回參數服務器,節點向量和負采樣向量均需要傳遞1 維度參數,參數服務器將會利用一維梯度去更新其他維度梯度,更新結果同原來一致,故通信開銷是O(2m).
總體通信開銷為拉取與推送兩個操作帶來模型傳輸和梯度傳輸之和,一個批次下,通信量為O(4m).
3.2 圖分割嵌入分布式策略
? 數據存儲與模型存儲
節點向量模型按照節點的id 分布在計算節點的每臺機器上,在參數服務器上存儲全部的負采樣向量模型,同一節點向量的不同維度存放在相同的機器上,它的訓練執行流程如圖6 所示.
? 訓練流程
步驟1.每臺機器進行本地的數據讀取,得到需要參與計算的模型行索引,數據讀取按照圖上節點id 進行哈希劃分,分散在每臺機器上;
步驟2.需要拉取的模型為負采樣向量的部分模型,由于圖節點向量在每個計算節點本地,通信開銷為O(mD);
步驟3.每臺機器需要進行梯度的計算.節點向量的模型放置在計算節點上,數據為點對信息,根據節點哈希到不同機器上,節點向量模型直接在本地更新;
步驟4.計算完畢之后,將負采樣向量模型的梯度傳遞回參數服務器,并且在本地更新相應節點向量模型.因為每個負采樣向量模型節點需要傳遞D維度的參數,通信開銷為O(mD).
總體的通信開銷為拉取與推送這兩個操作帶來的模型傳輸和梯度傳輸之和,一個批次下需要的通信量為O(2mD),對比圖簡易嵌入分布式策略,減少了一半通信量.
4 實驗與分析
4.1 圖分割嵌入分布式策略
? 數據集
我們采用 3 個公開的數據集(下載地址:https://snap.stanford.edu/data/),即維基百科(WIKI)、油管(YOUTUBE)、現場博客(LIVEJOURNAL)數據集.數據集的基本信息概括在表1 中.
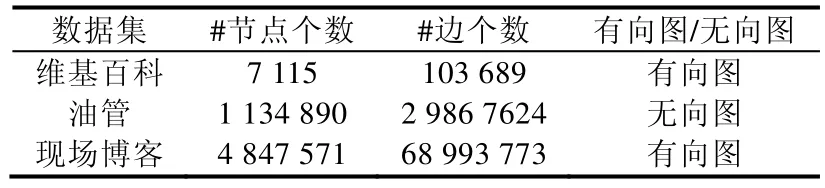
Table 1 Dataset size表1 數據集規模
? 實驗環境
目前的實驗在一個實驗室集群下進行,該集群包含了8 臺物理機,每個機器包含2 個CPU,32GB 內存,機器之間的網絡為1Gb/s.筆者在開源系統Spark 上統一實現了3 種圖嵌入分布式策略.
? 實驗設計
我們從以下3 個角度設計實驗:(1)選用3 種常見的圖嵌入算法進行實驗,以證明算法的通用性;(2)采用常見的圖嵌入算法對3 種不同分布式嵌入策略在不同數據集上進行對比,以展示圖分割嵌入式策略的高效性;(3)對3 種圖嵌入分布式收斂的情況分析,以證明各種實現策略均不影響算法的正常收斂.在所有實驗中,采用的圖節點嵌入向量維度均為128 維,均使用負采樣算法進行訓練.
4.2 各分布式策略的性能與可擴展性分析
圖點積嵌入分布式策略在較少計算節點的數目下具有性能優勢,在2 個或者4 個計算節點時,其訓練的時間開銷往往低于圖簡易嵌入分布式策略和圖分割嵌入分布式策略.隨著計算節點數目的增加,圖點積嵌入分布式策略的性能開始下降.下降原因來自計算節點數目增加后,點積運算帶來的提升有限,并且點積運算所需要的加法次數變多.此外,機器數目增多引入額外協調開銷,一臺機器需要等待另外的機器點積運算完畢才能拿到結果,因此拿到結果最終取決于最慢的機器.因此,其核心運算優勢減少,通信開銷增加,最終導致性能大幅下降(如圖7~圖15 所示).
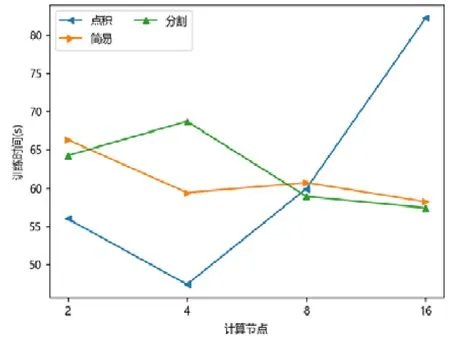
Fig.7 WIKI-LINE圖7 維基百科-大規模信息網絡嵌入

Fig.8 WIKI-APP圖8 維基百科-非對稱臨近可擴展性圖嵌入
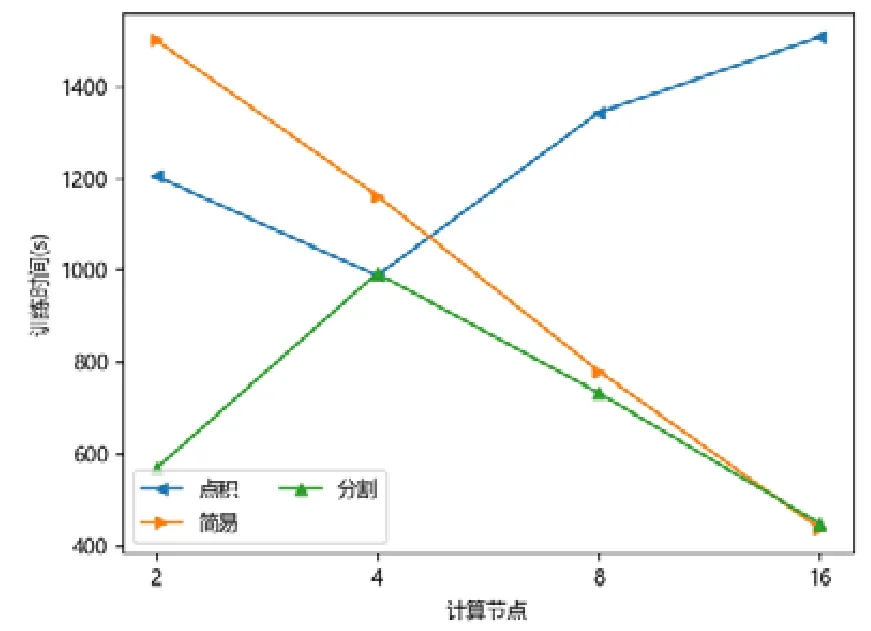
Fig.9 WIKI-DeepWalk圖9 維基百科-深度游走
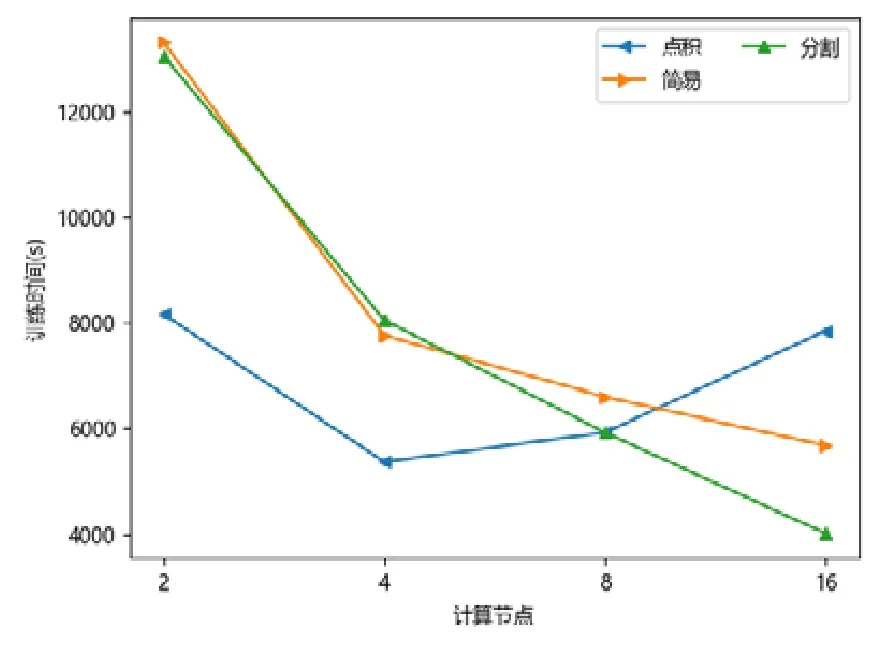
Fig.10 YOUTUBE-LINE圖10 油管-大規模信息網絡嵌入

Fig.11 YOUTUBE-APP圖11 油管-非對稱臨近可擴展性圖嵌入
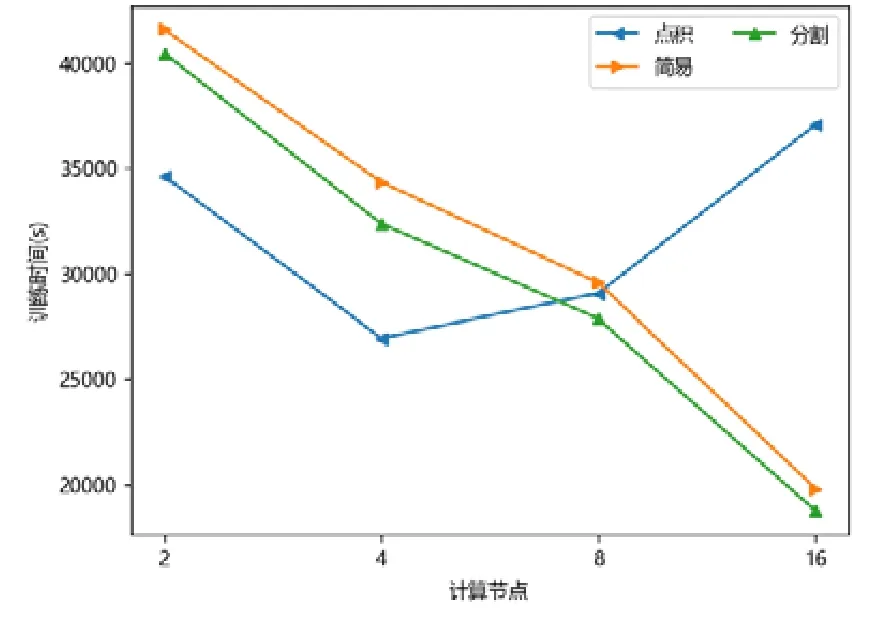
Fig.12 YOUTUBE-DeepWalk圖12 油管-深度游走

Fig.13 LIVEJOURNAL-LINE圖13 現場博客-大規模信息網絡嵌入
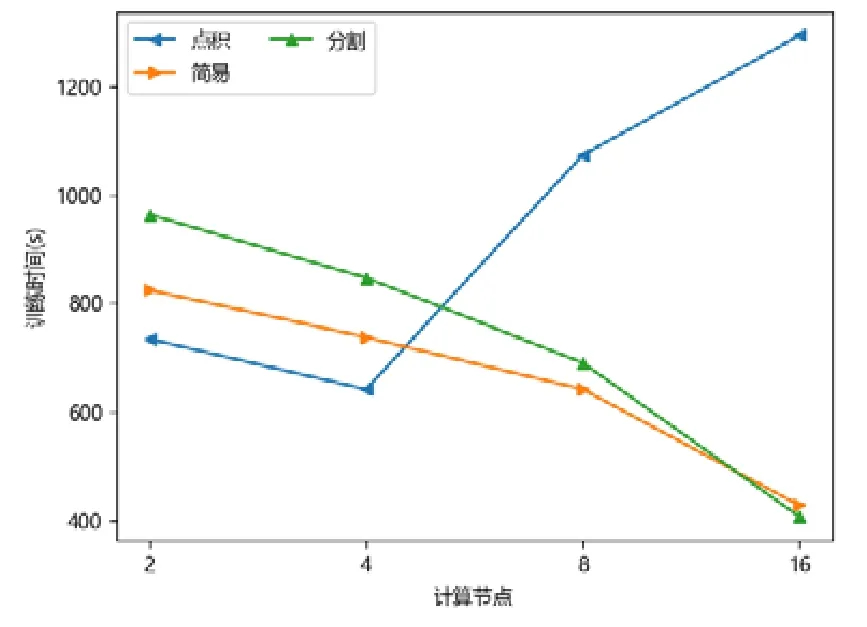
Fig.14 LIVEJOURNAL-APP圖14 現場博客-非對稱臨近可擴展性圖嵌入
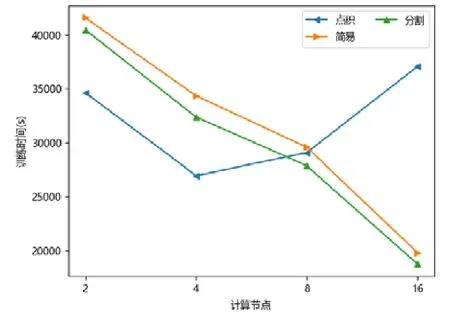
Fig.15 LIVEJOURNAL-DeepWalk圖15 現場博客-深度游走
對于圖簡易嵌入分布式策略而言,當計算節點和模型切片數目增加,其點積操作并不與模型切片數目相關,其具有較好的加速比;另一方面,每一臺機器的運算均可以獨立進行,無需和其他機器同步,因此機器的協調時間大大減少.雖然機器數目增加會帶來一定的額外時間開銷,但增大量遠不如圖點積嵌入分布式策略,其可擴展性較好,性能總體而言不如圖分割嵌入分布式策略.
對于圖分割嵌入分布式策略,其具有不錯的性能優勢.當計算節點和模型切片數目增加時,其計算模式同圖簡易嵌入分布式策略近似;但網絡開銷比其要少,其節點向量矩陣的更新與拉取在每臺機器本地完成,理論上將節省一半的網絡通信.同樣,與圖點積嵌入分布式策略不同,其額外開銷與機器數目影響不大,內積運算單獨在每臺機器上完成,并未累加.因此,其性能具有良好的可擴展性,并且其往往在多個計算節點的情況下,性能比圖點積嵌入分布式策略要好.由于其拉取操作的通信量比圖簡易嵌入分布式策略要少,其實驗表現比圖簡易嵌入分布式策略要好.而對于少許性能震蕩的情況而言,可能出于數據劃分的傾斜問題,導致每臺機器分配的算力不均衡,最終導致個別結果不如圖簡易嵌入分布式策略與圖點積嵌入分布式策略.總體而言,對比圖簡易嵌入分布式策略與圖點積嵌入分布式策略的分布式訓練策略,圖分割嵌入分布式策略在三者數據集上體現出了極好的性能優勢,并且表現出了優異的可擴展性.
4.3 各分布式策略收斂結果的對比
本文對計算節點、圖點積嵌入分布式策略、圖分割嵌入分布式策略這3 種采樣策略均進行了LOSS 收斂曲線的實驗.實驗中固定嵌入的維度為128,并且采用20 輪次的迭代.出于不同分布式策略的學習率與模型適應程度不同,并且不同分布式策略具有不同的計算模式,梯度更新順序與模式不完全一致.因此,為了讓每個算法取得更好的收斂結果,本文對于不同的算法采用了不同的學習率初始值.
本文以現場博客數據集為例,分別繪制了非對稱臨近可擴展性圖嵌入、深度游走、大規模信息網絡嵌入這3 種采樣策略對應的2,4,8,16 個計算節點和模型切片數目的LOSS 收斂曲線圖.接下來將通過圖表對結果做進一步的分析.
APP 基于根網頁排名,根據停留率(stoprate)對圖節點序列進行采樣,其中,圖節點序列采用隨機游走的方式得到,包括深度優先遍歷或寬度優先遍歷.因此,在輸入序列數據規模相同的情況下,其采樣點對會遠遠少于DeepWalk 的點對.由于圖嵌入為無監督學習,其LOSS 損失很大程度上取決于輸入數據規模:當數據規模擴大后,其總體數據復雜程度會有更大機率擴大;當輸入數據規模減少時,其數據復雜程度會減少.數據復雜程度影響LOSS 損失函數:當LOSS 損失很大時,表明模型對數據的認知較弱;當LOSS 損失較小時,表明此時模型對數據的認知較強.當數據復雜程度較小時,模型會很快收斂.因此,由圖中可以觀察得出:對于非對稱臨近可擴展性圖嵌入采樣算法,圖點積嵌入分布式策略、圖簡易嵌入分布式策略、圖分割嵌入分布式策略三者均會穩定收斂.以圖16(a)為例:當采用兩個計算節點時,3 種分布式策略均在第一輪迭代后很快收斂,并在后續的迭代中緩慢收斂.圖16(b)~圖16(d)分別表現了采用更多計算節點時,LOSS 的收斂情況.從4 張圖中可以發現:擴大計算節點個數后,圖點積嵌入分布式策略、圖簡易嵌入分布式策略、圖分割嵌入分布式策略三者均會穩定收斂.
深度游走采樣算法是最初提出用以建模圖節點向量,流程為從某一節點出發,根據深度優先遍歷結果或寬度優先遍歷統計節點鄰域序列,再根據節點鄰域序列學習得到模型.深度游走采樣對模型的刻畫較為粗糙,數據復雜程度較非對稱臨近可擴展性圖嵌入更為復雜.數據規模比非對稱臨近可擴展性圖嵌入大,模型學習難度較大.由圖17(a)可以看出:當采用2 個計算節點時,模型在第一輪迭代損失會下降,但下降程度并不明顯,隨后的幾輪迭代模型進入緩慢收斂期,出于模型的復雜程度較大,3 類算法對其學習程度略微陡峭,收斂速度整體不如非對稱臨近可擴展性圖嵌入.其中,圖點積嵌入分布式策略在第一輪次的收斂值相比其他兩者稍顯優勢,在后來幾輪迭代中進入緩慢收斂期,這一收斂結果與學習率的設置也有一定關系.總體三者最終收斂結果相同,趨于一致,表明3 類算法均可學習得到不錯的模型結果,取得優異的收斂值.
通過觀察發現:在采用大規模信息網絡嵌入采樣算法時(如圖18 所示),圖簡易嵌入分布式策略與圖分割嵌入分布式策略的LOSS 曲線較為一致.這一現象是由于圖簡易嵌入分布式策略與圖分割嵌入分布式策略具有較為近似的計算模式,其梯度更新順序較為接近.兩者不同之處僅僅在于模型存儲位置以及其存儲帶來的梯度傳輸差異,例如:在圖分割嵌入分布式策略中,其梯度將有一部分在本地更新;而圖簡易嵌入分布式策略則全于參數服務器中更新.兩者還具有相應的數據劃分引入的差異性:在圖簡易嵌入分布式策略中,其數據劃分為隨機進行;而圖分割嵌入分布式策略則是預先進行劃分,不含有梯度寫回的誤差.最終,3 種分布式策略在大規模信息網絡嵌入采樣算法中達到同樣的收斂結果.結合上述圖表與分析,3 種分布式策略的收斂結果差異不大,有些算法在收斂中間略有震蕩.這一結果可能與不同機器的數據分布不同,以及分布式策略對數據的依賴性、數據打亂的結果以及初始學習率的設置有關.最終,在3 種圖嵌入采樣算法中,3 類分布式訓練策略得到的損失(LOSS)收斂結果均為一致,表明三者策略對于數據的學習程度較為接近.
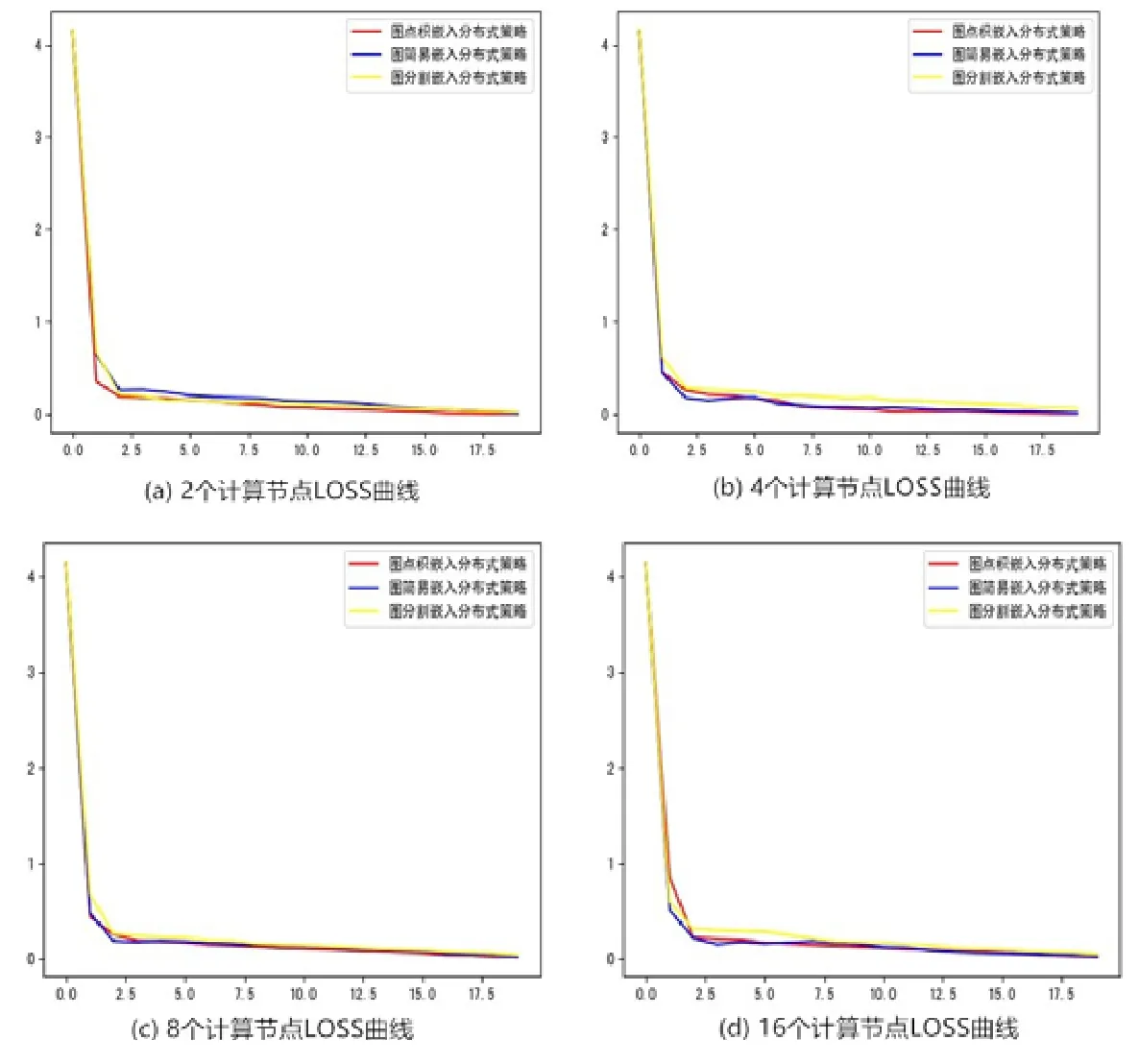
Fig.16 The LOSS curve of APP圖16 非對稱臨近可擴展性圖嵌入算法LOSS 曲線

Fig.17 The LOSS curve of DeepWalk圖17 深度游走LOSS 曲線
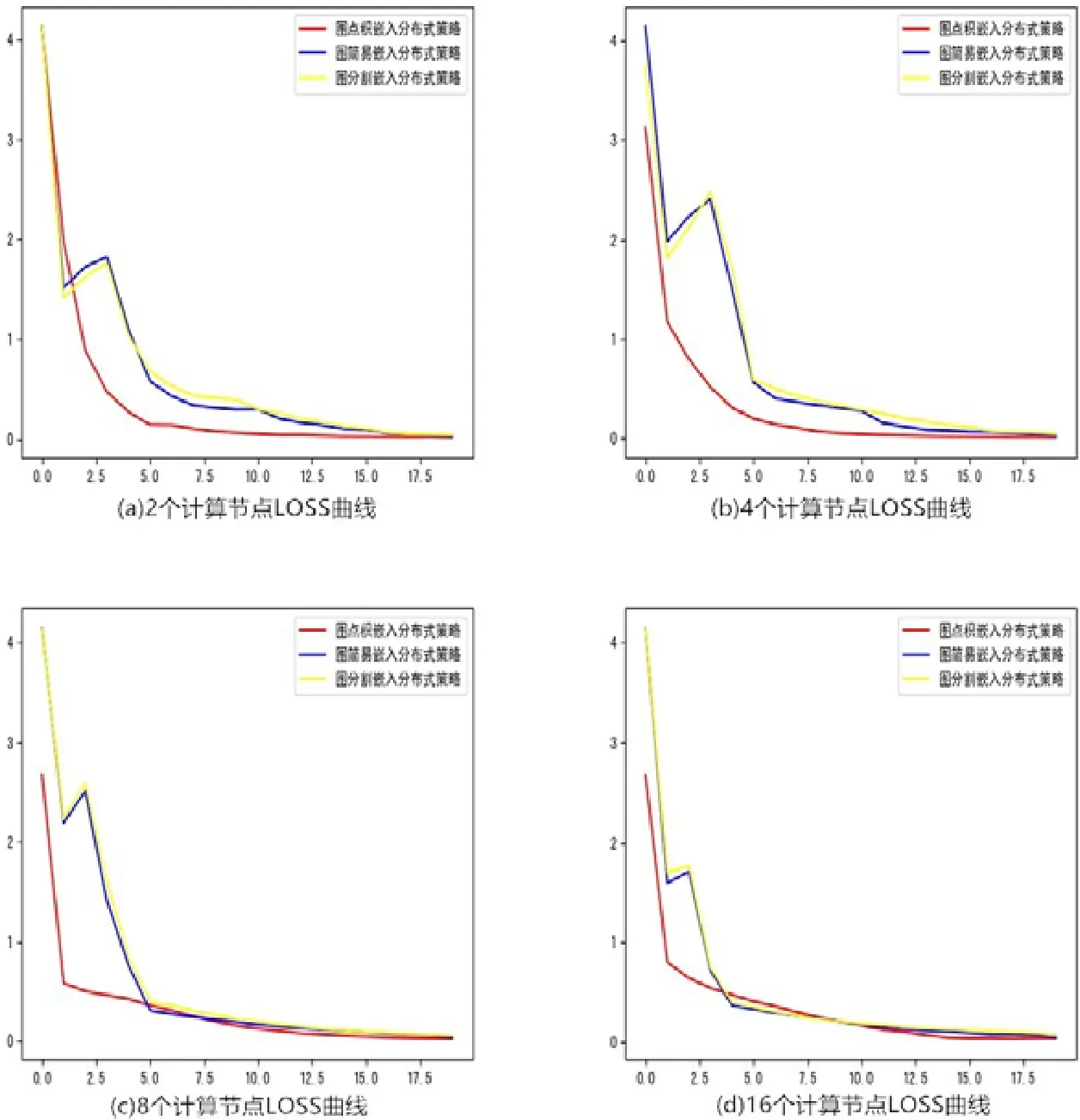
Fig.18 The LOSS curve of LINE圖18 大規模信息網絡嵌入LOSS 曲線
4.4 各分布式策略收斂速度的對比
通過多次實驗發現:機器學習模型的收斂速度與其初始的學習率具有較大的關聯,并且與選擇的優化器有直接關系.其中,優化器可以分為有動量的與隨機梯度下降法,出于對分布式多機器收斂影響的考慮,在此選擇為最基礎的隨機梯度下降法.若初始的學習率較大,那么模型將會很快地進入較優值,并且LOSS 收斂曲線會隨著迭代輪次數目的增加時而震蕩.如果初始的學習率較小,模型收斂到達最優解的可能性會增加,通常情況下,LOSS 收斂曲線會在最后迭代次數下輕微震蕩.不同的分布式訓練策略往往有著不同的數據依賴,模型向量之間的依賴,每一種訓練策略,其并行運算的流程與常見的串行算法并不一致,而基于HOGWILD[22]理論,每個機器之間可以無序的寫回梯度,使得最終結果收斂.
5 總結
本文首先通過對多種現有的圖嵌入方法進行調研,提出了一個高可用的分布式訓練框架.該框架通過將采樣、訓練過程解耦,從而能夠表達多種圖嵌入算法.用戶可以只關心采樣的流程或只關心訓練的流程,從而使得其中的算法具有高度的可復用性.另外,筆者針對業界現有的分布式圖嵌入策略進行分析,發現了這些算法在訓練性能以及擴展性上的不足,進而提出了一種圖分割嵌入分布式策略.筆者實現了一個原型系統,并通過充分的實驗分析了3 種分布式策略.筆者發現:機器數目增加后,圖點積嵌入分布式策略的可擴展性變差,在性能對比上處于劣勢地位;而圖簡易嵌入分布式策略和圖分割嵌入分布式策略具有較為不錯的可擴展性,本文提出的圖分割嵌入分布式策略具有更好的性能優勢.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
