用于表格事實檢測的圖神經網絡模型?
2021-05-23 13:17:06鄧哲也
軟件學報 2021年3期
鄧哲也,張 銘
(北京大學 信息科學技術學院 計算機科學技術系,北京 100871)
隨著如今文本數據越來越多,并且可以輕松地通過互聯網傳播,當人們面對錯綜復雜的信息時,為了辨別信息的真假,需要對這些信息進行驗證,這就體現出了事實檢測任務的重要性.
在自然語言理解和語義表征的研究中,驗證一句文本陳述是否基于給定的事實證據非常重要,這是自然語言理解中的一個基礎任務.現有的研究主要局限于處理非結構化證據的事實驗證,如自然語言的句子、文檔、新聞等,在這一類研究中,細分下來有很多不同的任務,如檢查文本關聯性[1]、自然語言推理[2]、基于維基百科的事實驗證[3].它們用到的證據都是純文本信息.而結構化證據下的驗證還有待探索,比如基于表格、圖表、數據庫等形式的事實驗證.在這一類研究中,有基于圖片證據的數據集NLVR[4]/NLVR2[5],還有基于表格證據的數據集TabFact[6].
TabFact 數據集是一個包含1.6 萬個維基百科中的表格作為事實證據和11.8 萬條人工標注的自然語言陳述的事實驗證數據集.不僅形式上與純文本數據不同,采用的是表格形式的數據,而且它與一般的事實驗證數據集不同的點在于,它要求模型同時具有語義推理和符號推理的能力.圖1 就是該數據集的一個實例.
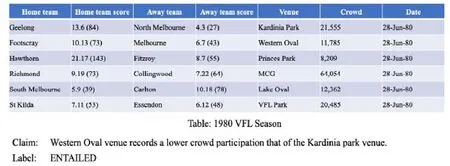
Fig.1 An instance of the TabFact dataset圖1 TabFact 數據集的一個實例
TabFact[6]中提出了兩個基線模型,分別是基于自然語言推理的Table-BERT 和基于搜索和數據庫查詢的LatentProgram 算法.這兩個做法都沒有取得非常好的效果,因為Table-BERT 簡單地把表格中的內容拼接在一起組成了文本,轉化為了基于文本的事實驗證問題,忽略了表格中行與行、列與列之間的關系;而LatentProgram 算法是基于人工規則的搜索,泛化效果并不好.
本文將圍繞TabFact 數據集,針對表格數據的特殊的結構特征,設計基于表格數據的事實驗證模型和算法,完成代碼實現,并在基于表格的事實檢測數據集上驗證了效果.
本文的貢獻可以概括為以下兩點:
(1)提出了以表格的行為單位的Row-GVM 模型,利用表格的行特征和圖注意力網絡對該任務建模,準確率相比基線模型提升了2.62%;
(2)提出了以表格的單元格為單位的Cell-GVM 模型,利用表格的單元格特征和圖卷積網絡對該任務建模,準確率相比基線模型提升了2.77%.
1 相關工作
1.1 事實檢測任務數據集
FEVER(fact extraction and verification,事實抽取和檢測)[3]數據集是一個公開的事實檢測數據集,它包含185 445 條陳述,陳述是通過改編維基百科中的句子生成的.FEVER 數據集關注的是驗證文本陳述的真偽,依據是維基百科中詞條里出現的文本信息.這與本文關注的基于表格的事實驗證任務非常相似.在本文的任務中,陳述也是文本的形式,但是依據的形式是維基百科中詞條里出現的表格.
TabFact[6]數據集是一種全新的基于表格的事實驗證數據集,難點在于需要模型能夠完成語義推理和符號推理.還有一些其他的基于表格的數據集,如基于表格的問答數據集WikiTableQuestion[7],但本質上和TabFact數據集有很大的區別,因為WikiTableQuestion 數據集中的問題對答案的類型有強烈的指向性,對于模型的推理能力要求不高,因此,在這個數據集上的做法很難遷移到TabFact 數據集上.
1.2 圖神經網絡
圖神經網絡[8]可以比一般的神經網絡更好地挖掘出用圖表示的數據.在圖神經網絡中,節點可以通過與它相連的邊共享鄰居節點的信息,學到更好的表示.最近的一些研究在利用不同的神經網絡結構來優化整張圖中節點信息的交互.
圖神經網絡在基于文本的事實檢測任務數據集FEVER 上有不錯的表現.GEAR[9]使用了圖注意力網絡(GAT)[10]來對陳述-依據對進行推理和整合,它把陳述和依據的文本拼在一起當作節點,構建了一張完全圖,利用GAT 在圖上傳遞節點信息.KGAT[11]也采用了GAT,它把依據的文本當作節點,引入了稱為邊核和點核的高斯核池化層,其中,邊核用來在依據圖上傳遞信息,點核用來把所有節點的信息進行合并得到整個圖的表示.這種方法得到的依據和陳述的注意力相對而言更為集中,使得在FEVER 數據集上的表現要好過GEAR.不同于直接把依據文本傳進預訓練語言模型的其他模型,DREAM[12]關注到了文本中的語義層面的信息,比如人物、地點、時間等不同實體之間的關系,認為這類語義信息對理解依據中的結構關系非常重要,于是對陳述和依據建出了語義圖,在語義圖上,利用圖卷積網絡(GCN)[13]進行推理,在FEVER 數據集上取得了目前最好的結果.
圖神經網絡在閱讀理解任務上也有很好的表現,比如,Entity-GCN[14]在建圖過程中,把文本中出現的所有實體都當作了圖中的節點.根據節點之間的關系連接了不同種類的邊,如:不同文檔中描述的同一實體之間連邊,同一文檔中的所有點互相連邊等.之后,運用GCN 對文本內容進行多輪推理,取得了目前最好的效果.
1.3 自然語言推理
對語言的推理建模,是自然語言理解的重要的第1 步.自然語言推理的目標是,判斷一個自然語言假設可否由一個自然語言前提推理得到.具體地說,是判斷假設和前提的關系,可以是支持、反駁或中立中的任何一種.
隨著深度學習的興起,涌現出了很多解決這類問題的模型,如 SNLI[2],Decomposed Model[15],Enhanced-LSTM[16],Multi-NLI[17],BERT[18].本文的任務雖然也是自然語言推理,但是本文的前提不是完全以文本形式呈現的,而是由文本組成的半結構化的表格形式呈現的,所以該任務可以看作是半結構化領域的自然語言推理問題.
1.4 預訓練語言模型
如今在很多自然語言處理的任務上,預訓練的語言表示模型,如ELMo[19],OpenAI GPT[20],都被證明是非常高效的.BERT[18]是一種預訓練語言表示的新方法,通過聯合調節所有層中的雙向Transformer 來預訓練深度雙向表示.在本文的工作中,使用BERT 來對文本信息進行編碼.
2 方 法
2.1 任務定義
在介紹本文的方法之前,首先給這個基于表格的事實檢測任務進行一個正式的定義.
本文把數據集中的每個實例表示成(T,C,L),其中:表格T={Ti,j|0≤i≤RT,1≤j≤CT},RT和CT分別為表格的行列數,Ti,j表示第i行第j列的單元格的內容;陳述C={c1,c2,…,cn}是一個n個單詞組成的基于表格內容的陳述;標簽L∈{0,1},L=1 表示陳述C被表格T支持,L=0 表示陳述C被表格T反駁.本文的目標是給定(T,C),預測正確的標簽L.
2.2 方 法
本文結合表格的結構特征,提出了兩種用來對基于表格信息的陳述進行事實檢測的模型,分別是:
(1)Row-GVM:以表格中的每一行為單位的(Row-level)基于圖神經網絡的事實檢測模型(GNN-based verification model);
(2)Cell-GVM:以表格中的每一個單元格為單位的(Cell-level)基于圖神經網絡的事實檢測模型.
2.2.1 Row-GVM
如圖2 所示,Row-GVM 模型分為3 個部分.
(1)信息編碼:對行信息進行編碼,把每一行當作圖中的一個節點;
(2)信息傳遞:建立一個全連接圖,在圖上利用GAT 的原理進行信息傳遞;
(3)整合預測:整合每個節點的表示得到一個最終表示,進行二分類預測.
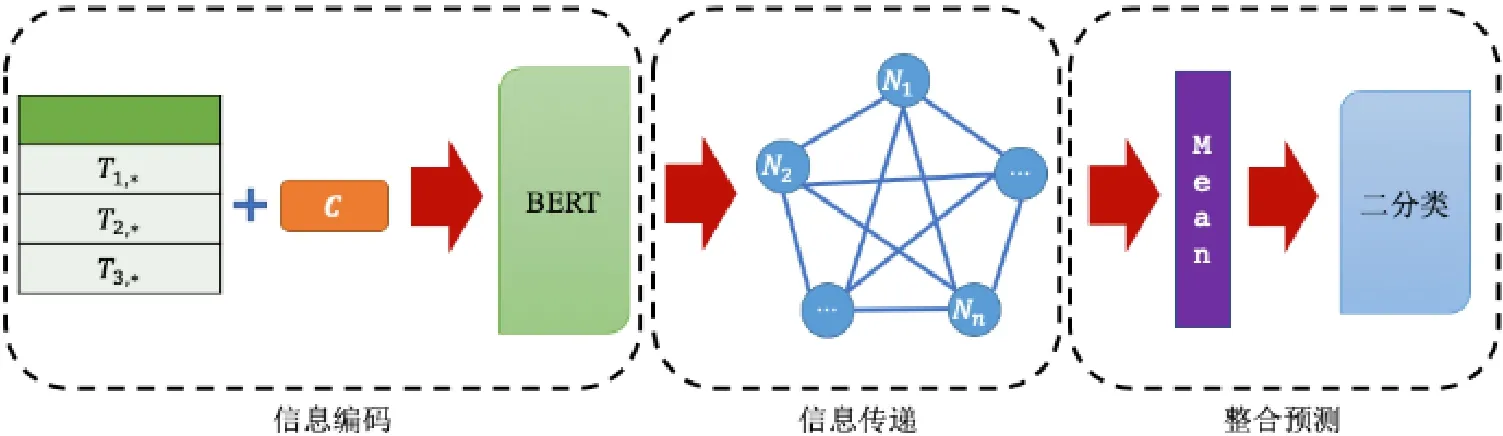
Fig.2 A flowchart of Row-GVM圖2 Row-GVM 的流程圖
(1)編碼
為了得到第i行的表示,本文把第i行的信息拼接起來,得到Ti,*.為了在后續的信息傳遞中更好地捕捉和陳述相關的信息,本文將第i行的信息Ti,*和陳述C拼接在一起后,通過BERT 獲得第i個節點的表示Ni=BERT(Ti,*,C).Ni∈?F,其中,F是每個節點的特征維數.
(2)信息傳遞
在信息傳遞模塊,本文引入了GAT,它是由若干個圖注意力層堆疊而成的.
在第t層圖注意力層中,輸入是ht?1,輸出是ht.為了更好地捕捉節點之間的信息,本文先用一個矩陣Wt∈?F′×?F把ht?1映射到高維空間,再對每個節點計算自注意力,用映射β∈?F′×?F′→?來計算注意力系數這表示第j個點對第i個點的重要程度.本文希望每個節點的信息都可以傳達到圖中其他的每一個點,所以對每一對節點都要計算注意力系數.對于點i,本文要把其他點對它的重要程度做一個正則化,這里使用softmax函數:

在本文的實驗中,自注意力模塊β中,和第i個節點有關的重要程度是用一個權值向量βi∈?2×F′來實現的,并且引入了LeakyReLU(負數輸入的斜率為0.1)[21],αij可以重寫為
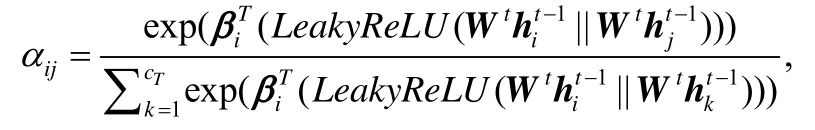
其中,?T表示轉置,||表示向量的連接操作.
最后,根據計算出的注意力系數把其他點的表示整合起來,得到每個節點的新的表示,作為第t層的輸出:

(3)預測
為了進行最后的預測,本文需要得到一個整張圖的表示.這里,本文采用求每一維特征的平均值的方法得到最終表示hG,hG∈?F.得到了圖的表示hG后,用一個一層的全連接網絡來獲得最終的預測結果:
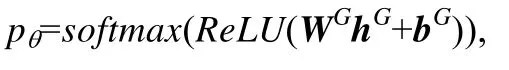
其中,WG∈?2×F,bG∈?2×1.本文通過優化參數θ來最小化交叉熵損失L(pθ,L),其中,L是真實的標簽.
2.2.2 Cell-GVM
如圖3 所示,Cell-GVM 模型分為3 個部分.
(1)信息編碼:對單元格的信息進行編碼,把每個單元格當作圖中的一個節點;
(2)信息傳遞:同一行之間的點兩兩之間互相連邊(圖3 中的實線邊),記作ROW 邊;同一列之間的點兩兩之間互相連邊(圖3 中的點線邊),記作COL 邊.在圖上利用GCN 的原理進行信息傳遞;
(3)整合預測:整合每個節點的表示得到一個最終表示,進行二分類預測.
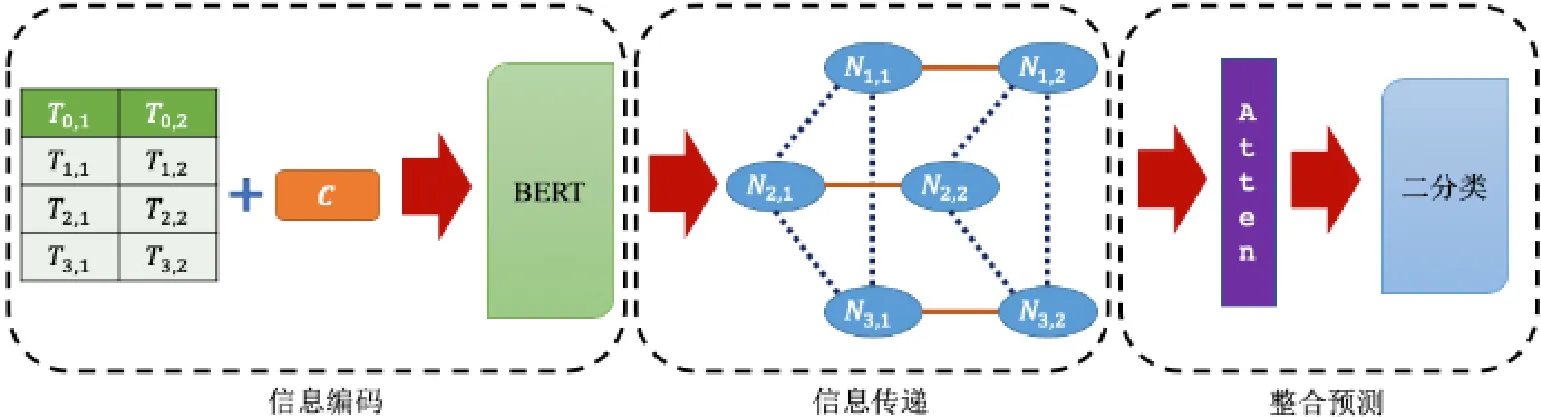
Fig.3 A flowchart of Cell-GVM圖3 Cell-GVM 的流程圖
(1)編碼
為了在后續的信息傳遞中更好地捕捉和陳述相關的信息,將第i行第j列的單元格的信息Ti,j和陳述C拼接在一起后,通過BERT 獲得第i行第j列的節點的表示Ni,j=BERT(Ti,j,C).這里把陳述C也通過BERT,得到它的表示NC=BERT(C).Ni,j,NC∈?F,其中,F是每個節點的特征維數.
(2)信息傳遞
在信息傳遞模塊,與Row-GVM 不同的是,本文引入了GCN.
本文把RC個節點和RC(C?1)/2 條ROW 邊組成的子圖記作GCOW,RC個節點和RC(R?1)/2 條COL 邊組成的子圖記作GCOL.
記圖Gr(r∈{ROW,COL})給每個點加上自環后的鄰接矩陣為Ar,度數矩陣為,歸一化后
第t層圖卷積層會通過兩類邊整合每個點的鄰居的信息,得到第t層的輸出:的對稱鄰接矩陣為

其中,r表示的是邊的種類,是權值矩陣,σ是激活函數.
(3)預測
為了得到圖的表示,先用矩陣WH和WC分別把ht?1和NC映射到高維空間,WH,WC∈?F′×F,然后用映射γ:?F′×?F′→?來計算節點和陳述之間的注意力,然后進行歸一化,得到:

在本文的實驗中,映射γ采用的是點積運算,所以βi,j可以重寫為
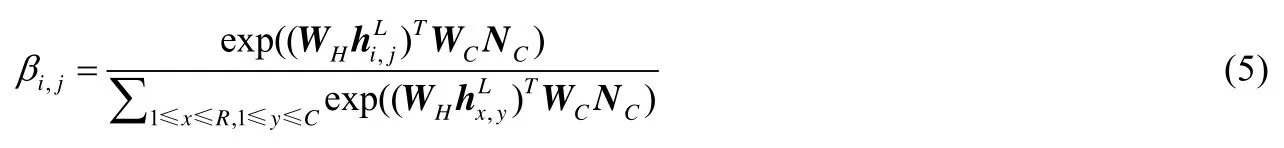
得到了圖的表示hG后,把它和陳述的表示NC拼接在一起,通過一個一層的全連接網絡來獲得最終的預測結果:

其中,WG∈?2×F,bG∈?2×1,||表示向量的連接操作.
本文通過優化參數θ來最小化交叉熵損失L(pθ,L),其中,L是真實的標簽.
3 實 驗
3.1 實驗設置
3.1.1 數據集
本文的實驗全部在TabFact 數據集[6]的子集TabFact-small 上進行,其中每一條陳述都是針對某一個表格的,并且被人工打上了“支持”或者“反駁”的標簽.
由于計算資源的限制,本文從原數據集中移除了最大的一些表格,這部分表格占到原數據集的8.12%左右.本文對所有模型做的實驗都是在TabFact-small 數據集上進行.TabFact-small 數據集的信息見表1.
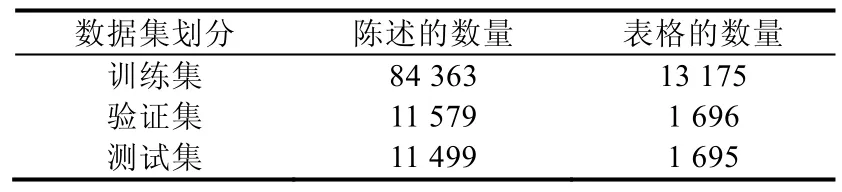
Table 1 Statistics for the TabFact-small dataset表1 TabFact-small 數據集的統計數據
3.1.2 基線模型
本次實驗中的基線模型一共有3 個.其中,第1 個模型Bert-Concat 是TabFact 數據集[6]中提出的表現最好的模型;后面兩個模型Row-Mean 和Cell-Atten 是受第1 個模型的啟發,并結合本文提出的模型,實現的兩個基線模型.
? Bert-Concat[6]
如圖4 右上角圖所示,把每一個單元格的信息拼起來,然后和陳述C拼接在一起,通過Bert 和一個多層感知器fMLP對結果進行分類,得到一個預測pθ(T,C)=σ(fMLP(BERT(T,C))),其中,σ是sigmoid函數.
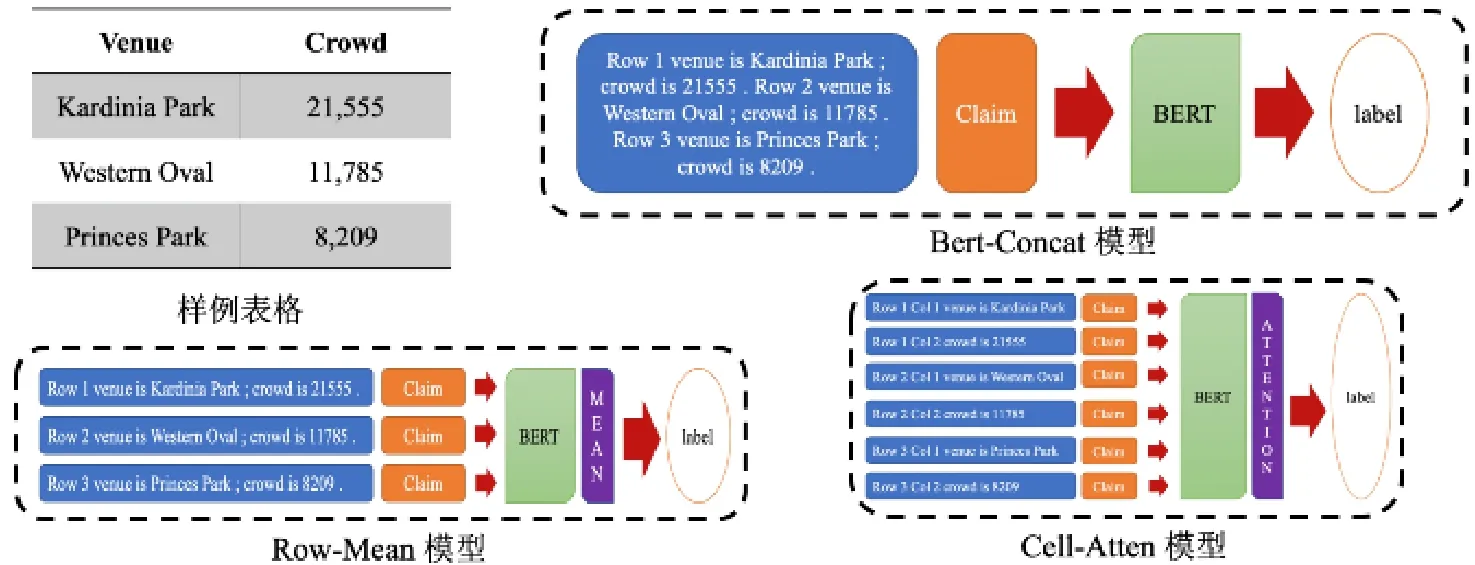
Fig.4 Flowcharts of baseline models圖4 基線模型的流程圖
? Row-Mean
如圖4 左下角圖所示,把每行的所有單元格的信息拼起來,一共得到R個句子.每一行的句子都和陳述C拼接在一起,通過Bert 后先對所有表示取平均值,然后用一個多層感知器fMLP對結果進行分類,得到一個預測:
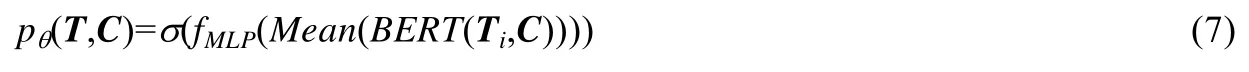
其中,σ是sigmoid函數.
? Cell-Atten
如圖4 右下角圖所示,對每一個單元格都得到一個句子,一共有RC個句子.每一個單元格的句子都和陳述C拼接在一起,通過Bert 后對所有表示計算和它和陳述C之間的注意力,然后用一個多層感知器fMLP對結果進行分類,得到一個預測:

其中,σ是sigmoid函數.
3.1.3 評價標準本文通過比較模型的預測輸出和數據集中人工標注的真實標簽計算準確率來評價模型,即:
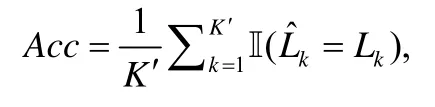
其中,K′是測試集的大小,是模型預測的標簽,Lk是真實的標簽.
3.2 實現細節
在所有的模型中,本文使用的都是用104 種語言預訓練的12 層、隱藏層維數768、12 頭的BERT 模型[18].所有的參數都是默認參數.優化器是BERTAdam[18],學習率是1e?5.對于Row-GVM,最大序列長度設為128,批大小設為8;對于Cell-GVM,最大序列長度設為64,批大小設為2.熱身比例是0.4.
4 結果與分析
4.1 實驗結果
在表2 中列出了每個模型在TabFact-small 數據集的驗證集和測試集上的表現.在這個表中有如下發現.
(1)Row-Mean 的表現比Bert-Concat 稍好,但是Cell-Atten 的表現沒有超過Bert-Concat.這可能是因為獨立地檢查單個單元格很難得出正確的判斷,需要一行或所有單元格聯合起來才能提供更有效的信息;
(2)Row-GVM 和Cell-GVM 都顯著地超過了原文獻的基線模型Bert-Concat,它們在驗證集上的提升分別是2.47%和3.08%,在測試集上的提升分別是2.62%和2.77%.這說明利用表格的行與列的相關性特征可以顯著提高模型的表現;
(3)Cell-GVM 在該數據集上取得了最好的效果.

Table 2 Main results表2 主要實驗結果
4.2 消融實驗與分析
4.2.1 Row-GVM 中GAT 模塊的有效性
為了驗證Row-GVM 中GAT 的有效性,本文調整了GAT 的層數,分別設置成了0 層~3 層,每種情況的實驗結果都列在表3 中.其中,0 層的GAT 等價于從Row-GVM 中刪除了GAT 模塊,退化為Row-Mean 模型.
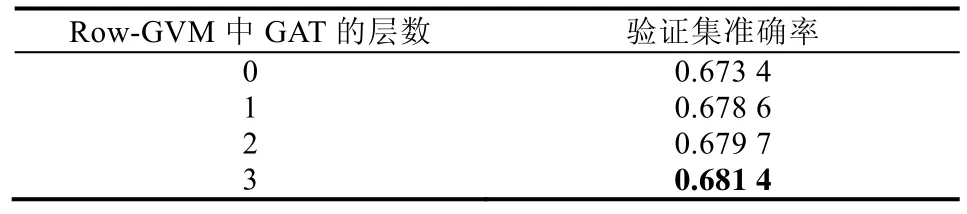
Table 3 Comparison of different layers of GAT with respect to their effectiveness表3 不同的GAT 層數對模型效果的影響
本文發現:有GAT 模塊的Row-GVM 的表現始終比刪去GAT 模塊的Row-Mean 要好,表現最好的由3 層GAT 組成的Row-GVM 在結果上提升了0.80%,證實了GAT 模塊的有效性,同時也說明了Row-GVM 有能力處理需要多輪推理的事實檢測問題.
4.2.2 Cell-GVM 中GCN 模塊的有效性
為了驗證Cell-GVM 中的有效性,本文調整了GCN 的層數,分別設置成了0 層~3 層,每種情況的實驗結果都列在表4 中.其中,0 層的GCN 等價于從Cell-GCN 中刪除了GCN 模塊,退化為Cell-Atten 模型.

Table 4 Comparison of different layers of GCN with respect to their effectiveness表4 不同的GCN 層數對模型效果的影響
值得注意的是,Cell-Atten 的表現要低于基線模型Bert-Concat.本文分析:這是因為本文對所有單元格的內容都求出了經過Bert 的向量表示,然后直接對所有表示進行了簡單融合,因此不能捕捉單元格與單元格之間的聯系.相比之下,把所有單元格拼成一起經過Bert 得到的表示還是可以捕捉到一部分單元格之間的聯系,所以Cell-Atten 的表現會低于Bert-Concat.
本文發現:有GCN 模塊的Cell-GVM 的表現始終比刪去GCN 模塊的Cell-Atten 要好,表現最好的由3 層GCN 組成的Cell-GVM 在結果上提升了4.32%,證實了GCN 模塊的有效性,同時也說明了Cell-GVM 有能力處理需要多輪推理的事實檢測問題.
4.2.3 Cell-GVM 中區分邊的種類的有效性
為了驗證Cell-GVM 中區分ROW 邊和COL 邊的有效性,本文設置了一組對比實驗.在這組實驗中,不區分ROW 邊和COL 邊,建圖時把這兩類邊標記為同一種邊,信息傳遞時,節點的信息不再通過兩種邊傳遞,而是只通過這一種邊傳遞.在該模型的GCN 的第t層中,直接整合第i行第j列的單元格節點的鄰居的信息:

記該模型為Cell-GVM-SameEdge.
Cell-GVM-SameEdge 和Cell-GVM 的實驗結果列在表5 中.可以看到:在不區分邊的情況下,Cell-GVM 的表現下降了0.42%,證實了區分邊的種類對提升實驗效果是有效的.

Table 5 Comparison of different types of edges with respect to their effectiveness表5 邊的種類對模型效果的影響
本文分析認為:3 層GCN 是最有效的,因為3 層的GCN 可以把一個單元格(如hi,j)的信息通過ROW 邊傳到同一行的另一個單元格(hi,k),再通過COL 邊傳到同一列的另一個單元格(hl,k),最后通過ROW 邊傳到同一行,且和起點單元格的列數一樣的單元格(hi,j).這樣就可以在3 步之內整合另一列的信息傳遞到這一列中其他的節點上.
5 結 論
本文針對基于表格的事實驗證數據集TabFact,利用了表格的結構特征,結合圖注意力網絡和圖卷積神經網絡,分別設計了以表格的行為單位的Row-GVM 和以表格的單元格為單位的Cell-GVM,并且都在TabFact-small數據集上取得了最好的結果,比基線模型分別提高了2.62%和2.77%.這兩個模型通過實驗被證明都是高效的,這說明利用表格的行與列的相關性特征確實可以提高模型的表現.
從目前的結果可以看到,預測的準確率還有很大的提升空間.分析了錯誤的案例后,發現本文的模型在捕捉和陳述相關的行與單元格方面的表現有較好的提升,但是符號推理方面表現稍有不足.在未來的研究中,將設計更加側重于符號推理的模塊,融入到本文的模型中,相信會有更好的表現.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
