多尺度目標檢測的深度學習研究綜述*
2021-05-23 06:12:34陳科圻朱志亮鄧小明馬翠霞王宏安
軟件學報 2021年4期
陳科圻 ,朱志亮 ,鄧小明 ,馬翠霞 ,王宏安
1(中國科學院大學 計算機科學與技術學院,北京 100190)
2(計算機科學國家重點實驗室(中國科學院 軟件研究所),北京 100190)
3(人機交互北京市重點實驗室(中國科學院 軟件研究所),北京 100190)
4(華東交通大學 軟件學院,江西 南昌 330013)
目標檢測是一個重要的計算機視覺任務.它由圖像分類任務發展而來,區別在于不再僅僅只對一張圖像中的單一類型目標進行分類,而是要同時完成一張圖像里可能存在的多個目標的分類和定位,其中分類是指給目標分配類別標簽,定位是指確定目標的外圍矩形框的頂點坐標.因此,目標檢測任務更具有挑戰性,也有著更廣闊的應用前景,比如自動駕駛、人臉識別、行人檢測、醫療檢測等等.同時,目標檢測也可以作為圖像分割、圖像描述、目標跟蹤、動作識別等更復雜的計算機視覺任務的研究基礎.
目標檢測算法主要分為3 個步驟:圖像特征提取、候選區域生成與候選區域分類.其中,圖像特征提取是整個檢測流程的基石.傳統算法普遍是基于人工設計的特征算子來描述圖像,例如SIFT 特征[1]、HOG 特征[2]等等.這些特征算子普遍是基于底層視覺特征來設計的,因此很難獲取復雜圖像里的語義信息.2012 年,Krizhevsky 等人[3]提出的AlexNet 在ILSVRC 挑戰賽[4]的圖像分類任務上以顯著優勢奪得了冠軍,讓人們看到了卷積神經網絡強大的特征表示能力.自此,基于深度學習的研究熱潮拉開了帷幕.在之后的幾年里,VGGNet[5]、GoogLeNet[6]、ResNet[7]等更強大的分類網絡相繼問世.由于它們都能夠提取出非常抽象的特征,因此除了完成圖像分類任務以外,還普遍被用作更復雜的計算機視覺任務的骨架網絡,其中就包括目標檢測.2014 年,Girshick 等人[8]提出的R-CNN 算法在PSACAL VOC 檢測數據集[9]上以絕對優勢擊敗了傳統的DPM 算法[10],為目標檢測開啟了一個新的里程碑.自此,深度學習算法在目標檢測的研究領域里占據了絕對的主導地位,并一直持續至今,近年有很多綜述文獻對此進行了詳細的調研[11-13].
基于深度學習的目標檢測算法主要分為兩個流派:(1) 以 R-CNN 系列為代表的兩階段算法;(2) 以YOLO[14]、SSD[15]為代表的一階段算法.具體來說,兩階段算法首先在圖像上生成候選區域,然后對每一個候選區域依次進行分類與邊界回歸;而一階段算法則是直接在整張圖像上完成所有目標的定位和分類,略過了生成候選區域這一步驟.兩種流派各有優勢,通常來說,前者精度更高,后者速度更快.對于現階段的目標檢測任務來說,無論采用哪種流派的算法,都不可避免地會面臨著尺度問題的挑戰:不同圖像之間、甚至是同一張圖像里,需要被檢測出的目標的大小相對于整張圖像的比例的差異是非常大的.例如,從圖1 可以看到,圖1(a)~圖1(c)這3張圖中的大本鐘、狗、人群的尺度是從大到小的,而圖1(d)所示的兩張圖則均包含了多種尺度的目標.對于檢測任務常用的MS COCO 數據集[16],若根據目標掩膜相對于圖像的像素比例對所有實例的尺度進行統計和排序后會發現:數據集中有10%的目標的尺度小于0.020 7,同樣有10%的目標的尺度大于0.345,尺度跨度極大.在該數據集的評價標準下,現有的檢測器在檢測不同尺度的目標時,普遍存在著精度不均衡的現象,即小目標的準確率通常只有中、大目標的準確率的一半左右.這種尺度差異帶來的挑戰性,嚴重限制了現有檢測器的整體表現.因此,如何更好地實現多尺度目標檢測,近年來一直是目標檢測領域的研究熱點之一.
目標檢測包含了目標的定位和分類這兩個子任務,而尺度問題的根源就在于,卷積神經網絡在不斷加深的過程中,表達抽象特征的能力越來越強,但淺層的空間信息也相對丟失.這就導致深層特征圖無法提供細粒度的空間信息,對目標進行精確定位.同時,小目標的語義信息也在下采樣的過程中逐漸丟失.因此,解決尺度問題的一個通用的思路就是構建多尺度的特征表達.目前,常用的構建多尺度特征的方法包括:(1) 采用圖像金字塔,將圖像以不同的分辨率依次進行目標檢測;(2) 在神經網絡內部通過對不同深度的特征圖進行跨層連接,構建特征金字塔并進行目標檢測;(3) 在神經網絡內部設計感受野不同的并行支路,構建空間金字塔并進行目標檢測.除了構建多尺度的特征表達以外,也有學者從算法流程中更細節的層面研究縮小不同尺度目標檢測精度差距的策略,包括錨點、交并比、動態卷積、邊界框損失函數等等.
本文圍繞基于深度學習的多尺度目標檢測,首先在第1 節中對背景知識進行介紹,包括從兩階段和一階段這兩類算法的角度回顧主流檢測器的奠基過程,以及尺度問題的提出.第2 節介紹基于圖像金字塔的多尺度目標檢測.第3 節介紹基于網絡內特征金字塔的多尺度目標檢測,包括跨層連接和并行支路兩種構建金字塔的方式.第4 節介紹多尺度目標檢測的錨點、交并比、動態卷積、邊界框損失函數等策略.第5 節對多尺度目標檢測未來可能的研究方向和趨勢進行展望.第6 節對全文進行總結.

Fig.1 The scale variance of the objects within different images or one image in object detection task圖1 目標檢測任務中不同圖像或同一圖像內的目標存在的尺度差異
1 背景知識
1.1 基于深度學習的目標檢測主流算法
本節將對基于深度學習的目標檢測算法中的兩階段算法和一階段算法這兩大主要流派的發展歷史進行簡要回顧.兩階段算法首先通過啟發式方法或者卷積神經網絡生成一系列可能存在潛在目標的候選區域,然后根據候選區域的特征對每一個區域進行分類和邊界回歸.一階段算法則省略了候選區域生成的步驟,僅使用一個卷積神經網絡直接完成整張圖像上所有目標的定位與分類.兩種流派各有優勢:兩階段算法相對而言精度更高,尤其體現在定位上;而一階段算法的速度普遍更快,更容易滿足實際應用場景中的實時性需求.
1.1.1 兩階段算法
傳統目標檢測算法的流程主要包括候選框生成、特征提取和目標分類這3 個步驟,而兩階段算法正是在傳統算法的基礎上一步步演化而來的.2014 年,Girshick 等人[8]提出的R-CNN 算法,在PASCAL VOC 數據集[9]上以絕對優勢擊敗了經典的DPM 算法[10],開啟了基于深度學習的兩階段目標檢測算法的先河.R-CNN 算法包括3個模塊:(1) 采用選擇性搜索[17]生成可能包含潛在目標的候選區域;(2) 將所有候選區域采樣至某一固定分辨率后,逐一輸入卷積神經網絡,提取出固定長度的特征向量;(3) 采用多個支持向量機對所有特征向量進行分類.最后,作者還額外增加了一個矩形框回歸的步驟:根據已知類別和提取出的特征向量,對矩形框進行回歸修正,從而進一步提高定位精度.相較于傳統算法,R-CNN 的最大創新點在于不再需要人工設計特征算子,而是引入卷積神經網絡自動學習如何更好地提取特征,實驗結果也表明這樣做是更有效的.但是,R-CNN 算法本身存在很多缺陷:(1) 雖然在提取特征向量時使用了CNN,但生成候選區域采用的選擇性搜索算法仍然還是基于底層視覺特征,因此候選框質量不高;(2) 算法的3 個模塊是相互獨立的,導致訓練過程繁瑣,無法實現端到端的訓練,且不能獲得全局最優解;(3) 在提取特征向量時,每個候選區域都會被單獨地從原圖上裁剪下來,再依次輸入神經網絡,這樣做既占用了大量磁盤空間,也帶來了很多重復性計算,導致訓練速度和推斷速度都非常緩慢.
為了解決R-CNN 算法的這些缺陷,后續出現了一系列算法對其進行改進.He 等人[18]意識到,卷積層本身并不限制輸入圖像的分辨率,R-CNN 之所以在提取特征向量前需要統一候選區域的尺寸,是因為CNN 最后的全連接層只能處理固定尺寸的輸入.于是,為了避免重復運算,他們提出的SPP-Net 不再是將候選區域依次通入CNN,而是直接計算整張圖的特征圖,然后劃分出每一個候選區域的特征.在全連接層之前,為了統一特征向量的長度,他們新增了一個SPP 層,通過池化操作將任意輸入都轉化為固定長度的輸出.由此可以看出,相較于R-CNN,SPP-Net 最大的貢獻在于顯著加速了訓練和推斷的過程.但是,SPP-Net 的精度與R-CNN 并無明顯差別,而且它的算法流程依舊是獨立的多個模塊,保存特征向量依舊需要大量存儲空間.于是,Girshick 在此基礎上,又提出了Fast R-CNN[19].Fast R-CNN 吸納了SPP-Net 的思想,對整張圖進行一次性的特征計算,新提出的RoI 池化層相當于SPP 層的簡化版.除此以外,Fast R-CNN 為了簡化流程,不再使用支持向量機進行分類,也不再使用額外的回歸器,而是設計了多任務損失函數,直接訓練CNN 在兩個新的網絡分支上分別進行分類和回歸.這也正是Fast R-CNN 最大的創新:將特征提取、分類、回歸整合為了一步,這樣就不再需要中途保存特征向量,從而解決了存儲空間的問題;而且在訓練時能夠進行整體的優化,因此取得了更高的精度.
Fast R-CNN 雖然成功地將分類和回歸也整合進了神經網絡,但距離真正的端到端訓練還差一步:候選框的生成依舊是完全獨立的.選擇性搜索等傳統算法是基于圖像的底層視覺特征直接生成候選區域,無法根據具體的數據集進行學習.而且,選擇性搜索非常耗時,在CPU 上處理一張圖像需要2s.即便是當時能夠最好地權衡候選框的生成質量與速度的EdgeBoxes 算法[20],處理一張圖像也需要0.2s,與Fast R-CNN 的神經網絡部分的耗時差不多[21].因此,Ren 等人[21]再次對Fast R-CNN 進行改進,提出了Faster R-CNN 算法.該算法最大的創新點在于設計了RPN 這樣一個候選框生成網絡.RPN 有兩大創新:(1) RPN 的輸入是已有的Fast R-CNN 的骨架網絡所提取的整張圖像的特征圖,這種共享特征的設計既充分利用了CNN 的特征提取能力,又節省了運算;(2) 提出了錨點(anchor)概念,RPN 基于預先設定好尺寸的錨點進行分類(前景或背景)和回歸,既確保了多尺度的候選框的生成,也讓模型更易于收斂.RPN 生成候選區域之后,算法的剩余部分就和Fast R-CNN 一致了.正因為有了RPN 取代選擇性搜索算法,Faster R-CNN 最終在GPU 上的檢測速度達到了5FPS,打破了PASCAL VOC 數據集的記錄.同時,它還是第一個真正實現了端到端訓練的檢測算法,標志著兩階段檢測器的正式成型.
自Faster R-CNN 問世之后,新誕生的兩階段檢測器幾乎都以它為雛形.Dai 等人[22]提出的R-FCN 為了進一步提高Faster R-CNN 的效率,去除了各分支獨立的計算耗時的全連接層,設計了位置敏感得分圖和位置敏感RoI 池化層來保留空間信息,顯著提高了推斷速度與精度.Lin 等人[23]考慮到網絡深層特征有較強的語義信息,而淺層特征有較強的空間信息,于是提出了將深層特征圖通過多次上采樣和淺層特征圖逐一結合的FPN 架構,基于多層融合后的特征圖進行輸出,能夠更好地檢測到不同尺度的目標,是多尺度目標檢測的里程碑.He 等人[24]提出的Mask R-CNN 在Faster R-CNN 的基礎上將RoI 池化層替換成了RoI 對齊層,使得特征圖和原圖像素能對齊得更精準,并新增了一個掩膜分支,用于實例分割.令人驚訝的是,該算法不僅在實例分割任務上取得了優秀表現,對分類、回歸、掩膜分支同時進行多任務訓練也提高了目標檢測任務的性能.Qin 等人[25]則提出了輕量級的二階段檢測器ThunderNet:通過為檢測任務定制輕量級骨架網絡SNet、對RPN 和檢測頭進行壓縮以及引入CEM、SAM 等模塊,讓模型在速度和精度方面超越了不少一階段檢測器.
1.1.2 一階段算法
從Faster R-CNN 開始的二階段算法雖然已經實現了端到端訓練的完整流程,但是與真正滿足實時性需求仍有相當大的差距.因此,以YOLO 算法[14]為代表的一階段檢測器便登上了舞臺.這一類算法不再單獨設計生成候選區域的初始階段,而是在整張圖像上一次性完成所有目標的定位與分類.Sermanent 等人[26]于2013 年提出的OverFeat 是最早的一階段檢測器.雖然它的精度不如同期R-CNN,但其思想很有前瞻性:(1) 采用卷積層替代全連接層實現全卷積神經網絡,適應不同分辨率的圖像作為輸入,相當于用卷積來快速實現滑動窗口算法;(2) 采用同一個卷積神經網絡作為共享的骨架網絡,通過更改網絡頭部分別實現分類、定位和檢測任務,這使得OverFeat 比R-CNN 的檢測速度快了9 倍[8].2015 年,Redmon 等人[14]提出的YOLO 算法則真正地實現了實時性目標檢測.其核心思想是將目標檢測視為一個回歸任務,算法流程十分簡潔:將輸入圖像劃分為7×7 的網格,每一個網格負責預測中心點處于該網格內的目標,回歸中心點相對于網格的位置、目標的長寬和類別.YOLO 的損失函數由定位損失、置信度損失、分類損失這3 部分組成,其中,置信度是指是否存在目標.可以看到,YOLO 是一種端到端的算法,沒有候選框這一概念,輸入一張圖片,在檢測到前景的同時就回歸得到了需要的屬性.從實驗結果來看,YOLO 的檢測速度能夠達到45FPS,Fast YOLO 甚至能到155FPS,比二階段檢測器快了一個數量級.除此以外,YOLO 在檢測時考慮了更多的背景信息,因此將背景誤判為前景的概率比Fast R-CNN 要低很多[14].當然,YOLO 也存在一些明顯的缺陷:(1) 每一個網格只檢測兩個目標,且規定為同一類別,導致算法難以處理密集目標的檢測;(2) 精度比Fast R-CNN要差,尤其體現在定位上,主要原因在于,后者經過了從整體到局部的兩次矩形框回歸,而YOLO 只經過了一次;(3) 由于全連接層的存在,輸入圖像的分辨率是固定的;(4) 只在單張特征圖上檢測目標,導致算法難以駕馭多尺度目標的檢測.
YOLO 誕生之后,更多的一階段檢測器也相繼問世.Liu 等人[15]提出的SSD 算法繼承了YOLO 的核心思想,而主要的不同之處在于:(1) 訓練網絡在多個不同深度的特征層上預測不同尺度的目標,最后進行整合;(2) 引入Faster R-CNN[21]的錨點概念,使模型更容易收斂,保證不同感受野的特征圖適應不同尺度的目標檢測;(3) 使用全卷積神經網絡,適應不同分辨率的圖像輸入;(4) 損失函數由定位損失和分類損失組成,沒有YOLO 的前景置信度這一概念,因為它在分類時直接將背景也視為一個類別,與其他類別同時進行預測.此外,SSD 在特征圖上鋪設了密集的錨點,而有效匹配目標的錨點個數是很有意義的,若直接采用所有樣本進行訓練,會存在嚴重的正負樣本不平衡問題.于是,SSD 采用了難例挖掘的手段來緩解這一問題.從實驗結果來看,SSD 的檢測速度能和YOLO 媲美,而精度能夠匹敵Faster R-CNN.不過,雖然SSD 在多層特征圖進行預測,但是相對于Faster R-CNN,小目標的檢測結果并未能夠得到明顯的改善.其主要原因可能在于,淺層的特征層雖然有著較小的感受野,但特征表示能力相對于深層特征要弱很多.
對原始的YOLO 進行全面升級之后,Redmon 等人[27]推出了YOLOv2.YOLOv2 做出了一系列改進:(1) 對所有的卷積層引入批量標準化;(2) 統一預訓練與實際訓練的圖像分辨率;(3) 去除全連接層,引入錨點作為預測目標尺寸的參照物,錨點的尺寸通過k-means 聚類來確定;(4) 設計了passthrough 層,將不同層的特征圖拼接在了一起,基于更豐富的特征進行預測;(5) 采用多尺度訓練,使模型更魯棒;(6) 設計了Darknet-19 作為骨架網絡,加快了速度.可以看到,YOLOv2 吸取了很多深度學習的技巧,最終在速度、精度上均得到提高.此外,Redmon 等人還同時提出了YOLO 9000,采用樹的形式將ImageNet 分類數據集和COCO 檢測數據集的目標類別進行合并,通過聯合訓練分類任務和檢測任務,讓模型最終能夠檢測超過9 000 種目標.YOLO 9000 的思想是想要消除分類和檢測數據集在數據量上的鴻溝,這對于檢測任務的拓展性有很大幫助.
新誕生的這一系列一階段檢測器雖然普遍有著絕對的速度優勢,但與頂尖的二階段檢測器相比仍然存在著不可忽視的精度差距.Lin 等人[28]認為,兩類算法最本質的區別在于,后者通過對候選框的篩選,保證了第2 階段訓練樣本的高質量和類別的均衡,而前者必須在圖像上每一個滑動窗口處進行預測,換言之,即存在嚴重的正負樣本不均衡和難易樣本不均衡問題.因此,他們為一階段檢測器設計了新的損失函數Focal Loss.Focal Loss 在交叉熵損失函數的基礎上引入了兩個新的參數,一個用于降低負樣本的權重,另一個用于降低簡單樣本的權重,讓模型在訓練時能夠避免被一階段算法存在的大量負樣本、簡單樣本轉移注意力.實驗測試中,作者采用ResNet 和特征金字塔網絡架構設計了簡單的一階段檢測器RetinaNet,并應用Focal Loss 進行訓練,最終在MS COCO 測試集上展現出了超越Faster R-CNN 的精度的能力,尤其體現在小樣本的檢測上.
YOLOv2 之后,Redmon 等人再次對其進行升級,提出了YOLOv3[29].YOLOv3 主要有3 個改進點:(1) 采用多個邏輯回歸分類器取代softmax 分類器,使模型能夠適用于類別間存在交集的分類任務;(2) 引入特征金字塔網絡架構,對最深層特征圖進行兩次上采樣,分別與淺層特征相融合,最后在3 個特征層上設置不同的錨點,預測不同尺度的目標;(3) 學習殘差網絡的思想,設計了Darknet-53 作為新的骨架網絡,在精度上可與Resnet-101、ResNet152 相匹敵,而且速度更快.YOLOv3 在當時實現了最好的速度與精度的權衡,也是目前工業界目標檢測的首選算法之一.
近年來,在“舍棄錨點(anchor-free)”的潮流之下,除了對傳統的錨點策略進行反思與改進的算法之外[30-32],還有另外一系列基于關鍵點檢測的一階段目標檢測算法涌現出來.Law 等人提出的CornerNet[33]通過檢測矩形框的左上和右下成對的角點來確定目標.Zhou 等人提出的CenterNet[34]則更進一步,只檢測目標的中心點位置,然后通過回歸不同的屬性(目標的長寬、深度、方向等),將目標檢測、3D 目標檢測、姿態估計等多項視覺任務進行了統一.將目標檢測問題轉換為關鍵點檢測問題之后,就可以使用Hourglass[35]等下采樣系數更小的關鍵點檢測網絡以保留更多的空間信息.由此可見,在不同的計算機視覺任務之間進行算法遷移,同樣是一個重要的研究方向.
1.2 目標檢測的尺度問題
為了對目標的尺度進行量化,通常以目標實例所占面積(即掩膜所占的像素數量)除以所在圖像的面積并開方得到的結果作為該目標實例的相對尺度(介于0~1 之間),簡稱尺度.因此,不同圖像中的目標的相對尺度存在很大差異,或同一張圖像中的多個目標的尺寸存在較大差異,這一狀況即被稱為尺度問題,一直以來都是影響目標檢測任務精度的最核心的挑戰之一,即便是進入深度學習時代也同樣如此.MS COCO 數據集[16]是目前目標檢測領域最常用的基準數據集之一,很適用于對算法的多尺度目標檢測能力進行綜合評估,主要基于以下幾點原因.
(1) 數據集包含了80 種不同類別的目標,覆蓋范圍廣,場景跨度大;
(2) 根據尺度對數據集中的所有目標實例進行排序后,得到的尺度分布曲線如圖2 所示,可見,最小的10%目標的尺度均小于0.020 7,最大的10%目標的尺度都超過了0.345,尺度跨度極大,因此,COCO 數據集非常考驗模型的多尺度目標檢測能力;
(3) 在數據集的評價指標中,將面積小于32×32 的實例視為小目標,大于96×96 的實例視為大目標,剩下的實例視為中等目標.因此,在評價模型時除了給出整體的準確率、召回率之外,數據集還會分別計算并給出小、中、大目標3 種情況下的準確率和召回率,這有利于直觀地看出模型在面對不同尺度目標時的檢測能力.

Fig.2 The scale distribution curve of the instances among MS COCO detection dataset圖2 MS COCO 檢測數據集的目標實例的尺度分布曲線
表1 中列舉了一些目標檢測算法在MS COCO 測試集上的檢測結果,“++”符號表示模型在推斷時使用了圖像金字塔.其中,AP 是指當IoU 閾值分別為0.50:0.05:0.95 時的平均準確率,AP50 和AP75 分別是IoU 閾值為0.50和0.75 的準確率,APS、APM、APL 分別指小、中、大目標的AP.從表1 中的數據可以看出,早期的SSD、YOLOv2、FPN 等檢測器的小目標的檢測精度都不到中、大目標的精度的一半.近兩年的檢測器在尺度問題上有所改善,但小目標的精度仍然與中、大目標的精度有著顯而易見的差距,這嚴重影響了整體精度的提高.因此,如何讓檢測器能夠更好地應對不同尺度的目標(尤其是小目標),仍是當今目標檢測研究的一個重要難題.
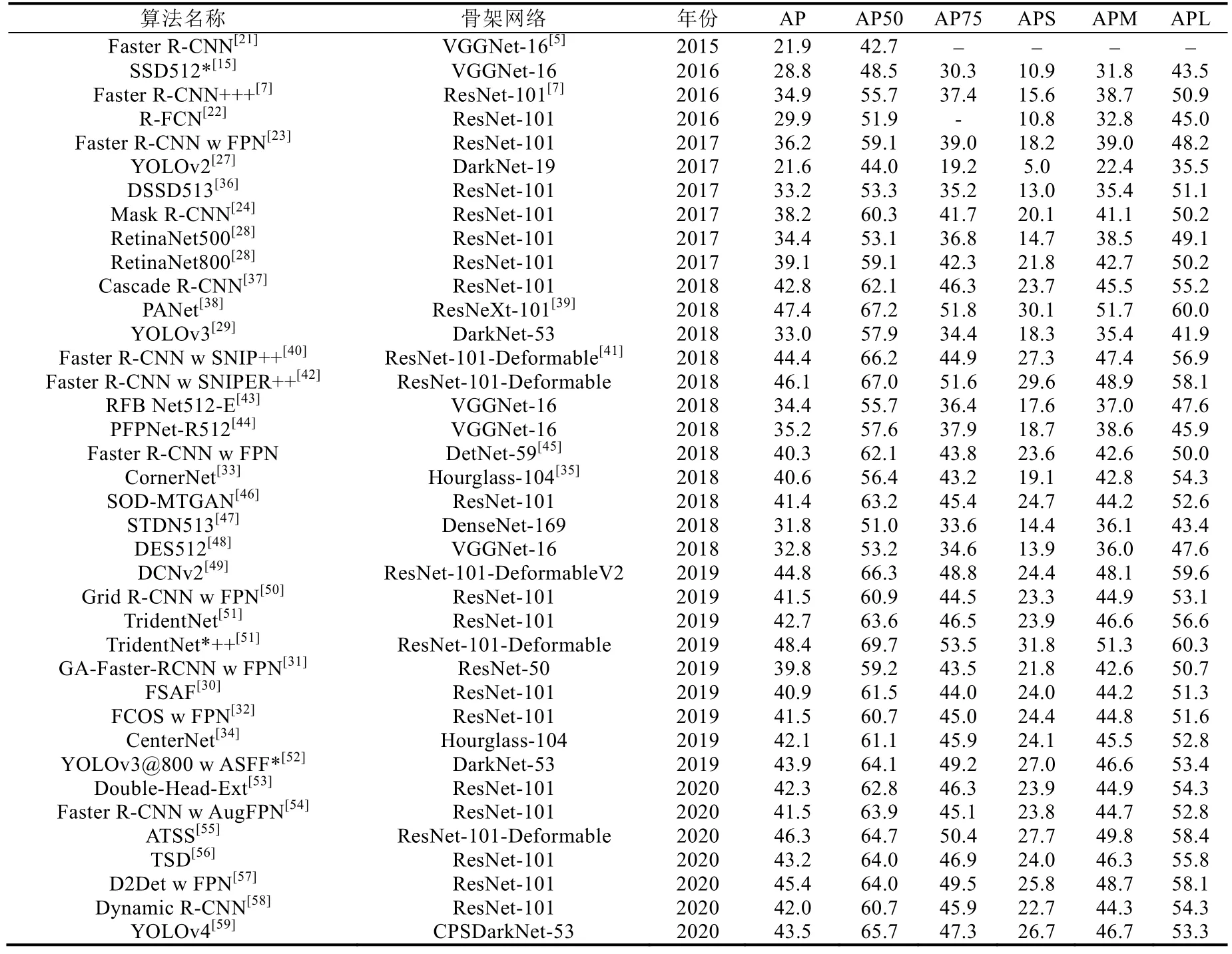
Table 1 Detection performance on the MS COCO TEST-DEV dataset表1 目標檢測算法在MS COCO 測試集上的檢測性能
檢測器在面對尺度跨度較大的數據集時會表現不佳的根本原因在于,卷積神經網絡在不斷加深的過程中,表達抽象特征的能力越來越強,淺層的空間信息也相對丟失.以基于ResNet-50 的Faster R-CNN 為例,在檢測包含多尺度目標的圖像時,可以看到圖3(a)中遠處較小的人沒有被檢測到.為了能直觀地進行分析,圖3 對骨架網絡ResNet-50 逐層提取出的特征進行了可視化,可以觀察到,淺層網絡提取出的特征包含了邊緣等空間信息,隨著網絡的加深,特征逐漸抽象化,空間信息也不斷丟失,圖3(a)中沒有檢測到的那個人的特征早已經無法分辨.此外,由于目標檢測任務包含了目標分類和目標定位這兩個子任務,因此在檢測尺度較大、細節特征豐富的目標時,需要更強的語義信息作為分類依據;在檢測尺度較小、偏差容忍度較小的目標時,則需要更細粒度的空間信息以實現精確定位.因此,要解決尺度問題,最常見的思路是構建多尺度的特征表達,常用的方法包括:(1) 輸入圖像金字塔提取不同尺度的特征;(2) 在網絡內部融合不同深度的特征層,構建特征金字塔;(3) 在網絡內部設計并行支路,構建空間金字塔.除此以外,也有對錨點策略進行反思和對小目標進行特征重建等其他方法來緩解尺度問題.下文將從這些方面對已有算法進行概述.本文關于實驗結果的陳述,若不明確強調數據集,則默認是在MS COCO 數據集上進行測試得到的結果.
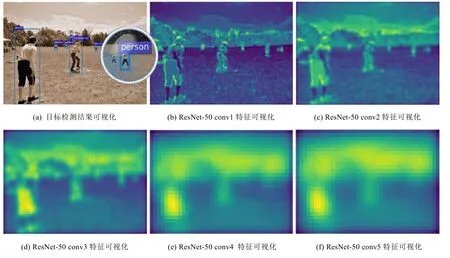
Fig.3 The visualization of detection results and backbone network features of ResNet-50-based Faster R-CNN圖3 Faster R-CNN 目標檢測結果及骨架網絡ResNet-50 特征可視化
2 基于圖像金字塔的多尺度目標檢測
同一張圖像,在低分辨率下能看到整體的輪廓,在高分辨率下能看清更多的細節,這正是圖像金字塔的基本原理.早在目標檢測進入深度學習時代之前,圖像金字塔就已成為一種通用的提高檢測精度的手段,比如用同樣大小的滑動窗口在不同尺度的圖像上進行特征提取.而神經網絡的本質也是特征感知,因此圖像金字塔同樣適用于神經網絡,如下文中圖4(a)所示.在訓練階段,隨機輸入不同尺度的圖像,能夠強迫神經網絡適應不同尺度的目標檢測;在測試階段,對同一張圖像以不同的尺度進行多次檢測,最后采用非極大值抑制算法整合所有結果,能夠使檢測器覆蓋盡可能大的尺度范圍內的目標.實驗結果表明,圖像金字塔的引入的確能夠在一定程度上提升整體精度,但其弊端也十分明顯:高分辨率的圖像輸入既會增大內存開銷,也會增加計算耗時.這不僅會導致訓練時難以使用較大的批尺寸,影響了模型精度,同時成倍增加的推斷時間還會進一步抬高將算法投入實際應用的門檻.因此,最原始的圖像金字塔的實用價值可以說是十分有限的.
2.1 基于尺度生成網絡的圖像金字塔
Hao 等人[60]在將圖像金字塔運用于人臉檢測時注意到一個問題:在進行多尺度檢測時,金字塔的很多層實際上是沒有檢測到有效目標的,即存在著明顯的資源浪費.其原因在于,每一張圖像的目標的尺度分布都存在著顯著差別:有的圖像可能只有一種尺度的目標,因此實際只需要對金字塔的某一層進行檢測;有的圖像可能只有中等目標和大目標,因此金字塔里分辨率最高的那一層其實是不需要的,而那恰好是計算開銷最大的一層.為了提高檢測效率,他們認為:在正式進行目標檢測之前,若能先判斷圖像內目標的尺度分布情況,就能去除圖像金字塔中冗余的層,而且在已知目標尺度的情況下還可以對后續檢測作進一步的優化.因此,他們設計了一個尺度生成網絡,將原本的目標檢測任務拆分成尺度估計和單一尺度的目標檢測這兩步,如圖4(b)所示.尺度生成網絡顧名思義,是用于估計圖像里的被檢測目標的尺度分布.該網絡基于圖像級別的監督信號進行訓練,輸出尺度直方圖向量,經過均值濾波和一維的非極大值抑制操作后就能夠得到離散的目標尺度分布.由于已知目標尺度,因此后續的檢測器只需檢測單一尺度的目標,所以可以將RPN 的錨點的尺寸數縮減為1,這樣就能在不影響精度的前提下進一步提高檢測速度.最后,將圖像依次采樣至目標尺度所對應的分辨率,再輪流進行檢測,最后對所有結果進行匯總,就完成了多尺度目標的檢測.從實驗結果來看,該算法針對FDDB[61]、AFW[62]和MALF[63]數據集無論是在速度還是在精度上均超越了原版RPN.
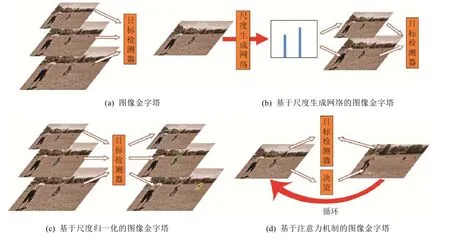
Fig.4 Overview of the image-pyramid-based multi-scale object detection圖4 基于圖像金字塔的多尺度目標檢測總覽
從本質上講,尺度生成網絡其實是提供了構建圖像金字塔的參考意見,讓金字塔的層數和每一層的分辨率都更適應于具體圖像,有效提高了算法的檢測效率.值得深究的一點是,為什么卷積神經網絡固定的感受野不適用于多尺度目標檢測,但卻可以估計出圖像中目標的尺度分布呢?作者基于尺度生成網絡的響應圖,給出的解釋是,對于人臉檢測,即便是感受野受限,比如只能看清眼睛,也能根據眼睛的尺度相對估計出整張臉的尺度.不過,人臉檢測有其特殊性,在面對目標類型更豐富的通用目標檢測任務時,該算法的思路是否仍然適用,需要進一步的實驗驗證.
2.2 基于尺度歸一化的圖像金字塔
Singh 等人[40]就MS COCO 數據集中大量的小目標帶來的挑戰,采用不同的訓練策略對Faster R-CNN 算法做了詳細的對照實驗,最后測試小目標的檢測精度.常規訓練策略是以800×1200 的分辨率進行訓練,測試時則采用1400×2000 的分辨率.以該策略為參照,他們在實驗中發現:若將訓練集上采樣至1400×2000,最后測試時小目標的精度有所提升但十分微弱,可能是由于本來很大的目標經過上采樣后變得更大,干擾了模型對小目標的學習;若同樣對訓練集上采樣,但只讓模型檢測小目標,超出小目標尺度范圍的標簽則無視,模型精度卻嚴重下降,這很有可能是因為大量的訓練數據的丟失帶來了更嚴重的負面效果;若采用隨機多尺度訓練策略,精度卻幾乎沒有變化,原因或許是上采樣會導致大的目標可能更大、下采樣會導致小的目標可能更小,于是帶來了更加極端的尺度變化,不利于模型學習.綜合這幾組實驗,他們得出的結論是:極端尺度的目標不利于訓練,所有的訓練樣本都應該參與訓練.因此,他們最終提出了名為尺度歸一化圖像金字塔(簡稱SNIP)的訓練策略:采用圖像金字塔訓練模型,但是每一層都只提供合適的尺度范圍內的監督信號,如圖4(c)所示.這樣做的根本目的是讓模型專注于檢測某一尺度范圍內的目標,同時又通過金字塔的方式保證所有的訓練數據都能夠被學習.最后,在驗證模型時同樣采用圖像金字塔.該策略可同時應用于Faster R-CNN 的兩個階段,并對所有尺度的目標的檢測精度帶來全方位的提升.可以說,SNIP 本質上是基于CNN 的固有缺陷對傳統的多尺度訓練策略的一個改進,將圖像金字塔的優勢發揮到了極致.不過,該訓練策略并未能夠解決圖像金字塔的內存與時間開銷問題.
之后,Singh 等人將SNIP 升級為SNIPER[42].為了能夠解決圖像金字塔在訓練時的內存限制問題,SNIPER不再是對完整的圖像進行訓練,而是從金字塔的每一層中裁剪出分辨率固定為512×512 的碎片作為訓練單元.其中,在不同層上以碎片大小為網格單元,選擇囊括了該尺度下有效目標的網格作為碎片,即為訓練時的正樣本.而為了防止檢測器將背景誤判為目標,Singh 等人也將包含了若干假正例的碎片作為負樣本,共同參與訓練.由于碎片的分辨率較小,從而有效解決了圖像金字塔的內存問題,在訓練時可以使用更大的批尺寸,這樣既加快了訓練速度,也提高了模型的檢測精度.不過,在實際應用模型檢測目標時,仍然必須通入完整的圖像金字塔,因此,推斷的計算耗時問題還有待解決.
2.3 基于注意力機制的圖像金字塔
有一系列文獻基于注意力機制的思想,通過引入放大操作,重點關注圖的某個區域,以自適應的方式實現多尺度目標檢測.最早在深度學習目標檢測中引入放大操作的是Lu 等人提出的AZ-Net[64].他們認為,RPN 網絡的錨點策略本質上是一個固定了滑動窗口大小的窮舉算法,效率既不高,對多尺度的目標也不具備適用性.因此,他們設計了一種自適應搜索的候選區域生成算法AZ-Net.算法以整張圖像作為搜索起點,提供鄰接區域預測和放大指示器兩種輸出,前者是指與該搜索區域尺度接近的一系列候選區域,后者是用于指示當前搜索區域內是否存在更小的目標.若存在,則將整張圖像分為左上、左下、右上、右下、中間這5 個區域,依次作為新的搜索起點,直到所有區域都不再包含小目標為止.在PASCAL VOC 數據集上的實驗結果表明,該算法生成的候選區域比RPN 網絡生成的候選區域數量更少但質量更高.不過,精度優勢并不明顯.其原因有兩點:一是算法的自適應優勢在單個數據集上體現得不夠明顯,二是算法的遞歸搜索操作始終是在原始圖像經過CNN 后提取出的特征圖上進行,沒有引入更細粒度的特征.不過,該算法仍舊提供了一個很好的解決尺度問題的思路.
Gao 等人[65]延續了AZ-Net 的搜索的思想,通過引入具有決策能力的強化學習,設計了一個由粗到精的策略來檢測高分辨率圖像中的目標:首先用一個粗糙的Fast R-CNN 對下采樣后的低分辨率圖像進行檢測,生成準確率提升概率圖,然后利用強化學習找到有可能包含小目標的區域,采用更精細的檢測器對高分辨率的這一區域進行目標檢測,同時將該區域作為新的算法輸入,再次通入粗糙檢測器,如此循環,直到不再包含小目標.實驗結果表明,在幾乎未損失精度的前提下,該算法在Caltech 行人檢測數據集[66]上的像素處理數量減少了50%、推斷時間縮短了25%,在YFCC100M 數據集[67]上的像素處理數量減少了70%、推斷時間縮短了50%.Uzkent 等人[68]延續了Gao 等人的做法,同樣是引入強化學習選擇圖像中需進一步查看的區域,不過其區別在于,算法還會判斷該區域是由大目標主導還是小目標主導,然后分別通過兩種不同尺度的檢測器進行檢測,其目的在于進一步節省計算量.在xView 遙感圖像數據集[69]上所進行的實驗結果表明,算法相對于直接在高分辨率原圖上進行檢測的檢測器而言,效率提升了50%,精度卻幾乎沒有下降.總的來說,這些算法都是源于注意力機制的思想,將多尺度目標檢測視為由粗到細、從整體到細節的遞歸過程(基本流程如圖4(d)所示),并且拓寬了目標檢測算法的邊界,引出了高分辨率圖像、深度強化學習等新的方向.除此以外,這些算法同樣可以看作是對圖像金字塔的優化:從金字塔的最頂端開始檢測,并利用強化學習判斷金字塔的下一層中的哪一部分區域存在潛在目標,如此循環,直到下一層不再包括目標為止.所以,算法相當于利用強化學習的決策能力做引導,去除了圖像金字塔的冗余部分,解決了SNIPER 策略中仍然存在的推斷時計算耗時這一嚴重的問題.
3 基于網絡內特征金字塔的多尺度目標檢測
早期以R-CNN[8]為代表的檢測器直接在神經網絡的最后一層特征圖上進行預測,由于細粒度空間特征的缺失,對小目標的檢測效果不佳,因此需尋求多尺度的特征表示.圖像金字塔雖能基于不同分辨率的輸入提取不同尺度的特征,但也會帶來嚴重的內存和時間開銷問題,不具備適用性.因此,如果能在卷積神經網絡內部構建多尺度的特征表示,就能夠在只輸入一次圖像的情況下近似地得到圖像金字塔所能提取的多尺度特征,且計算代價要小得多.現階段主要通過以下兩種方式構建網絡內的特征金字塔:(1) 基于跨層連接融合網絡內不同深度的特征圖,得到不同尺度的特征表示;(2) 基于感受野不同的并行支路,構建空間金字塔.
3.1 基于跨層連接構建特征金字塔
3.1.1 特征金字塔網絡
考慮到卷積神經網絡層層相疊的結構,越深的特征圖,其感受野越大,因此,網絡內不同深度的特征圖就形成了天然的多尺度表達,于是SSD 算法[15]和MS-CNN 算法[70]即被提出,可以直接在這些不同尺度的特征圖上分別檢測目標并最后進行整合,其中,淺層特征圖負責檢測小目標,深層特征圖負責檢測大目標.但是,從實驗結果來看,小目標的檢測精度卻并未得到明顯改善.究其根本原因在于,這些特征層因為深度各不相同,特征表示能力也各不相同,存在著顯著的語義鴻溝.淺層特征層雖然保留了更為細粒度的空間信息,但特征表示能力太弱,缺少有效的語義信息,所以檢測效果差.因此,直接在網絡內不同深度的特征圖上預測不同尺度的目標是不合適的,需要首先構建出每一層都具有足夠特征信息的特征金字塔.
針對SSD 算法存在的缺陷,Lin 等人提出了著名的特征金字塔網絡FPN[23],其基本思想在于結合淺層特征圖的細粒度空間信息和深層特征圖的語義信息對多尺度的目標進行檢測,網絡結構如下文圖6(a)所示.算法在RPN 網絡的基礎上,額外增加了一條由上至下的側路:從最深層特征圖開始,經過1×1 卷積與上采樣之后,與淺層特征層對齊,然后通過對應元素相加的方式融合得到新的特征圖,以此類推,將新得到的特征圖再進行1×1 卷積與上采樣,就能與更加淺層的特征圖相融合.最終,FPN 網絡內便成功構建了一個每一層都具備多層特征信息的5 層特征金字塔.然后,在特征金字塔的每一層上分別預測相應尺度的目標,整合之后便得到了最終的檢測結果.原版RPN 在特征圖上每一點處都有3 個尺度的錨點,FPN 由于特征金字塔每一層只需要預測單一尺度范圍的目標,因此所有層均只設置一種尺度的錨點.實驗結果表明,該網絡結構雖在一定程度上削弱了模型檢測大目標的能力,卻顯著提高了小目標檢測的精度,整體性能甚至超越了采用圖像金字塔進行推斷的Faster R-CNN,且能夠保證6FPS 的檢測速度.由此可見,FPN 在代價較小的前提下,有效提升了檢測網絡對于多尺度目標的適應性.該網絡結構如今已成為目標檢測領域在處理多尺度問題時的通用網絡架構,而且還被推廣到了其他的計算機視覺任務上(例如實例分割).與FPN 同期誕生的DSSD 算法[36]也是基于類似的思想融合不同深度的特征,但區別在于DSSD 是通過反卷積操作提升特征圖分辨率,而非雙線性插值.
為了對FPN 提出的特征融合的效果有一個直觀的認識,下文圖5 中以熱度圖的形式展示了采用FPN 架構的YOLOv3 網絡在處理包含較小尺度的目標的部分圖像時,淺層特征在融合深層特征前后的可視化對比情況.可以明顯看出,圖5(a)中整張圖都是密集的響應,語義信息強和弱的區域沒有明顯區分性,這也反映了為什么SSD 算法直接利用淺層特征預測小目標的表現不佳;圖5(b)中,在深層特征的影響下,熱度明顯聚焦到了圖中的小目標上,受背景干擾的影響小了很多,這體現了FPN 架構對于小目標檢測的優勢.
3.1.2 改進特征金字塔網絡的特征融合
FPN 的核心思想在于融合網絡內部的不同深度的特征信息,但是,由上至下逐層融合的結構是值得商榷的,因此出現了一系列對此進行討論和改進的算法.Liu 等人[38]認為:(1) FPN 雖然將深層語義特征用于構建金字塔的每一層,但是由于網絡加深的過程中淺層特征不斷丟失,導致金字塔頂端的特征層缺少空間信息,這不利于精確的目標定位;(2) 根據目標的尺度將其分配到金字塔的某一層進行預測,這個策略并非最優,因為沒有考慮到其他特征層可能存在的有用信息.因此,他們提出了PANet,特征金字塔部分的結構如圖6(b)所示.可以看出,PANet 從FPN 已經構建的特征金字塔的最底層開始,又增加了一條自底向上的特征再融合的側路,重新構建了一個強化了空間信息的金字塔.然后,將RoI 對齊操作應用于金字塔的每一層,再將對齊后的特征層通過取最大值來進行融合,最終在融合的特征圖上進行檢測,就保證了每一個目標的預測都充分利用了所有特征層的信息.實驗跟蹤了PANet 的每一個候選區域的融合后特征所對應的原特征金字塔的層數,可以發現,大約有70%的特征都來自于其他尺度的特征層,只有30%來自于尺度最接近的某一特征層,這證明了特征融合的必要性.最終,該算法取得了當年MS COCO 實例分割挑戰的第1 名和目標檢測挑戰的第2 名.

Fig.5 The comparison of the visualizations of the shallow features of YOLOv3 detector under circumstances whether concatenating deep features or not圖5 對比YOLOv3 淺層特征在融合深層特征前后的可視化
Kong 等人[71]認為FPN 的特征融合本質上相當于特征層的線性組合,難以勝任高度非線性的識別任務.因此,為了讓網絡能夠更靈活地學習每一特征層的關鍵信息,他們提出了一種新的構建特征金字塔的方式:將不同深度的特征層拼接在一起后,采用SENet[72]的SE 模塊添加全局注意力,再通過一個殘差模塊實現局部重構,最后完成新的特征層的構建.如此重復,便構造出了特征金字塔,結構如圖6(c)所示.全局注意力和局部重構這兩個輕量級模塊可以被任意嵌入到不同網絡中,實驗中分別將其運用在了Faster R-CNN 和SSD 上,均提高了模型的整體性能.
Pang 等人[73]認為金字塔的每一層應該相對平衡地兼顧所有特征層的信息.但是,無論是FPN 還是PANet,在構建金字塔時都是通過從上至下或自底向上的側路逐層傳遞特征,這個過程勢必會導致信息的不斷流失,于是金字塔每一層的信息都主要來源于相鄰的特征圖,因為較遠的特征圖的信息已經被稀釋.所以,他們提出的Libra R-CNN 將特征金字塔的多層特征統一為中間層尺度后,計算它們的平均特征,然后通過non-local 模塊[74]對特征進行加強,最后將其疊加于原本的特征金字塔的每一層,如圖6(d)所示.實驗中,將該架構應用于FPN 和PANet 后,模型在MS COCO 數據集上都提升了0.9 的精度.
Liu 等人[52]同樣對FPN 進行了反思,認為每一特征層之間存在的不一致性限制了一階段檢測器的性能.例如,某一目標若被分配給了某一特征層進行預測,那么該目標在其他特征層上的相應區域相當于被視為了背景,而這顯然是不合理的.部分學者為此將鄰接特征層的相關區域的梯度置零[30,31],但這種矯枉過正的做法可能會讓鄰接特征層的檢測質量下降.因此,他們提出了自適應空間特征融合算法(簡稱ASFF):將原特征金字塔的所有特征圖采樣至金字塔中的某一層的尺度,按照一定的權重進行線性組合得到新的特征圖,該權重由模型學習得到.有了所有尺度的特征圖后,就得到了新的特征金字塔,如圖6(e)所示.Liu 等人從梯度計算的層面證明了該方案構建的金字塔的特征一致性,在實驗中以增強版YOLOv3 作為基準線,證明了ASFF 模塊要優于簡單的特征求和或特征連接,并且沒有帶來顯著的計算開銷.
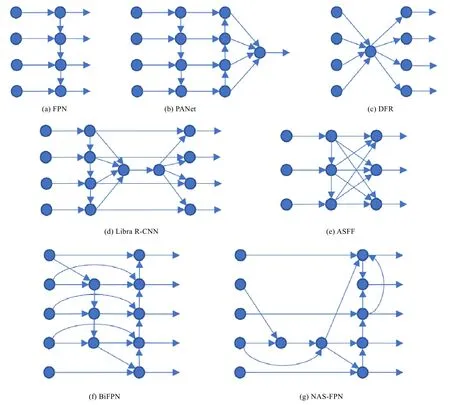
Fig.6 Overview of different ways to construct the in-network feature pyramids through cross-layer connections圖6 基于跨層連接構建網絡內特征金字塔的多種方式
Guo 等人[54]針對FPN 存在的3 個缺陷,依次提出解決方案將其升級為了AugFPN:(1) 不同特征層的語義信息是不一致的,FPN 將它們直接通過1×1 卷積后相加,勢必會削弱多尺度特征的表達能力,因此AugFPN 在訓練時會根據融合前的特征直接進行檢測并計算損失,再與網絡本身的損失進行加權求和,提供監督信號;(2) FPN采用從上至下的特征融合強化特征金字塔的語義信息,但是1×1 的卷積過程會導致最高層特征信息的損失,因此,AugFPN 對原本的最高層特征圖進行空間金字塔池化操作,對所有分支進行自適應的特征融合后,再和1×1降維后的最高層特征圖融合,彌補丟失的信息;(3) FPN 中每一個實例都是根據尺度啟發式地選擇特征層,但其他層也可能有重要的特征信息,因此,AugFPN 對每一個實例會提取出它在金字塔每一層上的特征,再讓網絡學習權重參數對這些特征進行求和,最后預測目標.AugFPN 應用在不同骨架網絡的RetinaNet 和Faster R-CNN 上后,都明顯提升了模型的精度.
Tan 等人[75]提出的EfficientDet 在PANet 的特征金字塔架構的基礎上做出了幾點改變:(1) 將只有一個輸入的節點移除,理由是未經過特征融合,對多尺度特征的貢獻較小;(2) 在同一尺度的輸入特征圖和輸出特征圖之間增加了一條連接,以融合更豐富的特征;(3) 將整個特征金字塔架構進行多次堆疊,使其具有更強大的特征表示能力.最終,得到了BiFPN 架構,如圖6(f)所示.BiFPN 同樣對特征進行加權融合,讓網絡能學習到不同輸入特征的重要性.EfficientDet 以基于神經網絡架構搜索的EfficientNet[76]作為骨架網絡,在MS COCO 數據集上取得了當時最好的精度.
PANet、Libra R-CNN 等方案都是人工設計網絡內特征金字塔的構造方式,而在2019 年,Ghaisi 等人[77]則采用神經網絡架構搜索來尋找更好的構造方案:以遞歸神經網絡作為控制器,用強化學習對其進行訓練,讓它決定每次選擇哪兩個特征層以怎樣的方式進行融合,并以某一分辨率輸出,直到填滿特征金字塔的每一層.算法最終搜索得到的NAS-FPN 的結構如圖6(g)所示,在MS COCO 數據集上相較于原版FPN 精度提升了2%~4%不等.Wang 等人[78]同樣采用神經網絡架構搜索,在FCOS 的基礎上搜索FPN 結構,與NAS-FPN 相比,增加了可變卷積,實驗中模型性能比原版FCOS 提升了1%~2%不等.
3.1.3 改進特征金字塔網絡的骨架網絡
上述文獻都是針對FPN 提出的特征融合的方式而做出改變,Li 等人[45]則是對FPN 的骨架網絡本身進行了改進.由于多數檢測器都采用分類網絡作為骨架網絡(例如ResNet),預訓練也是在分類數據集上完成,他們認為這帶來了兩個問題:(1) FPN 等檢測器引入了未參與預訓練的額外的網絡階段;(2) 骨架網絡的感受野和下采樣系數均較大,這雖然有利于圖像分類,但空間信息的缺失不利于大目標的精確定位,下采樣過程中語義信息的丟失不利于小目標的識別,即便是引入了FPN 架構也沒有解決本質問題.為此,他們專門針對檢測任務的需求設計了新的骨架網絡DetNet-59,與ResNet-50 相比,有3 點主要的區別:(1) 網絡與FPN 有著相同的階段數量,因此所有階段都可以參與預訓練;(2) 從第4 階段開始,DetNet 的下采樣系數固定為16,通道數固定為256;(3) 在殘差模塊中引入空洞卷積增加感受野.從實驗結果來看,DetNet 的參數量介于ResNet-50 和ResNet-101 之間,但在檢測任務上的性能表現要優于它們.具體到不同尺度的目標,可以看到,DetNet 尤其擅長定位大目標和尋找小目標,符合作者預期.
3.2 基于并行支路構建特征金字塔
3.2.1 構建空間金字塔
要構建多尺度的特征表達,除了使用圖像金字塔或在網絡內融合不同深度的特征層構建特征金字塔以外,還有一種方案是在網絡內設計參數不同的并行支路,每條支路基于各自的感受野提取不同空間尺度下的特征圖,進而構建出了空間金字塔.空間金字塔這一概念最早源于Lazebnik 等人[79]提出的空間金字塔對齊策略(簡稱SPM),是詞袋模型[80]的延伸:根據不同的尺度將圖像劃分成若干子塊,然后分別統計每一子塊的特征,最后匯總所有特征對圖像進行完整表達.在深度學習領域,類似的思路可以追溯到GoogLenet[6]提出的Inception 模塊,模塊內包含了4 個分支,其中,前3 個分支分別用1×1、3×3 和5×5 的卷積核進行卷積操作,第4 條分支進行最大池化,最后將所有分支的輸出融合,如圖7(a)所示.雖然具體的實現方法有很大差異,但Inception 模塊和SPM 的思想是一致的,都是為了提取圖像在不同空間尺度下的特征.SPP-Net[18]的SPP 模塊同樣是采用SPM 的多尺度分塊的方法,對每一分塊進行池化操作,即可將任意大小的特征圖轉換為固定長度的特征向量.總而言之,構建空間金字塔同樣是解決目標檢測的尺度問題的一個可行方案.
受SPP-Net 的SPP 模塊的啟發,Chen 等人[81]在DeepLabV2 里設計了類似的ASPP 模塊提取多尺度特征.但不同于SPP 模塊和Inception 模塊的是,ASPP 模塊第一次采用空洞卷積[82]構建空間金字塔:4 條支路的卷積核的大小雖均為3×3,但空洞卷積系數分別為6、12、18、24,因此感受野也各不相同.在DeepLabV3[83]中,作者們又發現,隨著空洞卷積系數的增大,濾波器的有效權重逐漸變小,最后會退化為1×1 卷積.因此,他們將ASPP 模塊的空洞卷積系數為24 的支路修改為了1×1 卷積,同時新增了一條全局平均池化的支路,如圖7(c)所示.雖然DeepLab 系列針對的是語義分割任務,但思路同樣適用于目標卷積.Liu 等人提出的RFBNet[43]中設計了包含3條支路的RFB 模塊.該模塊為了盡可能地模擬人類視覺系統的感受野結構,融合了Inception 模塊和ASPP 模塊的特點,如圖7(b)所示:3 條支路首先分別經過1×1、3×3 和5×5 的卷積核濾波,然后再分別經過空洞卷積系數為1、3、5 的3×3 空洞卷積,最后融合輸出特征圖.將RFB 模塊運用于SSD 網絡后,在保證檢測速度的前提下,精度也有較大提升,并明顯改善了原SSD 網絡在面對小目標時的不佳表現.
Zhao 等人[84]為了將全局信息和局部信息相結合,設計了類似于SPP 模塊的金字塔池化模塊,模塊內包含了4 條分別進行1×1、2×2、3×3、6×6 池化的分支提取多尺度信息,在語義分割任務上效果有明顯提升.Kim 等人提出的PFPNet[44]同樣是出于融合不同尺度的上下文信息的思想,在一階段檢測器里引入了包含3 條支路的SPP 模塊,不過,每個分支池化得到的特征圖還經過了作者設計的MSCA 模塊,分別與另外兩個分支的輸出特征進行了融合,如圖7(e)所示:將另外兩個分支的特征圖進行上下采樣,然后和主干支路進行特征拼接.最后,在3 條支路的輸出特征圖上分別進行目標檢測,采用非極大值抑制算法匯總結果.從MS COCO 數據集的實驗結果來看,PFPNet 比使用FPN 架構的YOLOv3 還要略勝一籌.
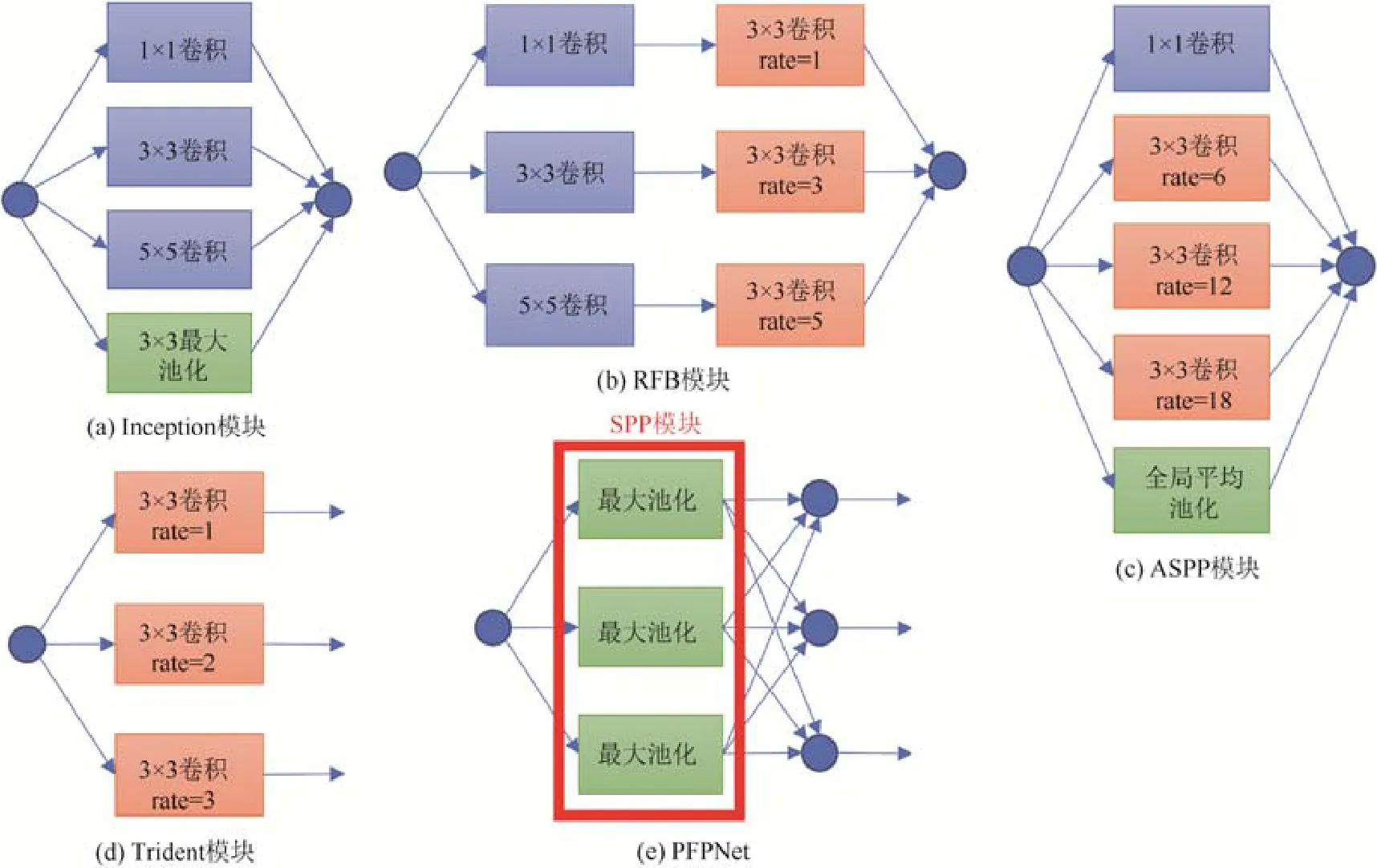
Fig.7 Overview of different ways to construct the in-network feature pyramids through parallel branches圖7 基于并行支路構建網絡內特征金字塔的多種方式
3.2.2 尺度不變特征
SSD[15]、FPN[23]等一系列在網絡內部的不同特征圖上檢測不同尺度目標的算法,本質上是以更小的計算代價近似地構建圖像金字塔最終得到的多尺度特征表達.但是,Li 等人[51]指出,網絡內部的多尺度特征圖的深度各不相同,感知特征的能力也大相徑庭,簡單的特征融合并不能完全彌補較小的目標所缺失的語義信息,因此勢必會犧牲不同尺度目標的特征一致性.而圖像金字塔就不存在這個問題,因為任何尺度的輸入圖像都經過了同種程度的特征提取,所以經過精心設計的SNIPER 算法[42]取得了更出色的實驗結果,當然,計算開銷始終是圖像金字塔算法繞不過去的坎.如何才能結合圖像金字塔和FPN 的優勢呢?Li 等人認為,圖像金字塔和構建網絡內特征金字塔的共同思路在于,模型在檢測不同尺度的目標時需要使用不同大小的感受野才能有更好的表現.因此,他們首次設計了以感受野作為唯一變量的實驗:利用空洞卷積,只改變特定卷積層的空洞卷積系數,觀察模型在MS COCO 數據集上的表現.實驗結果印證了他們的觀點:小、中、大目標分別在空洞卷積系數為1、2、3 的模型中有著最佳精度.基于這一結果,他們提出了Trident 模塊,基本結構如圖7(d)所示.該模塊包括了3 個核心設計:(1) 模塊內有3 條支路,每條支路的卷積層的空洞卷積系數不同,換言之,即感受野不同;(2) 3 條支路雖然感受野不同,但是權值是共享的;(3) 訓練時,采用類似SNIP[40]的策略,在不同的分支上根據感受野的不同,設置不同尺度的目標的監督信號.將Trident 模塊運用于Faster R-CNN 上得到TridentNet,推斷時將3 個分支的輸出進行匯總,最終在MS COCO 數據集上取得了超越SNIPER 的結果.可以看出,與RFB 模塊或PFPNet 相比,Trident 模塊最大的特點就在于巧妙地利用了空洞卷積的特性,設計了3 條支路權重共享這一妙招,可以說是體現了模塊的精髓:同樣的目標在不同的尺度下,有些特征會發生變化,也有些特征不會隨著尺度而改變.權重共享這一設計就相當于在強迫神經網絡學習尺度不變的特征,在不同的感受野下檢測不同尺度的同一目標,能夠得到同樣的結果.
盡管TridentNet 的計算開銷趕不上圖像金字塔,但多條支路的輸出仍然是比較耗時的.為了保證算法的實用性,他們額外設計了訓練時在所有分支訓練所有目標、但推斷時只使用中間分支的TridentNet Fast,相當于網絡內部的多尺度數據增強,在沒有引入任何額外計算量的前提下精度相較于基準線提升了 2.7,與原版TridentNet 的差距也只有0.6.雖然TridentNet 的本質在于學習尺度不變的特征,但是,為什么舍棄了SNIP 訓練策略的TridentNet Fast 也能夠取得接近TridentNet 的實驗結果呢?作者給出的猜測是由于權重共享,更具體的原因還有待進一步研究.
4 多尺度目標檢測的其他策略
無論是使用圖像金字塔,還是在網絡內構建特征金字塔,都是利用基于多尺度的特征來解決目標檢測的尺度問題.除了這一思路以外,也有學者從檢測算法流程中更細節的層面去解決尺度問題,包括錨點、動態卷積、基于生成對抗網絡重建特征等.本節將對這些策略一一進行概述.
4.1 錨 點
4.1.1 錨點分布的影響
早期的目標檢測為了檢測到不同尺度的目標,除了采用固定大小的滑動窗口在圖像金字塔上逐層滑動以外,還可以采用不同大小的滑動窗口輪流在同一張圖上滑動.Ren 等人[21]提出的RPN 網絡引入的錨點這一概念,同樣相當于在骨架網絡提取的特征圖上設置了9 個不同大小的滑動窗口(3 種尺度和3 種長寬比)作為檢測的先驗信息,以確保網絡能夠盡可能地覆蓋更大尺度范圍內的目標.雖然模型對于小目標的檢測精度并不理想,但多尺度的錨點策略還是成為了后來多數檢測器的標配,結合特征金字塔甚至能夠進一步擴大錨點的尺度范圍.例如,FPN 就在每一輸出特征層都布置了不同尺度的錨點.
也正是考慮到錨點的影響,Ming 等人[85]指出,除了特征的融合以外,FPN 架構有效的根源,可能并非特征金字塔網絡架構帶來的多尺度的特征表達,而是每一層特征圖上不同的錨點分布,它們的數量、尺度分布加起來遠遠超過了最早的Faster R-CNN,在過往的分析中忽視了這一因素.因此,Ming 等人基于WIDER FACE 人臉檢測數據集[86],在FPN 架構的基礎上設計了多組實驗進行對比,結果見表2.其中,原版FPN 為基準線,FPNfinest-stride 表示只利用FPN 的最后一層特征圖進行檢測,但是設置和原本的FPN 所有特征層上同樣的數量以及分布的錨點,結果精度相對于原版FPN 幾乎沒有下降.這說明,至少對于人臉檢測而言,在FPN 的多層特征圖上進行檢測可能并不是必要的,錨點的設置才是關鍵.于是,他們設計了表2 中的FPN-finest,即同樣是在最后一層特征圖上進行預測,但將所有錨點的步長都統一為最小尺度的錨點的步長,結果是:簡單和普通目標的精度有所上升,但困難目標的精度卻明顯下降.鑒于此,對不同模型的錨點分布進行統計后,他們得出新的結論:錨點的尺度分布不均衡和正負分布不均衡對結果有著重要影響.因此,他們提出了錨點的分組采樣策略,即表2 中的FPN-finest-sampling:將錨點按照尺度分為不同的組別,在計算損失函數時,不再使用所有的數據,而是在每一個組內進行隨機采樣,實現不同尺度的錨點的平衡.從表2 中可以看到,即便FPN-finest-sampling 只利用了FPN 的最后一層特征圖進行檢測,應用了分組采樣策略后卻超越了包括原版FPN 的所有模型.雖然人臉檢測的結論不確定是否能夠直接推廣到其他數據類型的多尺度檢測,但是作者們對于FPN 結構的反思和對于錨點分布這一因素的探討,的確值得深入研究.

Table 2 Quantitative comparison of different anchor strategies based on Faster R-CNN’s face detection performance on WIDER FACE validation set表2 基于Faster R-CNN 在WIDER FACE 驗證集上的人臉檢測性能量化對比不同的錨點策略
4.1.2 錨點的功與過
多尺度的錨點設置雖然已成為多數檢測器面對尺度問題的標配,但是近年來越來越多的學者意識到錨點策略所存在的天然缺陷.例如,以FPN 為例,Zhu 等人[30]指出訓練時會規定目標的尺度大小,這一點決定了哪一特征層負責對它進行檢測,然后又根據目標和錨點的交并比決定哪一種尺度的錨點負責回歸它的坐標,這些都是人為經驗決定的啟發式規則,實際上并不是最優的.因此,為了改善這一問題,Zhu 等人基于RetinaNet 提出了FSAF 模塊.該模塊在特征金字塔的每一層都新增了一條無錨點(anchor-free)分支,直接預測當前位置相對于目標矩形框的4 個邊界的距離.兩種分支參與聯合訓練,其中,不基于錨點進行預測的分支會通過在線特征選擇的方式進行學習:根據每一條支路的輸出為每一個目標選擇確定最優(即損失最小)的特征層,并且只為相應特征層提供監督信號.在推斷的時候,可以結合基于錨點的分支和舍棄錨點的分支進行預測.從結果來看,單獨的舍棄錨點的分支,其預測結果即已超越了原RetinaNet,而若與基于錨點的分支共同預測,那么就能更好地加以互補,因為從實驗結果來看,不基于錨點的分支能夠檢測出尺度更加極端的目標.在MS COCO 數據集的測試中,FASF 比RetinaNet 的整體準確率提升了1.8%,小目標準確率提升了2.2%.
同樣地,Wang 等人[31]也指出錨點的缺陷:(1) 錨點的尺寸需要預先定義,如果定義得不好會明顯降低模型的性能;(2) 為了保證足夠的召回率,往往需要大量的錨點,然而其中的大部分錨點都是對檢測結果沒有幫助的.于是,他們提出,根據圖像的特征首先預測出合適的錨點的中心點位置和長寬.然后,根據錨點的尺度采用可變卷積對原始的特征圖進行修正,最后基于新的特征圖和預測的錨點進行目標檢測.實驗中,該算法生成的候選區域的小目標召回率比RPN 高了9.2%,錨點的數量卻減少了90%,應用在Faster R-CNN 上能夠提升2.7%的mAP.Tian 等人[32]為了排除錨點帶來的負面影響,提出了FCOS 算法,類似語義分割那樣逐像素點地進行目標檢測.他們規定,圖像中每個落入了矩形框內的點都屬于正樣本,并回歸該點到矩形框4 條邊界的距離.如果同一個點落入了多個目標的矩形框中,則選擇面積較小的框進行標記.同時,為了避免大量遠離目標中心的位置產生的低質量矩形框,他們還添加了一個中心度分支,以預測偏離中心點的程度,取值在0~1 之間.將中心度與分類結果相乘,得到最終結果,就能降低遠離中心的矩形框的權重.算法既能直接運用于一階段檢測器,也能用在二階段檢測器的RPN 階段.在同樣的骨架網絡下,FCOS 比RetinaNet 小目標的準確率高了2.6%.不過,Zhang 等人[55]在對只使用一個錨點的RetinaNet 和FCOS 算法進行仔細的對比研究后認為,基于錨點的算法和舍棄錨點的算法的本質區別在于正負樣本的選取,錨點的尺寸反而影響不大.因此,他們提出了自適應訓練樣本選取策略(簡稱ATSS),運用在RetinaNet 和FCOS 上都能有穩定的性能提升.Ke 等人[87]認為,現有錨點策略僅通過錨點和目標交并比的大小來分配錨點,導致了分類與定位任務的割裂.因此,他們提出了多錨點學習策略,為每一個目標篩選出交并比較高的多個錨點組成錨點袋,并結合分類和定位的分數來評估錨點袋中的正樣本錨點,整體參與迭代訓練,以使最終選擇的錨點在檢測任務上有更好的表現.
4.2 交并比閾值
在目標檢測的訓練過程中,我們通常是基于預測矩形框和真實標簽的交并比來確定正負樣本,譬如交并比大于0.5 的為正樣本,小于0.3 的為負樣本.但是,這樣的閾值設定主要是基于經驗,并不一定是最優選擇.而且,采用固定的交并比閾值對于多尺度目標檢測來說更加不合適,因為相等的坐標偏差會對小目標的交并比造成更大的影響,對于大目標的影響則微弱得多.為了嘗試解決這一問題,Cai 等人[37]提出了Cascade R-CNN 算法,將3個R-CNN 網絡分別設置0.5、0.6、0.7 的交并比閾值,然后級聯在一起.這樣做的依據是,如果直接在單個網絡上將交并比閾值提高,會使得正樣本數量快速減少,導致網絡精度顯著下降.因此,Cai 等人便想到了以級聯的方式逐步提升生成的矩形框的質量,將前一個檢測網絡的輸出作為后一個檢測網絡的輸入,就能夠不斷地適應更高的交并比閾值,并且每一個網絡都可以檢測特定交并比范圍內的目標.該算法提出的級聯結構對于精度的提升是顯著的,不過也明顯增加了訓練時間和推斷時間.同樣是考慮到固定的交并比閾值并不合理,Zhang 等人[58]提出的Dynamic R-CNN 算法則是基于候選框的整體質量,根據一定百分比動態地控制交并比閾值.雖然與Cascade R-CNN 的思想相似,但該算法沒有級聯多個檢測器,只調整了訓練過程,不影響推斷過程,實用性更強.
4.3 動態卷積
傳統的卷積神經網絡存在著一個固有缺陷:卷積核的大小是固定的,池化層的尺度也是固定的,這就導致了網絡內所有特征層的感受野始終是固定的,不利于感知不同尺度的目標.因此,便有了一系列方法嘗試著將卷積操作動態化.例如,空洞卷積[82]的提出,就是讓卷積層能夠在參數量不變的情況下,感受野隨著空洞卷積系數單調變化,這也使得神經網絡能夠更方便地捕獲多尺度的特征.而Dai 等人提出的可變卷積[41]則更進一步,對卷積計算的每一個采樣點的位置都增加了一個偏置,這樣就可以讓卷積核呈現出各式各樣的形狀,空洞卷積相當于是可變卷積的一種特例.同樣地,池化層也可以增加偏置,進而被改造為可變池化.從實驗的可視化結果來看,可變卷積的確能夠幫助神經網絡更好地適應不同形狀和尺度的目標.不過,Zhu 等人[49]也發現可變卷積因為偏置不可控,引入了過多的可能造成負面影響的上下文信息.因此,他們對可變卷積進行了升級,讓其不僅能學習偏置,還能學習到每個采樣點的權重,相當于局部的注意力機制.此外,文獻[49]還讓模型去模仿R-CNN 算法提取出的特征,以進一步消除冗余的上下文信息的影響,提高了模型性能.總體來說,可變卷積這一設計顯著增加了卷積神經網絡的自由度,可以很好地與其他檢測器兼容.Chen 等人[88]則提出了動態卷積,即根據輸入集成多個并行的卷積核,再基于注意力機制對其進行融合,因此具有適應性更強的特征表達能力.該方法應用于輕量級的MobileNetV3-small[89]后,在ImageNet 分類數據集上取得了4%的Top-1 正確率提升,但是參數量也變為了原模型的3~4 倍左右,因此,目前而言還難以推廣到成熟的檢測網絡中.
4.4 邊界框損失函數
L1 和L2 范數是經典的回歸損失函數,在目標檢測任務中可以用于對邊界框進行回歸.但是L1 損失函數的收斂速度較慢且解不穩定,L2 損失函數對離群點敏感而不夠魯棒.因此,Girshick[19]提出了平滑L1 損失函數,結合了兩者的特點:相比L1 損失函數,在靠近真實值時,梯度值足夠小,收斂更快;相比L2 損失函數,離群點的梯度更小,更魯棒.不過,這3 種損失函數有兩個共同的缺點:(1) 都是對矩形框的頂點坐標和長寬的偏移進行懲罰,無法直接反映預測框與真實框的相似程度;(2) 都不具備尺度不變性.為了解決這一問題,Yu 等人[90]提出了交并比損失函數,將矩形框視為一個整體,直接對比例形式的交并比求對數來指導邊界回歸,因此,該損失函數就具備了尺度不變性,相比L2 損失函數,在處理多尺度的目標時有著明顯的效果提升.
Rezatofighi 等人[91]對交并比損失函數進行了更加深入的分析,指出了它的不足:(1) 如果預測框與真實框沒有相交,那么交并比始終為0,無法根據兩個框的真實距離進行學習;(2) 交并比無法區分矩形框重合的角度,進而無法精確反映重合程度.為此,他們提出了廣義交并比(GIoU),在交并比的基礎上新增了一個基于預測框和真實框的最小閉包面積的懲罰項.由于該懲罰項受預測框和真實框的距離和角度的影響,因此在保留尺度不變性的前提下解決了上述兩個問題.實驗中,GIoU 取代L2 損失函數后,讓YOLOv3 的AP 和AP75 分別提升了1.9%和2.9%,取代平滑L1 損失函數后,讓Faster R-CNN 的AP 和AP75 分別提升了0.9%和1.2%.
Zheng 等人[92]在實驗中發現,GIoU 在訓練過程中會傾向于先增大預測框與真實框產生交集,然后公式中的交并比項發揮作用,使交集最大化.一旦預測框將真實框完全包圍,GIoU 損失函數會退化為普通的交并比損失函數,無法區分相對位置關系.因此他們認為,過于依賴交并比項使得GIoU 的收斂速度太慢,甚至對于很多先進的檢測算法無法很好地收斂.所以他們提出了距離交并比(DIoU)損失函數和完全交并比(CIoU)損失函數.DIoU在交并比損失函數的基礎上增加了預測框和真實框的中心距離的懲罰項,CIoU 在DIoU 的基礎上新增了長寬比相似性的懲罰項.以基于交并比損失函數的Faster R-CNN 為基準線,他們所做的對比實驗的結果見表3.可以看到,DIoU 在所有指標上均超越了GIoU,但CIoU 的小目標準確率卻出現了下滑,說明長寬比這一懲罰項對于小目標的收斂帶來了更多的負面效應.

Table 3 Quantitative comparison of different loss functions based on Faster R-CNN’s detection performance on the MS COCO TEST-DEV dataset表3 基于Faster R-CNN 在MS COCO 測試集上的檢測性能量化對比不同的損失函數
4.5 解耦分類與定位
目標檢測任務包含了目標分類和目標定位兩部分,Faster R-CNN 等傳統算法在第2 階段普遍通過共享的全連接層對候選區域進行特征提取,最后再在兩個分支上分別進行分類和回歸.但是,這種做法的合理性值得商榷.Song 等人[53]基于熱度圖分析指出,分類任務的敏感區域為目標的顯著性區域,而定位任務的敏感區域則是目標的邊界區域,兩者在空間上無法對齊.顯然,對于多尺度目標檢測,隨著目標的尺度增大,分類與定位任務在空間上的不對齊問題也會愈加嚴重.同樣地,Wu 等人[56]則從全連接層和卷積層的特性出發,認為前者的空間敏感性使它更適合于進行分類,后者的權重共享的特點使它提取出的特征的空間相關性更強,更適合回歸邊界,實驗結果證明了這一觀點.為了解決分類與回歸問題潛在的沖突,最直觀的思路就是將兩個任務進行解耦.
Lu 等人[50]提出Grid R-CNN,首次將回歸分支分離出來,對候選區域特征使用全卷積網絡得到概率熱度圖,再預測邊界框的網格點,實現定位.實驗結果表明,該方案能夠顯著提升較高的交并比閾值下的準確率.Wu 等人[56]的解決方案是Double-Head,在RoI 對齊層后分為兩條支路,一條經過兩層全連接層后進行分類,另一條經過兩層卷積層后進行回歸.而Song 等人[53]提出的TSD 模塊則對候選區域特征也進行了解耦,即分類和回歸分支對原始的候選區域進行了不同的特征變換,使其更適應于不同的任務.Cao 等人[57]考慮到Grid R-CNN 在固定區域內尋找關鍵點的策略難以應對尺度較大的目標,因此提出了密集局部回歸策略,使用全卷積網絡預測候選區域的多個前景子區域的偏移量并求平均.從表1 中的實驗對比可以看到,該算法與Grid R-CNN 相比在大目標的精度上提升了5%.
4.6 小目標特征重建
在MS-CNN 算法[70]中,為了能夠更好地檢測尺度較小的目標,網絡中設計了反卷積層來對特征圖進行上采樣,有效地減少了內存占用和計算耗時.Zhou 等人提出STOD 算法[47],以DenseNet-169[93]作為骨架網絡,設計了尺度變換模塊,將最后的多個通道的特征圖通過平鋪展開的方式構造成為分辨率更高、通道數更少的特征圖,用來檢測小目標.Zhang 等人提出的DES 算法[48]為了能夠加強SSD 的淺層特征在檢測小目標時缺失的語義信息,設計了一個分割模塊的分支進行語義分割,將分割得到的特征圖作為權重疊加到淺層特征圖上,相當于一種注意力機制.從可視化的結果來看,淺層特征圖上的無關特征得到了有效的抑制.
除此以外,生成對抗網絡的出現,同樣為小目標的特征重建提供了新的思路.Li 等人[94]設計了一個Perceptual GAN 模型,其中的生成器負責學習將小目標的特征重建為與大目標的特征相接近的超分辨率特征,判別器既負責判斷生成的特征是否是真實的大目標特征,同時還會將定位精度反饋給生成器,計算感知損失函數,其目的在于判斷生成的超分辨率特征是否有助于提升檢測精度.算法最終在Tsinghua-Tencent 100K[95]和Caltech 數據集[66]上取得了當時的最佳結果.Bai 等人[46]提出了一個端到端的多任務生成對抗網絡MTGAN,其中生成器用于對模糊的低分辨率圖像進行超分辨率重建,判別器除了判斷生成的超分辨率圖像的真假以外,還會完成目標的分類和定位,即檢測器的任務.事實上,該算法的一大優勢在于能夠與任何已有的檢測器相結合.在訓練時,判別器計算得到的分類和定位的損失也會反向傳播給生成器,以便使其能夠重建出更多對檢測有益的細節.作者們認為,相較于傳統的雙線性插值,超分辨率網絡生成的圖像更真實、質量更高,更有利于檢測任務.該算法在MS COCO 數據集上取得了超越Mask R-CNN 的結果,而且精度的提升尤其體現在小目標上.
4.7 數據增強
此外,數據增強同樣是緩解尺度問題的可行方案,比如 YOLOv2 算法[27]的隨機多尺度訓練策略.此外,Kisantal 等人[96]以Mask R-CNN 作為基準線,針對MS COCO 數據集小目標檢測精度較差的問題提出了兩種數據增強的手段:(1) 采用過采樣策略,解決數據集中包含小目標圖片較少的問題;(2) 在同一張圖片里,對小目標的分割掩膜進行復制粘貼,使錨點策略能夠匹配到更多的小目標正樣本中,進而增加小目標在損失函數中的權重.該思路的本質是通過改變訓練數據的目標尺度分布,讓模型更傾向于感知小目標.從實驗結果來看,大目標的檢測精度略有下降,小目標的檢測精度有所提升.
在目標檢測任務中,為了提高檢測器的整體性能,通常會采用額外的數據集對模型進行預訓練,然后再在正式的數據集上進行微調,亦或是直接讓額外的數據集參與聯合訓練.但是,Yu 等人[97]指出,如果兩個數據集的目標尺度差異較大的話,會對模型的性能造成負面影響.因此,他們提出了尺度匹配算法:通過在原數據集里隨機采樣來確定期望的目標絕對值尺度分布,然后計算該尺度相對于額外數據集的某一張圖像的尺度比例,根據比例對整張圖像進行放大或縮小,如此循環,直到處理完整個額外數據集.當然,該算法還存在一個缺陷:數據集在經過尺度匹配之后,目標的尺度順序可能會發生改變,原本的小目標可能被縮小,大目標被放大.因此,作者們也采用了直方圖均衡化的思想,設計了單調尺度匹配算法,以保證尺度匹配過程中不會改變尺度順序.最后的實驗結果表明,若在單調尺度匹配后的MS COCO 數據集上進行預訓練,相對于直接在原始的MS COCO 數據集上進行預訓練,得到的模型在包含大量極端小目標的TinyPerson 數據集[97]上有5%左右的相對精度提升.可見,該數據增強策略不失為一種構建不同尺度數據集間的橋梁的可行方案.
Chen 等人[98]提出的圖像拼接(stitcher)也是一種能夠顯著提升小目標精度的數據增強手段.類似的思路最早起源于Yun 等人[99]提出的CutMix 數據增強策略,即將一張經過裁剪的圖像以補丁的形式粘貼到其他圖像上作為新的訓練數據,如圖8(a)所示.

Fig.8 CutMix and Mosaic data augmentation圖8 CutMix 與Mosaic 數據增強
這樣做能夠提高訓練效率、增強模型的魯棒性.Bochkovskiy 等人[59]在YOLOv4 中將CutMix 改進為Mosaic數據增強,不再只是將一張圖粘貼到另一張圖上,而是將4 張圖拼接在一起,如圖8(b)所示,這讓目標的上下文信息變得更加復雜.圖像拼接屬于Mosaic 數據增強的特殊形式,雖然該想法不是Chen 等人的首創,但他們從多尺度目標檢測的視角賦予了圖像拼接新的意義.他們觀察到數據集中小目標的分布極不均勻,導致損失函數的計算中小目標的占比非常低,沒有提供給網絡充足的監督信號.因此,受SNIP 和SNIPER 裁剪策略的啟發,他們反其道而行之,將圖像縮小并拼接在一起,從而能夠將中、大目標的尺度縮小,進而更好地權衡訓練數據的尺度分布.此外,他們還提出了相應的訓練策略:以損失函數中小目標的比重作為圖像拼接的反饋信號,若上一次迭代中小目標的損失比重過低,則下一次迭代就會采用拼接圖像來訓練.圖像拼接的實驗對比見表4,可以看到,模型的性能得到了全方位的提升,其中小目標的精度上漲最為明顯.此外,在訓練時間加倍的情況下,引入圖像拼接的模型能夠持續獲得穩定的性能提升,而不會輕易過擬合,這應該得益于顯著增強的數據多樣性.相比SNIPER,圖像拼接數據增強除了實現更簡單、不需要經過繁瑣的正負碎片制作以外,更難能可貴的是,推斷時不需要付出任何額外代價.

Table 4 Quantitative evaluation of Stitcher augmentation and corresponding training strategies based on Faster R-CNN’s detection performance on the MS COCO TEST-DEV dataset表4 基于Faster R-CNN 在MS COCO 測試集上的檢測性能量化評估圖像拼接數據增強及其訓練策略
5 多尺度目標檢測的研究展望
多尺度目標檢測一直以來是一個研究難點.結合目前已有的方案,本節總結了一些值得深入探討的問題,可作為未來研究的方向.
(1)“碎片式”圖像金字塔.SNIP[40]策略讓CNN 能夠盡最大可能地發揮圖像金字塔的潛力,但是訓練時的內存問題和推斷時的速度問題限制了它的推廣.SNIPER[42]通過裁剪圖像金字塔的碎片作為訓練樣本,解決了訓練問題,但是推斷問題沒有得到改善,因為圖像碎片的生成是基于已有的目標標簽.若要解決這個問題,則需要通過某種不依賴于標簽的方法,構建出“碎片式”圖像金字塔,即每一層都只保留了同一尺度范圍內的目標.用強化學習來選擇放大區域或許是一個可行的方案.
(2) 高分辨率圖像的多尺度目標檢測.在對高分辨率圖像進行目標檢測時,往往并不缺少小目標的細節信息,而是難以實現精度與計算資源的權衡.由于受到內存、檢測速度需求等限制,Faster R-CNN[21]、YOLO[14]等算法都會先將高分辨率圖像下采樣至某一分辨率,再通入網絡進行檢測,這就導致了信息的丟失.若采用滑動窗口法實現地毯式檢測,整體速度又太慢.Gao 等人[65]提出的用強化學習引導細粒度檢測的策略,對于日常設備拍攝的高分辨率圖像是有一定效益的.但是,對于細粒度信息更密集的圖像是否仍有效(例如無人機航拍)以及能否設計出更簡潔的算法,都還有待于進一步加以研究.
(3) 特征金字塔架構下的特征融合.自特征金字塔網絡(FPN)[23]誕生之后,有很多新算法在它的基礎上改進了特征金字塔的構建方式.但是,PANet[38]、Libra R-CNN[73]和ASFF[52]等算法都是在FPN 已構建好的特征金字塔的基礎上再次融合特征,構建新的金字塔.這不得不讓人提出疑問,究竟是新提出的特征融合方式發揮了作用,還是反復地堆疊特征融合操作才是精度提升的主要原因,例如像EfficientDet[75]那樣多次堆疊BiFPN.要證明前者,需要在實驗中嘗試拋棄FPN.例如,直接將ASFF 模塊運用于原本的特征層上,再看精度的提升是否強于FPN.但是如果答案是后者,則需考慮:特征融合對目標檢測任務的精度提升的上限在何處.
(4) 神經網絡架構搜索.近年來興起的神經網絡架構搜索(NAS)方法在目標檢測任務上展現出了相當大的潛力:通過NAS 得到的特征金字塔網絡結構[77,78]和骨架網絡[100],與以往人工設計的模型相比都展現出了性能上的優勢.但是,一方面,只有針對完整的目標檢測算法流程進行搜索,才可能得到真正意義上突破現有算法流程的結構,目前的NAS 仍只是對局部網絡架構進行搜索改進,譬如FPN 式的特征融合對于尺度問題并不見得是最合適的選擇.另一方面,過于復雜的拓撲結構并不一定具有普適性,反而更可能在數據集上出現過擬合.因此,如何更好地運用NAS,仍是一個值得探討的方向.
(5) 卷積神經網絡能否理解尺度概念.特征金字塔網絡的出發點是在不同尺度的特征圖上檢測不同尺度的目標,但是,這也意味著網絡實際上是在把不同尺度的目標當作不同的目標在檢測,即便它們可能真的就是同一個目標.因此,卷積神經網絡可能并沒有真正理解尺度這一概念,只是在依靠龐大的參數量來強行記憶.這可能也正是引入FPN 架構的算法在檢測大目標時精度普遍會有所下降的原因.TridentNet[51]最特別的地方就在于,通過權重共享和尺度歸一化的訓練策略嘗試著讓CNN 用相同的網絡參數在不同的感受野下分辨不同尺度的目標,這一設計的本質就是在讓CNN 學習尺度這一概念.但是,TridentNet 和完全舍棄了尺度歸一化訓練策略的TridentNet Fast 的性能差距卻非常小,說明這一思路的潛力可能還沒有被完全挖掘出來.
(6) 錨點的存在價值.早期的YOLO 和Densebox[101]算法都沒有錨點,而RPN 網絡的提出最早引出了錨點這一概念,相當于為回歸任務提供了一個先驗知識,該思想被之后的多數檢測器所采納,與FPN 架構相結合后顯著擴大了目標檢測的尺度范圍.但是,近兩年來,卻有越來越多的學者重新回歸到舍棄固有錨點的思路上進行研究,因為他們認為錨點存在著引入額外超參數、難以回歸極端尺度的目標等問題.但是,從形式上看,很多舍棄錨點的算法其實相當于在每一個像素點處都有一個錨點,沒有太本質的區別.而從性能上看,這些新提出的算法目前也沒有明顯超越基于錨點的算法.此外,Zhang 等人[55]提出的正負樣本的選取才是這兩類算法的本質區別的觀點,也提醒我們需要重新審視錨點對于多尺度目標檢測的真正影響.
(7) 多尺度目標的交并比.現有的多數目標檢測算法在訓練過程中,仍然是基于固定的交并比閾值來確定正負樣本.盡管已有部分學者[37,58]指出了這樣做并非最優解,并嘗試通過對閾值進行動態調整來改進算法.但是,這樣的改進始終是將所有的目標視為了一個整體來進行同等處理,實際上不同尺度的目標對于交并比的敏感度是不同的.小目標由于自身尺度較小,候選框的交并比通常會更低,在相同的閾值下更難以得到足夠的正樣本.因此,若能夠針對不同尺度的目標設計不同的交并比閾值,亦或是重新定義更加公正的正負樣本的選擇依據,或許能夠進一步提高多尺度目標檢測的性能.
(8) 數據集的尺度不均衡.特征金字塔網絡等算法很多時候會給我們帶來錯覺,認為模型在分配了更多資源提升小目標的檢測精度后,大目標的精度也會有所下降,是學習資源受限的必然趨勢.但是,針對錨點設置而提出的分組采樣策略[85],從每個尺度的錨點中隨機采樣來計算監督信號,保證尺度均衡,訓練得到的模型性能卻全方位地超越了其他所有的對照組,包括大尺度目標占據主導的模型.圖像拼接數據增強策略[98]也出現了類似的現象,訓練數據里中、小目標所占的比重增加,但最終得到的模型在檢測大目標時精度同樣有所提升.這些實驗結果提供了一種可能:原本的模型在大目標上有可能已經過擬合了,而小目標則處于欠擬合的狀態,因此相對均衡的尺度能夠給模型帶來全方位的性能提升.
6 總結
本文以基于深度學習的目標檢測為背景,首先對主流算法的成型歷史進行了簡要回顧,包括R-CNN 等兩階段檢測算法和YOLO 等一階段檢測算法.然后,本文總結了近幾年來提出的眾多檢測算法在MS COCO 檢測數據集上的表現,并以相應評價指標為依據,指出了目標檢測所面臨的尺度問題這一巨大挑戰,并分析了其根本原因在于目標定位所需要的淺層空間信息和目標分類所需要的深層語義信息的矛盾.
以解決尺度問題為導向,本文對現有的多尺度目標檢測策略進行了匯總和歸納.其中,構建多尺度特征表達是最典型且宏觀的策略,具體可以分為圖像金字塔和網絡內特征金字塔.前者將多尺度的圖像通入網絡,能夠穩定提升檢測精度,但顯著增加的內存開銷和計算耗時是主要問題.后者則只需輸入原圖,根據特征金字塔構建方式的不同可分為跨層連接和并行支路,計算代價比圖像金字塔更小.除此以外,本文也從錨點、交并比閾值、動態卷積、邊界框損失函數等更細節的層面分析了能夠改善尺度問題的策略,更透徹地了解了檢測算法流程的許多細節設計的意義.
最后,本文基于上述分析,對多尺度目標檢測的研究方向進行了展望.譬如,能否構建“碎片式”圖像金字塔解決計算耗時問題、堆疊特征融合操作的上限在何處、卷積神經網絡能否理解尺度這一概念以及數據集中是否存在不同尺度目標的過擬合和欠擬合問題等等.這些疑問都值得繼續深入探討.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
