一種多頭注意力提高神經網絡泛化的方法
2021-05-25 05:26:36陳曦,姜黎
軟件導刊 2021年5期
陳 曦,姜 黎
(湘潭大學物理與光電工程學院,湖南湘潭 411100)
0 引言
眾所周知,深度神經網絡具有較強的函數逼近能力,能夠表征復雜函數[1]。最近研究表明,神經網絡的表征能力隨著網絡深度指數增長而增強[2]。在機器學習領域,泛化能力指學習到的模型對未知數據的預測能力[3]。根據可能近似正確(probably approximate correct,PAC)理論[4]理解為以e 指數形式正比于假設空間的復雜度,反比于數據量。目前提高泛化能力方式有增加數據量[5]、正則化[6]、凸優化[7],這些方法因為實際條件差異在使用時有一定的局限性。如今神經網絡在許多領域大放異彩,然而在某些場景中卻不盡如人意[8]。由于神經網絡的泛化問題會影響其推廣,所以提高神經網絡泛化對生產生活都極具意義。
提高泛化能力研究目前主要有基于神經網絡剪枝[9]和基于多個獨立單元結合的方法。基于神經網絡剪枝的方法提高泛化能力效果甚微,其主要作用是減少神經網絡參數量。基于多個獨立單元結合的研究將多個相同的子模塊獨立運行,然后再對子模塊信息進行整合,從而提高模型性能。這種方法提高泛化效果較好,但參數量明顯多于剪枝方法。Li 等[10]提出一種新的循環神經網絡——獨立循環神經網絡方法,即同層的神經元相互獨立,跨層連接;Henaff 等[11]在Entnet 結構中應用獨立的門從每個記憶單元中讀寫,能夠在bAbI 任務中有優于基準模型的表現;Clemens 等[12]采用激活層控制多個模塊信息交流,但只有在特定的時間步才能進行信息交流[13]。這些研究未對交流的信息進行篩選,在一定程度上保留了冗余信息,因此影響網絡的泛化能力;Vaswani[14]提出的Transformer 模型在兩項機器翻譯任務中表現遠優于當前的最優模型,其中提出的注意力機制能夠極大提高模型的泛化能力。
受上述方法啟發,本文沿用多個獨立單元結合思想,采用多頭注意力以提高并行長短期記憶網絡(Long Shortterm Memory,LSTM)模型的泛化能力。多頭注意力根據當前時間步的輸入和LSTM 狀態的相關度進行選擇性激活,激活的LSTM 包含當前輸入重要的信息。在信息交流時,激活的LSTM 會讀取其它LSTM 信息(包括未激活LSTM中的信息),未激活的LSTM 則按照原有的狀態獨立更新。于是,當某個LSTM 信息被改變后,其它激活的LSTM 中還存有其信息。如此操作即能提取到樣本普遍性特征,增強了魯棒性,與很多提高泛化的研究思想不謀而合。為了驗證本文方法可行性,與傳統并行LSTM 進行對比實驗,證明本文方法比傳統并行LSTM 更穩定、更泛化。將本文方法與3 種相關研究方法進行對比,結果表明本文方法比相關方法能更顯著地提高泛化能力。
1 基本結構
1.1 LSTM 結構
當輸入為長序列時,傳統的循環神經網絡(Recurrent Neural Networks,RNN)會出現梯度消失和梯度爆炸問題,LSTM 就是為解決該問題而專門設計的。LSTM 能夠在長或者短的序列輸入中保留關鍵信息[15]。實踐證明,LSTM性能優于傳統RNN。LSTM 狀態參數在每個隱藏節點是共享的,就是每個細胞參數可以對整個反應鏈狀態作出修改,Colah 將這種細胞狀態的更新機制類比為傳送帶。LSTM 內部結構如圖1 所示(彩圖掃OSID 碼可見,下同)。
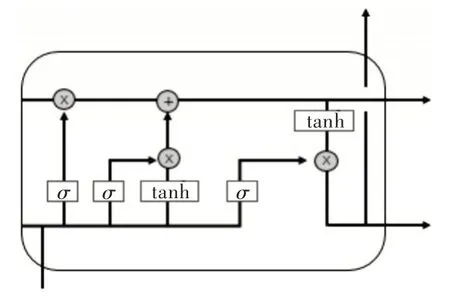
Fig.1 LSTM internal structure圖1 LSTM 內部結構
如圖1 所示,LSTM 關鍵在于細胞狀態和整個穿過細胞上方的那條水平線,細胞狀態在這條水平線上傳遞,只有少量的線性交互[16]。若只有上面那條水平線是無法實現添加或者刪除信息的,只有通過一種叫做“門”的結構來實現。門可以控制信息流通,通常是利用非線性激活sig?moid 函數和點積運算實現。sigmoid 層輸出的每個元素都是0 和1 之間的實數,表示讓對應信息通過的比例。比如0 表示“不讓任何信息通過”,1 表示“讓所有信息通過”。LSTM 通過3 個這樣的門結構實現信息的保護和控制,分別為遺忘門、輸入門和輸出門。
遺忘門可以過濾之前計算出的狀態向量,然后加入到后續運算中,其數學表達式如下:
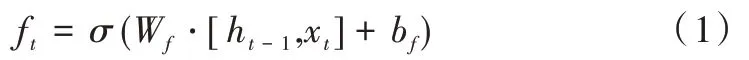
遺忘門輸入來自當前時間步的輸入向量xt和上一個時間步輸出門的輸出向量ht-1,其中Wf和bf為遺忘門的權重及偏置向量。經過sigmoid 運算將結果映射到[0,1],得到遺忘門的輸出ft。ft控制舊狀態信息舍棄,可以和上一時間步的細胞狀態進行點積運算,從而更新舊狀態。
輸入門則是通過激活函數控制上一時間步的狀態和當前輸入信息,然后參與當前細胞狀態更新,其數學表達式如下:
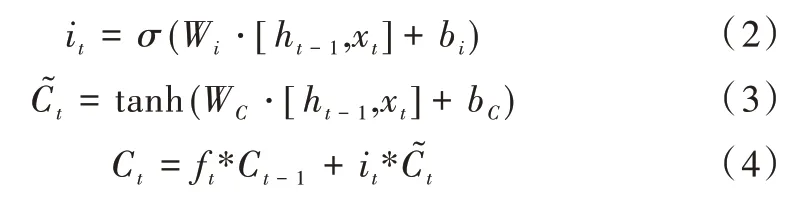
式(2)表示對細胞狀態進行更新,式(3)計算出一組候選的細胞狀態來取代更新細胞狀態中的舊值,式(4)將這兩個向量逐元素相乘,接著與經過遺忘門的細胞狀態相加,如此完成輸入門更新。
輸出門建立在之前兩個門基礎上,數學表達式如下:
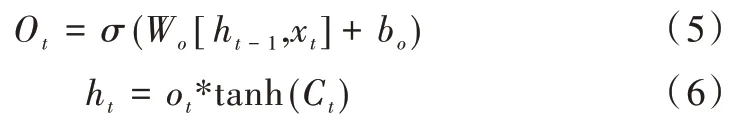
輸出門的輸出是基于當前輸入門更新過的細胞狀態。式(5)決定輸出的狀態信息,式(6)中tanh 層將當前細胞狀態壓縮到(-1,1)區間內,該輸出變量同時作為下個單元的ht-1加入到循環。
1.2 多頭注意力機制
對于單個注意力模型可以理解為給定查詢向量到一系列鍵值對的映射,本文查詢向量來自LSTM 的狀態信息,鍵向量和值向量來自于當前輸入。在給定目標中查詢某個元素向量后,通過計算其和各個鍵向量的相似度得到每個查詢向量對應值向量的權重系數,再經過softmax 歸一化,將權重系數和相應的值向量加權求和,最終計算出注意力數值。所以,本質上注意力機制是對給定目標中元素的值向量進行加權求和,而查詢向量和鍵向量用來計算對應值向量的權重系數[19]。最常用的兩種注意力機制是加性注意力和點積注意力,本文采用點積注意力,其數學表達式如下:
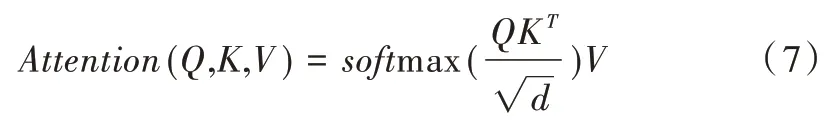
Q,K,V分別是查詢向量、鍵向量、值向量,d是鍵向量的維數,除以d可以防止softmax 之后的值變得很小。
對于多頭注意力模型,可以認為是結合多個單獨的注意力而成,其數學表達式如下:
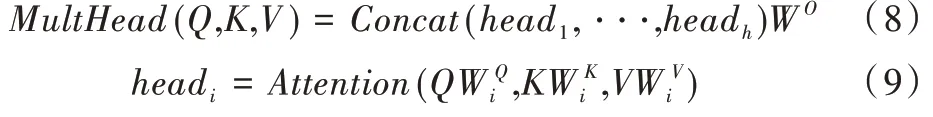
其中,Q、K、V經過線性變換后輸入到單個注意力運算[11],這里要做h次,也就是所謂的多頭。每次計算一個頭,頭之間的參數不共享,每次Q、K、V進行線性變換的權重參數W不一樣。接著將h次的注意力運算結果進行拼接,最后執行線性變換,就可計算出多頭注意力。
2 泛化方法
本文首先利用多頭注意力根據并行LSTM 狀態信息求出每個LSTM 的注意力權重,然后從中挑選出權重較大的LSTM 進行激活,再將激活的LSTM 中的狀態信息通過多頭注意力按照一定比例進行信息交流。雖然采用多個網絡結構并行的方法較多,但是結合多頭注意力激活子網絡并進行信息交流的方法卻沒有,且多次對比實驗表明本文方法有較強的泛化性和穩定性。
2.1 本文網絡結構
神經網絡研究發現,通過增加網絡層數可以學習到任務的更高層特征以解決更復雜的任務。雖然增加層數可以提高網絡性能,但是模型的運算成本也大幅增加。為了減少深度神經網絡的訓練時間,基于各種計算平臺設計的并行神經網絡逐漸成為研究熱點[17]。
對于神經網絡的并行化主要有數據并行和模型并行兩種方法[18]。數據并行是當數據量十分龐大時,將數據分成多個小的子數據集,再將各個子數據集在多個相同模型上并行訓練,最后由參數服務器完成參數交換[19];模型并行指將網絡結構分解到各個計算設備上,依靠設備間的共同協作完成訓練。本文實驗在Cuda 平臺上進行模型并行訓練測試,并行網絡中每個LSTM 就是獨立的結構單元,如圖2 所示。
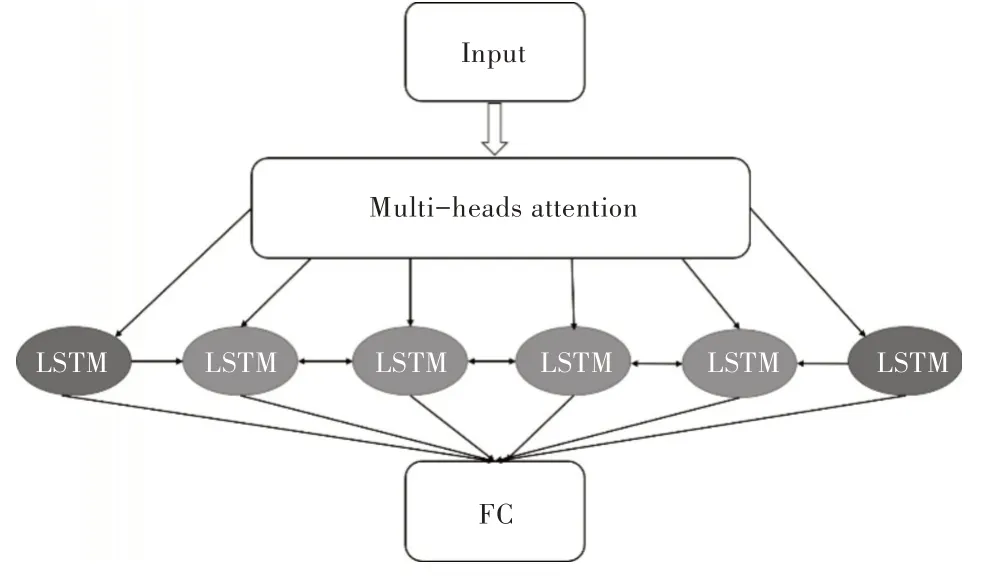
Fig.2 Structure of this paper圖2 本文結構
多頭注意力結合當前LSTM 狀態與輸入的相關度選擇性激活LSTM,其中綠色框表示已激活的LSTM,藍色為未激活。在每一時間步,激活的可從其它LSTM 中讀取信息,未激活的則保持隱藏狀態不變。最后經過神經元個數為10 的全連接層得出預測結果。本文中LSTM 總個數為6,每個時間步激活4 個LSTM,每個LSTM 的神經元個數為32。
2.2 采用多頭注意力進行信息交流
起初每個LSTM 是相互獨立的,初始狀態也是隨機的,然后進行自身動態更新。經過多頭注意力選定與輸入相關的LSTM 設置激活,激活的LSTM 讀取其它激活或未激活LSTM 一定比例的信息[20]。本文中每個激活的LSTM 都可以讀取其它LSTM 中1/10 的信息。因此,不僅能保留當前任務的重要信息,還能通過信息交流提高魯棒性[21]。
設每個LSTM 都是相互獨立的,它們之間沒有信息交流。對于未激活的LSTM,其隱藏狀態保持不變,如式(10)所示。

此為第k個LSTM 在t時間步的狀態。模型會動態地在每個時間步挑選出和當前輸入相關的LSTM 激活,激活的LSTM 得到真實的輸入,未激活則得到由全0 組成的空白輸入。令xt為時間步t時的輸入,如果未激活則:

式(11)是將xt在行方向上進行連接。
接下來用線性操作建立:

R的每行對應一個獨立的LSTM 隱藏狀態。Wv是將輸入映射到對應的V向量矩陣,Wk是將類似的矩陣輸入映射到K。是將LSTM 從其隱藏狀態映射到Q。
注意力運算結果如下:
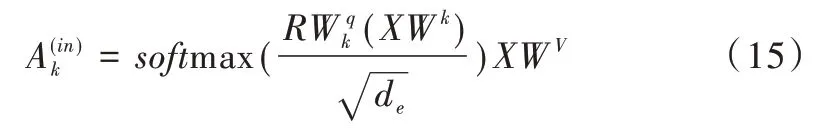
基于上式softmax 計算的值,在每個時間步將較大的softmax 值設置為1,其余則為0。將這幾個值與其對應的LSTM 執行點積運算就完成了激活步驟。未激活LSTM 的梯度保持以往的更新,其狀態可以被激活的LSTM 讀取。對于激活的LSTM 將進行如下更新:
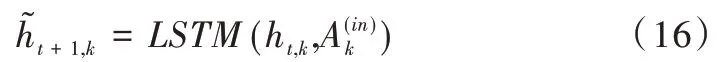
LSTM 在t時間步經過多頭注意力作用得到下一時間步的狀態ht+1。本文方法即按照上述步驟進行循環更新。
3 實驗研究
3.1 實驗數據
本文采用MNIST[22]、Fashion-MNIST[23]、CIFAR10[24]、Animals-10 開源數據集進行實驗驗證。MNIST 是手寫數字(0-9)數據集,Fashion-MNIST 是時尚穿搭衣物數據集,CIFAR10 是常見物體彩色圖片數據集,Animals-10 是10類常見動物圖片數據集,各數據集詳情如表1 所示。
3.2 實驗對比并行LSTM
本文實驗在Linux 系統下搭建的Pytorch 環境進行,批量大小設置為100,損失函數采用交叉熵損失函數,優化函數采用SGD,學習率為0.1,迭代訓練1 000 次。
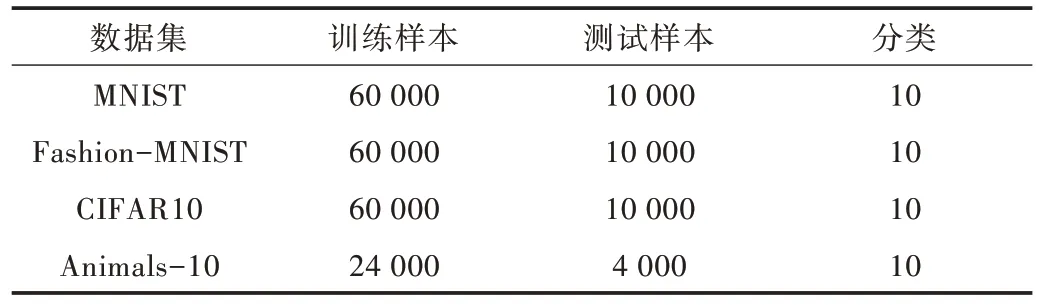
Table 1 Distribution of experimental data sets表1 本文實驗數據集分布
實驗中LSTM 總個數為6,設置每一時間步激活的LSTM 個數為4,單個隱藏層神經元為32。對比實驗中采用4 個并行的LSTM,單個隱藏層神經元也為32,其它參數設置與本文方法相同,這樣的設置排除神經個數對實驗的干擾。4 種數據集的對比實驗如圖3 所示。
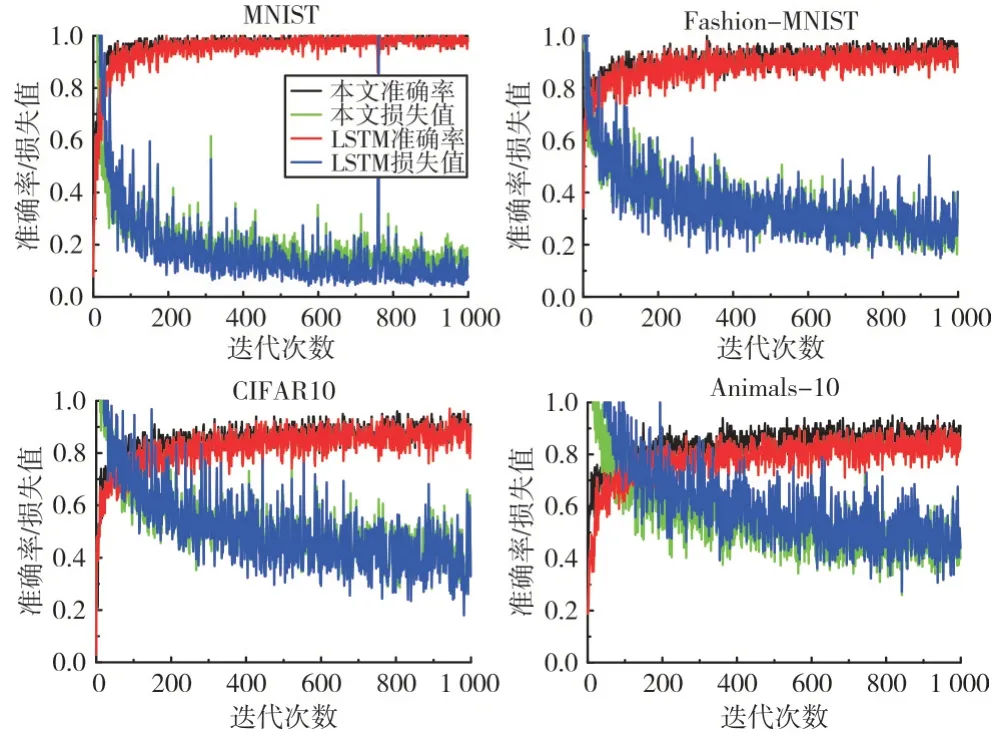
Fig.3 Comparison between the proposed method and parallel LSTM training圖3 本文方法與并行LSTM 訓練對比
如圖3 所示,黑色曲線和綠色曲線分別對應本文方法在訓練中的準確率、損失函數值,紅色曲線和藍色曲線對應并行的LSTM 準確率、損失函數值。在4 種數據集上,本文方法均比并行LSTM 的訓練準確率高。兩種方法在MNIST 數據集上的訓練準確率差距極小,但是并行LSTM的訓練損失值波動較大。本文方法在Fashion-MNIST 和CIFAR10 的訓練準確率明顯高于并行LSTM,訓練損失值同樣比并行LSTM 穩定。在Animals-10 數據集上,本文方法的訓練準確率比并行LSTM 有較大提升,訓練損失值也更低、更穩定。從訓練表現來看,采用本文方法的性能優于并行LSTM 模型。
通常采用測試誤差來衡量神經網絡的泛化能力,其中測試誤差為1 減去測試準確率。將本文方法與并行LSTM在4 種數據集的測試誤差進行對比實驗。在測試集進行10 次測試,計算出平均測試誤差,如表2 所示。
由表2 可知,本文方法在4 種數據集的測試誤差均低于并行LSTM。其中,由于MNIST 數據集的任務較為簡單,兩種方法的測試誤差僅相差0.35%。Fashion-MNIST 數據集和CIFAR10 數據集的分類任務較難,測試誤差相差約1%,能明顯看出本文方法的泛化能力強于并行LSTM 模型。Animals-10 數據集由于任務較難且訓練數據較少,導致測試差距較大,達到3.03%。實驗表明,本文提出的方法能夠有效提高泛化能力。

Table 2 Comparison of test errors between the proposed method and parallel LSTM表2 本文方法與并行LSTM 測試誤差對比(%)
3.3 實驗對比相關研究
為進一步探究本文方法的泛化能力,繼續在4 種數據集上對本文方法與相關研究進行實驗。對比的方法有基于門控交流的Entnet[11]方法、基于注意力機制讀寫信息的RMC[25]方法、基于多個循環結構結合的方法[10]。訓練參數設置前保持一致,依舊采用測試誤差作為衡量泛化的指標。對比實驗測試誤差如表3 所示。
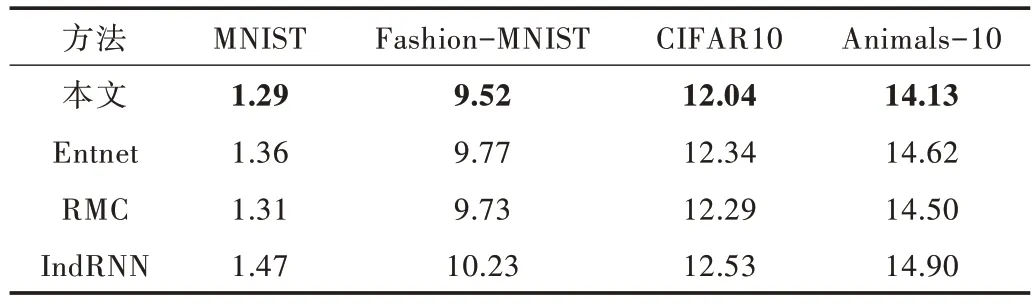
Table 3 Test error comparison between the proposed method and related research表3 本文方法與相關研究的測試誤差對比(%)
由表3 可知,本文方法在4 種分類任務中都取得了最好成績。其中在MNIST 數據集上,本文方法比RMC 方法測試誤差低0.02%。由于這個數據集上的分類任務比較簡單,所以各種方法差距都很小,并不能明顯看出泛化性能的強弱。在其它分類難度大的數據集上,本文方法的測試誤差分別比次優方法低0.21%、0.25%、0.37%。因此本文方法比其它3 種相關研究更具泛化能力,表明本文方法能提高神經網絡泛化能力。
3.4 圖片加噪測試
泛化能力是在真實場景中依然能夠發揮出色,對數據的變化具有魯棒性。本實驗使用Python 中的skimage 庫將測試集的圖片添加高斯噪聲,其中高斯噪聲均值為0,方差為0.01,訓練集則保持原有狀態。然后基于前述的訓練模型,在4 種數據集上對比相關算法的測試誤差,詳情如表4所示。
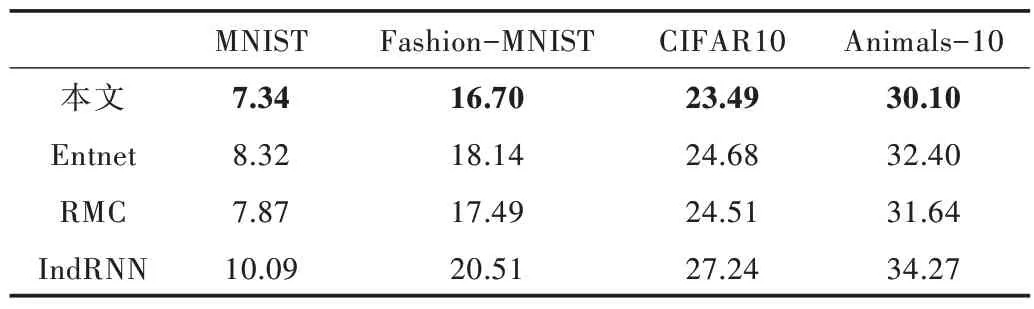
Table 4 Test error comparison between the proposed method and related research表4 本文方法與相關研究測試誤差對比(%)
由表4 可知,在加噪情況下本文方法的測試誤差都是最小。和未加噪情況相比,本文方法測試誤差的變化值均小于相關方法,分別比次優方法低0.35%、0.62%、0.77%、1.19%。這意味著本文方法對于數據的變化有更強的魯棒性,泛化能力也優于相關方法。綜上所述,本文方法能夠顯著提高神經網絡的泛化能力和穩定性。
4 結語
本文采用多頭注意力以提高神經網絡泛化能力,通過多頭注意力選擇性激活LSTM 進行信息交流,保留任務中普適性信息,從而提高神經網絡的泛化能力。與并行LSTM 網絡相比,本文方法表現出更強的泛化能力和穩定性。與其它相關方法相比,本文方法的泛化能力也更強。但本文方法參數量較大,會耗費大量的計算和內存成本。后續研究方向為將本文方法推廣到簡單的并行結構中,使其能夠移植到硬件中。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
