基于PG-BP 神經網絡的流域洪澇預測及仿真
2021-05-25 05:26:40韓卓慧閆長青
軟件導刊 2021年5期
韓卓慧,閆長青
(1.山東科技大學計算機科學與工程學院,山東青島 266590;2.山東科技大學智能裝備學院,山東泰安 271019)
0 引言
我國洪澇災害頻發,其破壞程度極其嚴重,因洪澇災害造成的損失不計其數。因此,對洪澇災害進行預測及模擬仿真非常必要。河流水位數據是分析洪水淹沒范圍的重要數據,精準的水位預測可以為洪水淹沒范圍模擬提供可靠的參考信息。在大數據時代,利用數據驅動模型對已有數據進行分析進而預測下一階段的數據成為研究熱點。其中,BP 神經網絡是一種靈活的數據驅動模型,可以應對各類非線性問題并達到理想精度。已經有眾多專家學者使用BP 神經網絡對不同領域進行預測研究[1-2]。Xiao 等[3]提出結合Purelin、Logsig 和Tansig 激活函數的BP 神經網絡方法以預測水產養殖中的溶解氧,并與常見的預測模型CF、AR、GM、SVM 作比較,實驗結果表明神經網絡預測精度最高,并且所有預測值小于誤差極限的5%,可以滿足實際應用需求;He 等[4]提出一種集合經驗模態分解(EEMD)和BP 神經網絡的建模方法,用于預測南海的月平均海平面,實驗結果表明,與直接使用BP 相比較,結合EEMD 海平面建模方法的精度更高;Li 等[5]提出基于人工蜂群(ABC)優化算法的BP 神經網絡預測模型,以準確預測西北過度開發干旱地區的地下水位,實驗表明ABC-BP 模型的擬合精度、收斂速度和穩定性均優于粒子群優化(PSO-BP)、遺傳算法(GA-BP)和BP 模型,從而證明了ABC-BP 模型可以成為預測地下水位的新方法。由以上可知,在數據預測領域,BP 神經網絡雖然有著非常廣泛的應用,但是單一的BP神經網絡預測模型仍然存在局限性[6]。若使用單一的BP神經網絡進行預測,不僅會使預測模型的網絡規模和運算時間增加,導致收斂性能及泛化能力大大降低[7],還會因為輸入層變量之間可能存在的相關性,導致輸入信息重疊,模型準確率降低。因此,本文提出一種PG-BP 神經網絡預測模型用于預測研究區域的河流水位。
主成分分析法(Principal Component Analysis,PCA)是一種多元統計方法,它將一組相關變量通過正交變換轉化為一組正交且不相關的變量,轉化后的這組變量叫作主成分[8](Principal Component,PC)。其目標是從數據集中提取最重要的信息,通過減少維數來壓縮數據集的大小,同時保證不會丟失太多信息,因此在各類指標評價中常用PCA篩選最能夠概括全局信息的指標[9-10]。Xu 等[11]使用主成分分析消除了評價指標之間的相互影響,然后采用偏最小二乘法(PLS)建立了SBS 改性瀝青老化行為預測模型,并且用實驗證明了該模型預測的準確性;Wang 等[12]提出一種基于主成分分析(PIMRO-ARFTCN)的自適應接收場時域卷積網絡的預測模型,并且用實驗數據證明與其他方法相比,該方法在時間序列建模中具有更好的預測性能;張成君等[13]使用主成分分析法消除了影響土壤肥力因素之間的相關性,并且得到了優選的影響因子,從而提高了綜合評價結果的準確性。以上研究表明,主成分分析法能夠使用少數幾個主成分較好地表征樣本信息,不僅減少了網絡規模,而且去除了變量之間的相關性,非常符合BP 神經網絡特征優化的要求。遺傳算法[14](Genetic Algorithm,GA)通過模擬生物的遺傳機制和進化過程自適應地進行全局最優解搜索,其在并行性、魯棒性和全局性等方面均有良好表現,通過將遺傳算法引入BP 神經網絡,不僅顯著降低了陷入局部最優解的風險,還實現了網絡初始權閾值優化,最終進一步提高了網絡的穩定性[15]。
大沽河流域降水量豐沛,主要集中在汛期,有產生洪澇災害的可能性[16],因此有必要對大沽河流域進行洪水水位預測并實現洪水淹沒仿真模擬。因此,本文以山東省青島市大沽河流域為研究區域,利用計算機和虛擬現實等技術實現對大沽河流域的高真實感三維地形可視化;根據基于PG-BP 神經網絡的水位預測模型預測下一年汛期(6-9月)的河流水位,在給定水位的條件下,開展基于GIS 的洪水淹沒模擬研究,在地形模型上直觀地顯示出洪水的淹沒范圍和受災地區,為研究區域的洪水災害風險評價提供更好的依據,為防洪減災提供強有力的支撐。
1 研究區域概況
大沽河流域位于山東半島西部,約在東經120°03′~120°25′,北緯36°10′~37°12′之間,干流全長179.9km,總流域面積為6 131.3km2,其中青島市境內面積為4 781.01km2,是山東半島最大的河流[16]。大沽河流域走向大致與干流走向相同。大沽河流域汛期降雨量較為豐沛,暴雨多出現在流域北部山丘區,而山丘區植被覆蓋率較低,水土流失較嚴重,會導致洪水下泄,占滿河槽,使下游平原因排水困難產生內澇[17]。因此,精準預測河流水位變化,高效快速地進行洪水仿真模擬,能夠有效支持防洪決策,減少損失。
2 大沽河流域提取
2.1 數據來源
數字高程模型(DEM)是地形表面形態的數字化表達。它是一組有序數值的集合,其中包含了空間位置特征和地形屬性特征的信息。數字高程模型主要有3 種形式:柵格型、矢量型和不規則三角網。本文采用柵格型30m*30m 的DEM,研究區域的高程數據從地理空間數據云中獲取。輪廓圖來源于國家基礎地理信息系統。
2.2 數據預處理
由于在地理空間數據云中下載的高程數據不是連續的,不能直接使用,需要對它們進行預處理,如裁剪、鑲嵌、填洼等操作。
在ArcGIS 中對高程數據進行鑲嵌,使分塊的DEM 數據拼接起來,然后根據研究區域輪廓圖對鑲嵌得到的DEM數據進行裁剪,就能夠獲取研究區域的高程數據。
對DEM 進行填洼。洼地的形成有兩種情況,一種是真實地理情況,如盆地、湖泊、喀斯特地貌等,還有一種是人為因素造成的地形誤差[18]。這種人為因素造成的誤差由采集地形信息的工作人員在采集數據時因選取精度問題而產生[19]。因此,在使用ArcGIS 軟件對DEM 數據進行水文分析時,會因為一些異常數據產生錯誤的分析結果,流域在進行水文分析之前,必須剔除這些異常數據,這些異常數據也被稱為偽洼地。填洼前和填洼后對比如圖1 所示(彩圖掃OSID 碼可見)。
2.3 流域水文分析
2.3.1 流向分析
本文采用D8 單流向算法進行流向分析。D8 算法是假定雨水降落在地形中某一個格子上,該格子的水將會流向周圍8 個格子地形最低的格子中。如果多個像元格子的最大下降方向都相同,則會擴大相鄰像元范圍,直到找到最陡下降方向為止。流向分析結果如圖2(a)所示。
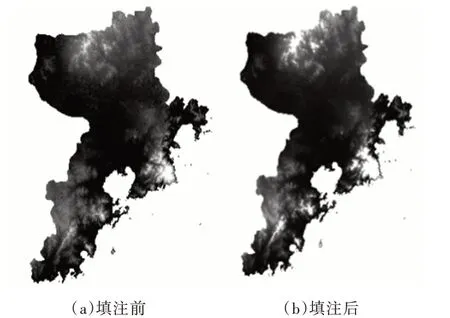
Fig.1 Comparison before and after filling圖1 填洼前后對比
2.3.2 流量統計
流量統計的實際意義在于在一定流量值時會產生地表徑流,在徑流達到一定數值時成為常規河流。因此,在進行流量統計后,必須對統計的柵格數據進行重分類和篩選。流量統計結果如圖2(b)所示。
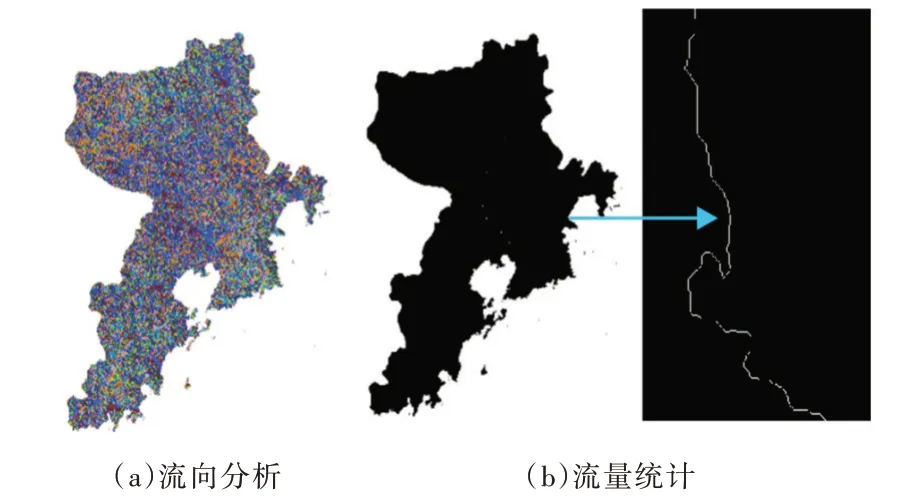
Fig.2 Flow direction and flow accumulation圖2 流向與流量統計結果
2.3.3 河流水系生成與流域劃分
通過示范區建設,加強農業基礎設施,改善農民的生產、生活條件,擴大農機化服務功能,提高了科技對農業的貢獻率,并通過技術培訓,使農民的科技文化素質得到提高。
河流主要根據水流累積量大小判定,水流累積量越小,河流劃分越細,流域劃分結果如圖3(a)所示。流域提取是根據河流的流向和出水口共同確定的空間范圍,流域提取結果如圖3(b)所示。圖3(c)是最終提取出的大沽河流域。
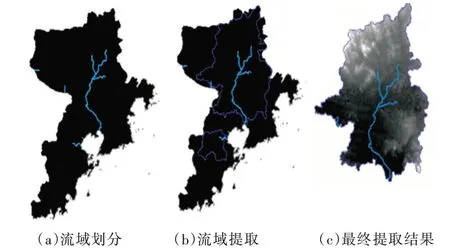
Fig.3 Formation of river system and division of river basin圖3 河流水系生成與流域劃分
3 水位預測模型
3.1 灰色關聯度分析
關聯度指兩個系統之間的因素隨時間或者不同對象的變化而產生變化的關聯性大小的度量。在系統發展過程中,若兩個因素的變化趨勢一致,代表二者之間關聯程度較高;反之,則較低。因此,灰色關聯分析方法是根據因素之間發展趨勢的相似或相異程度作為衡量因素間關聯程度的一種方法[20-21]。
3.2 主成分分析原理
假設X1,X2,…,Xn為n個隨機變量,記X=(X1X2…Xn)T。設取自X的一個容量為m的簡單隨機樣本xi(i=1,2,…,m),S為xi的樣本協方差矩陣,其特征值及相應的單位正交向量為λ1≥λ2≥… ≥λn≥0 和e1,e2,…,en,則第i個樣本主成分為:
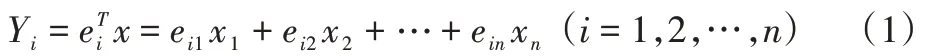
式中,x=(x1x2…xn)T,T為X的任一觀測值,ei=(ei1ei2…ein)T。當依次代入X 的m個觀測值時,便得到第i個樣本主成分的m個觀測值Yki(k=1,2,…,m),并稱為第i個主成分的得分。第i個特征值與各特征值之和的比值稱為第i個樣本主成分的貢獻率,選取前p個樣本主成分,使其累計貢獻率達到一定要求(如80%以上),并以前p個樣本主成分的得分代替原始數據作分析[6,22]。
3.3 遺傳算法優化BP 神經網絡算法
本文選用GA 優化BP 神經網絡是想利用GA 的尋優操作得到最優初始值,用染色體表達其初始值,將所期望樣本數據的范數當作輸出量,進一步得到所需的適應度值,經過算法的一系列運算得到所需最優解,也即算法最開始的初始值[23]。尋優后的BP 神經網絡能夠更加準確地預測所期望的函數值。目前,大部分非線性問題選用單層隱含層結構的BP 模型就能夠很好地得到解決,因此本文采用三層BP 神經網絡模型加以分析。
3.4 PG-BP 神經網絡水位預測模型
本文首先使用灰色關聯度分析確定影響水位變化的主要因素,然后對這些影響因素進行主成分分析,通過線性組合構造綜合因子,分別計算各綜合因子的貢獻率,并以累計貢獻率達到一定數值的前m 個綜合因子為輸入變量導入GA-BP 神經網絡模型。為了綜合考量實驗模型的效果,本文使用均方根誤差(RMSE)及預報準確率(FA)進行分析[24]。式中,y(pred)表示預測值,y(raw)表示實際值。
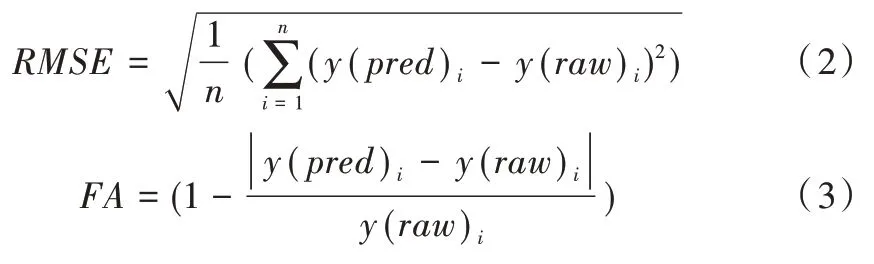
3.5 研究區域水位預測
3.5.1 大沽河水位變化及其影響因素
根據河流水位動態分析,初步選取影響河流水位的影響因子月降雨量(x1/mm)、月蒸發量(x2/mm)、月平均氣溫(x3/°C)、月出水量(x4/萬m3)、月進水量(x5/萬m3)五類。由于汛期暴雨大多出現在大沽河流域上游,選取2000-2019年大沽河上游河段產芝水文站的統計數據為樣本,使用MATLAB 對樣本數據進行灰色關聯分析,得到大沽河水位與其影響因素的關聯度如表1 所示。取閾值為0.7,即排除關聯度小于0.7 的影響因素,最終確定的影響因素為:月降雨量、月蒸發量、月出水量、月進水量。

Table 1 Correlation degree between river water level and influencing factors表1 河流水位與各影響因素關聯度
根據灰色關聯分析確定的影響大沽河水位變化的優選指標進行主成分分析,進一步優化選定指標,確定輸入指標。主成分分析結果如表2 所示。由表2 可知,前3 個主成分的累計貢獻率達到80%以上,根據主成分分析原理,前3 個主成分(Y1,Y2,Y3)基本能夠代表原始數據的所有信息。
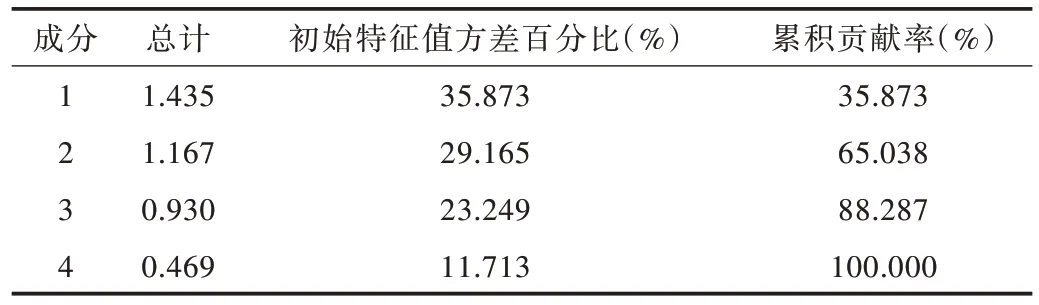
Table 2 Results of principal component analysis表2 主成分分析結果
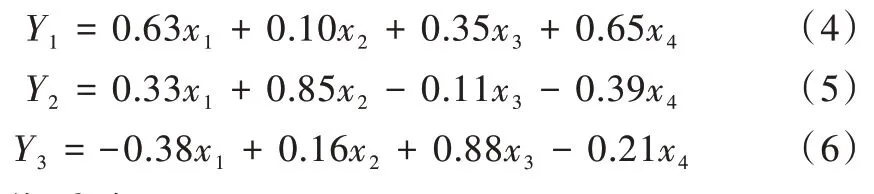
3.5.3 水位預測
本文以3 個主成分(Y1,Y2,Y3)為GA-BP 神經網絡模型輸入層的輸入變量,以汛期的月平均水位為輸出變量(T),構建了PG-BP 神經網絡模型。為檢驗PG-BP 神經網絡模型性能,分別建立BP、PCA-BP 的神經網絡預測模型進行對比。PG-BP 模型與PCA-BP 模型的參數選取一致,結構為(3,8,1),學習率為0.05,最大訓練次數為100,目標誤差為0.001。其中,PG-BP 中交叉率為0.6,變異率為0.1,迭代次數為100,種群規模為60。以月降雨量、月蒸發量、月出水量、月進水量為傳統的BP 神經網絡輸入層數據,模型結構為(4,8,1),學習率為0.05,最大訓練次數為100,目標誤差為0.001。選取2010-2018 年汛期(6-9 月)的水文數據為訓練數據,2019 年汛期的月平均水位為輸出數據,預測結果如表3 所示。
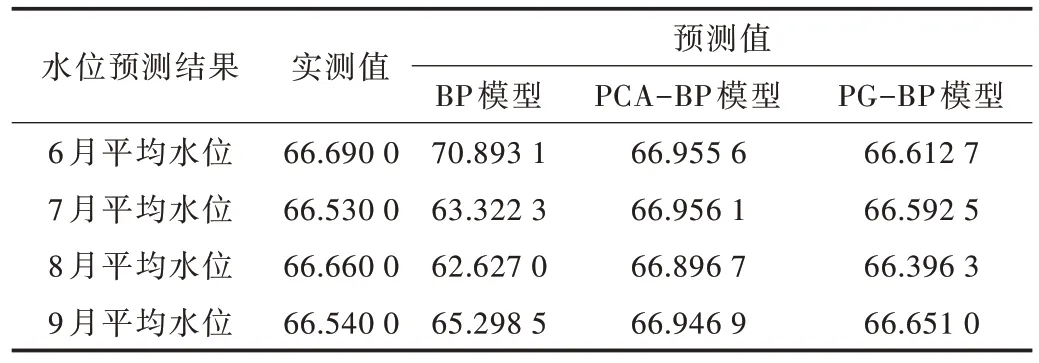
Table 3 Prediction results of neural network model表3 神經網絡模型預測結果
2019 年汛期的河流水位預測結果如表4 所示,可以看出PG-BP 神經網絡預測模型的均方根誤差為0.15,遠低于單一的BP 神經網絡預測模型,略低于PCA-BP 模型;PGBP 模型的預報準確率高達99.8%,均高于其它兩個模型的預報準確率。實驗結果表明,PG-BP 神經網絡模型擬合精度較高,效果較好。
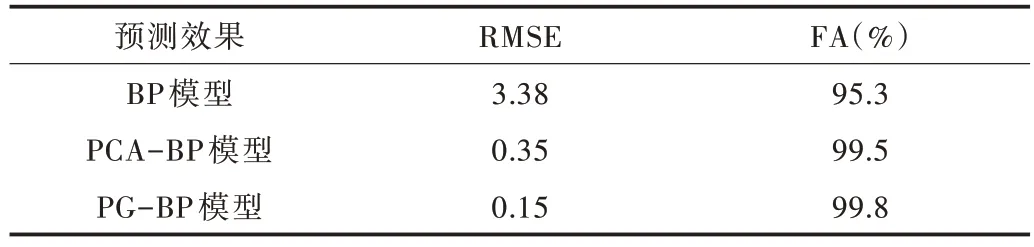
Table 4 Comparison of prediction results表4 預測效果對比
4 洪水淹沒模擬
4.1 可視化相關技術
地形可視化涉及復雜的空間異構數據,主要用到以下幾種軟件工具。ArcGIS(https://developers.arcgis.com/)是ESRI 公司研發的地理信息編輯和管理軟件。本文利用該軟件對空間數據進行鑲嵌、裁剪、統一坐標系等操作。Da?ta Explorer(https://www.opengeosys.org/)是德國赫姆霍茲環境研究中心所研發的地理信息顯示框架,支持多種格式的數據導入和導出,本文利用該軟件進行可視化建模和數據集成。ParaView(https://www.paraview.org/)是由桑迪亞國家實驗室、Kitware 公司和洛斯阿拉莫斯國家實驗室共同開發的一個開源的多平臺數據分析和可視化應用程序。本文使用該軟件進行格式轉化,將普及性較低的多邊形數據文件vtp 格式轉化為Unity3D 能夠識別的通用三維表達的fbx 格式文件。MiddleVR(https://www.middlevr.com/home/)是一個沉浸式虛擬現實插件,其為Unity3D 提供三維場景中自動虛擬現實集成、身臨其境的導航、多人協作等功能。本文通過MiddleVR 為虛擬場景添加多種導航功能,使瀏覽更加便捷。Unity3D(http://unity3d.com/)是由Unity Tech?nologies 開發的一個全面整合的專業游戲引擎,由于它強大的虛擬仿真功能,本文利用Unity3D 進行洪澇災害仿真模擬。
4.2 研究區域三維地形可視化
4.2.1 數據獲取與處理
研究區域輪廓圖在國家基礎地理信息系統中下載獲得,高程數據源于地理空間數據云,遙感影像數據從BIGE?MAP 地圖下載器中下載。為使三維地形具有高真實感,下載的高程數據分辨率為30*30m,遙感影像數據的分辨率為1.92*1.92m。由于下載的高程數據和遙感影像不是連續的,因此需要在ArcGIS 中進行鑲嵌,將分塊的DEM 和影像數據拼接起來,然后根據研究區域輪廓圖對DEM 數據和遙感影像進行裁剪、統一坐標系等處理。
4.2.2 異構數據集成
本文通過DataExplorer 軟件對數據進行集成。導入研究區域的輪廓圖,利用軟件的Mesh Generation 工具生成該區域的不規則三角網格,在此基礎上導入DEM 數據生成地形網格模型,最后導出為vtp 格式的文件。在該過程中需要注意研究區域的輪廓圖和DEM 數據的坐標系必須一致,否則會出錯。
4.2.3 三維地形可視化
使用ParaView 軟件進行數據格式轉換,準備工作是下載一個名為“VtkFbxConverter”的插件,它可以將文件的格式從vtk 轉換為fbx;然后將fbx 格式的地形網格模型導入Unity3D 中,并將對應的衛星影像設置到對應的網格模型上,生成高真實感三維地形。根據提取出的大沽河流域輪廓,將它及附近區域分為9 塊,并在此基礎上提升不規則三角網的密度,實現大沽河流域高真實感三維地形可視化。圖4 為其中一塊區域的三維地形可視化流程。

Fig.4 3D terrain visualization process圖4 三維地形可視化流程
4.3 洪水淹沒范圍
洪水淹沒是一個非常復雜的動態變化過程。洪水淹沒的本質是水源區和被淹沒區域存在水位差,且它們之間是連通的,因而會有一個淹沒過程。洪水的淹沒范圍是指當水位達到一個平衡狀態時水流所經過的區域。本文主要研究在預測水位條件下的洪水淹沒范圍。
在給定水位的條件下,計算洪水的淹沒范圍,主要有兩種情況[25]。一種是將所有高程值低于該水位值的柵格記入淹沒范圍,雖然這種“水平面”近似方法沒有考慮到地域的連通性,但是可以高效快速地計算出近似淹沒范圍,在防洪抗災工作中具有重要意義;另一種是在第一種情況的基礎上,考慮到地域連通,洪水從源點沿著地表流動,當水位達到平衡狀態時,洪水所經過的地區被記為淹沒區,也即存在低于洪水水位的低洼地區由于地形原因而不會被淹沒。根據PG-BP 神經網絡的水位預測模型預測出河流水位,若預測的汛期水位高于河流的堤防,則采用“水平面”近似方法在集水區的范圍內進行洪水淹沒模擬。
當河流水位預測結果為50m 時,即將大沽河流域范圍內高程值低于該水位值的區域都記入淹沒區。大沽河流域范圍內淹沒情況如圖5(a)所示,提取出的淹沒范圍如圖5(b)所示。同理,當河流水位預測結果為70m 時,大沽河流域范圍內淹沒情況如圖5(c)所示,提取出的淹沒范圍如圖5(d)所示。
4.4 洪水淹沒可視化
在實現研究區域可視化的基礎上,將洪水的淹沒范圍添加到三維地形上,實現洪水淹沒可視化。圖6 分別是水位為50m 和70m 時洪水淹沒的可視化仿真模擬。

Fig.5 Flood submergence range under different water levels圖5 不同水位下的洪水淹沒范圍

Fig.6 Flooding simulation圖6 洪水淹沒模擬
5 結語
本文提出結合主成分分析和神經網絡的PG-BP 的河流水位預測模型,對大沽河流域的汛期水位進行研究,并在此基礎上借助GIS、Unity 等技術實現了大沽河流域洪水淹沒的三維可視化。水位預測模型的實驗結果表明,引入主成分分析的GA-BP 神經網絡預測模型準確度達99.8%,該模型擬合精度較高、效果較好,具有一定適用性。并且,洪水淹沒的可視化模擬能夠清楚地顯示出受災范圍,可為防洪決策提供有力支撐。但研究中也存在一些不足:①本文建立的PG-BP 神經網絡水位預測模型在選取影響水位因子時帶有一定主觀性,會對預測結果產生影響,其選取依據和方法還需作深入研究;②在給定水位的情況下,洪水淹沒區的確定沒有考慮到地域的連通性,有些低洼地區由于受到周圍地形的影響而不會被淹沒,因此要對淹沒范圍作進一步分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
光學精密工程(2016年6期)2016-11-07 09:07:19
