康養(yǎng)型住宅大數據分析與智能控制
2021-05-25 05:27:00江桃,張珣
軟件導刊 2021年5期
江 桃,張 珣
(杭州電子科技大學電子信息學院,浙江杭州 310018)
0 引言
近年來我國老齡化人口比例不斷增加,獨生子女因工作等原因無法照顧老人,居家養(yǎng)老[1]是大部分老人的選擇,但護理人員緊缺,老年人對常規(guī)的智能家居使用方式難以適應。在物聯網技術、計算機網絡技術以及數據挖掘技術跨越式發(fā)展的大背景下,智能家居發(fā)展呈現出突飛猛進態(tài)勢[2],智能家居系統(tǒng)向更高級的具有學習能力的自主操控方向發(fā)展。
智能家居系統(tǒng)研究較多,如英國的“智能家居交互屋系統(tǒng)”[3],通過與日常生活數據對比來檢測老年人健康狀況,有異常時自主向外界求救;芬蘭的“活躍家庭生活”居家養(yǎng)老科技產品,在各個房間安裝傳感器,通過傳感器數據分析老年人的位置信息,監(jiān)測活動信息有無異常;我國“基于物聯網ZigBee 技術的智能社區(qū)居家養(yǎng)老系統(tǒng)”[4],利用物聯網ZigBee 技術實現對老人的身體狀況、居家安全、環(huán)境能耗等方面的智能監(jiān)測,可實時將監(jiān)測數據傳輸到社區(qū)監(jiān)護中心。以上技術在一定程度上對老人健康與生活行為數據進行異常分析,但是忽略了老年人的認知特點,即他們對高智能設備的學習能力以及接受能力不及年輕人。另外,健康數據獲取一般通過佩戴相應的檢測模塊,增加了老人的心理負擔。
本文對數據挖掘算法進行優(yōu)化改進,挖掘和識別用戶多種生活行為,得出用戶的習慣模型,根據用戶的偏好自動調控設備參數,或者根據環(huán)境因素變化,按照用戶在不同環(huán)境的使用習慣自動調控,以及對多個設備聯動調控,為老年人提供精準的智能服務。
1 智能控制系統(tǒng)設計
1.1 系統(tǒng)總體架構
本系統(tǒng)架構采用B/S 模式即瀏覽器/服務器模式。系統(tǒng)前端頁面采用HTML、CSS、JavaScript 等技術設計,前后端交換數據通信時采用Ajax 技術使頁面不跳轉,響應速度加快,在Web 客戶端處理少量簡單的業(yè)務邏輯和數據操作。服務端利用SSM(Spring,Spring MVC,Mybatis)等開源框架技術,在阿里云平臺搭建Tomcat web 服務器、Hadoop+MySQL 數據庫,解決智能家居用戶海量的數據存儲問題。而復雜的業(yè)務邏輯和數據分析通過在服務端MySQL 數據庫采集智能網關的傳感器數據以及無線智能設備使用的歷史數據,進行大數據分析,獲得用戶習慣模式,與當前模式進行匹配從而實現系統(tǒng)的智能控制。系統(tǒng)框圖如圖1 所示。
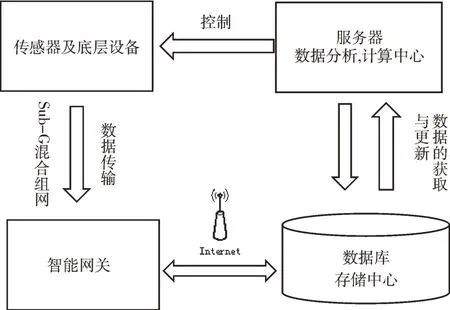
Fig.1 System architecture圖1 系統(tǒng)架構
1.2 老年人群的特點與需求
老年人的認知特點:①感官能力(視覺、聽覺、嗅覺等)逐漸衰退,身體的協(xié)調性、靈活性也相應下降;②注意力不易集中,警覺性較低,在異常情況中的應變能力降低;③記憶力下降,學習能力也大幅降低。
面向老年人的系統(tǒng)需求:操作簡便實用、舒適的家居環(huán)境、智能化的設備、安全保障。
1.3 系統(tǒng)功能需求
(1)數據采集與傳輸需求。對家庭環(huán)境參數如溫度、濕度、光照等諸多模擬量的采集,智能家電以及燈具的開關量采集。因為采集的數據要供后續(xù)的行為分析預測及建立行為偏好模型,所以要進行數據預處理,剔除孤立、敏感的數據點;要保證同步采集的數據能夠完整存入服務器平臺數據庫,以供后續(xù)分析預測。
(2)服務器數據平臺需求。服務器數據平臺主要由Web 訪問頁和數據庫管理系統(tǒng)構成。Web 頁面提供基本的用戶和設備信息操作,數據庫管理系統(tǒng)主要負責用戶和設備歷史操控信息,以及傳感器獲取的上下文信息存儲與管理。
(3)服務器數據分析模塊需求。對數據進行挖掘,實現行為分析與預測,建立偏好模型,根據歷史信息推斷老人的異常行為,推送異常信息。
(4)用戶信息模塊需求。服務器平臺用戶分為使用設備的老人、老人子女和系統(tǒng)管理員3 類。注冊老人基本信息、子女信息包括注冊登錄、個人信息修改和設備運行結果查詢。系統(tǒng)管理員則登錄至系統(tǒng)后臺,對設備、平臺以及用戶數據進行管理。
2 操控行為大數據分析
智能家居數據非常龐大,可能涉及數百萬條記錄,每個記錄通常達到數百個屬性[13]。基于Hadoop 的數據處理平臺對大量傳感信息進行分布式并行處理,并根據處理結果向底層設備發(fā)送指令實現智慧化服務[14]。
2.1 Hadoop 技術
Hadoop 是對大量數據進行分布式處理的軟件框架,以可靠、高效、可伸縮的方式進行大數據處理,以并行的方式工作,通過并行處理加快處理速度,具有高可靠性、高擴展性、高效性、高容錯性的優(yōu)點。
Hadoop 框架核心是HDFS 和MapReduce。HDFS 為海量的數據提供存儲,而MapReduce 至少包含Map 函數、Re?duce 函數。Map 函數接受一組數據并將其轉換為鍵值對列表,輸入域中的每個元素對應一個鍵值對。Reduce 函數接受Map 函數生成的列表,根據它們的鍵縮小為鍵值對[9]。Hadoop 框架數據存儲與處理框架如圖2 所示。
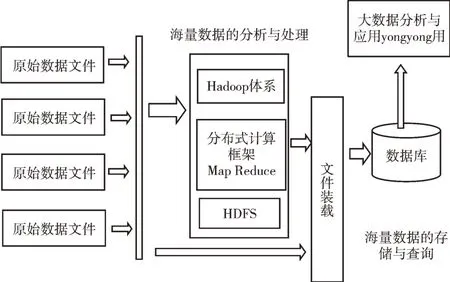
Fig.2 Hadoop framework data storage and processing framework圖2 Hadoop 框架數據存儲與處理框架
2.2 聚類分析算法
聚類分析屬于無監(jiān)督學習任務,在學習過程中不需要知道目標值,也不需要輸入每條數據的標簽。聚類分析主要任務就是從大量的無標簽數據中分析出數據的共同特征,并嘗試為每個數據分配一個比較合適的標簽。可挖掘用戶的某些屬性進行聚類,得到用戶對某一設備的控制習慣,從而建立用戶偏好模型。傳統(tǒng)K-means 聚類算法由于其簡潔和高效的特性被廣泛使用,K-means 聚類算法步驟如下:
(1)為每個聚類確定一個初始凝聚點。可選擇K 個樣品作為初始凝聚點,或者將所有樣品分成K 個初始類,然后將K 個類的重心(均值)作為初始凝聚點。
(3)將計算得到的類內樣本均值作為新的凝聚點。
(4)重復步驟(2)和(3),直到聚類中心位置幾乎不變。
(5)輸出:含有K 個M 維質心向量的集合。
由以上步驟可知,K-means 聚類算法選取的質心是隨機的,生成的K 個類別簇也是人為選定的,而且對噪聲和孤立的數據點異常敏感,這些都會導致聚類結果不穩(wěn)定。為減少選取類別簇的數量K 的影響,提高算法自組織能力,提出融合自組織神經網絡SOM 算法對數據特征向量進行訓練,將此作為K-means 聚類算法的K 個初始聚類中心,得出最終的行為偏好模型。
2.3 融合自組織神經網絡的K-means 算法
SOM 算法可以最大限度地保障訓練不會陷入局部最優(yōu)解,其代價是訓練時間較長,而K-means 算法聚類時間短但是易陷入局部最優(yōu)解。結合SOM 的優(yōu)點可先將數據輸入SOM 網絡進行初始聚類,再將這些結果作為K-means 算法的初始聚類中心,從而得到最終的聚類結果[10-12]。實現框圖如圖3 所示,具體步驟如下:

Fig.3 Clustering process圖3 聚類流程
(1)對每個神經元隨機初始化,參考權值向量wj(j=1,2,……p)。
(2)尋找獲勝的神經元。求出輸入樣本與所有神經元所對應的參考權值向量的歐式距離,與最小距離對應的即為獲勝神經元。
兩個m 維類別向量Xi,Xj的歐氏距離如下:
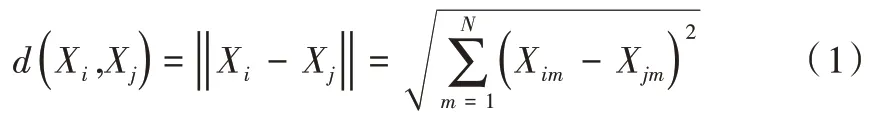
Wj中優(yōu)勝者權值向量與輸入樣本Xi的距離為:
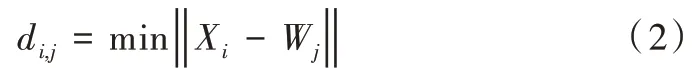
更新獲勝神經元的鄰域函數及其它神經元權值:
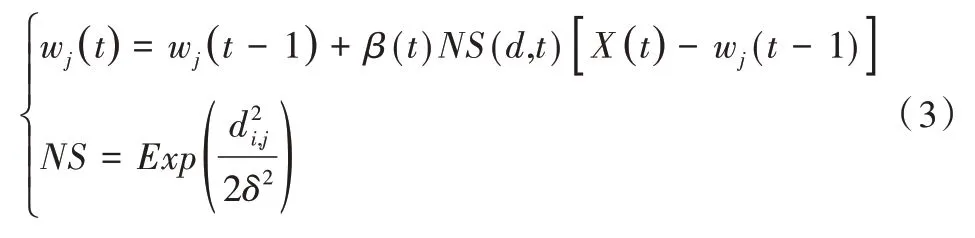
其中,i是輸入的第i個神經元,j是第j個競爭神經元;wj(t)是在t次迭代后的權值更新;wj(t-1)是在前一次迭代的權值更新;β(t)是隨著迭代t變化的學習率變化;NS(d,t)是鄰域強度,由在迭代t時刻從獲勝者到一個鄰點神經元的距離d的函數表示;x(t)是在第t次迭代所表示的輸入向量。
(3)迭代足夠的次數獲得最終的聚類中心。
(4)將SOM 算法得到的聚類中心作為K-means 算法的初始聚類中心和K 的數值。
(5)計算簇中數據對象到初始聚類中心的距離,所得距離靠近的劃分為一個簇:
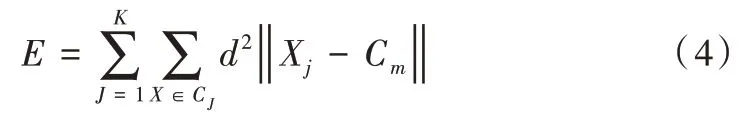
(6)將所得簇的均值作為新的聚類中心重新聚類,直到所得聚類中心不再改變。
2.4 關聯控制算法
為讓老年人群更加適應智能家居環(huán)境,本文采用關聯分析算法Apriori 利用用戶的歷史設備使用信息分析多個設備控制模式之間的關聯性,并將這個關聯性轉換為智能家居情景自動生成模式。
在大規(guī)模混雜的數據集中尋找出一些具有較強關聯性的規(guī)則即關聯規(guī)則。在智能家居領域挖掘出隱含在多個智能家居設備操作之間的相互關系可實現用戶的“關聯操控習慣”,對多個家居設備進行集成控制。
常用的頻繁項集評估標準有支持度、置信度,流程框圖如圖4 所示,實現步驟如下:
(1)輸入界定頻繁與非頻繁的最小支持度事物集T。
(2)從事件集合E 中抽取若干個事件組合生成多個元素互不完全相同的候選集合C。
(3)遍歷所有的候選集,計算候選集的支持度support(包含X 和Y 的事件數與所有事件數之比)。
Support(X=>Y)=P(X∪Y)=count(X ∪Y)/|T|(5)
(4)如果支持度大于最小支持度,則將該集合認定為頻繁項集保存到結果中。
(5)關聯規(guī)則生成:從頻繁項集中提取所有高置信度的規(guī)則,即一個事件出現后另一個事件出現的概率。
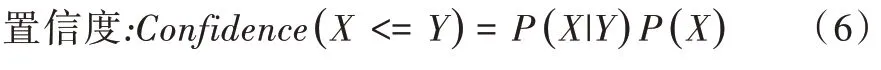
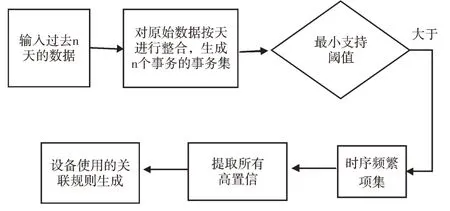
Fig.4 Flow of association analysis algorithm圖4 關聯分析算法流程
3 行為分析與預測模型實現
3.1 數據采集
在一個復雜的智能家居環(huán)境中,通過組建的無線傳感器網絡收集環(huán)境數據與設備的使用日志,即在服務端記錄的設備和服務端交互通信產生的數據。數據對象對應于傳感器和設備的狀態(tài)和功能,用戶活動標識符(ID)由該活動執(zhí)行的服務ID 以及相關的對象ID 按時間順序存儲在數據庫中。為老年用戶提供傳感器網絡與家庭環(huán)境有效的智能交互,如用戶在不同位置、不同的時間時的行為數據。傳感器會獲取當前環(huán)境的上下文信息,如時間、位置、溫度、設備狀態(tài)、壓力等。以燈光為例日志數據如表1 所示。

Table 1 Log data generated by control lights表1 控制燈光產生的日志數據
3.2 數據預處理
對采集的數據進行清洗、去噪等操作,減少數據冗余,方便數據分析。將經過數據挖掘分析出的用戶活動標識與設備使用習慣等行為特征作為活動唯一標識,ID 作為key,行為特征作為value,值之間用逗號隔開,以鍵值形式存儲。
3.3 數據分析與實現
數據分析模塊利用基于自組織神經網絡SOM 改進的K-means 聚類算法,挖掘老年用戶在不同時間段、不同位置對某一設備的使用習慣屬性值,即聚類中的特征值,如用戶在不同房間、不同時間段對燈光亮度的習慣使用屬性值。臥房接近睡覺時間段的燈光亮度要柔和,在客廳活動的時段燈光要亮等,對其進行聚類分析,燈光控制參數可表示為Xi向量,其中包括時間段、位置、時間、亮度等p種屬性,表示為{X1,Xi2,…,Xip}。將設備的歷史使用信息數據采用基于SOM 改進的k-means 算法聚類。
服務端的數據分析模塊利用關聯規(guī)則算法Apriori 挖掘在同一時間段內多個設備使用的相互關系,以時間戳序列記錄已經使用過的設備數據,從而得到用戶關聯操控數據。對用戶在某一時間段的行為進行識別,對下一個行為進行預測,為老年用戶提供基于其習慣的關聯操控以及家居活動軌跡預測。如將設備使用進行事務序列化,不同設備用不同的字母表示,A、B、C…,同一設備的不同時間段用字母表示為:[A1,A2,A3…],[B1,B2,B3…]等。
利用數據聚類確定設備與時間和環(huán)境因素的關聯,然后應用頻繁模式挖掘發(fā)現設備與設備的關聯,通過這兩個過程提取不同設備按時間序列以及按區(qū)域劃分的使用模式,將這些模式存入數據庫中進行活動預測[13]。當系統(tǒng)無法判斷當前新產生的模式時,先反饋給用戶,由用戶決定這一模式是否安全,作為新的模式存入數據庫。模型建立流程如圖5 所示。

Fig.5 Process of behavior analysis model establishment圖5 行為分析模型建立流程
4 結語
本文基于SOM 算法改進的K-means 算法和Apriori 算法,結合大數據分析、無線傳感器網絡等技術,在傳統(tǒng)居家智能家居系統(tǒng)基礎上研究適合老年人生活的康養(yǎng)型智能住宅。簡化智能家居設備的控制指令,通過關聯規(guī)則分析,將某一時間的多個設備進行關聯以推測老人當時的活動類型,為居家養(yǎng)老提供更加舒適智能的生活。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
當代陜西(2021年17期)2021-11-06 03:21:36
電子制作(2018年11期)2018-08-04 03:26:08
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
工業(yè)設計(2016年12期)2016-04-16 02:52:00
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
